
改进的SIFT特征人脸识别方法ADSIFT
2013-09-24 07:57:58闫敬文
汕头大学学报(自然科学版) 2013年2期
林 哲,闫敬文
(1.汕头职业技术学院计算机系,广东 汕头 515078;2.汕头大学工学院电子工程系,广东 汕头 515063)
0 引言
人脸识别技术是指根据人脸图像确定人物的身份的技术,在视频监控、视频会议、照片检索、身份认证等多个领域有重要的应用价值.但是,除了与物体识别[1]、手势识别[2]等图像识别问题一样要面对光影、噪声的影响之外,人脸识别还具有特殊的困难之处.首先,由于脸部肌肉的运动使脸部的弹性变化很大,有喜怒哀乐的表情,这些都会导致脸部形象发生变化,比如,笑的时候会眯上眼睛或张大嘴巴,怒的时候会瞪大眼睛;其次,人脸是一个复杂的三维表面,五官等重要特征分布在人脸正面和两侧,因此,不同的摄像角度和姿态会使人脸的透视效果产生很大差异;再次,发型,眼镜、络腮胡须等也都可能对脸部形象造成不同程度的改变;最后,遮挡、光照也是影响人脸识别的主要因素.
当前,人脸识别的基本方法是从人脸图像中提取出特征然后与已知人脸样本的特征进行匹配.现有的研究基于不同特征提出了很多种人脸识别方法,例如2DPCA[3]、Local Probabilistic Subspace[4]、SOM face[5]、S2DPCA[6]、U2DDLPP[7]、KPCA+CNPE[8]、WV2PCA[9]、Radon变换[10]、拉普拉斯平滑变换[11]、AIC[12]等.
David G.Lowe[13]在2004年提出的SIFT(scale invariant feature transform)特征是一种能够对尺度空间、图像缩放、旋转等仿射变换保持不变的图像局部特征,对噪声也能够保持一定程度的稳定性.SIFT特征在物体识别[1]、手势识别[2]、图像匹配[14]、图像拼接[15]、图像检索[16]、人脸识别[17,18]等领域都有成功应用.
文献[1]将SIFT特征用于从足球比赛图像中识别出足球,先利用霍夫变换从图像中检测并分割出圆形物体,然后从每个被检测出的圆形物体图像中提取出SIFT特征集合,再与存储足球图像SIFT特征的数据库进行匹配,从而判定是否为足球.文献[2]将SIFT特征用于人机交互中的手势识别,可以识别"六"、"手掌"、"拳头"三种具体手势.先从训练图像中提取出SIFT特征,利用每个SIFT特征构造一个弱分类器,再使用Adaboost选出一部分弱分类器联合成强分类器,总共构造了四个强分类器,一个用于识别图像中是否有手势,另外三个分别用于识别三种具体手势.在每个强分类器中,计算每个被选出的弱分类器的SIFT特征与目标图像的欧氏距离,当距离小于弱分类器阈值时,就将该弱分类器的权重累加,最后以权重累加值是否超过强分类器阈值作为最终分类依据.
SIFT特征的主要缺点是计算复杂性高,而且每个SIFT特征向量长达128维.本文针对光照、表情、噪声等因素容易造成误识别的问题,将文献[2]方法进行改进并用于人脸识别,提出一种改进的基于Adaboost和SIFT特征的ADSIFT人脸识别方法.实验表明该方法在ORL人脸数据库上可达到98%识别率,优于文献[6-9]的方法.
2 基于SIFT特征的人脸识别
文献[17]利用SIFT特征向量来衡量人脸图像的相似性.先从人脸图像中分割出五官所在的六个子区域,把每个子区域图像的相似度定义为SIFT特征向量的最大相似度,再综合六个子区域的相似度得到总体相似度.但由于表情的影响,眼睛、嘴巴的形态会发生很大变化,容易造成该子区域的SIFT特征向量集合不稳定而导致误匹配;另一方面,由于角度的影响,某一侧的眼睛或耳朵子区域也可能没有出现在人脸图像中,从而影响该方法的适用性.
文献[18]也是从人脸图像中分割出若干子区域,但不是根据五官所在位置进行自然划分,而是通过K-means方法将人脸图像所有SIFT特征向量进行聚类,据此将人脸图像分割为若干子区域,而不再受到五官位置的约束,具有更好的灵活性.但由于这种子区域划分方法是以SIFT特征向量这种局部特征为依据,因而对表情、光照的变化非常敏感,使子区域的划分结果有很大不确定性,容易造成不同脸部子区域的误匹配.
每个人的脸部图像都有一些与众不同的特征,借助于SIFT特征的尺度不变性和旋转不变性,从脸部图像提取得到的SIFT特征向量可以在尺度、角度甚至表情有变化的情况下仍保持一定稳定.但实际上从同一个人的不同脸部图像提取得到的SIFT特征向量集合却有很大差异,这是因为光照、噪声、夸张表情等因素可能破坏某些重要的SIFT特征向量或者带来额外的SIFT特征向量,这些SIFT特征向量是无法反映脸部特征的,让所有SIFT特征向量都参与计算反而会对准确衡量脸部图像相似度造成干扰.因此,必须从人脸图像的SIFT特征向量集合中选出那些最稳定的SIFT特征向量作为衡量相似度的依据.
2.1 SIFT特征
2.1.1 SIFT特征的提取
David G.Lowe提出的SIFT特征提取算法[13],先通过检测尺度空间极值点构造出不同尺度的高斯差分核与图像卷积生成高斯差分尺度空间(DOG scale-space),如图1所示;再在所有检测点中选出那些在尺度空间和二维图像空间同时取得极大值或极小值的检测点作为关键点,计算出每个关键点梯度模值和梯度方向;最后,将坐标轴旋转为关键点的方向,然后以关键点为中心取16X16的窗口,分割为16个4X4的子窗口,在每个子窗口内计算8个方向的梯度累加值,最后得到128个数据,形成128维的SIFT特征向量.
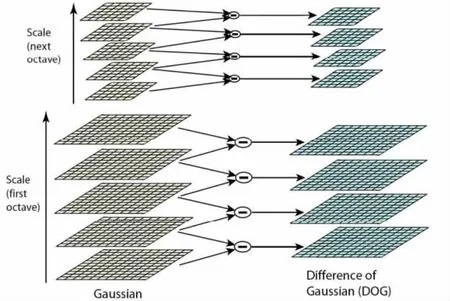
图1 在不同尺度下生成高斯差分尺度空间[13]
2.1.2 从人脸图像提取SIFT特征向量
用SIFT算法,从每副人脸图像提取得到SIFT特征向量集合,结果如图2所示,其中每个SIFT特征向量用箭头标出,箭头的起点和方向分别表示SIFT特征向量的位置和方向.

图2 从人脸图像提取得到SIFT特征向量
2.2构造人脸图像相似度函数的算法
对每个训练图像m,SIFTm表示提取得到的SIFT特征向量集合,本文在文献[2]方法的基础上进行了改进,利用一种基于Adaboost的算法从SIFTm中选出子集,并为子集中每个SIFT特征向量分配阈值和权重,然后用于构造相似度函数.
Adaboost是一种优秀的分类算法,其基本思想是利用多个弱分类器联合形成强分类器,要求每个被选出的弱分类器必须至少优于随机猜测.Adaboost算法由循环构成,每轮循环将根据正、反训练样本及其权重,从弱分类器集合中选出一个最好的弱分类器,使之具有最小的错误率,然后重新调整正、反样本的权重,增加那些被正确分类的训练样本的权重,减少那些被错误分类的训练样本的权重,使Adaboost算法在下一轮循环中更关注那些被错误分类的训练样本.循环过程持续到选出足够数量的弱分类器或者剩余弱分类器的错误率都大于0.5为止.最后得到的强分类器由那些被选出来的弱分类器的代数和组成.
为了构造人脸图像的相似度函数,令
Q={(SIFT1,l1),(SIFT2,l2),…,(SIFTm,lm),},其中SIFTm表示训练图像m的SIFT特征向量集合,lm表示训练图像m的类别.Bm=(→p,θp,αp)→p∈SIFTm),其中 θp和 αp分别表示SIFT特征向量对应的阈值和权重.
对训练图像m,构造相似度函数Sm(x)的算法如下所述:
(1)为每个样本(SIFTu,lu)∈Q-({SIFTm,lm)}分配一个初始权重
(2)利用每个→p∈SIFTm并选择阈值θp可定义一个分类器:
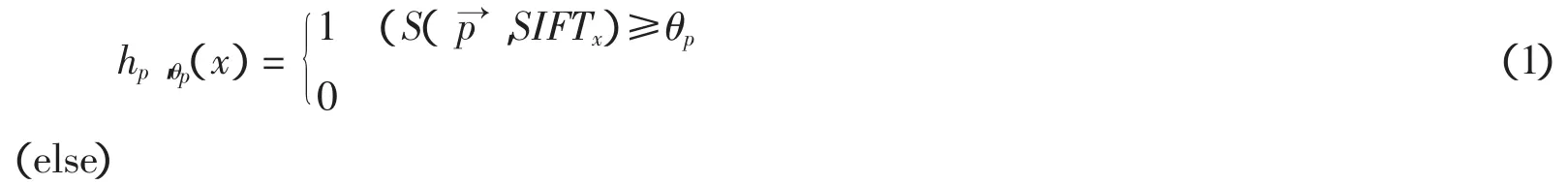
该分类器称为弱分类器,它对所有(SIFTu,lu)∈Q-{(SIFTm,lm)}进行分类,错误率为:
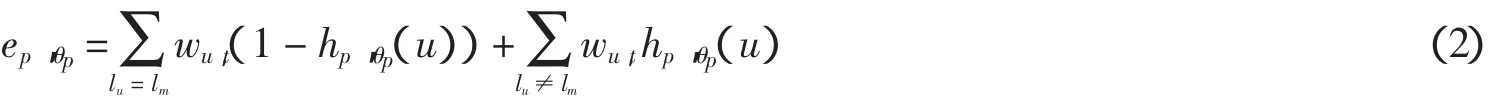
调整 θp,使 hp,θp(x)的错误率最小,记 ep=min({ep,θpθp∈[0,1]})
(3)得到弱分类器集合{hp,θp(x)→p∈SIFTm}后,从中选出一个错误率最低的弱分类器,即选出ht,θt(x)满足et=min({ep→p∈SIFTm}.若et≥0.5,说明当前最好的弱分类器的效果并不优于随机猜测,因此不再挑选弱分类器,跳转到第(5)步.若et<0.5,则令其中αt就是该弱分类器的权重.可以看出,错误率越低的弱分类器,其对应的SIFT特征向量的区分能力越强,因而将得到更大的权重.
(4)根据最佳弱分类器的分类结果调整每个训练样本的权重.被ht,θt(x)正确分类的样本,调整其权重由于βt<1,相当于增加了被ht,θt(x)错误分类的样本的权重.
(5)标准化权重集合{w},使之成为概率分布.
重复上述第(2)-(5)步,直至选出尽快多弱分类器.
(6)利用被选出的弱分类器构造相似度函数.
首先,两个SIFT特征向量→p和→q的相似度定义为它们的内积:


接下来,利用弱分类器所对应的SIFT特征向量和阈值、权重来构造训练图像m的相似度函数:
而SIFT特征向量→p与SIFT特征向量集合Λ的相似度定义为:

可以看出,与文献[2]方法不同的是,本文并非直接利用弱分类器的代数和作为强分类器,而是利用弱分类器所对应的SIFT特征向量和阈值、权重来构造相似度函数,每个相似度函数将用于衡量特定训练图像的SIFT特征向量集与目标图像SIFT特征向量集的相似度.
上述算法用伪代码描述如下:

对每个→p∈SIFTm,选择最佳阈值θp构造弱分类器hp,θp(x),使其对所有(SIFTu,lu)∈Q-

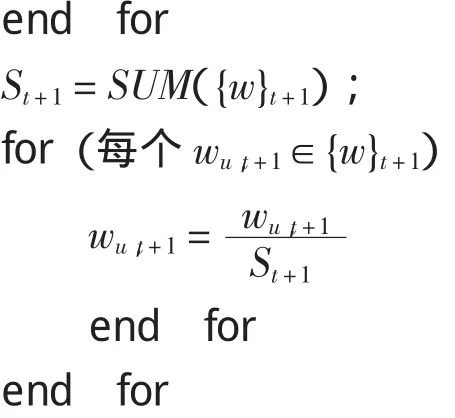
根据公式(5),由Bm构造人脸图像的相似度函数Sm(x)

2.3 使用相似度函数识别目标图像的算法
构造出每个训练图像的相似度函数之后,就可以分别计算目标图像x与每个训练图像的相似度,相似度越高说明两张人脸图像属于同一个人的概率越大,从而求出目标图像x与每个类的训练图像的平均相似度,则目标图像应属于平均相似度最高的类.上述算法用伪代码描述如下:
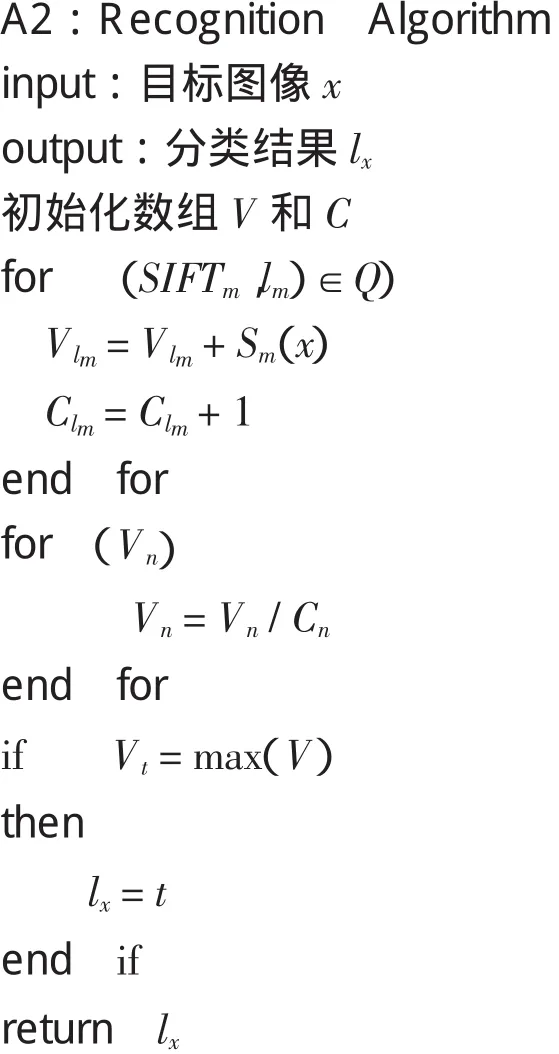
3 仿真实验与讨论
3.1 实验结果
为了测试ADSIFT方法的识别效果,在Matlab7.0中实现了算法A1和A2,并在ORL人脸库上进行识别实验.ORL人脸库中包含40个不同身份的人,每个人有10张图像,表情、转角有变化,如图3所示.

图3 ORL人脸库
每次实验过程分为四个阶段:
(1)利用David G.Lowe[13]提供的SIFT算法从每个图像提取出SIFT特征向量集合.
(2)用算法A1对训练图像进行学习,得到的学习结果记录了从每个训练图像的SIFT特征向量集合选出来的SIFT特征向量及其对应的阈值和权重.
(3)用算法A2对每个测试图像进行识别.
(4)统计识别率.识别率的定义如下:
实验结果如表1所示,可见识别率高达98%.

表1 ORL人脸库识别率
将ADSIFT方法的识别率与文献[6-9]提出的方法对比,如表2所示,可见ADSIFT方法的识别率优于文献[6-9]的方法,
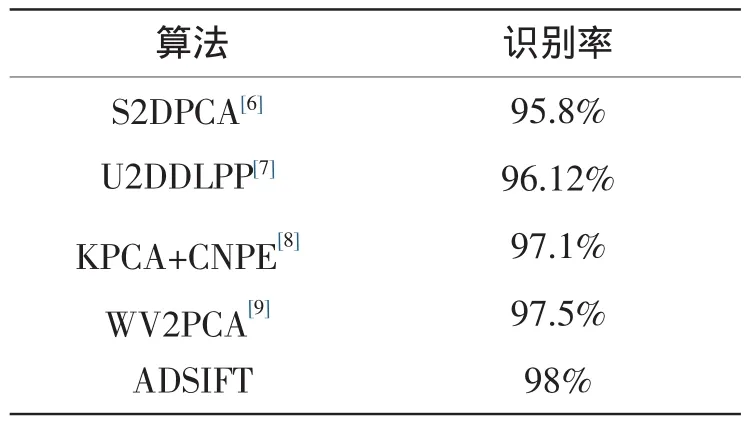
表2 ORL人脸库识别率对比
3.2讨论
实验结果证明了ADSIFT方法的有效性,该方法具有很高的识别率,其原因主要有两个方面.首先,SIFT特征本身具有良好的尺度不变性和旋转不变性,因此,当人脸图像在尺度、角度方面发生变化时,SIFT特征能保持稳定,为准确识别提供了重要条件,解决了尺度变化、角度变化这两个影响识别率的因素.其次,SIFT特征是一种局部特征,提取的是人脸局部区域的特点,因此,当人脸有局部遮挡时(如戴眼镜、帽子等),未被遮挡区域的SIFT特征完全不受遮挡的影响,从而解决了遮挡这个影响识别率的因素;而当人脸表情发生变化时,人脸因受到表情肌肉的拉动而发生一定的弹性变化,但主要集中在表情肌肉丰富的眼睛周围、嘴巴周围和两边脸颊等区域,其他一些区域(如额头、眼睛内部、鼻子、耳朵等)并不会有明显变化,其局部特征也会保持相对稳定.此时,算法A1发挥了挑选稳定特征的重要作用,从人脸图像中收集稳定特征并根据其稳定程度分别精确赋予权重,能更好地解决表情这个影响识别率的因素.
事实上,如果考虑文献[18]中划分人脸子区域时的一种特殊情况,将每个SIFT特征向量的位置作为初始聚类中心,则人脸图像将被划分为n个子区域(n等于SIFT特征向量的数量),每个子区域中包含1个SIFT特征向量.同时将文献 [18]定义的局部相
似度计算公式SL(It,Ir)视为图像Ir的函数FIt(Ir).容易看出,此时FIt(Ir)就是本文公式(3)定义的相似度函数SIt(Ir).
因此,本文的算法A1实际上是将训练图像划分成更多子区域,使每个子区域只包含一个SIFT特征向量,然后再从子区域集合中剔除那些与同类图像相似度过低的子区域,只保留那些与同类图像的相似度大于或等于阈值的子区域来构造相似度函数,这与文献[18]在计算局部子区域相似度时采用阈值是一致的.
比文献[18]更进一步的是,在本文中每个子区域都通过算法A1分别得到一个独立的精确阈值,而不是统一采用0.7作为阈值,因此更能抓住每个具体训练图像的独特之处快速进行相似度比较,既降低了计算复杂度,又增强了鲁棒性.
4 结论和展望
本文将Adaboost算法与SIFT算子结合起来用于人脸识别,提出一种改进的SIFT特征人脸识别方法.先利用一种基于Adaboost的算法选出每个训练图像中最有区分能力的SIFT特征向量并确定其阈值和权重,然后构造出每个训练图像的相似度函数并据此计算目标图像的类别.实验证明该方法能够有效提高人脸识别率,在ORL人脸数据库上识别率可达到98%.
但是,由于ADSIFT方法是基于训练图像与测试图像的相似性来识别,因此,识别效果不可避免地受到训练图像多样性的影响,如何选择训练图像才能有效提高识别效果将是进一步要研究的问题.
[1]Leo M T.Orazio D,Spagnolo P,et al.SIFT based ball recognition in soccer images[J].Image and Signal Processing.2008,5099:263-272.
[2]Wang C C,Wang K C. Hand posture recognition using adaboost with SIFT for human robot interaction[J].Lecture Notes in Control and Information Sciences,2008,370:317-329.
[3]Yang J,Zhang D,Frangi A.F,et al.Two-dimensional PCA:A new approach to appearancebased face representation and recognition[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence,2004,26(1):131-137.
[4]Martinez A M.Recognizing imprecisely localized,partially occluded,and expression variant faces from a single sample per class[J].IEEE Trans.on Pattern Analysis and Machine Intelligence 2002,25(6):748-763.
[5]Tan X Y,Chen S C,Zhou Z H.et al.Recognizing partially occluded,expression variant faces from single training image per person with SOM and soft kNN ensemble[J].IEEE Transactions on Neural Networks,2005,16(4):875-886.
[6]曾岳,冯大政.一种基于人脸垂直对称性的变形2DPCA算法[J].计算机工程与科学,2011,33(7):74-79.
[7]曹孝斌,廖海斌,李原.面向酉子空间的二维判别保局投影的人脸识别[J].计算机应用研究,2011,28(9):3569-3571,3575.
[8]卢桂馥,林忠,金忠.基于核化图嵌入的最佳鉴别分析与人脸识别[J].软件学报,2011,22(7):1561-1570.
[9]曾岳,冯大政.一种基于加权变形的2DPCA的人脸特征提取方法[J].电子与信息学报,2011,33(4):769-774.
[10]Jamal A D,Ali C,Ervin M,et al.Radon transform for face recognition[J].Artificial Life and Robotics.2010,15(3):359-362.
[11]Yu W W.Face recognition via adaptive image combination[J].Journal of Shanghai Jiaotong University(Science),2010,15(5):600-603.
[12]Gu S C,Tan Y,He X G.Laplacian smoothing transform for face recognition[J]. Science Chine Information Sciences,2010,53(12):2415-2428.
[13]Lowe D G.Distince image features from scale-invariant keypoints[J].1nternational Journal of Computer Vision,2004,60(2):91-110.
[14]原思聪,刘金颂,张庆阳,等.双目立体视觉中的图像匹配方法研究[J].计算机工程与应用.2008,44(08):75-77.
[15]何敬,李永树,鲁恒,等.基于SIFT特征点的无人机影像拼接方法研究[J].光电工程,2011,38(2):122-126.
[16]吴锐航,李绍滋,邹丰美.基于SIFT特征的图像检索[J].计算机应用研究,2008,25(02):478-481.
[17]周志铭,余松煜,张瑞,等.一种基于SIFT算子的人脸识别方法[J].中国图象图形学报,2008,13(10):1882-1885.
[18]罗佳,实跃祥,段德友.基于SIFT特征的人脸识别方法[J].计算机工程,2010,36(13):173-174.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
作文中学版(2022年1期)2022-04-14 08:00:34
保定学院学报(2022年2期)2022-04-07 02:26:50
学生天地(2020年31期)2020-06-01 02:32:06
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
中国交通信息化(2016年2期)2016-06-06 07:28:02
