
基于云计算的物联网数据挖掘
2012-08-01 07:14张海江赵建民朱信忠徐慧英
微型电脑应用 2012年6期
张海江,赵建民,朱信忠,徐慧英
0 引言
随着物联网的迅猛发展,芯片技术、无线网络技术、传感技术、全球导航系统等技术不断完善与成熟,信息传感、信息收集、信息感知已不再是问题。物联网中会产生RFID数据流、地址/唯一标识、位置数据、环境数据和传感器网络数据等数据,如何在这海量的数据集中发现有用的信息已成为数据挖掘研究的热点。云计算与数据挖掘技术相结合,可以增强物联网的数据处理能力,利用云模式下数以百万的计算机集群,提供强大的可信计算能力,弹性可扩展技术、分布式存储机制以及分布式计算技术,快速地对海量的业务数据进行分析、处理、存储、挖掘,在短时间内提取有价值的信息,为物联网的商业决策服务。
物联网数据挖掘主要以RFID 信息数据为研究对象,利用数据挖掘的技术分析发现各种物品的潜在的有价值的信息。在实际领域中,对RFID 数据的挖掘主要集中在对RFID数据流分析、基于路径的分类和聚类分析、频繁模式和序列模式分析以及孤立点分析等问题[1]上。其中,RFID 路径挖掘对于企业分析货物流通方向和流通时间,商业决策,有着非常重要的意义。RFID 采集的原始数据是一个三元组:EPC(标签的标识码)、Location(阅读器读取标签的地点)、Time(阅读器读取标签的时间),这些数据总是海量的、分布式的、时间和空间相关的。同时,这些海量的数据是异构的、动态的,节点的资源是有限的等这些特征,对数据进行精确的挖掘就十分困难。目前物联网数据挖掘待研究的两个问题:一是如何整合存储这些动态异构的数据;二是如何实现高性能、可伸缩的分布式并行的数据挖掘算法,保证挖掘的精确性及效率性。
物联网数据挖掘处理的是海量的数据,并且这些动态异构的数据都是以指数级增长的,制定物联网数据交换的标准也颇具难度,同时数据挖掘的算法的设计也面临着巨大的挑战。本文采用PML[2](实体标识语言)来来描述物联网上采集到的RFID 异构数据信息,并且融入云计算技术,可以解决物联网中分布的海量数据信息的数据挖掘问题,具有非常重要的意义。
1 云计算的概述
1.1 云计算的定义
云计算是将各种资源通过整合、抽象后提供给用户的一种产业模式及技术体系的总称,其核心就是集中计算资源、分布式存储、分布式并行计算,处理效率得到充分发挥,用于千变万化的应用,实现IT 架构中的资源抽象和简化,经过资源整合而形成简洁的资源池。
1.2 Hadoop 开源架构概述
1.2.1 Hadoop 基本结构
Hadoop 从上层架构上看是一个典型的主从式结构,它提供一个开源的框架,用于开发高度可扩展的分布式计算应用软件。Hadoop 框架负责处理任务并行分配的细节,使得应用程序开发者可以专注于应用程序逻辑上[4]。其基本结构,如图1所示:

图1 Hadoop 基本结构
Hadoop 真正的创新在于不相信节点服务器,将服务器作为一种不稳定的系统来对待,利用低档的服务器集群来存储与计算,大大降低服务器成本,同时采用副本策略的计算存储迁移,解决了节点失效问题。
1.2.2 Map/Reduce 编程模型
Map/Reduce 编程可以屏蔽底层的实现机制,向上层提供大量的接口,使开发者方便的开发分布式计算程序。Map/Reduce 两项重要的核心操作:Map 和 Reduce,即映射和规约。一个Map 函数就是对存储在HDFS 各个节点上的原始数据进行指定的操作,每个Map 之间是并行的,且相互独立的。一个Reduce 函数就是对每一个Map所产生的中间结果进行归约合并操作,每个Reduce 处理所得的中间结果是不相交的。这整个计算过程中,Map/Reduce 模型都是使用(key,value)的键值对作为输入和输出的,最后由Reduce 输出结果。
Map/Reduce 操作过程[5]:
(1)Map/Reduce 先把输入的文件分成M 块,通过参数决定每块的大小(大概16M-64M);
(2)执行程序,分为主控程序Master 和分工作机Worker。总共有M 个Map 操作和R 个Reduce 操作,由Master把这些Map 或Reduce 处理任务分配给处于空闲列表中的Worker;
(3)一个被分配Map 任务的Worker 读取处理数据后将
(4)这些缓存中的中间结果被定时写到本地硬盘,通过分区函数分成R 个块区,然后Master 把这些数据在本地硬盘上的位置信息传送给Reduce 函数;
(5)Reduce Worker 根据Master 传递的文件信息以远程读取的方式找到对应的本地文件,对文件中的中间Key进行有序排列后再远程发送到具体执行的Reduce 上;
(6)Reduce Worker 根据key 遍历排序后的中间数据,并把key 和相关的中间结果集传给Reduce 函数来把结果写到一个最终的输出文件;
(7)当所有的Map 和Reduce 任务都完成时,Master激活用户程序。此时,MapReduce 返回用户程序的调用点。
2 基于云计算的物联网数据挖掘系统的设计与实现
2.1 系统概述
基于云计算的物联网数据挖掘系统处理海量的动态异构数据,其流程与一般的数据挖掘基本一致,但是其处理数据的方式却是不同的,借助了Hadoop 中的Map/Reduce模式来处理:一、首先把物联网中的RFID 异构数据进行过滤、转换、合并转为一种PML 文件后,保存到分布式系统HDFS 中,同时采用副本策略,一个文件都会产生2-3 个副本并将其保存在同一机构的不同节点上或者不同机构的某个节点上,这样子可以解决高效率存储与处理问题,同时解决了节点失效问题。二、执行任务时,由主控程序Master负责任务的创建、管理控制,同时分配任务给空闲状态下的Worker 去处理,经过Map/Reduce 操作后由Master 负责将最终结果归并,返回给客户。
2.2 计算和存储的整合及迁移
数据存储的分布式方式可以实现计算向存储的迁移,因此云计算的一个重要特征就是计算和存储的整合。Map/Reduce 处理过程中,Map 在每一个节点上的操作都是相互独立的,没有数据的传输,只有在Reduce 过程中会向Master 传送计算结果,对于物联网中的挖掘是计算和数据同时密集的任务,实现计算向存储的迁移,可以大大节省数据的传输时间。其实现策略为:采用Map/Reduce思想分割PML文件(大小为16M-64M),先暂存到缓存中,然后定时发送至本地硬盘中,由Master 保存这些信息的位置信息,并在保存这些数据块的Worker 上执行Map 任务,这种策略是在本地计算机上操作的,大大节省了数据的传输时间。此外,还采用了PML 文件副本策略。在当前节点失效的情况下,Master 节点会根据DataNode 节点上副本数据的存储情况找到一个存有副本的DataNode 节点,并把计算迁移到该节点重新对该数据进行处理工作,这样不会重启整个工作,同时在计算迁移的过程中数据不会在DataNode 节点间相互传递,因此节省了数据传输时间,效率非常高。
2.3 系统架构的设计与实现

图2 基于云计算的物联网数据挖掘系统基本架构图
本文设计的基于云计算的物联网数据挖掘系统的基本结构,如图2所示:由数据存储层、数据挖掘算法层、挖掘任务处理层这三层组成。整个系统由Master 作为主控节点,负责与用户进行交互,并且负责调度与管理整个系统中节点之间的工作;系统中有一部分节点用于存储Map/Reduce 化的数据挖掘算法,用于进行高效地挖掘;此外,HDFS 分布式存储系统中,有一个NameNode 主节点和若干DataNode 子节点。用户的请求由 NameNode 进行接收并将存储数据的DataNode的 IP 返回给用户,并通知其他接收副本的DataNode。
2.3.1 数据存储层数据存储层采用主从式分布式系统存储HDFS,系统由一个NameNode 主节点和多个DataNode 子节点组成,其基本结构,如图3所示:

图3 HDHS 基本结构
数据存储层负责存储和读取由物联网上采集并转化的PML 文件。该层集成了过滤转化中间件,可自动把物联网上的海量数据解析为结构化的PML 文件,并且由NameNode分割成大小为16M-64M的文件存入HDFS 中,同时提供了大量的分布式数据访问接口。NameNode 存储着PML 文件的元数据,元数据中包含了文件系统的名字空间等,向用户映射文件系统,并且负责管理PML 文件的存储和处理,但是实际的数据并不存放在NameNode 下,NameNode的作用就像文件系统的总指挥,而实际数据存放在DataNode 下,因此,用户直接与DataNode 建立通信,进行访问。另外,本系统还采用数据块副本策略来解决节点失效问题,使计算向存储迁移,同时节省了数据传输的时间,大大提高了处理效率。每个PML 文件都有2 个副本,一个存放在同一机构下的不同节点,另一个存放在不同机构下的某个节点上,当当前节点失效的情况下,由NameNode 找到存有当前处理PML 数据块副本的节点,然后将计算迁移过去来完成数据的处理。
2.3.2 数据挖掘算法层
算法节点中集成了数据挖掘的常用算法,这些算法都是进行Map/Reduce 化的,可以运用于云计算平台的。在实际的使用过程中是由Master 主控节点来控制管理的,按照客户请求将算法传输到相应的节点进行计算。本文的分布式并行的关联规则算法是将Apriori 算法Map/Reduce 化而得到的。
2.3.3 挖掘任务处理层
任务调度是基于云计算的分布式数据挖掘系统设计的核心所在,系统中所有的挖掘器都由 Master 负责调度,执行流程如下:由Mater 查找空闲的DataNode 节点,找到后将该DataNode 放入空闲节点列表。Master 接收用户的请求,获得各DataNode 中数据块的存储信息以及挖掘时所需调用的算法,然后向算法存储节点申请所需的挖掘算法,挖掘算法存储节点直接将所需的算法发送到原始数据所在的DataNode 节点上,计算任务立即在HDFS 服务器启动计算工作,完成后只向Master 传送相关结果,期间并不向Master传送文件数据块,Master 汇总后生成最终的结果返回给用户。这一处理过程中没有了数据重组和传送的过程,计算和存储在一个节点上,节省了文件传输时间。
2.4 基于云计算的数据挖掘算法
数据挖掘算法种类繁多,有序列模式、分类聚类、关联规则等,其中关联规则在物联网数据挖掘中发挥着重要作用。Apriori 算法使用逐层搜索迭代的方式利用K 项集来探索(K+1)项集。第一步先扫描一次数据集,产生频繁1-项集L1,然后利用L1来探索频繁项集L2,不断迭代,直到频繁项集为空为止。同时,运用频繁项集的任意子集都是频繁项集这一性质来进行对搜索空间的压缩处理,提高生成频繁项集的效率。其具体过程如下:在第K 次循环搜索中,首先进行连接(JOIN)操作,由LK-1产生候选集候选集CK,然后进行连接操作,再根据Apriori的一些性质进行统计支持度操作以及剪枝操作,接着由CK产生频繁项集LK。此算法的缺点就是需要对数据库进行多次扫描才能够发现所有的频繁项集,在物联网如此海量的数据面前,多次扫描的话会耗费大量的时间和内存,本文利用云计算平台的分布式并行计算的性质把Apriori 算法移植上去,把扫描数据库查找频繁项集得到并联规则的工作放进Hadoop 架构中,在各个DataNode 节点并行扫描处理,得到各自计算节点上的局部频繁项集,然后再由Master 统计出实际的全局支持度,并且最终确定全局的频繁项集,将Apriori 算法移植进云平台可以大大提高其挖掘的效率,同时节省了时间和内存耗费。
将Apriori 算法Map/Reduce 化及其处理流程如下:首先由用户提出挖掘服务的请求,并且设置给出所需关联规则的最小支持度和最小置信度。接着当Master 接到请求后,向NameNode 申请所需的PML 数据文件,同时访问空闲节点列表,对空闲的DataNode 分配任务,把存储算法节点的算法调度到各个DataNode 进行并行处理。每个DataNode都可以通过Map 函数把
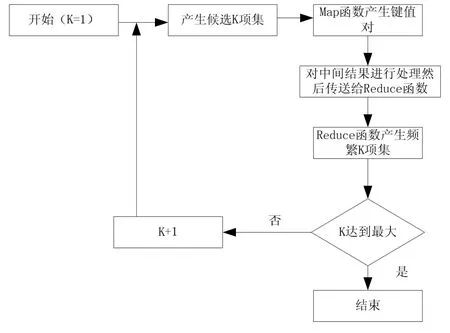
图4 M ap/ Reduce 化的的Apriori 挖掘算法实现流程
3 结论
随着物联网的不断发展,物联网上海量的动态异构的数据在不断增长,对这些数据的挖掘越来越困难,与传统的物联网数据挖掘相比,基于云计算的物联网数据挖掘系统,其分布式存储机制、分布式并行计算、计算存储迁移等功能解决了数据存储以及节点失效的问题,降低了数据传输的时间,同时大大提高了挖掘的效率。系统能够面向商业运用,为商业决策服务。
[1]顿海强,赵文,邓鹏鹏,等.一种基于RFlD 数据集的物品工作流挖掘方法[J].电子学报,200802A).
[2]David L.Brock The Physical Markup Language,Feb,2001.
[3]Hsu I-Ching,Chi Li-Pin,Bor Sheau-Shong.A platform for transcoding heterogeneous markup documents usingontology-based metadata[J].Journal of Network and Computer Applications,2009,32(3):616-629.
[4]王鹏.云计算的关键技术与应用实例.[M]人民邮电出版社,2010.1
[5]刘鹏.云计算.[M]电子工业出版社。2010
[6]万至臻.基于MapReduce 模型的并行计算平台的设计与实现[ D].杭州:浙江大学,2008
[7]王鄂,李铭.云计算下的海量数据挖掘研究[ J].现代计算机,2009,319(1):22 -25.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
网络安全和信息化(2019年8期)2019-08-28
当代陕西(2019年14期)2019-08-26
计算机系统应用(2019年2期)2019-04-10
天津科技大学学报(2018年4期)2018-08-22
大连理工大学学报(2017年5期)2017-09-20
中学数学杂志(初中版)(2016年5期)2016-11-01
现代电子技术(2015年2期)2015-09-18
导航定位学报(2015年2期)2015-06-05
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
