
改进的维吾尔语Web文本后缀树聚类
2013-10-15 01:38:24邹志华田生伟冯冠军
中文信息学报 2013年2期
邹志华,田生伟,禹 龙,冯冠军
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046;2.新疆大学 软件学院,新疆 乌鲁木齐830008;3.新疆大学 网络中心,新疆 乌鲁木齐830046;4.新疆大学 人文学院,新疆 乌鲁木齐830046)
1 引言
聚类作为一种自动化程度较高的无监督机器学习方法,近年来在信息检索、多文档自动文摘等领域得到了广泛的应用。文本聚类基于以下假设:同类的文本相似度较大,不同类的文本相似度较小。
Za mir提出了后缀树聚类(Suffix Tree Cl ustering,STC)算法,通过识别不同文档之间的共享短语对文本聚类,其时间复杂度为O(Nl og N)。STC算法基于文档集的后缀树模型(Suffix Tree Model,ST M),其考虑到了词之间的邻近顺序关系,产生了比较好的聚类效果。相比向量空间模型,STC算法有很多优点:(1)广义后缀树将文本表示成一定的词组的集合,能保持原文本的语义结构并提高比较的准确度和效率。(2)基于广义后缀树的文本聚类算法可以较容易的提取聚类结果的类别标识。(3)STC是一种软聚类算法,允许一个文档属于几个不同的类别。但STC算法存在一定不足:(1)不能有效处理文本数目差距很大但具有包含关系的节点。(2)文本相似但其主题不同的聚类节点可能被合并到同一个聚类中。(3)缺乏有效的类别标识选择算法。
本文主要探讨了改进的后缀聚类算法在维吾尔语Web文本聚类中的应用。第1节为引言,分析了传统的后缀树聚类的优势与不足;第2节介绍了后缀树聚类及其改进算法的相关研究;第3节着重介绍了改进的维吾尔语Web文本后缀树聚类STCU算法;第4节给出了评价标准并对实验结果进行了分析;最后,对研究工作做出总结和展望。
2 相关工作
Weiner[1]首次提出了线性时间的后缀树建树算法。Mc Creight[2]在此基础上提出了更为节约空间的算法。Ukkonen[3-4]提出了改进的线性时间建树算法,它易于理解且具有在线特性。Gusfield[5]对Ukkonen的后缀树算法进行了详细的阐述。在实际应用中,Ukkonen提出的算法得到了广泛应用。
现阶段,对于文本聚类和后缀树聚类的相关工作已经有了广泛而深入的研究。文献[6]对文本聚类进行了综述。对于 Web文本,文献[7]提出了通过二次特征提取和聚类的方法,将Web文本按照主题进行自动聚类。文献[8]提出了一种新的基于主题的文本聚类方法:LFIC,能准确识别文本主题并根据文本的主题对其进行聚类。文献[9]应用LDA模型进行文档的潜在语义分析,将语义分布划分成低频、中频、高频语义区,采用文档类别与语义互作用机制对聚类结果进行修正。Zamir[10-12]首次提出了STC算法,利用短语来发现文档,通过抽取片段中的短语作为标签,提高了算法的性能,比AHC,K-means等传统算法要好。文献[13]在聚类过程利用语义相似度,改善了STC方法,采取了有效的启发式方法进行结果聚类,通过语义相似度,减少了后缀节点和分支。文献[14]比较了两种文本后缀树模型抽取短语的方式,讨论了表示模型和相似度计算方法,并研究了计算算法。文献[15]提出新的后缀树聚类方法NSTC,采用了新的相似度计算方法对后缀树相似度测量。文献[16]提出了语义后缀树聚类SSTC并构建了语义后缀树,利用Wor d Net数据库进行语义相似度和字符串匹配,通过剪枝减少子树规模来分离语义类。文献[17]利用后缀数组发现核心短语,采用了矩阵奇异值分解提高聚类精度。文献[18]改进了短语打分公式,将STC应用到层次聚类。文献[19]在聚类之前就产生好的标签,在生成了标签的基础上,再进行检索结果聚类。文献[20]利用后缀树文档模型的后缀树的快速匹配,实时获得文本的向量表示,不需要对文本进行分词、特征抽取等复杂计算。文献[21]提出了使用后缀树聚类算法优化K-means文档聚类初始值的快速混合聚类方法STK-means。文献[22]针对 Web文档的结构及其特征,提出了一种新的加权后缀树聚类方法WSTC。文献[23]使用改进的后缀树算法用于中文网页聚类,结合了中文的语言特性,采取了新的单元选择原则和新颖的后缀树构造策略。文献[24]通过去除同义词、近义词、相同句子的方法对文本进行降维处理,并查询关键字与文本的相似度,对文本打分来降低STC的时间复杂度以提高STC聚类准确率。文献[25]提出了适合中文 Web信息搜索结果的后缀树聚类算法,采用有效的策略解决了类别描述问题,利用短语类语义层面的相似性合并同义短语类,有效地改善了聚类结果的质量。文献[26]结合STC算法和变色龙算法提出了STCC算法,采用雅可比系数修改了STC算法中基本类相似度的计算方法,出色地完成了网页聚类。
针对维吾尔语语言和Web文本特点,本文提出了一种改进的维吾尔语Web文本聚类的后缀树聚类算法(STCU)。文中对词语进行词干提取,构建了两种维吾尔语停用词表,并采用文档频率和词性结合的方法对关键短语提取。合并基类时采用了改进的二进制方法,能根据语料类别数对聚类类别阈值自动调整。最后,利用最一般短语对聚类结果进行描述,提高了文本聚类的质量。
3 改进的维吾尔语后缀树聚类
3.1 维吾尔语的特点
维吾尔语属于阿尔泰语系突厥语族[27],是一种黏着语,它的语法形式都是通过在单词原形的后面或前面附加一定的附加成分来完成的。在维吾尔语文本中,一个词语具有多种语法形式。在文本预处理时,需要对维吾尔语词语进行词干提取。另外构形附加成分表示一定词汇意义或语法意义,它们不仅与词干互相黏连,并且彼此之间也互相黏连。在维吾尔语词切分中,除了词干提取之外还要对构形附加成分加以切分。
3.2 改进的维吾尔语文本聚类流程
改进的维吾尔语后缀树聚类具体流程为:
(1)维吾尔语Web文本预处理,对词语进行词干提取,过滤绝对停用词和相对停用词;
(2)构造Web文本广义后缀树,其中后缀树以维吾尔语句子为单位进行构造;
(3)遍历维吾尔语文本广义后缀树,得到文本集的公共短语;
(4)对公共短语,利用文档频率和词性结合的方法提取关键短语;
(5)利用关键短语作为基类,然后利用改进相似度公式对基类进行合并;
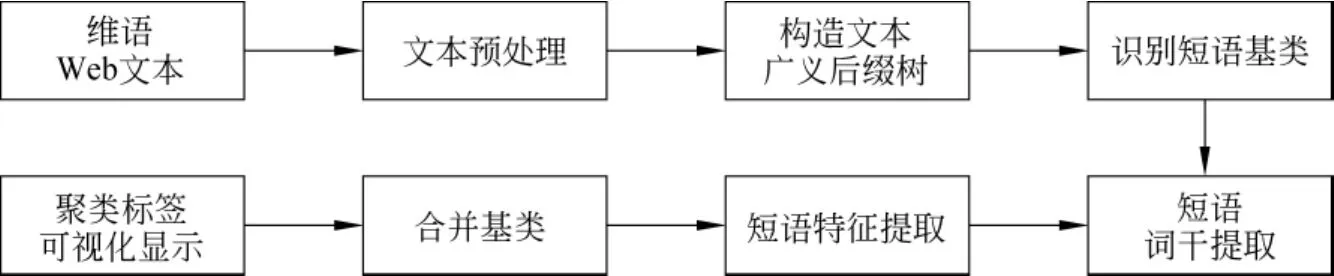
图1 维吾尔语后缀树聚类流程
(6)利用最一般短语作为聚类标签并将聚类结果可视化显示。
3.2.1 算法描述
改进的维吾尔语后缀树聚类算法STCU(Improved Suffix Tree Cl ustering f or Uyghur)描述如下:
输入:文本集合D={d1,d2,…,dn};
输出:带有类别短语标签的簇集合C={c1,c2,…,cn};
Step1 对文本集合D中文本di进行清洗、过滤、解析,得到对应文本集合的字符串集合S={s1,s2,…,sn};
Step2 使用线性时间复杂度算法对s1构造后缀树N1,在N1基础上,依次增量构造后缀树N2,N3,…,Nn,得到广义后缀树T;
Step3 遍历广义后缀树T,找到内部节点集合V={v1,v2,…,vt}中的每个节点vi所对应的最大短语基类,得到基类集合B={b1,b2,…bt},vip代表基类bi的短语标签;
Step4 公共短语分别构建多短语表P1和单短语表P2,公共短语中两个及以上单词的短语具有丰富的语义信息,不予处理;单个单词需要进行词性标注,去除连词、语气词、动词;
Step5 对短语进行文档频率提取,并调节阈值ST1,得到有效短语;
Step6 计算每个基类bi的得分,由高到低排序,过滤得分过低的噪声簇,得到新的基类集合M={m1,m2,…,mc};
Step7 聚类阈值ST2自动调整,使得合并的短语类簇数目不至过大,满足实际聚类要求;
Step8 定义短语类簇mi和mj相似度si m(mi,mj),合并基类短语构造短语簇图,遍历图找出最大连通分量对应的新的簇集合E={E1,E2,…,El},并计算合并后短语簇的得分,从而得到类簇短语标签;
Step9 依据短语簇的得分和包含文本数目两个指标,由高到低排序,并根据指定的簇数目阈值k决定最终聚类集合C={c1,c2,…,ck};
Step10 使用最一般短语GP=(gp1,gp2,…,gpn)作为标签对聚类结果进行描述,并可视化显示。
3.3 文本分析及预处理
文本分析是STC算法的基础,主要工作是对文本进行规范化处理。识别文本中的词语,对维语文本进行词干提取,去除停用词,识别数字、标点符号(维吾尔语的标点符号主要有:“-”,“.”,“《”,“》”,“‘”,“:”,“!”,“”,“;”等符号)、网页中的 HT ML标签等。
在文本预处理阶段,将文本句子转化为词的序列。对于一些非维吾尔语的元素,如标点符号和HT ML标签等会干扰后缀树的构建,采取正则表达式把这些元素从文本中过滤掉。
3.3.1 构建绝对停用词表和相对停用词表
维吾尔语文本中存在停用词现象,即出现频率很高和出现频率很低但对主题描述意义不大的词。如:助词、代词等,它们的存在会严重影响聚类结果的质量。相同的两个短语如果使用了不同的停用词,它们会被识别为不同的短语类,最终导致聚类结果中出现主题相同但分属不同类别的现象。停用词在文本聚类过程中将增加后缀树构建的复杂度,去除后不仅能减少构建后缀树的代价,加快后缀树遍历效率,而且能提高聚类效果。
为了消除停用词对聚类结果的影响,本文定义并维护了一个维吾尔语绝对停用词表和相对停用词表,使在后缀树构建过程中出现在停用词表中的词语全部被剔除,用以改善聚类结果的质量。
绝对停用词表:通用的停用词表,包括连词、虚词、叹词等无实际意义的词语,在文本预处理阶段必须去掉。在维吾尔语中,语气词(啊)、(哎呀)、(唉哟);连词(只是)、(竟然)为停用词。
相对停用词表:对于Web文本语料库,其中有很多未登录词,此时需要对语料库进行统计分析,去掉一些特定的高频词。如:(我台报道),(图片新闻),(评论员)、(编辑)等词;
3.4 后缀树模型
定义1 字符串S是由一串词语组成的文本。定义2 字符串S的长度是指其包含的词语的个数。
定义3 字符串S的后缀是指从某一个词开始到最后一个词语所构成的字符串。长度为m的字符串S[1…m]共有m个后缀S[i…m],其中,i=1,2,…,m。每个后缀都由一个或多个词语组成。
定义4 字符串S的后缀树就是一棵由S的全部后缀所构成的压缩检索树(Co mpact Trie)。具备以下特性:
(1)后缀树是一棵有根的有向树;
(2)对于每一个不是根节点的中间节点至少包含两个子节点;
(3)每一条边标记为S的一个非空子串;
(4)从一个节点发出的两条边不能包含相同词开始的子串;
(5)每一个节点的标签定义为由根到这个节点的路径上的边的标签的串联;
(6)对于任何一个叶子i,从根到该叶子的整个路径上的边标签串联起来的内容就是S从位置i起的后缀子串,即S[i…m]。
一个由m个词的字符串S的后缀树T,有m个叶子,这些叶子编号从1到m。
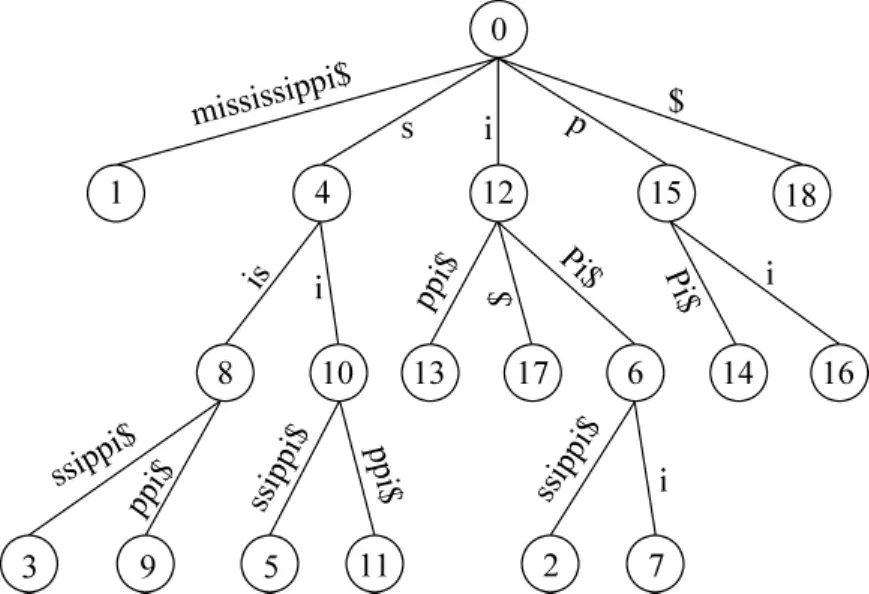
图2 字符串“mississippi$”的后缀树
一般后缀树只能表达一个文本的后缀字符串,而文本集包含大量字符串,为了利用后缀树进行聚类,需要将待处理的多个文本或者文本建立在同一棵后缀树上,形成多个文本的广义后缀树(Generalized Suffix Tree,GST)。
定义5 一个广义后缀树就是由若干字符串组成的后缀树,即:设字符串集合有n个字符串S1,S2,…,Si,…,Sn,字符串Si的长度为mi,由这些字符串构成的广义后缀树T,是一个有根的有向树,该树有∑mi个叶子。
图3是三个维吾尔语文本的广义后缀树,为方便构造广义后缀树,在每个字符的末尾增加一个特殊的终止符“$”。

图3中,每一个中间节点附着一个方框。在广义后缀树中有一类特殊节点,其入边的标签只包含特殊终止符“$”,用灰色圆圈表示,称为终端节点。
文本集包含三个文本字符串,第一个字符串有3个后缀,第二个字符串有4个后缀,第三个字符串有4个后缀,图中共画出了8个叶子节点。

图3 维吾尔语广义后缀树实例
广义后缀树的一个重要的特点是可以发现多个字符串的公共子串。这也是能够使用后缀树进行聚类的一个主要特性。
字符串S的后缀树的构造,一般是先将S[1,…,m]作为一个单边加入树中,然后依次将各个后缀S[i,…,m],i=2,3,…,m;加入树中。采用一般后缀树算法构造一个长度为m的字符串S的后缀树的时间复杂度为O(m2)。很多文献对后缀树的构造算法进行了改进,其中最著名的是Ukkonen提出的线性的后缀树构造方法。本文使用与Za mir相同的方法构造后缀树。
3.5 文本聚类特征提取
在文本聚类中最为常用的几种无监督特征选择方法有文档频率、单词权、单词熵和单词贡献度[28]。本文采用文档频率和词性结合的方法对特征进行提取。
3.5.1 文档频率
文档频率是最易理解的一种无监督特征选择方法。词的文档频率是在整个文本集中出现该词的文本数。文档频率的理论前提是:词在某个类中出现次数过多或过少对问题是无贡献的,删除这些单词会提高聚类结果,尤其是稀少单词恰好是噪声单词的情况。文档频率的优点在于它的速度十分快,其时间复杂度O(n)与文本数成线性关系,适合于海量文本数据集的特征提取。
3.5.2 词性标注
在现存的大部分语言中都有词兼类问题,维吾尔语词中也存在兼类词的问题,并且兼类词在具体的文本中运用更加复杂,在文本预处理的过程中需要考虑如何在具体的语境中确定兼类词的词性。
本文中所采用的词性标注词类是维吾尔语中最基本的12种词类。所使的词性标记集由13个标记符号组成,即T={A,D,N,M,V,P,O,C,O,E,H,W }。其中,包括形容词(A),副词(D),名词(N),数词(M),动词(V),代词(P),量词(O),连词(C),拟声词(O),叹词(E),后置词(H),语气同(Y)以及标点符号(W)。该标注集是《新疆大学词性标注集》的一个子集。
3.6 基本类簇识别
STC算法中,基本类簇的识别就是找出短语类簇。在构造广义后缀树后,通过识别包含多个文本的中间节点得到。
定义6 短语是指由一个或多个词组成的一个有序序列。短语的长度不确定,但是不能跨越短语的边界。
定义7 短语边界是文本解析器识别特殊语法符号时插入到短语间的标记,如标点符号,或者HT ML标签等。文本的开头和结尾也被认为是短语边界。
定义8 短语类簇是一个至少被两个文本共享的短语,以及包含该短语的一组文本。
定义9 最大短语类簇是在不改变文本树的情况下,不能再增加短语的词语。
短语类簇的识别可以看成是建立文本集的短语倒排表(Phrase Inverted Table)。广义后缀树的每一个至少包含两个短语的节点都可以看作一个短语类簇,对于一个短语类簇,根据它包含的文本的数量及组成短语的词语数量赋予一定的权值,根据权值大小选择短语类簇作为基本类簇。
任一短语类簇B的权值函数s(B)定义为:

其中,|B|为短语类簇的文本数,|P|为短语P的词数,即短语的有效长度。函数f是一个短语长度调节函数,对于单个词语取得最小定值,对于长度介于2~5之间的短语是线性的,对于更长的短语设为一个常数。
一般设置一个阈值ST,权值大于ST的短语类簇作为基本类簇,或者对短语类簇按照权值进行逆排序,选择前面的短语类簇作为基本类簇。
3.7 聚类阈值选择
聚类阈值r是关于聚类范围的描述,r越大,得到类簇个数越多。阈值选择策略如下:
(1)统计出文本的类别数目N;
(2)计算基类的数目N0;
(3)聚类阈值ε取值为ε×N,其中ε≥1。
当ε达到一定的数值,基类聚类数目变得稳定,从而聚类性能也变得稳定,聚类阈值选择问题得到了解决。同时,聚类阈值的大小受文本集影响。不同文本类别数目会随着差异产生不同的聚类个数,这就解决了聚类中的聚类个数固定不变的问题。实验结果表明,ε在[1,5]范围内取值效果比较理想。在本文方法测试中,取ε1=3,ε2=2。ε1表示STC的阈值,ε2表示STCU的阈值。
3.8 合并基本类簇
获得基本类簇后,两个文本之间共有的短语可能存在多个,不同短语类簇的文本集存在重叠,需要合并短语类簇形成最终的聚类簇。根据基本类簇之间文本集的重叠程度定义一个二值相似性度量。给定任意两个基类簇Bm和Bn,各自包含的文本个数为|Bm|和|Bn|,|Bm∩Bn|表示两个基类簇的共有文本,Si mT为基本类簇合并阈值。当满足下面公式时,两个基类的相似度为1,否则为0。

3.9 改进的相似度公式
如果一个基类是另一个基类的子集,“与”布尔操作符在下面情况不适用。
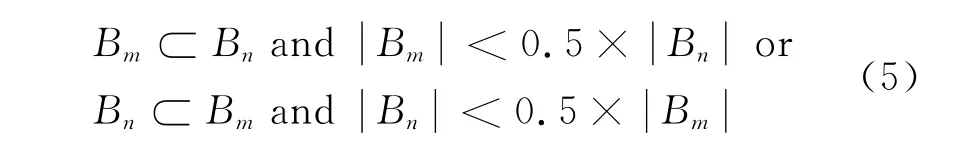
本文采用文献[19]提出的方法,把公式的“与”操作符改为“或”操作符:
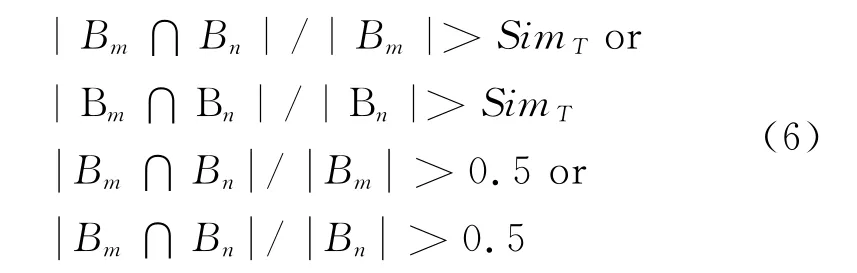
本文采用变化的阈值参数为0.5,0.6,0.7。
然后,构造基本类簇图(Base Cl uster Graph)。为每个基类簇在图中画一个顶点,如果两个基类簇的相似度为1,则把这两个顶点用边连接起来表示基类簇之间的关联。依据基类簇关联图的连通性,确定哪几个基类簇合并为一个类簇。基类簇中的文本划分为一个类簇,从而形成最终聚类得出对文本的聚类结果。
实验发现,调整基本类簇合并阈值Si mT可以改变最终的类簇数量。Si mT增大,类簇数量增加;Si mT减少,类簇数量减少。
3.10 聚类标签的识别
STC算法得到的短语具有相当高的相似性,从而显得冗余。冗余短语会降低聚类描述的简洁性和清晰性,也不利于利用其他富含信息量的短语,应该淘汰掉或尽量少选这些冗余短语来描述聚类。如果一个聚类只有一个短语,则可以用这个短语来描述聚类。如果一个聚类对应了多个短语,则使用Oren Za mir在文献[12]提出的以下三个启发式规则来识别冗余短语。
(1)子字符串和超级字符串
定义10 若短语1是短语2的子字符串,则短语1为短语2的子短语,短语2为短语1的超级短语。
从覆盖率角度来看,子短语的覆盖率一般不小于其相应的超级短语覆盖率。超级短语比其相应的子短语更具有描述信息的细节性,从而超级短语更具有信息量。最后描述聚类时只需从最一般短语和最具体短语中选择即可。对于每个短语,都要验证它是否是这个聚类中的其他短语的子短语和超级短语。
最一般的短语:如果某个短语没有子短语,则表明该短语是一个最一般的短语。
最具体的短语:如果某个短语没有超级短语存在,则表明该短语是一个最具体的短语。
显然,最一般短语的长度应该小于等于其相应的最具体短语。对于只有一个短语的聚类,则该短语既是最一般短语也是最具体短语,描述聚类时,选择这个短语即可。对于那些既不属于最一般短语也不属于最具体短语,在描述聚类时就不显示这些短语。
(2)较低覆盖率的最一般短语
选择短而一般的短语作为聚类描述的目的是为了达到较高的覆盖率。最一般短语一般比其相应的具体短语覆盖率高。如果一个最一般短语与其相应的最具体短语相比几乎没有增加多少覆盖率的话,可认为该最一般短语具有较低覆盖率而不显示这个最一般短语。定义一个最小覆盖率增加值,只有不低于这个增加值的最一般短语才显示。
(3)词重叠度
对于最一般短语或者最具体短语的两个短语,如果一个短语中属于有效短语的词在另一个具有较高覆盖率的短语重复出现的频率超过60%,这个短语将不显示。
依据上面三个启发式规则,每个聚类都确保选择了至少一个短语作为描述。在一个聚类中如果选择了多个短语,则在最后描述时,再将这些短语按照覆盖率降序排序即可作为聚类了。
STCU算法中利用启发式规则,得到的聚类标签如表1所示:

表1 改进后缀树聚类类别标签
表1列举了用改进的后缀树聚类算法得出的10个类别与标签,标签短语有长有短,能够代表相应的类别。
4 实验结果与分析
4.1 评价标准
维吾尔语没有英语reuters21578和汉语《人民日报》语料库等已建好的标准类别语料库,本文使用的测试语料是从维吾尔语网站收集的经人工分类并标注的新闻文本集合。其中新闻话题任意两篇文本称为一个人工关联文本对,并定义如下一些数据[29]:Pt:文本集中所有可能的关联对数目,Pt=人工分类中所有可能的文本对的数目。Ta:聚类结果中所有可能的文本对的数目。Ei:错误关联,指在聚类结果中出现,而在人工分类中没有出现的文本对的数目。Em:遗漏关联,指在人工分类中出现,而在聚类结果中没有出现的文本对的数目。Ce:聚类错误率,Ce=(Ei+Em)/Pt。Cr:聚类全面率,Cr=(Ta—Ei)/Tm。Cp:聚类准确率,Cp=(Ta—Ei)/Ta。
4.2 实验结果及分析
新闻文本集包含第26届世界大运会、首届亚欧博览会、“7.23”动车追尾事故等20个新闻话题,每个话题包含20~60个相关话题文本,共689个话题文本,每个文本词数40~600,平均词数82。在搜集话题集的基础上,设计了三组实验语料:第一组实验语料,从20个话题中任选10个,每个话题中任选10个相关话题文本,总共100个话题文本,作为DB1;第二组实验语料,选取这20个话题,每个话题中任选20个相关话题文本,总共400个话题文本,作为DB2;第三组实验语料,选取这20个话题,每个话题中的相关话题文本全部选取,总共689个话题文本,作为DB3。
(1)不同的数据集算法性能比较
为测试算法对语料的稳定性和适用性,本文对三个数据集分别进行了聚类算法性能测试,结果如表2所示。
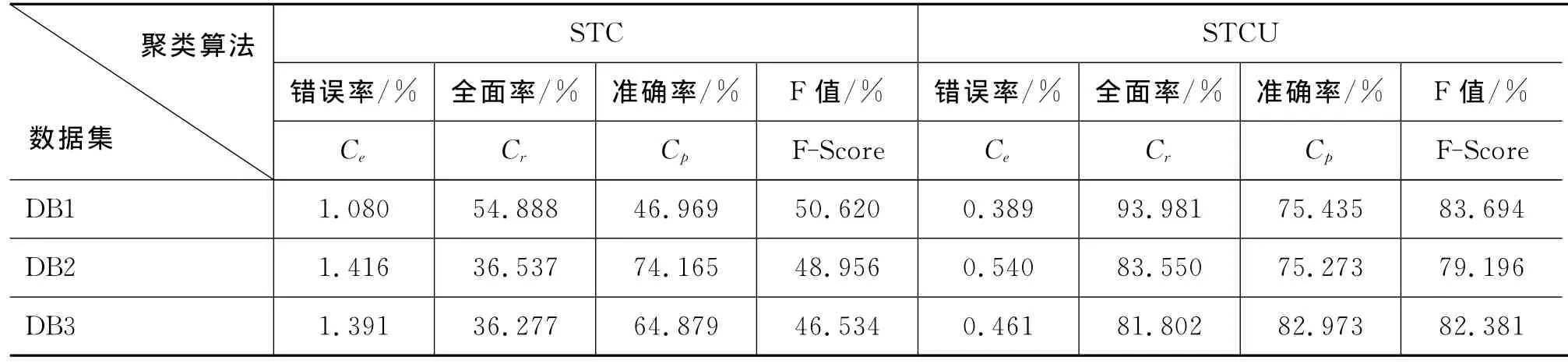
表2 不同的数据集算法性能比较
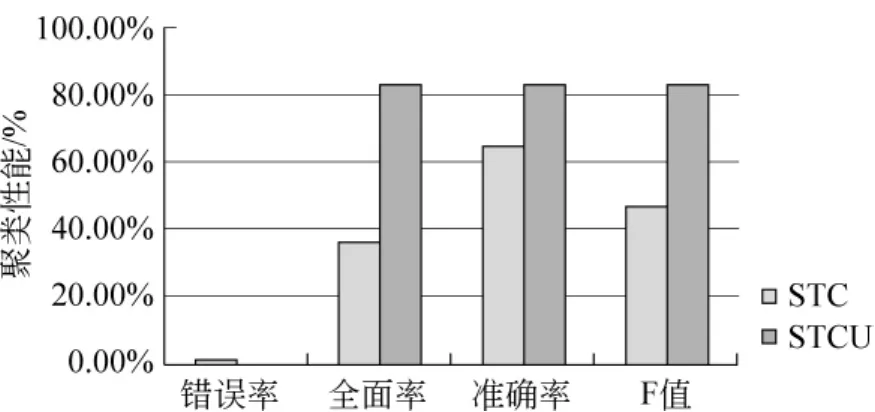
图4 DB3的STC算法和STCU算法的对比
表2为不同的数据集下相应阈值调整后STC算法与STCU聚类性能比较。从表中可以看出,两种方法在DB1下错误率较DB2、DB3都要小,总体性能也要优于其他两个数据集。这主要是因为DB1数据集小,包含的类别数目少,冗余信息较少,利用两种算法聚类得到的精度则相对较高。在STC算法中,DB2的聚类效果比DB3好是由于STC算法未对公共短语进行相应的特征提取,所取的公共短语打分后多为语料库频率分布在中间的短语,聚类的结果与实际效果不同;在STCU算法中,DB3的效果要比DB2效果好的原因在于,公共短语经过特征提取后,关键短语的分布更为合理,利用其抽取出的聚类结果更为理想。两种聚类算法在DB2和DB3上的全面率和准确率等聚类指标上相差不大,说明了提出的STCU算法能应对不同大小的数据集,对非平衡语料库具有适用性和稳定性。
图4为DB3下阈值调整后STC算法和STCU算法对比,从图4中可以看出,本文的方法较传统的STC方法,全面率、准确率有了较大的提高,全面率提高了44.51%,准确率提高了11.74%;错误率降低了0.94%。从实验结果中可以看出,本文提出的STCU算法很好地改善了实验效果,从而验证了本文方法在文本聚类的有效性。
为测试聚类阈值与特征提取对算法的影响,对DB3做实验如下介绍。
(2)聚类阈值的影响
由于基类的数目比较多,在合并基类后,单独成类的基类仍较多。如果在合并后进行筛选再排序,很难得到需要的聚类结果。在基类合并前,设置一个大致的范围对基类进行合并,不仅可以减少时间复杂度,而且能提高聚类的精度。按照文中所给公式,聚类的数目越多,文本对数目将急剧增多,全面率会大幅度提高,相应的准确率则达不到要求。在实验中,设置了1倍人工语料的类的数目,1.5倍人工语料的数目,2倍人工语料类的数目。由图5可知,当调整聚类数目和人工语料的类的数目大致相等时,聚类的全面率和准确率取得了很好的效果。
(3)特征提取的影响
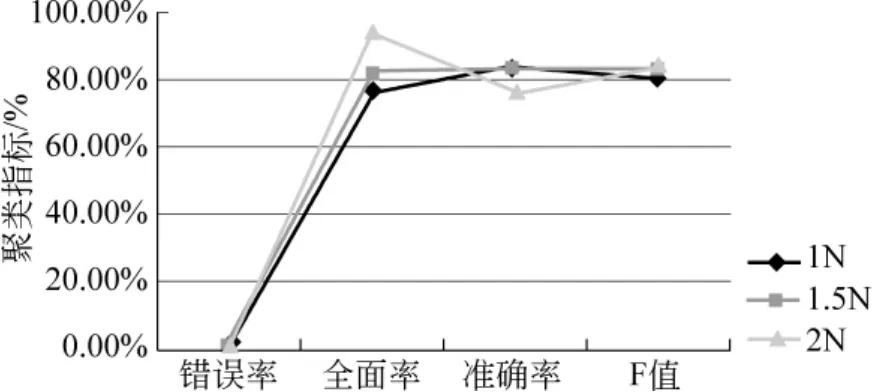
图5 基类的选择数目对聚类的影响
为测试文档频率的特征提取方法对聚类算法的影响,从后缀树中提取公共短语后,去掉其中的低频词和高频词。在公共短语中,低频词一般对结果影响不大,在实验中取一个较大的定值(公共短语的50%)予以去除,去掉这些低频词能加快后续处理。而高频词对结果影响较大,因为该短语可能在大部分文本中出现,一些关键性词语往往出现在其中。抽取过多,则把一些关键词排除在外,聚类精度不高,取公共短语的1%~2%的比例对算法进行测试。从图6可以看出,在比例为1.5%时取得较好效果。实验结果充分说明了文档频率的特征提取方法可以很好地提高算法性能。

图6 特征短语对STCU算法的影响
5 结论与展望
针对维吾尔语语言和Web文本特点,本文提出了改进的维吾尔语 Web文本后缀树聚类算法STCU,采用了多种有效的方法和策略,不仅降低了聚类错误率,而且提高了聚类正确率和召回率,大大改善了文本聚类的质量。将来的工作是引入语义知识对后缀树构建过程的进一步改进、关键短语的抽取方法研究以及结合其他的聚类算法得到层次形式的聚类效果,为用户提供个性化的聚类结果显示。
[1]Weiner P.Linear patter n matching algorith ms[C]//IEEE Conference Record of 14th Annual Sy mposium on Switching and Auto mata Theory,1973.SWAT'08,1973:1-11.
[2]E.Mc Creight.A space-econo mical suffix tree construction algorith m[J].Journal of the ACM 23,1976:262-272.
[3]E.Ukkonen.Constr ucting suffix trees on-line in linear ti me,in Algorith ms,Soft ware,Architect ure[J].Inf or mation Pr ocessing 92,vol.I (J.van Leeu wen,ed.),Elsevier,1992:484-492.
[4]Ukkonen Esko.On-Line Construction of Suffix Trees[J].Algorith mica,1995,14(3):249-260.
[5]Gusfield D.Algorith ms on strings,trees,and sequences:co mputer science and co mputational biology[M].Cambridge Univ Pr,1997.
[6]刘远超,王晓龙,徐志明,等.文档聚类综述[J].中文信息学报,2006,20(3):55-62.
[7]孙学刚,陈群秀,马亮.基于主题的 Web文档聚类研究[J].中文信息学报,2003,17(3):21-26.
[8]赵世奇,刘挺,李生.一种基于主题的文本聚类方法[J].中文信息学报,2007,21(2):58-62.
[9]刘振鹿,王大玲,冯时,等.一种基于LDA的潜在语义区划分及 Web文档聚类算法[J].中文信息学报,2011,25(1):60-70.
[10]Zamir O,Etzioni O,Madani O,et al.Fast and Intuitive Clustering of Web Documents[C]//Proceedings of t he 3r d Inter national Conference on Knowledge Discovery and Data Mining.New Yor k,USA:ACM,1997:287-290.
[11]Zamir O,Etzioni O.Web Document Clustering:A Feasibility Demonstration [C]//Proceedings of the 21st Inter national ACM SIGIR Conference on Research and Develop ment in Inf or mation Retrieval.USA:ACM,1998:46-54.
[12]Oren Zamir,Oren Etzioni.Grouper:A dynamic clustering interface to Web Search Results[J],WWW8/Co mputer Net wor ks,1999,31(11-16):1361-1374.
[13]Janr uang,Jongkol,Guha,Su manta,Ieee.Applying Semantic Suffix Net to Suffix Tree Clustering[C]//3rd Conference on Data Mining and Opti mization(DMO)/1st Multi Conference on Artificial Intelligence Technology (MCAIT),Putrajaya,MALAYSIA,2011:146-152.
[14]Rafi M,Maujood M,Fazal M M,et al.A co mparison of t wo suffix tree-based docu ment clustering algorithms[C]//Inf or mation and Emerging Technologies(ICIET),2010 Inter national Conference,Karachi,2010:1-5.
[15]H.Chi m and X.Deng.A New Suffix Tree Si milarity Measure f or Docu ment Clustering[C]//Proc.of WWW'2007,Banff,Alberta,Canada,2007:121-129.
[16]Jongkol Janruang,Sumanta Guha.Semantic Suffix Tree Clustering[C]//2011 First IRAST International Conference on Data Engineering and Inter net Technology(DEIT),Bali,Indonesia.2011.
[17]Zhang Dell,Dong Yisheng.Semantic,Hierarchical,Online Clustering of Web Search Results[M].Advanced Web Technologies and Applications:Springer,Berlin,Heidelberg,2004:69-78.
[18]KOPIDAKI S,PAPADAKOS P,TZITZIKAS Y.STC+and NM-STC:t wo novel online results clustering methods for web searching[C]// WISE 2009:10th International Conference.Berlin,Ger many:Springer,2009:523-537.
[19]骆雄武,万小军,杨建武,等.基于后缀树的 Web检索结果聚类标签生成方法[J].中文信息学报,2009,23(2):83-88.
[20]郭莉,张吉,谭建龙.基于后缀树模型的文本实时分类系统的研究和实现[J].中文信息学报,2005,19(5):16-23.
[21]杨瑞龙,朱庆生,谢洪涛.快速混合Web文档聚类[J].计算机工程与应用,2010,46(23):12-15.
[22]杨瑞龙.基于短语特征的 Web文档聚类方法研究[D].重庆大学博士学位论文.2010.
[23]胡海龙,孙晨,赫枫龄,等.基于改进后缀树算法中英文聚类引擎的实现[J].吉林大学学报(理学版),2009,47(2):299-304.
[24]林庆,袁晓峰,吴旻.中文 Web文档聚类算法研究[J].计算机工程与设计,2009,30(20):4759-4761.
[25]J W Yang.A Chinese Web Page Clustering Algorith m Based on t he Suffix Tree.Wuhan University Journal of National Sciences[M].2004,9 (5):817-822.
[26]史庆伟,赵政,朝柯.一种基于后缀树的中文网页层次聚类方法[J].辽宁工程技术大学学报(自然科学版),2006,25(6):890-892.
[27]哈米提·铁木尔.现代维吾尔语语法[M].北京:民族出版社版,1987.
[28]刘涛,吴功宜,陈正.一种高效的用于文本聚类的无监督特征选择算法[J].计算机研究与发展,2005,21(3):381-386.
[29]闵可锐,赵迎宾,刘昕,等.互联网话题识别与跟踪系统设计及实现[J].计算机工程,2008,34(19):212-214.
猜你喜欢
电子技术与软件工程(2021年6期)2021-11-21 01:24:53
自动化学报(2017年4期)2017-06-15 20:28:55
电脑知识与技术(2016年9期)2016-05-18 11:15:21
服装学报(2015年1期)2015-10-21 01:20:30
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
现代计算机(2015年15期)2015-09-18 01:22:19
语言与翻译(2015年4期)2015-07-18 11:07:45
语言与翻译(2014年3期)2014-07-12 10:32:09
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
