
基于关联图和文本相似度的实体消歧技术研究*
2022-01-15 06:24王章辉吕亚茹张涵婷
计算机与数字工程 2021年12期
王章辉 吕亚茹 张涵婷
(辽宁大学信息学院 沈阳 110036)
1 引言
网络中的数据通常都是以自然语言的形式存在的,而自然语言存在较多的一词多义或多词一义的现象。因此,计算机是不能直接理解和处理这些非结构化文本信息的。我们利用实体链接技术将自然语言中的提及和知识图谱中存储的实体相关联,在进行自然语言处理的时候就可以利用知识图谱中的结构化信息,使计算机更好地理解文本中的信息。
实体消歧任务是实体链接中最为重要的一个阶段。因为实体识别后的结果很难直接加入到知识图谱当中。必须要对实体识别的结果进行消歧,才能找到文档中实体指称在知识图谱中所对应的实体。本文对实体消歧技术进行研究,提出一种文档级的实体消歧技术。
本文的主要贡献如下:
1)提出一种文档级实体消歧技术,在局部消歧的基础上,增加了文档中实体之间的关联信息。
2)局部消歧采用BiLSTM+Attention模型提取文本中实体指称的上下文特征向量,利用TransE[1]模型来表示知识图谱中候选实体的特征向量,然后利用相似性函数计算实体指称和候选实体的之间的相似性得分作为候选实体的局部消歧得分。
3)提出一种关联图的构造方法,将候选实体作为节点,利用知识图谱中实体之间的路径信息计算节点之间的关联度。
4)利用文档中的所有实体指称之间的关联信息和候选实体的局部消歧得分,采用基于关联图和PageRank算法[2]的全局消歧模型进行对文档中的所有实体指称协同消歧。
5)使用不同的数据集,通过局部消歧和全局消歧两种方法进行对比试验和消融实验,实验结果表明本文的方法具有较好的消歧效果。
2 相关工作
实体消歧技术一般分为局部消歧和全局消歧两种,局部消歧算法是对文档中的每个实体单独进行消歧,而全局消歧算法是对文档中所有的实体指称进行协同消歧。
局部消歧技术通过对文本中实体指称的特征进行提取来进行实体消歧,关键是选取合适的模型对实体指称的信息进行表示。从不同粒度来表示实体比较复杂,可以采用基于深度学习的方法自动学习实体以及实体指称项的分布式表示。Francis-Landau等[3]分别利用卷积神经网络(CNN)学习文本的表示,根据余弦相似度对实体指称的每一个候选实体进行局部评分。Sun等[4]利用卷积神经网络来表示上下文,使用神经张量网络对实体指称上下文的语义进行建模。通常实体指称的上下文信息比较多,有些词和实体指称的关联性不大,这样在训练上下文的表示时会产生噪音,影响消歧效果。有学者提出将注意力机制与深度神经网络结合来训练上下文的语义特征表示。Wei等[5]提出一种基于注意力的深度神经网络(DNN)的中文实体链接系统。局部消歧技术每次只处理文档中单个实体指称,忽略了文档中所有的实体指称所对应的目标实体之间所存在的联系。而这些信息对于实体消歧任务非常重要。
全局实体消歧认为一篇文档中的实体指称所对应的实体是有关联的,利用实体之间的关联信息来对所有实体进行全局协同实体消歧。Yamada等[6]提出了一种基于单词和实体的上下文嵌入的全局实体消歧模型。该模型基于BERT,为输入文本中的单词和实体生成上下文嵌入。通常全局消歧方法使用基于图的方法,利用候选实体之间的关系构建图,对构建的图进行一些运算,从中选出最佳匹配实体。深度学习方法发展迅速,有学者利用深度神经网络来学习图中的信息,来实现实体消歧。Hu等[7]提出一种充分利用全局语义信息的端到端图神经实体消歧模型GNED。
基于图的全局实体消歧方法进行具有较高的准确率,与局部消歧技术相结合进行实体消歧将会取得更好的消歧效果。本文提出一种文档级的实体消歧技术,首先对单个实体指称进行局部消歧,然后利用文档中的所有实体指称之间的关联信息和候选实体的局部消歧得分进行全局消歧。
3 基于BiLSTM+Attenion模型的局部消歧
深度神经网络可以自动地学习潜在的句子语义特征,因此本文选择基于深度学习的方法进行特征提取信息。BiLSTM由正向LSTM和反向LSTM两个模块组成,可以学习到句子的双向信息,能够更好地捕捉句子的双向语义依赖。Attention模型在处理序列问题时,可以规定注意力范围,防止处理长序列文本时丢失掉一些重要的信息。
BiLSTM+Attention模型如图1所示。

图1 BiLSTM+Attention模型图
模型由五部分组成:
输入层:输入实体指称上下文信息{w1,w2,…,wn};实体指称的局部上下文为一个以实体指称为中心的上下文窗口[8]。根据经验[9],本文将待消歧指称上下文窗口的设置为对称窗口,left=right=8。
嵌入层:将实体指称上下文中的每一个单词w用一个低维向量x表示;单词嵌入向量包括词嵌入向量和位置嵌入[10]向量。
BiLSTM层:利用BiLSTM[11]网络获取实体指称上下文特征H=[h1,h2,…,hn];
Attention层:本文在BiLSTM层之后使用Attention[12]机制,为实体指称上下文中每个单词的特征赋予不同的权重,产生一个权值向量α,将实体指称上下文中每个单词的特征与对应的权值相乘,合并为实体指称的句子级特征向量;
输出层:输出实体指称的句子级特征向量Om。
本文提出的基于BiLSTM+Attention的局部消歧模型如图2所示。首先在实体指称上下文特征表示部分,首先将实体上下文信息输入到BiLSTM+Attention模型,采用BiLSTM+Attention模型得到待消歧实体指称上下文的特征向量;其次在候选实体特征表示部分,利用知识图谱中实体之间的结构约束来得到实体的特征向量。采用TransE模型训练得到实体嵌入和关系嵌入,将实体嵌入作为候选实体的特征向量;最后使用Cosine函数对实体指称上下文的特征向量和候选实体的特征向量进行相似性计算得到候选实体的局部消歧分数。

图2 基于BiLSTM+Attention的局部消歧模型
4 基于关联图和PageRank算法的全局消歧
只考虑局部上下文,会存在信息较少或者出现噪音等问题,可能导致实体消歧的效果较差。因此在局部消歧的基础上,利用同一篇文档中所有实体指称所对应的实体之间的关联信息,对文档中所有实体指称进行全局协同消歧。
文档中的实体指称具有以下两种特性:如果一个候选实体和其他多个实体指称的候选实体关联程度越紧密,则说明这个实体和文档中的实体指称匹配的概率越大;局部消歧得分越高的实体,和实体指称匹配的概率就越大,因此,在知识图谱中,与这个实体相关联的其他实体指称的候选实体为正确匹配实体的概率也越大。这与PageRank算法的思想一致[13]。本文使用PageRank算法对构建的关联图进行迭代运算,对文档中所有实体指称进行协同消歧。
在构造关联图之前,首先构造包含实体之间所有路径的实体连通图,其次根据实体连通图去构建实体关联图。
4.1 实体连通图的构建
实体连通图是指知识图谱中包含不同实体指称的候选实体之间所有路径的子图。构建实体连通图的目的就是找到不同待消歧实体指称的所有候选实体之间的路径。
当查询两个实体之间路径的时候,可能会出现连接两个不相连的实体的中间实体,它被称为桥接实体。当一条路径中存在较多桥接实体时,在知识图谱中搜索时,工作量将会非常大,降低计算的效率。由于找到两个实体之间路径的目的是为了计算两个实体之间的关联度,当两个实体之间的路径过长时对实体之间关联度影响不大,所以忽略掉实体之间长距离的路径对于计算结果没有太大影响。因此本文设置一个路径长度阈值Q,本文通过实验分析将Q大小的设置为6。
由于在进行消歧时只考虑不同待消歧实体指称所匹配在知识图谱中的实体之间的关联,故同一待消歧实体指称的候选实体之间的路径不需要被搜索。
对于一个实体连通图G(N,E,paths),有以下定义:
N表示图中所有节点的集合,E表示图中所有边的集合,EM∪B。其中EM是所有候选实体的集合,即EM={EM1∪EM2∪…∪EMn}。
EMi为文档中一个实体指称的候选实体集合,n为一篇文档中实体指称的个数。B表示属于不同实体指称集合的任意候选实体对(eij,epq)路径之间的 桥 接 实 体 集 合,B={bk,…,bz|{
paths为任意实体指称的候选实体之间的路径。具 体 形 式 为paths={paths(eij,epq)|∀eij,epq∈EM}。其中,paths(eij,epq)表示在实体连通图中顶点eij和顶点epq之间所有路径的集合,具体形式为paths(eij,epq)={{
实体连通图构建的方法就是遍历知识图谱得到一个子图,从一个候选实体eij开始,沿着路径在知识图谱中找到另一个候选实体epq为止。其思想和图的深度优先遍历算法类似,因此本文在实体连通图的构造过程中,利用基于图的深度优先搜索算法。实体连通图的构造过程为见算法1和算法2。
算法1实体连通图的构造算法
输入:EM={EM1∪EM2∪…∪EMn}
输出:G(N,E,paths)
1)初始化N=E=paths=NULL
2)for EMiin EM do
3)C=EMi+1∪EMi+2∪…∪EMn
4)for eijin EMido
5)path=NULL
6)CNode=ConnectNode(eij)/*将和eij相邻的节点放到集合CNode中*/
7)While CNode is not NULL do
8) Get path via CNode.top w.r.t Algorithm2
9) if len(path)≤Q then
10) for step=1,len(path)do
11) Store path[step].Node in N
12) Store{path[step].Node,path[step+1].Node}in E
13) end for
14) Store path in paths(eij,CNode.top)
15) end if
16) Delete CNode.top from CNode
17)end while
18)end for
19)end for
20)return G(N,E,paths)
算法2图的深度优先搜索算法
输入:TNode,path,C,Q
输出:path
1)if TNode in C then
2)return path
3)else if len(path)>Q then
4)return path=NULL
5)else
6)Store
7)CNode=ConnectNode(TNode)
8)while CNode is not NULL do
9)TNode=CNode.top
10)Delete TNode from CNode
11)Depth-First Search of Connected Graph(TNode)
12)end while
13)end if
4.2 实体关联图的构建
本节在实体连通图的基础上,利用各个实体之间的关联关系来构造实体关联图。实体关联图中的节点为一篇文档中所有实体指称的候选实体,边代表两个实体之间有关联。
对于一个实体关联图R(Nr,Er,Tr),有以下定义:
Nr表示所有实体指称的候选实体的集合,即Nr=EM={EM1∪EM2∪…∪EMn},n为文档中实体指称的个数,m为实体指称的候选实体的个数。
Er表示两个候选实体之间的边,Er={
Tr表示一个图的邻接矩阵,Tr(eij,epq)是实体eij和实体epq之间边的权值,表示两个实体的关联度。
实体关联图中两个候选实体的关联度利用卡茨相关性[14]计算。计算如式(1)所示:

实体关联图的构造过程见算法3。
算法3实体关联图构造算法
输入:G(N,E,paths),EM,β
输出:R(Nr,Er,Tr)
1)初始化N=EM,Er=NULL,Tr=0
2)for EMiin M do
3)C=EMi+1∪EMi+2∪…∪EMn
4)for eijin EMido
5)for epqin C do
6) Get paths(eij,epq)from paths
7) Store
8) SCS(eij,epq)=0
9) for p in paths(eij,epq)do
10) SCS(eij,epq)=SCS(eij,epq)+βlen(p)
11) end for
12) Tr(eij,epq)=SCS(eij,epq)
13)end for
14)end for
15)end for
16)return R(Nr,Er,Tr)
4.3 PageRank算法消歧
每个实体顶点PageRank初始值利用每个候选实体的局部消歧得分,为了平衡局部消歧得分对所有实体指称的候选实体节点的影响,对同一个实体指称的候选实体的局部得分进行归一化处理,归一化之后的得分为实体顶点的初始得分。

首先将实体关联图中每个实体顶点的值作为初始的PageRank得分P0。然后基于所构造的邻接矩阵来构造转移矩阵M,将邻接矩阵Tr每一行的值进行归一化,表示每个顶点跳转到其他顶点的概率,也表示这个实体与和它有关联的实体之间同为最佳匹配实体的概率。得到转移矩阵和顶点的初始PageRank得分,就可以对图采用PageRank算法进行运算。PageRank迭代公式如公式(3)所示。

当一次迭代完毕,从得到的结果中选出得分最高的实体作为所属待消歧实体指称的消歧结果。然后更新实体关联图和实体关联图的转移矩阵M。将上次迭代计算出的每个实体的PageRank得分作为下一次PageRank迭代计算的初始得分;把关联图中和上一次迭代所得到的得分最高的实体属于同一实体指称候选列表的实体顶点删除,并删除和它们有关联的边。继续进行迭代,直到消歧结束。
5 实验与结果
5.1 数据集
本文使用FreeBase(FB5M)的子集作为实体链接的参考知识图谱。FB5M在SimpleQuestions数据集中发布,它包含4,904,397个实体,752,3个关系和22,441,880个事实。本文实验所采用的数据集为ACE2004和MSNBC,两个数据集均为英文新闻数据集。
5.2 参数设置
本文从准确率P,召回率R,F1值和耗时TC四个指标对实验结果进行评估。
在构建实体连通图时,为了减小搜索和计算的复杂度而对路径长度设置了阈值Q,设置Q的值为从1~10,在两个数据集上进行实验,通过F1值和耗时TC两个评价指标对实验结果进行分析。实验结果如图3所示。由图可以看出,阈值Q=6是最佳选择。
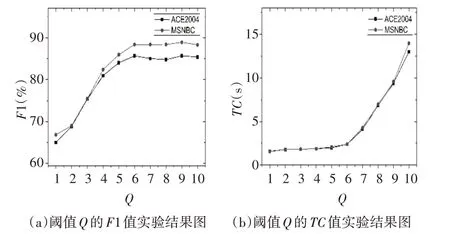
图3 参数Q的实验结果图
对于PageRank公式(3)中的参数c,本文对其在[0,1]进行实验,间隔为0.1,实验结果如图4所示。通过F1值对实验结果进行分析,可以看出,当c=0.5时,F1值达到最大,消歧效果最好。即对于本文中的PageRank算法,在当前节点停留的概率和转移到其他节点的概率相同时,得到的实验效果最好。

图4 参数c的F1值实验结果图
5.3 消融实验
为了更好地对比出加入全局特征对实体消歧的影响,本小节首先使用局部消歧模型进行实验,选取局部消歧分数最高的实体作为最佳匹配实体,然后再与使用了全局特征的整体消歧框架的消歧效果进行对比。在两个数据集上的实验结果分别如表1和表2所示。
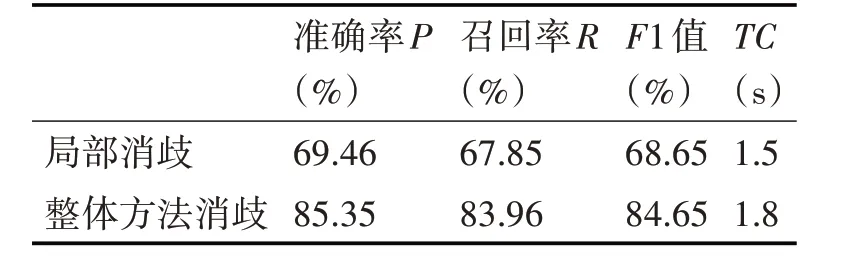
表1 数据集ACE2004上的消融实验结果

表2 数据集MSNBC上的消融实验结果
通过结果可以看出,只有局部消歧时的实验效果比较差,局部消歧利用实体指称的上下文信息进行消歧,但当利用的信息较少,或者利用的信息有太多噪音时,提取文本特征时会出现偏差,影响消歧效果。加入全局特征以后,实验效果明显上升,因为全局消歧中加入了实体的全局性特征,对局部消歧中存在的偏差进行纠正,提升整体实验效果。
5.4 对比实验
为了对本文的消歧效果进行更好的分析,选取DSMM[15]消歧方法和Graph Ranking[16]方法与本文方法进行对比。两种方法中,DSMM方法属于基于上下文的局部消歧算法,与本文局部消歧所使用的方法类似,通过和其对比,可以看出本文在局部消歧的基础上加入全局消歧之后的效果。Graph Ranking方法是基于图的全局消歧算法,和本文的全局消歧部分处理类似,但节点初始得分的处理是不一样的,通过和其对比,可以看出初始得分的处理对实验结果的影响。通过和这两种方法的对比,可以充分对比出本实验所使用的局部消歧和全局消歧相结合的方法的效果。DSMM方法、Graph Ranking方法和本文方法在数据集ACE2004和数据集MSNBC的实验结果如表3和表4所示。

表3 数据集ACE2004上的对比实验结果

表4 数据集MSNBC上的对比实验结果
通过实验结果可以看出,在数据集ACE2004和数据集MSNBC上本文的方法在准确率、召回率、F1值等方面取得了较好的效果。DSMM方法只考虑了实体的上下文信息而忽略了同一篇文档中实体之间的关系,F1值最小,消歧效果不如后面两种全局消歧的算法。而Graph Ranking方法在构建关联图中使用的实体流行度作为节点初始得分,没有考虑到实体的下文信息,算法耗时时间最短,但F1值低于本文的消歧算法。并且可以看出,Graph Ranking方法和本文方法两种全局消歧算法在数据集MSNBC的实验效果比在数据集ACE2004上的实验效果要好,这是因为数据集MSNBC中平均每篇文档的实体数较多,可以提取到实体之间较多的关联信息,能更好地反映局部消歧和全局消歧性能的对比效果。根据实验结果可以看出,本文方法是一种对文档中实体进行协同消歧的有效的方法。
6 结语
本文提出一种文档级的实体消歧技术,将局部消歧技术与基于图的全局消歧方法结合起来进行实体消歧。局部消歧采用基于BiLSTM+Attention模型的消歧算法,全局消歧采用基于关联图和PageRank算法的全局消歧算法,利用每个候选实体局部消歧中得到的局部消歧得分,对文档中所有实体指称进行全局消歧。实验结果表明本文的方法具有较好的消歧效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
当代陕西(2019年15期)2019-09-02
现代计算机(2019年19期)2019-08-12
金桥(2018年4期)2018-09-26
学苑创造·A版(2018年11期)2018-02-01
电脑爱好者(2017年7期)2017-05-06
读者(2017年5期)2017-02-15
