
视听同步输入模式对口译质量的影响
——基于多模态理论的实证研究
2012-11-03 05:04:08李彬
长江师范学院学报 2012年9期
李彬
(徐州工程学院 外国语学院,江苏 徐州 221000)
□翻译学研究
视听同步输入模式对口译质量的影响
——基于多模态理论的实证研究
李彬
(徐州工程学院 外国语学院,江苏 徐州 221000)
基于多模态话语分析理论,探讨多种信息输入模式对口译质量的影响。实验对两组各20名受试学生分别进行视听/听音口译对比研究。研究采用统计软件SPSS对实验数据进行分析。研究结果显示,视听组学生的总体口译质量比听音组学生的口译质量高,但并不是很明显;同时,视听同步输入模式下视觉信息对受试的理解和记忆有积极的影响,还可提高受试对源语意义的整体理解和意义构建。
视听同步输入;多模态;口译质量
传统的以单一的文字形式获取信息的方式通常被称为单模态交流。随着科学技术的进步,这种单一模态的运用已远远不能满足当今人们获取大量信息的需要,视觉信息的输入也不再仅仅局限于传统的书本文字的输入,动画、卡通、幻灯片等大大丰富了人们的视觉信息获取方式。多媒体等视频高科技产品更是集视听多种模态于一体的信息传递和交流方式。多模态的应用方便了人们的交际,尤其是在语际交际中,交际双方具有不同的文化背景和语言习惯,但他们之间的交流与生活在同一文化中的人们之间的交流没有本质上的差异,相反,由于文化背景的不同,交际双方为了能够准确地表达自己的交际意愿,常常会运用许多多模态手段实现信息的准确传递,比如语速、语调、音高、手势、表情以及其他的一些身体动作等。口译作为 “人们跨文化跨语言的交往活动中由能运用交流各方面所使用语言的人,采取口语表达的方式,将一种语言所表达的思想内容以别种语言做出转述的即时翻译过程” (张文,韩常慧),是不同文化之间沟通和交流的桥梁。译员在工作过程中可以通过捕捉交际双方在交际过程中表现出多模态信息,准确把握交际意图,实现交际过程的顺利进行。因此,将多模态概念引入到口译研究中是一个很好的切入视角。对近年来的相关研究回顾发现,多模态理论的研究虽已引起重视,但将多模态理论和口译结合起来的研究并不多。本研究尝试运用多模态话语分析理论,结合口译实证研究,探讨多模态信息输入形式与口译质量之间存在的关系,多模态情境对译员的影响等问题。
1 多模态话语分析
多模态话语分析是近十年来发展并活跃于西方的一种新的话语分析理论,其理论基础是系统功能语法。在多模态话语分析方面最早的研究者之一R. Barthes在 1977年发表的论文 “图像的修辞”(Rhetoric of the Im age)中探讨了图像在表达意义上与语言的相互作用。之后,韩礼德(Halliday)的系统功能语法被运用到多模态话语分析中。该理论框架由五个部分组成:(1)文化层面;(2)语境层面;(3)意义层面;(4)形式层面;(5)媒体层面。其中,形式层面包括语言的词汇语法系统、视觉性的表意形体和视觉语法系统、听觉性的表意形体和听觉语法系统、触觉性的表意形体和触觉语法系统等以及各个模态的语法之间的关系;媒体层面是话语最终在物质世界表现的物质形式,包括语言的和非语言的两大类。语言的包括纯语言的和伴语言的两类;非语言的包括身体性的和非身体性的两类。身体性的包括面部表情、手势、身势和动作等因素;非身体性的包括工具性的,如PPT、实验室、网络平台、音响、同声传译室等。系统功能语言学创立以来,被广泛运用到语言语篇的分析中。从符号学看系统功能语法,其语篇分析的对象本质上讲是语言符号,或是符号系统。对视觉图像、声音、印刷体式、建筑设计、身体动作、电子媒体和电影等多模态交际符号的关注也是系统功能语言学的研究范畴。因此,克瑞斯和勒文 (Kress and Leeuwen)将韩礼德的语言元功能的思想运用到视觉模式中,创立了视觉语法,用于分析视觉图像。克瑞斯主要将系统功能语法理论运用到视觉艺术的分析;勒文第一次系统解释了视觉语法,建立了视觉交流基于多模态符号的理论基础。多模态话语分析的基础是语篇,即多模态语篇。对于多模态语篇的研究,克瑞斯和勒文 (2001)曾指出多模态语篇 (m u ltim odal discourse)是一种融合了多种交流模态 (如声音、文字、形象等)来传递信息的语篇。胡壮麟教授从符号学的视角研究了多模态,开创了我国多模态研究的先河。他在 “社会符号学研究中的多模态化”中讨论了模态的符号学特性。依照他的研究,多模态语篇可以定义为多种 “符号资源”共同出现的语篇,或是由传达同一意思的多种符号有机构成的 “符号系统”。在“多模态小品的问世与发展”一文中,他又提出了“多模态小品”的概念,这是对多模态语篇概念的概括、发展和延伸,极大地丰富了多模态语篇的研究,本文中所涉及的口译实验材料也可归属于 “多模态小品”范畴。
2 研究设计
2.1 研究问题
本实验研究的主要问题如下:
(1)就所有受试的口译表现 (成绩)而言,多模态情景下的视听信息输入模式是否优于听音信息输入模式?是否会对个别受试的口译表现造成显著性影响?
(2)视听输入模式对实验组整体表现的影响具体表现在哪些方面?
2.2 实验对象
本次研究对象为南京某高校英语专业三年级学生,分为A、B两组,每组各20名。所有学生均学习过一年的口译课程,掌握了基本的口译知识和口译技能。两组实验受试的整体口译水平基本一致,受试选取的参照标准为上一学年期末考试口译成绩。
2.3 实验设备与材料
实验地点为语音实验室。所有受试对象都配有高保真耳机和电脑显示器。实验过程中,电脑屏幕显示及实验材料选取均由教师统一提供。实验在口译课上进行,测试形式为交替传译。
本实验共分实验一和实验二两部分。考虑到受试学生对演讲材料整体风格相对比较熟悉,本实验选取了语速适中、题材相对较容易的演讲材料。实验一的视频材料为奥巴马在上海复旦大学的演讲。实验时,对A组学生播放视频,对B组学生只播放音频,两组材料实验内容完全相同,根据播放形式不同分别记为m aterialA1,m aterialB1。为了更好保证实验二中实验材料难度和受试学生对测试材料的反应所选材料一致性,实验二的音频材料仍取自该演讲材料,记为m aterialA2。所有测试材料时间均为两分钟,语速和长度基本一致。实验前所有材料均被技术处理,放音过程中停顿一次,并留有时间供学生口译。
2.4 实验步骤
实验一。本实验中,A组为实验组,B组为控制组。对A组学生播放m aterialA1,学生在信息听辨过程中可以通过多媒体屏幕观看视频,获取演讲现场的信息,听到口译提示音后进行传译。本实验只关注不同输入模式对口译最终结果的影响,因此对所有受试学生笔记不作任何要求。待所有学生口译完成后,将所有口译音频进行存档。
对B组学生播放m aterialB1。学生在口译过程中,只能通过耳机获取源语信息,然后根据提示音逐次传译。学生可以在必要的时候以笔记辅助记忆。实验结束后,对该组学生的音频也进行存档。
实验二。本实验对象为A组所有学生。选用m aterialA2。本次除实验材料外,其他实验条件和实验一中B组完全相同。实验结束后,存档所有学生的口译音频。
待所有实验完成后,参照对原文信息的忠实程度、语言表达规范性、口译技巧的运用、对语体基本特点的整体把握四个标准对不同实验组的学生进行评分。本实验需要分析的项目为:实验一中A、B组学生测试成绩比较;A组学生实验一、二的测试成绩比较。测试成绩用SPSS做数据处理。
3 结果与讨论
3.1 多模态情景下的视听信息输入模式与听觉信息输入模式的比较分析

表1 实验分组的平均分和标准差
所有受试成绩均为有效数据,表1显示三组实验的平均分和标准差。通过比较发现,实验组学生的平均分和标准差分别为80.15和5.66,均高于控制组1中的79.35和5.08,说明视听同时输入模式对受试口译操作中的信息输入、信息整合及译语的表达起到了积极的作用,从而提高受试最终的口译表现。但从标准差的结果看,实验组受试高于控制组,说明视听同时输入的情况下,不同的受试由于各自不同的原因,在口译时受到的不同影响比仅通过听音信息输入时要大,因此各受试的分数与平均分的偏离度变大。比较实验组和控制组2,我们发现,对同一组受试先后采用视听和听觉信息输入模式时,实验结果也发生了变化。控制组2的标准差和平均分都低于实验组。同时尽管实验环境试验材料难度基本相同,控制组2的标准差(5.14)略高于控制组1(5.08),但均分 (78.95)却略低于控制组1(79.35),这主要是由于控制组2和实验组受试群体相同,试验一的视听输入对受试群体产生一定的影响,这也从侧面说明视觉信息输入模式对受试的影响。
结合三组实验结果综合分析发现,在听音信息输入模式下,受试的成绩接近平均分,而在视听信息输入模式,受试的成绩离散现象比较明显。因此可以得出如下结论:由于两组受试群体在平时的口译学习和训练中大都以听觉信息输入为主,因此对听觉信息输入都比较习惯,在两组实验中成绩差异不会很大,但受试对于视觉信息的获取各自具有不同的能力和技巧,因此最终的表现出现了明显的差异。

表2 实验成绩统计
对实验组和控制组1的受试成绩使用独立样本t检验,视听同步输入模式组与听觉信息输入模式组相比,测试成绩不存在显著性差异 (t=.47,d.f.=38,P=.641〉.05)。
对实验组和控制组2的受试成绩使用独立样本t检验,同一组受试在视听同步信息输入模式下与听觉信息输入模式下的成绩也不存在显著性差异 (t=.702,d.f.=38,P=.487〉.05)。
结合表1、表2的数据分析发现,实验组成绩均分高于控制组,但没有显著性差异。从标准差看,实验组受试成绩的标准差远远高于控制组,视听同步信息输入模式加大了口译成绩的离散度。因此,得出结论是,视听同步输入模式整体上提高了受试的口译发挥 (成绩)情况,大部分受试得益于视觉信息的辅助作用发挥良好,但个别受试在口译过程中出现超常或失常发挥现象,因此造成了测试成绩相对较高的离散度。我们可以推测,实验组中大部分受试成绩之所以略高于控制组中的受试,或者说差距不大主要是因为两组受试平时的口译训练模式都是以听觉信息输入为主,但同时视觉信息的输入不会对他们构成干扰。对于另外部分少数受试来说,视觉信息的输入或构成干扰,或极大地刺激其视觉信息感知系统,与听觉信息协同作用。
3.2 视听输入模式对实验组整体影响的具体表现
本实验中所选的视频为奥巴马2010年在上海复旦大学的演讲。视频画面为实验组受试提供了所选材料的背景知识、场景信息,方便了受试对发言人的身份、面部表情等信息的获取,这对受试在实验中的表现都起到积极的作用。
笔者将实验材料中的信息依据意义的完整性标准切分为30个 “意义单位”(鲍刚,2005),每个意义单位都包含有完整的信息,其中数字、以数字标示的年份等和其他的语言单位分离出来,作为独立的意义单位。本研究中,称之为 “翻译单位”或 “口译单位”。我们分别对实验组和两个控制组受试的口译情况进行统计,参照的标准是受试对每个 “口译单位”的处理情况,统计的项目为各组受试处理 “口译单位”时 “合格”的个数及占总数 (30)的比例。如表3所示。
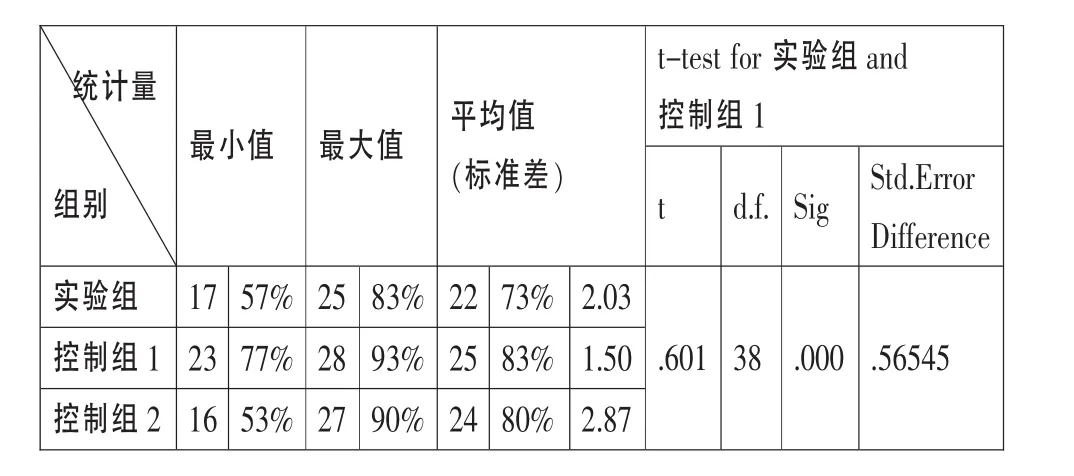
表3 受试对于 “口译单位”处理的合格率
从表3可以看出,实验组 (73%)受试对于 “口译单位”处理的合格率低于控制组 (83%;80%),而3.1部分的数据表明实验组受试口译的总体表现是优于控制组的。实验组中受试合格率标准差 (2.03)大于控制组1(1.50),说明视听输入模式增加了受试合格率相对于均值的偏离度,反映出受试在处理视听信息时存在的个体差异要比控制组大。此外,实验组和控制组1中的数据符合正态分布,独立样本t检验发现这两组数据之间具有显著性差异 (t=.601;d.f. =38;p=.000〈.05)。结合实验后的访谈,得出如下结论:在视听同步输入模式下,受试的注意力重心放在对原文信息的整体把握上,因此翻译的译文文本逻辑性和连贯性都比较好;但同时对于数字、关键词语的捕捉上存在问题,而对于听音组来说,口译时受试更专注于语言形式及信息单位的获取。评价口译的主要指标是译员是否传递出了源语的交际意图,之后再看译员对于细节的把握是否到位,因此出现上述总体表现和合格率不一致现象。
此外,不同的信息输入模式对受试的理解和记忆方面的影响是不同的。实验组中,受试对待翻译信息的获取和理解要优于对照组。但信息量超过受试的信息处理能力后便给受试造成记忆负担,导致受试分掉部分的注意力用于已听信息的记忆而影响对后续信息的接收。相比之下,听音输入模式下受试注意力要相对集中于语言信息的听觉接收和记忆,多偏于机械性记忆而非下意识的理解记忆,在口译结束后,很难对刚传译的信息进行整体构建。但从表1中的平均分看,视听信息输入模式对于受试的理解和记忆的总体影响并不明显。
4 结语
本研究对两组各20名受试学生分别进行视听/听音口译对比研究,并采用统计软件SPSS对实验数据进行分析。研究结果显示,视听组学生的总体口译质量比听音组学生的口译质量高,但并不是很明显;同时,视听同步输入对个别受试在一定程度上构成干扰。视听同步输入模式下视觉信息对受试的理解和记忆有积极的影响,但不是很明显。视听同步输入可以提高受试对源语意义的整体理解和意义构建,但对源语中细节信息给予的关注度较对照组要小。
口译质量是比较宏观的概念,对其进行严格界定需要多维度的深度研究,受试的理解和记忆也是一个复杂的心理过程。此外,本研究数据处理对象为各组受试的口译成绩,尽管取多次打分的平均分,仍然无法排除打分过程中主观性因素对最终结果的影响。另外受试对象仅为一所高校的学生,且由于设备所限,受试人数不多,因此所得结果缺乏一定的代表性。
将多模态理论用于口译的研究目前尚处于起步阶段,相关的文献也很少。本文是运用多模态理论对口译进行尝试性研究。在高校口译教学中,教师可根据学生水平,选择适当难度的视频作为口译训练材料,培养学生在视频场境下获取信息和理解能力,为今后的口译实践打下良好的基础。鉴于此,本研究所得出的结论对现行的高校口译教学实践和口译教学模式的革新具有一定的借鉴意义。
[1]Halliday,M.A.K.An Introduction to Functional Grammar[M].London:Oxford University Press,2004.
[2]Kress,G.amp;T.Wan Leeuwen.Mu ltim odalDiscourse:The Mode and Media of Contemporary Communication[M]. London:Arnold,2001.
[3]鲍 刚.口译理论概述[M].北京:中国对外翻译出版公司,2005.
[4]胡壮麟.社会符号学研究中的多模态化[J].语言教学与研究,2007,(1):1-9.
[5]胡壮麟.多模态小品的问世的研究与发展[J].外语电化教学,2010,(4):3-9.
[6]刘和平.口译理论与教学研究现状及展望[J].中国翻译,2005,(2):17-18.
[7][法]赛莱斯科维奇.口译技艺:即席口译与同声传译经验谈[M].黄为忻,钱慧杰译.上海:上海翻译出版公司,1992.
[8]叶起昌.超文本多语式的社会符号学分析[J].外语教学与研究,2006,(6):437-442.
[9]张 文,韩常慧.口译理论研究[M].北京:科学出版社,2006.
H051
A
1674-3 652(2012)09-0 105-0 4
2012-07-24
李 彬,女,江苏徐州人,主要从事英语语言文学和英汉翻译研究。
[责任编辑:何 来]
猜你喜欢
青少年科技博览(中学版)(2019年7期)2019-10-11 04:13:55
文教资料(2019年31期)2019-01-14 02:32:05
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:36
校园英语·中旬(2016年8期)2016-07-09 21:25:53
外语教学理论与实践(2016年2期)2016-06-11 01:49:42
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
中国实用医药(2015年24期)2015-05-08 09:42:17
上海电机学院学报(2015年4期)2015-02-28 14:30:00
外语教学理论与实践(2014年1期)2014-06-15 06:40:32
计算物理(2014年2期)2014-03-11 17:01:39
