
基于条件随机场模型的数据异常检测算法*
2015-01-09 03:53:54王文珂文雅玫
计算机工程与科学 2015年9期
王文珂,文雅玫,蔡 喆
(1.国防科学技术大学计算机学院,湖南 长沙 410073;2.湖南省烟草专卖局(公司)经济信息中心,湖南 长沙 410004)
基于条件随机场模型的数据异常检测算法*
王文珂1,文雅玫2,蔡 喆2
(1.国防科学技术大学计算机学院,湖南 长沙 410073;2.湖南省烟草专卖局(公司)经济信息中心,湖南 长沙 410004)
企业数据中心作为辅助决策的重要工具,保证其数据的及时性、准确性和科学性是最基本的要求和最核心的原则。对于数据异常的情况,若仅依靠人为的经验在海量数据中进行判断是很困难的,也是不科学且低效的。针对企业购销存数据的准确性问题,研究了基于机器学习的数据异常检测算法。由于购销存数据是由一组相对固定的数据项组成,可以看作是一个结构化数据序列,因此选择了解决结构化序列预测问题最为有效的条件随机场模型CRFs。通过对大量历史数据进行学习,分析出数据的自身规律以及关联关系,使计算机具备自动检测异常的能力。实验结果表明了该算法的有效性。
数据中心;机器学习;数据异常检测;条件随机场模型
1 引言
湖南烟草商业企业的数据中心建设,从全局视角整合了企业经营和运行的数据资源,形成了包含卷烟营销、烟叶、专卖、财务、宏观经济数据和工业协同等综合性数据信息的企业级数据仓库,成为企业管理的标准数据源。在此基础上,通过数理分析,形成各层级人员需要的统计分析报表,为战略监控、业务运营和职能管理提供参考依据,初步实现了企业管理规范化,决策科学化[1]。
然而,由于数据中心本身不产生数据,其数据源来自于省公司自建的营销系统、行业统一建设的打扫码系统等多个一线业务系统,中间涉及全省14个地州市公司以及近百个县公司的数据统计环节,任何一个环节出现问题,都会使得最终汇集到数据中心的数据与实际销量产生偏差。对于这种与实际销售数据不符的、有偏差的数据,我们称之为异常数据。通常,有经验的企业领导和业务人员通过经验,可判断出报表数据存在偏差及异常,但这严重影响了工作效率,也降低了数据中心的权威性。为了提高数据质量,我们通过经验积累,尝试建立了一系列的数据检测规则,例如:库存数应是正数等。但是,无法枚举出所有规则,也无法科学地找出数据中存在的客观规律。寻求合适的异常数据检测方法、提升数据质量,是我们亟需解决的问题。
由于数据中心存在大量的历史数据,这些数据可用于对计算机进行训练,从而获取其内在规律。当出现异常时,经过训练的“智能化”计算机则可自动检测并发出异常警告。本文的主要工作是,以企业购销存相关数据为例,借鉴机器学习的方法,研究数据异常的自动检测方法。由于企业购销存数据之间存在一定的关联关系,属于结构化数据序列,充分考虑数据项之间的关系,而不是单独对每个数据项进行局部检测,能提高检测质量,获得全局最优结果。因此,其异常检测问题可看作是结构化数据序列的预测问题。本文选择了解决结构化序列预测问题最为有效方法之一的条件随机场CRFs(Conditional Random Fields)模型。条件随机场模型最早由Lafferty J等[2]提出,是一个广泛应用于结构化序列预测问题的概率模型。该模型不但可以自动综合多种数据特征,还可以有效利用数据之间的关联关系。相比独立预测的方式,该模型可以更好地获取全局最优解。
条件随机场模型是一个图结构模型,本文首先根据企业购销存数据的特性定义了一种图结构。然后,基于该无向图,详细介绍了如何利用条件随机场模型进行数据异常检测。
本文内容的组织如下:第2节简要介绍了条件随机场模型的相关概念;第3节详细描述了基于条件随机场模型的企业购销存数据异常检测算法;第4节给出了算法的实验结果;最后,第5节总结了本文工作并展望了下一步研究方向。
2 条件随机场模型
条件随机场模型对结构化数据预测问题提供了一套非常有效的表示方法和推理框架,且已经成功应用于计算机视觉[3]、自然语言处理[4]、互联网数据挖掘[5]和计算机辅助设计[6]等多个领域。
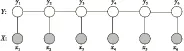
Figure 1 Structure of the linear conditional random fields model
图1给出了线性条件随机场模型的结构示意图。图V=X∪Y中包含有两种类型的节点:X是输入节点集合,表示可观测到的信息;Y是输出节点集合,表示需要被预测的标注信息。基于该图结构,条件随机场模型的定义如下[7]:

(1)
其中Z(x) 是一个正则化函数,使得所有的条件分布和为1,满足概率意义:
参数λk是特征函数fk的权值,需要通过训练数据集来估计该参数值。
在本文中,用y(或者yt、y′)表示某一观测节点对应的标注变量。例如,在图1 中有六个标注变量y1,y2,…,y6。Y则表示所有观测节点的标注集合。例如,在图1中,Y={y1,y2,…,y6}表示所有标注变量的集合。同理,X表示观测变量的集合,x表示某一观测变量。从公式(1)中可以看出,条件随机场模型是同时考虑所有标注变量来获得全局最优结果,而不是只考虑一个标注变量的局部最优结果,这也是条件随机场模型的优势之一。
3 基于条件随机场模型的企业购销存数据异常检测算法
应用条件随机场模型解决企业购销存数据异常检测问题,主要包括以下三个步骤:(1)由于条件随机场模型是一个图结构模型,因此需要将企业购销存数据的关系以图结构表示。(2)由于条件随机场模型是通过自动综合多种数据特征对异常情况进行预测,因此需要定义有效的特征函数。(3)需要定义如何评估参数值θ={λk}。并且,对于新的数据,如何预测标签Y。对于以上三个步骤,将分别在下面三个小节中进行详细说明。
3.1 图结构
这一步,将根据数据的关联关系,构造数据关系图。通常,经营简报中关于月度企业购销存数据的描述如下:
“某月份,全省系统购进卷烟a万箱,其中省产卷烟b万箱、省外卷烟c万箱;全省系统销售卷烟d万箱,同比增长e,其中省产卷烟f万箱、省外卷烟g万箱,省外烟销量累计占比h;某月末,全省系统卷烟库存为s万箱,存销比l。”
根据数据间的关联关系,可构造月度企业购销存数据关系图。
定义2月度企业购销存数据关系图MDG={L,E}是一个用于表示各数据项之间关联关系的无向图,其中L是节点集合,E表示边集合。集合L中的节点与数据项一一对应,集合E中的边则表示相连两数据项间的关系。
图2给出了根据上述描述构造的月度企业购销存数据关系图。
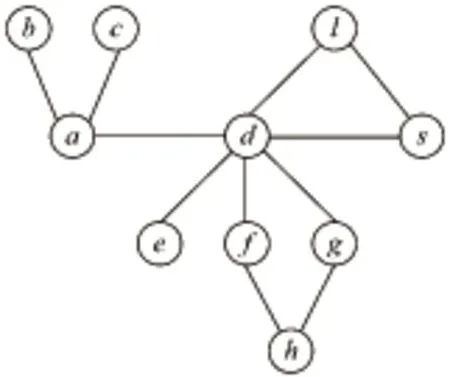
Figure 2 Constructed MDG
3.2 特征集
条件随机场模型的一大优势在于可以自动综合多种特征函数,从而挖掘出数据潜在的规律性。本节将详细介绍用于机器学习的特征集。
表1 列出了数据异常检测用到的特征集,其中定义了两类特征:一类是数据关系图中节点的属性特征;另一类是数据关系图中边上的关联特征。目前,定义了三种属性特征和四种关联特征。数据项的属性特征包括:数据项是否为正数、数据项是否为小数、数据项的位数。关联特征则描述了数据项之间的逻辑关系。
接着,需要为每个特征定义对应的特征函数。根据条件随机场模型的定义,公式(1)中的特征函数fk(y,y′,x)也包含两种类型:一类是状态特征函数sk(yi,x),用于表示标签yi与观察变量x之间的关系;另一类是传递特征函数tk(y,y′,x),用于表示相邻标签y和y′之间的关系。传递特征函数tk(y,y′,x)也可依赖于观察变量x。为了简化该模型,本文定义的传递特征函数与观察变量x无关。因此,可根据属性特征定义状态特征函数,根据关联特征定义传递特征函数。

Table 1 Features表1 特征集
注:n表示数据关系图中某数据项i对应的图节点。
对于表1 所列的特征,分别定义了相应的离散特征函数。例如,对应于属性特征PN(n)的状态特征函数定义为:
其中,y表示节点n的标签,x表示观察变量。
对应于属性特征FN(n)的状态特征函数定义为:
其中,y表示节点n的标签,x表示观察变量。
3.3 参数估计及预测
本小节将介绍如何估计参数值和预测新样本的最佳标注信息。这里主要包含两个任务:首先,对于预定义的特征函数,需要估计对应的参数值θ={λk},这样才能计算公式(1)中的条件概率p(y|x);其次,需要预测一个新样本X的最佳标签结果。如果一个样本包含n个节点,并且一共含有m种不同的标签类型,那么这个样本的标签结果Y有mn种可能。如果穷举所有的可能从而找到最佳结果,计算效率将会非常低。因此,需要利用一种有效的方法来找到最佳的预测结果。
利用条件随机场模型,主要包含以下两个步骤:训练(参数估计)和测试(预测)。在训练阶段,需要利用已有的标注数据来估计参数(特征函数的权值)θ={λk}∈Rk;在测试阶段,则利用学习的模型参数来预测新样本的标注结果。因为本文定义的数据关系图是一个树形图,因此需要一个树形结构的条件随机场模型,如图3所示。下面将主要介绍如何在树形条件随机场模型上进行参数估计和预测新样本的标注结果。

Figure 3 Structure of the tree conditional random fields model
(2)
这里的目标是解决如下优化问题:
argmaxθ=λkL(θ)
为了防止过拟合,在公式(2)中加入了正则因子,避免过大的参数估计值。加入正则因子后的条件似然函数定义为:
(3)
对公式(3)求参数的偏导数,可得:
其中,p(y,y′|x(i))是指给定x(i)的情况下,变量y和y′的边缘分布。
关于树形结构上的边缘分布计算问题,已有多种成熟的推理算法,本节则采用了精确推理算法Sum-Product[8]。Sum-Product算法利用消息传递技术来迭代处理相邻变量,是一种动态规划算法,可以有效地计算出上式中的边缘概率分布。
选择凸函数L(θ)作为目标函数,这样可以保证局部最优值的同时也是全局最优值。最优化函数问题可以采用迭代的方法求解,本节采用了L-BFGS方法[9]。该方法只需要利用目标函数的导数,并且已被证明是一种有效解决条件随机场模型的方法[10]。
在完成训练阶段估计完所有的参数值后,则可进入测试阶段预测新样本的标注信息。预测过程是希望能够为新样本找到最有可能的标注结果:
y*=argmaxp(y|x)
为了找到最优的y*,即需要找到使p(y|x)取值最大的y*。若通过枚举所有可能的标注结果来求得最优值是不现实的,因为这种暴力搜索的时间复杂度是O(mn),其中m是指标注类别的数目,n是指样本x包含的节点数目。因此,本文采用了一种有效的预测方法Max-Product[7]。Max-Product算法是上面所提Sum-Product算法的一种变形算法,它将Sum-Product中的求和运算(Sum)变为求最大值(Max)。同样,Max-Product算法也是一种有效的动态规划算法,它可将预测的时间复杂度从O(mn)降到O(m2)。
4 实验分析
为了验证本文算法对异常数据的检测效果,我们收集了2009年~2013年这五年的企业月度购销存数据。对于60组全部正确的数据,首先,手工将其中多组数据中的单个数据项进行修改。然后,随机选取了其中的40组作为训练集,剩下的20组则作为测试集。接着,手工为数据序列中的每个数据项标记正常/异常标签。在学习阶段,通过对训练集数据进行评估,获得了表示特征函数相对权重的最优参数θ={λk}。在测试阶段,首先隐藏测试集数据中手工标记的标签,然后采用本文基于条件随机场模型的算法对数据序列中每个数据项的标签进行预测。最后,通过比较手工标记的标签和机器预测的标签是否一致来检测该算法的有效性。
对于上述实验步骤,我们重复了五次,实验数据说明如表2所示。
由于本文算法是用于检测新增的月度数据是否正确,异常数据只是个别现象,所以实验中异常数据选择在1~5个。此外,异常数据是由于统计不全面造成的,因此异常数据浮动范围选择在2%~30%。实验结果表明,本文算法准确识别出了手工修改的实际工作中常见的异常数据。

Table 2 Experimental data表2 实验数据说明
5 结束语
本文针对数据中心里数据异常的问题,以成熟的机器学习方法为基础,研究了基于条件随机场模型的数据异常检测算法。
数据异常检测、数据预测等数据分析技术的研究在数据中心的优化完善中具有重要的应用价值,企业对于科学实用的数据分析技术也有着迫切的需求。然而,这方面的研究还不够深入和全面,数据里更深层次的信息还未被充分挖掘。下一步,可以从智能化的角度出发,综合考虑企业的实际需求,在充分挖掘数据信息、提高数据科学性及权威性等方面继续进行深入研究,以推动数据分析技术在数据中心的应用。
[1] Jiang Xiao-fang. Date center,a good helperofleaders[J].China Tobacco,2012(5):1.(in Chinese)
[2] Lafferty J, McCallum A, Pereira F. Conditional random fields: Probabilistic models for segmentingand labeling sequence data [C]∥Proc of the 18th International Conference on Machine Learning,2001:282-289.
[3] Quattoni A,Collins M,Darrell T. Conditional random fields for object recognition [C]∥Proc of Advances in Neural Information Processing Systems (NIPS-17),2005:1097-1104.
[4] McCallum A. Efficiently inducing features of conditional random fields [C]∥Proc of the 19th Conference on Uncertainty in Artificial Intelligence,2003:403-410.
[5] Culotta A,Bekkerman R,McCallum A. Extracting social networks and contact information from email and the web [C]∥Proc of the 1st Conference on Email and Anti-Spam (CEAS),2004:1.
[6] Wen Ya-mei. Studies on 3D solid reconstruction from 2D engineering drawings with sectional views [D]. Beijing: Tsinghua University, 2012. (in Chinese)
[7] Sutton C, McCallum A. An introduction to conditional random fields for relational learning [M]∥Introduction to Statistical Relational Learning.Massachusetts:MIT Press,2006.
[8] Kschischang F,Frey B,Loeliger H. Factor graphs and the sum-product algorithm [J]. IEEE Transactions on Information Theory,2001,47(2):498-519.
[9] Liu D,Nocedal J. On the limited memory BFGS method for large scale optimization [J]. Mathematical Programming,1989,45(1):503-528.
[10] Sha F,Pereira F. Shallow parsing with conditional random fields [C]∥Proc of Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume (HLT-NAACL),2003:213-220.
附中文参考文献:
[1] 蒋晓方.数据中心——决策的好帮手[J].中国烟草,2012(5):1.
[6] 文雅玫. 基于带剖视工程图的三维重建算法研究[D]. 北京:清华大学,2012.

王文珂(1981-),男,山东德州人,博士,副研究员,研究方向为虚拟现实与科学计算可视化。E-mail:wangwenke@nudt.edu.cn
WANG Wen-ke,born in 1981,PhD,associate research fellow,his research interests include virtual reality, and scientific visualization.
Abnormal data detection algorithm based on conditional random fields model
WANG Wen-ke1,WEN Ya-mei2,CAI Zhe2
(1.College of Computer,National University of Defense Technology,Changsha 410073;2.Information Center,Hunan Tobacco,Changsha 410004,China)
Data centers are an important auxiliary tool for business leaders to make decisions, and timely, accurate and scientific data are basic requirements and key principles. It is difficult and inefficient to find out abnormal one in huge amounts of data by human experience. In this paper, we propose an algorithm for detecting abnormal data based on machine learning. Because enterprise sales data consist of a series of relatively fixed data items, they can be recognized as a structured data sequence. Conditional Random Fields (CRFs) model is efficient for structured data sequence prediction, so it can be used as the detection model. A large number of history data are learnt and their intrinsic rules and relationship are analyzed so as to enable computers to detect abnormal data automatically. Experimental result shows the effectiveness of the proposed algorithm.
data center;machine learning;detection of abnormal data;conditional randomfieldsmodel
1007-130X(2015)09-1756-05
2014-07-08;
2014-10-21基金项目:国家自然科学基金资助项目(61202335)
TP274
A
10.3969/j.issn.1007-130X.2015.09.026
通信地址:410004 湖南省长沙市烟草专卖局(公司)经济信息中心 文雅玫
Address:Information Center,Hunan Tobacco,Changsha 410004,Hunan,P.R.China
猜你喜欢
环球时报(2023-02-28)2023-02-28 17:16:37
铁道通信信号(2020年3期)2020-09-21 09:13:04
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:48
黑龙江科学(2020年5期)2020-04-13 09:14:04
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
邢台学院学报(2018年4期)2018-12-14 11:11:56
新高考(英语进阶)(2017年11期)2018-01-22 03:02:42
数码设计(2017年14期)2017-11-15 06:01:52
