
基于FSVM脱机手写体汉字分类识别研究
2014-08-03 15:23朱程辉王建平
计算机工程与应用 2014年23期
朱程辉,甘 恒,王建平
合肥工业大学 电气与自动化工程学院,合肥 230009
基于FSVM脱机手写体汉字分类识别研究
朱程辉,甘 恒,王建平
合肥工业大学 电气与自动化工程学院,合肥 230009
1 引言
汉字具有汉字类别多、字体结构复杂、字型变化多、相似字多的特点[1]。脱机手写体汉字除此之外,还具有书写风格众多、书写不规范、随意性较大等特点。这些特点导致脱机手写体汉字成为目前文字识别领域最困难的问题之一。近些年已有一些新的方法理论运用到脱机手写体汉字识别领域,如神经网络、粗糙集等,与这些方法相比支持向量机有很好的泛化能力,同时避免了维数灾难[2]。
脱机手写体汉字识别首先要进行粗分类。目前采用支持向量机粗分类的方法主要有:按汉字字型结构特征和按汉字部首特征。按汉字字型结构特征进行粗分类存在某些字的字型结构不明确的问题[3]。按汉字部首特征粗分类,存在部首特征难以提取的问题[4]。和前两种特征相比,汉字像素密度特征易于提取并且分类明确。本文结合汉字整体的像素密度特征和小波分解横、竖、斜向笔划细节描述特征,利用模糊支持向量机(FSVM)进行粗分类。
一个待识别汉字像素密度若距离汉字样本像素密度期望值越远,则待识别汉字归属该样本的可能性越小。本文采用FSVM方法,根据不同输入样本对分类重要程度的不同,赋予不同隶属度[5]。减少噪声对传统支持向量机的影响,进而改善并提高识别精度。同时根据待识别汉字样本归属类别的可能性大小,建立按可能性大小排列的二叉树,以提高识别速度。
2 模糊支持向量机(FSVM)概述
设 模 糊 支 持 向 量 机 训 练 集 为 s={(x1,y1,μ1),…,(xj,yj,μj),…,(xl,yl,μl)},其中xj∈ Rn,yj∈{-1,1},μj∈[0,1]。μj表示样本xj对其所属类别 yj之间的权重,不同样本对超平面的训练有着不同的重要性,其值越大表明越重要。μj称为模糊成员(Fuzzy membership)[6]。
优化问题如下:

3 汉字的粗分类
3.1 像素密度的定义
汉字像素密度特征定义如下:设手写体汉字二值图像(包括小波分解图像)为 f(x,y),其中 x={1,2,…,N}; y={1,2,…,N};脱机手写体汉字像素点与图像总像素的比值,称之为脱机手写体汉字像素密度,如式(4):

本文定义:经细化后的汉字图像由式(4)计算得到的像素密度称为整体像素密度;小波分解后的横向子图由式(4)计算得到的像素密度称为横像素密度;同样方法定义竖、斜向像素密度。
3.2 汉字像素密度分布
本文根据汉字的像素密度对汉字进行粗分类。由于每个汉字笔画数目的不同,每个汉字的繁简度也就不尽相同。在汉字图像上即表现为汉字的像素密度的不同。通过对汉字细化、归一化后样本的仿真表明,汉字水平方向像素密度百分比分布在0.322到8.261的区间内,汉字水平像素密度的方差(δ)最大值为0.521。其中一个实际汉字“椽”其样本分布情况如图1(横坐标表示样本的像素百分比,纵坐标表示在该像素百分比下汉字样本出现的个数)。图中值为6.3竖线表示的是“椽”所有样本的像素百分比的一个期望值。可以看出汉字样本在其期望附近比较集中。经统计得到:脱机手写体汉字在3δ范围内集中了汉字样本的92.5%,在4δ范围内集中了97.5%,在5δ范围内集中了99.5%。
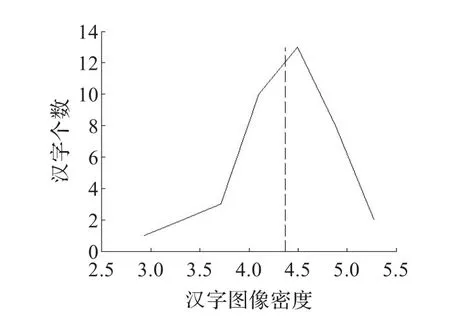
图1“椽”字样本分布图
3.3 汉字图像的二维小波分解
采用FSVM的方法进行粗分类,首先要对汉字样本进行预处理[7],包括二值化、归一化和细化。然后采用二维小波对图像进行分解。汉字图像的二维小波分解重构可以得到四个子图,分别是低频分量子图、水平分量子图、垂直分量子图和斜向分量子图。以“叶”的二维小波一级分解为例,如图2。

图2“叶”字小波分解及重构图
由图可以看出汉字图像的水平、垂直、斜向分量重构图在一定程度上刻画了汉字横笔划、竖笔划、斜向笔划的特征。同时也可以看出,与印刷体汉字相比,由于手写汉字的变形引入了干扰。如图1中“叶”字由于变形引入了斜向笔划的干扰信息。这也正是手写体汉字比印刷体汉字识别更加困难的原因之一。
3.4 动态剪枝模糊支持向量多级分类算法
3.4.1 模糊成员定义
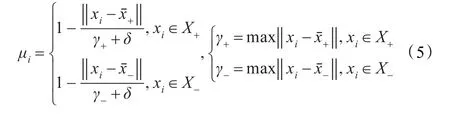
采用FSVM的关键是对模糊成员(有的文献中也称为隶属度函数)的定义,目前尚未有统一的方法[8]。常见的方法主要是基于距离定义模糊成员[9],即其中 X+表示 yi=+1(正类)的输入空间,X-表示 yi=-1(负类)的输入空间;xˉ+表示 X+的中心,xˉ-表示 X-的中心;γ+表示 X+的半径,γ-表示 X-的半径;δ表示一个无穷小量,为了防止分母为零的情况出现。

以第一级水平像素密度分类为例介绍FSVM手写体汉字分类算法(图3),如下:
步骤1计算待识别汉字的密度百分比ρi。
步骤2根据 ρi,由汉字样本分布图(如图1)找出所有与 ρi有交集的汉字(如图4)作为待识别空间样本S,其他没有交集的汉字剔除。将空间S依照像素密度百分比分为n类,记S的长度为L。取像素密度期望在内对应的汉字样本作为正类的训练样本(S+)。
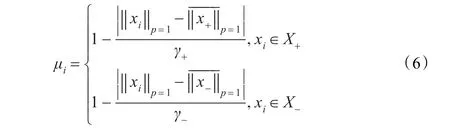
3.4.2 多级分类的算法
通过小波分解后得到三幅有效的汉字图像,即水平分量子图、垂直分量子图和斜向分量子图。采用FSVM进行如图3所示的多级分类。

图3 汉字粗分类示意图
子集(即粗分类类别)根据汉字像素密度进行划分,其中子集1、子集2、……、子集k-1、子集k根据集合密度区间与待识别汉字密度距离由近到远依次排列。也就是采用剪枝二叉树的方式[10],按可能性由大到小排列——子集像素密度与待识别汉字密度越接近,待识别汉字属于该子集的可能性越大,也就越靠近二叉树的根节点。通过这样的方式优化二叉树结构,加快识别速度。

图4 相交汉字示意图
步骤3S+的余集作为负类的训练样本(S-)。通过式(6)计算模糊成员 μj。通过式(2)求出 αj,代入式(3)即可求得最优超平面并判断待识别汉字是否属于S+。

完成第一级依照水平像素密度分类后,第二第三级(垂直像素密度和斜向像素密度)分类按同样方法进行。
3.5 粗分类仿真实验
首先对第20区94个汉字(每个字100个样本)进行二值化、细化、归一化、去孤立点和二维小波分解。然后计算每个汉字像素密度的期望和方差,水平分量子图的统计结果如图5和图6所示。其中横坐标表示对应汉字,纵坐标表示像素密度百分比。
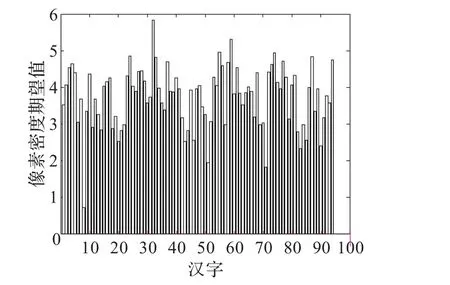
图5 像素密度期望
以“椽”字作为待识别汉字为例,进行第一级粗分类。首先计算待识别“椽”字样本像素密度百分比为5.468。椽字像素密度的期望值 E椽=4.431。如图4所示,求与其有交集的汉字(共60个)。

图6 像素密度方差
这60个汉字像素密度期望值的分布区间为[4.262,5.825]。其中像素密度期望最小值对应汉字是“窗”,值为 E窗=4.262,δ窗=0.427;最大值对应汉字是“蠢”,值为 E蠢=5.825,δ蠢=0.549。

取n=4根据步骤2,正类落在区间[4.34,6.59]内的汉字共16个。其余38个汉字所有样本作为负类的训练样本。按式(6)计算模糊成员,部分值如表1所示。

表1 部分样本模糊成员μ值
然后按照步骤3~步骤5,判别待识别汉字所属类别。其中核函数采用径向基(σ=3.6,C=2),特征向量为小波分解水平分量子图的水平、垂直方向投影直方图(维数为96维)。经FSVM判别,待识别汉字属于正类且与其实际所属类别一致。
实验选取第20区94个汉字,每个汉字的50个样本作为训练样本,另50个作为待识别样本进行粗分类。通过实验仿真得到分类数n与正确率关系如图7。

图7 粗分类正确率与分类数关系图
根据图7所示n与正确率的关系兼顾分类子集汉字数目的大小,选取分类数n=5。与选取同样参数的普通支持向量机作比较,FSVM粗分类正确率平均值为96.2%,粗分类结果所有子集中最大类别集合汉字为16个字。而普通支持向量机粗分类正确率平均值为93.1%,最大类别集合汉字为22个字。可见采用FSVM在同样的参数情况下精度更高,同时粗分类得到的集合更小。
4 脱机手写体汉字的识别
粗分类利用汉字的像素密度特征,根据小波分解后的汉字像素密度特征,将汉字粗分类为小集合。在此基础上进行细分类识别。为了提高识别的精度,本文采用“一对多”支持向量机算法[11]。
4.1 手写体汉字特征提取
脱机手写体汉字识别的特征主要有基于笔画密度、笔画轮廓特征、背景特征、方向线素特征以及端点奇点等点特征[12]。
(1)基于网格方向分解的方法[13]
该方法首先将汉字用网格进行划分,通常采用的是非均匀网格。划分的方法有多种,常见的是基于像素点的方法,其他还有基于笔画穿越数、笔画间隔和线密度的方法。划分网格后在网格内将笔画分解到横、竖、45°方向和135°方向模式。方向分解的方法主要有边缘方向分解法、骨架方向分解法、轮廓方向分解法等。产生网格数乘以四的特征向量。
(2)外围轮廓特征[14]
外围特征定义为从汉字图像边缘垂直于边缘方向接触到汉字黑像素点的距离。其中第一次接触到黑像素点的距离即称为一阶外围特征,第二次的称为二阶外围特征。采用固定扫描线的即称为均匀外围特征。非均匀扫描线的即称为非均匀外围特征。
(3)小波多网格特征[15]
该方法是首先对汉字图像进行小波变换,再对变换后的四幅子图建立网格。在网格内计算像素平均灰度值,从而构造特征向量的一种方法。特征向量维数等于网格数乘以四。
4.2 一对多支持向量机的算法
假设共有n个类别,算法如下:
步骤1选取第i类所有样本作为正类样本,其余所有样本为负类。
步骤2从i=1开始支持向量机训练,直到i=n,训练结束产生n个分类器。
步骤3将待识别样本用n个分类器进行分类。
步骤4计算待识别汉字分类间隔,分类间隔最大的一类即为待识别样本所属类别。
4.3 细识别实验仿真
在细分类识别中采用外围轮廓特征融合小波多网格特征的方法进行识别。外围轮廓特征采用16维的非均匀网格,从水平和垂直方向提取一阶、二阶到四阶的外围特征。构成16×4×2=128维的特征向量。
小波分解后采用固定网格的小波特征,这里为6×6的固定网格对汉字图像进行网格划分,然后计算每个网格中的灰度平均值作为小波网格特征。用MATLAB中dwt2()函数对汉字图像的255色灰度图像进行小波变换后,水平、垂直以及斜向分量子图仅存在±127.5,±255和0五个值。由于灰度值是由0到255表示,小波变换系数值的大小表示灰度,故对小波变换系数进行取绝对值处理后计算每个网格的平均灰度值,构成6×6×3=108维的特征向量,与外围轮廓特征组合构成236维的特征向量,通过一对多支持向量机的方法进行汉字细分类识别。细分类识别核函数采用径向基,用交叉参数法确认参数。表2为粗分类中分别采用FSVM和普通支持向量机进行汉字识别的识别率对比。

表2 识别率对照表
5 结束语
从仿真结果可以看出,粗分类采用FSVM的方法,最终汉字识别率要优于采用普通支持向量机的方法。本文中利用FSVM的方法进行粗分类是有效的。从数据结果可以看出对于简单汉字的识别率明显要优于笔画结构复杂的汉字。如“川”明显优于“矗”和“搐”。同时采用汉字像素密度特征进行粗分类,简单汉字的识别率及分类精细程度都要优于复杂汉字。
[1]赵继印,郑蕊蕊,吴宝春,等.脱机手写体汉字识别综述[J].电子学报,2010,38(2):406-415.
[2]高学,金连文,尹俊勋,等.一种基于支持向量机的手写汉字识别方法[J].电子学报,2002,30(5):651-654.
[3]朱程辉,项思俊.手写体汉字识别的二叉树SVM算法研究[J].计算机技术与发展,2009,19(9):42-45.
[4]马龙龙,刘成林.基于统计部首模型的联机手写汉字识别方法[J].智能系统学报,2010,5(5):385-391.
[5]Lin C F,Wang S D.Fuzzy support vector machines[J].IEEE Transactions on Neural Networks,2002,13(2):464-471.
[6]吴青,刘三阳,杜喆.基于边界向量提取的模糊支持向量机方法[J].模式识别与人工智能,2008,21(3):332-337.
[7]黄襄念,程萍,杨波,等.自然手写汉字预处理子系统[J].重庆大学学报,2000,23(4):33-37.
[8]张翔,肖小玲,徐光祐.模糊支持向量机中隶属度的确定与分析[J].中国图象图形学报,2006,11(8):1188-1192.
[9]Lin C F,Wang S D.Fuzzy support vector machines with automatic membership setting[J].Stud Fuzz,2005,177(1):233-254.
[10]Wang Anna,Hou Yuntao,Zhao Yue,et al.Research on fault diagnosis method of blast furnace based on clustering combine SVMS dynamic pruned binary tree[J]. IEEE,2010,8(10):67-70.
[11]郑勇涛,刘玉树.支持向量机解决多分类问题研究[J].计算机工程与应用,2005,41(23):190-192.
[12]高彦宇,杨扬.脱机手写体汉字识别研究综述[J].计算机工程与应用,2004,40(7):74-77.
[13]高学,金连文,尹俊勋.一种基于笔画密度的弹性网格特征提取方法[J].模式识别与人工智能,2002,15(3):351-354.
[14]张君祥,施鹏飞.基于网格外围特征的平假名识别及应用[J].实验室研究与探索,2009,28(12):27-30.
[15]陈力,丁晓青.基于小波特征的单字符汉字字体识别[J].电子学报,2004,32(2):177-180.
ZHU Chenghui,GAN Heng,WANG Jianping
School of Electrical Engineering and Automation,Hefei University of Technology,Hefei 230009,China
Considering the features of off-line handwritten Chinese characters,this paper presents a course classification method based on FSVM(Fuzzy Support Vector Machine).According to pixel density characteristics of wavelet decomposition, writer makes coarse classification on Chinese characters by using FSVM.On extracting peripheral features through fine classification and recognition,together with wavelet multi-grid characteristics,this paper relatively succeeds to do fine recognition by one-against-all method.The emulation test shows that the new method has a high recognition rate.
off-line handwritten Chinese characters;Fuzzy Support Vector Machine(FSVM);pixel density;wavelet
针对脱机手写体汉字特点,给出一种采用模糊支持向量机粗分类的方法。根据小波分解像素密度特征,利用模糊支持向量机对汉字进行粗分类。细分类识别提取外围特征,同时融合小波多网格特征,采用一对多算法进行细识别。仿真实验表明,该方法有较高识别率。
脱机手写体汉字;模糊支持向量机;像素密度;小波
A
TP391.43
10.3778/j.issn.1002-8331.1212-0250
ZHU Chenghui,GAN Heng,WANG Jianping.Classified identification of off-line handwritten Chinese characters recognition based on FSVM.Computer Engineering and Applications,2014,50(23):189-193.
国家实验教学示范中心项目(No.411101)。
朱程辉(1959—),男,副教授,硕士生导师,主要研究方向为图像处理、模式识别与神经网络;甘恒(1985—),男,硕士研究生,主要研究方向为图像处理与模式识别;王建平(1955—),男,教授,博士生导师,主要研究方向为智能测控技术、机器人视觉与图像识别系统等。E-mail:gdl_02@163.com
2012-12-21
2013-01-22
1002-8331(2014)23-0189-05
CNKI网络优先出版:2013-03-13,http://www.cnki.net/kcms/detail/11.2127.TP.20130313.0955.022.html
◎信号处理◎
猜你喜欢
星星·散文诗(2023年1期)2023-04-15
小哥白尼(军事科学)(2022年2期)2022-05-25
实用临床医药杂志(2021年7期)2021-05-18
科技风(2020年3期)2020-02-24
中国篆刻(2019年6期)2019-12-08
红领巾·萌芽(2019年8期)2019-08-27
中国现代医药杂志(2019年6期)2019-07-31
中国民间疗法(2019年24期)2019-02-12
中国与非洲(法文版)(2017年10期)2017-11-23
电脑知识与技术(2017年3期)2017-03-27
