
基于补偿回滚的操作系统故障自恢复技术
2015-02-22 01:47朱怡安史佳龙
西北工业大学学报 2015年5期
关键词:操作系统
朱怡安, 史佳龙
(西北工业大学 计算机学院, 陕西 西安 710072)
基于补偿回滚的操作系统故障自恢复技术
朱怡安, 史佳龙
(西北工业大学 计算机学院, 陕西 西安710072)
摘要:操作系统故障根据传播特性可分为process-local和kernel-global 2类,分别造成进程局部数据和内核全局状态的错误。现有技术通过重启系统或故障进程实现对进程局部数据错误的恢复,但未考虑内核全局状态的不一致问题,不能保证对kernel-global类型故障的恢复效果。针对以上问题,提出了一种基于补偿回滚的故障自恢复技术。该技术通过监测内核全局方法调用,在进程局部数据被正确恢复的前提下,利用补偿操作对不一致的内核全局状态进行恢复,控制了故障的传播效应,减小了单点故障造成的影响。此外,该技术以内核模块的形式实现,不需要对目标操作系统进行修改,可便捷地实现功能扩展和移植。故障注入实验结果表明,在保证系统功能正常的前提下,该技术能对91.6%的故障进行有效恢复,且带来的系统负载较小。
关键词:操作系统;内核补偿;进程状态回滚;故障自恢复
操作系统作为重要的系统软件之一,负责管理软硬件资源,为系统软硬件交互提供接口,充当TCB(trusting computing base)的角色[1]。在软件系统的开发过程中,操作系统大都以COTS(commercial off-the-shelf)的形式提供[2]。由于操作系统与上层的应用软件和底层硬件均存在耦合交互,软硬件故障均会影响其运行状态,对其进行故障诊断、定位和恢复难度较大。故障自恢复技术可以使操作系统及时发现故障,并采取一定策略恢复系统正常执行状态。这对于减少系统失效时间和数据状态丢失,提高整体系统可靠性、减少故障损失具有重要作用[3]。
1相关研究
操作系统在出现严重内部错误时大都采取fail-stop行为模式,如Windows的蓝屏和Linux的kernel panic状态,因此故障的出现等价于系统失效。研究[4]将操作系统故障根据其传播范围分为process-local和kernel-global 2类。其中process-local类型故障的影响范围仅限于故障进程上下文,而kernel-global类型故障则会影响到其他进程的执行上下文和全局数据结构。由于kernel-global类型故障不仅会带来进程数据的丢失,还会引起系统其他模块甚至整体的失效,故其故障危害要大于process-local故障。如Linux 内核,其本身存在很多防范机制,包括对指针数据结构的检查,在发现数据不一致时终止故障进程的执行。该类机制虽然可以缩小错误传播的范围,控制故障的传播,但进程功能的失效也是不可接受的[5]。基于以上分析,故障恢复策略应该在完成进程执行状态恢复的同时,保证共享数据的一致性,消除故障传播的影响。
故障恢复技术的设计涉及2个问题:①如何清除系统的错误状态;②如何恢复系统失效前的执行状态。需要满足以下几点要求:①抢占性,可以在程序执行过程中的任意一点执行checkpoint操作;②透明性,对于已有的程序不需要对原有的代码进行修改就能支持备份重启机制;③低负载,不能造成显著的系统负载;④易于移植,不需要对操作系统代码或结构进行修改,能够较为便利地集成到现有操作系统中;⑤安全性,机制避免系统程序的优先级和权限被恶意提升[9]。针对操作系统故障,除重新启动外,其他方法都无法将系统从故障状态完全恢复。但对于安全关键应用,重新启动带来的损失是无法接受的。因此,在不对系统进行重启的前提下,设计有效的恢复策略是十分有意义的。
对于process-local类型故障,传播途径主要是错误调用参数和函数返回值,通过重启故障进程是一种有效的手段。kernel-global类型故障会造成内核共用数据错误,如导致内核中负责管理堆栈的红黑树数据结构污染,则需要对全局的数据操作进行跟踪记录相关信息来实现故障修复。当前操作系统通过冗余设计或重启的方法实现故障自恢复。此外,对故障系统、组件或操作进行重启是简单有效的局部数据错误恢复策略,如微重启[6-7]、transactional recovery[8]等,典型代表为Berkeley Lab开发的BLCR[8]系统,但未考虑kernel-global类型故障带来的全局数据状态错误。
针对以上问题,本文提出了一种基于补偿回滚的故障自恢复方法。该方法对内核全局数据或方法进行监测,在进程局部数据被正确恢复的前提下,通过控制故障的传播效应,保证了全局数据状态的一致性,兼顾了对2类故障的恢复效果。
2故障自恢复模型
process-local类型故障会造成当前进程执行状态的丢失,可通过周期性备份进程执行状态,定义为该进程的执行镜像,在出现故障时通过重新载入备份镜像的方法完成快速重启,降低失效时间。对于kernel-global类型的故障,利用备份的信息,重启某个进程在某些情形下无法达到故障恢复的目的。如图1所示,在连续2次进程状态备份操作之间,进程A在执行过程中需要获取自旋锁SPIN-LOCK-A,获取后在执行过程中出现故障导致程序崩溃,此时系统会使用进程A的状态备份信息执行恢复操作。但此时SPIN-LOCK-A仍然处于被占用状态,进程A在尝试获取SPIN-LOCK-A时会在内核态进入死循环状态,系统将再次载入进程镜像并重启进程A,但仍无法达到恢复的效果。因此对于该类型故障,在进程恢复时只考虑本进程相关的信息是不能够保证恢复效果的。
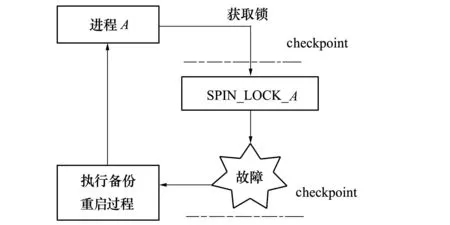
图1 kernel-global故障恢复失效实例
基于以上分析,在设计恢复机制时,必须考虑内核全局状态的一致性。内核调用会导致操作系统全局状态变化,该类型操作大都包含对应的逆操作,如加锁与释放锁操作、分配与释放内存操作,在程序代码中表现为成对出现的内核方法调用,本文中将其定义为关键方法和补偿方法。kernel-global类型故障会导致内核状态不一致问题,通过执行关键方法对应的补偿方法来消除不一致状态是简单可行的思路。本文设计了补偿栈结构,存储进程已执行的关键方法调用对应的补偿方法,用于故障恢复时消除内核的不一致状态。
2.1进程级checkpoint机制
进程备份机制对进程相关的文件句柄、内存信息、寄存器等信息进行保存,实现process-local类型故障的恢复,此外还需记录进程对全局数据的修改操作。

图2 进程级Checkpoint恢复机制
操作系统中,进程对内核全局数据的操作通过特定的系统调用实现,因此对全局数据修改的记录可转化为对系统调用序列的记录。如图2所示,在每个备份周期内,进程级checkpoint机制主要包括进程信息备份和内核调用追踪2个阶段。
进程信息备份阶段,图2中t0到t1时间段,将与该进程相关的全局寄存器、内存指针、进程局部寄存器等信息保存到非易失存储器中。在每个checkpoint周期结束时,需要更新进程备份镜像。
内核调用追踪阶段,图2中t1到t2时间段,内核动态追踪技术,将能够导致全局数据修改的操作及其参数等信息存储到内核补偿栈结构中,该结构常驻于系统内存中,实现快速地增加删除内核系统调用信息。
2.2内核补偿机制
对于kernel-global类型故障,需要记录该进程对内核全局数据的修改操作,在使用备份镜像恢复进程执行时,首先需要消除故障对内核全局数据状态的影响。内核补偿机制的工作流程分为如下几个阶段,内核调用监测阶段、补偿操作映射阶段、补偿栈数据维护阶段和故障补偿修复阶段,具体功能可描述如下:
1) 内核方法调用监测:应用基于动态追踪的故障监测方法,对内核执行流中关键方法调用进行监测,将采集到的信息传输至补偿操作映射阶段,当监测到补偿方法调用时则直接修改补偿栈数据。
2) 补偿操作映射:根据监测到的内核调用信息,映射出可以消除该调用导致的全局数据变化的补偿调用,并将该信息传输到栈数据维护阶段。
3) 栈数据维护阶段:对内核调用信息及其对应的补偿操作信息进行维护,为故障恢复阶段提供数据支持,若无故障,则执行完栈数据操作后返回内核执行流,若收到故障监测器故障报警,则进入故障补偿恢复阶段。
4) 故障补偿恢复阶段:通过补偿栈中的数据生成补偿操作序列,恢复内核全局数据一致性。
由于补偿栈为内核全局共享结构,执行时会触发大量的读写操作,故其提供的数据操作应具有较高的执行效率。
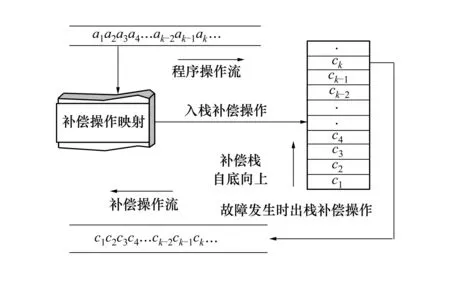
图3 内核补偿栈工作流程
图3中描述了内核补偿栈的工作流程,ci为ai对应的补偿操作,补偿操作映射模块可以根据ai映射出对应的ci。若某一执行的进程中包含a1、a2、a3、…、ak-1、ak关键方法调用,在该进程顺次执行该操作序列时,补偿映射模块根据补偿操作映射获得其补偿操作,同时将补偿操作信息加入补偿栈中保存。若在当前备份周期内操作流执行完后无故障正常退出,则在监测到补偿调用时,会依次出栈相应的补偿操作信息,补偿栈应为空。若执行过程中出现故障,则需依次出栈当前补偿栈中与该操作流相关的补偿操作,生成补偿操作序列并依次执行,完成对系统全局不一致状态的修复。
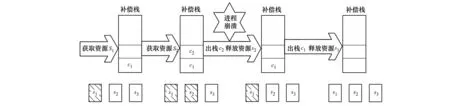
图4 补偿栈故障恢复示例
图4中给出了一个使用补偿栈进行故障恢复的示例。该示例中,进程执行过程中需要获取S1、S2、S33个共享资源,对应的关键方法和补偿方法分别为a1、a2、a3、c1、c2、c3。程序执行a1、a2操作获取S1、S2资源后,补偿栈中的数据为c2、c1,此时程序由于故障崩溃,由于没有释放S1、S2,导致共享资源处于不一致状态。当监测到该不一致状态后,补偿回滚机制会顺次出栈c2、c1,并执行相应的补偿操作,使共享资源状态恢复一致。
3故障自恢复技术实现
恢复技术基于BLCR工具集[10]和Kprobes机制[11]在Linux(内核版本3.5)操作系统中实现。BLCR在设计时没有考虑全局数据状态的恢复,如对系统IPC对象的占用,本文通过增加内核补偿机制,实现基于补偿回滚的故障自恢复技术。
3.1进程级Checkpoint实现
BLCR提供了cr-run、cr-checkpoint、cr-restart 3个调用接口,完成进程的启动、备份和重启操作,核心功能以内核模块的形式实现,在使用前需要加载到内核中。基于BLCR提供的基本操作和支持备份类型,利用进程树粒度的备份机制,进程级checkpoint机制以Python脚本的方式为用户提供接口。用户需指定进程pid和备份周期,对某个进程应用checkpoint机制。
进程级checkpoint机制执行流程是:在计时器累加后会判断当前是否处于新的checkpoint周期,若处于新的周期,则对原有的进程镜像进行更新。若处于旧的的周期,则会监测内核关键方法的调用,在内核补偿栈中记录关键方法、补偿方法调用信息。用户可以在不需要恢复模块时将其卸载。在每个checkpoint周期完成调用信息记录或进程镜像更新操作后,会检查该加载的自恢复模块是否有效,若无效则会退出整个checkpoint机制;否则执行计时器进行累加,进入后续信息记录更新过程。
3.2内核补偿实现
内核补偿机制可分为3层,分别为关键方法监测层、补偿栈操作层、栈数据层,以内核模块的形式实现。
关键方法监测层主要完成监测关键方法调用,获取调用参数和全局寄存器数据,其核心为关键方法到补偿方法的映射机制。该层基于Kprobes机制实现,可监测到对关键方法调用并获取相应调用参数。当监测到某一关键方法调用时,利用映射机制可获取其对应的补偿方法,构建结构体存储相关信息,并加入补偿栈。表1中描述了部分当前版本中内核关键方法的标识、关键方法以及补偿方法的对应关系,其中每个关键方法都对应唯一的标识,程序中用枚举变量表示。
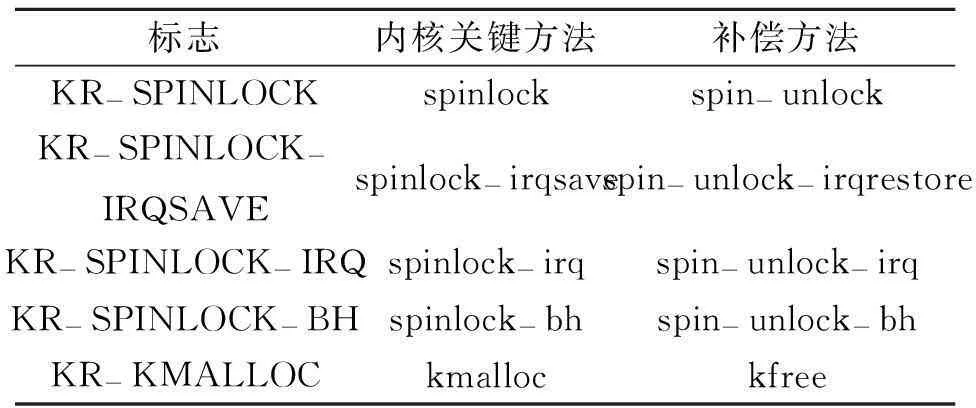
表1 内核补偿操作映射
通过在关键方法处设置监测断点,获取相应信息构建补偿方法记录结构体,利用调用栈操作层提供的接口,完成补偿方法数据信息入栈出栈的操作。根据关键方法监测层采集到的数据,补偿栈操作层提供对栈内数据进行操作的接口,包括在栈内加入、删除补偿操作信息以及出现故障时顺次出栈完成故障恢复的接口。例如,add-kr-object方法完成向栈内增加补偿信息的操作,其参数包括补偿方法信息数据结构体、补偿操作类型、当前寄存器内信息、调用该方法的进程结构体指针。
栈数据层存储补偿操作相关信息,提供入栈、出栈、栈数据查询等基本操作接口。由于程序以内核模块形式实现,对操作的效率有较高要求,故在实现栈是使用了Linux内核中内置的list-head类型来实现基本栈操作。数据以链表的形式进行存储,在数据结构体中加入list-head提供其存储顺序信息。入栈操作通过在头结点后插入节点实现,出栈操作通过反向遍历链表删除头结点实现。
补偿栈数据为全局数据,且对其访问操作较短,且不能被中断或抢占,故设置了自旋锁保证其数据一致性。每次进行栈数据操作时需要首先获取相应的自旋锁,操作补偿栈操作流程如图5所示。

图5 补偿栈操作流程
3.3故障自修复流程
通过动态追踪技术监测到故障后,会进入故障修复流程,包括内核补偿阶段和进程状态恢复阶段。
内核补偿阶段完成恢复内核一致性状态的功能,流程如图6所示。在对故障进程进行修复时,首先将检查内核补偿栈。若栈中信息不为空,说明当前进程在出错退出时对全局数据造成的影响未被消除,则从补偿栈中依次出栈补偿操作,根据其操作标识调用补偿方法,使内核状态恢复到一致状态。若补偿栈为空,则直接进入进程状态恢复阶段。

图6 补偿回滚机制故障自恢复流程
进程状态恢复阶段完成具体应用程序执行状态和数据的恢复。首先需要载入故障进程执行镜像文件,调用进程级checkpoint机制提供的重启接口,完成故障恢复恢复。
4验证分析
通过故障注入实验的方法对补偿回滚故障自恢复方法的有效性进行验证。实验计算机配置为AMD 速龙II双核 P360(2.3GHz 双核),2.0G内存,500G硬盘,内核版本为Linux 3.5。为了模拟系统真实的运行环境,在进行故障注入实验时选取了Unixbench 5.1.2[12]测评集模拟系统运行负载,选用了多个负载测试集以保证对内核关键方法调用的覆盖率。故障库以内核模块的形式实现,在实验中以一定的时间间隔动态注入负载流,同时记录监测到的故障数。表2中给出了实验中使用的负载集程序功能说明。
通过注入process-local和kernel-global 2类型的故障各50次到不同系统负载中,以验证补偿回滚机制的有效性。分别统计其在注入故障后的系统的3类反应出现的次数:分别为成功恢复、panic、System Hang,后两者本文认为其恢复失败。其中process-local类型的故障包括程序运行过程中出现异常导致其直接崩溃,实验中通过控制进程向其发送特定的异常信号实现。kernel-global类型的故障则通过内核模块的形式注入,故障类型主要包括资源竞争和内存泄露2类。实验结果如图7所示,可知补偿回滚机制能对91.6%的故障进行有效恢复,对于操作全局状体较多负载集如fstime,kernel-global类型故障恢复次数低于proces-local类型故障。部分故障未恢复的原因包括操作系统已有对某些故障的保护机制,补偿栈操作反而会造成系统不一致状态,大量进程并发执行时系统资源耗尽导致系统崩溃等。

表2 负载程序功能表
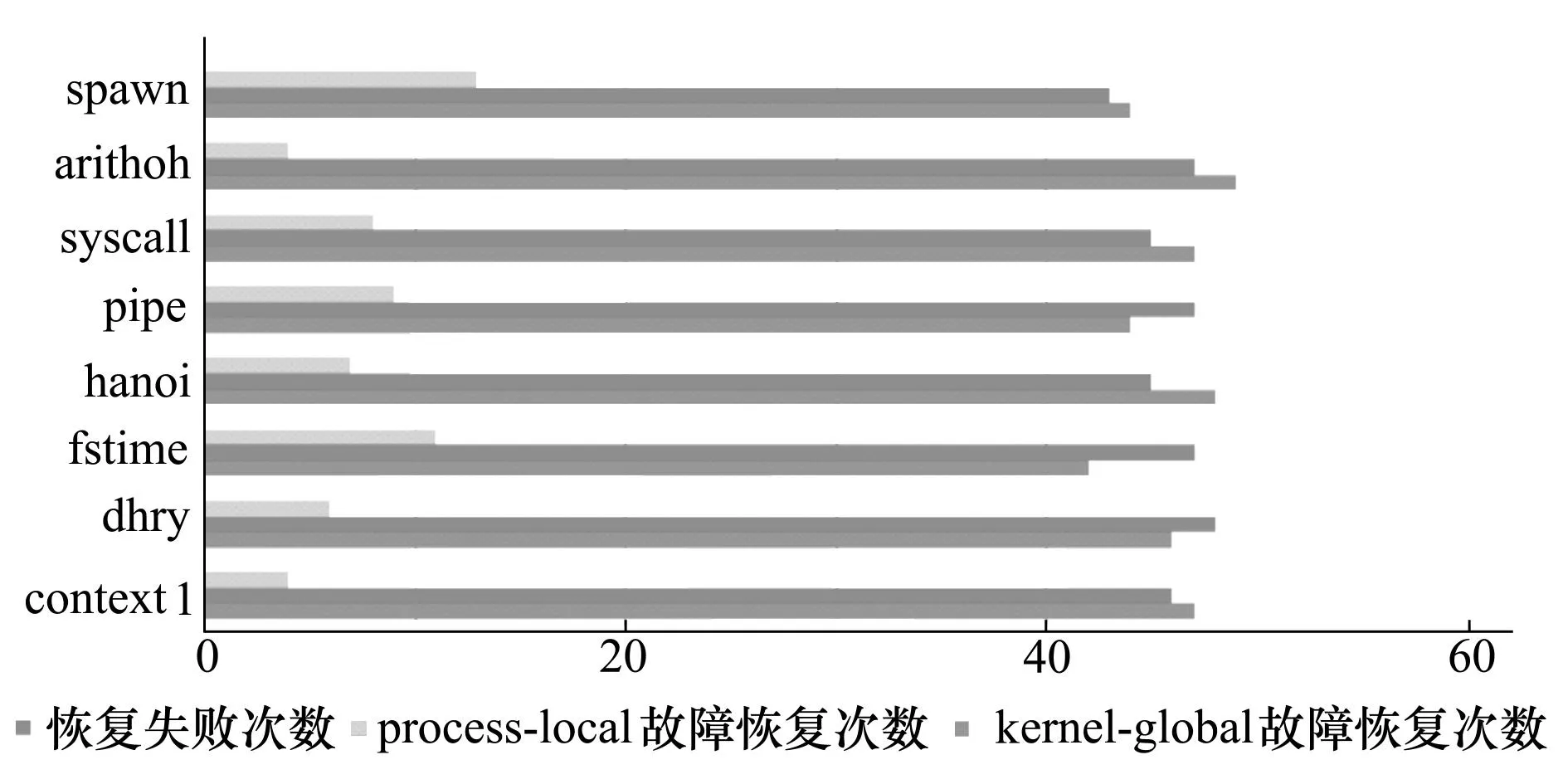
图7 故障恢复实验结果
实验中通过对备份重启不同的负载集程序来对补偿回滚机制的有效性进行评估,表3中为补偿回滚机制开销及性能测试结果。选取的指标包括备份文件的存储开销、checkpoint延时、重启延时以及其运行时所占内存大小。checkpoint延时为执行一次进程信息备份操作所需要的时间,在此期间相应的进程无法提供服务,该时间的长度同进程占用资源多少、程序镜像文件大小和执行操作的类型相关,可对机制造成的系统负载进行评估。重启延时为使用备份的进程镜像恢复程序执行状态需要的时间,可以对故障恢复的效率进行评估。

表3 补偿回滚机制开销及性能测试结果
如表3中数据所示,备份文件大小以及负载集类型会影响恢复机制的性能。较大的进程镜像和较多的内核全局信息会带来更多的备份开销和恢复延时,如context1负载集由于需要创建多个进程来完成上下文切换功能,其备份开销要高于其他负载。fstime负载由于涉及较多的文件拷贝操作,重启时需要恢复文件句柄等较多内核全局信息,其恢复延时要高于其余的负载集。
BLCR是checkpoint机制的典型代表,对其机制进行故障注入实验,比较其与补偿回滚机制的故障恢复效果,结果如图8所示。由于BLCR 工具库中没有对kernel-global类型故障设计相应的恢复机制,在该类型故障出现时只能依靠操作系统中原有机制进行处理,其故障恢复率低于本文中提出的补偿回滚机制。
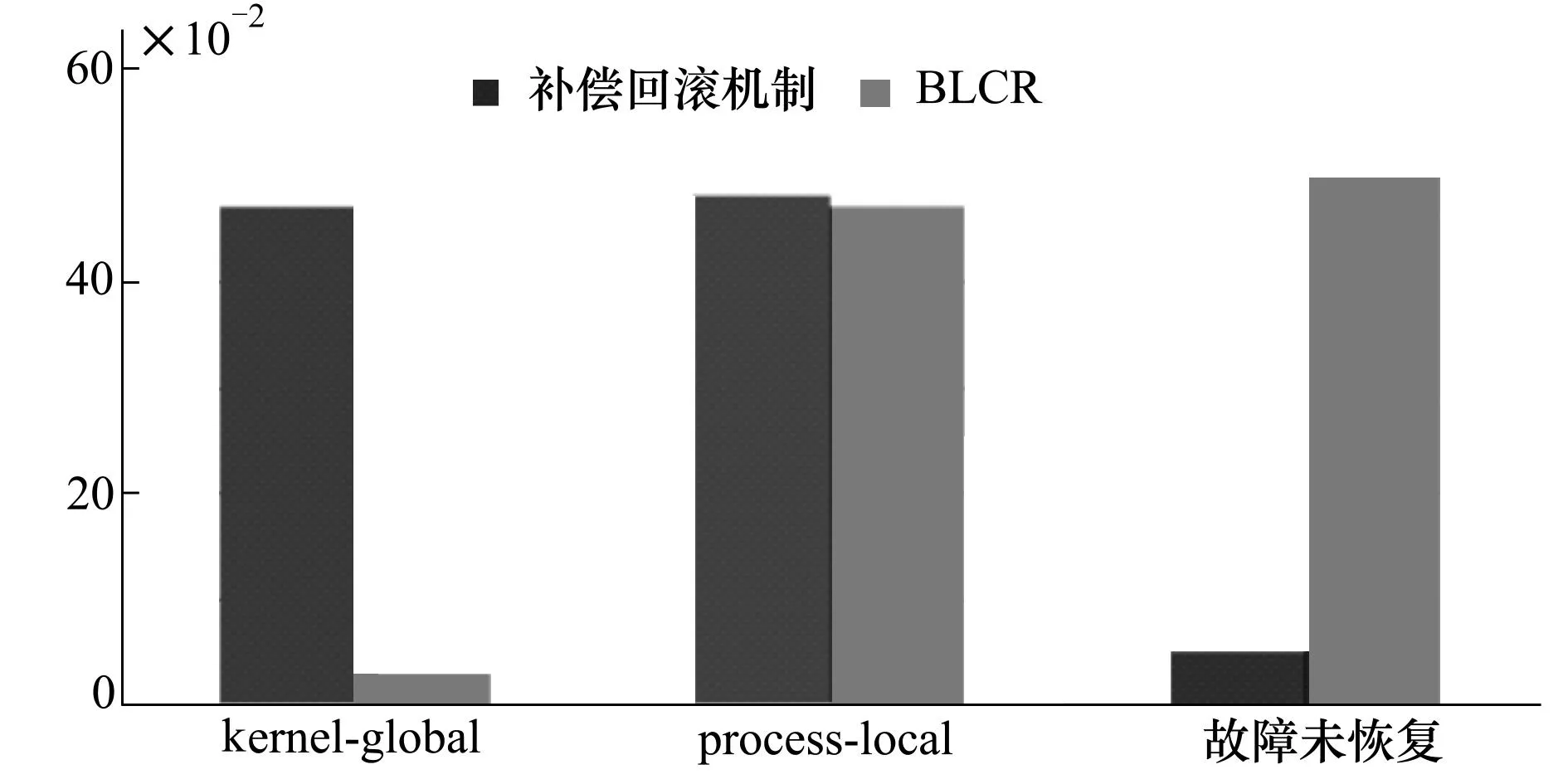
图8 故障恢复率对比实验结果
较传统的Checkpoint机制,补偿回滚机制增加了内核补偿阶段,会带来额外的系统负载。图9和图10中为BLCR机制与补偿回滚机制Checkpoint延时与故障恢复延时对比实验结果。从图中可知,增加内核补偿机制后,恢复延时和Checkpoint延时增长较少,证明了补偿栈结构设计的高效性。
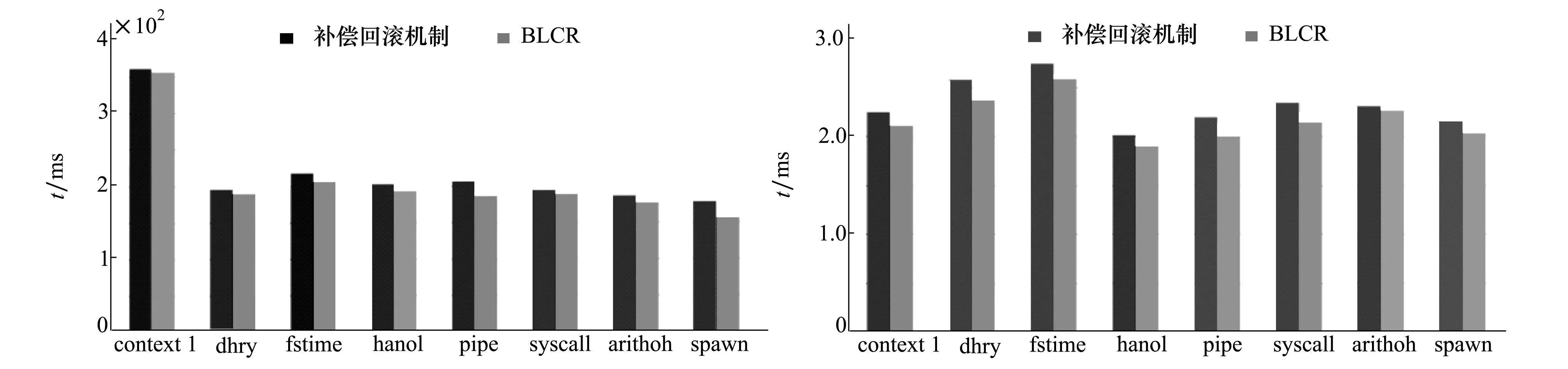
图9 checkpoint延时对比实验结果图图10 故障恢复延时对比实验结果
5结论
本文提出了一种基于补偿回滚操作的故障自恢复方法,该方法通过对内核全局数据或方法的监测,在保证进程局部数据被正确恢复的前提下,控制了故障的传播效应,保证了全局数据状态的一致性。故障注入实验结果表明,该技术能够有效地完成对故障的监测、恢复,且带来的系统负载较小。
参考文献:
[1]Deshpande B D. System and Methods for Self-Healing from Operating System Faults in Kernel/Supervisory Mode[P]US8930764 B2, 2014
[2]Hamann P S, Perry R L. Compensation Recommendations[P]US20140032382 A1, 2014
[3]Asghari S A, Kaynak O, Taheri H. An Investigation Into Soft Error Detection Efficiency at Operating System Level[J]. The Scientific World Journal, 2014(1): 1-9
[4]Yoshimura T, Yamada H, Kono K. Is Linux Kernel Oops Useful or Not?[C]//Proceedings of the Eighth USENIX Conference on Hot Topics in System Dependability, 2012: 2-7
[5]Frei R, McWilliam R, Derrick B, Purvis A, Tiwari A, Serugendo G D M. Self-Healing and Self-Repairing Technologies[J]. The International Journal of Advanced Manufacturing Technology, 2013, 69(5/6/7/8): 1033-1061
[6]Davis T A, Bishop A K, Cruzan C J. Detecting and Recovering from Process Failures[P]US8103905 B2, 2013
[7]Kato Y, Saito S, Mouri K, Matsuo H. Faster Recovery From Operating System Failure and File Cache Missing[C]//Proceedings of the International Multi Conference of Engineers and Computer Scientists, 2012
[8]Mousa N M. Avida Checkpoint/Restart Implementation[J]. McNair Scholars Research Journal, 2014, 10: 10-14
[9]Schneider C, Barker A, Dobson S. Autonomous Fault Detection in Self-Healing Systems: Comparing Hidden Markov Models and Artificial Neural Networks[C]//Proceedings of International Workshop on Adaptive Self-Tuning Computing Systems, ACM, New York, 2014: 24-33
[10] Hargrove P H, Duell J C. Berkeley Lab Checkpoint/Restart (blcr) for Linux Clusters[J]. Journal of Physics: Conference Series, IOP Publishing, 2006(46): 494-503
[11] Zhu Y, Li Y, Xue J, Tan T, Shi J, Shen Y, Ma C . What Is System Hang and How to Handle It[C]//2012 IEEE 23rd International Symposium on Software Reliability Engineering, 2012: 141-150
[12] Slaby J, Strejĉek J, Trtík M. Clabure DB: Classified Bug-Reports Database[C]//Verification, Model Checking, and Abstract Interpretation, Springer, 2013, 268-274
A New Operating System Fault Recovery Technique Based on Kernel
Compensation and Process State Roll-Back
Zhu Yian, Shi Jialong
(Department of Computer Science and Engineering, Northwestern Polytechnical University, Xi′an 710072, China)
Abstract:Sections 1 through 4 of the full paper explain and evaluate a new fault recovery technique based on kernel motion compensation and process state roll-back. The core of our thinking and that of sections 1 through 4 consists of: (1) past research papers on operating system fault recovery mainly focus on the data loss caused by process-local faults and the global state inconsistency caused by kernel-global faults is neglected; we propose a new fault recovery technique based on kernel motion compensation and process state roll-back model; it can minimize the propagation of faults and ensure the consistency of global state; this technique is implemented as loadable kernel module which makes it easy to expand functionality;(2) section 2 presents the design of kernel motion compensation and process state roll-back model; (3) section 3 presents the implementation details of this technique in Linux operating system; (4) evaluation results presented in section 4 and their analysis show preliminarily the effectiveness of the proposed technique.
Key words:adaptive algorithms, approximation algorithms, backstepping, conception design, cost functions, computer simulation, computer software, design, dynamic models, efficiency, embedded software, embedded systems, estimation, failure modes, fault detection, fault tolerance, global optimization, intelligent systems, mathematical models, models, motion compensation ,real time control, reliability analysis, safety engineering, software reliability; fault recovery,kernel compensation, operating system, process state roll-back
中图分类号:TP391
文献标志码:A
文章编号:1000-2758(2015)05-0709-07
作者简介:朱怡安(1961-),西北工业大学教授,主要从事高性能计算、云计算及普适计算的研究。
收稿日期:2015-03-12基金项目:航天支撑技术基金(2013-HT-XGD(10))、陕西省科学技术研究发展计划项目(2014K05-25)、陕西省科学技术研究发展计划项目(2015GY035)与航空科学基金(20130753006)资助。
猜你喜欢
卷宗(2016年10期)2017-01-21
无线互联科技(2016年13期)2017-01-10
电脑知识与技术(2016年18期)2016-11-02
电脑知识与技术(2016年22期)2016-10-31
课程教育研究·学法教法研究(2016年22期)2016-10-31
电脑知识与技术(2016年20期)2016-08-19
科教导刊·电子版(2016年18期)2016-07-18
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年3期)2016-04-07
电脑知识与技术(2016年1期)2016-03-22
