
基于Hilbert-Huang算法的缺时检测问题的研究
2013-11-01 07:17李忠海王文龙
沈阳师范大学学报(自然科学版) 2013年1期
张 华,李忠海,王文龙,赵 义
(1.沈阳师范大学 教师专业发展学院,沈阳 110034;2.沈阳航空航天大学 自动化学院,沈阳 110136;3.辽宁省语言文字应用中心,沈阳 110136)
0 引 言
普通话水平测试的第四项测试内容为命题说话,在命题说话评分中有一重要评分项是缺时,这里的缺时是指应试人说话时间不足3分钟。对测试中应试人说话不足3分钟的,国家普通话水平测试大纲有明确、严格的规定:“说话不足3分钟,酌情扣分。缺时1分钟以内(含1分钟),扣1分、2分、3分;缺时1分钟以上,扣4分、5分、6分;说话不满30秒(含30秒),本项测试成绩为0分。”在普通话水平测试中应试人说话出现的语音空白间隔5秒以上就被认定是缺时,测试中应试人说话出现的语音空白间隔在5秒钟以内(含5秒),归自然流畅程度扣分。缺时是对这一部分评分的重要依据。目前虽然计算机评测系统有自动统计缺时时长的功能,但由于一些应试人在普通话水平测试中充分利用无效语料“嗯”“啊”等一些技术手段来混淆视听,从而使计算机在自动统计缺时时长时出现了误差,影响了测试信度。另一种情况是,采用测试员用秒表评判应试人的缺时数据以避免计算机评测误差,但有些测试员对缺时评判不认真,而出现错判和误判现象。因此对应试人语音信号进行端点检测来判定缺时信息的研究很有必要。
为了能准确快速的判定应试者的缺时信息,直接方法是在时域或频域上进行语音信号的端点检测。李金宝等[1]人提出了一种自适应子带谱熵(adaptive subband power spectral entropy,ASPSE)它能成功地在不同的背景噪声下检测语音端点。韩志艳等[2]人提出了一种利用短时能零积法和鉴别信息的互补优势,一边降噪一边端点检测,利用子带能量鉴别信息方法对噪声帧来进行二次复检,根据鉴别信息来更新噪声能量门限的端点检测方法。刘红星等[3]人提出了一种在窄带语谱图上通过sobel算子计算窄带语谱图的方向场,通过Gabor滤波增强谐波区域,求取谐波分布区域内的能量,以此作为门限判决的特征。李晋等[4]人提出用一种改进的基于谱减法和自适应子带谱熵的语音端点检测方法来提高低信噪比下语音端点检测的性能。王秀坤等[5]人提出一种引入自适应门限的基于基音频率的检测算法。顾亚强等[6]人提出了一种新的利用对短时能零和过零率进行差分的方法来求取语音的起始点,达到了语音端点检测的目的。谈雪丹等[7]人提出了一种基于Hilbert-Huang变换瞬时能频值的耳语音端点检测的算法。龚英姬等[8]人提出用HHT(Hilbert-Huang)变换提取的瞬时能量(A)和瞬时频率(f)的标准差参数描述病态噪音,实验结果表明此方法能有效区分病态噪音和正常噪音。
本文从另外一个角度来考虑语音信号缺时的检测,将语音信号划分成若干小段,对每一段进行Hilbert-Huang变换,求出每个IMF分量的瞬时幅值和瞬时频率,利用瞬时幅值和瞬时频率求取该IMF分量的能频值,利用该段的所有IMF分量的能频值构造其能频值特征向量。将待测信号与静音样本的能频值特征向量相比较求取欧氏距离,根据欧氏距离与阈值的大小来判定该段是否为静音段。根据相邻静音段的拼接最大时间长度是否大于5s来判定是否缺时,通过语音段的前后段的属性来判定该段是否为噪声段,消除噪声段,最后得到完整的缺时信息。
1 基于Hilbert-Huang变换语音信号缺时的分析方法
目前理论研究和实验都支持语音信号是一个复杂非线性过程的观点,因此,引入非线性方法适宜对具有非线性特征的语音信号进行分析。Hilbert-Huang变换因其具有良好的时频聚集性和极高的时频分辨率而非常适于处理非线性、非平稳信号,该方法首先采用EMD(empirical mode decomposition,经验模式分解)方法将信号分解为若干IMF(intrinsic mode function,固有模态函数)分量之和,然后对每个IMF分量进行Hilbert变换得到瞬时频率和瞬时幅值。
1.1 基于Hilbert-Huang变换语音信号特征提取步骤
1)对于语音信号x(t)进行EMD分解
对于信号x(t)EMD分解按如下步骤进行:
使用三次样条线将原始信号x(t)的所有局部极大值点连接起来形成上包络线,再以相同方法求出信号的下包络线,上、下包络线应该包络所有的数据点。将上、下包络线的平均值记为m1,求出h1。

判断h1是否满足IMF条件,如果满足则将h1作为EMD分解的第1个IMF分量,否则将h1作为原始信号按式(1)重复计算,直至得到满足条件的IMF分量。并将此第1个IMF分量记为c1。将c1从x(t)中分离,得到

将r1作为原始数据重复式(1)、(2)得出信号的第2个IMF分量c2。循环EMD分解步骤,有

当残余函数rn成为单调函数无法继续提取满足条件的IMF分量时,循环结束,得到

2)求IMF分量的瞬时幅值和瞬时频率
为求IMF分量的瞬时频率,对式(3)中的每个内禀模态函数ci(t)作Hilbert变换得到
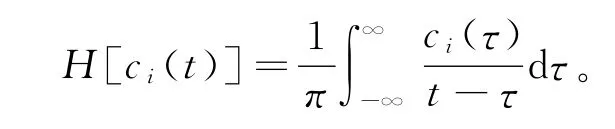
构造解析信号
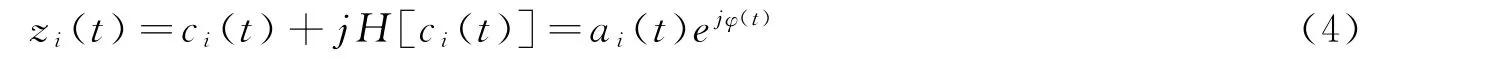
其中ai(t)为瞬时幅值,由式(4)能得到相位函数
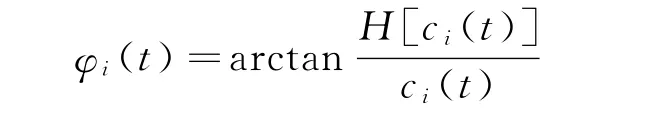
进一步求得IMF分量的瞬时频率
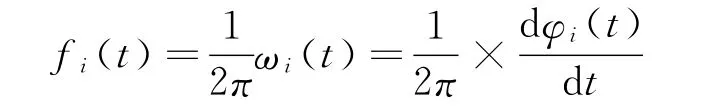
3)求取能频值及能频值特征向量
由于语音在不同频段上所占能量不同,将语音分解得到的IMF分量大致可以分为两个频段,一个是含有语音大部分信息的中高频段,一个以低频噪声能量为主的低频段。因此可以利用这一特性构造语音的特征向量,有声音的语音信号的特征向量和静音信号的特征向量会有很大的区别。定义某一IMF分量的Hilbert变换后的所有瞬时幅值的平方和相应频率之积称为该IMF分量的能频值。定义第i个IMF分量的能频值为
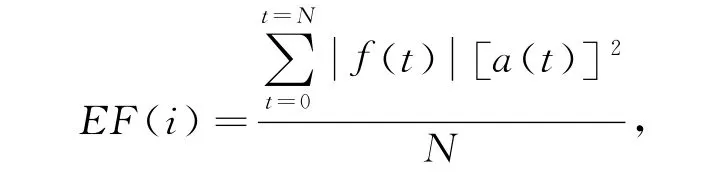
其中N为采样频率,将某一段语音信号经Hilbert-Huang变换得到的所有m个IMF的能频值组成的向量T=(EF1,EF2,…,EFm)称为该语音段的能频特征向量。
1.2 缺时检测步骤
基于上面构造的语音信号的能频值及能频值特征向量,设计基于Hilbert-Huang变换的普通话缺时检测步骤如下。
1)提取静音特征
截取一段静音数据,利用Hilbert-Huang变换将静音信号分解得到IMF分量,然后计算每个IMF分量的平均能频值,并将这些平均能频值组成特征向量,作为普通话水平测试语音信号缺时检测的对比样本特征向量。
2)计算每个窗的能频值
将待检测的语音信号分割成以1秒为长度的小段语音信号帧,即对语音信号加窗。然后对每段语音信号帧进行EMD分解,得到IMF分量,并利用Hilbert-Huang变换得到每个IMF分量的平均能频值,并将这段语音的所有IMF分量的平均能频值组成该段的平均能频值特征向量。
3)对比特征向量
根据步骤2)求得的每段的能频值特征向量,并将该特征向量与步骤1)中的样本特征向量相比较,求二者之间的欧氏距离,并将欧氏距离与设定的阈值相比较,若所得的欧氏距离大于阈值,则认为该段语音为非静音帧,将该帧的真值记为1,否则将该帧的真值记为0,将每帧的真值按时间顺序组成能频真值序列。
4)查找缺时序列
在真值序列上,查找真值连续为0的个数大于等于5(由于每段长1秒,因此大于等于5就可以判定为缺时)的序列段,称这样的序列段为缺时段,并记录缺时序列段在真值序列上的起止位置。
5)消除噪声窗
在真值序列上,查找真值单独为1的段,即该段前后段的真值均为0,称这样的段称为疑似噪声段,并记录该段在能频真值序列上的位置。
判定疑似噪声段的前后是否是为缺时序列段,若噪声段前后均为缺时段或其中之一为缺时段时,则疑似噪声段为真实噪声段,并消除该段,连接前后的静音段组成新的缺时段。
2 实验分析
为了验证本文算法,首先对一个样本静音信号进行EMD分解得到得到13个IMF分量,然后对每个IMF分量进行Hilbert变换,最后利用本文构造特征向量的方法构造静音样本特征向量。如图1所示为静音样本的原始信号和其每个IMF分量的能频值。为了和静音样本信号对比,本文选取了一段语音信号,按照和静音信号同样的处理方法得到如图2所示的结果。从图1和图2所示的结果可知,静音信号的所有IMF分量的能频值都比较小,而语音信号的低级IMF分量的能频值较大,因此二者的能频值特征向量之间的欧氏距离会比较大。

图1 静音信号的能频值
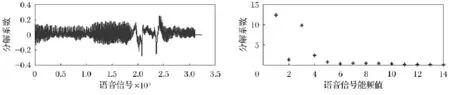
图2 语音信号的能频值
本文采用长度为3分钟的实际的普通话测试录音,在Matlab环境下以采样频率16 000对其采样读取,以1秒为长度分割该信号,然后利用Hilbert-Huang变换对每一段进行EMD分解得到IMF分量,然后对每个IMF分量进行Hilbert变换求取瞬时幅值和频率,再利用本文构造特征向量的方法构造每个1秒语音信号的特征向量,并将这些特征向量分别与静音样本特征向量相比较。确定每1秒长的信号是静音信号还是语音信号,最后利用算法的4、5步确定缺时序列。最后的检测结果如图3所示,这个检测结果不但与实时相符,而且很好的消除了部分强噪音的影响,如在检测结果的第三段缺时中就把强噪音滤去了。

图3 缺时检测结果
为了体现本文算法在普通话测试缺时检测中的优点,本文选择100个普通话测试者的录音作为样本,样本经人工检测出的缺时数目为348个。分别用本文的算法和端点检测算法对这100个样本进行缺时检测,得出如表1的统计结果。其中的检出率为检测出的缺时个数与真实的缺时个数之比,正确率为该算法正确检测出的缺时个数与检测出的缺时个数之比。由表1中的数据可知,本文算法在正确检出缺时数据上有一定的优势。

表1 样本统计结果
3 结 语
本文以普通话测试中说话部分的缺时检测为背景,以Hilbert-Huang变换为基本方法,构造语音段的能频特征作为静音识别手段,将普通话测试录音分成有很多静音段和语音段的组成,然后通过对缺时段和噪声段的识别,消除噪声段,最后留下完整的缺时段。该方法新颖独特,能够有效识别普通话测试中的缺时信息,并且能消除一些短时噪音的干扰。但由于Hilbert-Huang变换计算的复杂性,因此该方法比较消耗时间。
[1]李金宝,屈百达,徐宝国,等.基于自适应子带功率谱熵的语音端点检测算法[J].计算机工程与应用,2007,43(12):57-58.
[2]韩志艳,王旭,王健.基于短时能零积和鉴别信息的语音端点检测[J].东北大学学报:自然科学版,2009,30(12):1690-1693.
[3]刘红星,戴蓓,陆伟.基于共振峰谐波能量的语音端点检测[J].清华大学学报:自然科学版,2008,48(增刊1):754-759.
[4]李晋,刘甫,王玲,等.改进的语音端点检测技术[J].计算机工程与应用,2009,45(24):133-135.
[5]王秀坤,李宁,魏燚潍,等.一种基于基音频率的实时性端点检测方法[J].微计算机信息,2009,25(2-1):250-251.
[6]顾亚强,赵晖,吴波.一种语音信号端点检测的改进方法[J].计算机仿真,2010,27(5):340-343.
[7]谈雪丹,顾济华,赵鹤鸣,等.基于HHT瞬时能频值的耳语音端点检测[J].计算机工程与应用,2010,46(29):147-150.
[8]龚英姬,胡维平.基于 HHT变换的病态嗓音特征提取及识别研究[J].计算机工程与应,2007,43(34):217-219.
[9]钟佑明,秦树人,汤宝平.一种振动信号新变换法的研究[J].振动工程学报,2002(6):233-238.
[10]罗进文,胡正伟,蒋占军,等.窄带音频信号时差估计算法[J].计算机应用,2011,31(3):23-30.
[11]颜彪,杨娟.关于希尔伯特变换的分析和研究[J].电气电子教学学报,2004(5):10-15.
[12]胡正伟,王喆.射频窄带信号时差估计算法研究[J].数据通信,2010(4):21-24.
[13]宋牟平,赵斌.希尔伯特变换处理的布里渊散射DOFS的研究[J].光子学报,2005,34(9):1328-1331.
[14]王珂,肖鹏峰.基于二维希尔伯特变换的相位一致模型图像特征检测方法[J].测绘学报,2010,39(6):605-609.
[15]王凤鹏,邹万芳,尹真,等.希尔伯特变换实时全息干涉条纹相位提取[J].光电工程,2009(4):92-96.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
数学物理学报(2022年2期)2022-04-26
保定学院学报(2022年2期)2022-04-07
橡胶科技(2022年11期)2022-03-01
石油沥青(2021年3期)2021-08-05
电脑报(2020年50期)2020-03-10
中学生数理化·教与学(2019年8期)2019-09-18
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
数学物理学报(2017年1期)2017-06-05
