
两阶段孤立点挖掘算法在保险欺诈中的应用
2012-10-10 03:25陈亮
长春工业大学学报 2012年1期
陈 亮
(泰山职业技术学院 信息工程系,山东 泰安 271000)
0 引 言
伴随国家经济的迅猛发展,保险业进入了发展的春天。2008年保费收入2 336亿元,保费年平均增长超过20%[1]。然而保险欺诈也应运而生。北京和上海保险监管机构估测,我国机动车保险欺诈的比重大致为20%,2009年全国机动车保险赔付790亿元,当年保险欺诈金额高达15亿元[2]。因此,保险欺诈严重影响了保险公司的偿付能力和经营的稳定性,甚至会导致保险市场失效。保险欺诈的出现涉及多种原因,如历史原因、投保人原因、保险公司原因及社会原因。正因为保险欺诈产生的背景复杂,保险欺诈的方法和方式也逐年复杂化、隐蔽化和多样化,因此,保险欺诈发现亦更加困难。
智能化研究应用的保险业的多数是客户研究,应用到保险欺诈较少。有关保险欺诈发现的研究和方法多集中在规章制度制定和主观方面的要求,涉及数据分析的主要是“内部数据查询法”——统计学的分析方法[3]。文中采用山东某保险公司近6万笔业务信息数据为研究对象,分两个阶段对以上数据进行挖掘分析,发现其存在欺诈的业务。在此基础上,提出一种两阶段孤立点发现方法。
1 两阶段孤立点发现方法
1.1 基于粗糙集的模糊集合相似性度量
Dubois和Prade提出并研究了粗模糊集与模糊粗糙集,并指出合理选择模糊规则是模糊推理系统的关键因素,粗糙集理论和模糊集理论不是互相排斥的,而是可以相互补的[4]。文中利用粗糙集诱导的模糊集,定义近似空间中集合间的粗相似度。
在近似空间(U,R)中,X是一个粗糙集,映射
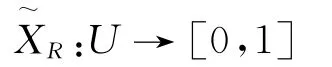
满足

设U = {x1,x2,…,xn}
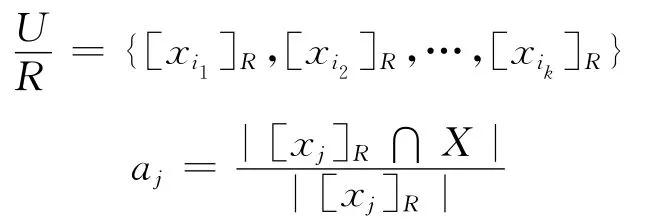
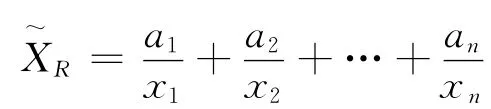
在粗糙集中,集合的相似度定义为
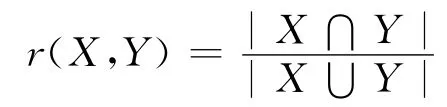
定义1 在近似空间(U,R)中,U={x1,x2,…,xn},∀X⊆U,∀Y⊆U,集合X与Y 的粗糙相似度为:

定理1 在近似空间(U,R)中,∀ X,Y∈def(U,R),则有:
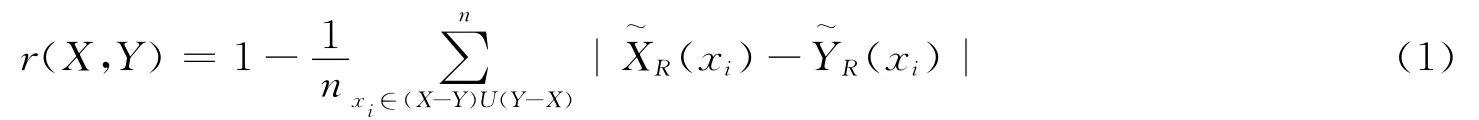
证明:由定理X~R=X⇔X[4]可知:

对于∀X⊆U
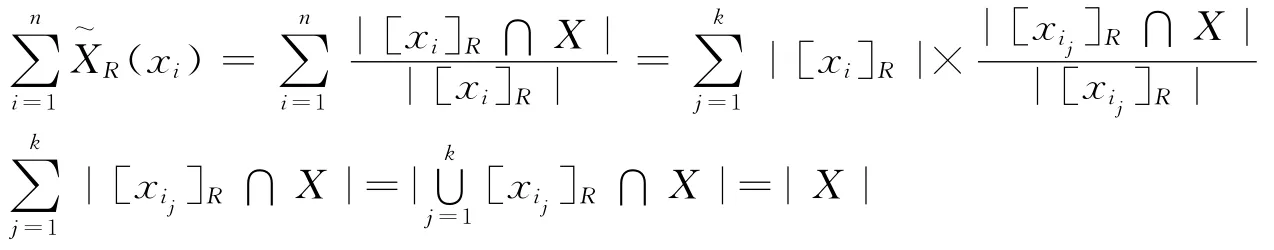
成立,可知:

所以

由集合的相似度r(X,Y)的定义可知,其取值范围在0~1之间。当r(X,Y)越接近1,两集合越相似,当r(X,Y)=1时,两集合相同。
1.2 基于向量相似性的最大相异系数
相似性函数是用函数的方法来表征两向量相似的程度。一般向量的相似性函数有夹角余弦法、相关系数法、广义Dice系数法、广义Jaccard系数法等,这几种方法都是在夹角余弦的基础上演变而来,在计算夹角余弦时或有难度或计算量较大[6]。为此,文中提出了最大相异系数方法。
设X=(x1,x2,…,xn)为未知的待比较向量,Y=(y1,y2,…,yn)为确知向量,X 与Y 的相对误差向量γ为:

显然,有可能存在某个γi的值过大或过小的情况,当评价γ时,过大或过小的γi可能导致相对误差向量的部分数据项的影响过大,使部分小值数据项的作用被忽略,从而严重影响相似度的精确度。根据保险业务的二元选择模型,保险单项业务数据分为无效因子、弱显著性因子和显著因子3种[7]。因此忽略无效因子,提高计算效率,强调显著因子,保证算法有效、准确。
定义2 对向量γ各位置赋权α={α1,α2,…,αn},把向量γ按数值降序排列得新向量:

其中,γi>γj,当i<j时,取出向量γ′的前m个值组成新向量η,η=(ηi1,ηi2,…,ηik),则定义向量X与向量Y的相异系数为:
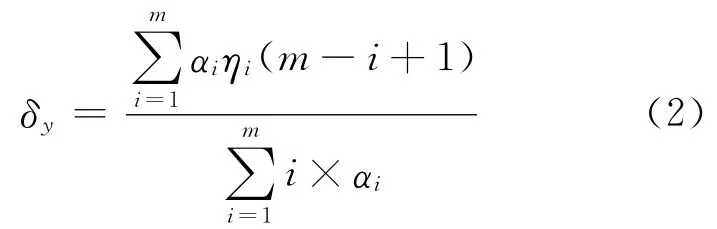
最相异系数δy的取值范围为[0,∞),δy越小则两向量越相近,当且仅当δy=0时,两向量完全相同。显然δy是γ的前n个较大数据项的加权平均值,被忽略的数据项相对误差小,对判决过程影响较小,甚至可以忽略,同时,由于各项权值不同,越大的相对误差给定的权值越大,有效突出了其对判决的影响,同时位置权值αi强调了数据项本身的价值,δy突出了业务上的意义。
1.3 基于相似度的两阶段聚类算法步骤
算法分两阶段进行,第一阶段以集合相似性为判定标准,按聚类算法把数据分为不同的子类簇,目的是将相同或相近的业务归到同一类簇;度量向量最大相异系数为判定标准,当系数阀值过小时,可能产生较多的族类;第二阶段以向量相异系数为判定标准,将上阶段产生的类簇进一步分类,目的是把同一类簇中的可疑业务分离出来。算法的具体步骤如下:
1)由专家指定各项业务的各个特点的典型实例作为初始族类Y={Y1,Y2,…,Yn};
2)任取x∈U,令X={x},如果r(X,Yi)<Δ1,则Yi=Yi∪{x},否则令Y={Y1,Y2,…,Yn)∪{Yn+1},其中Yn+1={x};
3)重复2),得Y={Y1,Y2,…,Yn,Yn+1,…,Yn+k};
4)∀Yj={x1,x2,…,xl}∈Y,n+k≥j≥1,令j=1;
5)∀xi1,xi2∈Yj,令Yn+k+1={xi1},如果δx2<Δ2,则令Yn+k+1=Yn+k+1∪{xi2};
6)重复5),直到Yj所有的向量处理完毕,删除Yj;
7)重复4),5),直到j=n+k;
8)输出Y中元素个数小于指定数量的类簇。
2 实验分析
实验采用的数据来自泰安某保险公司的客户投保信息数据库。投保信息分为12个大类,含73个子类,所有近3年的近1万多条记录。由该公司理赔部专家指定73条业务记录作初始族类,把每个子类的数据项划分出无效因子、弱显著性因子和显著因子3部分,为每个子类指定Δ的值。采用的对比算法为欺诈识别聚类算法[8]和3-Sigma(3tr)统计检测法。
下面分别给出3种算法得到的孤立点搜索结果见表1。

表1 文中算法、欺诈识别聚类算法和3-Sigma搜索孤立点对比表
其中,文中算法设置的阀值Δ1=0.083,Δ2=0.041,欺诈识别聚类算法的阀值为0.1(原文指出为最佳参数)。
从实验可以看出,文中算法搜索到保险欺诈数量比另两种算法多,通过与该保险公司合作对算法发现的部分保户进一步核实,确实发现了其中部分保户存在欺诈行为而没有被发现,文中算法的欺诈发现算法效果较好。
3种算法的执行时间比较如图1所示。
由图1可知,当数据量较小时,文中算法在执行时间上消耗较大,而当数据量增大时,3种算法逐步接近,当数据量达到一定规模时,3-Sigma算法的时间消耗远超其它两种,而文中算法也快速接近欺诈识别聚类算法。
3 结 语
针对保险业近年来不断上升的欺诈行为进行了深入研究,在前人研究的基础上,推导出了基于粗糙集的模糊集合相似性度量公式以提高聚类效果,改进了向量相似性判断方法最大相异系数,提高了算法执行效率,文中提出了基于聚类算法的两阶段孤立点发现算法,并应用到保险企业欺诈发现问题中,经一定规模数据量的试验验证了文中算法的有效性和可行性,识别效果表现良好。文中算法的缺点是参数设定和聚类初始值是由专家指定,使之通用性受到很大影响,需要进一步改进。
[1]叶明华.我国机动车保险欺诈识别的因子分析[J].华东经济管理,2010,24(2):84-86.
[2]陈亮.基于混合蛙跳算法的背包问题求解算法[J].河南城建学院学报,2011,20(3):41-44.
[3]赵丽霞.个体风险模型中总索赔分布函数的估值问题[J].长春工业大学学报:自然科学版,2011,32(2):191-194.
[4]吴瑞,宁玉富,郭长友.基于模糊粗糙近似的web浏览模式的聚类[J].系统工程学报,2010,25(1):132-137.
[5]仲兆满.基于相似度的粗糙集近似算子快速求解[J].小型微型计算机系统,2010,31(1):251-252.
[6]张宇.向量相似度测度方法[J].火控雷达技术,2009,28(4):78-81.
[7]叶明华.我国机动车保险欺诈识别的因子分析[J].华东经济管理,2010,24(2):84-86.
[8]Rekha Bhowmik.Detecting auto insurance fraud by data mining techniques[J].Journal of Emerging Trends in Computing and Information Sciences,2011,2(4):371-377.
猜你喜欢
眼科新进展(2022年12期)2022-12-29
科教导刊·电子版(2021年6期)2021-05-06
甘肃科技(2020年19期)2020-03-11
中国外汇(2019年16期)2019-11-16
计算机与生活(2019年11期)2019-11-12
成都信息工程大学学报(2019年2期)2019-08-28
中国外汇(2019年10期)2019-08-27
科技与创新(2019年14期)2019-08-12
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
