
子区域视觉短语稀疏编码的图像检索
2015-02-22 01:47王瑞霞彭国华
西北工业大学学报 2015年5期
关键词:角点
王瑞霞, 彭国华
(西北工业大学 理学院, 陕西 西安 710129)
子区域视觉短语稀疏编码的图像检索
王瑞霞, 彭国华
(西北工业大学 理学院, 陕西 西安710129)
摘要:针对BOVW模型忽略图像特征空间排列导致量化误差较大的缺点,利用角点和特征点对图像进行区域分割,结合区域的空间排列信息,提出一种多通道融合的图像检索方法。其主要思想是将子区域编码和特征空间排列直方图结合组建视觉短语,这种构造方式在减少编码误差的同时还能更好地保留局部空间信息。首先,利用稀疏编码保留局部信息的高效性对提取的子区域进行编码;其次,利用特征的空间位置关系,计算子区域内的特征空间排列直方图;利用区域编码和特征排列直方图构建视觉短语;最后,结合BOVW模型的鲁棒性,统计视觉短语直方图用于图像检索。实验结果表明,该检索方法不仅比BOVW和SPMBOVM有更好的检索准确率,而且其编码过程稳定,误差较小。
关键词:角点; BOVW模型;视觉短语;稀疏编码;图像检索;SPM模型
视觉词袋模型(bag-of-visual-words,简写BOVW是由词袋(bag-of-words,简写BOW)模型演变而来,图像的词袋思想最初是由Zhu Lei等[1]引入计算机视觉。由于其思想简单,对图像的目标位置和形变具有鲁棒性,近几年得到了广泛关注和应用,尤其在图像检索、视频检索以及多媒体信息检索方面已经取得许多研究成果,具有重要的实用价值。
2003年J.Sivic和A.Zisserman[2]首次提出了BOVW模型在目标检索中的应用,并获得良好的效果。该模型采用局部特征直方图表示图像,虽然对特征的空间平移不变具有稳定性,但直方图量化过程损失了图像的空间位置信息,并且忽略了特征的语义理解,检索结果只针对个别简单类有效果。针对该缺点,S.Lazebnik等[3]通过研究局部区域的空间信息,提出了空间金字塔匹配(spatial pyramid match,简写SPM)BOVW模型。它不需要考虑复杂的空间几何关系却能有效利用图像的局部空间信息,节约了计算成本。但SPM的每个块(block)仍然采用直方图量化形式,使得图像表示的空间信息不足,使得图像视觉描述和语义理解之间还存在很大差距,对于目标和背景界限不清以及背景稍微复杂的图片分类结果很差。在上述2个模型的基础上,Yang Jianchao等[4]使用稀疏编码(sparse code,简写SC)进一步改进了模型中的缺点,它将线性支持向量机(support vector machine,简写SVM)应用到SPM,并把量化直方图转换成稀疏编码,不仅利用了图像的空间信息,而且减少了直方图的量化误差,同时线性SVM的应用也节约了计算成本。但它的缺点是相似的block在编码过程中会得到完全不同的码,导致编码过程不稳定,而这一点恰恰是直方图的优点。
因此,本文在稀疏编码模型基础上,利用局部空间排列信息,结合稀疏编码算法保留局部信息的高效性和BOVW模型的鲁棒性,提出一种基于稀疏编码的视觉短语(bag-of-visual-phrases, 简写BOVP)模型。该方法包含2个部分:(1)构建视觉短语:第一,利用角点分割图像为一系列子区域,利用特征点提取有效子区域;第二,利用max pooling函数对子区域进行稀疏编码;第三,统计子区域的特征空间排列直方图,构建区域视觉短语。(2)结合BOVW模型,计算图像视觉短语量化直方图。与BOVW模型和SPM-BOVW模型比较,实验结果表明该检索方法不仅提高了图像的检索效率,而且编码误差较小,编码过程比较稳定。
1理论知识
1.1BOVW模型
bag-of-visual-words模型是由用在文本分类中的bag-of-words模型扩展而来的。它把1副图像看成是由许多block组成,1个block就是1个视觉词,比如1幅人脸图像,眼睛、鼻子、嘴、人脸、头发分别都看成1个block,其主要思想框架如下:
1) 选择特征提取方法提取图像的特征,经典的BOVW算法采用的是sift特征提取算法;
2) 对提取的所有特征用k-means聚类,把相近的特征归为一类,得到k个聚类中心,这k个聚类中心构成视觉词典;
3) 计算所有特征与视觉词典中每个视觉词的相似度,一般采用欧氏距离计算,找出视觉词典中与特征距离最近的视觉词;
4) 统计1幅图像中视觉词的个数,得到图像的直方图表示(如图1所示)。

图1 BOVW模型示意图
BOVW模型虽然具有很好的鲁棒性,但却完全忽略特征空间位置信息,大大降低了其性能。
1.2SPMBOVW模型
在SPM模型的启发下, S.Lazebnik等提出了SPMBOVW模型。该模型是在BOVW基础上提出的,如果SPM只有1层,与BOVW一致。SPM把图像划分成越来越细的空间子区域,对每个子区域统计特征直方图,典型的3层分解为1×1、2×2、4×4的子区域,该模型对空间金字塔划分的各层子区域分别使用BOVW模型的直方图量化表示(如图2所示)。然而, 随着分级层数的增加,目标在图像中的位置、形状越来越敏感,使得最终图像的表示形式越来越不稳定,该方法相对于BOVW模型的优势便荡然无存,并且由于对子区域仍采用直方图量化形式,使得局部空间信息不足,背景稍复杂的图片处理结果不理想。
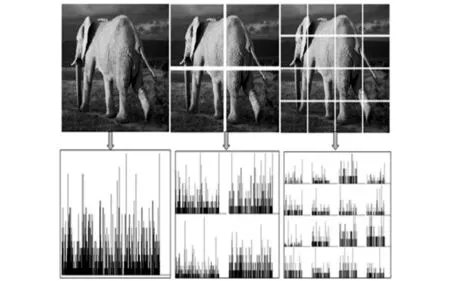
图2 SPM-BOVW模型示意图
其中,图2上部从左到右依次表示空间金字塔第1层、第2层和第3层分割结果图,下部从左到右依次表示相对应的每层空间金字塔的统计直方图;3层空间金字塔一共构成了21个子区域,每一层的权重分别为1/4、1/4、1/2。
1.3稀疏编码公式
稀疏编码作为一类有效的技术已经被成功应用在许多计算机视觉领域,如图像分类、图像识别等[5-6]。设X=[X1,X2,…,XN]∈RD×N是1幅图像的特征,Xi是局部特征描述子,B=[B1,B2,…,BM]∈RD×M为码本,是由所有图像局部描述子通过聚类得到的M个聚类中心组成,Bi是码本中的第i个码词。图像的每个局部描述子Xi通过码本B进行编码生成一个M维的稀疏向量。
稀疏编码公式定义如下:
满足条件:‖Bi‖≤1,∀i=1,2,…,M。
(1)式中的第1项是重构误差,第2项是用来控制稀疏码Ci的稀疏性,λ是用来平衡稀疏性和重构误差的权衡因子。
通常码本B是过完备的,这个特性保证了重构系数的稀疏性。但是,码本的过完备损失了编码特征的局部信息,使得相似的特征可能被编码成完全不同的码,导致编码过程的不稳定性[4]。
1.4Max pooling函数

式中:Zi表示第i个block所表示的子区域编码,Ci1,Ci2,…,Cin表示系数矩阵C∈RM×N的i1,i2,…,in列,是第i个block中所包含的ni个局部特征描述子的编码,其中:N=∑ni。
2子区域视觉短语稀疏编码的图像检索算法
SPMBOVW模型的优点是空间金字塔将图像划分为一系列按顺序排列的block,每个block看成1个整体,以此来融入图像的局部空间信息。因此,本文利用角点把图像分割为若干个子区域,将每个子区域看成1个block,提取每个子区域的特征排列信息。
2.1图像子区域的分割
2.1.1角点与特征点的对比
当提取1幅图像的所有特征时会发现,1幅图像有很多特征点,但并不是所有的特征都是图像目标区域的特征,有很多是属于背景区域的特征,如图3所示。图3a)中第1幅图像提取的sift特征大部分都属于海洋的信息,而这幅图片的目标却是海豚;图3b)中的第1幅图像提取的角点虽然较少,但海洋特征减少更多,相对而言信噪比提高了。图3a)和图3b)中的第2幅图像,有背景图像树枝的干扰,2幅图像比较,虽然图3b)中目标和背景的特征都有所减少,但仍能反映出图像的基本结构和内容。图3a)和图3b)中的第3幅图像对比,该图像本身虽然不太受背景的影响,但从图中可以看出检测的角点在减少特征数量的同时,还完全可以表示出莲花的结构,并且特征的减少提高了编码的速度,说明损失部分特征点是值得的。

图3 角点与特征点对比图
2.1.2子区域的分割
提取角点的位置,以角点位置为中心,R为半径,形成1个圆形区域,整幅图像将被划分成若干个子区域,如图4所示,图中每个圆圈表示1个子区域。将这些圆形区域中不包含特征点的区域直接去掉,包含特征点的作为有效区域,每个有效区域被记为1个block。
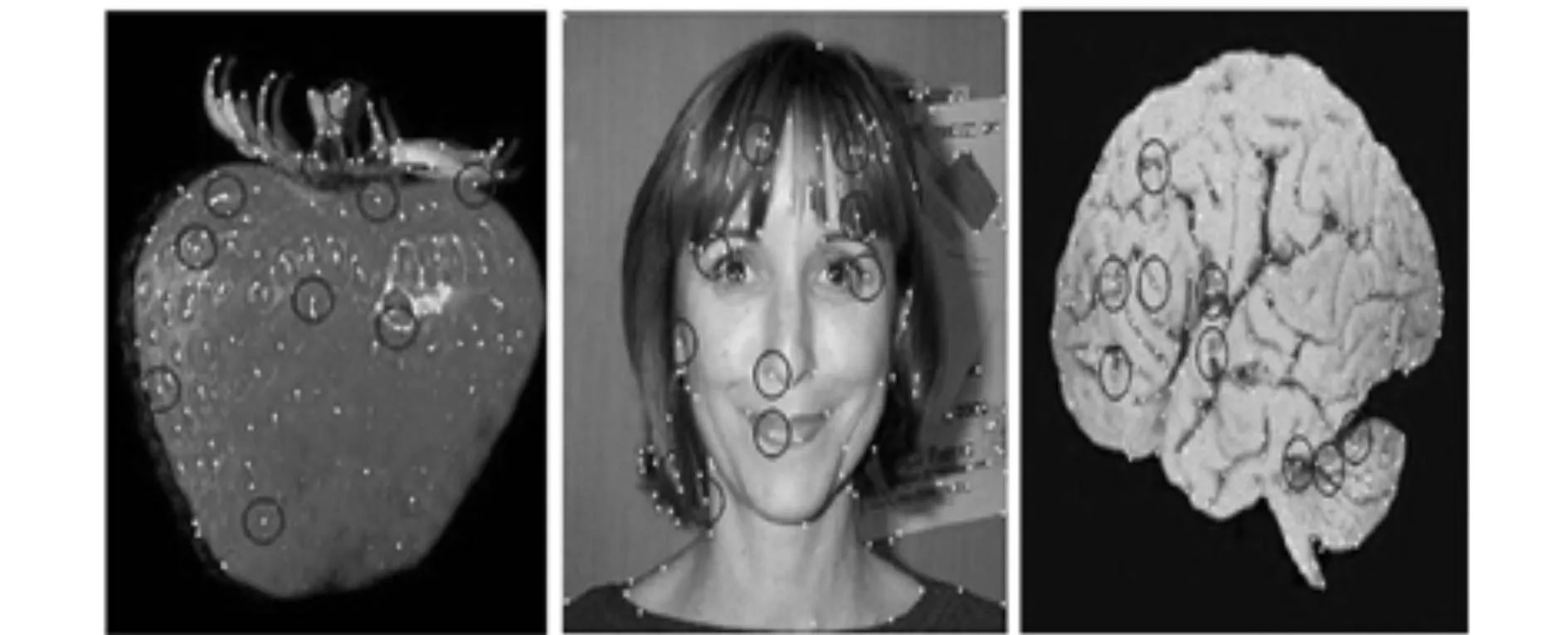
图4 子区域分割图
关于半径R的选取,R太大的话有效区域太多,利用角点筛选有效区域就没有任何意义,反而会增加计算成本;R太小则会使得包含特征点的有效区域极其少,无法表示出图片的主要内容。本文根据实验结果最终选取半径R=15。
2.2基于视觉短语的图像检索
视觉短语模型(bag-of-visual-phrase,简写BOVP)是近几年在BOVW的基础上针对图像提出来的[8-9],通常一个视觉词有多个语义信息,它能在一定程度上缓解BOVW的语义缺陷,对视觉词的空间共现模式有一定的意义。
2.2.1构建视觉短语
对提取所有图像的特征用k-means聚类,得到M个聚类中心,这M个聚类中心就是特征编码所需的码本。为了减少编码的误差,考虑到特征的多层语义信息,采用KNN法进行编码,计算视觉词与码本的距离,找出最近的K个码词表示这个视觉词。根据文献[4], 选取K=5。子区域视觉短语构建流程图如图5所示。

图5 子区域视觉短语构建流程图
子区域视觉短语构建过程:
1) 提取子区域的特征,对特征进行编码。计算每个特征和M个码本的距离,利用KNN法对特征进行编码。采用max-pooling函数融合子区域所有的特征编码系数,最终得到该子区域的稀疏编码C;
2) 统计子区域特征空间排列信息直方图。将子区域平均分为16个方向,即[0,360]平均分为16等分,根据过程(1)中1个特征点对应5个码词,按顺时针统计每个方向视觉词出现的个数,以视觉词出现最多的方向为主方向,并且该统计方式对旋转鲁棒[10]。得到其特征空间排列直方图,进行量化,得到其量化直方图H;
3) 构建视觉短语。合并子区域的稀疏编码C和特征空间排列直方图H,构建视觉短语P=[C;H],由于是2种不同方式的结合,因此需要对其进行归一化。
2.2.2统计视觉短语直方图
结合BOVW模型的鲁棒性,对提取的所有视觉短语构建视觉短语模型,其步骤如下:
1) 建立视觉短语词典。用k-means对所有视觉短语聚类,得到K个聚类中心,组成视觉短语词典,本文设置K=1 000。
2) 统计视觉短语直方图。根据视觉短语词典统计视觉短语频数,得到视觉短语直方图。
3各类算法实验结果比较
本文使用Caltech101数据库,该数据库包含101类和1个背景类,一共是102类,9 144幅图片,图片大小不一。在图像检索时,相似度的计算方法通常也会影响检索结果的准确度,用任何一种方法计算相似度都会有其弊端,因此,本文采用欧氏距离和余弦定理2种方式结合来计算相似度。对于评价准则,计算查全率和查准率得到综合评价指标F1-measure值。图6是BOVW模型、SPMBOVW模型以及本文算法的F1-measure指标对比图,给出了25类查询图像的检索结果。从图中可以看出本文提出的算法(为方便简写为RVPBOVW)虽然在个别类中检索精度有所下降,但大部分的检索结果都得到很大的提高。

图6 各类算法F1-measure指标对比图
其中:纵坐标是各类算法的F1-measure指标值,横坐标相对应的25类图像分别表示:1(airplanes)、2(accordion)、3(brain)、4(car-side)、5(butterfly)、6(dollar bill)、7(faces-easy)、8(grand piano)、9(ketch)、10(mandolin)、11(motorbikes)、12(pigeon)、13(revolver)、14(rooster)、15(schooner)、16(scissors)、17(snoopy)、18(starfish)、19(stop-sign)、20(strawberry)、21(watch)、22(water-lilly)、23(windsor-chair)、24(yin-yang)和25(wrench)。
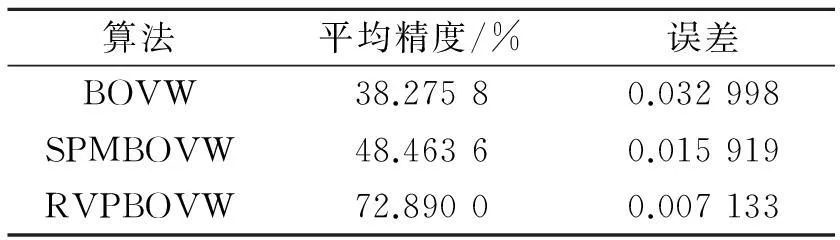
表1 各类算法平均准确率
表1给出了各类算法检索的平均准确率,可以看出本文提出的RVPBOVW算法检索平均准确率提高了24%,而且其误差也相对减少了一半,说明该方法有效地保留了特征局部空间信息,而且计算方法比较稳定。

图7 本文算法部分检索结果示例
图7列出了Caltech101数据库的部分检索结果,返回的是前30幅检索结果图,每一类图像的第1张图像为查询图像。图7说明本文方法不仅提高了每类图像的检索准确率,而且返回的相似图像排在前面的结果基本都是正确的结果图,检索排序也是检索效率的另一评判标准。
4结论
视觉短语是根据图像本身带有一定的语义信息而提出的,是对视觉词的一个扩展。利用稀疏编码保留局部信息的高效性将稀疏编码应用到视觉短语的构建中,能更好地描述图片所要表达的内容,减弱了图片描述和语义理解之间难以逾越的鸿沟。本文提出的视觉短语稀疏编码的图像检索算法不仅能够很好保留图像局部空间信息,而且减弱了编码误差引起的检索的不准确性,同时该方法有很好地鲁棒性。但编码和构建视觉短语的过程都比较花费时间,将两者结合,增加了时间计算成本,因此,如何更好的将两者结合,减少后台计算时间,提高前台检索速度,这也是进一步要考虑的问题。
参考文献:
[1]Zhu Lei, Rao Aibing, Zhang Aidong. Theory of Keyblock-Based Image Retrieval[J]. ACM Trans on Information Systems, 2002, 20(2): 224-257
[2]Sivic J, Zisserman A. Video Google: a Text Retrieval Approach to Object Matching in Videos[C]//Proceedings of the Ninth IEEE International Conference on Computer Vision. Nice, France: IEEE, 2003: 1470-1477
[3]Lazebnik S, Schmid C, Ponce J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2006: 2169-2178
[4]Yang Jianchao, Yu Kai, Gong Yihong, Huang Thomas. Linear Spatial Pyramid Matching Using Sparse Coding for Image Classification[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Miami, Florida, USA: IEEE, 2009: 1794-1801
[5]Zhang Lihe, Ma Chen. Low-Rank Decomposition and Laplacian Group Sparse Coding for Image Classification[J]. Neurocomputing, 2014, 135(7): 339-347
[6]Liu Huaping, Liu Yulong, Sun Fuchun. Traffic Sign Recognition Using Group Sparse Coding[J]. Information Sciences, 2014, 266(5): 75 - 89
[7]Wang Jinjun, Yang Jianchao, Yu Kai, et al. Locality -Constrained Linear Coding for Image Classification[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2010:3360-3367
[8]Zhang Shiliang, Tian Qi, Hua Gang, et al. Generating Descriptive Visual Words and Visual Phrases for Large-Scale Image Applications[J]. IEEE Trans on Image Process, 2011, 20(9): 2664-2677
[9]Chen Tao, Yap Kimhui, Zhang Dajiang. Discriminative Bag-of-Visual Phrase Learning for Landmark Recognition[C]//Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing. Kyoto, Japan, 2012: 893-896
[10] 张琳波,王春恒,肖柏华,邵允学. 基于Bag-of-phrases的图像表示方法[J]. 自动化学报,2012,38(1):46-54
Zhang Linbo, Wang Chunheng, Xiao Baihua, Shao Yunxue. Image Representation Using Bag-of-Phrases[J]. Acta Automatica Sinica, 2012, 38(1):46-54 (in Chinese)
Image Retrieval of Sub-Region Visual Phrases
with Sparse Coding
Wang Ruixia, Peng Guohua
(Department of Applied Mathemetics, Northwestern Polytechnical University, Xi′an, 710129, China)
Abstract:The BOVW model ignores the image feature spatial arrangement, thus causing quantization error. Considering this shortcoming, we divided an image into a series of sub-regions according to corners and features. Combining spatial arrangement information of the sub-regions, we, using multimodal fusion, proposed a new image retrieval method. The main idea is to construct visual phrases through sub-region encoding and feature spatial arrangement histograms. By this combination, it not only reduces the encoding error but also better preserves the local spatial information. First, using the advantages of sparse coding, we encoded the sub-regions; second, according to the feature spatial location relations, sub-region feature spatial arrangement histograms were calculated; third, visual phrases were composed of sub-region encoding and feature spatial arrangement histograms; at last, incorporating the robustness of BOVW model, we calculated the visual phrase histograms for image retrieval. The results and their analysis show preliminarily that the proposed retrieval method not only has better retrieval accuracy than BOVW and SPMBOVW but also its encoding is more stable and the error is smaller.
Key words:calculations, clustering algorithms, combinatorial optimization, data fusion, errors, flowcharting, functions, image coding, image retrieval, image segmentation, mathematical operators, MATLAB, mean square error, pixels, robust control, schematic diagrams, stability; corner, BOVW(bag-of-visual-words) model, visual phrase, sparse code, spatial pyramid match model
中图分类号:TP391
文献标志码:A
文章编号:1000-2758(2015)05-0721-06
作者简介:王瑞霞(1984—),女,西北工业大学博士研究生,主要从事基于内容的图像检索研究。
基金项目:国家自然科学基金(61201323)资助
收稿日期:2015-01-18
猜你喜欢
计算机应用与软件(2022年12期)2023-01-31
探测与控制学报(2022年6期)2023-01-04
现代电子技术(2022年17期)2022-09-09
计算机仿真(2021年8期)2021-11-17
现代电子技术(2021年11期)2021-06-18
计算机系统应用(2020年1期)2020-01-15
电子技术与软件工程(2019年9期)2019-07-12
电子技术与软件工程(2018年10期)2018-07-16
陕西科技大学学报(2018年2期)2018-04-11
火力与指挥控制(2015年7期)2015-06-23
