
基于Spark+MLlib分布式学习算法的研究
2015-01-03 02:21李彦广
商洛学院学报 2015年2期
李彦广
(商洛学院数学与计算机应用学院,陕西商洛726000)
基于Spark+MLlib分布式学习算法的研究
李彦广
(商洛学院数学与计算机应用学院,陕西商洛726000)
电子商务服务的关键是用户的需求,随着电子商务业务的急速扩展,用户数据量的海量增长,针对传统的单机算法很难满足业务需求的现状,提出了基于Spark+MLlib的分布式学习算法,系统在实现过程中进行了分类和预测,并实现了用户标签系统。通过测试,新的算法明显优于单机算法。
Spark;MLlib;标签系统;构建
对用户需求的了解是电子商务企业服务好用户的关键[1]。对用户进行画像是了解用户的属性和行为特征的最好途径[2]。一些商业行为的背后,需要对海量数据进行分析,归类用户的各种属性和行为特征,以便做分类和预测。机器学习是实现分类和预测的重要手段,然而,电子商务业蓬勃发展,数据量大规模增长,按文献[1]所提到的传统单机算法很难以满足需求,文献[2]所提到的梯度下降法非常费时。Spark的出现,便以多迭代、轻量级的框架设计,窄依赖流水化的计算模式摆脱了大量磁盘交换的桎梏[3]。MLlib是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器[4]。鉴于Spark及MLlib的特性,本文提出了基于Spark+MLlib的分布式机器学习算法,主要描述使用Spark+MLlib进行分类与预测的原理、实现方法。
1 Spark+MLlib平台
1.1 Spark
Spark是一个基于内存的分布式计算系统,是由UC Berkeley AMPLab实验室于2009年开发的开源数据分析集群计算框架,是BDAS (Berkeley Data Analytics Stack)中的核心项目,被设计用来完成交互式的数据分析任务[4]。Spark起源于Hadoop开源社区,基于HDFS构建系统,但相比Hadoop,它在性能上比Hadoop要高100倍,计算过程能兼容MapReduce,但并不局限于两个阶段式MapReduce范型[5]。
1.2 MLib
MLlib是建立在Apache Spark上的分布式机器学习库,在机器学习算法上比基于Mapreduce实现的分布式算法有100倍的性能提升[5]。MLlib支持分类、回归、聚类、协同过滤、降维等主要机器学习算法。底层数值优化算法主要包括SGD和L-BFGS(Limited-memory BFGS)。
MLlib的线性代数计算使用了Breeze包,这个包依赖于netlib-java和jblas,都需要Fortran运行环境。最近发布的Spark1.0中已经增加了对稀疏矩阵的支持,这给MLlib的使用者带来了很大便利[6]。
2 分类和回归的数学表示
定义1机器学习问题可以表示为min w∈Rdf(w),表示包含d维变量w的凸函数f的最小值,其中w就是机器学习中的权重矩阵。
定义2机器学习问题可以表示成数学上一个最优化问题目标函数,其中向量集合Xi∈Rd是训练样本,n表示训练样本的个数,yi∈R是样本所属类的标签。
在定义2中,目标函数f主要是由损失函数L(w;x,y)和正则化项R(w)组成,λ的作用是调节损失函数和模型复杂度的权重。
3 分类和回归问题的设计
3.1 MLlib的分类和回归
机器学习问题的结果有两种类型,结果连续的是回归问题,结果离散的是分类问题。
MLlib主要支持的分类算法有支持向量机(SVM,Linear support Vector mschine)、逻辑回归(LR,Logistic regression)、决策树(DT,Decision Tree)和朴素贝叶斯(NB,Naive Bayes)。
支持向量机SVM算法使用式(1)作为损失函数,使用式(2)为正则化项,基于式(1)中wTx的计算结果做分类预测。如果wTx≥0输出是正例,否则是负例。
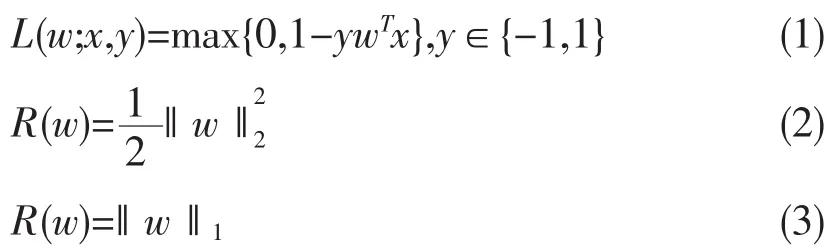
逻辑回归LR算法使用式(4)作为损失函数,使用式(5)进行预测。默认情况下,如果log it(wT)>0.5,结果是正例,否则是负例。在MLlib中实现这个算法的类是LogisticRegressionWithSGD。
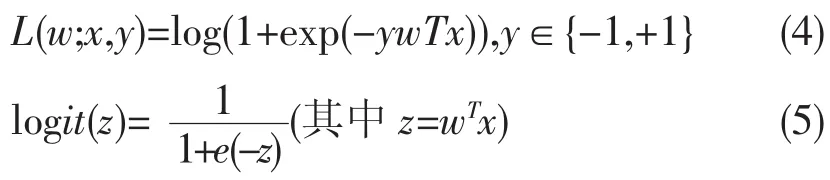
MLlib主要支持的回归算法有Linear least squares、Lasso和ridge regression,这一系列方法都是线性回归。Linear least squares的损失函数是squares loss,根据使用的正则化方法不同,又分为ordinary least squares和Linear least squares,Linear least squares不使用任何正则化;ridge regression使用式(2)正则化;Lasso regression使用式(3)正则化。Squared loss对于异常非常敏感,所以在实际应用时候、推荐使用带有正规化的回归。MLlib中实现这三种方法的类分别是LogisticRegressionWithSGD、RidgeRegression WithSGD和LassoWithSGD。
3.2 分类效果的评价
通过训练集把模型训练出来之后就需要放在测试机上评价这个分类模型的好坏[7]。在分类问题中常用的评价指标有Precision、recall、F-measure、ROC(Receiver Operating Characteristic)、Precision-recall曲线和AUC(area under the curves)。通常ROC是用来比较模型好坏的,而Precision、recall和F-measure等是用来决定Threshold的。这些评价指标在MLlib中都支持。
4 分类的算法描述
在机器学习中,很多问题都可以归结为参数优化问题,即找到使目标函数最大或者最小的参数[8]。在MLlib里求解minw∈Rdf(w)这样的最优化的问题主要的方法有SGD算法和L-BFGS算法。
4.1 SGD算法
在梯度下降最快的那个方向寻找函数极值,不断迭代就可以寻找到最大值或者最小值[9]。当目标函数不可微时使用次梯度寻找极值,这样的一阶优化方法也非常适合大规模分布式计算。梯度下降法在计算每个点的梯度或者次梯度过程中需要使用全部的训练数据,非常费时,所以在实际使用中更常见的是随机梯度下降法(SGD,Stochastic Gradient Descent),算法描述如下:
在i∈[1,…,n]选择一个随机样本点,得到目标函数f(w)的一个随机梯度,表示为f'w,I:=L'W,I+ λR'w,其中L'w,i∈Rd是第i个样本点决定的损失函数的梯度,表示为。其中R'w的梯度是正则化R(w)的结果,表示为,而且R'w和i没有相关性。f'w,I表示起始目标函数f的一个梯度,表示为。这样运行SGD算法可以用式(6)表示。

在式(6)中,γ表示第t轮迭代中步长值,与迭代次数成反比,其数值可以用式(7)计算得到。在式(7)中,t代表迭代的轮次,s代表初始步长。
SGD算法是MLlib中的一种通用优化方法,在各种线性模型的训练中被广泛运用。MLlib中通过Mini-Batch Gradient Descent算法实现随机梯度下降。在每一轮的迭代计算梯度时,通过MiniBatchFraction参数指定用于计算梯度或次梯度的样本比例,然后取平均值作为该点的随机梯度。如果MiniBatchFraction=1,那么这个实现就变成了标准的梯度下降;如果MiniBatchFraction非常小,在GradientDescent.runMiniBatchSGD方法,已通过类似LogisticRegressionWithSGD的形式和模型包装在一起了。
4.2 L-BFGS算法
L-BFGS算法是Quasi-Newton方法中的一种,其思路是用目标函数值和特征的变化量来近似Hessian矩阵[10]。L-BFGS算法的基本思想是只保存最近的m次迭代信息,从而大大降低数据存储空间。
L-BFGS在MLlib中目前还只是一种优化方法,还没有和模型包装在一起,如果使用这个优化方法需要用户显示调用LBFGS.runLBFGS方法。
5 标签系统的实现关键代码
按照分类问题的实现方法,给出了基于Spark0.9平台的关键代码。

在每一轮迭代过程中都会产生一个新的weights矩阵,然后下一轮迭代中会使用这个变量,但这个weights变量会比较大,在任务中一般有几十个MB到几百MB,对于相对比较大的变量建议使用广播变量,例如可以这样写:

由于模型大多比较复杂,百万级别的数据和百万级别的维度,产生的模型权重矩阵weights会非常大。这个权重矩阵weights在每次迭代计算之后都要更新,更新后会重新广播一份新的数据到所有worker节点。由于内存计算的速度非常快,权重矩阵weights生成的速度非常快,worker节点的内存很快就会填满。即使worker节点会将之前的数据dump到磁盘,但磁盘I/O的速度还是不如权重矩阵生成的速度快,这样的结果就是worker节点OOM。解决这个问题最简单的思路就是增加内存,但这个不是长久之计。令人欣喜的是在最新的Spark 1.0中看到了可以手动销毁过时的广播变量接口。
6 结语
针对目前电子商务的海量数据,单机算法很难满足用户的服务需求的缺点,本文深入分析了机器学习的分类和回归问题,给出了基于Spark+MLlib平台的机器学习数学模型,并在Spark0.9给出了核心代码的实现。但是分布式机器算法也受到环境的限制,主要存在两方面,其一是Spark的计算和存储都在内存中,而且是分布在不同的worker节点上,所以要保证机器内存足够大。其二是Spark虽然支持Python和Java语言,但在实际中还是使用了原生的Scala开发,而且解决的又是数学味道比较浓的机器学习问题,因此需要对模型的原理和实现有比较深入的了解才能得到正确的结果。总而言之,使用Spark+MLlib做机器学习是一项处于初级阶段,是未来发展的一个方向,随着机器软硬件的发展和模型的优化,目前的一些瓶颈问题会慢慢突破。
[1]严霄凤,张德馨.大数据研究[J].计算机技术与发展, 2013,23(4):168-172.
[2]Ghemawat S,Gobioff H,Leung S T.The Google file system[C].ACM SIGOPS Operating Systems Review, 2003,37(5):29-43.
[3]唐振坤.基于Spark的机器学习平台设计与实现[D].厦门:厦门大学,2014.
[4]淘宝技术部.Spark 0.9.1 MLLib机器学习库简介[EB/OL].http://www.tuicool.com/articles/aymuien,2014-05-10.
[5]吴韶鸿.大数据开源技术发展研究[J].现代电信科技, 2014(8):17-22.
[6]Xin R S,Rosen J,Zaharia M,et al.Shark:SQL and rich analytics at scale[C].Proceedings of the 2013 international conference on Management of data,2013:13-24.
[7]李彦广.基于HTTP平台的网络安全性研究[J].商洛学院学报,2013,27(4):59-62.
[8]Armbrust M,Fox A,Griffith R,et al.A view of cloud computing[J].Communications of the ACM,ACM, 2010,53(4):50-58.
[9]Weng J,Lim E P,Jiang J,et al.Twitterrank:finding topicsensitive influential twitterers[C].Proceedings of the Third ACM International Conference on Web Search and data mining,2010:261-270.
[10]李彦广.网络攻防仿真系统终端子系统的设计与实现[J].计算机与现代化,2014(3):169-172.
[11]李彦广.基于PHP的Flash与MySQL数据库通讯的实现[J].商洛学院学报,2013,27(6):53-56.
(责任编辑:李堆淑)
Research on Distribution Learning Algorithm Based on Spark+MLlib
LI Yan-guang
(College of Mathematics and Computer Application,Shangluo University,Shangluo726000,Shaanxi)
The key of E-commerce service is the users'demands.With the rapid expansion of E-commerce business,and the enormously increasing of the users'data amount,due to the fact that traditional single algorithm hardly meets the current business requirements,based on Spark+MLlib,the distributed learning algorithm is proposed,the system is able to carry on classification and prediction in the process of implementation,as well as the tag system.According to the testing,the new algorithm is obviously superior to single algorithm.
Spark;MLlib;tag system;construction
TP392
A
1674-0033(2015)02-0016-04
10.13440/j.slxy.1674-0033.2015.02.005
2015-01-16
商洛学院科研基金项目(09SKY007)
李彦广,男,陕西镇安人,硕士,讲师
猜你喜欢
数学物理学报(2021年6期)2021-12-21
今日农业(2020年13期)2020-12-15
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2019年1期)2019-01-31
数学年刊A辑(中文版)(2018年2期)2019-01-08
数学杂志(2018年5期)2018-09-19
高中生学习·高一版(2016年7期)2016-11-14
现代企业(2015年6期)2015-02-28
数学年刊A辑(中文版)(2014年5期)2014-11-01
河南科技(2014年3期)2014-02-27
