
维吾尔文智能输入法研究
2013-10-15 01:38:20米日姑肉孜吐尔根依布拉音麦热哈巴艾力
中文信息学报 2013年2期
米日姑·肉孜,吐尔根·依布拉音,麦热哈巴·艾力
(新疆大学 信息科学与工程学院,多语种信息技术重点实验室,新疆 乌鲁木齐830046)
1 引言
从20世纪90年代开始的智能输入法演变到现在的“搜狗”输入法、谷歌输入法、QQ拼音、百度输入法,形成了百花齐放的市场格局。至今为止,在维吾尔文信息处理当中还没有出现一个类似于“智能ABC”、“搜狗”输入法等功能强大的维吾尔文智能输入系统。输入维吾尔文时我们都希望输入单词的前几个字母,系统自动列出以这个字母开头的单词候选列表,但是维吾尔文当中每一个单词都有几十个到几千个的形态[1],以某一个字母开头的单词也有几千个到几万个[2],即使系统给我们列出这些候选词,但在这些候选词当中找出我们想要的单词花费的时间,远远超过了用户把单词的每一个字母逐步输入时耗费的时间。还有很重要的一点,那就是用户输入维吾尔文内容时经常出现拼写错误,因此也得考虑拼写检查这个因素。
维吾尔文的结构和语法跟汉字完全不一样,汉字是象形文字,维吾尔文是拼音文字,所以不能把汉字输入法[3-4]的特点完全使用在维吾尔语当中。维吾尔文智能输入当中要解决的问题很多,因此,做一个类似与中文智能输入法基本功能的维吾尔文输入法是相当困难的。
现在维吾尔文输入法的种类很多,比较常用的有:维软公司的Alkatip、维吾尔计算机科学协会发布的Uyghur Unicode I ME、艾维达公司发布的Elpida Unicode、爱革网络科技公司的爱革维文输入法,还有Alamas、Ilikyurt、Hiyal等。虽然编码方式统一到了国际标准(Unicode),但这些输入法共同存在的缺点都是没有智能输入功能:每个输入法都是基于单字母的输入,用户录入时必须一个字母一个字母地敲击键盘,不像现在流行的中文智能输入法一样具备单词自动预测、单词联想输入、校错和自动学习功能。因此在编写文档、网上聊天、论坛发帖、写博、评论等网络应用中,用户输入维吾尔文时导致输入速度慢,而且容易发生错误,发生的错误虽然不影响阅读,但是严重妨碍了计算机处理。因此开发一个具备自动预测、单词联想、自动学习和校对功能的输入法具有很重要的意义。
2 维吾尔文字的特点
现在使用的维吾尔文是在晚期察合台文基础上形成的以阿拉伯字母为基础的拼音文字。它与中文和西文有很大的区别,维吾尔文字输入有如下特点:
现行维吾尔文有8个元音字母,24个辅音字母,书写方向是从右到左,行向从上到下。每个字母按出现在词首、词中、词末的位置有2到6种变体。通过英文26个字母输入维吾尔文32个字母时,有6个字母需要借助上档键(Shift+),因此这些字母输入时不但影响速度,而且容易出错。比如:(新疆)错成(因为和在同一个键上),(人民)错成(和在同一个键上)。因此使用Shift键会导致打字速度变慢。
维吾尔人同时并用过以拉丁字母为基础的维吾尔文,1965~1982年整整使用了17年,该文字对各方面的影响还较深,很多应用软件根本无法识别我们现用的阿拉伯文为基础的维吾尔文的输入(如:腾讯QQ,Messenger等),所以现在很多维吾尔人在计算机交流时还在使用拉丁字母为基础的维吾尔文。然而阿拉伯文为基础的维吾尔文和拉丁字母为基础的维吾尔文的键盘布局有所不同,这两种文字字母键盘布局对照如表1所示。现在很多人用计算机打字的时候经常会把这两种文字的布局搞混,如:想输入“”字母时就会错按成A键,而不是F键。
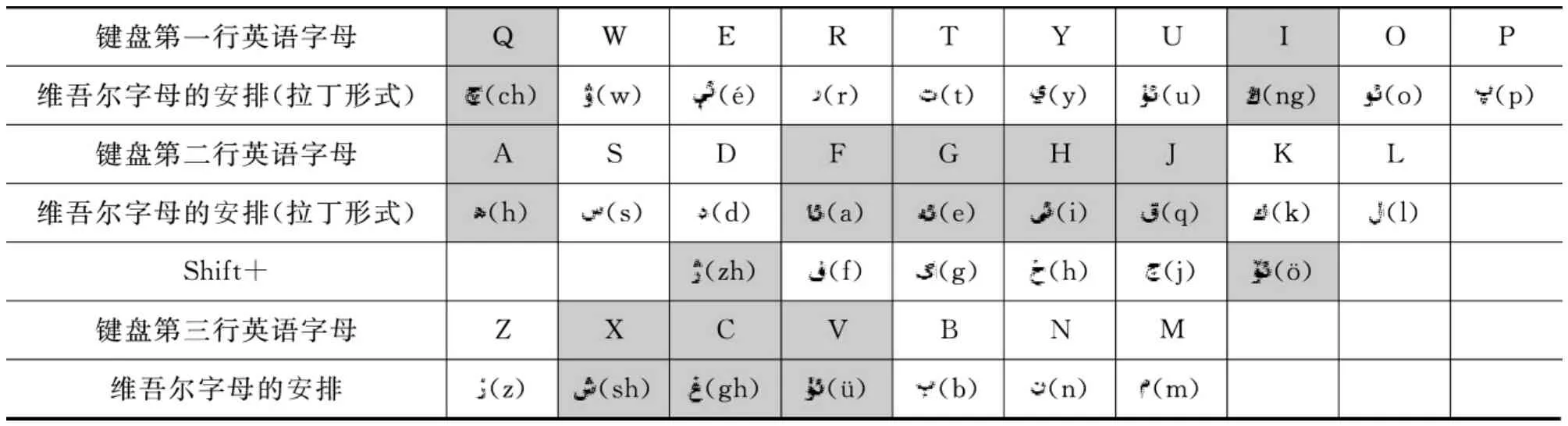
表1 两种维吾尔文字母键盘布局对照表
维吾尔文单词是由字母拼写而成的,发什么音就写什么字。但是由于方言、发音习惯以及发音相近字母的影响等原因,导致许多单词的发音与其书面形式不同。因此打字时就按口语发音录入,不遵守维吾尔文字母的拼写规则,就容易出现正字错误。如表2所示。
考虑以上几种情况,开发一个具备自动预测、单词联想、自动学习和校对功能的输入法,不仅可以提高打字速度,从大的方面来说,对新疆的信息化、社会经济发展都将产生很大的影响。

表2 维吾尔语词与口语形势比较
3 输入系统的处理过程
3.1 输入系统
本输入系统的处理过程如图1所示。以下是其中主要模块的功能。
(1)在索引词库中检索数据:为了提升输入检索速度,首先建立一个完整的索引词库,然后根据用户输入对词库进行检索,将检索到的结果输出给屏幕。使用前方一致的检索方法,对检索结果排序时完全一致的检索结果优先,其次是前方一致的检索结果。比如:用户输入这个关键词以后,系统自动推荐等一些候选列表,并按以下形式排序:。
(2)拼写校对[5]:如果用户输入的内容在词库中不存在,系统对此内容进行自动校对并对修正结果重新检索,生成相应的检索结果。此功能在3.2节会详细讨论。
(3)学习用户选择:用户在输入内容时可能出现系统预测错误,联想出来的内容不够合理,需要用户选择或更正。在维吾尔文输入系统中,系统学习的行为主要是跟踪并记录用户的选择及其上下文,以便提高候选词列表排序的合理性。
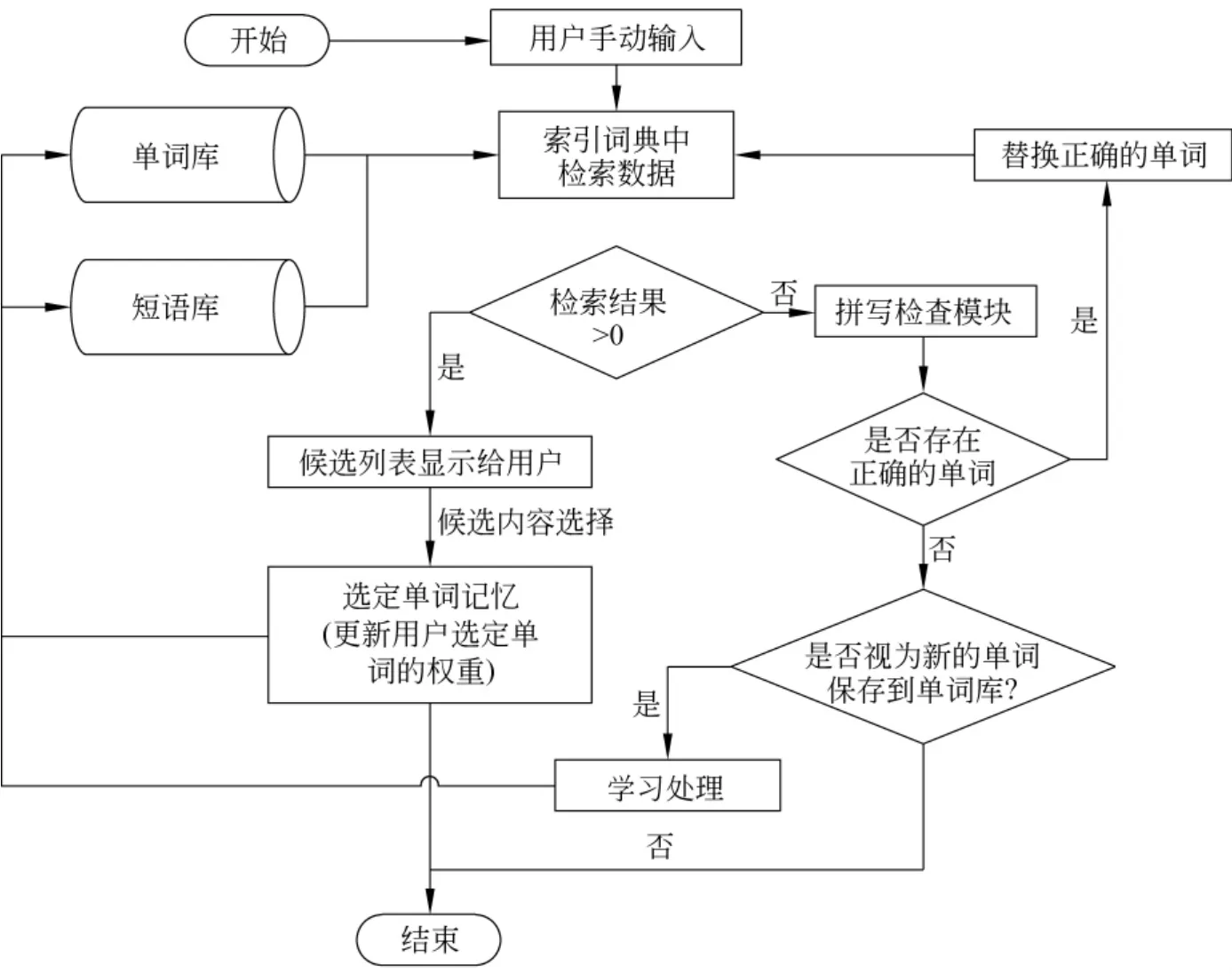
图1 输入系统的处理过程
3.2 拼写校对
拼写校对在本输入法中起很大的作用。此模块工作流程如图2所示。拼写校对模块的组成部分如下:
(1)预处理:首先在词库中搜索用户输入的单词,如果词库中存在,则认为拼写正确,否则预处理。预处理阶段的主要任务是,分析单词的前三个字母的组成并进行删除和字母的偏移序列替换。这里的偏移序列指的是:用户在键盘上敲打字母时,用户的手指可能从正确的字母键位偏移到其他字母的键位,或者因为SHIFT键引起的错输,也可能是因为用户习惯性地按照基于拉丁字母的输入习惯来输入内容,如:基于拉丁字母的“a”和基于阿拉伯字母的“”不是同一个键位,因此引起误敲。通过实验,偏移位置大致在这个正确键位附近的键,比如:“”的偏移序列是 ()。比如:用户输入的单词是,经过偏移处理后的序列:;很明显,其中正确的单词可能是或者还有其他的。
(2)特征提取:从用户输入的内容进行预处理,如果预处理结果中没有正确的单词,则系统从这些预处理结果单词中提取单词的特征,生成一个特定的单词模式。
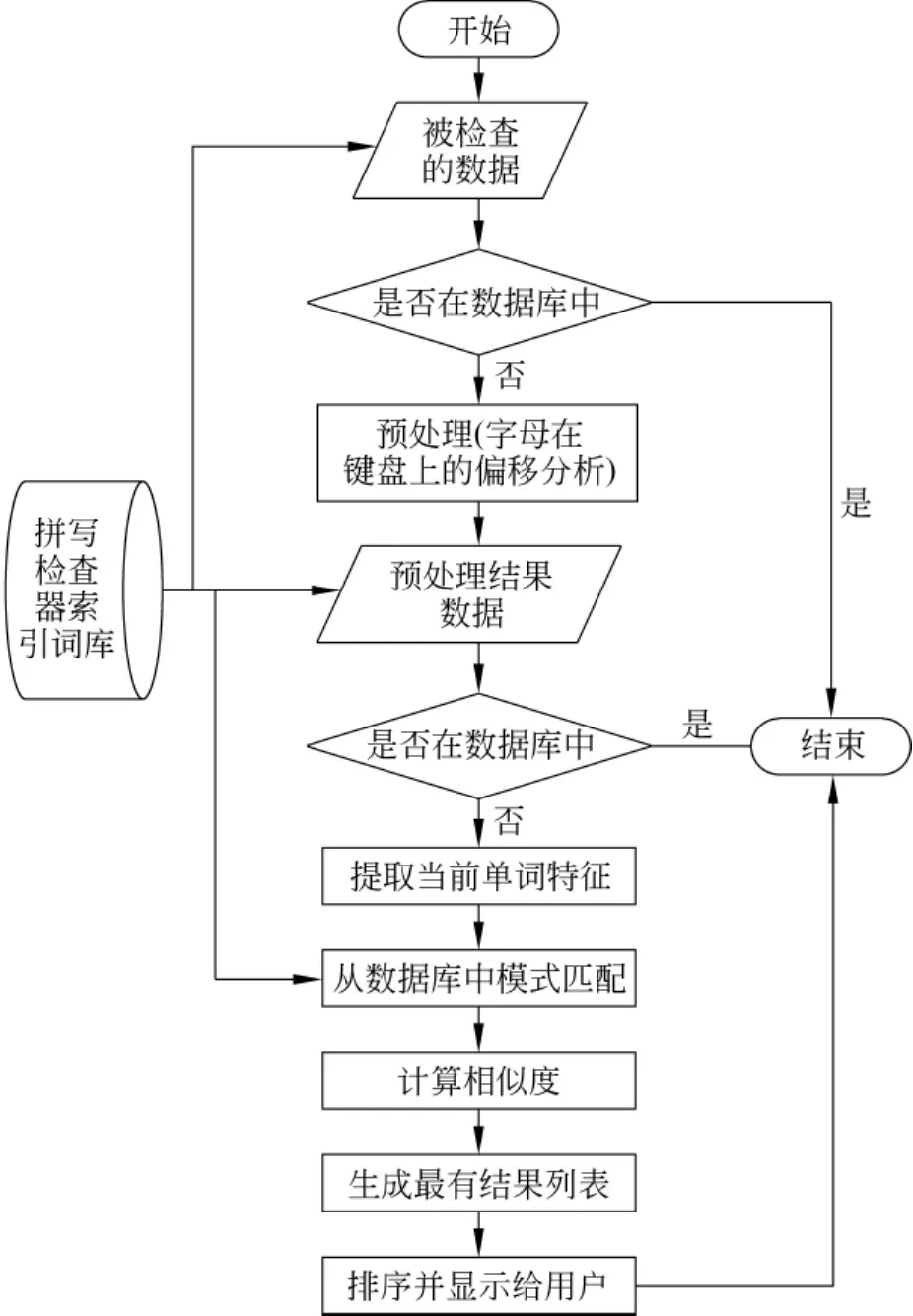
图2 拼写校对处理过程
(3)模式匹配:按照预处理结果中生成的匹配规则,从词库中进行模式匹配,找出与此模式成功匹配的单词集合。
(4)计算相似度:经过模式匹配获取到的单词集合与用户输入的内容进行相似度计算。通过相似度计算获取与用户输入的内容相似度最高单词集合。
(5)排序并显示给用户:通过相似度计算得来的单词集合,按照它们相似的度量进行排序,相似度量最高的排在最前面视为最优的单词候选。
4 基于二元语法模型(Bigram)的维吾尔文分词
为了使输入法具有联想功能,本文采用二元文法模型[6-8]对语料进行分词并保存。对用户输入的单词根据二元模型联想出其最佳的搭配。
当输入完前段单词以后,后面的单词用户很想知道可能输入的单词是哪一个?比如:___后面的空格从单词列表当中用户很可能输入哪一个单词呢?怎样找出最佳候选?输入法的实现,首先需要建立一个输入法语言模型。从统计角度来看,自然语言中的任何句子s可以由若干个单词构成。
对于一个句子T而言一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。如果一个词的出现仅依赖于它前面出现的一个词,称之为bigram。即:

下面我们用Bigra m举个例子。
假设语料库中有10000个单词:

表3 单词和单词序列频度表
按照Bigram模型,实现了单词自动联想输入功能。单词自动联想输入是用户输入某一个单词以后,系统自动联想出跟当前单词匹配的最佳单词结果到候选列表中供用户选择。如图3所示单词联想功能原理图。
5 接口编码
在中文Windows系统下,维吾尔文输入法的设计主要是根据 Windows系统所定义的I MM-I ME结构。按照该结构的规范,在结构的框架内使用I ME API(输入法程序编程接口)为各个部分编写程序代码,实现维吾尔文智能输入法功能。输入法运行结果界面如图4所示。
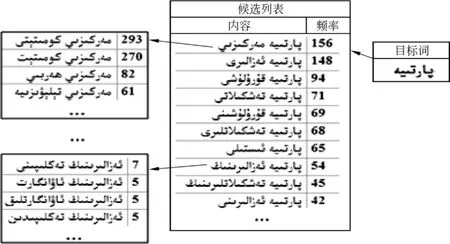
图3 单词联想原理

图4 输入法界面
6 实验

图5 单词联想界面
为了验证输入法程序的性能,对不同用户进行了输入测试。抽出的6名用户打字速度不同。经过从政府文献中选取的有关《中华人民共和国邮政法》的一页(包含4个段落、252个维吾尔文单词、33个标点符号)内容进行测试,并得到了测试数据。测试结果如表4所示。
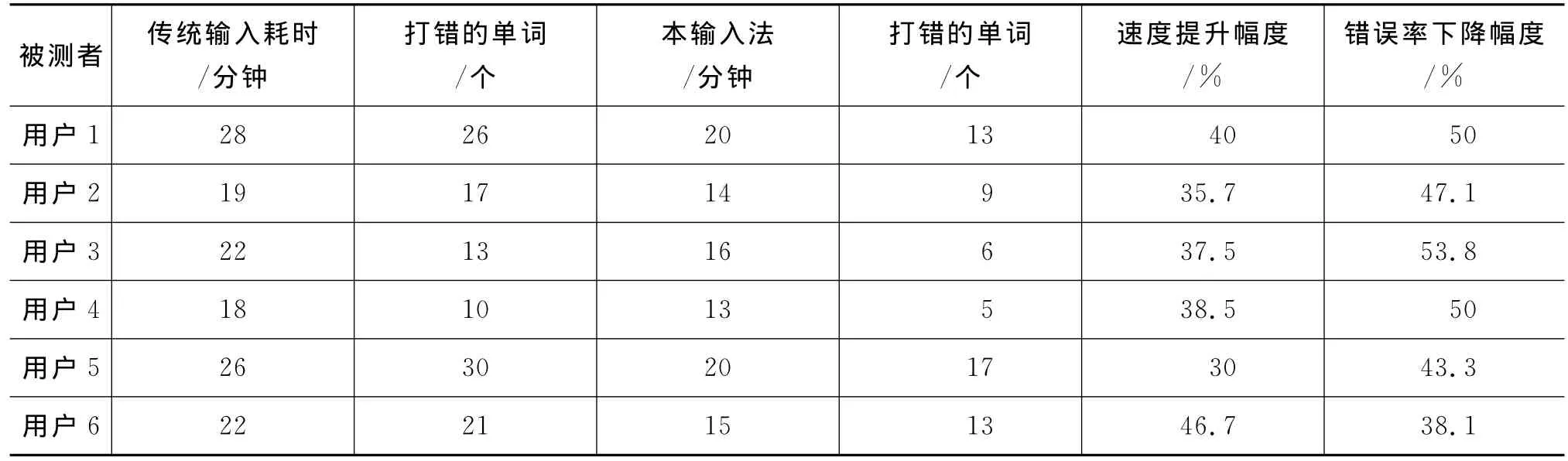
表4 输入法输入测试数据表
从表4中可以看出,用户1明显比其他用户打字速度慢,而且输错的单词数目也比较多。完成测试之后可以看出使用本智能输入法输入时,速度比传统方式输入速度平均提高了38.1%,错误率平均下降了47%。但仍存在输错单词的情况,主要是因为用户还不太适应,还有候选词选择错误,翻页查找候选词等因素引起了输错或者选择候选词时的停顿,都影响了输入法的性能[9]。通过完善训练词库可以提高输入速度。
7 结束语
本文在分析维吾尔文智能输入技术现状的基础上,提出并讨论了一种基于混合Bigra m语言模型的智能输入技术,最后讨论了自动预测和自动联想功能和系统自动校对功能的维吾尔文智能输入的技术。此维吾尔文输入系统的自动预测和联想功能明显提高了输入速度,基本实现了预期目标。但是,测试的结果也说明了系统存在一些问题,尤其是出现用户输入训练集以外的内容时正确率有所下降,发现混合Bigram模型还不够精确,用于训练该模型的语料选取太偏重于小说、新闻、社科等领域,不够全面,要扩大训练语料的规模;通过系统自动学习,采用高阶语言模型和进行数据平滑技术[10]能显著提高维吾尔文输入系统的性能。
[1]http://kenjisoft.ho melinux.co m/i mla/index.ht ml,2007-1-3.
[2]艾尼瓦尔·麦麦提,吐尔根·依布拉音.维吾尔文字母频率统计及其应用[C]//第二届全国学生计算语言学研讨会论文集,2004年.
[3]李亭骞,曹渠江.Windows平台下的汉字输入法机制及应用[J].计算机应用与软件,2006,(1):40-42.
[4]高升,王晓龙.语句级汉字输入系统中语义规则研究[J].计算机工程与应用,2003,39(4):80-82.
[5]陈正,李开复.拼写纠正在拼音输入法中的应用[J].计算机学报,2001,(7):758-763.
[6]刑永康,马少平.统计语言模型综述[J].计算机科学,2003,30(9):22-26.
[7]冯志伟.自然语言的计算机处理[M].上海外语教育出版社,1996.
[8]赵以宝江,孙圣和.一种基于单字统计二元文法的自组词音字转换算法[J].电子学报,1998,(10):55-59.
[9]汤步洲,王晓龙,等.语句级汉字拼音输入技术评估方法的研究[J].中文信息学报,2008,22(5):51-55.
[10]黄永文,何中市.基于互信息的统计语言模型平滑技术[J].中文信息学报,2005,19(4):46-51.
[11]朱巧明,倪明逸.基于统计的智能输入技术分析[J].苏州大学学报(自然科学版),2001(2):43-47.
猜你喜欢
小雪花·初中高分作文(2021年3期)2021-08-27 08:42:22
北方文学(2017年36期)2018-01-18 13:10:40
英语知识(2016年1期)2016-11-11 07:07:54
中国知识产权(2016年11期)2016-11-11 02:55:06
新疆大学学报(自然科学版)(中英文)(2014年1期)2014-11-02 08:36:38
民族古籍研究(2014年0期)2014-10-27 08:24:53
电脑迷(2014年14期)2014-04-29 00:44:03
电脑迷(2012年22期)2012-04-29 23:34:02
电脑迷(2012年15期)2012-04-29 17:09:47
计算机应用文摘(2011年8期)2011-04-29 10:22:57
