
从Web中获取部分整体关系
2013-10-15 01:38:18曹馨宇曹存根吴昱明
中文信息学报 2013年2期
曹馨宇,曹存根,吴昱明
(1.中国科学院 计算技术研究所,北京100190;2.中国科学院大学,北京100190)
1 引言
从Web中进行知识获取已成为知识获取的研究重点之一[1-5]。知识获取的研究包括概念获取、语义关系获取、属性及属性值获取等多个方面。其中语义关系的获取一直是知识获取的研究热点。部分整体关系是一种基本的语义关系。对部分整体关系的理解是人们理解世界中一些现象的基础[6]。近年来对部分整体关系获取的研究多针对于封闭语料库。随着互联网的迅猛发展,大量的信息以电子文档的形式出现在人们面前,Web应作为部分整体关系获取的一种重要信息资源。但由于当前搜索引擎的技术限制,使人们准确、快速获得有价值信息的难度大大增加,只有18%的用户表示总能在网上搜索到需要的信息[7]。当前主流的搜索引擎都是采用关键词技术对Web信息进行组织和访问。其工作原理一般是,用户输入查询关键字提出查询请求,然后搜索引擎根据用户的查询请求在网页索引库中进行检索,最后以一定的算法将检索结果排序输出。但由于Web信息的异构性、海量性,搜索引擎的这种查询机制使得其只能检索数据,不支持语义搜索,无法提供知识[8]。且对于每个查询请求,不同的搜索引擎通常会根据其各自的匹配算法,返回与查询最为匹配的一定数量的网页,即如果查询设定的不合适,可能无法检索或检索到很少的含有我们所需知识的网页。已有工作表明,在不对检索对象本身作出改变的情况下,可以通过改变检索串,使基于语义的搜索在语言学上具有可行性[9]。因此在不改变当前搜索引擎的查询机制情况下,查询构造的优劣直接影响Web中知识的获取。我们认为好的查询请求应该具备以下两个特点:一是能索引到尽可能多的富含我们所需知识的网页;二是能够指导进一步的知识获取。故本文首先提出一种能充分表达用户查询意图的查询串构造方法,我们称这种查询串为意图查询。意图查询的构造基于部分整体关系的不同分类,使用该查询可以有针对性地从Web中检索到尽可能多的包含部分整体关系的结果,检索结果集合构成进一步获取部分整体关系的语料。然后我们利用查询的格式和检索结果中的HT ML标记信息,过滤获取的语料并从中抽取关于给定概念的候选部分整体关系。最后基于部分整体关系在自然语言表述中的特点和汉语的构词规律,计算具有相同概念的候选部分整体关系的得分,按得分高低排序候选关系。实验结果表明,我们的方法取得了较高的准确率。在前20个结果中准确率为86%,最优F值为64%。
2 相关研究
部分整体关系是一种复杂的语义关系[10]。从语言心理学角度,Winston等[11]基于part在语言学上的使用,将部分整体关系分为6类,一般称为WCH 分类:(1)部件—整体关系(component-integral object),(2)成员—集合关系(member-collection),(3)部分—团关系(portion-mass),(4)材料—物体关系(st uff-object),(5)特征—活动关系(feature-activity)和(6)地点—区域关系(place-area)。WCH分类已经成为一种普遍被接受的对部分整体关系的分类,许多学者基于WCH分类的基础,对部分整体关系的分类[12-13]形式化表示做出继续的研究[14]。Hearst[15]试图使用模式的方法从语料库中获取部分整体关系,但没有获得理想的结果。她认为这是由于表示部分整体关系的模式具有更大的模糊性。但后面的很多部分整体关系获取的研究还是基于模式的。Berland等[16]受Hearst思想的启发,利用少量的genitive模式和六个表示整体物体的概念,利用统计方法从大规模语料库中获取部分整体关系。但由于Berland等选取的模式数量和给定的整体概念较少,此算法得到的部分整体关系的实例很少,准确率较低。Girju等[17]依然受Hearst方法的启发,借助于资源 Word Net,手工获取了一些表示部分—整体关系的lexico-syntactic模式。并在基于两个表示部分和整体的名词之间的语义关系可以由名词的语义特征检测到的假设前提下,通过标注名词的语义特征,构建大量的训练集实例,利用ISS方法学习关于部分整体关系的分类规则,从语料库中获取通用的部分整体关系。
在获取中文部分整体关系方面,吴洁[18]基于模式的方法获得包含部分关系知识的例句,再进行句法语义分析,获取准概念,最后基于图论的方法构造部分整体图,将所有准概念从全局的角度进行分析验证,形成可供使用的知识库。我们[19]给出了一种领域独立的发现语料库中部分整体关系的方法。基于Winston等对于部分整体关系的分类作为标准和Hearst的方法,手工抽取表示部分整体关系的模式。根据模式从语料库中抽取表示部分整体关系的候选概念对,利用启发式规则,最终得到表示部分整体关系的概念对。但由于模式的限制,此算法很难获取一般概念之间的部分整体关系。
以上各种方法都是基于语料库的,近年来随着Web中信息量的急剧增长,研究的重点集中出现在很多从 Web中进行语义关系获取的研究。Davidov[20]给出一种从 Web中获取关于给定概念的语义关系的方法。作者利用Google从Web中搜索包含已知种子关系对出现的网页,从网页中搜索每个种子关系出现的语境,通过语境获取与给定概念相关的表示各种语义关系的模式,再次利用Google搜索引擎从Web中获取关于给定概念的语义关系。从文章中给出的试验结果可以看出,获取的每类概念的语义关系数量差别较大,且其中均没有部分整体关系。Shinzato等[2]提出利用HT ML文档中的itemization和listing标记获取候选上下位关系,通过和动词—名词的共现率等统计测量方法对其进行验证,最后通过三条启发式规则的应用很大地提高了算法的准确率。Shinzato的方法使用已经下载的8.71×105HT ML文档作为上下位关系获取的语料库。Davidov[21]针对于问答领域,从 Web中获取给定物体的属性值。Davidov从Wor d Net和Web中获取一些与给定物体相似的物体概念列表,然后检索列表中每个物体的属性值,通过比较列表中的不同物体推测给定物体的属性值的范围,从中选择或推测出所需要的数据值。对于从Web中进行部分整体关系获取的专门研究并不多。Hage等[22]提出一种基于模式的从Web中获取关于给定概念的部分整体关系的方法。该方法沿用从语料库中获取部分整体关系的方法,用 Web替代语料库,利用Google搜索引擎从Web中获取表示部分整体关系的模式,使用获取的模式和人工编纂的词典,再次利用Google搜索引擎从Web中获取部分整体关系语料,再从语料中获取给定概念的部分概念。Hage方法由于利用的词典是关于食品方面,所以只获取了关于食品领域的给定概念的部分整体关系知识。此种方法非常依赖于词典,不能扩展到独立领域的部分整体关系的获取。Hage方法中构造的查询串比较简单,不能有效地从Web中获取包含部分整体关系的语料。
3 从Web中获取部分整体关系
3.1 总体框架
从Web中获取部分整体关系方法的基本流程如图1所示。

图1 从Web中获取部分整体关系
3.2 语料获取
我们不是直接从Web中下载大量的网页将其作为关系获取的语料,而是利用搜索引擎从Web中下载与给定部分整体关系有关的检索结果,并将这些检索结果的集合作为获取部分整体关系的语料。利用搜索引擎从Web中获取语料,可以保证我们获取的语料的针对性,最大限度地从Web中获取包含部分整体关系的检索结果,即保证获取的语料中大部分包含部分整体关系。同时由于Web中网页数量是随时间推移成指数级增长的[23],利用搜索引擎利于我们随时补充和更新从Web中获取的部分整体关系,具体内容已在文献[24]中详细阐述。
从Web获取部分整体关系语料基于以下两个前提:
前提1:部分整体关系可以由其共同频繁出现的某些词体现;
前提2:可以用多个蕴含部分整体关系的概念对代表部分整体关系。
与部分整体关系联系紧密,可以体现部分整体关系的词,我们称为语境词。包含语境词和部分整体关系的语句片段,我们称为语境片段。由于语境词可以反映概念之间的关系,故构造带有语境词的查询串不仅可以从Web中获取富含大量部分整体关系的语料,同时还可以根据查询串提供的信息进一步从获取的语料中得到部分整体关系。由于这种查询可以很好地反应我们的查询意图,在本文中将带有语境词的,基于意图的查询串称为意图查询。我们首先利用已知蕴含部分整体关系的概念对S和搜索引擎,从Web中获取一定长度的语境片段Occ;其次依据前提2,计算语境片段中频繁出现的词与部分整体关系的相关度,由相关度确定候选语境词CW;再次利用Web验证候选语境词,将语境词W 和初始查询串提交搜索引擎,得到新的语境片段Occ';最后从新的语境片段中抽取意图查询Patter n,获取部分整体关系语料Cor pus。
具体步骤如下:
1)将表示同一种部分整体关系概念对直接作为初始查询串q,提交搜索引擎,取检索结果集的前k,搜索引擎会根据与查询的相关度,由大到小排序检索结果,在本算法中我们取k=100;
2)语境片段的获取包括两部分。
a.对于中文文件而言,通常一个句子表达一个相对较完整的意思[25],处于一个句子中的概念更能反映出意义上的相关性。故对查询串q返回的检索结果集的Topk文档,截取概念w和概念p所在句子,然后取句子中概念w和概念p固定长度为m的文档片段Dq为语境片段;
b.返回的网页中,搜索引擎通常会提供与查询有关的相关搜索,记检索结果中提供的相关搜索的内容为Drq;
3)对语境片段Dq和Drq分词,分别统计Dq和Drq中出现的各词的词频,由于动词和名词会表示比较明确的意义,故记Dq和Drq中出现的名词和动词的集合分别为Cq和Crq,C=Cq∪Crq;
4)取n对蕴含部分整体关系的概念对,重复1、2、3步骤,n个初始查询串组成查询集合Q;
5)计算词c(c∈Cq)与部分整体关系R的相关度。相关度高说明此词与部分整体关系联系密切。我们从以下两个方面度量词c与部分整体关系R的相关度:
(1)如果词c在查询串q的检索结果中出现次数较多,则词c与查询串q相关度高;
(2)查询同一个问题,可以构造多个查询串。词c出现在越多查询串的检索结果中,词c与这个问题越相关。
在步骤1中,我们已经将已知蕴含部分整体关系的概念对转化为初始查询串,将相关度计算公式定义为式(1)

其中,cf(q,c)为查询q的检索结果中词c出现的次数,sc(c)表示与词c相关的查询串q的数目。当词c是由搜索引擎的相关搜索提供时,即c∈Crq,δ=0.1;否则δ=0。
6)取corr val ue(c,R)值在前k之内的词c作为候选语境词,在本算法中我们取k=10;
7)查找包含候选语境词的语境片段Dq,根据其出现的频度,确定语境词c与查询q频繁出现的形式,将其中的部分概念置为*,得到查询串q′;将q′提交搜索引擎,如果返回的前m个(m=100)检索结果中出现查询串q中的部分概念,则候选语境词c是我们所需的语境词,查询串q′是从 Web中获取给定整体概念的部分整体关系的查询串。
8)将查询串提交搜索引擎,我们将匹配查询串的文档片段集合作为包含部分整体关系的语料。
3.3 候选部分整体关系获取
候选部分整体关系获取之前,首先对语料进行预处理。根据构造的意图查询可知,在检索结果中,只有与查询相匹配的字符串才包含部分整体关系知识,而根据Google检索机制,我们将检索结果中与查询匹配的字符片段用粗体加斜体的方式显示,如表1所示。根据网页中的HT ML标记,我们可以很容易地提取检索结果中与查询匹配的字符片段。这些片段中完全包含我们所要获取的部分整体关系。为提高获取的效率,对满足以下两个条件的字符片段进行过滤。
1)含有标点;
2)不完全包含查询串中关键词。
通过过滤,可以删除明显不包含部分整体关系的字符片段。如“汽车、拖拉机的构造”。
根据意图查询,字符片段中与查询中通配符*匹配的部分即为候选部分概念,与已知的整体构成候选部分整体关系。如意图查询为“汽车*的结构”,获取的字符片段为“汽车蓄电池的结构”、“汽车发动机的结构”和“汽车音箱的结构”等,通配符*匹配部分为“蓄电池”,“发动机”和“音箱”,则(蓄电池,汽车)、(发动机,汽车)和(音箱,汽车)可以作为候选部分整体关系。
3.4 部分整体关系验证
我们对获取的候选部分整体关系进行评分,分值越高,我们认为其越可能为正确的部分整体关系。我们基于以下两个假设,给出评分公式。
假设1:一个整体概念的正确部分概念应该会匹配多个查询模式;即“发动机”可以匹配“汽车*的结构”,“汽车*的功能”和“汽车*的清洗”等多个查询模式。
假设2:正确的部分概念应该会多次出现;
根据假设1和假设2,我们首先给出衡量部分整体关系ri是否成立的基准得分BaseScore,如式(2)所示。

其中f req(ri)表示关系ri出现的次数,pat f(ri)表示关系ri符合的模式数,系数θ1和θ2表示假设1和假设2两个因素的权重,即假设1和假设2对分值具有不同影响。在本文中,我们取系数θ1=2,θ2=3。在后面的实验中,我们将会对比具有不同系数的公式对部分整体关系验证的影响。
为了能得到更好的验证结果,通过对部分整体关系在自然语言中的表述形式和部分整体关系中整体概念和部分概念的观察,我们发现部分整体关系通常具有以下特征。
特征1:同一个整体概念的部分概念通常会有相似的意思。如“汽车”的部件有“变速器”、“离合器”、“传感器”、“油门”、“车门”等。
根据汉语中的构词规律,词的结尾的字往往表示词的含义。如“汽车”,通过最后的“车”字,可以推测“汽车”可能是一种交通工具。结合特征1,我们给出部分整体关系的第二个特征。
特征2:对于同一整体概念,和已知部分概念具有相同结尾的概念更可能为正确的部分概念。如已知部分整体关系(离合器,汽车),则候选关系(变速器,汽车)也可能为正确的部分整体关系。
根据特征2,我们设定修正函数ReScore对关系ri的基准得分进行调整,ReScore主要通过后缀信息调整关系ri的BaseScore值。
将所有候选关系按其基准函数值从高到低排序构成全序集合Q,则在Q中排序越靠前的关系越可能为正确的部分整体关系,其包含的后缀更可能为正确后缀,因此ReScore与位置信息成反比,定义关系ri后缀的位置函数r ank如式(3)所示。

suf(ri)表示关系ri的后缀,即其部分概念的后缀,Index(suf(rj),Q)表示与关系ri有相同后缀的关系在Q中的序号,r ank(ri)表示与关系ri的有相同后缀的关系在Q中出现的最小序号。
根据特征2,ReScore与候选关系ri中部分概念的后缀次数成正比。在此基础上定义修正函数,如式(4)所示。
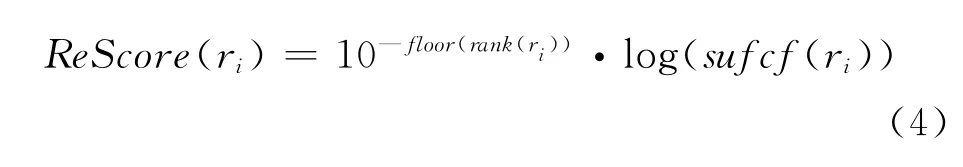
suf cf(ri)表示和关系ri有同样后缀的关系的个数。
基于基准得分BaseScore和修正函数ReScore,定义关系ri的分数Score,其计算公式如(5)所示。
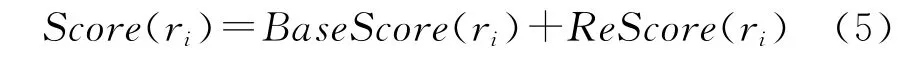
计算每个候选部分整体关系的得分,分值越大说明候选关系更可能为部分整体关系。
3.5 方法实例
我们选取Google搜索引擎,以“汽车”为已知的整体概念,根据上面所提的方法从Web中获取部分整体关系语料。
1)我们选取了10对蕴含部分整体关系的概念对,例如,(计算机 硬盘)、(相机 镜头)、(飞机 机翼)等,分别构建初始查询串,如“计算机 硬盘”,“相机镜头”等,将其提交给Google。根据语境片段获取方法,我们得到例如“计算机硬盘技术”、“计算机硬盘维修”、“专业相机所用镜头”、“相机镜头知识”、“相机镜头清洗”和“飞机机翼的作用”、“飞机机翼结构”文档片段,通过计算相关度,共得到10个候选语境词,如技术、维修、作用等;
2)根据候选语境词在语境片段中出现的频率,选取包含高频度候选语境词的语境片段。构造查询串q′,如“相机镜头清洗”、“计算机硬盘技术”和“飞机机翼的作用”,其相应查询串q′分别为“相机*清洗”、“计算机*技术”和“飞机*的作用”。通过Web验证,最终得到8个语境词,分别为使用、维修、清洗、技术、原理、结构、类型、价格。同时获取查询串为:“汽车*的<!语境词>”,<!语境词>表示语境词变量,可以替换为任意一个语境词;
3)分别构造意图查询“汽车*的使用”、“汽车*的维修”、“汽车*的清洗”、“汽车*的技术”、“汽车*的原理”、“汽车*的构造”、“汽车*的类型”和“汽车*的价格”提交Google搜索引擎,以各自返回的前100项检索结果作为语料。意图查询"汽车*的构造"的部分检索结果如表1所示。我们将所有检索结果的集合作为我们获取部分整体关系的语料;用黑体和斜体表示检索结果中与查询匹配的部分。
从获取的语料中,得到候选部分整体关系,同时统计每个候选部分概念出现的次数及满足的模式数,便于BaseScore的计算。示例如表2所示。
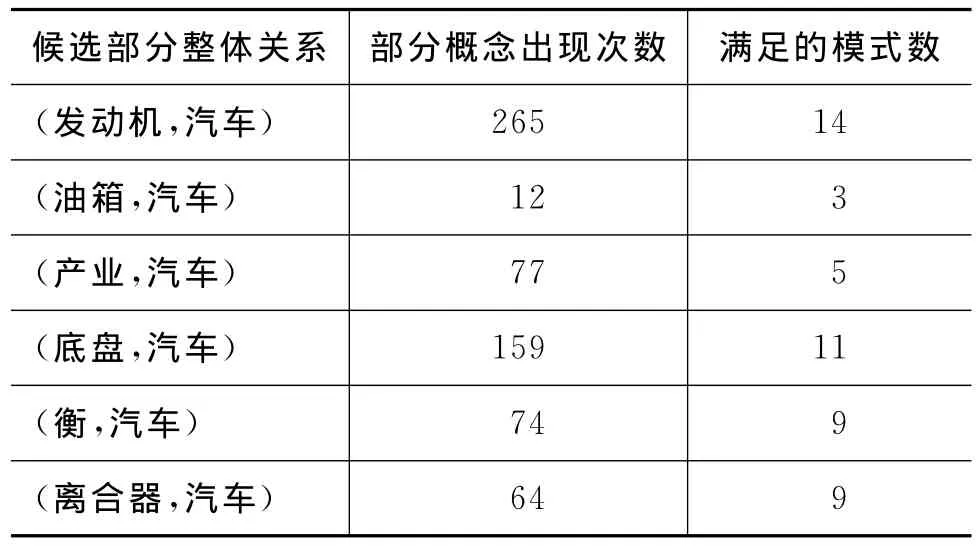
表2 候选部分整体关系实例及相关统计值
3.6 实验结果
我们选取了100个已知的部分整体关系,利用Google搜索引擎从Web中获取与其相关的部分整体关系。首先我们分别构造表示不同类型的部分整体关系的意图查询,从Web中分别下载前k个(k=100,200,300,400,500)检索结果作为受限语料,其中含有部分整体关系的语句数量如图2所示,因为前300、前400和前500中包括的含有部分整体关系语句的数量基本相同,故我们将前300检索结果作为语料。
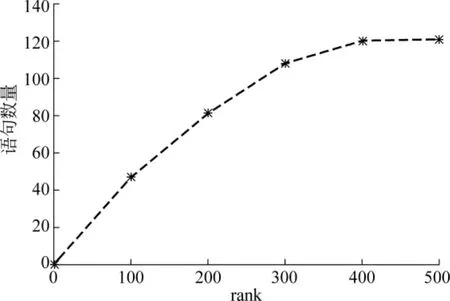
图2 语料中含有部分整体关系的语句的数量
我们计算候选关系的基准得分和加入修正函数后的得分,根据得分排序候选关系,分别考察前N个获取结果的准确率(Precision)和召回率(Recall)[26]。
图3中给出两种方法的Precision/Recall曲线,从图4中可以看出修正函数对于部分整体关系获取的准确率提高有很大的作用。
在式(2)中,我们分别取θ1=2,θ2=3和θ1=1,θ2=1,计算候选部分整体关系的分值。图4给出此两种情况下得到的关于前N个获取结果的Precision/Recall的曲线。
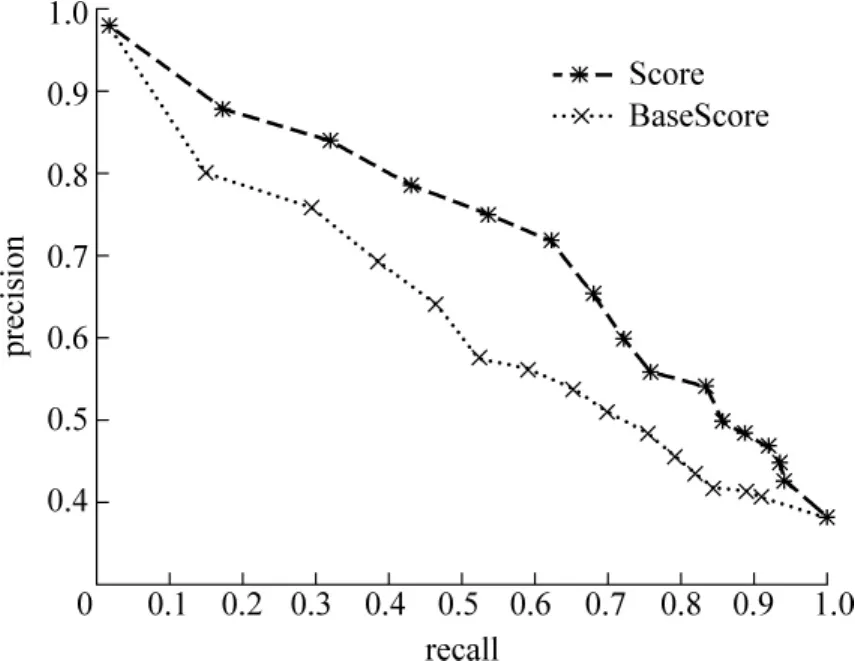
图3 Precision/Recall曲线

图4 不同系数情况下Precision/Recall曲线
从图4可以看出,用具有相等系数的公式进行评分时,结果的准确率与召回率都低于本次实验中系数不等时得到的结果的准确率与召回率。
表3获取的部分整体关系实例给出一些获取的候选部分整体关系实例、获取这些实例所用的查询、关系实例的BaseScore和Score得分。我们用yes表示此候选关系是部分整体关系,no表示不是部分整体关系。从表3获取的部分整体关系实例中BaseScore和Score值的对比,我们也可以看出修正函数对于BaseScore具有较大改善。

表3 获取的部分整体关系实例

续表
4 结束语
本文提出了一种利用搜索引擎从Web中获取部分整体关系的方法。我们构造一种基于部分整体关系分类的反映我们查询意图的查询串——意图查询,通过意图查询可以从Web中获取富含部分整体关系的语料。然后从过滤后的语料中抽取候选部分整体关系,基于部分整体关系在自然语言中的表述形式和汉语构词特点,给出验证候选部分整体关系的度量标准——Score函数,得分越高的候选关系更可能为正确的部分整体关系。本文中所提意图查询构造方法可以直接推广用于从Web中获取包含其他语义关系的语料。实验也表明我们的方法在前20个获取结果中准确率为86%,最优F值为64%。但我们的方法召回率较低,且通过对实验结果的分析,发现获取的部分整体关系实例中包含较少的自然物与其部分之间的关系。在下一步的工作我们希望通过迭代获取提高算法的召回率,通过查询串的改变获取关于不同概念的部分整体关系实例。
[1]Ser ger Brin.Extraction Patter ns and Relations fro m the World Wide Web[C]//Web DB wor kshop at 6t h Intl.Conf.on Extending Database Technology,1998.
[2]Keiji Shinzato,Kentaro Torisawa.Acquiring Hyponymy Relations from Web Documents[C]//Proceedings of the Hu man Language Technology Conference of the North American Chapter of the Association for Computational Linguistics.Boston,MA,2004:73-80.
[3]Kosuke Tokunaga,Jun'ichi Kazama,Kentaro Torisa-wa.Automatic Discovery of Attribute Words from Web Docu ments[C]//Proceedings of t he 2 Inter national Joint Conference on Natural Language Processing(IJCNL-05),Jeju Island,Korea,2005:106-118.
[4]Harith Alani,Sanghee Ki m,David E Millard,et al.Automatic Extraction of Knowledge from Web Documents[C]//Wor kshop on Hu man Language Techonology for the Semantic Web and Web Services,2nd Int.Semantic Web Conf.Sanibel Island,Florida,USA,2003.
[5]Cindy Xide Lin,Bo Zhao,Tim Weninger,et al.Entity Relation Discovery fro m Web Tables and Links[C]//Proceeding of the 19th Inter national Conference on World Wide Web.New Yor k,USA,2010.
[6]Graeme Shanks,Elizabeth Tansley,Jas mina Nuredini,et al.Representing Part-Whole Relationships in Conceptual Modeling:An Empirical Evaluation[C]//Proceedings of 23r d Inter national Conference on Infor mation Systems:ICIS 2002.2002:89-100.
[7]吴友政,赵军,段湘煌,等.问答式检索技术及评测研究综述[J].中文信息学报,2005,19(3):1-13.
[8]张森,王斌.Web检索查询意图分类技术综述[J].中文信息学报,2008,22(4):75-82.
[9]袁毓林.用同义表达形式来扩充信息检索的查询语句例证研究——对于一种基于语义的搜索方式的若干设想[J].语言文字应用.2008:123-131.
[10]Iris Madelyn,Bonnie Litowitz,Martha Evens.Problems of the part-whole relation[J].M W Evens,editor,Relational Models of t he Lexicon:Representing Knowledge in Semantic Net works.Cambridge University Press,Cambridge,1988:261-288.
[11]Winston Morton,Roger Chaffin,Douglas Her mann.A taxono my of part-whole relations[J].Cognitive Science,1987,11(4):417-444.
[12]Gerstl Peter,Pribbenow Si mone.Mid winters,end games,and body parts:a classification of part-whole relations[J].Inter national Jour nal of Hu man-Co mputer Studies,1995,43(5-6):865-889.
[13]James J Odell.Six Different Kinds of Co mposition[J].Journal of Object Oriented Programming.1994,5(8).
[14]Keet,C Maria,Alessandro Artale.Representing and Reasoning over a Taxono my of Part-Whole Relations[J].Applied Ontology.2007.
[15]Hearst Marti A.Acquisition of hypony ms from large text cor pora[C]//Proceedings of the 14th Inter national Conference on Co mputational Linguistics(COLING-92),1992:539-545.
[16]Berland,Matthew,Eugene Charniak.Findings parts in very large corpora[C]//Proceedings of the 37th Annual Meeting of t he Association f or Co mputational Linguistics(ACL 1999),1999:57-64.
[17]Girju Roxana,Adriana Badulescu,Dan I.Moldovan.Automatic discovery of part-whole relations[J].Computational Linguistic,2006,32(1):83-135.
[18]吴洁.网络文本中部分关系知识的获取与验证方法[D],华东理工大学,硕士论文,2006.
[19]Cao Xinyu,Cao Cungen,Wang Shi,et al.Extracting Part-Whole Relations from Unstructured Chinese Corpus[C]//Proceedings 4th International Conference on Natural Co mputation(ICNC'08)and 5th Inter national Conference on Fuzzy Systems and Kno wledge Discover y(FSKD'08),Jinan,China.
[20]Dmitry Davidov,Ari Rappoport, Moshe Koppel.Fully Unsupervised Discovery of Concept-Specific Relationships by Web Mining[C]//Proceedings of the 45th Annual Meeting of the Association of Co mputational Linguistics(ACL-07),2007:232-239.
[21]Dmitry Davidov,Ari Rappoport.Extraction and Approxi mation of Numerical Attributes from the Web[C]//Proceedings of the 48th Annual Meeting of the Association f or Computational Linguistics,Uppsala,Sweden,2010:1308-1317.
[22]Willem Robert van Hage,Hap Kolb,Guus Schreiber.A Method for Learning Part-Whole Relations[C]//ISWC 2006,Athens,Georgia,2006:723-735.
[23]Zakon R H.Hobbes'Inter net Ti meline[DB/OL].http://www.zakon.org/robert/inter net/ti meline/,Nov.5,2009.
[24]曹馨宇,曹存根.从 Web获取部分整体关系语料的方法[J].中文信息学报,2011,25(5):17-23.
[25]贺宏朝,何丕廉,高剑峰,等.一种基于上下文的中文信息检索查询扩展[J].中文信息学报,2002,16(6):32-37.
[26]Makhoul John,Francis Kubala,Richard Schwartz,et al.Perfor mance Measures for Infor mation Extraction[C]//Proceedings of DARPA Broadcast News Wor kshop,Her ndon,VA,Febr uary 1999.
猜你喜欢
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
海外华文教育(2016年1期)2017-01-20 08:21:58
专利代理(2016年1期)2016-05-17 06:14:36
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
质量与标准化(2010年5期)2010-05-03 04:15:40
