
网页兴趣度度量方法及其在兴趣模型中的应用研究
2012-08-01 07:14南智敏钱松荣
微型电脑应用 2012年6期
南智敏,钱松荣
0 引言
互联网已经成为了人们获取资讯信息的重要途径。面对海量信息,人们习惯使用搜索引擎进行信息检索,但目前搜索引擎只做关键词匹配,很难区分用户兴趣,往往会推荐一些用户不感兴趣的内容,从而浪费了用户甄别信息的时间。因而有必要建立一个可用的用户兴趣模型,根据用户兴趣去推荐内容,以提高信息的推荐质量。
目前发现用户兴趣的方法主要有两种:(1)通过用户主动提供个人兴趣来直接得到用户兴趣;(2)通过用户的操作信息来分析得到用户兴趣[1]。前者存在用户兴趣描述准确性、完整性、实时性等方面的缺陷;相比,后者更能准确地反映出用户的兴趣。用户的操作信息包括访问内容和访问时的动作。对于访问内容,通常采用文本聚类、语义分析等方法进行聚类分析。其中尤以文本聚类方法为多,即以向量空间模型(Vector Space Model,简称VSM)来表征用户浏览的内容,进而聚类找出用户的兴趣所在[2]。对动作行为的分析是为了获得用户对内容的感兴趣程度,即兴趣度(Interest Rate,简称IR)。目前对内容兴趣度的评价存在量化合理性的问题,评价方式较为粗糙。文献[3]提出了一种基于时间的兴趣度度量方法,但其算法较为简单,容易引起偏差。在这方面本文提出一种更加合理的用户行为评估算法。
1 网页的用户兴趣评价
网页的用户兴趣评价分为两部分:基于VSM的网页内容表征和基于用户浏览行为的网页兴趣度评价[4]。
1.1 基于VSM的网页内容表征
在对网页内容进行表征之前,需要对网页内容进行一些预处理,去除网页上的广告、导航、脚本、显示样式等冗余信息和内容中的无意义词、干扰词和高频词,避免这些信息对用户兴趣模型的准确性造成影响。
对处理后的网页内容使用VSM 法进行表征。忽略HTML 标签,将网页内容进行文本分词,根据词频取出词频最高的m 个特征词作为向量的m 个维度,将网页内容表征为词频特征向量{(term1,weight1),(term2,weight2),...,(termm,weightm)}。其中termi为词条,weighti为对应的词频。考虑到title、h1 等标签内的内容相对重要,在词频统计时,对于这些特殊标签内的内容进行加权处理[5],本文设定title 标签内的内容权值为4,h1 标签内的内容权值为3,h2 标签内的内容权值为2,其他内容权值为1。
1.2 基于用户浏览行为的网页兴趣度评价
单纯对网页内容进行词频统计无法反应出用户对网页内容的感兴趣程度。例如,用户打开了某些网页,发现不感兴趣会马上关掉,把这些网页放在兴趣模型的统计范畴内是不合理的。需要对用户的浏览行为进行观察,分析出用户对网页的兴趣度,从而降低这些网页对推荐结果造成的干扰。
用户浏览网页时的操作行为多样。 Nichols 给出了能够作为隐式反馈的用户行为类型列表,如访问、打印/保存、删除、引用、回复、标注、阅读、略读、查询等[6]。对于众多的用户行为,根据行为所能体现的用户对网页的兴趣度的不同,将行为分为重要动作行为和普通动作行为。从而提出了兴趣度评价算法,以伪代码表示为:

其中,action 代表用户浏览网页时发生的动作;{ save,print,copy,bookmark,…}是用户在浏览时可能发生的保存(save)、打印(print)、复制(copy)、收藏(bookmark)等重要动作集合;IR 为通过计算得到的用户兴趣度;rt (read time)为用户阅读某个页面时的停留时间;f(rt)为rt 到IR的映射函数,其具体形式将在下文给出。
除了重要操作性动作外,其余诸如选择、浏览、拖拉滚动条、点击鼠标、滚动鼠标等用户行为均会延长用户浏览网页的时间,在一定程度上可以用浏览时间来表征。考虑到前文所述用户打开了网页但立刻关闭的情形,说明此时用户对该网页不感兴趣,兴趣度为0;相反,用户打开了网页并停留了很长时间,并不说明用户对该网页内容很感兴趣,而可能是意外原因没有及时关闭网页,由于无法判断,因而视用户对该网页的兴趣度为0。采用阅读时间来评价用户对网页内容的兴趣度还与网页的长度和阅读者的阅读速度有关。正常情况下,阅读速度一定,网页内容dl (document length)越长,则阅读时间越长;反之,阅读时间越短。如果网页内容长度一定,阅读者阅读速度越慢,那么阅读时间就会越长。阅读速度差异在现实中普遍存在,如大多数老年人的阅读速度慢于年轻人。从以上分析可知,单纯的阅读时间无法准确反映出用户对某一网页的兴趣度,还必须结合网页内容长度以及用户的阅读速度等因素。为此,本文引入单字阅读时间swrt (single word read time)以及平均单字阅读时间()的概念,swrt=rt/dl,为用户在每个单字上的统计平均阅读时间,通过对用户多次阅读的swrt 取平均得到。swrt 和的引入能够很好地消除网页长度和阅读速度差异所带来的影响,使得兴趣度的评价更加合理。至此,将上文算法中的f(rt)用F(swrt)代替,F(swrt)为兴趣度IR 关于swrt的函数,采用分段函数进行拟合,如式公1所示:
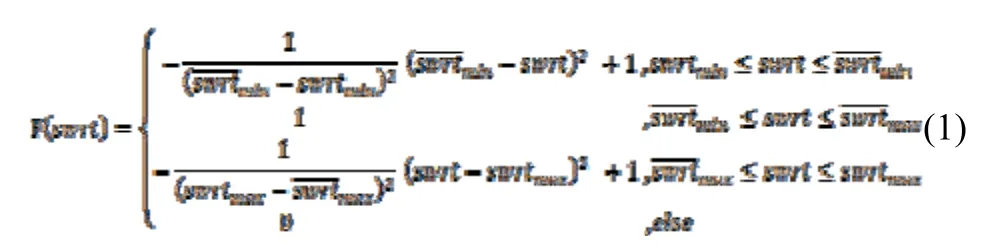
根据经验,普通人阅读速度为300 至500 字每分钟,取兴趣度为1的两个临界值为60/500=0.12秒每字,为60/300=0.2秒每字;取兴趣度为0的两个临界值删除、引用、回复、标注、阅读、略读、查询等[6]。对于众多的用户行为,根据行为所能体现的用户对网页的兴趣度的不同,将行为分为重要动作行为和普通动作行为。从而提出了兴趣度评价算法,以伪代码表示为:
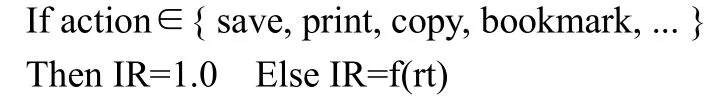
其中,action代表用户浏览网页时发生的动作;{ save,print, copy, bookmark, …}是用户在浏览时可能发生的保存(save)、打印(print)、复制(copy)、收藏(bookmark)等重要动作集合;IR为通过计算得到的用户兴趣度;rt (read time)为用户阅读某个页面时的停留时间;f(rt)为rt到IR的映射函数,其具体形式将在下文给出。
除了重要操作性动作外,其余诸如选择、浏览、拖拉滚动条、点击鼠标、滚动鼠标等用户行为均会延长用户浏览网页的时间,在一定程度上可以用浏览时间来表征。考虑到前文所述用户打开了网页但立刻关闭的情形,说明此时用户对该网页不感兴趣,兴趣度为0;相反,用户打开了网页并停留了很长时间,并不说明用户对该网页内容很感兴趣,而可能是意外原因没有及时关闭网页,由于无法判断,因而视用户对该网页的兴趣度为0。采用阅读时间来评价用户对网页内容的兴趣度还与网页的长度和阅读者的阅读速度有关。正常情况下,阅读速度一定,网页内容dl (document length)越长,则阅读时间越长;反之,阅读时间越短。如果网页内容长度一定,阅读者阅读速度越慢,那么阅读时间就会越长。阅读速度差异在现实中普遍存在,如大多数老年人的阅读速度慢于年轻人。从以上分析可知,单纯的阅读时间无法准确反映出用户对某一网页的兴趣度,还必须结合网页内容长度以及用户的阅读速度等因素。为此,本文引入单字阅读时间swrt (single word read time)以及平均单字阅读时间()的概念,swrt=rt/dl,为用户在每个单字上的统计平均阅读时间,通过对用户多次阅读的swrt取平均得到。swrt和的引入能够很好地消除网页长度和阅读速度差异所带来的影响,使得兴趣度的评价更加合理。至此,将上文算法中的f(rt)用F(swrt)代替,F(swrt)为兴趣度IR关于swrt的函数,采用分段函数进行拟合,如式公1所示:
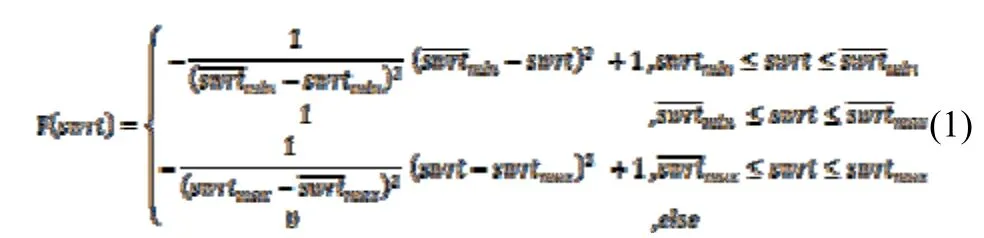
根据经验,普通人阅读速度为300至500字每分钟,取兴趣度为1的两个临界值min为60/500=0.12秒每字,max为60/300=0.2秒每字;取兴趣度为0的两个临界值swrtmin为0.01秒每字,swrtmax为1秒每字,代入式1,得到式2,对公式2作图,F(swrt)函数曲线,如图1所示:
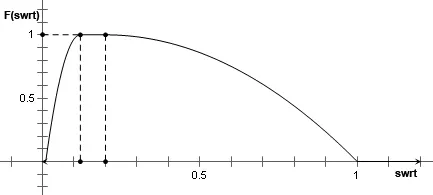
图1 F(swrt)函数曲线
结合式2和上文中的兴趣度评价算法可以根据用户的操作信息分析得到用户对于某一网页的兴趣度。
2 用户兴趣模型
2.1 用户兴趣模型的表示
传统的VSM模型使用(term, weight)对来表征用户浏览某个网页所隐含的兴趣信息。本文在VSM模型的基础上对每次浏览行为引入了兴趣度IR的表征,将网页兴趣向量扩展表示为{(term1, weight1),(term2, weight2),..., (termm,weightm),IR}。用户的兴趣模型最终表征为公式3:

其中,n为兴趣模型包含的用户兴趣数,即兴趣向量的个数;m为每个兴趣向量所包含的维数;如某个兴趣向量维数不足m,则空缺的维度(termi,j, weighti,j)以("",0)填充。
2.2 用户兴趣模型的初始化
系统初始启动时,用户兴趣模型为空矩阵。此时可以由用户主动提供能表征自己兴趣的多组词语来构建出初始状态的兴趣模型矩阵;也可以根据用户的收藏夹记录或历史访问记录来生成用户的兴趣模型。根据用户的收藏夹记录、历史访问记录获取对应网页,使用上文所述的基于VSM模型的网页内容表征方法对所有网页进行内容特征表示,在每个特征向量中加入平均用户兴趣度 ,从而构建出用户的初始兴趣模型矩阵。根据初始用户兴趣矩阵可以实现在未获取到用户浏览操作信息之前向用户推荐其感兴趣的文章。
2.3 用户兴趣模型的更新
在用户浏览网页过程中,记录下用户浏览的网页内容、操作行为和浏览时间,使用基于VSM的网页内容表征方法表示出网页内容特征,根据网页兴趣度度量算法计算出用户对网页内容的兴趣度,结合起来得到用户浏览每个网页过程中隐含的用户兴趣——以兴趣向量的形式来表示。用户的每一次浏览行为都会得到一个兴趣向量,在更新用户兴趣模型时需要对这些兴趣向量进行聚合,聚合后得到最终的用户模型矩阵供后续使用。聚合过程采用以下算法:
算法1. 兴趣向量的和操作Vr+ Vs, Vr= {(termr1,weightr1), ..., (termrm, weightrm), IRr}, Vs= {(terms1,weights1), ..., (termsm, weightsm), IRs},计算步骤如下:
1)如果某个词term既在Vr中又在Vs中,则把该词在Vr和Vs中的权值weight相加的和作为它在Vr的权值;
2)如果某个词term 在Vs但不在Vr中,那么把该词和它在Vs中的权值weight 加入到Vr中;
3)新得到的Vr按权值从大到小排序,取前m 个元素作为结果的前m 维元素,结果向量的兴趣度为IRr+IRs。
算法2.两个m 维兴趣向量Vr和Vs的相似度,计算过程如公式4所示:
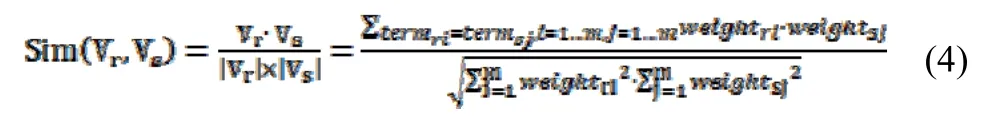
其中兴趣度IRr和IRs不参与Vr和Vs的相似度计算。算法3.兴趣矩阵Pz的N-压缩操作,将Pz压缩为行向量数
不超过N的矩阵,计算步骤如下:
1)若|Pz|≤N,则返回Pz作为结果;
2)否则,计算矩阵Pz中任意两个向量的相似度Sim(Vr,Vs);
3)找出最大相似度,如最大相似度大于Simthreshold则转到步骤4;否则转到步骤5。其中Simthreshold为可合并的最小相似度;
4)合并具有最大相似度的两个向量,合并规则为用Vr+Vs替换掉Pz原有的Vr和Vs。回到步骤2;
5)根据每个兴趣向量中的兴趣度IR 对Pz中的向量从大到小排序,Pz只保留前N 个向量组成矩阵,其余向量丢弃,返回处理后的Pz作为结果。
2.4 用户兴趣模型的使用
根据得到的用户兴趣模型,可以有针对性地给用户推荐其可能感兴趣的新网页内容,具体使用步骤如下:
1)利用基于VSM 模型的网页内容表征方法计算出用于表征新网页的网页内容特征向量Vnew
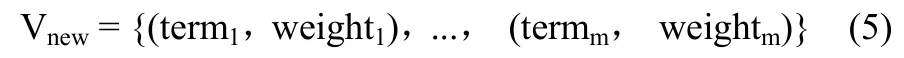
2)通过以下评价公式得到新网页的兴趣评价值E:
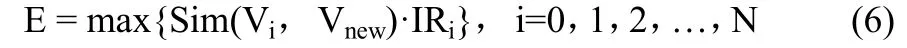
其中Sim(Vi,Vnew)为用户兴趣模型中第i 个兴趣向量Vi与Vnew的相似度,计算方法同算法2。
3)对所有新网页根据计算得到的E 值从大到小排序,将E 值超过一定阈值的或者E 值较大的若干篇网页推荐给用户。
3 实验结果及分析
实验采集门户网站上世博栏目和曼联栏目下各1000 篇文章生成语料库作为实验数据,并建立了加入本文提出的兴趣度度量算法的兴趣模型实验系统。实验使用基于K-Means聚类的用户兴趣模型进行对比。
实验一、正常阅读10 篇世博文章,打开并快速关闭10篇曼联文章,使用本文的用户兴趣模型和基于K-Means的用户兴趣模型进行文章推荐,兴趣模型推荐结果,如表1所示:

表1 用户兴趣模型推荐结果
可以发现打开并快速关闭10 篇曼联文章的浏览操作在本文提出的兴趣模型中对推荐结果没有造成影响,而在K-Means 模型中则产生了较大的影响。
实验二、模拟用户以0.7的兴趣度阅读10 篇世博文章,以0.3的兴趣度阅读10 篇曼联文章,使用本文提出的用户兴趣模型和基于K-Means的用户兴趣模型进行文章推荐,推荐结果中世博文章所占比例,如图2所示:
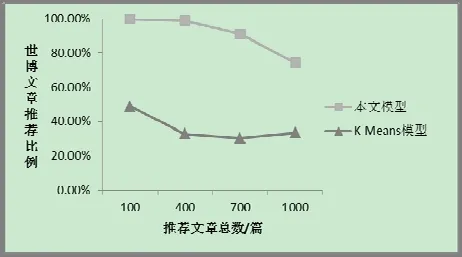
图2 世博文章推荐比例
分析结果可知本文提出的用户兴趣模型可以优先推荐用户兴趣度大的文章,符合用户兴趣分布。
4 结论
本文在前人研究的基础上,对VSM 模型做了拓展,引入了兴趣度IR的概念,采用兴趣度来表征用户对于网页内容的喜好程度。在计算用户对某一网页的兴趣度时,提出了一种可量化的基于隐式反馈信息的兴趣度评价算法,能够较为准确地计算出用户对网页的喜好程度。
在未来的工作中,将考虑兴趣的转移特性并引入兴趣模型的反馈模块,更有效地对建立的兴趣模型进行优化,使最终的兴趣模型更贴近用户的真实兴趣。同时,在构建VSM向量时,考虑引入语义算法,合并一些同义词,提高每个兴趣向量的价值,进一步优化兴趣模型的准确性和计算效率。
[1]Zhao ZY,Feng SZ.Mining User's Interest from Interactive Behaviors in QA System[C].2009 First International Workshop on Education Technology and Computer Science.
[2]Debajyoti M,Ruma D,Anirban K,Rana D.A Product Recommendation System Using Vector Space Model and Association Rule[C].International Conference on Information Technology,2008.
[3]李峰,裴军,游之洋.基于隐式反馈的自适应用户兴趣模型[J].计算机工程与应用,2008,44(9):76-79.
[4]Jehwan O,Seunghwa L,Eunseok L.A User Modeling using Implicit Feedback for Effective Recommender System[C].International Conference on Convergence and Hybrid Information Technology 2008.
[5]张彦,张永奎,安增波,王鹏.基于层次概念的用户兴趣模型研究[J].计算机工程与设计,2008,29(1):181-183
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
成都信息工程大学学报(2021年6期)2021-02-12
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
