
一种基于综合语义加权临床诊断本体领域概念计算方法*
2014-05-14 02:17朱文婕刘玉文翟菊叶
通化师范学院学报 2014年6期
王 凯,朱文婕,刘玉文,翟菊叶
(蚌埠医学院公共课程部,安徽蚌埠 233030)
一种基于综合语义加权临床诊断本体领域概念计算方法*
王 凯,朱文婕,刘玉文,翟菊叶
(蚌埠医学院公共课程部,安徽蚌埠 233030)
针对当前临床诊断知识库融合过程中,领域概念相似度计算所存在的语义融合不充分且计算方法复杂等不足,提出一种改进的基于语义综合加权的概念对相似度矩阵生成算法.根据概念在概念格中的层次结构来确定概念属性特征集合,从概念节点属性信息量、节点层次以及概念非对称性等三个方面对语义距离度量进行扩展,通过引入横向节点透明度算子、纵向节点深度算子以及非对称算子,使最终语义相似度度量结果更精确.并通过使用一个标准的临床诊断知识库概念对该模型进行实验验证,实验结果表明该方法具有可行性和有效性.
概念格;节点透明度;节点深度;非对称;相似度
医学临床诊断知识的复杂性、经验性等特点决定了该领域知识表示的多样性,使得医学领域知识的共享与复用受到很大程度的限制.而高血压作为一种常见的临床综合征,严重影响人类健康,并且以其为主要研究对象的知识库之间缺少必要的联系,彼此间存在着较大的差异性.目前,医学领域知识库的研究还处于基础研究阶段,相关理论与方法还在不断完善中,大规模、集成化的知识库融合也只进行了初步的研究.
语义相似度度量是一种基于概念或术语相似程度判别的分类关系,能够有效地发现语义信息,对后期大规模融合知识库以及知识挖掘与发现等具有现实而重要的意义.目前的研究成果主要有:一是基于信息论的相似度计算,通过度量对象内的属性重叠度,判别概念间语义距离的远近.文献[1]用父类概念节点与子类概念节点之间的有向数量表示概念间的语义差异,结合概念属性密度函数进行计算.文献[2]通过定义相似边权重函数,考虑节点纵向深度的权重取值,度量节点语义距离.文献[3]利用基于特征的属性值,刻画不同概念的相似度.研究发现虽然具备相对严格的理论基础,但对于概念间的语义度量仍相对粗糙,没有完全考虑到概念内的层次关系.
另一种是基于语义边距离的计算方法,该方法将概念间的分类关系转变成具有节点结构的层次树,通过计算节点之间路径计数,获取语义信息.文献[4]首先构建层次节点树状概念图,用节点间最短连接路径作为语义衡量的标准.文献[5]通过计算概念对的最近距离的相同父类节点到彼此最上层根节点的边个数,确定语义相似度.上述方法由于需要设定相等的边连接线长度,忽略了节点间边连接的语义差别,同时基于语义边距离的度量方法需要概念节点之间语义关系的完整性描述,对知识表示系统的要求相对较高,也从另外一方面限制了该方法的使用范围.
本文在对相关内容研究分析的基础上,针对上述方法的不足之处,通过引入节点透明度、节点深度以及非对称度等算法因子,分别从概念节点的自身特征属性集、节点层次概念权重以及非对偶概念对等角度计算概念对语义距离,最后综合加权,得到包含该概念对特征属性集的语义相似度矩阵.
1 相关概念
概念格[6],也有学者称为形式概念分析理论,该理论是基于二元关系,构建具有概念层次的格结构,在数据分析、数据挖掘以及规则提取等领域具有广泛的应用前景.概念格结构的本质是从数据集中产生一系列概念聚类的过程[7],从而达到清晰表达概念间层次结构的目的,同时使用格节点间的继承、父类关系等特征展现概念间泛化或是特化的语义关系.
概念格节点其本质即为一个形式概念,规范化的形式概念包含概念的外延和概念的内涵.前者包含所有与此概念相关的对象集合,从领域应用的角度则是概念所蕴含的应用实例,后者则表示概念对象的属性特征.
假设对于任意三元组K=(G,M,I),若G为对象的并,M为属性的并,I表示G与M之间的二元关系集合,同时有且仅有一个偏序集合与之相对应,则称该三元组为一个形式背景.该偏序集所构成格结构满足自反性、反对称性和传递性[8].若g∈G,m∈M,gIm表示对象g包含m属性.概念格结构中的任意两个直接相连节点之间必然存在某种偏序关系,假设节点C1=(X1,Y1),C2=(X2,Y2),满足X1<X2Y1<Y2,则C1是C2的上层父类节点.领域形式背景通常是由二维表展现,如表1所示,其中横向维表示属性,纵向维表示对象,第i行j列为1表示存在该属性,为0表示不存在该属性,与其相对应的外延与内涵如表2所示.同时基于上述偏序关系可以画出与之相对应的Hasse图,如图1所示.

表1 形式背景示例

表2 所生成的概念
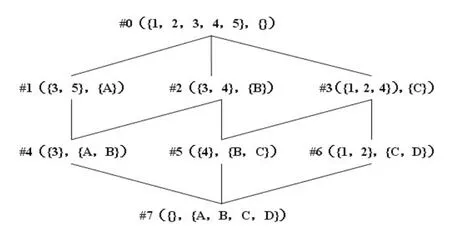
图1 与表2相对的Hasse图
2 改进的概念相似度计算模型
定义1 概念节点透明度是指概念外延节点c所包含的直接子类节点数量,记做O(c).

其中,degree(anc12)是概念节点1、2子节点数量;degree(fc)表示该形式背景所生成的概念格结构中的各节点度的最大数值.
2.1 基于概念横向节点透明度相似度
tversky认为概念间的语义距离由一对概念实体中所包含的共享属性量以及差异属性量共同决定,相似度与共享属性成某种线性正相关性,与差异属性成线性负相关性.在仅讨论上下相邻节点的前提下,任意一个概念的属性集合等于其上层节点概念的属性集合并上自己的专属特征集合,若概念格结构划分规范且完整,相邻节点间特征集合所包含的属性数量为1,在Hasse图中,以一个有向边表示.
通常情况下,某概念节点的直接子节点数量越多,透明度愈大,表明对其细化的概念描述愈具体,即其所含子类节点之间的语义相似度就愈大;反之亦然.本文从集合论的角度,将该影响算子对概念间相似度的影响定义为:
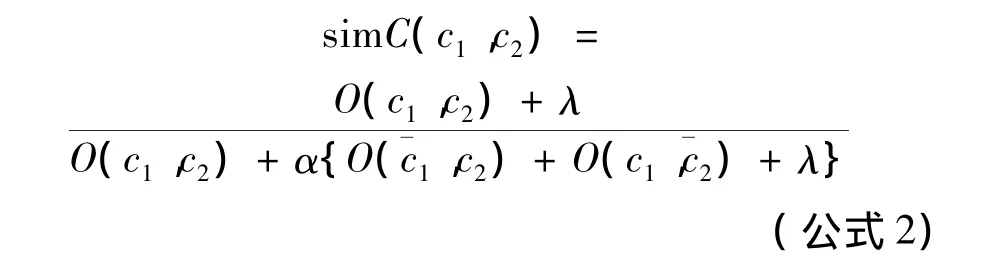
其中,O(c1,c2)为两概念所交的共同属性集;O,c2)与O(c1).为概念对的差异属性.
2.2 基于概念纵向节点深度相似度
概念内涵纵向节点深度是指在基于该领域形式背景所表达的领域知识中,针对某种以偏序集存在的概念层次二元关系格结构,外延节点与根节点的最短路径中所包含的边数.在概念格Hasse图中,每个横向层次概念节点均是对上层节点的特化表示,越到下层,概念的表示就越具体,所包含的内在属性就越丰富.若领域内任意两个概念存在共同的特征,则其上层节点间必然存在交点;相反,若不存在共性,则上层节点间必然不存在交点.
定义2 在形式背景中,若任意概念节点间语义距离相等时,概念对的节点深度和(差)越大(小),概念间的语义相似度就越大.即层次节点距离根节点越远,其概念节点间的相似度就越大.该影响算子的公式为:
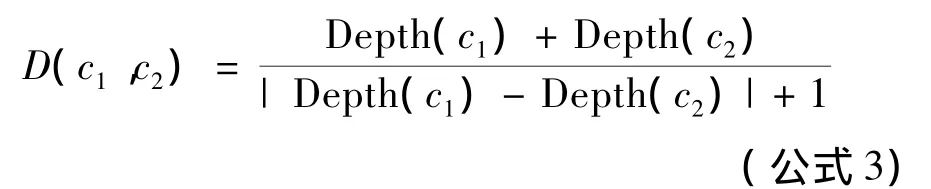
其中,Depth(C)是格内节点的节点深度计算函数.
由上文分析可知,概念对的节点深度越大,代表其所表示的内涵属性就越具体,概念相似度就越大,故可以用指数函数来描述纵向节点深度所代表的相似度.

2.3 基于概念节点非对称相似度
定义3 若概念相似求解函数 Sim,满足Sim(A,B)=Sim(B,A),则称该概念对完全对称,否则为非对称.
本文在对大量医学临床高血压知识库形式背景概念节点的分析过程中,利用文献[9-10]提出的模型分别从基于距离、信息内容以及概念属性角度计算一组随机抽样的样本概念对数据,在格内节点中,概念节点间的语义相似度在一定程度上存在非对称性,即语义匹配具有方向性.
通常情况下,概念与其祖先节点的相似度值大于其祖先与其子节点的相似度取值,即若概念A为概念B的祖先,则Sim(A,B)要小于 Sim(B,A).因此,本文针对大多数概念对求解模型,提出非对称相似度计算影响因子:
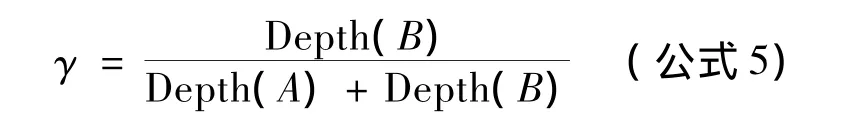
此时概念c1,c2的相似度可表示为:

2.4 基于综合加权的概念相似度模型
由于基于概念横向节点透明度相似度方法没有考虑到节点透明度相同、深度不同的概念节点相似度;而基于概念纵向节点深度相似度又无法区分深度相同、透明度不同的问题[11].因此,为解决上述方法所存在的不足,将其用线性方法加权,提出基于综合加权的概念相似度计算模型:
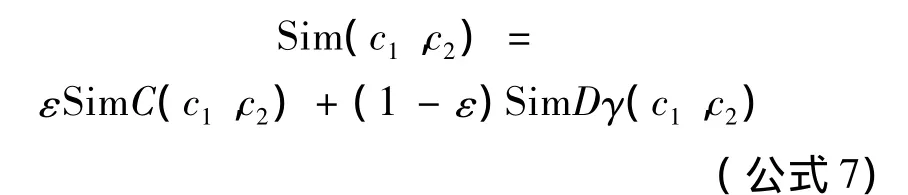
其中,ε为权重因子,用以调节概念节点透明度和深度对相似度的影响.
本模型满足概念相似性的基本特征如下:
1)概念对语义相似度是0到1之间的实数,且数值越大,表明相似度越大.
2)概念对为同一节点时,语义相似度为1.
3)概念对在Hasse图中的共享部分越大,即共同属性越集中,语义相似度越大.
4)概念对在Hasse图中位置越深,即属性表征越聚向,语义相似度越大.
3 实验结果评估与分析
实例中的形式背景来源于高血压临床诊断知识库中所包含的对象集和属性集分别为:G={Patient1;Patient2;Patient3;Patient4;Patient5},M={I-atrogenic;Career incentives;Pathological changes;Clinical indicators}.由此所形成的形式背景及其对应的概念格如表3和图2所示.
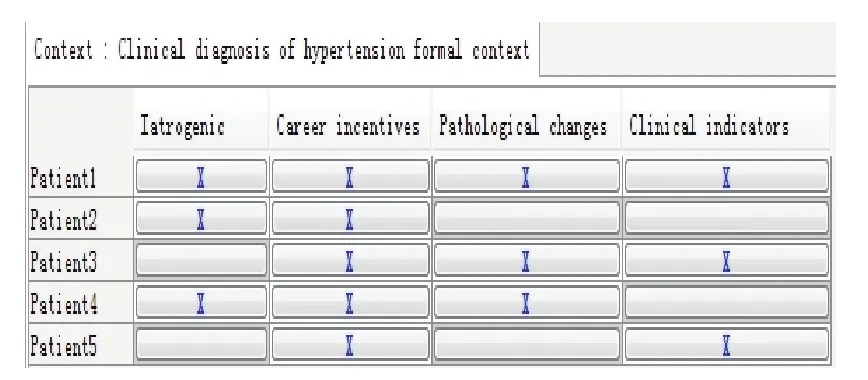
表3 高血压临床诊断形式背景

图2 与表3相对应的概念格结构图
由于领域概念存在于某个特定的领域,从理论的角度并不存在某些完全相同或是完全没有关联的概念对集合,但为了分析的需要,本实验设定,若概念对集合中的语义完全相同,则相似度值为1;反之完全没有关联时,其相似度值为0;显然多数概念间存在某种偏序集关系,而非严格意义上的继承与被继承关系,故相似度值的取值限定在0~1区间.公式中相关参数的取值是医学领域本体概念集样本数据训练以及参考文献[12,13]中关于模型参数取值的讨论,选取概念权重因子ε=0.5,调节参数λ和a,带入公式可以得出包含对象以及属性的形式概念节点的相似度值,本文同时将此模型的结果与基于信息距离[14]的计算结果相比较,图3是笔者所编写的程序截图.两种方法所形成的相似度矩阵以数值为1的对角线为临界线,将此表分为上下两个部分,上三角数值结果为改进的概念相似度取值,下三角为基于信息距离模型的相似度取值.

图3 相似度矩阵
本文根据概念在概念格中的层次结构来确定概念属性特征集合.同基于信息距离模型相比具有以下改进:提高计算精度.通过引入横向节点透明度算子、纵向节点深度算子以及非对称算子对语义距离度量进行扩展,使得相似度值均有不同程度的提高;同时减少不相关概念对的出现.由于领域概念在一定程度上具有相关联的内在属性特征,故任意两个概念出现相似度为零的情况应该越少越好,概念对为零的矩阵值相比之下在样本抽样实验中发生率有了明显降低,提高了概念间相似度度量准确度.
4 结束语
语义概念相似度度量在知识融合,特别是消除医学临床诊断知识的复杂性、经验性等方面,具有十分重要的意义.不仅能有效提高诊断评估的准确性和治疗干预的安全有效性,还可以为建立可共享、可复用的临床诊断知识库系统提供理论依据与技术支持.
本文的工作仍然存在着一些不足和需要改进的地方,主要有:医学临床诊断包含许多具有主观概念的知识节点,由于运算量太大,在语义关系的整理中,本文仅仅计算了概念对之间的两两相似度问题,并没有遍历所有涉及到的语义概念,对计算结果可能会有部分偏差;临床知识库中的相关关系含义十分广泛,本文在具体处理过程中并没有对此加以严格区分.以上不足之处拟在后续的研究中逐步加以解决.
[1]杨立,左春.基于语义距离的K最近邻分类方法[J].软件学报,2005,16(12):2054 -2062.
[2]王腾,朱青,王珊.基于语义相似度的Web信息可信分析[J].计算机学报,2013,36(8):1668 -1680.
[3]Pirro G.A semantic similarity metric combining features and intrinsic information content[J].Data and Knowledge Engineering,2009,68(11):1289-1308.
[4]杨春龙,顾春华.基于概念语义相似度计算模型的信息检索研究[J].计算机应用与软件,2013,30(6):88 -92.
[5]李文庆,谢红薇.基于医疗本体的语义相似度评估方法[J].计算机工程与设计,2013,34(4):1287 -1291.
[6]穆斌.语义Web中的语义度量与本体映射[J].合肥工业大学学报,2006,29(3):300 -304.
[7]顾进广,黄屹.Mediator模式下基于语义映射的多本体融合机制研究[J].武汉大学学报,2006,52(1):81 -86.
[8]强宇,刘宗田,林炜,等.模糊概念格在知识发现的应用及一种构造算法[J].电子学报,2005,33(2):350 -353.
[9]毛华,窦林立.基于矩阵列秩属性优先的概念格算法[J].河北大学学报(自然科学版),2009,29(2):130 -132.
[10]吕刚,郑诚.改进的基于概念相似度的文本检索[J].计算机工程,2010,36(12):55 -57.
[11]DoanA H,Madhavan J,Domingos P.Leanring to M Between Ontologism on the Semantic Web[C]//Proceedings of the 1lth Intemational Conferenceon World W ide Web.New York,USA:ACM Press,2002.
[12]赖院根,王娜.概念语义相似度计算与参数估计[J].情报杂志,2009,28(08):148 -152.
[13]夏天.汉语词语语义相似度计算研究[J].计算机工程,2007,33(06):191 -193.
[14]Budanistsky A,Hirst G.Semantic distance in WordNet:An experimental,application - oriented evaluation of five measures.[C].Proc of the Workshop on WordNet and other Lexical Resources.Pittsburgh:ACM,2001:95-100.
TP301.6
A
1008-7974(2014)03-0004-04
2013-11-12
王凯(1985-),男,安徽蚌埠人,硕士,教师.
安徽省教育厅高校自然科学研究项目(KJ2011B092);蚌埠医学院科研项目(ByKy1304).
(责任编辑:王前)
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
开放教育研究(2020年2期)2020-03-31
五邑大学学报(自然科学版)(2019年3期)2019-09-06
制造技术与机床(2019年6期)2019-06-25
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
中国交通信息化(2016年9期)2016-06-06
长江学术(2016年4期)2016-03-11
