
基于概念格的关联规则在排产管理的应用
2014-04-03 01:45张晓,龙伟,卢斌
计算机工程与应用 2014年9期
张 晓,龙 伟,卢 斌
ZHANG Xiao,LONG Wei,LU Bin
南昌大学 信息工程学院,南昌 330031
School of Information and Engineering,Nanchang University,Nanchang 330031,China
1 引言
汽车冲压厂在生产过程中,具有混线生产、多品种以及多工艺的特征,近几年来,随着生产信息管理系统的广泛使用,冲压厂积累了大量的生产历史数据,但是目前该系统大部分仅限于查询、统计等功能,无法发现数据中存在的关系和规则,导致了“数据爆炸但知识贫乏”的现象[1]。而数据挖掘技术[2-3]能有效从这些大量复杂的数据中找到有用的规则和信息,并将它们转化为知识表示,为管理人员在生产排产中提供理论依据。
关联规则[4-5]是数据挖掘中的一个重要分支,描述了数据间的潜在关系,Apriori算法是经典的关联规则算法,目前很多常见的关联规则挖掘算法都是在此算法的基础上加以改进的,但其生成频繁项集过程复杂,对规则的可视化存在不足。本文重点分析了基于概念格[6-7]的关联规则在生产信息数据中的应用,通过概念的内涵和外延及泛化和特化之间的关系来表示知识,通过量化概念格寻找关联规则,并与经典的Apriori算法进行对比,能非常容易实现规则的可视化,不需要计算频繁项目集,就能容易获取用户感兴趣的规则,提高了挖掘效率。根据找到的关联规则,指导企业作出排产方案[8],达到优化排产,降低库存,提高产品生产效率和增强企业竞争力的目的[9-10]。
2 汽车冲压厂排产管理分析
汽车冲压厂的生产管理是以科室为单位进行的,其生产流程为:首先,制造科人员根据冲压厂的库存数据、零件需求、订货成本、订货周期、持有成本、缺货率等信息,计算冲压件可支撑天数,从大到小排列生成一张排产信息表。然后由科室排产人员对相应零部件安排好加工生产线、班次和工序次序。其次由技术科对冲压件在生产过程中的技术要求作出规划。最后冲压车间根据排产信息和技术要求进行冲压件的生产,并填写生产数据信息,质管科对生产过程中所有产品的质量进行监测,并由设备科维护或维修设备。
其中,制造科人员如何根据已有信息作出高效的排产计划是生产过程的关键。其他科室人员都是根据该排产计划来作业生产,排产计划愈合理,冲压厂的生产效率愈高,企业绩效愈好[11]。因此,本文重点研究了如何利用数据挖掘中基于概念格[12-13]的关联规则技术来实现优化排产的目的[14]。
2.1 关联规则概述
关联规则既可以发现不同事物间的新规律,又能检验事物间隐藏的相互关系、依存性和关联性。若两个或多个变量的取值之间存在某种规律性,就称为关联。关联规则挖掘技术用于发现数据库中属性之间的有意义的联系,旨在寻找在同一事件中出现的不同事物的相关性。关联规则挖掘问题就是在事物数据库中找出具有用户给定的最小支持度和最小置信度的关联规则,关联规则挖掘问题可以分为以下两个子问题:
(1)生成频繁项集:其任务是生成所有满足最小支持度阀值的项集,这些项集被称为频繁项集。
(2)生成规则:其任务是从上一步生成的频繁项集中提取所有高置信度的规则。
其中第一个问题是关联规则的核心问题,相对生成频繁项集而言,规则的生成则比较简单和直接。通常,生成频繁项集所需的计算开销要远远大于规则生成所需的计算开销。一般来说关联规则挖掘算法主要是对第一部分提出来的。
2.2 概念格定义
(1)形式背景
对于一个三元组K(U,A,I),其中U表示对象集合,A表示属性集合,I表示对象U和属性A之间的二元关系。如果存在(u,a)∈I,说明对象u具有属性a。当X*={a|a∈A,∀x∈X,xIa},X⊆U;B*={x|x∈U,∀a∈B,xIa},B⊆A 。若 ∃X*=B 且 B*=X ,称 (X,B)为一个形式概念。 X定义为概念(X,B)的外延,B定义为概念(X,B)的内涵。概念的外延是指概念覆盖的所有对象之集,概念的内涵是指所有对象所共有的属性。
(2)概念格
属性和对象之间的关系用概念格来表示,在概念格的结点之间,有一种偏序关系存在,若有C1(X1,B1)和C2(X2,B2),则 C1<C2必然有 B1<B2,这一种偏序关系说明 C1(X1,B1)是 C2(X2,B2)的高级概念,或者说 C1(X1,B1)是C2(X2,B2)的一个泛化。对于形式背景 (U,A,I),在关系I中,只存在着唯一的偏序集,这个偏序集产生的格结构,称为概念格。所以,一个形式背景只可能产生唯一的概念格。
(3)Hasse图
Hasse图用一种简明有效的图将概念格中的偏序集关系表示出来,能够非常完整直观地表示出所有概念结点之间外延和内涵以及泛化和特化的关系,是表示概念格最通用的方法。
3 基于概念格的关联规则在排产管理的应用
3.1 数据准备
5个科室管理人员分别从不同的入口把数据采集到生产信息管理系统各个子系统数据库中,期间产生了许多冗余的、不规范的、错误的和不一致的数据,如果把这些数据直接用于数据挖掘,那么需要花费大量的时间,所以在数据挖掘之前必须做好对数据的清洗等工作,为数据挖掘准备好数据。
到目前为止,冲压车间生产的汽车零部件有1305多种,产品生产总记录数超过30万。如果对数据库的所有数据进行分析,得到的关联规则支持度可能会非常低,甚至得不到关联规则,因此,本实例中选取某特定车型零部件产品序号为T074的生产信息数据作为数据挖掘库,对同一产品序号进行挖掘,在实际应用中,用户可以选择其他产品车型或字段属性生成数据挖掘库。
在收集到的生产信息数据中有很多属性,但是其中有一些与数据挖掘关系不大,或数据本身没有挖掘意义。例如产品名称等属性,这些属性值是唯一性的,没有什么挖掘意义,而数据量又很大,可以直接删除,从而压缩搜索空间。另外还有像日期之类的属性,没有分类的意义,可以剔除这些数据,达到精简数据规模的目的。同时,对不完整的、有噪声的和不一致的字段或数据进行清理,具体操作为填充某些空缺的字段值,消除多个表中的不一致,构造一些字段以便概化,对某些数字型字段进行离散化的归约工作等,以确保数据的有效性。
经过数据预处理后,为了说明问题,数据集中最终确定的生产信息数据表中包含了7个相关属性(ID,生产线,班次,工序次序,库存数量,缺货率,核对完工数)。根据相关标准,把核对完工数、库存数量和缺货率是否达标作为规则的结果(Y表示最优,N表示不是),其部分数据如表1。
为了方便数据的表述,对表1中属性“生产线”用字母a表示,具体值A1、A2分别用1、0表示;属性“班次”用字母b表示,具体值白班、晚班用1、0表示;以此类推形式化表1中的数据。本文中为了说明基于概念格的数据挖掘在汽车冲压工序应用的可行性及高效性,选取其中的6组数据(分别用 ui(i=1,2,3,4,5,6)表示)来说明问题,最终用来阐述问题的部分数据如表2所示。

表1 生产信息数据表

表2 生产信息数据简化表
3.2 关联规则挖掘
本文首先利用经典的Apriori算法对表2中的数据进行关联规则挖掘,然后使用量化概念格生成关联规则,并将挖掘结果进行对比分析,利用生成的关联规则给制造科人员排产提供理论依据。
3.2.1 Apriori算法挖掘
Apriori算法是经典的关联规则算法,其核心是基于频集理论的递推方法。该算法使用一种称作逐层迭代的候选产生测试的方法,K项集用于探索产生K+1项集。将Apriori算法应用于上述准备好的数据中,并且设置支持度为0.04和置信度为0.45,具体实现过程如下:
产生1-候选项CX(1),设 rx∈CX(1),如果对任意ry∈D都存在sup(rx=>ry)<0.04,则称rx是非频繁的,将rx从CX(1)中删除,否则,如果conf(rx=>ry)≥0.45,则说明规则rx=>ry符合条件。CX(1)删除所有非频繁项集后构成1-频繁集L1。
在L1的基础上,利用Apriori性质压缩搜索空间,由连接和剪枝生成2-候选项集CX(2),扫描事物数据库,利用与上述相同的方法,并根据最小支持度和最小置信度找到满足条件的关联规则,删除所有非频繁项集后生成2-频繁集 L2。
这一过程反复进行,直到生成K-频繁项集Lk,并且不可能再生成满足最小支持度的k+1项集为止。
最后产生的有效关联规则如表3所示。
3.2.2 构造概念格
对于表2中的形式背景,利用分而治之方法来构造Hasse图,即首先将表2中的形式背景进行拆分,分解得到两个小的形式背景,然后分别对各个小的形式背景构造概念格,最后将两个小形式背景构造的概念格进行合并[15-16]。其构造算法的伪代码如算法1所示。
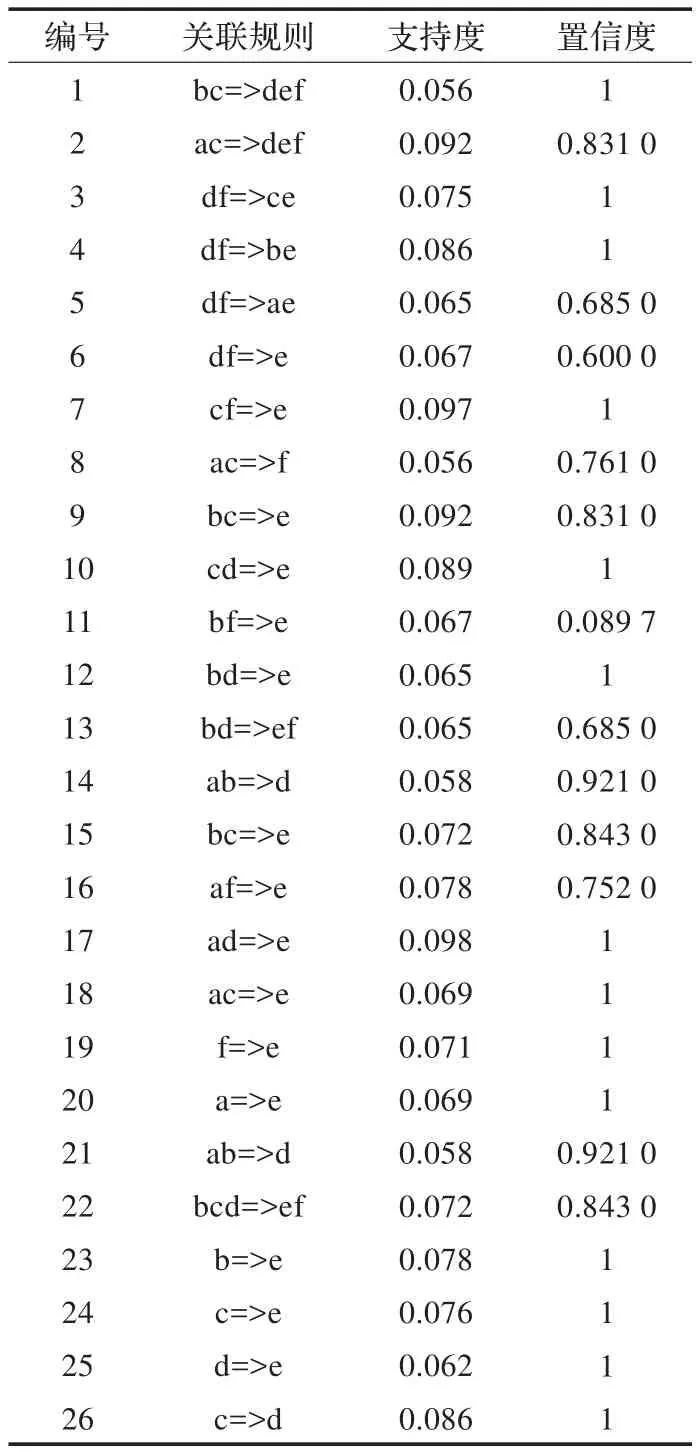
表3 基于Apriori算法的关联规则
算法1

本例中采用横向拆分与纵向合并的策略来构造最终的Hasse图。采用分治策略构造概念格可以有效地简化构造过程的复杂性,同时提高构造效率。本文设定属性的阀值个数为4,即由属性个数大于或等于4的构成形式背景1,其余属性个数小于4的属于形式背景2,拆分后得到的两个小形式背景分别如表4、表5所示。

表4 形式背景1
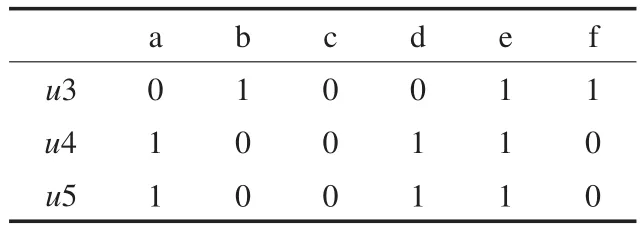
表5 形式背景2
首先对表4和表5两个小形式背景分别构造相应的概念格,构造子概念格的算法伪代码如算法2所示。
算法2


按照上述算法最终得到的子形式背景的Hasse图分别如图1、图2所示。

图1 形式背景1对应的Hasse图

图2 形式背景2对应的Hasse图
然后按自上而下的顺序对图1和图2中的概念格进行合并,其合并算法的伪代码如算法3所示。
算法3


根据算法3得到最终合并后的总体概念格,其对应Hasse图如图3所示。

图3 概念格的整体Hasse图
3.2.3 基于概念格生成关联规则
概念格作为数据挖掘和提取关联规则的有效工具,直接通过所有概念格结点之间的泛化和特化关系来提取规则,得到数量较少的、用户感兴趣的、容易理解和能有效反映真实情况的关联过则。为了简化实现过程,可以用计数值来表示每个概念格结点的外延。如果外延个数大于最小支持度计数,则说明该结点的内涵就是一个频繁项集。因此,在进行概念格的关联规则挖掘之前,首先把概念格进行形式上的改变,即用计数值来表示概念格结点的外延个数,这种概念格就称为量化概念格。该表示方法具有诸多优点,主要表现在:在每个概念格结点中包含有外延计数值,不需考虑外延所包含的具体信息,因此,在只考虑外延计数值的情况下,能快速高效地计算关联规则的置信度和支持度。本例中概念格的整体Hasse图量化之后如图4所示。
从量化概念格中生成关联规则是数据挖掘中的关键,概念格中各个结点生成的关联规则依赖于其双亲结点。
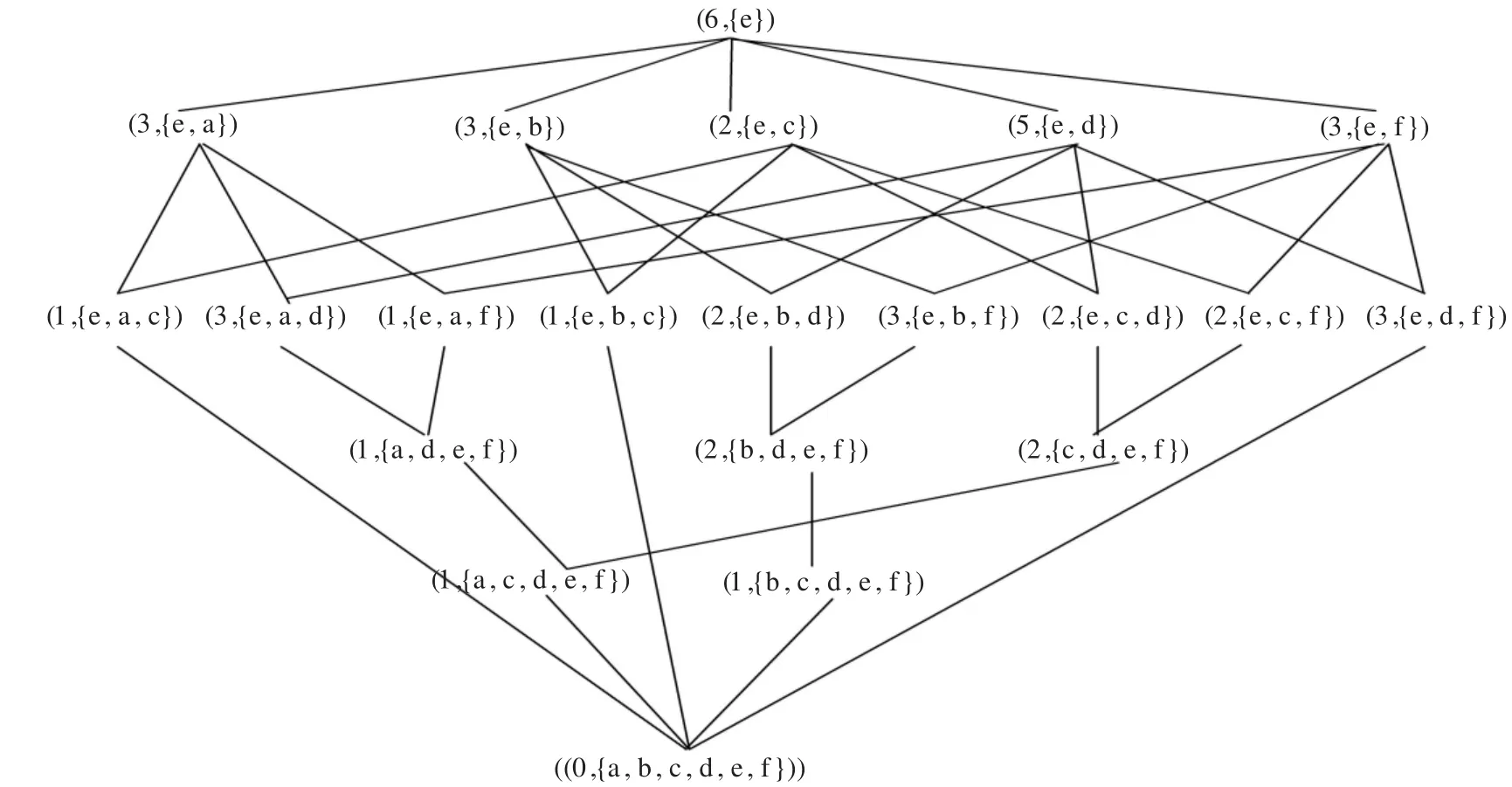
图4 量化概念格
(1)如果结点 C(X,B)只有一个双亲结点 C1(X1,B1),则C蕴含规则的前件为(B-B1),对于∀p∈(B-B1),存在的蕴含规则为 p=>B-p。例如,对于图4中第二层的第一个结点(3,{e,a}),其只有一个双亲结点(6,{e}),那么满足条件,因此该结点产生的规则前件是(B-B1)={e,a}-{e}={a},所存在的关联规则:a=>e。
(2)如果结点 C(X,B)有两双亲结点 C1(X1,B1)和C2(X2,B2),则对于 ∀p1∈(B1-B1∩B2)∀p2∈(B2-B1∩ B2),存在蕴含规则为 p1p2=>B-p1p2。例如图4中,第三层第二个结点(3,{e,a,d})的双亲结点为(3,{e,a})和(5,{e,d}),则
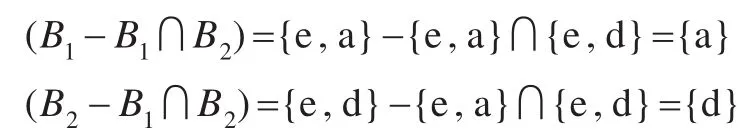
因此该结点的规则为ad=>e。
(3)如果结点 C(X,B)有 n 个双亲结点 C1(X1,B1),C2(X2,B2),…,Cn(Xn,Bn),则对于∀p∈(B-B1∪B2∪…∪Bn),存在蕴含规则为 p=>B-p。
(4)前面三种方法产生的关联规则都是概念格结点与其双亲结点间的联系,置信度全部是1。但概念格结点内涵里也有可能存在强关联规则,需要进一步计算。例如对于图4中第三层的最后一个结点(3,{e,d,f}),有|X|/|X1|=3/5=0.6,所以存在强关联规则df=>e,且置信度为0.6。
根据上述算法依次计算各结点产生的关联规则,最终由图4所示的量化概念格得到的关联规则如表6所示。
3.3 结果分析
由上述分析可知,根据量化概念格的Hasse图,能够非常容易获得各个频繁项目集,相比Apriori算法更加简捷直观。比较表5和表6的数据,可以看到,通过量化概念格的挖掘得到了20条关联规则,与Apriori算法相比减少了6个规则,但是这6条规则均可由已经产生的规则推倒得到,基于概念格的关联规则挖掘只需扫描一次概念格结点就能生成规则,经典的Apriori算法则需要多次扫描事物数据库,效率较低。因此,该算法在结果和效率上都比Apriori算法更优。
对于表6中的数据进行分析,例如选取规则bc=>def,表示班次和工序次序会对库存数量、缺货率和核对完工数的影响程度为100%,即会产生比较重要的影响。这与人们的直观认识也比较近似,班次、工序次序等安排合理,库存数量、缺货率和核对完工数才能达标。另外选取规则ac=>def,规则的置信度为83.1%,说明生产线、工序次序会影响最后的库存数量、缺货率和核对完工数。因此,在只考虑生产线、班次、工序次序、库存数量、缺货率和核对完工数属性,不考虑其他各种具体复杂影响因素的情况下,必须合理安排生产线、班次、工序次序等信息,才能较好地完成工作量。例如,对于产品序号为T074的零件,给定一定生产计划量:把计划量分为6个阶段,分别以字母顺序进行排序,表示为{A:(0~199)件,B:(200~399)件,C:(400~599)件,D:(600~799)件,E:(800~999)件,F:(1000件及以上)},同理,将库存数量表示为:{A:(0~99)件,B:(100~199)件,C:(200~299)件,D:(300件及以上)},为了保证缺货率和核对完工数都完全达标,针对本文中分析的6个属性,可得到如表7所示的生产计划排产情况。

表6 基于量化概念格的关联规则
本文只选取了部分数据来说明问题,阐述了该方案的可行性,对于实际应用中的更多数据,也能采用同样的分析方法,通过概念格理论构造量化概念格,然后从量化概念格中挖掘关联规则。对关联规则和支持度、置信度逐一进行分析,明显发现其中隐藏的、人们感兴趣的、对生产调度有用的信息,然后为管理人员作出排产计划提供理论依据,从而指导人们进行生产,达到优化排产、提高生产效率的目的。

表7 生产计划排产表
4 结论
根据汽车冲压厂生产数据特点和需求分析,为了优化排产和解决生产数据量巨大的问题,提出了适合于冲压厂实际情况的基于概念格的关联规则挖掘算法。根据企业计划,在总体上实现优化排产、改善企业整体管理水平、提高企业业绩的目的。首先利用Apriori算法得到关联规则,然后重点研究了基于概念格的关联规则在汽车排产管理的应用,通过对比分析可知,采用量化概念格,比Apriori算法更加简捷、直观、高效,并且易于理解,能有效实现规则的可视化。但是本文只是研究了基于概念格的关联规则在汽车厂排产管理上的应用,讨论了数据挖掘中的关联规则技术,在以后的工作中,将深入研究概念格在其他问题上的应用,为更多的数据挖掘提供理论方法和现实依据。
[1]中国统计网.Sybase数据分析与管理技术之四大法宝[EB/OL].(2012-02-05).http://www.itongji.cn/news/0205MR012.html.
[2]Michael J A B,Linoff G S.数据挖掘[M].袁卫,译.北京:中国劳动社会保障出版社,2004.
[3]胡可云,田凤占,黄厚宽.数据挖掘理论与应用[M].北京:清华大学出版社,北京交通大学出版社,2008.
[4]文拯.关联规则算法的研究[D].长沙:中南大学,2009.
[5]高飞.关联规则挖掘算法研究[D].西安:西安电子科技大学,2001.
[6]何超,程学旗,郭嘉丰.面向分面导航的层次概念格模型及挖掘算法[J].计算机学报,2011,34(9):1589-1602.
[7]毕强,滕广青.国外形式概念分析与概念格理论应用研究的前沿进展及热点研究[J].现代图书情报技术,2010,26(11):17-23.
[8]潘燕.数据挖掘在汽车销售企业CRM中的应用[J].计算机时代,2011(11):35-36.
[9]Adomavicius G,Tuzhilin A.Using data mining methods to build customer profiles[J].Computer,2001,34(2):74-82.
[10]Chen Ming-Syan,Han Jiawei,Yu P S.Data mining:an overview from a database perspective[J].IEEE Transactions on Knowledge and Data Engineering,1996,8(6):866-883.
[11]Ngai E W T,Xiu L,Chau D C K.Application of data mining techniques in customer relationship management:a literature review and classification[J].Expert Systems with Applications,2009,36(2):2592-2602.
[12]Qu K S,Liang J Y,Wang J H,et al.The algebraic properties of concept lattice[J].Journal of Systems Science and Information,2004,2(2):271-277.
[13]Eklund P,Villerd J.A survey of hybrid representations of concept lattices in conceptual knowledge processing[C]//Lecture Notes in Computer Science,2010,5986:296-311.
[14]毕建新.基于APS的企业生产线调度系统设计与实现[D].沈阳:东北大学,2011.
[15]滕广青,董立丽,田依林,等.基于概念格的社区用户知识需求模型研究[J].情报科学,2013,29(1):108-122.
[16]胡立华,张继福,张素兰.一种基于剪枝的横向分块概念格构造算法[J].小型微型计算机系统,2011,32(7):1394-1399.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
数学物理学报(2018年1期)2018-03-26
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年12期)2014-02-27
网络安全与数据管理(2010年1期)2010-05-18
苏州市职业大学学报(2010年1期)2010-01-29
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
