
一种无指导的隐式篇章关系推理方法研究
2013-10-15 01:38:14周小佩车婷婷姚建民朱巧明
中文信息学报 2013年2期
周小佩,洪 宇,车婷婷,姚建民,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州215006)
1 引言
随着对单词以及句子级别的分析研究日益深入和成熟,研究者们开始将重点转移到更大的单位,即篇章的分析中,如篇章关系识别、篇章结构分析等。其中,篇章关系是指同一篇章内部,相邻片段或跨度在一定范围内的两个片段之间的语义连接关系,如条件关系、转折关系、因果关系等。
篇章关系研究一方面有利于理解篇章文本内容,如Lin等[1]借助篇章语义关系类型实现了篇章内容的连贯性检测;另一方面,还有利于实现篇章文本结构化,如基于修辞结构理论(RST)构建篇章结构关系树[2]。而结构化关系树可用于更深层次的篇章分析,如计算篇章之间语义级的相似度等。因此,篇章关系分析是自然语言处理领域中一项重要的基础性研究。
在研究过程中,可将篇章关系分为显式篇章关系和隐式篇章关系。显式篇章关系如实例(1)所示:
(1)Arg1①Arg1和Arg2为Penn Discourse TreeBank 2.0篇章语料库中指向具有连接关系句子对的标签:The federal govern ment suspended sales of U.S.savings bonds
(译文:联邦政府终止销售美国存储债券)
Arg2:because Congress hasn’t lifted t he ceiling on govern ment debt
(译文:因为美国国会还没有提高政府债券的上限)
Discourse Relation:Contingency.Cause.Reason(篇章关系:因果关系)
其中,because即为显式连接词,且表明由它连接的Arg1和Arg2之间属于因果关系。隐式篇章关系是指片段之间未标记显式连接词,但在语义层面上确实存在某种连接关系,如实例(2)所示:
(2)Arg1:This is an ol d stor y
(译文:这是个老故事)
Arg2:[in f act]we are tal king about years ago bef ore anyone heard of asbestos having any questionable properties.
(译文:[实际上]我们正讨论数年前还没有人听说石棉有质量问题)
Discourse Relation:Expansion.Restatement.Specification(篇章关系:扩展关系)
其中,Ar g1和Arg2之间不存在显式连接词,但根据具体语义可以推断出,Ar g2是对Ar g1的详细阐述,方括号中in f act是人工添加的连接词,称为隐式连接词。
另外,2008年发布的篇章语料库PDTB(Penn Discourse Tree Bank)2.0中,将篇章关系类别由粗到细分为三层:第一层是四种主要的语义关系类别:Expansion(扩展)、Contingency(因果)、Co mparison(转折)和Temporal(时序);第二层和第三层分别针对上一层进行细分,如实例(1)中关系“Contingency.Cause.Reason”除了表示前后句子之间属于因果关系外,第三层Reason进一步区分了包含连接词的Arg2表原因,Arg1表结果。
本文的主要任务即是针对PDTB中的隐式篇章片段(语料中由Ar g1和Arg2组成的一个隐式关系实例),推理其具体语义关系类型。核心思想是基于无指导方法,将隐式篇章关系的分类问题转化为检索与排序问题,即通过搜索引擎,抽取与原隐式片段在结构和语义层面上较相近的候选显式片段;通过分析显式片段,实现隐式片段之间的关系推理。
本文组织形式如下:第2节介绍相关工作;第3节简要概括基于无指导方法推理隐式篇章关系的动机以及需要克服的困难;第4节详细介绍无指导的隐式篇章关系推理方法以及如何解决上述困难;第5节检验方法的可行性并给出了实验结果与分析;第6节进行总结和展望。
2 相关工作
由于早期篇章关系研究缺少统一规范的语料库,所以研究者们采用模板匹配的方法,从生语料中抽取显式片段,且直接去除显式片段中的连接词,人为构成隐式片段。Marcu等[3]即是通过此方法,获得训练和测试数据,然后选择数据中的单词信息(即词共现)作为基本特征进行分类。实验证明,单词特征对篇章关系的分类起相当重要的作用。另外,Saito等[4]在单词特征的基础上结合短语特征,实现日文的隐式篇章关系分类。但Sporleder[5]和Blair-Goldensohn[6]均指出,采用 Marcu方法对自然隐式片段进行分类时,往往会导致性能下降。原因是,显式片段中的连接词是为了便于上下文理解,当人为去除连接词构成隐式片段时,若缺乏足够上下文,很容易造成理解歧义。由此可见,人为构造的隐式片段在一定程度上未能真实反映隐式关系的内部特征。
PDTB语料的发布为篇章关系研究提供了有利条件。Pitler[7]等首次对PDTB 2.0进行了统计和分析,结果表明,显式关系实例中的大多数连接词不存在歧义。而且,仅采用连接词特征,显式关系的分类精确率可达到93.09%。因此,目前篇章关系研究的主要任务是解决隐式篇章关系的分类问题。Pitler等[8]通过提取句子中相关特征,如上下文特征,情感词极性,以及其他多种词汇特征实现隐式篇章关系的自动分类,并分析了不同特征对分类性能的影响。Lin等[9]实现了第二层篇章关系的分类,在单词以及上下文特征的基础上,选择添加句法树中的结构特征、依存树中词与词之间的关联特征。Zhou等[10]首次借助显式连接词进行隐式篇章关系识别,主要通过语言模型推测当前隐式片段的连接词,然后将预测出的连接词作为附加特征。与本文最相关的是,Wang等[11]使用基于树核函数的方法,自动抽取句法树中的结构信息,并结合时序信息,实现第一层隐式篇章关系的分类,其精确率达到40.0%。
3 基于无指导方法推理隐式关系的动机
由上述相关工作可知,目前针对隐式篇章关系的研究均采用机器学习的方法,选择各种有效特征对篇章关系进行分类,但最终分类性能依然偏低。这主要是由篇章中句子结构的复杂性、句子语义的歧义性以及上下文信息的不确定性造成的。因此,本文提出一种无指导的方法,将传统的检索与排序相结合,尝试解决较复杂的分类问题。前提是Pitler等[12]通过实验证明,直接利用连接词判别显式篇章关系可获得很好的性能。所以,本文把判别隐式关系的重点转移到,如何获得与隐式片段在句子结构以及语义层面上都较相近的候选显式片段。通过直接分析和应用候选片段的显式关系,达到对复杂隐式关系精确判别的目的。
为了使获得的候选片段具有广泛性和实时性,本文尝试借助Google搜索引擎,通过海量检索的方法获得较相关的候选片段。例如,针对实例(2)中隐式片段“This is an ol d story.We are tal king about years ago?”,我们通过检索,挖掘到如下候选显式片段:
(3)There's an ol d story about being self-valuable,and it is about three ol d Jewish ladies in Miami Beach,and these old Jewish ladies are tal king about their personal self-esteem
(译文:有个关于自我价值的古老故事,讲述的是有关迈阿密海滩的三位犹太女士以及她们谈论个人自尊)
(4)This is a bit of an ol d stor y.But I just wanted to make sure you knew who I was tal king about.
(译文:这是个有点古老的故事,但我只想确保你知道我在谈论谁)
尽管通过这一方式可以获得具有连接词的显式片段,但因为现有检索系统对语义相关度的度量尚不完善,使得上述检索过程往往会获得多于一种的冗余语义连接关系,比如(3)中连接词and表示并列,(4)中连接词But表示转折,两者分别代表了两种截然不同的候选关系。如何过滤冗余的连接关系,这往往取决于候选关系本身的质量以及候选显式片段与隐式片段的相似度等多个方面。鉴于此,本文提出对挖掘到的候选关系进行更深层次的质量评估,以赋予每个候选关系相应质量权重。依据权重较高的候选关系来推断隐式关系,使结果更加合理和可信。
为实现此方法,必须解决两个重要问题:1)如何从原隐式片段中提取关键信息构成高质量查询关键词,以便于在检索过程中抽取相关候选显式关系;2)如何构建推理模型以合理评估候选关系质量,进而提高最终隐式关系的推理性能。本文将会在下面章节中针对这两个关键问题给出相应有效的解决办法。
4 基于无指导方法推理隐式关系的方法
本文致力于探究一种无指导的方法,以实现隐式篇章关系的推理,图1即为方法框架,主要包括以下三个模块:
1)基于Google搜索引擎的候选关系抽取模块。从隐式关系片段中提取关键信息,构建高质量查询关键词;并从检索结果中按照一定规则抽取候选显式关系。
2)隐式关系推理模块。为了提高基于候选显式关系推理隐式关系的性能,本文构建了三种推理模型:当前显式片段与原隐式片段的相似度模型,查询关键词本身的关联度模型,以及查询关键词与当前候选关系的置信度模型。
3)基于排序学习的隐式关系判定模块。依据三种推理模型评估当前候选关系的质量,并根据质量进行排序学习;统计Top N个高质量候选关系中的类别分布,占据比例最高的关系类别即为推理出的原隐式片段的关系类型。
下面依次介绍以上三个模块的具体实现方法。
4.1 基于搜索引擎的候选关系抽取
本节主要探索如何构建查询关键词,使得更快更有效地抽取候选显式关系,以及从检索结果中抽取候选显式关系的具体方法。
4.1.1 高质量查询关键词构建
对检索而言,采用的查询关键词会直接影响检索的效率及质量,而且后续方法的展开完全依赖于检索出的显式片段。因此,为了验证实验的可行性进而提升方法的性能,本文分别从单词、二元组以及三元组的角度构建查询关键词,并从效率和质量两个方面进行了分析和比较:
· 单词(Unigram)
分别定义Ar g1:W1=<w11,w12,…,w1m>,Arg2:W2=<w21,w22,…w2n>,其中 W1和 W2分别表示Ar g1和Ar g2的单词序列。因为Ar g1和Arg2中的词汇特征为判断篇章关系提供了重要信息,所以,优先考虑采用单词对的形式构造查询关键词。本文先后使用了三种方法逐步筛选片段中的单词,以构成高质量单词对:
1)所有单词对集合:即按照笛卡尔积 W1×W2方式,构造的查询关键词集合Q={w1i+w2j}(1≤i≤m,1≤j≤n),如例句“This is an old story,we have tal king about it years ago”中,“This we”和“story talking”等都作为查询关键词。按照这种穷举方式,平均每个隐式片段构造的查询关键词数量为243。
2)去除停用词的单词对集合:Pitler等[8]通过实验证明去除停用词特征会降低分类的性能,但采用停用词构成的查询关键词进行检索时,很难匹配得到相关的显式片段。主要由于停用词的出现频率较高且未体现原片段的语义信息。因此去除Ar g1和Ar g2中的停用词,再按照笛卡尔积的方式构成单词对集合。此时平均每个隐式片段构造的查询关键词数量降为72。
3)tf×idf权重值较高的单词对集合:分别计算Arg1和Arg2中单词的tf×idf权重,选择Arg1、Ar g2中权重Top5的单词进行任意组合。此方式一方面控制了查询关键词数量,另一方面保证了筛选出来的单词普遍具有代表性,从而能够提高查询关键词的质量。
· 二元组(Bigram)
除了单词信息外,查询关键词中的词序信息同样对提高检索质量起重要作用。所以,为了在单词基础上融入词序信息,本文将查询关键词中单词替换成语言模型中的二元组即Bigra m。重新定义Arg1:B1= <b11,b12,…,b1p>,Arg2:B2=<b21,b22,…,b2q>,其中B1和B2分别是 Ar g1和Ar g2的二元组序列。因此,由B1和B2生成的查询关键词集合 Q={b1i+b2j}(1≤i≤p,1≤j≤q),如图2中“This is”+“We have”,“old story”+“hear d about”等。此时平均每个隐式片段将构造230个查询关键词。而且实验表明,包含停用词的二元组对往往能够检索到有效的显式片段,例如“This is”+“We have”等。这类包含词序信息的停用词对在一定程度上体现了句式结构信息,如“should have”表虚拟语气,出现在句子中常隐含对比的关系,这对检索相关显式片段具有促进作用。鉴于此,在采用二元组对方式构造查询关键词时保留了停用词。

图2 采用二元组对方式构建查询关键词
· 三元组(Trigram)
为了验证词序信息对检索质量的影响,本文在二元组的启发下又引入了三元组,以便进行比较。如上例中“This is an”+“We have hear d”即可作为一个三元组对实例。虽然三元组对囊括了更多的词义以及词序信息,但能同时包含此类信息的文档数目相当有限,甚至只能检索出原语料。因此,该现象严重限制了后续的候选关系挖掘。
由上述分析可知,若采用tf×idf权重较高的单词对构建查询关键词,其优点在于可以控制每个隐式片段构建的查询关键词数量。但检索过程中发现,单词对中的两个单词在检索文档中常紧密相邻,因此,不能构成上下文语句之间的连接关系。而且挖掘到的片段存在较多的噪音,例如歌名、新闻报道的标题等,这往往影响检索的质量。另一方面,若以二元组对的方式构建查询关键词,平均每个隐式片段构造的查询关键词数量偏多,造成检索效率下降。但由于二元组对比单词对包含更多的词汇和词序信息,所以,挖掘到的候选片段与原隐式片段更相关即质量更高。鉴于此,本文为了验证总体方法的可行性,在权衡效率和质量时优先选择了质量,最终以二元组对的方式构造高质量查询关键词。
4.1.2 候选关系抽取
构建高质量查询关键词的目的是抽取候选关系。而且,考虑到检索结果的摘要中包含了查询关键词及其相关上下文信息,如图3即是采用查询关键词“this is”+“any questionable”进行检索时获得的一个摘要示例。所以,本文选择直接从检索摘要中,按照自定义规则挖掘候选显式片段。

图3 查询关键词“this is”+“any questionable”的一个检索结果摘要示例
· 挖掘候选片段
在挖掘候选片段过程中,连接词起关键作用。为了确保候选片段与原隐式片段之间存在相关性,挖掘时必须同时满足以下三个条件:
1)相邻子句(句子)之间包含连接词;
2)查询关键词中来自Ar g1的二元组整体出现在连接词之前;
3)查询关键词中来自Ar g2的二元组整体出现在连接词之后。
按照以上规则,从图3的摘要示例中可挖掘出片段“While this is a public email address its tolerance for spam is extremely low.If you have any questionable ver biage,or large attach ments”。其中,if为连接词,且构成查询关键词的两个二元组“this is”和“any questionable”分别出现在由if引导的前后句子中。因此,该片段即是满足上述规则的候选显式篇章片段。
需要指出的是,若检索到相关的候选显式片段,则认为该显式片段与隐式片段之间存在一定语义上的对应关系。原因是,由以上匹配条件可知,显式片段中必须包含查询关键词,而该查询关键词则来源于原隐式片段。因此,候选显式片段与对应的隐式片段之间必然存在句法或者语义程度上的相关性。
· 判别候选关系
通过统计PDTB语料库中,各连接词在四种显式关系中的分布,证实了绝大多数连接词确实不存在歧义[12]。在此基础上,即可通过连接词特征,实现候选显式片段的关系判别。

表1 列举PDTB语料中,部分连接词在篇章关系中的分布比例/%
表1列举了部分连接词出现在四种篇章关系的比例,如and出现在Expansion类别中的比例高达96.83%,so甚至只出现在Contingency类别中。所以,针对某一连接词,本文选择其出现比例最高的关系类别作为与之对应的篇章关系。如上述显式片段“While this is public email address its tolerance for spam is extremely low.If you have any questionable...”中,连接词if在Contingency类别中的出现概率最高(95.99%),由此推断该显式片段的候选关系类型为Contingency。
4.2 隐式关系推理模型
在推理隐式关系过程中,需要评估候选关系质量以增强推理的可信度。因此,本文构建如下三种推理模型:候选显式片段与原隐式片段的相似度,查询关键词内部的关联度,查询关键词与候选关系之间的置信度。下面分别介绍这三种模型的运行机理。
4.2.1 相似度
候选片段与隐式片段在句子结构以及语义层面的相似度,能够直接体现当前候选片段的质量。本文采用了两种计算相似度的模型,具体方法如下:
· 向量空间模型
由于向量空间模型(VSM)具备利用空间相似性来逼近语义相似性的优点,所以常被用来计算文本之间的相似度。本文在用向量表示文本片段时,单词权重分别设置布尔值以及tf×idf值。tf×idf的计算方式如式(1)所示:
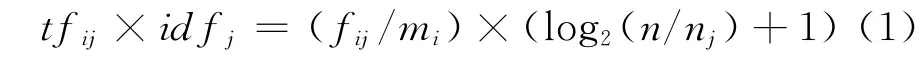
其中,fij表示单词j在句子i中出现的次数,mi是句子的长度,n是句子总个数,nj表示包含单词j的句子数。
·n-gram语言模型
基于VSM计算相似度时假设词与词之间是相互独立的,没有包含任何词序信息。而n-gra m语言模型[13]考虑了在自然语言中存在着后续单词的出现条件依赖于前面单词的现象,所以,本文尝试利用n-gram语言模型计算句子相似度。具体的计算如式(2)所示:

其中,S1和S2分别表示原隐式片段与显式片段划分成n-gram的集合,|S1∩S2|是两集合中相同的n-gram 数,|S1∪S2|则是两集合去重后的 ngram总数。
4.2.2 关联度
基于搜索引擎抽取候选关系时发现,并非所有查询关键词都能抽取到相关候选关系。即采用同种方式构造的查询关键词,在挖掘候选关系的能力方面仍然存在差异,这是由构成查询关键词的二元组相互影响的结果。若某查询关键词未能挖掘到候选关系,则说明构成当前查询关键词的二元组对不能引发上下文语义上的连接关系。例如二元组对“is an”+“about it”作为关键词检索时,两个二元组在相邻句子中共现的概率很小,导致在包含连接关系的相邻句子中共现的概率几乎为零。相反地,“anold”+“about it”作为关键词检索时却能挖掘到相对较多的候选关系,也就是说“anold”和“about it”组合时,引发上下文间连接关系的概率较高。
由此,我们定义查询关键词内部关联度,用于衡量当前查询关键词能够引发上下文连接关系的概率,间接体现查询关键词挖掘候选关系的能力。关联度不仅仅体现了查询关键词中两个二元组之间的相关程度,同时还体现了每个二元组内部单词之间的关联度,如二元组“anold”中an与old之间的关联度比二元组“is an”中is与an之间的关联度更高,这是由单词之间的共现概率决定的。
查询关键词q的内部关联度计算方法如式(3)所示:

其中,bi表示构成当前查询关键词的二元组,i=1表示查询关键词中来自Ar g1的二元组,i=2表示来自Ar g2的二元组。|S(bi)|指包含二元组bi且bi出现位置与q中位置相同的查询关键词个数,|T(bi)|是|S(bi)|集合中能够抽取到候选关系的查询关键词个数,因此|T(bi)|/|S(bi)|体现了包含二元组bi的查询关键词抽取到候选关系的概率。
4.2.3 置信度
基于搜索引擎抽取候选关系的过程中还存在另一现象:某类查询关键词检索时,会挖掘到多个候选片段,相应就可能出现多种候选关系。这一现象说明,对于此类查询关键词,构成它的二元组能够引发上下文产生不同的连接关系。如第3节中提到,采用查询关键词“ol d stor y”+“tal king about”抽取的候选关系中,除了连接词and引导的扩展关系,也有but引导的对比关系。因此,为了衡量当前查询关键词与候选关系之间的可信程度,本文构建了置信度模型。与关联度类似,置信度也是由查询关键词内部两个二元组共同影响的结果,计算见式(4):

(i=1,2且s=Ex p,Con,Com,Tem)
其中,bi表示构成当前查询关键词q的二元组,i=1,2的意义同式(3),p(s|bi)表示由包含二元组bi的查询关键词抽取的所有候选片段中,候选关系s的出现概率。
4.3 基于排序学习的隐式关系判定
借助上节中构建的三个隐式关系推理模型,可实现候选关系质量的综合评估。每个候选关系被赋予相应的质量值,计算方式如式(5)所示:

其中Si m即是相似度,Rel是关联度,Con是置信度。分母Su m1,Sum2,Sum3是对三种推理模型各自的计算值进行归一化。α,β,γ即是累加三种模型计算值时对应的权重,并满足0≤α,β,γ≤1且α+β+γ=1。
针对一个隐式片段,可挖掘出多个相应的候选显式片段,但其中存在质量的差别。本文依据它们的质量值由高到低进行排序,并统计Top N个高质量候选关系中各篇章类别的分布,从而间接实现隐式篇章关系的推理。本文基于排序学习的方法,确定最终当隐式关系推理性能达到最优时的α,β,γ以及N值,计算见式(6):

其中,p(s)表示关系类别s在隐式数据集中所占的比例,即先验概率。k是候选关系依据质量值排序后对应的位置,j是当前位置上的候选关系。bool(s,j)是判断当前位置候选关系j是否等于关系类别s,若是则bool(s,j)=1,否则为0。1/l og(k+1)是第k位置上的候选关系权重,可以看出排序位置k越靠后,对应的候选关系权重越小。
5 实验结果与分析
5.1 实验数据及评价标准
本实验选择Penn Discourse TreeBank 2.0①htt p://www.seas.upenn.edu/~pdtb/语料中23~24章节的所有隐式篇章关系实例作为数据集。表2列出数据集中四种篇章关系的分布,其中Expansion类别占据的比例最高。考虑若将数据集中所有隐式实例均判为Expansion类别,则精确率最高可达50.8%,本文将此作为Baseline系统。

表2 数据集中四种隐式篇章关系分布
为了有效评估四种篇章关系各自的推理性能,本文采用准确率(Precision)、召回率(Recall)和 F值(F-value)三项指标。另外,采用精确率(Accuracy)来衡量本文方法推理隐式篇章关系的整体性能。针对四种篇章关系推理结果,定义混淆矩阵A=其中,nij表示通过本文方法,将数据集中i类别的篇章关系推断为j类别的实例个数。所以上述评价标准的计算公式见式(7)、式(8)、式(9)和式(10)。阵中每列的和,数值上等于本文方法推断出的对应类别个数表示矩阵中每行的和,数值上等于数据集中对应类别的实例个数。
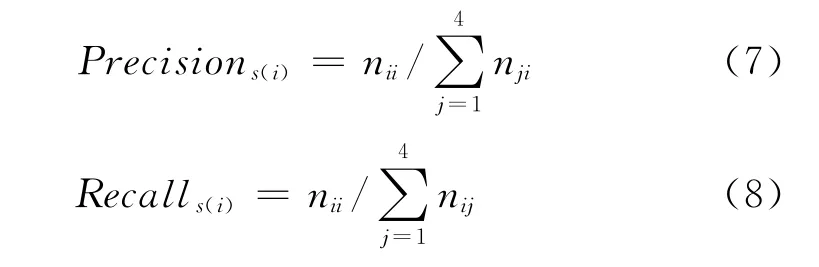

5.2 隐式关系推理模型对结果的影响
首先,由于本文方法是借助搜索引擎,通过挖掘候选显式关系,从而推理相关的隐式关系类型。因此,必须确保通过搜索引擎能够挖掘到相关显式关系。经分析,在所有的1192个测试实例中,仅有5个(0.4%)隐式实例未能检索到显式片段。造成此现象的主要原因有两个:1)该隐式篇章片段包含的信息量过少,如某些片段仅包含2~3个单词,因此构建的查询关键词数量有限,从而降低了基于搜索引擎挖掘显式篇章片段的概率;2)由该隐式篇章片段构建的查询关键词,不易引起上下文的语义连接关系。正如关联度模型中所述,某些查询关键词的两个二元组均未在显式片段中共现,因此挖掘不到相关显式片段。本文在最终性能评估时,若某隐式篇章片段检索不到相关显式片段,则认为该隐式片段的关系推理错误。但由于此现象的出现比例较小,因此,对本文方法的最终推理性能几乎没有影响。
下面主要分析三种推理模型(相似度、关联度、置信度)对最终隐式篇章关系判别性能的影响。同时,通过排序学习,确定最终取得最佳性能时的参数值。表示矩
其中

图4 采用相似度模型推理隐式关系的性能
图4表示随着Top N中N值的变化,相似度模型对最终隐式篇章关系判别性能的影响,其中包含了三种计算候选显式片段与隐式片段相似度的方法。基于VSM计算相似度时分别设置两种权重:bool值和tf×idf值。由图中可知tf×idf值的方法在总体趋势上略优于bool值,这主要是由于前者相当于后者的扩展,计算的相似度值更精确。另外,基于n-gram模型计算相似度时,选择n=2。图4表明,n-gra m模型的方法在整体性能上优于VSM方法,主要由于前者包含了上下文信息。与构造高质量查询关键词类似,n-gram不仅包含了单词特征还包含了词序特征,所以它一方面能够体现句子语义信息;另一方面也体现了句式结构信息。因此,基于n-gram模型计算句子相似度具有优势,直接导致隐式篇章关系的推理性能得到提升。
由图4还可以看出,当N值大于25时,无论采用哪种推理方式,最终的隐式篇章关系判别性能不再变化。导致这一现象的原因有两个:一是排序位置较后的候选关系权重较低,累加时对结果产生的影响较小;二是由于候选片段的个数限制,某些隐式实例抽取到的相关候选片段偏少,所以当N值增加到足够大时统计结果不再发生变化。鉴于此,在排序学习时分别设置N=1,2,…,30,并且当N=14时采用相似度模型推理隐式关系的精确率达到54.0%。

图5 采用关联度(Con)、置信度(Rel)以及综合三种模型(All)推理隐式关系的性能
图5 列出了采用关联度、置信度以及将三种模型(相似度、关联度、置信度)综合后,推理隐式篇章关系的性能。由图中可知,采用关联度(Rel)模型推理隐式关系的性能明显弱于相似度(图4)模型以及置信度(Con)模型。因为在构建模型评估当前候选关系时,候选片段与隐式片段的相似度、查询关键词与当前候选关系的置信度都属于直接评估方式。而关联度体现查询关键词内部二元组之间的相关程度,主要用来度量该查询关键词通过搜索引擎抽取到候选关系的概率,属于间接评估方式,导致推理性能不及前两者。图5中All表示综合三种模型推理隐式关系的性能,在总体趋势上,略优于三种模型各自推理隐式关系的性能。最终基于排序学习的方法,推理隐式篇章关系的精确率达到54.3%(N=21)。
5.3 隐式篇章关系的推理结果与分析
表3列举了当最终隐式关系推理精确率达到54.3%时,四种篇章关系类别分别对应的准确率、召回率和F值。从表中可以看出,扩展(Expansion)类别的推理性能远高于其他三个类别。原因是,连接词库中表示扩展类别的连接词所占比例最高,达到41.6%,直接导致检索抽取的全部候选关系中,扩展类别占了37.4%,因此该类别最终召回率较高。与之相反,因果(Contingency)类别的连接词所占比例最小,只有18.8%且该类别在抽取的所有候选关系中也仅占21.6%,所以因果类别最终的召回率较低。
另外,表3中时序(Temporal)类别的准确率偏低主要是由连接词的歧义性造成的,如连接词while在语义上既可以表示时序关系(Temporal),又可表示转折关系(Comparison),但根据while在显式篇章关系语料中的分布,由于它在转折类别中的出现概率较高(65.9%),所以当候选片段由连接词while引导时,候选关系将被判为转折类别。这直接导致候选关系中时序类别的判别精确率较低,从而影响了该类别的最终性能。
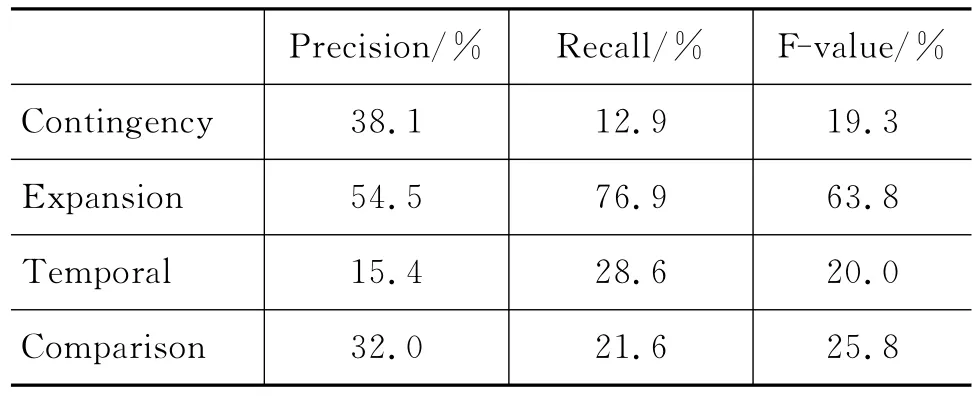
表3 各篇章关系的判别性能
表4中Baseline系统是已知数据集中篇章关系分布时,利用先验概率所能达到的最优性能(如表2)。System1是Wang等基于树核函数,抽取句法树中结构化信息以及句子之间的时序信息所达到的分类性能。由最终精确率可看出,采用机器学习方法达到的性能远低于Baseline。由此可见,针对隐式篇章关系这类较复杂的分类问题,采用有指导的方法不能显现出优势,因为复杂性的句式结构以及语义上下文之间的不确定性很难通过现有的特征进行描述。
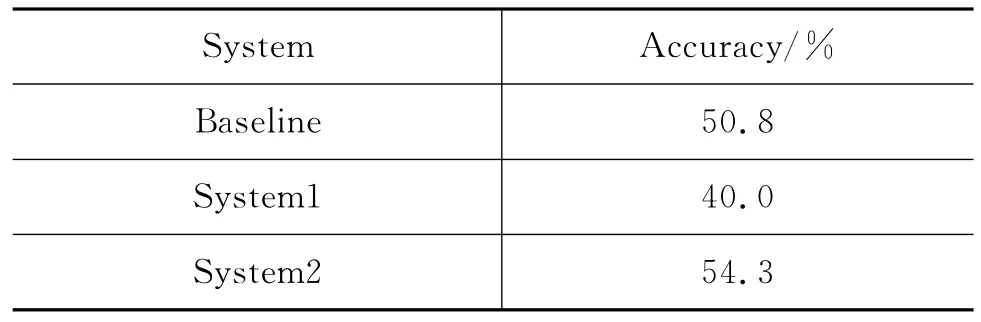
表4 系统性能对比/%
本文无指导方法的最终推理性能如System2所示,与Baseline系统相比,提高了约3.5%。虽然直观上该性能仍然偏低,但与基于句法特征、依存特征、词对特征等机器学习方法相比,本文方法提高了约14.3%。此外,由于隐式关系的判定存在一定主观性,比如“I love you”与“I hate you”之间加上不同连接词,会产生不同的语义和逻辑关系,比如,“I love you and I hate you”可同时表示扩展关系和对比关系,“I l ove you so I hate you”又可表示因果关系。因此,主观性往往造成隐式关系的实验数据本身即存在不确定性,而且现有PDTB的语料规模尚小,导致绝大部分研究性能难以达到70%~80%的近似实用化标准,此属正常现象。
本文方法的主要优势在于,借助搜索引擎将较难的隐式篇章关系推理转化为较简单的候选显式关系的分析与判别。其中无论是构建高质量查询关键词,还是构建隐式关系推理模型,都紧密结合句子结构信息以及语义相似度等多个方面。最重要的是,与System1相比,本文基于无指导的方法,除了最终推理性能具有较好的优越性外,方法本身还具有广泛的扩展性和可移植性。
6 总结和展望
本文提出一种无指导的方法,实现PDTB语料中隐式篇章关系类型的判别。由于显式篇章关系可以直接根据片段中的连接词推断,且推断性能很高,而隐式篇章关系判别仍然是相对较难的问题。鉴于此,本文尝试借助搜索引擎抽取高质量显式关系,进而由相关显式关系推理隐式关系。方法主要分为三个模块,首先解决如何从隐式片段中抽取关键信息构建高质量查询关键词,以便抽取相关候选关系;然后,构建三种隐式关系推理模型,包括候选片段与原隐式片段的相似度,查询关键词内部的关联度以及查询关键词与候选关系之间的置信度,从这三个方面综合评估候选关系质量;最后,基于学习排序的方法,统计高质量候选关系的分布比例,从而实现最终的隐式篇章关系判别。由实验结果可知,本文方法获得了54.3%的精确率,较相关工作有显著的提高。
在以后的工作中,我们将对目前方法进行继续深入和细化,为了提高查询关键词检索候选关系的效率,我们将尝试从大量查询关键词中提取特征(如本文中提及的关联度信息)构建分类器,过滤抽取候选关系能力较弱的查询关键词,从而提高检索效率。另外,在进一步提高第一层隐式篇章关系推理性能的基础上,细化到关系的第二层,实现更细粒度的篇章关系推理。
[1]Z Lin,H T Ng,M Y Kan.Automatically Evaluating Text Coherence Using Discourse Relations[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies,2011,Volu me 1:997-1006.
[2]乐明.汉语篇章修辞结构的标注研究[J].中文信息学报,2008,22(4):19-23.
[3]D Marcu,A Echihabi.An Unsupervised Approach to Recognizing Discourse Relations[C]//Proceedings of the 40th Annual Meeting on Association for Co mputational Linguistics,2002:368-375.
[4]M Saito,K Yama moto,S Sekine.Using Phrasal Patterns to Identif y Discourse Relations[C]//Proceedings of the Human Language Technology Conference of the NAACL,2006,Co mpanion Volu me:133-136.
[5]C Sporleder,A Lascarides.Using Auto matically Labelled Examples to Classify Rhetorical Relations[J].An assess ment,Natural Language Engineering,2008,14(3):369-416.
[6]S Blair-Goldensohn,K R Mc Keown,O C Rambow.Building and Refining Rhetorical-Semantic Relation Models[C]//Proceedings of NAACL HLT,2007:428-435.
[7]E Pitler,M Raghupathy,H Mehta,et al.Easily identifiable discourse relations[R].Technical Reports(CIS),2008:884.
[8]E Pitler,A Louis,A Nenkova.Auto matic Sense Prediction for Implicit Discourse Relations in Text[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th Inter national Joint Conference on Natural Language Pr ocessing of the AFNLP,2009,2:683-691.
[9]Z Lin,M Y Kan,H T Ng.Recognizing Implicit Discourse Relations in the Penn Discourse Treebank[C]//Pr oceedings of the 2009 Conference on Empirical Methods in Natural Language Pr ocessing,2009,Volume 1:343-351.
[10]Z M Zhou,Y Xu,Z Y Niu,et al.Predicting Discourse Connectives f or Implicit Discourse Relation Recognition[C]//Proceedings of the 23rd Inter national Conference on Co mputational Linguistics:Posters,2010:1507-1514.
[11]W T Wang,J Su,C L Tan.Kernel Based Discourse Relation Recognition with Temporal Ordering Information[C]//Proceedings of the 48th Annual Meeting of the Association f or Co mputational Linguistics,2010:710-719.
[12]E Pitler,A Nenkova.Using Syntax to Disambiguate Explicit Discourse Connectives in Text[C]//Proceedings of the ACL-IJCNLP Conference Short Papers,2009:13-16.
[13]G Kondrak.N-gram Si milarity and Distance[C]//String Processing and Inf or mation Retrieval,2005:115-126.
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26 22:28:29
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
专利代理(2016年1期)2016-05-17 06:14:36
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
质量与标准化(2010年5期)2010-05-03 04:15:40
质量与标准化(2010年3期)2010-05-03 04:15:36
外语学刊(2010年4期)2010-01-22 03:33:52
