
一种融合实体语义知识的实体集合扩展方法
2013-10-15 01:51:54齐振宇
中文信息学报 2013年2期
齐振宇,刘 康,赵 军
(中国科学院 自动化研究所 模式识别国家重点实验室,北京100190)
1 引言
无论在学术领域还是在工业领域,同类命名实体列表都具有广泛的应用。在工业领域中,搜索引擎公司比如Google、Yahoo、Bing等都在后台维护大量的命名实体列表以提高用户体验[1];而在学术领域,同类命名实体列表在问答系统、知识库构建等方面也有重要应用[2]。鉴于此,多年来一直有研究者在研究如何获得同类实体列表,即如何解决实体集合扩展问题。
实体集合扩展(Entity Set Expansion),指的是这样一类问题:给定某语义类的若干实体(以下称为“种子”),要求得到该类别的更多实体。比如已知{中国、美国、俄罗斯}三个国家,要求找出更多国家,比如{德国、日本、巴西…}。
目前解决实体集合扩展问题主要有三类方法,分别是基于分布的方法、基于模板的方法以及基于融合的方法。无论哪一类方法,都需要若干种子作为出发点,进而通过提取种子出现的上下文或者网页结构等信息来捕获种子共有的浅层环境特征,以此作为扩展的依据。但实体往往具有歧义性,这会导致所提取的浅层环境特征产生偏差,使得扩展得到的实体与原始种子在语义上不相匹配,从而影响实体集合扩展的精度。
比如“Washington”作为种子,可能指地点(美国首都)、可能指人物(美国前总统),也可能指一艘船(美国海军的一艘航空母舰)等。不同语义的“Washington”,其上下文具有不同特征。如果不区分各自的语义,简单地把不同语义的上下文特征混杂在一起,这种情况下得到的浅层环境特征是不可靠的,基于此得到的扩展结果也会包含很多错误。
为解决种子歧义性问题,本文提出了一种通过挖掘种子实体蕴含的语义信息,并与基于上下文统计特征的方法结合起来进行实体集合扩展的方法。具体地,我们在Wikipedia中利用种子实体的链接信息和类别信息进行实体集合扩展,在此基础上融合了传统的基于浅层环境特征的实体集合扩展方法。实验结果表明,本文方法可以同时提高准确率、召回率和MAP值。
本文组织结构如下:第2节介绍实体集合扩展的研究现状以及本文的动机;第3节介绍Wikipedia及其中蕴含的语义信息在实体集合扩展中的应用;第4节介绍本文提出的融合实体语义知识的实体集合扩展方法;第5节是实验结果与分析;最后给出总结与展望。
2 相关工作
实体集合扩展的目标可以分为两类,一类是大而开放类别的语义类,另一类是小而封闭类别的语义类[3]。在前者中,待扩展的语义类含有数量庞大的实体(即“大”),而且其实体可以是变化的(即“开放”);比如“运动员”这个类别。而在后者中,待扩展的语义类规模较小(即“小”),而且其实体基本没有变化(即“封闭”);比如“国家”这个类别。本文主要研究针对小而封闭语义类的实体集合扩展问题。
目前解决实体集合扩展问题的主流方法,大体上可以分为基于模板、基于分布以及基于融合等三大类。
基于模板的方法,代表性工作包括文献[3-7]等。这类方法的核心思想是,通过某种方式得到模板,利用模板抽取候选实体,最后对候选进行打分排序得到结果。这里的模板可以是预先定义的语义模板,比如“such as”,“and”等,也可以是种子在语料中出现的高频上下文。实验结果[6]表明这类方法适用于处理小而封闭的语义类扩展问题。
基于分布的方法,代表性工作包括文献[8-10]等。这类方法核心思想是,统计语料库中每个词项的上下文分布并构造词项分布矩阵,利用该矩阵计算每个词项与种子的相似度,以此作为打分和排序的标准。这一类方法更适用于处理大而开放的语义类扩展问题。
基于融合的方法,代表性工作包括文献[11-12]等。这类方法使用多种类型的数据(比如普通网页文本、网页表格、查询日志等),对不同类型的数据采用不同处理方法(基于模板或基于分布),并对各自的结果进行融合。这种方法可以降低单一方法所产生错误对总体结果的影响,这类方法同样更适用于处理大而开放的语义类扩展问题。
已有方法均从种子的上下文统计特征入手,没有使用种子的语义知识。这些方法的弊端在于单纯的上下文统计特征不足以完整刻画种子的全部特性。尤其当种子具有歧义性时,其上下文统计特征会产生偏差,此时扩展效果也会受到很大影响。
比如“Lincoln”这个词,可能指人物,可能指轿车,还可能指地点。而不同语义的“Lincoln”,其上下文统计特征显然具有不同规律。当指人物时,其上下文多为“…是美国总统”,“…出生于”等;而指轿车时,其上下文多为“…报价”,“…是一种豪华车”等;而指地点时,其上下文多为“…创建于”“…位于”等。
为降低种子歧义性对实体集合扩展的不良影响,我们提出一种融合实体语义知识的实体集合扩展方法。该方法把基于语义知识的扩展方法与基于模板的扩展方法融合在一起。在基于语义知识进行扩展时,引入语义知识库来挖掘种子蕴含的语义信息,并利用这些语义信息在知识库中进行扩展,以此降低种子歧义性的影响;在基于模板进行扩展时,使用种子的上下文进行扩展,以此弥补知识库在更新速度和完备性上的不足。最后把这两种方法的结果融合起来作为最终结果。
3 Wikipedia及其所蕴含语义知识的使用
3.1 Wikipedia
Wikipedia①http://www.wikipedia.org/是一个基于Wiki技术的百科全书项目,其产物是一个动态的、可自由访问和编辑的知识体。根据知名的Alexa网络流量统计排名,Wikipedia目前为世界网站流量排名第七大网站。
截至2011年11月,Wikipedia的总条目已达1900万条(其中英文条目超过370万条②http://en.wikipedia.org/wiki/Wikipedia:Size_of_Wikipedia),每个条目对应一篇高质量的、富含超链接以及类别信息的文档。Wiki基金会每个月都会放出一个新版本的Wikipedia下载以满足用户的需求。
由于Wikipedia具有信息量大、质量高、获取方便、更新快等优点,其在自然语言处理以及知识工程领域得到广泛的使用,大量的研究工作使用 Wikipedia作为语料或资源。本文使用英文版的 Wikipedia作为语义知识库。
3.2 Wikipedia所蕴含语义知识在实体集合扩展中的使用
本文利用Wikipedia中条目之间的超链接关系以及类别标签体系两类语义知识进行实体集合扩展。
超链接关系:在Wikipedia中,每个条目对应一篇文档(见图1),该文档是对该条目的描述。平均每篇Wikipedia文档含有34个到其他条目的链接,同时有34个其他条目链接到该文档[13],本文将这些链接视为对该条目的一种语义描述。

图1 条目“George Washington”
类别标签体系:Wikipedia中,一个条目可以有若干个类别标签(Category Label,见图2),而一个标签可以标注多个条目。这些标签反映了该条目所属的语义类别。此外,所有类别标签组成了一个复杂的类别体系。通过衡量单个标签在分类体系中的位置可以考察不同标签的语义信息,进而考察属于该标签的条目的语义信息。

图2 条目“George Washington”的类别标签
在本文中,我们使用条目之间的超链接关系进行消歧以及相关度的计算,使用类别标签体系进行扩展。在下一节中,我们会详细描述这两类语义知识的使用。
4 融合实体语义知识的实体集合扩展方法
在这一节中,我们将介绍融合实体语义知识的实体集合扩展方法。其中4.1节介绍基于语义知识的扩展方法;4.2节介绍基于模板的扩展方法;4.3节介绍二者的融合。
4.1 基于语义知识的实体集合扩展方法
首先我们做出一个基本假设:种子实体在Wikipedia中都能找到对应条目。
实际上,Wikipedia不可能覆盖所有的实体。但由于人们通常使用熟悉的实体作为种子,而Wikipedia对于常见实体的覆盖度非常高。所以这个假设可以成立。
结合Wikipedia知识库的结构特点,我们设计了一个三阶段的实体集合扩展系统:
第一阶段—消歧阶段。本阶段的任务是明确种子实体在Wikipedia中对应的条目。输入是3个种子,输出是这3个种子在Wikipedia中对应的条目。
第二阶段—扩展阶段。本阶段的任务是根据上一阶段的结果,找到Wikipedia中可能属于同语义类的条目作为候选。输入是种子对应的条目,输出是作为候选的若干条目。
第三阶段—选取阶段。本阶段的任务是对候选条目打分并排序,得到最终的结果。
以下分别介绍这三个阶段。
4.1.1 消歧阶段
当确认种子实体在Wikipedia中对应的条目时,由于种子锚文本可能具有多种不同语义,会出现歧义问题。关于这个问题我们通过一个例子加以说明。
仍然考虑“Washington”这个词,它可以指向很多实体:
人:1.美国第一任总统华盛顿。2.其他姓“华盛顿”的人,比如电影演员丹泽尔·华盛顿
地点:1.美国首都。2.美国的一个州名。3.其他地点。
船:1.美国海军华盛顿号航空母舰。
机构:1.华盛顿大学。2.其他机构。
实际上,“Washington”作为锚文本在 Wikipedia中指向的条目超过100个。这种一个锚文本指向多个条目的现象非常普遍。下一节实验数据表明,每个实体在 Wikipedia中作为锚文本指向的条目平均超过5个。为确认种子实体对应的条目,必须解决歧义问题。
我们提出了一种综合考虑条目概率与语义相关度的消歧方法。设种子A对应的候选条目集为{a1,a2,…,ai},种子 B 对应的候选条目集为{b1,b2,…,bj},种子C 对应的候选条目集为{c1,c2,…,ck},给定A、B、C后,我们按式(1)的方法选取最合适的条目组{al,bm,cn}。
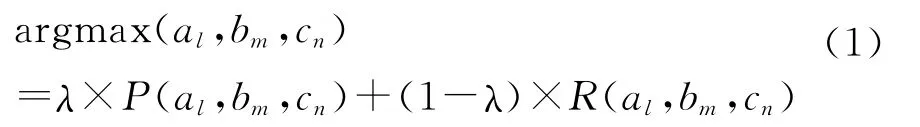
该方法考察两方面的因素:第一是三个候选条目被选中的概率得分;第二是三个候选条目之间的相关度得分。
其中概率得分通过计算三个条目被选中概率之积求对数得到:
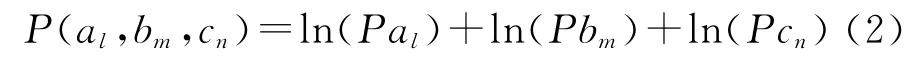
而相关度得分通过求三个条目两两之间相关度得到:
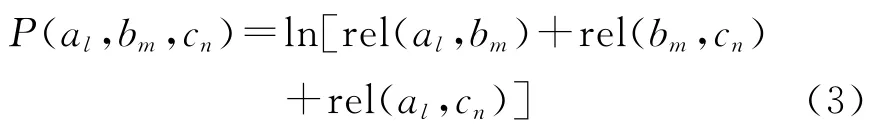
其中,我们使用 Milne[13]提出的算法来计算两个条目之间语义相关度,见式(4)。

其中x、y是两个条目,X、Y分别是链接到这两个条目的其他条目的集合,W 指整个Wikipedia。
λ作为参数调节两部分所占的比重。
4.1.2 扩展阶段
我们设计了一种使用Wikipedia中类别标签来寻找与种子条目属于同一语义类条目的扩展系统,该系统框架见图3。该系统可以分为两个阶段:
阶段一,求出a、b、c三个条目中每个条目的标签集合,记为La、Lb、Lc。取出至少在两个标签集合中出现的标签组成一个公共标签集合。
阶段二,抽取出公共标签集合中标签包括的文章作为候选条目。
为提高抽取效果,我们在阶段一中进行标签扩展:即La不仅包括条目a的标签,还包括条目a的标签在标签体系中的上一层标签。
4.1.3 候选选取阶段
我们考察候选条目与种子条目之间的相关度,并选取相关度在一定阈值(以下称该值为“相关度阈值”)以上的候选条目作为结果。
在训练阶段,为求得“相关度阈值”,我们采取以下做法:设训练集T共有m个语义类,对其中每个语义类s,我们利用4.1.1节中的式(4)计算同类别条目之间的平均相似度:
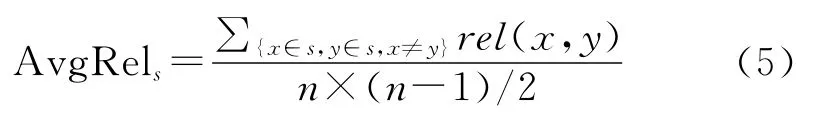
其中n为类s含有的实体个数。之后对T中m个语义类的平均相似度求平均,得到整个训练集T的平均语义相似度:

在本文中,经计算得到的“相关度阈值”为AvgRrelT=0.56。

图3 扩展系统
在测试阶段,我们利用4.1.1节中式(4)分别计算候选条目与三个种子条目之间的相关度并求平均值。抽取平均相关度在“相关度阈值”以上的候选条目组成结果集,并将结果集合中的条目按相关度排序作为结果返回。
4.2 基于模板的实体集合扩展
我们实现了一种高效的基于模板的实体集合扩展方法[6]。该算法把三个种子作为查询词送到搜索引擎中,并爬取搜索引擎返回的前100个URL对应的网页作为语料。之后针对单个网页学习种子在其中出现的模板,并利用学到的模板得到候选。最后我们采用按照出现频率排序的方式为候选排序并抽取出现次数大于1的候选作为结果返回。
4.3 基于语义知识与基于模板两种方法的融合
以上我们通过两种扩展方法得到两个结果集,基于语义知识的抽取结果集合记为Rs,其中的候选表现为<候选,相关度>;基于模板的抽取结果集合记为Rp,其中的候选表现为<候选,出现次数>。我们按以下方法对这两个集合进行融合:
首先把Rp中候选的出现次数按式(7)归一化到[0,1]区间。
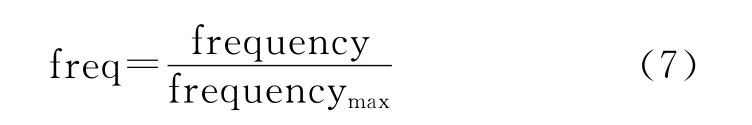
其中分子为该候选出现的次数,分母为该类别候选中出现次数最多候选的出现次数。之后对每个候选按照下面式(8)对其打分:
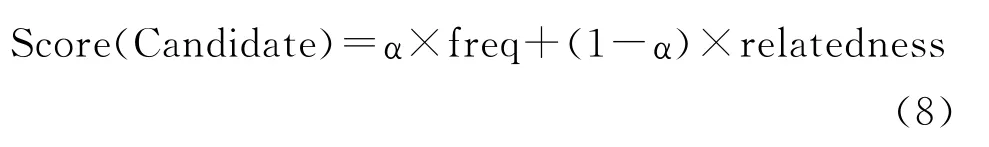
其中freq和relatedness分别为该候选的频率得分和相关度得分。如果该候选只有其中一个得分,那么另一项得分按0计算,α作为参数调节二者之间的权值。
5 实验数据与分析
5.1 实验数据
本文使用Wikipedia20110722版本作为知识库,另外使用了 WikipediaMiner①http://wikipedia-miner.cms.waikato.ac.nz/软件工具(1.2.0版本)处理Wikipedia数据。
本文构建了2组×6类别/组共12个语义类作为实验数据,人工标定每个语义类所包含的实体。其中第一组作为训练集,第二组作为测试集。相关数据如表1和表2所示。
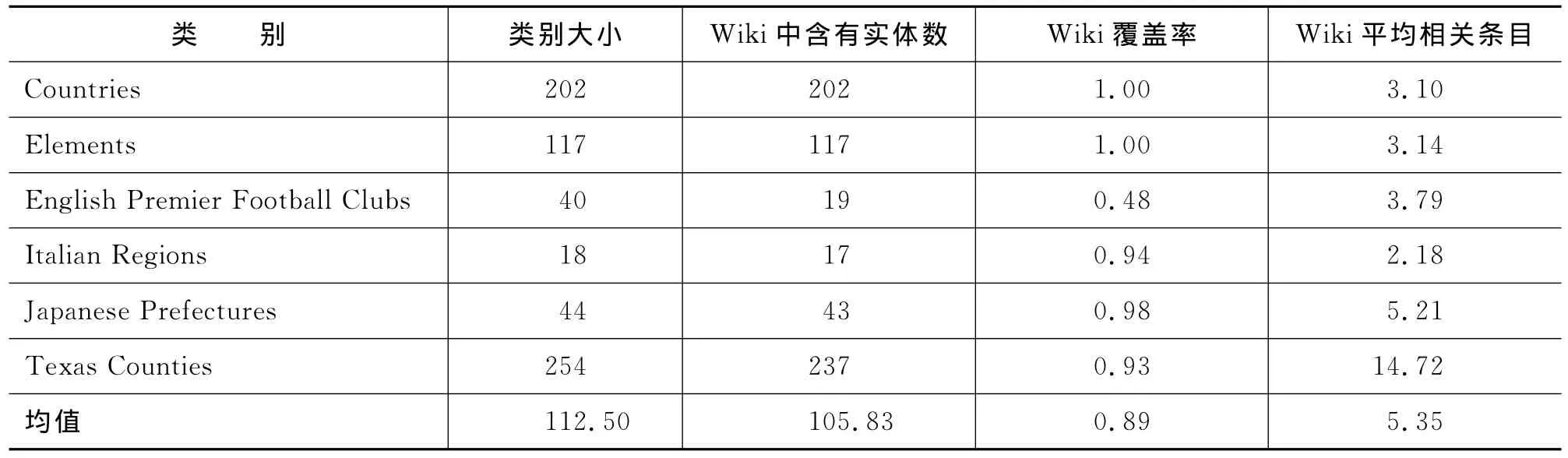
表1 训练集相关信息(6语义类)
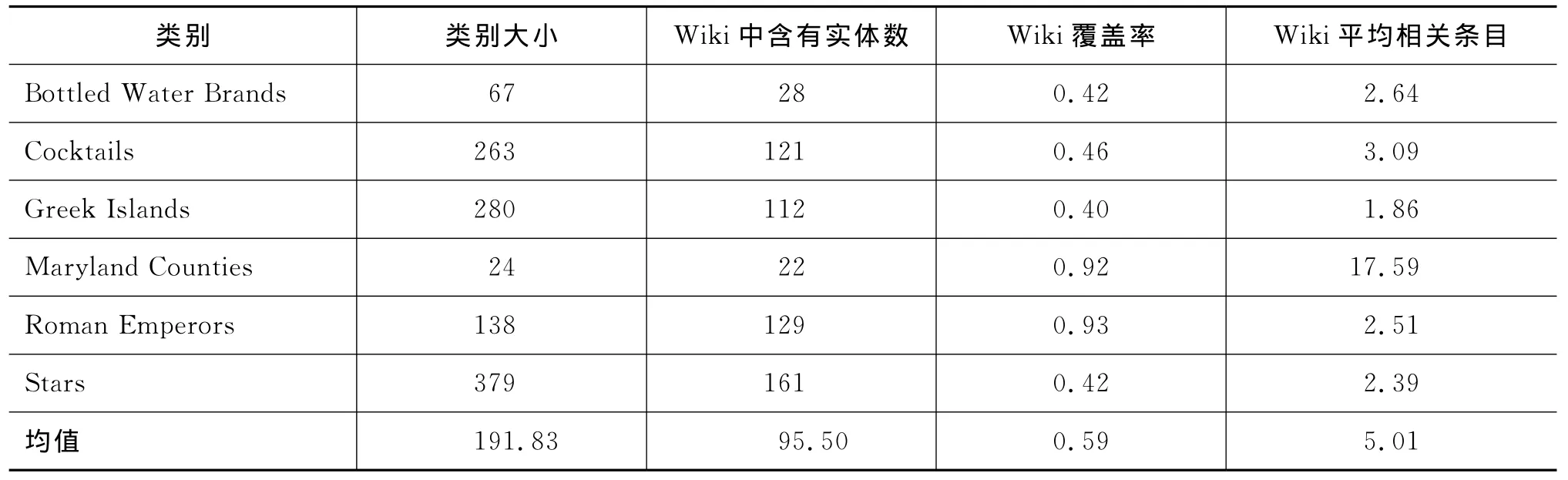
表2 测试集相关信息(6语义类)
5.2 消歧算法效果验证
本实验验证4.1.1节中消歧算法的有效性,对比不进行消歧与进行消歧两种方法的效果(表3)。进行消歧时,按照第4节所述方法进行实体集合扩展。不进行消歧时,采用如下方法:设种子A对应的候选条目集为{a1,a2,…,ai},种子B 对应的候选条目集为{b1,b2,…,bj},种子C 对应的候选条目集为{c1,c2,…,ck},抽取每个候选条目集中所有条目的标签以及标签的父标签分别组成标签集合LA,LB,LC,取出至少在其中两个标签集合中出现的标签组成一个公共标签集合,抽取出公共标签集合中标签包括的文章作为候选条目。在计算候选条目的相关度时,把候选条目与种子的所有可能条目的相关度均值作为该候选的相关度。
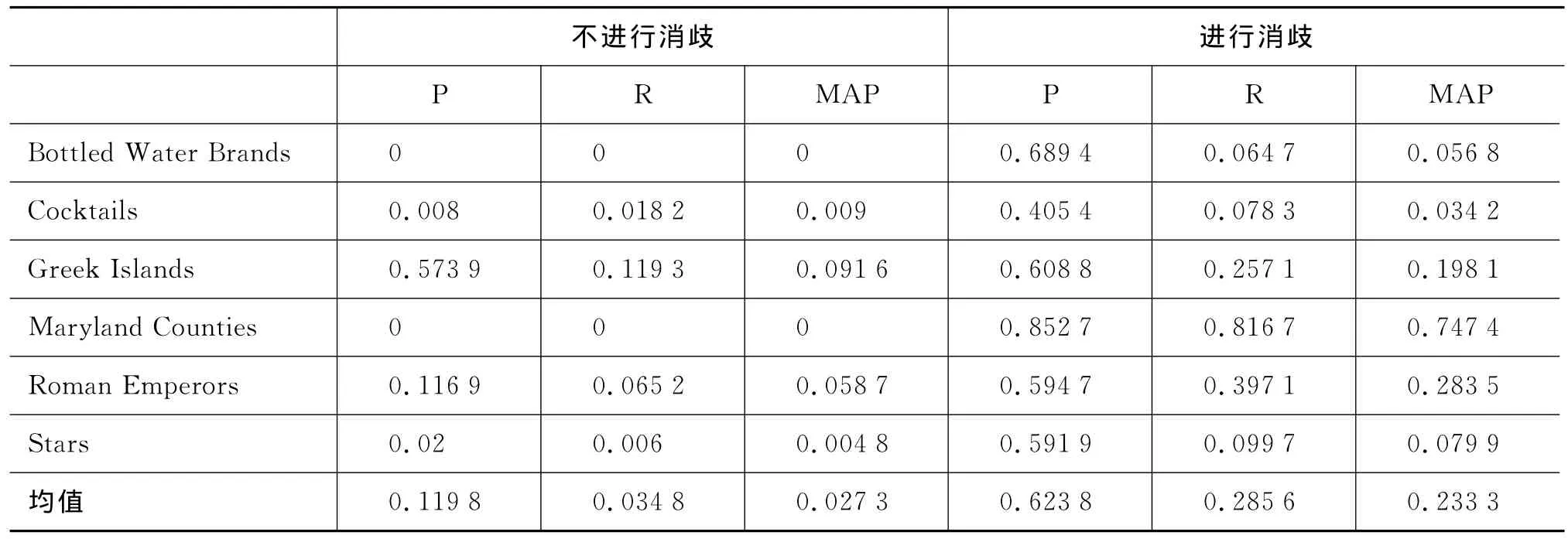
表3 消歧与不消歧效果比较
可以看出,由于不进行消歧,候选的相关度偏低,很难达到“相似度阈值”,使得结果很差。而进行消歧可以消除歧义,极大地提升方法的表现。
5.3 消歧算法中参数λ的确定
本实验确定4.1.1节式(1)中参数λ的值。对每个语义类做100组实验,每组实验随机抽取该类别的3个实体作为种子,记录λ取不同值时3个种子对应的条目,当3个条目都正确时视为正确,否则视为错误。实验结果如表4所示。

表4 消歧阶段λ的确定

续表
5.4 对标签进行扩展的重要性分析
本实验验证4.1.2节中标签扩展的重要性(表5)。对每个语义类做500组实验,每组实验随机3个种子,依据4.2节中描述的算法确认其在知识库中对应条目后,对得到的3个条目抽取其标签。可以看出,不进行标签扩展时,平均每组种子只能抽出2.8个标签;进行扩展后每组种子可以抽出10.3个标签。这可以证明加入标签扩展后,大大增加了得到相关条目的可能。
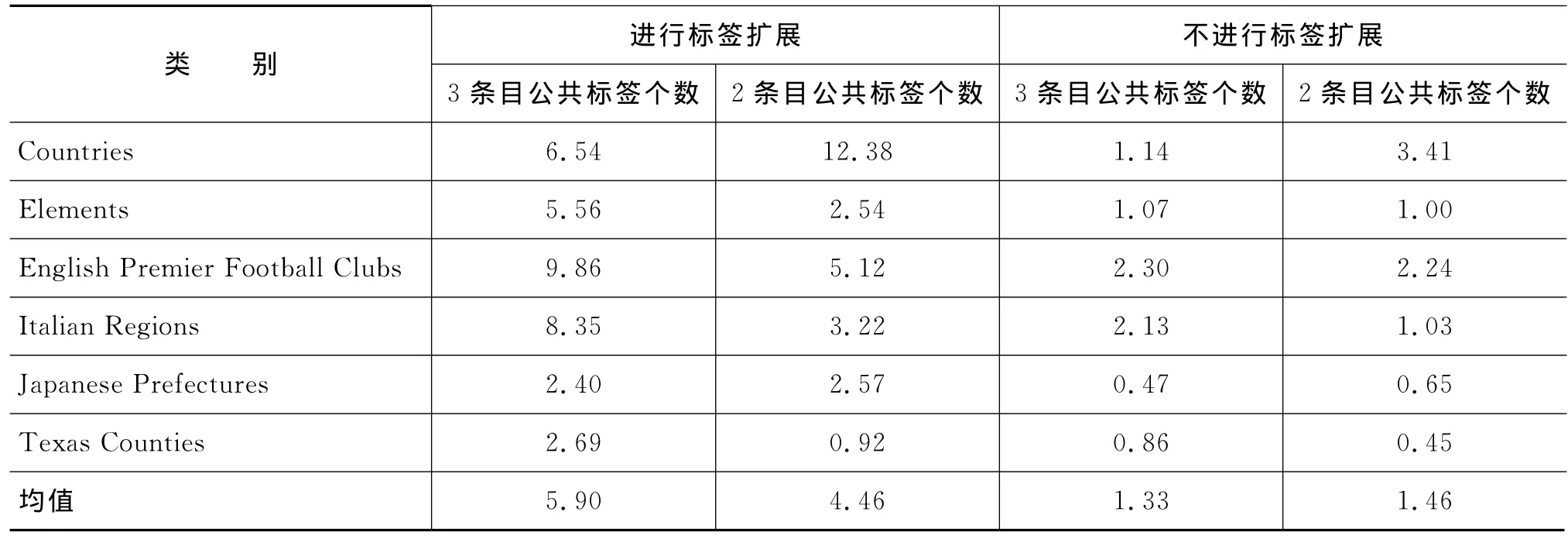
表5 扩展阶段进行标签扩展的重要性分析
5.5 候选选取过程中相关度阈值影响
本实验验证4.1.3节中相关度阈值对抽取条目的影响。我们对每个类别进行50组实验,每组实验随机选取3个种子,通过第4节介绍的算法在Wikipedia中进行扩展。加入相关度阈值和不加入两种情况下的实验结果如表6所示。

表6 按照相关度规则抽取条目
从上表可以得到以下两个结论:
1.正确候选条目和错误候选条目,二者与种子的相关度有很大差别(0.63Vs 0.16),引入相关度作为衡量候选准确性指标非常合理。
2.引入相关度阈值后,在损失1/3正确候选条目(96Vs 65)的前提下,滤去了4.7倍的错误候选条目(585Vs 101)。这证明了引入相关度阈值的有效性。
5.6 融合语义知识与统计信息的实体集合扩展
本实验对比单纯基于模板、单纯基于语义以及二者融合三种方法的实体集合扩展结果。我们对每个类别做5组实验,每组随机抽取3个种子,分别使用基于模板、基于语义以及二者融合三种方法进行实体集合扩展,最后对5组实验的结果求均值。实验结果如表7所示。

表7 三种方法的结果比较
可以看出,传统单纯基于模板的方法召回率较高,但由于受到种子歧义性问题的影响,准确率较低;而单纯基于语义的方法解决了种子歧义性问题,所以准确率较高,但召回率较低。二者融合以后,P值提升了18.5%,R值提升了6.8%,而MAP也提升了22.8%,这说明二者融合的方法吸收了两种方法各自的优点,弥补了不足,使得整体结果有了很大的提升。
另外,我们也测试了式(8)中不同α对融合结果的影响,可以看出,融合语义知识后的效果比单纯使用模板的效果要好,而当α取0.2时,融合结果最好。

图2 不同α对融合结果(MAP)的影响
6 总结与展望
实体集合扩展问题是开放式信息抽取中一个重要问题。目前解决该问题的方法基本都是从若干个种子出发,利用模板或种子的分布信息进行扩展,没有考虑到种子的语义信息,所以无法解决种子歧义性问题。
本文提出了使用种子的语义信息进行扩展以解决种子歧义性问题的思路,并利用Wikipedia作为语义知识库,实现一种基于语义知识的扩展方法。在给定种子的情况下,经过消歧阶段、扩展阶段、选取阶段最终得到扩展结果。
此外,本文把基于语义知识的扩展和基于模板的扩展相融合。实验结果表明,新方法在P值上提升了18.5%,R值上提升了6.8%,MAP值提升了22.8%,这证明了本文方法的有效性。
未来工作主要包括以下几个方向:
1.提升消歧阶段准确率。消歧阶段对后续工作影响重大,接下来我们考虑引入更丰富的语义知识,比如类别标签等来提升消歧阶段的准确率。
2.采用更好的融合方式。目前我们使用的是简单的线性融合,以后还可以探索其他融合方式。
[1]Vishnu Vyas,Patrick Pantel,Eric Crestan.Helping editors choose better seed sets for entity set[C]//Proceedings of CIKM 2009.Hong Kong:ACM,2009:225-234.
[2]Richard C Wang,Nico Schlaefer,William W Cohen et al.Automatic Set Expansion for List Question Answering[C]//Proceedings of EMNLP 2008.USA:ACL,2008:947-954.
[3]Richard C Wang,William W Cohen.Automatic Set Instance Extraction Using the Web [C]//Proceedings of ACL/AFNLP 2009.Singapre:ACL,2009:441-449.
[4]Luis Sarmento, Valentiin Jijkoun. “More Like These”:Growing Entity Classes from Seeds [C]//Proceedings of CIKM 2007.Portugal:ACM,2007:959-962.
[5]Pasca.Weakly-supervised discovery of named entities using web search queries[C]//Proceedings of CIKM 2007.Portugal:ACM,2007:683-690.
[6]Richard C Wang,William W Cohen.Language-Independent Set Expansion of Named Entities Using the Web[C]//Proceedings of ICDM 2007.USA:IEEE Computer Society,2007:342-350.
[7]Richard C Wang,William W Cohen.Iterative set expansion of named entities Using the web[C]//Proceedings of ICDM 2008.Italy:IEEE Computer Society,2008:1091-1096.
[8]Patrick Pantel,Eric Crestan,Arkady Borkovsky,et al.Web-Scale Distributional Similarity and Entity Set Expansion[C]//Proceedings of EMNLP2009.Singapore:ACL,2009:938-947.
[9]Benjamin Van Durme,Marius Pasca.Finding Cars,Goddesses and Enzymes Parametrizable Acquisition of Labeled[C]//Proceedings of AAAI08.USA:AAAI Press 2008:1243-1248.
[10]Yeye He,Dong Xin.SEISA Set Expansion by Iterative Similarity Aggregation [C]//Proceedings of WWW 2011.India:ACM,2011:427-436.
[11]Partha Pratim Talukdar,Joseph Reisinger,et al.Weakly-supervised acquisition of labeled class instances using graph random walks[C]//Proceedings of EMNLP 2008.USA:ACL,2008:582-590.
[12]Marco Pennacchiotti,Patrick Pantel.Entity Extraction via Ensemble Semantics[C]//Proceedings of EMNLP 2009.Singapore:ACL,2009:238-247.
[13]David Milne,Ian H Witten.Learning to link with Wikipedia [C]//Proceedings of CIKM 2008.USA:ACM,2008:509-518.
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
神州·下旬刊(2019年1期)2019-02-11 06:03:50
电脑与电信(2018年12期)2018-03-23 02:37:20
中国神经再生研究(英文版)(2017年10期)2017-11-08 11:48:42
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
中文信息学报(2012年4期)2012-06-29 06:29:14
