
基于大数据下的手写体识别的设计与研发
2020-02-24 06:52文中芳孙新杰
科技风 2020年3期
关键词:识别
文中芳 孙新杰


摘 要:为了使人机交互更为自然、和谐,我们通过KNN算法对手写体识别进行了研究,手写体识别是为了使计算机对手写体进行图像预处理、基于数字图像的特征提取以及数字串的分割等步骤后,让计算机能够识别人类通过手动书写在输入设备上的字符轨迹并且装换为计算机所存储的编码,让计算机更加智能地辅助我们的生活、办公以及教学等各个方面。
关键词:KNN;手写体;识别
出生在20世纪90年代的我们,见证了我国科学技术、社会经济以及生态环境等领域的飞速发展。近几年,“大数据”、“物联网”以及“人工智能”等名词已然是家喻户晓,这是时代在进步的必然趋势,就如同十多年前“网上购物”是少数人知道且极少数人去尝试的一种购物方式,而现在几乎是人人都会“网上购物”,可称得上是“家喻户晓”。正是这些与计算机相关的科学技术地逐步普及与推广,使得人们的生活变得越来越智能化、高效化、便捷化。当人们在生活或工作中时,会时不时地进行各种各样的信息交流从而产生各式各样的数据,计算机则可以通过收集、分析这些数据后产生新的具有一定价值的数据。在这个数据以指数形式增长的时代,世界上中存在着大量的信息数据需要录入计算机中,或存储,或处理,收集到的全球海量数据经过分析、处理等步骤后就会产生其相应的价值(换句话说,万物都可以使用数据来描述,而数据就是一种实物或者虚拟世界的抽象描述)。目前人们对于海量数据的快速输入有着越来越迫切的需求,它已经成为制约信息处理系统性能的关键。因此,如何提高各种信息的输入速度?如何使得人机交互更加自然和智能?就要求计算机不断地对手写体识别技术加以研究,努力提高识别过程中的稳定性和准确性。
任何一项研究都有它存在的价值与意义,那么研究手写体识别的理论意义在于,手写体识别技术与人类的认知能力和语言能力有着密切联系,它要实现物与人的相连、物与物相连、人与人相连,在这个万物相连的时代,计算机的自我优化能力、机器的自我学习能力都在不断地发展中,使得相关学科有着进一步发展。而它的实用性价值在于,手写体识别技术不断地深入研究,该技术将一步步的满足人们对人机交互的需求,满足人们无纸化的需求,减少资源的浪费,于人们的生活中给人们带来便捷,使得一些产业实现无纸化的链接,减轻地球的负担,使得计算机在生活中、学习中、工业中不断地发展与壮大,并且它对扩大计算机在社会中各行业的应用具有重大的实际意义。
近年来,海内外历经多年对手写体识别技术的研究,人们取得了良好的应用性成果。手写体识别存在着最大的问题便是人们所书写的字体存在着很大的差异性,计算机无法做到像人类一样通过“眼睛”来认识这些有差异的手写体(人工智能也正在致力于使计算机能够像人类一样通过“看”、“听”、“说”、“触”来实现人机交互)。本文基于机器学习的特点在大数据环境下对手写体进行准确的识别,致力于把大数据、人工智能等技术运用到手写体识别的领域对手写体进行预处理以及特征提取,最终实现提高计算机对手写体的识别精度与准确率的目标。本文采用KNN-近邻算法设计了手写体识别系统。该系统主要包括机器学习与识别两个模块,利用Python语言编写相关代码,且利用Python自带的环境Anaconda与Windows10下的SQL server 2012(存储数据)来实现该系统的运行。
1 系统主要概念
1.1 KNN-近邻算法
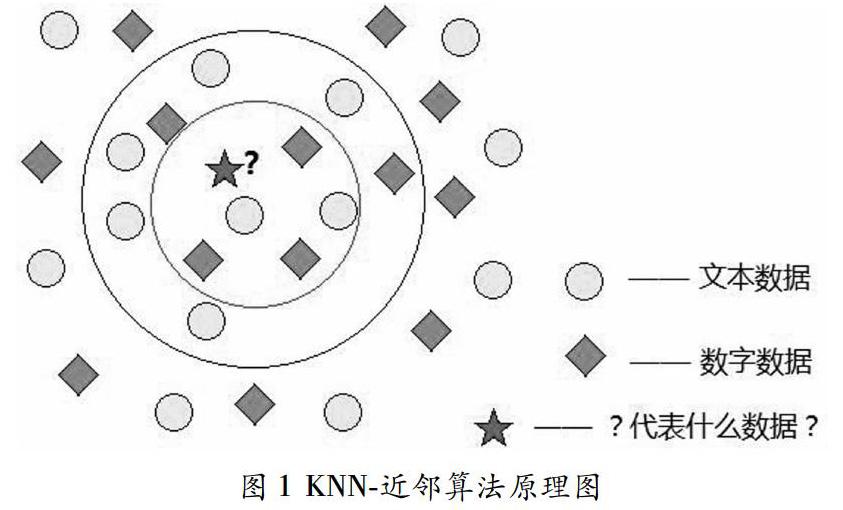
KNN-近邻算法是一种能够实现分类和回归的算法之一,而该手写体识别系统则是通过KNN-近邻分类法来实现对数据进行分类的功能,也就是给出一个已有的训练数据集,而现在有一个新的数据,计算机并不知道它属于那一种数据,通过在已有的训练集中找出与该数据最近的K种数据,在这K种数据中,那一种数据多则这个新的数据属于数据较多的那一种数据即少数服从多数。根据这个原理,作出下图示例:
如上图所示,有两类已知的不同样本数据,分别用绿色的小菱形和黄色的小圆形表示,而图正中间的那个红色的五角星所标示的数据则是新的未知的数据。而现在要做的便是将这种新的未分类的数据点通过K值来确定它属于现有的已分类哪一种数据,接下来我们将根据KNN-近邻的思想来对绿色圆点进行归类,确定它是属于那一类别的数据。当K=5时,距离红色五角星最近的5个点分别是3个绿色的小菱形这一类和2个黄色的小圆形这一类,基于KNN算法,最终判定红色的这个未分类数据属于绿色的小菱形这一类。
当K=12时,绿色圆点的最邻近的12个数据点是7个黄色小圆形和5个绿色的小菱形,基于KNN算法,判定红色的这个未分类点属于黄色小圆形这一类。
通过上面的例子,我们知道如何给新的数据点来进行归类,即在一定的条件下也就是K的取值,再利用“少数服从多数”的原理,便可以对新的未分类的数据点进行归类。
1.2 欧几里得距离
欧几里得距离即是用来测量在平面上两点之间的距离即当平面上存在两点a与b时,若a(x1,y1) b(x2,y2),则欧几里得距离d=((x1-x2)^2)*((y1-y2)^2)。
1.3 二值化(即矩阵化)
图像二值化就是通过使用0、1来表示图片上的各个像素点后,再将这些由0、1数值构成的“图片”按照原本像素点的顺序安放到一个二维数组中,最后要达到让整个图像呈现出只有黑与白的视觉效果。
1.4 需要训练集
在手写体识别系统中,我们需要不断的训练产生一个训练集使得机器识别手写体。如同我们学习知识一样,一开始我们是通过不断地去看、写、读、说来掌握新知识。对于人来说,这是比较容易的,但是对于计算机来说它只能通过不断地计算、存储与之相关的数据,来掌握大量的数据。它是无法做到像人类那样自动地去认知。在系统中需要錄入大量的与之相关数据,不断地训练,产生一个训练集使得机器快速的计算并且得出结果。在后面,若是条件允许我们可以将所有常见的汉字、数字、符号、字符甚至是那些少数名族特有的语言文字录入一个数据库中,这样识别的效果会更好。
1.5 通过KNN算法建立机器识别
如何使用kNN近邻算法对人类书写的数据进行分类,目前我们构造的手写体识别系统还只能够识别0至9的纯数字,手写的数字经过一系列处理后,使其具有相同的大小、色彩,且高与宽为10×10像素,它的效果图如下:
这是一个10×10的矩阵图,它的显示出的结果则是1。
1.6 系统框架
手写体识别的过程如下图2所示,通常可以分为预处理、特征提取以及数字串分割等模块。预处理于手写体识别系统中的之主要功能,是对原始图像进行去噪或灰度等特定处理。现今,我们常常采用光电扫描仪来对原始图像进行扫描,以此获原始图像之二维图像信号。因为人们的书写方式和书写习惯的不同,所以不同的人书写的字体都存在着差异性。这些差距主要体现在手写体的字体大小、字体间距又或者是字体内距,若要对其进行分割有着较大的难度。由此可见,手写数字串的分割是其中最重要的环节,是提高机器对手写体识别率的关键。同样地,对原始图像的去噪处理也是预处理中亟为重要重要的环节之一,系统不但需要从人类书写的字体中精确地切分字符图像,而且需要滤除掉有粘连的边框又或者是由于在切分时的不正确而引入的其他字符笔划和随机出现的墨点等使前景点增加的噪声。特征则是可以分为结构特征以及统计特征两大类,提取的特征决定了分类器的选择,与之对应的识别方法便有结构方法和统计方法。
总而言之,通过手写体数字识别原理可知,手写体识别技术主要有以下几种:
(1)图像预处理;
(2)基于数字图像的特征选择和提取;
(3)数字串的分割。
2 系统实现
3 算法测试
当用鼠标在相应区域写下数字9的时候,左侧区域出现相应的数字,实现了手写体识别:
4 结语
文中介绍了基于KNN-近邻算法实现的手写体识别系统。该系统主要通过对手写体0至9中的数字進行图像预处理、基于数字图像的特征提取以及数字串的分割等一系列的处理后,使计算机能够对人类手写的数字进行学习和识别,当我们在系统中对0至9的数字进行一定量的训练后,该系统则可以较为准确的识别出手写输入的数字,由于人与人之间的手写体存在着巨大差异,这就要求我们必须在系统中对机器进行大量的训练,来提高计算机对手写体识别的准确率。目前,我们只实现了对0至9的纯数字的识别,待日后进一步学习后,希望能够实现对所有手写体的识别,而不仅限于纯数字。
猜你喜欢
物联网技术(2016年11期)2017-01-12
吉林农业(2016年12期)2017-01-06
合作经济与科技(2017年1期)2017-01-03
求知导刊(2016年30期)2016-12-03
东方法学(2016年6期)2016-11-28
商(2016年35期)2016-11-24
企业导报(2016年10期)2016-06-04
