
基于结构化学习的语句压缩研究
2013-10-15 01:38:12张永磊王红玲周国栋
中文信息学报 2013年2期
张永磊,王红玲,周国栋
(苏州大学 自然语言处理实验室,江苏 苏州215006;苏州大学 计算机科学与技术学院,江苏 苏州215006)
1 引言
随着网络的普及,我们每天接触的信息越来越多;如何能够在有限的时间内掌握更多有用的信息越来越引起人们的关注。文档的自动摘要作为目前的热门研究课题,是解决这一问题的有效途径之一。而作为自动摘要的重要组成部分,语句压缩除了应用于自动文摘外,在其他方面也有较广泛的应用。例如,Corston-Oliver[1]将文本压缩后显示在 PDA、手机等设备的小屏幕上。Vandeghinste&Pan[2]则在删除冗余的和非重要信息的同时保留话题主要论点,从而生成对话标题。语句压缩的另一个较早的应用是使用在盲人语音阅读设备上[3],文本经过压缩后再使用语音机器加快阅读速度,使得盲人的阅读方式类似于正常人的快速阅读方式。
语句压缩广义上可以定义为:给定一个句子,生成对应的一个句子,生成的句子满足以下三个条件:比源语句短;保留源语句的重要信息;符合语法规范。在先前的工作中,人们主要采用删除单词、插入单词、改变词序、替换单词等方法进行语句压缩。其中删除单词法是目前大多数系统采用的方法,如Knight&Marcu[4],Riezler等[5],Mc Donal d[6]等,即只考虑从源语句中删除单词与短语,这也是本文所采用的方法。在这个方法中,语句压缩可被定义为生成源语句x=l1,l2,……,ln的一个子串y*=c1,c2,……,cm的过程,其中,ci∈{l1,l2,……,ln};假设F(ci)表示ci在源语句中对应单词的序号,则F(ci)<F(ci+1),即在语句压缩的过程中不改变词的顺序。
目前针对语句压缩的研究才刚刚开展,存在着压缩结果不尽如人意、缺乏统一的评价标准等问题。本文将语句压缩看成一个结构化学习的过程,即在源语句的句法树上学习一棵子树作为其压缩后的语句(见图1)。同时,本文还提出了两种自动评测指标来评价压缩结果。
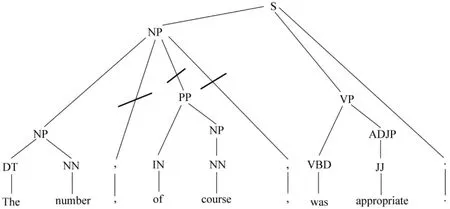
图1 语句压缩实例
本文的主要内容如下:第2节是相关工作的介绍,介绍了在基于单词删除框架下的语句压缩的方法及其不足;第3节是结构化学习方法的相关介绍;第4节是我们的主要工作,在这一部分我们主要介绍解码方式、丢失函数、特征的选择以及我们采用的评测方法;第5节实验与评测结果;第6节结论与未来工作。
2 相关工作
在语句压缩研究中,Knight&Marcu[4]的贡献是具有开创性的,他们首次将噪音信道模型和决策树模型用于语句压缩中,并提出了后来被广泛使用的评测指标:I mportance(重要性)、Gra mmaticality(语法符合度)和Co mpression Ratio(压缩率)。在其使用的噪音信道模型中,通过最大化目标语句的条件概率查找最优的目标语句。该方法的效果很好,但仍存在一些缺点:第一,该模型中用于表示目标语句生成概率的原模型,是使用未压缩的语句训练得到,因此造成了数据的不准确;第二,训练信道模型需要将源语句句法树与目标语句句法树对齐,由于句法分析器的可靠性等问题会导致源语句与目标语句句法树中有大量的错误,这使得句法树的对齐非常困难,最终导致信道模型概率的可靠性降低。
Knight和Marcu[4]提出的另一种决策树模型是通过学习源语句的句法树转换成目标语句的句法树的决策过程。在该过程中定义了四种操作:SHIFT(将当前输入队列的队首单词移到栈中)、REDUCE(移除栈首的k个句法树,并联合生成一个新的句法树,并将其重新放入栈中;在这里是用于生成目标语句的句法树)、DROP(从输入列表中对应句法成分的词的子序列中删除)、ASSIGNTYPE(修改栈顶句法树的标签,如词在源语句中的词性与在目标语句中的词性不同)。压缩以一个空栈和一个由源语句的句法树组成的输入队列开始,基于栈中保留的成分与单词和已经生成的部分的目标语句的特征,进行学习什么时候该使用哪个操作。该方法避免了噪音信道模型中句法树对齐带来的不可靠性,但是,该方法仅使用保留节点与删除节点的句法特征,没有使用词与词性层的二元或三元文法等特征,所以,该模型会生成短而不符合语法的目标语句。
Mc Donal d[6]抽取了词、词性、句法结构信息等特征,使用最大边缘学习算法学习每个特征的权重,最后查找目标语句集中最优目标语句。Mc Donald的工作取得了非常好的评测效果。我们对其研究做进一步的分析后发现,采用二元文法丢失函数的效果比采用一元文法的好。
3 结构化学习方法
对于结构化学习的问题,通常可以使用在线学习算法解决,如感知器、MIRA(mar gin-inf used relaxed algorith m)、Str uctured SV M 等。本文使用Str uct ured SV M,即支持结构化输出的支持向量机学习算法[7]。Str uctured SV M支持自定义丢失函数,这也是它对语句压缩和其他文本生成问题最大的吸引力。
传统的SV M是通过学习一个最大超平面将二元或多元分类问题分割开;同样,对于Str uctured SV M也是通过学习一个最大超平面将正确的结构与其他结构分割开。该学习算法的目标函数如式(1):
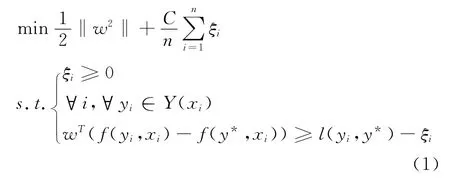
其中,ξi是训练语料中的实例对(xi,y)对应的松弛变量,C为常量,y*是实例xi的标准目标语句,l(yi,y*)是预测目标yi与标准结果y*相比的丢失值。
训练过程中,主要就是查找目标集合中具有较高得分和较大的丢失值的目标语句,即查询以下两个函数任意一个的最大值:
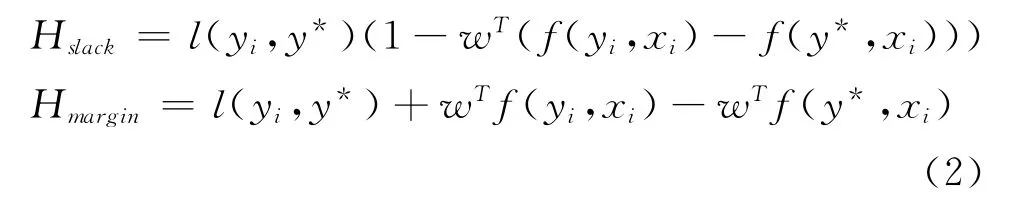
其中,下标sl ack表明训练过程中重定位松弛变量ξ,mar gin表示训练过程中重定位最大边缘。对于任意实例,当w特定时,wTf(y*,xi)为定值,所以式(2)可化简为式(3)形式:
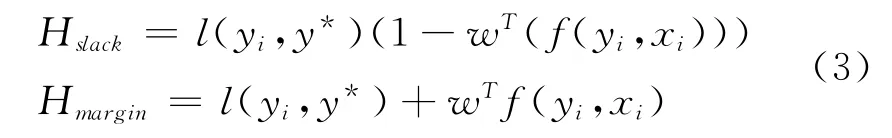
Tsochantaridis[7]分别使用了这两种函数进行实验,得到的结果性能相差并不大。因此在本文实验中,采用函数。另外,通过式(3)我们发现对于查找目标函数的最优值,可以通过扩展解码函数来实现,即在解码过程中增加丢失函数值。
对于目标函数(1)的优化问题,Tsochantaridis提出的算法大大降低了时间复杂度。该算法在每一轮迭代的过程中仅增加当前最大违反规则的限制条件,即当前实例的解码空间中与标准目标语句相比具有最高的得分与丢失值之和。
4 基于结构化学习的语句压缩
本文所采用方法的系统框架如图2所示。在此,我们将语句压缩看作是基于特征权重的最大边缘训练过程,即结构化学习过程。在实验中我们主要抽取了源语句x转换为目标语句y的相关特征,因此使用f(y,x)表示特征函数。这样解码就是一个求解线性最优问题,如式(4)所示。
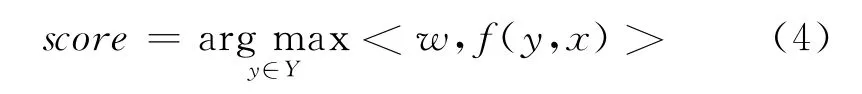
其中,Y是x的解码空间集,y为解码空间集中的最优目标语句,w为特征权重。
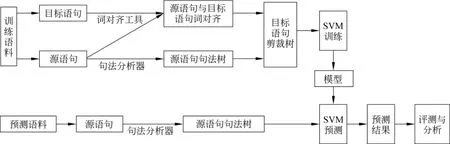
图2 基于结构化学习的语句压缩方法框架
4.1 解码
根据上面的介绍解码问题是一个线性规划问题。但是对于语句压缩问题的解码空间非常大,假设源语句x有n个单词,则它的目标语句集有2n个元素,随着单词数的增加,解码空间成指数级增长;算法1:解码算法在这样大的解码空间中,查找最优的目标,时间复杂度非常大,所以本文采用Mc Donald使用的简化的解码方法,具体算法如算法1,该算法的时间复杂度为O(n3)。在此算法中我们可以通过限定查找过程中变量len(即目标语句长度)的上限来限定压缩率的上限,则算法的时间复杂度为O(n2×len)。

4.2 丢失函数
0-1丢失函数是最简单的丢失函数,即当预测语句与标准目标语句不同时为1,相同时为0,但是这种简单的丢失函数无法明确表示预测语句与标准目标语句的差异性大小。在实验中我们分别测试了基于单词丢失比例以及二元文法丢失比例的丢失函数,结果表明二元文法丢失具有较好的性能,二元文法丢失函数在实验中定义如式(6):

其中,|B(y)|为语句y的二元文法,Max为求两个数中的最大数。
实验过程中,我们也测试了 Mc Donal d[6]所采用的丢失函数,即以预测出的语句与标准目标语句之间错误删除的单词数与错误保留的单词数的和为丢失函数。结果表明,采用该丢失函数的效果比采用的二元文法丢失的效果差,因此,在以后的实验中我们均默认使用二元文法丢失函数。
4.3 特征集
由于目前针对语句压缩还没有大规模的人工标注语料,所以选择合适的特征空间非常困难。经过反复的测试与对比,我们最终抽取了词和句法两方面的特征(表1)。在以后的工作中我们还将进一步对特征空间的选择进行研究。
4.3.1 词特征
实验中我们主要使用的词特征有:保留的单词的词性二元文法(DT&NN、NN&VBD等)、保留单词是否为停用词(Is Stop(t he)=1)、删除单词为动词、删除单词是否为源语句的中心词等。
实验中我们发现词汇级特征很容易导致数据稀疏和过度拟合问题,所以在实验中很少使用词汇特征,主要使用词性级特征。
4.3.2 句法特征
词特征不包含词在语句中的特征,如删除从句中的动词与主谓语动词是不一样的,因此这些信息起到了重要作用,所以我们提取了词在句子结构中的相关特征。
句法结构是自然语言处理中非常重要的信息,对于语句压缩句法结构信息有很大的指导性,这也是我们将语句压缩看做句法树的剪枝操作的原因。首先加入的是删除边的信息(如:NP——PP)指示当前节点被删除及其父节点的标签。在通过分析语料后,我们发现大量的从句以及介词短语会被删除,所以又加入了被删除的SBAR节点与其中心词词性的联合信息(如:SBAR&WP)、被删除的PP节点与其中心词词性的联合信息(如:PP&IN)两类特征。最后加入了被删除的节点与其父节点的结构框架(如图1中的实例:对于PP节点NP(NP,PP-D))等特征。
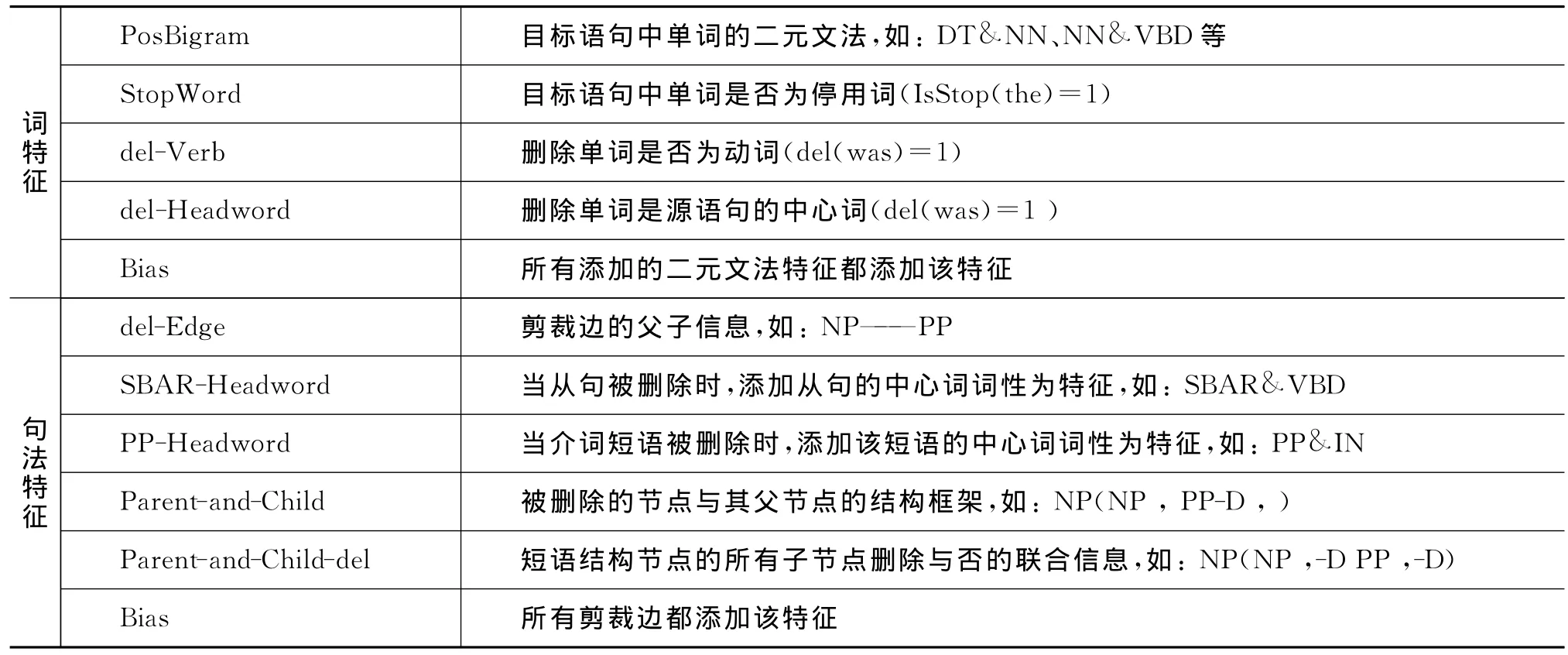
表1 特征表(以图1为例说明)
4.4 评测指标
到目前为止,对于语句压缩性能的评价,大都采用人工评测指标,还没有较好的自动评测指标。尽管人工评测具有较准确、可靠的优势,但也存在以下缺陷:首先,测试语料较大时,人工评测的工作量很大,测试语料较小时,人工评测的可信度较小;其次,人工评测的主观性较大,不同评测人员的评测结果没有比较意义。因此,本文提出了两种自动评测方案,以弥补人工评测的不足。而本文的实验结果最终采用了人工评测与自动评测结合的方式进行评测。
4.4.1 人工评测指标
在之前的工作中,语句压缩主要采用以下人工评测指标进行评测:
·Importance:压缩语句保留源语句重要信息度。
·Grammaticality:压缩语句的语法结构。
通常使用5分制给压缩后的目标语句的Importance和Grammaticality评分,最后统计分析。
4.4.2 自动评测指标
根据以上语句压缩的定义可知,语句压缩的性能主要是需要评测目标语句是否符合语法、保留源语句中重要信息度和压缩率等。所以,在我们的实验中又采用了以下的自动评测指标:
·压缩率:即源语句中单词在目标语句中保留的比例。压缩率是语句压缩目前唯一公认的自动评测标准,具有可对比性。但是,我们不能一味的追求高效的压缩率,通常压缩率越低,目标语句所包含的信息量会越少。目前,大多数的压缩系统的压缩率都是在60%左右。在我们的工作中,对压缩率的要求是达到人工压缩的同等水平,然后再追求其他评测标准较好的效果。
·N-Gram文法:即目标语句的N-Gram文法值。语言模型是自然语言处理的重要模型,应用非常广泛。在之前的工作中,有的将N-Gram文法值作为语句压缩的特征,在这里,我们使用N-Gram文法作为评测语句压缩的一个评测指标。由于NGram模型的构造需要大量的数据,所以,我们没有自己构造N-Gram模型,而是使用微软公司提供的N-Gra m网络服务接口①http://research.microsoft.com/en-us/collaboration/f ocus/cs/web-ngram.aspx。实验中我们统计了四元文法值,该项评测指标值越低表明目标语句的文法越好。
·BLEU(相似度):即目标语句与标准目标语句的相似程度。BLEU是机器翻译中最基本的评测指标。由于我们的语句压缩仅作单词删除操作,所以,可以使用BLEU进行评测。在实验中,我们使用BLEU进行相似度比较,计算到四元文法,该项指标值越大表明目标语句与标准目标语句越接近,即值越大性能越好。
在Cohn[8]的工作中还采用了丢失函数值作为自动评测指标,本文使用的丢失函数是基于词的二元文法丢失,在我们使用BLEU评测指标中已经使用了二元文法,所以,在自动评测中不再使用丢失函数作为评测指标。
5 实验
5.1 实验设置
实验中,我们使用的是爱丁堡大学的written平行语料,该语料来自于82个文件包含了1622组平行语句,且该语料仅进行单词删除,其中1250组语句用作训练语料,70组语句用作开发语料,302组语句用作测试语料。根据前文的介绍,我们首先需要对语料中的源语句集进行句法分析,使用的句法分析器是来自于斯坦福大学的开源工具Stanf or d-Parser②htt p://nlp.stanfor d.edu/soft ware/lex-parser.sht ml。在对平行语料做单词对齐时,实验中我们使用的是自己编写的词对齐代码,当然也可以使用Giza++、Ber keley Aligner等工具(我们的初步实验发现,Giza++、Ber keley Aligner工具在做相同语言的单词对齐时效果并不是很好)。
经过以上处理后,我们使用SV Mstruct③htt p://download.joachi ms.or g/sv m_str uct/current/sv m_str uct.tar.gz工具学习特征权重,本文在训练过程中,将收敛性ε设置为10-4。
5.2 基准系统
在实验中,我们建立了一个简单的基于规则的语句压缩系统作为基准系统(Baseline),用于和基于结构化学习方法的语句压缩进行效果对比。在这里,我们也是采用在成分句法树上做剪枝操作,主要用到以下简单的规则:(1)对于引用语从句只保留引用语;(2)删除表示时间地点等的状语从句;(3)删除部分介词短语;(4)删除名词的修饰语(包括定语从句、介词短语等);(5)删除插入语等(如表2中实例,这些实例都是从测试语料中抽取的)。这些规则都是我们通过观察大量语句的实例得来的,需要说明的是,这些实例不是来自于本文采用的实验语料written平行语料,而是来自于TAC2008中的语句,这是为了能够分析基于规则系统的规则是否具有普遍适用性。

表2 测试语料实例
基于规则的语句压缩对于特定的领域具有较强的适应性,但是它存在很多缺点:(1)规则归纳不方便;(2)规则的普遍适用性较差;(3)自然语言非常灵活且时刻在发展,规则通常无法适应新的语言特征;(4)可归纳的规则非常多;(5)不同领域对语句压缩要求不同等。
5.3 实验结果分析
表3和表4分别是我们实验的人工评测和自动评测结果。表中,Baseline表示基准系统的结果;Str uct ured SV M表示的是基于结构化学习系统的结果;Golden项表示人工标注结果,即标准结果。CR表示压缩率,N-Gram表示4-gra m得分,BLEU表示四元文法相似度。
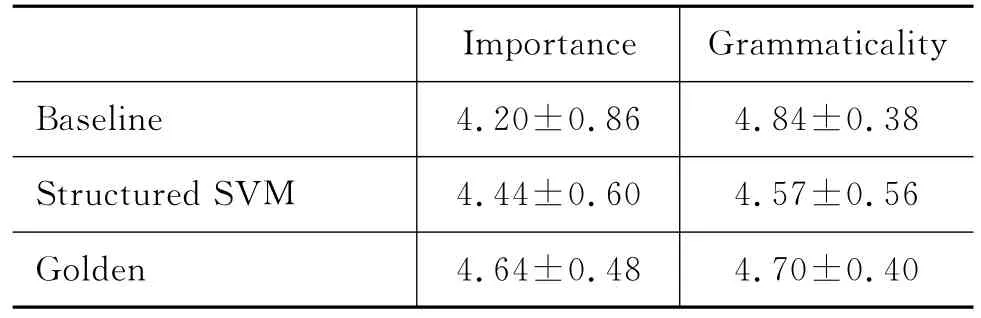
表3 人工评测结果
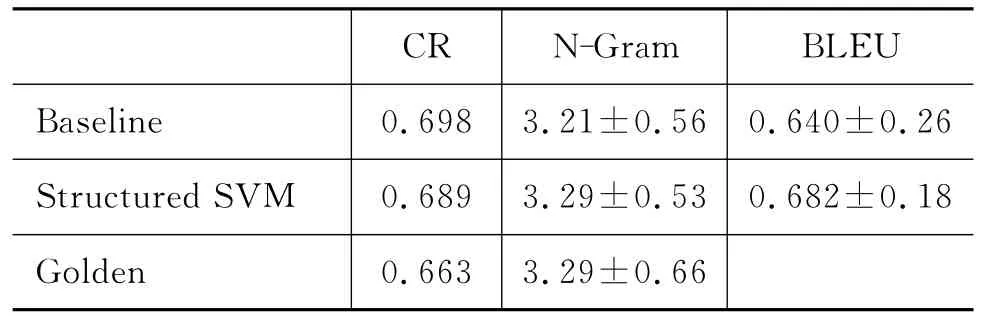
表4 自动评测结果
仔细分析表3和表4的评测结果,我们可以发现:
(1)从表3可知,基于规则方法的结果在语法结构方面能够有较好的效果,原因是规则由人工制定,大多来自对语句句法结构的人工分析,因此使用规则基本不会破坏句子本身的语法结构。
(2)从表3可知,基于结构化方法的结果在句法结构上效果较差,但在信息度的保留上具有较好的结果,优于使用规则的方法。
(3)从表4的N-Gram项可以看出基于规则的方法在文法值上有很好的效果,优于其他两个结果,甚至比标准结果还好。这与人工评测中(表3的Grammaticality项)的结论是一致的。
(4)从表4的BLEU项可以看到基于结构化方法的相似度值较高,本文认为标准目标语句保留了源语句的主要信息,则基于结构化方法的相似度评测较高时,其信息度也较高,这与表3中I mportance指标完全一致,所以,BLEU在我们的实验框架中可以评测信息的保留度。
(5)从表3、表4的各项评测结果可以发现,基于结构化方法在保持较好压缩率的情况下能够保留源语句的主要信息。
由以上分析可知,在我们的实验框架下,基于结构化方法相对于规则方法而言有较优的性能。其次,实验结果也证明了使用N元文法和BLEU相似度等自动评测指标,可以有效地对语句压缩结果进行评测。
6 结论与展望
本文将语句压缩看作是基于特征权重的最大边缘训练过程,使用基于结构化学习的方法来实现语句压缩,该方法是在一种最普遍易行的基于单词删除的语句压缩框架下。在该框架下,本文还提出了两个自动评测指标(BLEU、N-Gram)对结果进行评测。实验结果表明,采用结构化学习的方法进行语句压缩,能在保持较好的压缩率的情况下保留源语句的主要信息,且提出的两个评价指标能够有效反映语句压缩性能。
在我们的工作中,由于使用的特征集合比较小而且也是最简单的,这限制了语句压缩性能的提高。在下一步工作中,我们将进一步探讨语句压缩的特征工程,同时也将进一步思考更好的自动评测指标等。
[1]Corston-Oliver,Si mon.Text Co mpaction f or Display on Very Small Screens [C]//Pr oceedings of the NAACL Wor kshop on Auto matic Su mmarization.Pittsburgh,PA,2001:89-98.
[2]Vandeghinste V,Pan Y.Sentence co mpression for auto mated subtitling:a hybrid approach[C]//Marie-Francine Moens,S.S.(Ed.).Text Su mmarization Branches Out:Proceedings of the ACL-04 Wor kshop,Barcelona,Spain,2004:89-95.
[3]Grefenstette G.Producing Intelligent Telegraphic Text Reduction to Provide an Audio Scanning Service for the Blind[C]//Hovy,E.,&Radev,D.R.(Eds.),Proceedings of the AAAI Sy mposium on Intelligent Text Su mmarization,Stanf ord,CA,USA,1998:111-117.
[4]Knight K,Marcu D.Summarization beyond sentence extraction:a probabilistic approach to sentence compression[J].Artificial Intelligence,2002,139(1):91-107.
[5]Riezler S,King T H,Cr ouch R,et al.Statistical sentence condensation using ambiguity packing and stochastic disambiguation methods f or lexical-f unctional grammar[C]//Hu man Language Technology Conference and the 3r d Meeting of the Nort h American Chapter of t he Association f or Co mputational Linguistics,Ed monton,Canada,2003:118-125.
[6]Mc Donald R. Discri minative sentence compression with soft syntactic constraints[C]//Proceedings of the 11th Conference of the European Chapter of the Association f or Computational Linguistics,Trento,Italy,2006:297-309.
[7]Tsochantaridis I,Joachi ms T,Hof mann T,et al.Lar ge margin met hods for str uctured and inter dependent output variables[J].Journal of Machine Learning Research,2005,6:1453-1484.
[8]T Cohn,M Lapata.Sentence Compression as Tree Transduction[J].Jour nal of Artificial Intelligence Research,2009,34:637-674.
[9]江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,22(5):84-89.
猜你喜欢
家庭影院技术(2021年2期)2021-03-29 07:19:02
家庭影院技术(2021年1期)2021-03-19 05:14:58
西部蒙古论坛(2021年4期)2021-03-02 11:33:18
中国自行车(2018年11期)2018-12-03 08:20:30
High Technology Letters(2017年2期)2017-06-27 08:09:22
中国自行车(2017年1期)2017-04-16 02:54:06
海外华文教育(2016年1期)2017-01-20 08:21:58
High Technology Letters(2016年3期)2016-12-05 07:01:07
学生天地(2016年26期)2016-06-15 20:29:39
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
