
基于篇章上下文的统计机器翻译方法
2013-04-14 07:51:28吕雅娟林守勋
中文信息学报 2013年2期
于 惠,谢 军,熊 皓,吕雅娟,刘 群,林守勋
(中国科学院计算技术研究所智能信息处理重点实验室,北京100190)
1 引言
广泛意义上来讲,统计机器翻译[1]也可以看作是利用规则来翻译的,例如,基于短语的翻译模型[2-4]利用的是短语翻译规则,基于句法的翻译模型[5-7]利用的是句法翻译规则。一般的翻译规则包含源端和目标端,他们可能是词、短语或者是句法树,这依赖于它们所属的模型。通常,一个源端可能对应着多个目标端,由于对齐错误或其他原因其中的一些规则可能是错误的。统计机器翻译的一个主要任务就是对于给定的规则源端选择出正确的目标端,这会直接影响翻译模型的质量。
传统的方法是利用在训练语料中估计的翻译概率来做规则选择,这种方法没有充分利用上下文信息。对于不同的上下文一个词可能有不同的含义。例如,mouse,根据不同的上下文环境可以翻译成“老鼠”或“鼠标”。如表1所示,在文档1的句子1中,mouse的含义是“鼠标”,在文档2的句子1中mouse的含义是“老鼠”,这是根据mouse所在句子的上下文信息判断出来的。在文档3中,仅根据mouse所在的句子2,不能判断出它的含义,但是再加上句子1和句子3的信息,我们就可以判断出它的含义了。同样,要得到正确的翻译结果,解码器也需要当前句子或者周围句子的上下文信息。

表1 mouse在不同上下文的不同含义
本文中我们提出了一种利用整个文档的上下文信息来帮助规则选择的方法,首先我们利用向量空间模型[8-9]建立两个矩阵,一个是训练集的,一个是测试集的。矩阵中的每一行代表一个文档中每一个单词的出现次数(停用词表中的单词和出现次数太少的单词被过滤掉)。然后,利用这两个矩阵生成一个训练集和测试集的相似度矩阵。我们把相似度作为一个新的特征加入到BTG模型[4]中。实验表明,在英语到汉语的翻译工作中,我们的方法可以显著提高翻译质量。
2 相关工作
近年来,很多研究者利用上下文信息来提高机器翻译的质量。文献[4]提出了一种利用边界词信息预测短语重排序的方法,他的工作中把重排序看做分类问题,利用最大熵模型实现。文献[10-11]用上下文信息来帮助目标端规则的选择。他们利用非终结符的边界词信息建立最大熵模型。文献[12]提出了利用功能词选择源端规则的方法。文献[13]利用了相邻词的信息来计算语言模型的值。文献[14]提出了用上下文信息来调序的方法,所用的上下文信息包括源端的词汇化特征(边界词和相邻词),词性标注特征和目标端的词汇化特征(边界词)。也有研究者利用上下文信息来做领域自适应[15]。
这些研究者的方法都利用了一部分上下文信息,但大都利用的是当前跨度内的信息或周围词的信息,并没有利用到整个篇章中的信息。本文中我们提出了一种利用整个篇章信息的方法,实验表明,我们的方法可以显著提高翻译质量。
3 基于篇章上下文的统计机器翻译
3.1 基于VSM的相似度矩阵
VSM是信息检索中运用很广泛的一个模型,近年来,一些研究者也把它用到了统计机器翻译中[16]。在VSM中,每一篇文档表示为一个向量,向量中的每一个元素对应文档中的一个词,如果一个词在文档中出现,那么在向量中对应的就是一个非零的值,否则它对应的值就是零。第j个文档可以用向量Dj表示,Dj=<W1j,W2j,…,Wnj>。其中,Wkj表示第k个词的权重。在计算权重时我们用了TF-IDF(Term Frequency-Inverse Document Frequency)[9]。
TF-IDF是一种统计方法,TF表示一个词在一个文档中的出现次数,当然经常被归一化。第i个词的TF可以表示为是第i个词在第j个文档中的出现次数,分母就表示在第j个文档中所有所有词的出现次数之和。IDF是评价一个词在一个语料中重要性的指标。第i个词的IDF可以表示为:表示一个语料中文档的个数,|d|表示第i个词出现过的文档的个数。这样,tfidfi,j=tfi,j·idfi,利用TF-IDF可以过滤掉常见的词,并且保留重要的词。
在计算两个文档间的相似度时,我们利用了cosine angle[9]。

其中,W1k和W2k分别表示第k个词在文档向量D1和D2中的权重。
本文中,我们用了源端语言的篇章上下文信息,我们用的所有语料都是按照篇章信息分好的文档,每个文档就是一个篇章。首先,扫描训练语料并且记录下其中出现的所有词,去掉停用词后保存在一个向量中,我们称为words-vector。然后建立一个M×H的矩阵A,每个元素的初始值都为0。M是训练语料中文档的个数,H是words-vector的长度。A中的每一行表示一个文档。然后扫描训练语料中每一个文档,如果一个词在此文档中出现过,并且也在words-vector中(即这个词不是停用词),矩阵A中对应元素的值加1,最后我们可以得到包含所有文档上下文信息的矩阵A。
对于测试集,建立一个P×Q的矩阵B。P是测试集中文档的个数,Q是在训练语料或测试语料中出现但不在停用词中出现的词的个数。用与得到A相同的方法得到B。
为了保证从训练语料中得到的文档向量和测试语料中得到的文档向量长度相同,我们扩展矩阵A的列的个数由H到Q,新扩展出的元素的值都为0。在矩阵A和B中分别利用TF-IDF,得到每个词对应的权重。然后用cosine angle对矩阵B的每一行和矩阵A的每一行计算相似度,可以得到相似度矩阵C,矩阵中的每一个元素(i,j)是由矩阵B中的第i行和矩阵A的第j行得到的。在解码过程中,我们会用到这个相似度矩阵。
本报讯 根据湖北三宁化工股份有限公司大修计划节点,11月18日上午9:00尿素厂正式进入大修模式,1#系统停车,12:30置换完成,净化车间1#系统置换较以往不同的是将罗茨机开着置换,这样做旨在节约时间。19日凌晨3:002#系统停车,管理人员全体就位,到现场协调指挥,8:30完成置换,顺利停车,各项检修工作有序进行。
3.2 带有文档ID的规则
我们所用的语料都是带有文档标记的,即每个文档都有一个ID标记,比如1,2,3…在抽规则的同时,记录下每个规则所在的文档的ID。有的规则可能同时出现在几个文档中,这样的规则就有多个ID。比如一条规则表示为:
mouse|||鼠标0.1 0.1 0.1 0.1|||1 3
这个规则中最后的1和3表示它出现在第1个和第3个文档中。
3.3 解码过程
对数线性模型的框架使得我们很容易在解码器中加入新特征,如式(2)所示。

我们的目的是找到概率最大的e,λ代表特征函数,h是特征函数对应的权重,λm(m=1,2,…M)为原有的特征,λsimi为新加入的特征。
我们用的基准系统是基于BTG的解码器。该解码器用的是CKY形式的解码算法。为了利用整个文档的上下文信息,我们把相似度作为一个新的特征加入到基于BTG的解码器中。
对于给定的一个句子S,它所在文档的ID为d。首先,用规则表中的规则初始化chart图。对每个span(i,i),在规则表中可以找到有用的规则Pk(k=1,2,…K),有用规则的个数为K,有用规则指的是源端和span(i,i)一致的规则。我们用IDkt表示规则Rk所在的文档ID,t=1,2,…,T,T是规则Rk所在的文档ID 的个数。相似度特征的分数可以在相似度矩阵C(d,IDkt)中找到,代表矩阵C中第d行,第IDkt列的元素的值。如果T大于1,需要得到一个最终的分数,实验中分别用了它们的最大值和平均值,所以最终的相似度分数可以表示为:

对于span(i,j),i≠j,如果一条规则不能覆盖整个span,为了得到span(i,j)的候选翻译,需要把i,j间的子span进行组合,这时span(i,j)的相似度分数不能直接在相似度矩阵中得到,因为短语表中可能没有对应的规则。我们采用了比较简单的方法,例如,取两个子span相似度特征分数的平均值或最大值。
得到span(i,i)和span(i,j)相似度特征分数都有平均值和最大值两种方式,所以有四种不同的组合方式,可以得到四个解码器,如表2所示。表2中“init”表示解码的初始化过程,此过程中相似度特征的值可以取最大值或平均值;“cat”表示解码时两个span的拼接过程,此过程中相似度特征的值也可以取最大值或平均值。解码器中其他特征的计算和基准系统相同。在CKY解码的最后,我们可以得到整个句子的候选翻译。

表2 不同组合产生的四种解码器
3.4 时间复杂度
计算训练语料中文档和测试语料中文档相似度的时间复杂度是O(M×P×Q)。M是训练语料中文档的个数,P是测试语料中文档的个数,实验中它们的值如表3所示,Q是过滤后训练语料或测试语料中出现的词的个数,实验中其值为40 000。
4 实验
4.1 实验数据
我们的实验是在英语到汉语的翻译工作中做的。双语平行语料包括LDC2003E14,LDC2005T06,还有一部分LDC2004T08,共100万平行句对,用GIZA++做词语对齐,并且使用“grow-diag-final”的启发式方法。语言模型是5元giga语言模型。
我们在HTRDP-MT2005上做的最小错误率训练,测试集使用CWMT2008和NIST2008。翻译质量的评价指标是BLEU-4,测试工具是mtevalv11b.pl。实验中用的语料都是新闻领域的,详细信息如表3所示。

表3 实验中所用语料信息
4.2 实验结果
可以通过BLEU值证明我们方法的有效性,各个系统的结果见表4。在表4中,N表示阈值,即如果一个词在训练语料的每个文档中出现次数不超过N次,就过滤掉这个词。在N为1时,只有BTG_sim_4的结果比较好,对两个测试集分别提高了0.95和1个点。N为2时,只有BTG_sim_3低于基准系统的结果,其他的都高于基准系统。N为3时,几乎所有的结果都低于基准系统的结果。

表4 两个测试集的BLEU值
从这些结果我们可以得出一个结论:如果一个词仅出现了一次或两次,它可能是一个干扰,应该过滤掉,所以N为2时效果最好;如果一个词出现了3次,这个词是有用信息的可能性比较大,应该保留。在N为2时(最好的阈值),BTG_sim_2和BTG_sim_4的效果最好,即解码的过程中初始化和连接相邻span时都取平均值或都取最大值时效果最好。
我们通过两个例子比较一下新解码器和基准系统的翻译结果,见表5和表6,其中的两个句子来自NTST08。
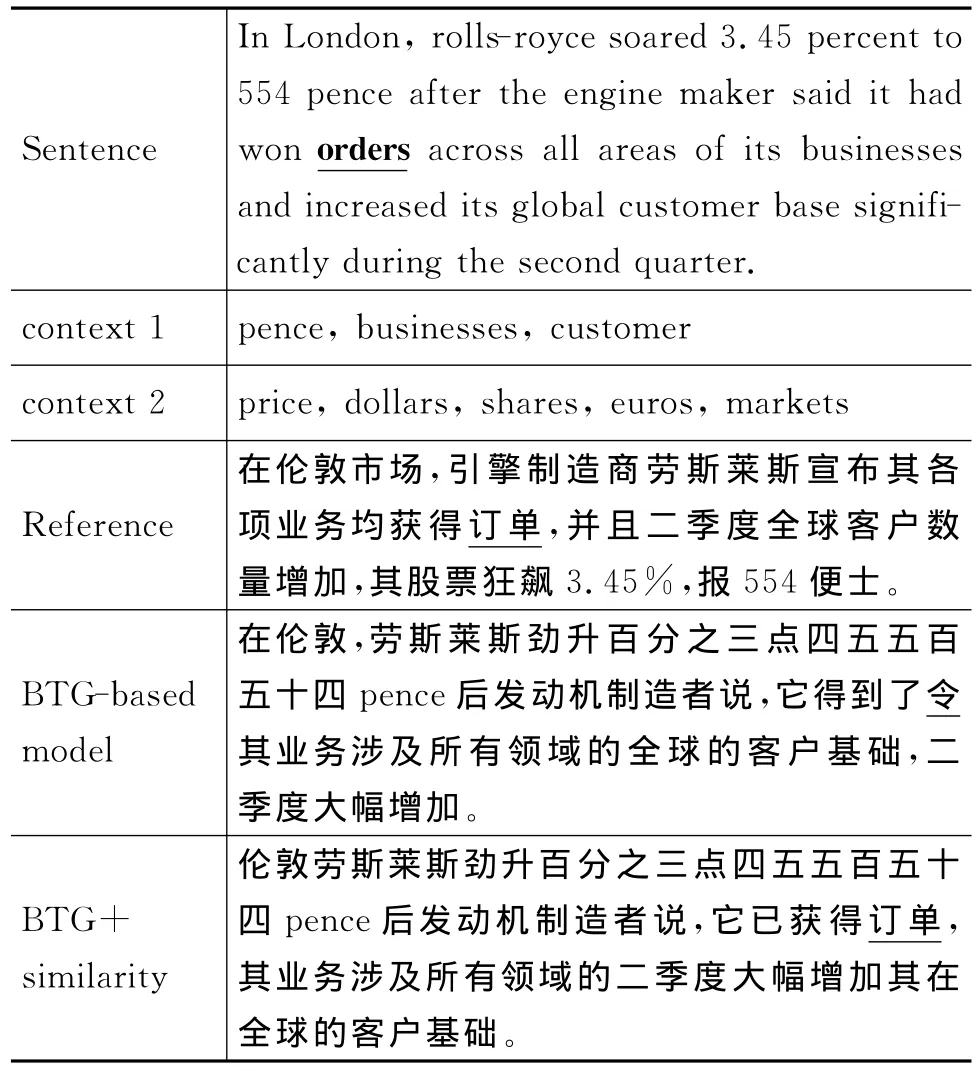
表5 单词orders的翻译结果

表6 单词fans的翻译结果
在表5和表6中,第一行sentence表示词orders和fans所在的句子;第二行context 1表示当前句子中出现的有用的单词;第三行context 2表示当前文档中(除了当前句子)出现的有用的单词,一个文档中有用的单词可能有很多,这里只举了其中几个例子。有用单词指的是对我们关心的单词or-ders和fans的翻译能起到帮助作用的词。第四行reference是第一行sentence的参考译文;第五行BTG-based model是基准系统的翻译结果;第六行BTG+similarity是加入相似度特征的解码器的翻译结果。
在第一个例子中,对于单词orders,基准系统的翻译结果是“令”。在第二个例子中,对于单词fans,基准系统的翻译结果是电风扇。我们可以看出这两个结果是错误的,但是加入相似度后的解码器找到了正确的结果“订单”和“迷”。在当前句子或当前文档中有很多上下文信息,相似度特征就是根据这些上下文信息得到的。通过这两个例子我们可以得出结论,在加入相似度特征后的解码器可以找到正确的规则,从而提高翻译质量。
5 总结和展望
本文中,我们提出了一种提高规则选择准确性的方法,利用整个篇章的上下文信息来提高翻译质量。首先我们利用向量空间模型获得训练语料的文档和测试集中文档的相似度,然后把相似度作为一个新的特征加入到短语模型中。实验表明,在英语到汉语的翻译工作中,我们的方法可以显著提高翻译质量。最后,我们对计算相似度的时间复杂度进行了分析。
下一步,我们会从两个方面继续这个工作。第一,在模型中加入相似度特征的方法是通用的,我们可以把它加入到层次短语模型或其他模型中;第二,由于很多语料是没有分好文档的,例如,WMT的语料,不能直接使用,所以我们可以利用语料自动分类方法,把语料按照内容划分为多个文档。
[1] 刘群.统计机器翻译综述[J].中文信息学报,2003,17(4):1-12.
[2] Och F J,Ney H.Improved statistical alignmentmodels[C]//Proceeding of ACL,2000:440-447.
[3] Koehn P,Och F J,Marcu D.Statistical phrase-based translation[C]//Proceeding of ACL,2003:48-54.
[4] Xiong D,Liu Q,Lin S.Maximum entropy based phrase reordering model for statistical machine translation[C]//Proceeding of ACL,2006:521-528.
[5] Chiang D.A hierarchical phrase-based model for statistical machine translation[C]//Proceeding of ACL,2005:263-270.
[6] Liu Y,Liu Q,Lin S.Tree-to-string alignment template for statistical machine translation[C]//Proceeding of ACL,2006:609-616.
[7] Galley M,Graehl J,Knight K,et al.Scalable inference and training of context-rich syntactic translation models[C]//Proceeding of ACL,2006:961-968.
[8] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[9] Salton G,McGil,M J.Introduction to Modern Information Retrieval[M].McGraw-Hill New York 1983.
[10] He Z,Liu Q,Lin S.Improving statistical machine translation using lexicalized rule selection[C]//Proceeding of ACL,2008:321-328.
[11] Liu Q,He Z,Liu Y,et al.Maximum entropy based rule selection model for syntax based statistical machine translation[C]//Proceeding of ACL,2008:89-97.
[12] Setiawan H,Kan M Y,Li H.Topological ordering of function words in hierarchical phrase-based translation[C]//Proceeding of ACL,2009:324-332.
[13] Shen L,Xu J,Zhang B.Effective use of linguistic and contextual information for statistical machine translation[C]//Proceeding of ACL,2009:72-80.
[14] He Z,Meng Y,Yu H.Maximum entropy based phrase reordering for hierarchical phrase-based translation[C]//Proceeding of ACL,2010:555-563.
[15] 曹杰,吕雅娟,苏劲松,等.利用上下文信息的统计机器翻译领域自适应[J].中文信息学报,2010,24(6):50-56.
[16] Chen B,Foster G,Kuhn R.Bilingual sense similarity for statistical machine translation[C]//Proceeding of ACL,2010:1-10.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
中国新闻周刊(2021年26期)2021-07-27 04:02:12
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
海外华文教育(2016年1期)2017-01-20 08:21:58
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
