
改进型特征权重自调节K-均值聚类算法
2014-07-18 11:53:41支晓斌许朝晖
西安邮电大学学报 2014年6期
支晓斌, 许朝晖
(1. 西安邮电大学 理学院, 陕西 西安 710121;2. 西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
改进型特征权重自调节K-均值聚类算法
支晓斌1, 许朝晖2
(1. 西安邮电大学 理学院, 陕西 西安 710121;2. 西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
针对特征权重自调节K-均值聚类(FWSA-KM)算法对噪声敏感的问题,提出一种改进型特征权重自调节K-均值聚类(IFWSA-KM)算法。用一种非欧氏距离代替FWSA-KM算法中的欧氏距离,以增加聚类算法的抗噪声性能。通过用人工数据和真实数据的对比性实验,可验证IFWSA-KM算法的有效性。
聚类算法;特征权重;鲁棒性;非欧氏距离
聚类分析是指用数学的方法研究和处理给定对象的分类问题,它是多元统计分析的方法之一,也是在无监督模式识别中的一个重要分支[1]。在众多的聚类算法中,由MacQeen提出K-均值聚类(K-means, KM)算法具有其简单、快速的优点,因此被广泛应用于科学研究和工业应用中,成为一种流行的聚类算法。尽管KM算法得到了广泛的应用,但KM算法却存在很多缺点,如过分依赖于初始中心点的选取,容易受到数据中噪声的影响,不能自动选取特征等。为了提高聚类算法的抗噪声性能,很多学者都提出了改进的聚类算法。基于鲁棒性统计理论,文[2]通过修改KM和FKM的度量,提出了改进型K-均值聚类(AlternativeK-means, AKM)算法和改进型模糊K-均值聚类(Alternative FuzzyK-means, AFKM)算法,AKM与AFKM算法在一定程度上都提高了原算法的抗噪声性。
传统KM聚类算法对数据的各个特征平等对待,不能自动选择相关特征。为了使得KM能够自动选择数据的特征,众多学者提出了基于特征加权的KM聚类算法。文[3]首先提出了特征加权K-均值聚类算法。文[4-5]提出了新的特征加权K-均值聚类算法,在该算法中,特征权重的优化被集成到KM迭代算法中,模糊K-均值聚类算法中隶属函数的求解方法被巧妙地用来计算特征权重,并且新算法没有牺牲原KM算法的高效性。
文[6]提出一种特征权重计算的自调节机制,并将其嵌入到KM聚类算法中,提出特征权重自调节K-均值聚类(K-means with feature weight self-adjustment mechanism,FWSA-KM)算法,该算法不但使用的参数较少而且还能不牺牲原KM聚类算法的效率,但有一个问题,使用欧氏距离,当数据结构复杂或者带有噪声时,FWSA-KM算法的聚类效果并不理想。
鉴于上述问题,同时受到AKM算法的启发,为了进一步提升FWSA-KM算法的性能,本文提出一种改进型特征权重自调节K-均值聚类(K-means with an improved feature weight self-adjustment mechanism,IFWSA-KM)算法。由于非欧氏距离的使用,IFWSA-KM算法在迭代计算过程中能够自适应地给数据生成一个权函数,这使得对聚类中心的估计更加稳健,从而提高算法的聚类精度。
1 FWSA-KM算法
设数据集X由n个数据点构成,即
X={x1,x2,…,xn}。
经典KM聚类算法的目标函数为
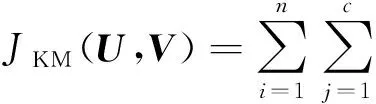
(1)
其中U=(uij)n×c是隶属度矩阵。如果第i个数据点xi属于第j个类,则uij=1,否则uij=0,并且

而V=[v1,v2,…,vc]是c个聚类中心构成的矩阵。KM聚类算法通过交替迭代优化隶属度矩阵U和聚类中心矩阵V求解。
为了使得KM聚类算法能够自动对数据进行特征选择,众多学者提出了基于特征加权的KM聚类算法[3-8],其中FWSA-KM聚类算法的目标函数为
minJFWSA-KM(U,V,W)=
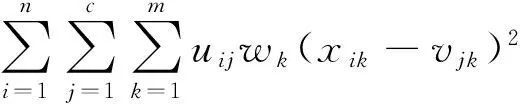
(2)
满足
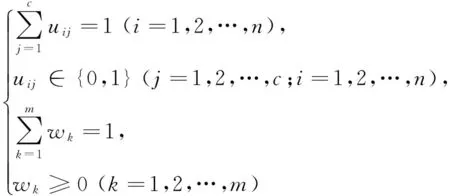
(3)
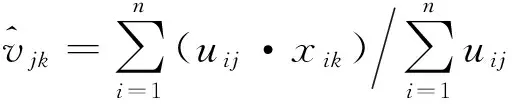
(4)
为了求解特征权重矩阵,文[6]重新定义了另一个目标函数

(5)
满足


FWSA-KM算法在计算特征权重时,考虑了类间分离度信息。
若设
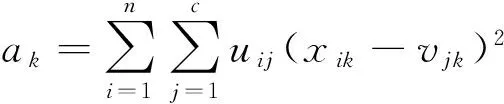

则式(5)可以重写为
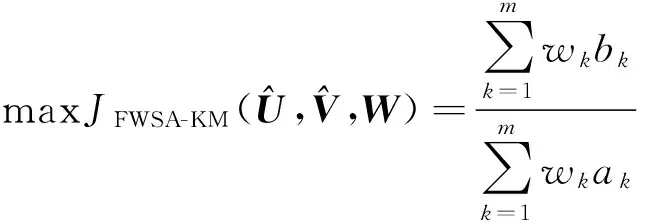
(6)
其中ak是聚类在第k维特征上总的类内紧致性度量,bk是聚类在第k维特征上总的类间分离性度量。文献[6]采用一种特征权重自调节方法来求解上述的优化问题。
设FWSA-KM聚类算法中第t步迭代的特征权重为集合
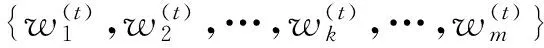
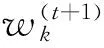
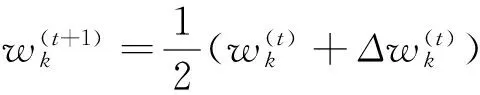
(7)
其中
(8)
为第t步迭代的特征权重调节差量。
与其他已有的特征加权KM聚类算法相比,FWSA-KM算法的优点是:(1) 特征权重的计算考虑了分离性度量;(2) 算法中的参数较少;(3) 不牺牲原KM聚类算法的效率。
2 IFWSA-KM算法
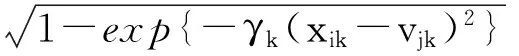
JIFWSA-KM(U,V,W)=
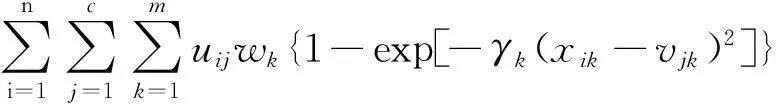
(9)
满足
通过迭代求解三个最小化问题,即可最小化式(9)。
问题1 固定

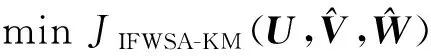
问题2 固定

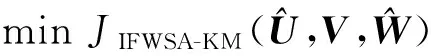
问题3 固定
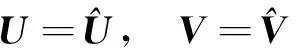
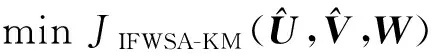
针对问题1,如果
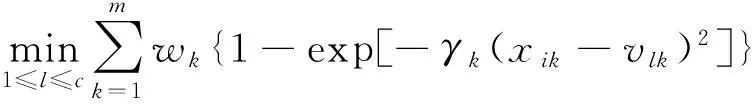
(10)
则uij=1,否则uij=0。
问题2的解

(11)
这是关于vjk的一个非线性方程,可以用不动点迭代法进行求解。
为了求解问题3,令

(12)

(13)
其中
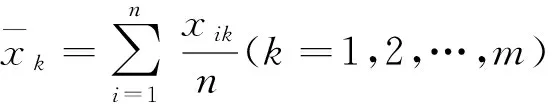
则ak度量了聚类在第k维特征上总的类内紧致性,bk度量了聚类在第k维特征上总的类间分离性度量。
为了求解特征权重矩阵,定义新的目标函数

(14)
满足
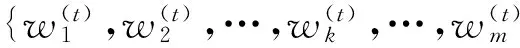
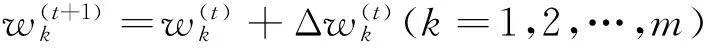
(15)
其中特征权重调节差量
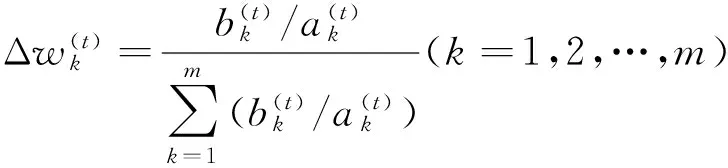
(16)
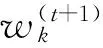
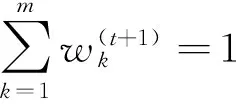
对式(15)进行规范化处理,得到特征权重
(k=1,2,…,m)。
(17)
综上所述,可以给出详细的IFWSA-KM聚类算法步骤。
步骤1 初始化聚类中心矩阵
V(0)={V1,V2,…,Vc},
初始的特征权重矩阵W满足

步骤2 计算隶属度矩阵U。
步骤3 计算新的聚类中心矩阵V。
步骤4 由式(17)计算特征权重矩阵W。
步骤5 如果
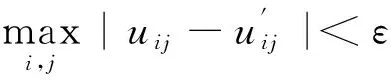
则停止;否则,转到步骤2。
3 实验结果及其分析
将IFWSA-KM算法与KM算法、AKM算法和FWSA-KM算法,分别对8个真实数据进行对比性实验,以验证其有效性。
3.1 实验设置
从UCI数据库中选取低维的数据集Iris,Wine,Letter_abc,User,Satimage,Breastcancer和Dermatology,另外选择1个高维数据集Leukemia进行聚类实验[8-9],相关数据特性如表1所示。
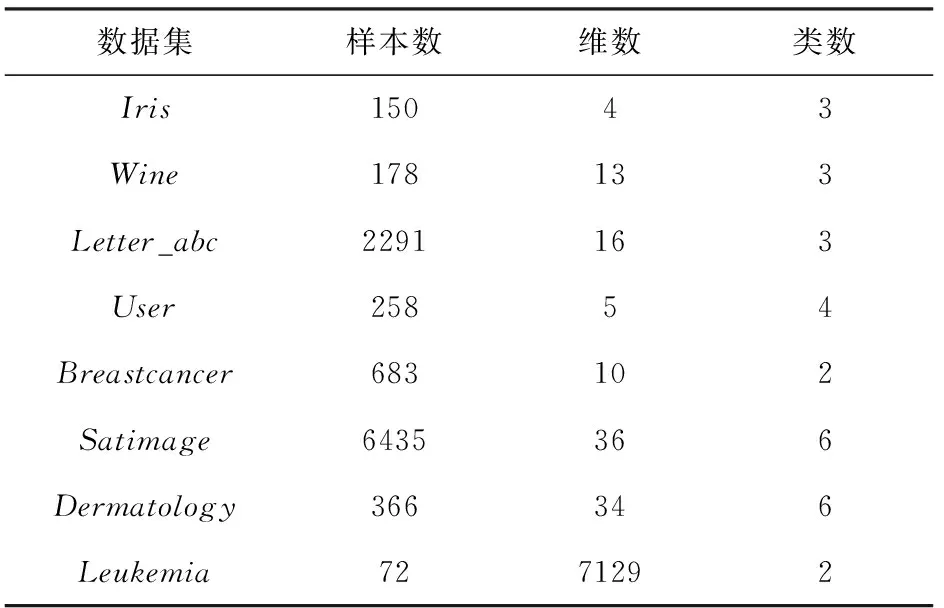
表1 数据描述
在实验中,用准确度和运算时间来衡量聚类的性能。准确度定义为

(18)
其中nj是数据正确分到第j类的数目。
实验中,4种算法各运行20次,选取20次运算的最优值和平均值作为最终的聚类结果。最大迭代次数设为100,停止阈值设为10-5。
3.2 算法的聚类精度测试
表2给出了4种聚类算法分别对8个数据集进行20次运算的最优聚类结果。
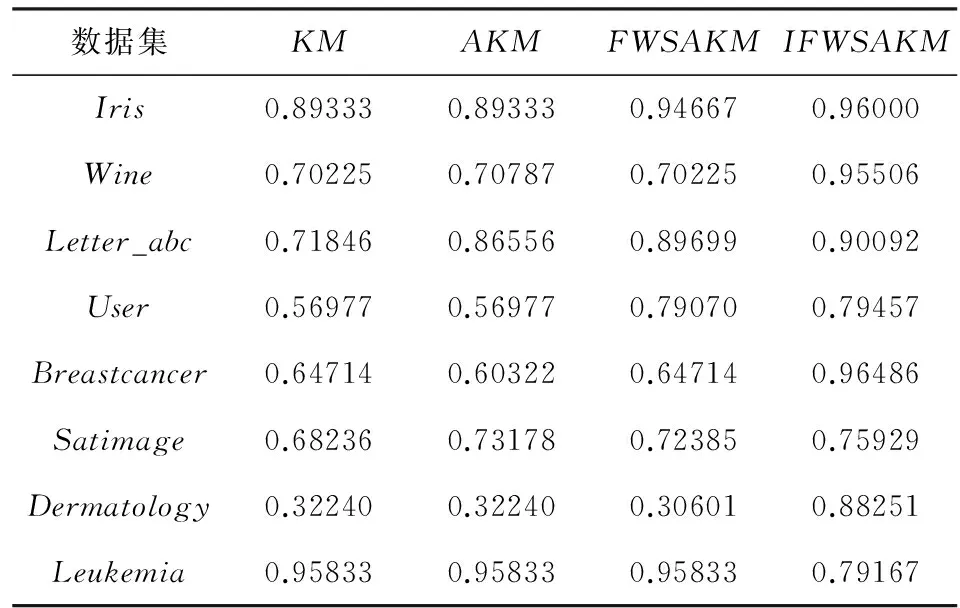
表2 各算法对8组数据集聚类的最优精度
从表2可以看出,IFWSA-KM算法在7个数据集上得到的最优聚类精度,明显优于其他3种聚类算法。由于在聚类运算中,最优结果只是所有结果中最好的情况,表3给出了4种聚类算法分别对8个数据集20次运算的平均聚类结果。
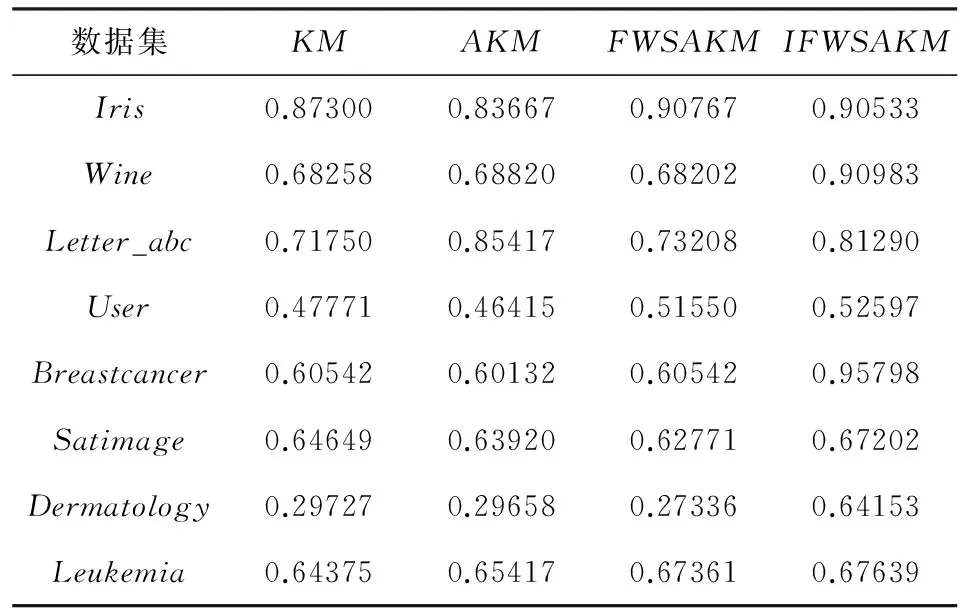
表3 各算法对8组数据集聚类的平均精度
从表3可以看出,IFWSA-KM算法在6个数据集的平均聚类精度都优于其他3种聚类算法。
综上所述,IFWSA-KM算法的总体聚类精度优于KM、AKM和FWSA-KM聚类算法。
3.3 测试算法的抗噪声能力
3.3.1 均匀分布噪声对算法的影响
为了测试IFWSA-KM聚类算法的抗噪声能力,在Wine数据集中使用Matlab软件中的Rand函数,生成30个均匀噪声样本,并将30个噪声样本置于Wine数据集的尾部,形成了一个新的人工数据集Wine1,该数据集有208个样本,13个样本特征。用4种聚类算法分别对Wine1数据集进行聚类,最终的聚类结果如表4和表5所示。
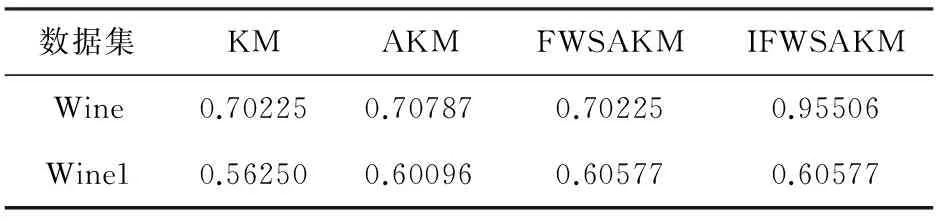
表4 各算法对Wine1数据集聚类的最优精度
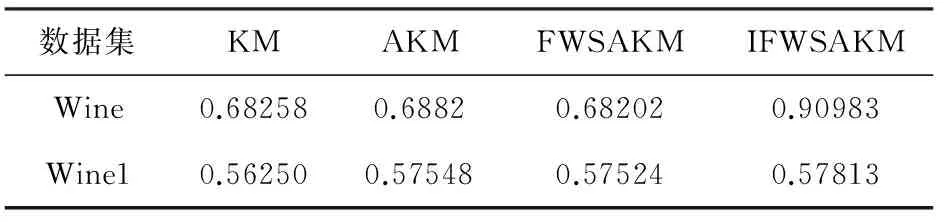
表5 各算法对Wine1数据集聚类的平均精度
由表4和5可以看出,在Wine数据集加入了均匀噪声,4种聚类算法的聚类精度都有所下降,但是IFWSA-KM聚类算法与KM、AKM、FWSA-KM聚类算法相比,在最优精度方面优于KM和AKM算法,与FWSA-KM算法精度相当,在平均精度方面优于其他3个算法。因此,IFWSA-KM聚类算法的抗均匀噪声性能较好。
3.3.2 离群点噪声对算法的影响
为了进一步测试IFWSA-KM聚类算法对噪声的鲁棒性,在Wine数据集上增加一个离群点噪声(用Matlab中的函数1000*ones(1,13)),生成一个新的人工数据集,记为Wine2,该数据集有179个样本,13个样本特征。用4种算法对wine2数据集进行聚类。聚类的结果如表6和7所示。
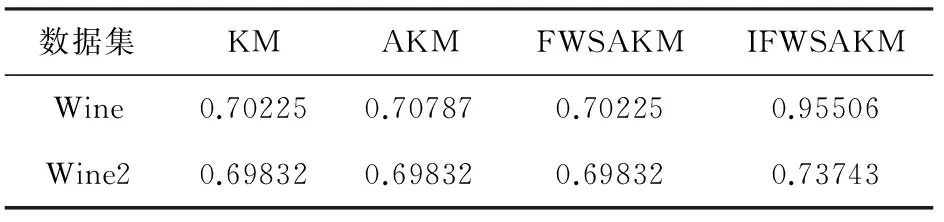
表6 各算法对Wine2数据集聚类的最优精度

表7 各算法对Wine2数据集聚类的平均精度
由表6和7可以看出,在Wine数据集加入离群点噪声后,IFWSA-KM算法的最优精度和平均精度仍然优于KM、AKM、FWSA-KM算法。因此,IFWSA-KM聚类算法的抗离群点噪声性能较好。综上所述,IFWSA-KM聚类算法明显具有抗噪声性强,鲁棒性好的优点。
3.4 测试算法的特征选择能力
Iris和Dermatology数据集都是真实的数据集,经常被用来作为聚类算法的测试数据集,现用这两个数据集测试IFWSA-KM算法的特征选择能力。用IFWSA-KM算法对Iris和Dermatology数据集进行聚类,得到两个数据集的特征权重,将得到的特征权重分别进行排序;根据排序的大小,将特征权重明显较小的舍去,用剩下特征权重所对应的数据,组成新的数据集[10];用4种聚类算法分别对特征选择前后的数据集进行聚类,以测试IFWSA-KM聚类算法对数据集进行特征选择的有效性。
表8和9分别给出Iris和Dermatology数据集分别经过IFWSA-KM算法聚类后得到的特征权重排序。
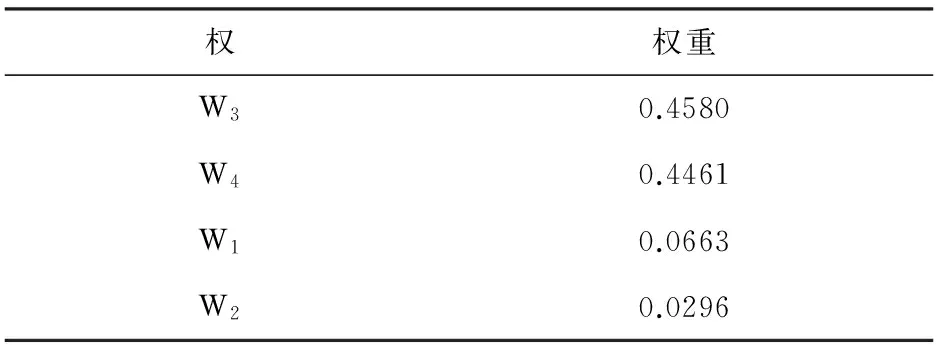
表8 Iris数据集的特征权重排序

表9 Dermatology数据集的特征权重排序
由表8可知,Iris数据集的第1、第2两个特征的权重明显比其它特征权重小,故在特征选择时将它们舍弃,得到新数据集Iris1。由表9可知,Dermatology数据集的第1、第13和第32三个特征的权重明显比其它特征权重小,故在特征选择时也将它们舍弃,得到新的数据集Dermatology1。
用4种聚类算法分别对Iris、Iris1、Dermatology和Dermatology1数据集进行聚类。聚类的结果如表10和11所示。

表10 各算法对Iris和Iris1数据集聚类的精度
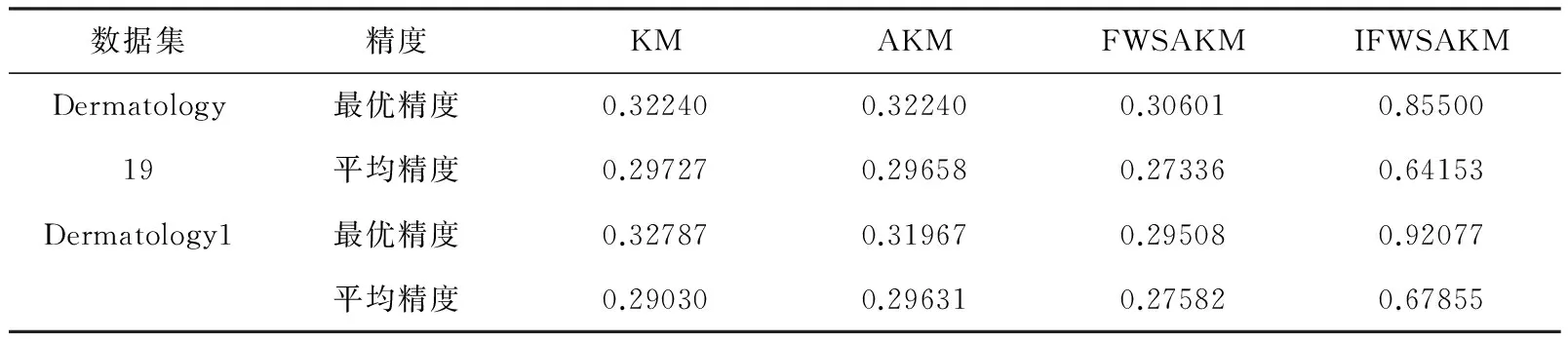
表11 各算法对Dermatology和Dermatology1数据集聚类的精度
由表10和11可以看出,4种聚类算法对经过特征选择后新数据集的聚类精度,都优于对原数据集的聚类精度,其中IFWSA-KM算法的聚类精度不但优于KM、AKM、FWSA-KM算法的聚类精度,而且还优于特征选择前IFWSA-KM算法的聚类精度。从而表明IFWSA-KM算法具有良好的特征选择能力。
4 总结
利用一种非欧氏距离代替FWSA-KM算法中的欧氏距离,提出一种改进型特征权重自调节K-均值聚类算法。新算法是原FWSA-KM算法的一种改进型算法,该聚类算法不仅具有良好的特征选择能力,同时具有一定的对复杂结构数据和噪声数据的鲁棒性,是一种可供选择使用的聚类算法。聚类算法收敛与否对于聚类算法是至关重要的,如何证明IFWSA-KM的收敛性将是下一步的工作。
[1] 高新波.模糊聚类分析及其应用[M].西安:西安电子科技大学出版社,2014:1-10;50-90.
[2] Wu Kuolung, Yang Miinshen. AlternativeC-means clustering algorithms[J]. Pattern recognition, 2002, 35(10): 2267-2278.
[3] DeSarbo W S, Carroll J D, Clark L A, et al. Synthesized clustering: A method for amalgamating alternative clustering bases with differential weighting of variables[J]. Psychometrika, 1984, 49(1): 57-78.
[4] Huang Zhexue, Micheal K Ng, Rong Hongqiang, et al. Automated variable weighting inK-means type clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 657-668.
[5] Jing Liping, Micheal K Ng, Huang Zhexue. An entropy weightingK-means algorithm for subspace clustering of high-dimensional sparse data[J]. IEEE Transactions on Knowledge and Data Engineering, 2007, 19(8): 1026-1041.
[6] Tsai C Y, Chiu C C. Developing a feature weight self-adjustment mechanism for aK-means clustering algorithm[J].Computational statistics and Data analysis, 2008, 52(10): 4658-4672.
[7] Guo Gongde, Chen Si, Chen Lifei. Soft subspace clustering with an improved feature weight self-adjustment mechanism[J]. International Journal of Machine Learning and Cybernetics, 2012, 3(1): 39-49.
[8] Zhi Xiaobin, Fan Jiulun, Zhao Feng. Robust Local Feature Weighting HardC-Means Clustering Algorithm[J]. Neurocomputing, 2014, 134: 20-29.
[9] 支晓斌, 田溪. 判别模糊C-均值聚类算法[J]. 西安邮电大学学报, 2013, 18(5): 26-30.
[10] 皋军,王士同.具有特征排序功能的鲁棒性模糊聚类方法[J].自动化学报,2009,35(2):146-153.
[责任编辑:王辉]
K-means clustering algorithm with an improved feature weight self-adjustment mechanism
ZHI Xiaobin1, XU Zhaohui2
( 1.School of Science, Xi’an University of Posts and Telecommunications, Xi’an 710121, China;2.School of Communication and Information Engineering, Xi’an University of Posts and Telecommunications, Xi’an 710121, China)
K-means with a feature weight self-adjustment mechanism (FWSA-KM) clustering algorithm is sensitive to noise. ThereforeK-means with an improved feature weight self-adjustment mechanism (IFWSA-KM) clustering algorithm is proposed in this paper. IFWSA-KM clustering algorithm can have some anti-noise performance by using a non-Euclidean distance. The effectiveness of IFWSA-KM algorithm is demonstrated by comparative experiments on synthetic and real data.
clustering algorithm, feature weighting, robust, non-Euclidean distance
10.13682/j.issn.2095-6533.2014.06.006
2014-05-14
陕西省自然科学基金资助项目(2014JM8307)
支晓斌(1976-),男,博士,副教授,研究方向为模式识别。E-mail:xbzhi@163.com 许朝晖(1988-),男,研究生,研究方向为现代信号处理与应用。E-mail:1113110702@qq.com
TP391.4
A
2095-6533(2014)06-0026-06
猜你喜欢
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
电子制作(2017年23期)2017-02-02 07:17:06
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
西北工业大学学报(2015年4期)2016-01-19 03:31:47
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
振动工程学报(2014年4期)2014-03-01 01:15:41
