
基于关联度的汉藏多词单元等价对抽取方法
2012-06-29 05:53诺明花刘汇丹丁治明
中文信息学报 2012年3期
诺明花,刘汇丹,吴 健,丁治明
(1. 中国科学院 软件研究所,北京100190;2. 中国科学院 研究生院,北京 100049)
1 引言
长尾真(Nagao,M.)[1]提出:计算机辅助翻译的过程一般是首先将输入句子分解为片段,接着把这些片段译成目标语言,最后把这些片段合并成长句,其中每个片段采取类比的原则进行翻译。这些片段可以是词、短语或其他由多个词组合而成的语言单位,我们将这些语言单位统称为多词单元。多词单元是单词的扩展,单词和多词单元一起构成了翻译的基本单位。在汉藏翻译过程中,从翻译人员的实践来看,仅仅把词作为翻译的基本单位并不合适,将多词单元作为一个整体来翻译更能够保证译文的准确度和流利度,这种整体性的翻译对于提高全文翻译的质量是大有好处的。
本文将要构建汉藏辅助翻译系统的多词单元翻译词典,其中每条记录包含汉语有效多词单元以及对应的藏文译文。基于双语语料库进行翻译词典编纂,国内外很多研究者都做了大量工作[2-3]。在汉藏短语对抽取方面,国内已经有了一些研究。文献[4]中提出藏文词串频率统计算法(简称TSM)和藏文词串序列相交算法(简称TIA)两种方法进行汉藏短语对抽取。TIA算法使用藏文词序列相交短语译文获取模型(Sequence Intersection Based Phrase Translation Extraction Model,SIBPTM),对句对齐双语语料库中包含待翻译汉语语块的句对集合求交集来抽取译文。为了提高准确率,SIBPTM模型以汉藏词典为辅助资源,并设定阈值解决部分未登录现象。由于使用的汉藏双语词典覆盖率较低,未登录现象较突出,所以,这种方法能够抽取的短语对规模有限。如果用大规模语料库进行训练以扩大覆盖率,一定程度上可以弥补召回率低的缺陷,但是汉藏机器翻译的研究还处于起步阶段,平行语料库规模十分有限。因此,在当前形势下,相对而言,准确率显得不是特别重要,如何提高召回率是当前更需要考虑的问题。
本文重点研究如何提高基于汉藏对齐语料库的多词单元等价对抽取方法召回率的问题。
2 基于关联度的多词单元等价对获取模型
本文提出CMWEPM(Collocation Based Multi-Word Equivalence Pair Extraction Model)模型来抽取汉藏多词单元等价对。与SIBPTM类似,CMWEPM模型同样分两步完成翻译等价对的抽取,但是它在获取有效汉语语块及确定译文方法上均与SIBPTM模型不同。
为了识别汉语多词单元,本文使用Ying Zhang和Ralf Brown等人[5]提出的关联度(Collocation)度量指标。下面简要介绍这个度量指标。
2.1 关联度
Collocation可以比较全面地衡量事件关联度,其定义如下:
(1)
其中,VMI是平均互信息;w1,w2是待衡量的两个事件,在本文中指单词的出现。VMI定义如下:
VMI(w1,w2)
(2)

H是一个词的平均信息量,是指每个词所含的信息量的统计。N个离散消息源的平均信息量定义如式(3),在本文中离散消息源指汉语单词。
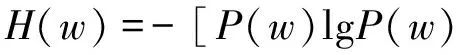

(3)
本文使用的平均互信息VMI值是建立在相邻两个词共现概率的基础之上的,但不仅仅是两个词的互信息MI值。可以看出,在VMI的计算公式中,前两项分别是两个词同时出现、同时不出现的情况,表现了对两个词共现有贡献的互信息;后两项是一个词出现而另一个词不出现的情况,表现了对共现有抵消作用的互信息。平均互信息能够综合考虑整个语料库的情况,可以全面地衡量两个词之间的关联度。
然而,平均互信息值也只是说明了两个词共现的趋势大小,该值高只能表明w1、w2同时出现的趋势大,可能它们其中一个或者两个都是高频词,因此,这两个词出现的频率应该被考虑进去。式中分母即是w1、w2的平均信息量,对平均互信息值起到归一化的作用。
假设句子片段包含三个词w1,w2,w3.将w1与w2的Collocation值记为x,w2与w3的Collocation值记为y,则BindingDegree(x,y)计算方法如下:
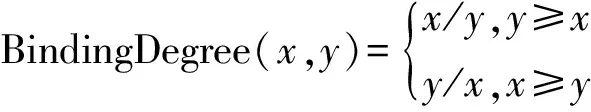
(4)
在这里,BindingDegree(x,y) 用于衡量多词单元中词语的结合度并确定多词单元的边界。以下将BindingDegree(x,y)称为结合度,它计算出的值简称BD值。
2.2 约束多词单元
CMWEPM模型是基于词对齐的,利用关联度和结合度确定汉语多词单元边界后,通过词对齐优化结果选择汉语多词单元的译文。利用 GIZA++获得词对齐矩阵是等价对抽取的起点。
Koehn[6]提出了一个基于词对齐的短语翻译模型。下面先给出短语定义。设:f=f1…fm,e=e1…en分别为源语言和目标语言句子,α是两个句子上的对齐,则短语互译对
(1) ∀j∃i′(i′,j′)∈α,i′∉{i1,…,im},j∈{j1,…,jn};
(2) ∀i∃j′(i′,j′)∈α,i∈{i1,…,im},j′∉{j1,…,jn};
(3) ∃k,l(ik,jl)∈α,1≤k≤m,1≤l≤n。
Koehn抽取方法是严格按照词对齐进行的,因此本文称此类多词单元为严格多词单元。它要求完全相容,因此抗噪声能力不强。本文从汉藏多词单元等价对抽取实际问题出发,采用基于词汇结合度约束的抽取策略来减小错误词对齐结果造成的精度损失。放宽一致性条件,使得等价对中的词对齐到多词单元内的某个词的同时可以对齐到该多词单元之外,可以避免抽取到不完整的多词单元等价对。只要这个词能够满足式(5)的对齐约束条件,避免破坏等价对的完整性。
(5)
满足式(5)的词串为约束多词单元,其中,sim(ei,fj)是词汇结合度度量函数,θ是阈值。
3 汉藏多词单元等价对识别流程
CMWEPM模型构建多词单元词典中汉语多词单元自动获取是关键。假设句子为W1,W2…Wi,Wi+1…Wn, 将W1和W2的Collocation值记为x,若通过了阈值过滤,则将这两个词作为一个多词单元;计算W2和W3的Collocation值,记为y,若BindingDegree(x,y) 值通过了阈值过滤,则将这三个词作为一个多词单元,依此类推。
3.1 多词单元分类与阈值选取
对于高频多词单元和低频多词单元设定同一个阈值并不合理,本文应用四点法则弱化主观影响且不失多词单元的全面性,从而降低阈值本身所带来的对精确度的影响,提高准确度和效率。为了使计算更有针对性,本文将多词单元分为以下四类:(1)短高频多词单元; (2)短低频多词单元;(3)长高频多词单元; (4)长低频多词单元 。表1给出多词单元类型趋向与关联度和结合度对应情况。

表1 多词单元分类表
设定四种阈值与多词单元类型对应,保证阈值的选取对多词单元类型具有更好的分辨力。阈值选取以关联度和提取出的多词单元的长度作为参考因素,基本上权衡这两方面就可以。约定横坐标表示Collocation值,纵坐标表示BindingDegree值;本文实验所使用的短高频、短低频、长高频和长低频对应的一组参考阈值用坐标形式表示如下:A(0.38,0.6),B(0.1,0.6),C(0.38,0.3),D(0.1,0.3);其中Collocation值和BindingDegree值的高值和低值的阈值分别设定为thresh_col1=0.38、thresh_col2=0.1、thresh_sim1=0.3、thresh_sim2=0.6。需要说明的是,这些值都无须非常精确,只要结果大体符合以上分类的标准就可以,在后面的处理中还会有进一步的调整。
3.2 识别多词单元等价对实例
本节举例说明提取多词单元等价对的流程。首先,预处理双语语料;得到的汉藏句对如图1,分词后的汉语和藏文句子分别用CS和TS表示,句子中的词用空格隔开。
第二步,计算汉语多词单元。图2给出CS中相邻词的关联度计算结果。

图1 实例词对齐结果

图2 例句关联度直方图
在图2中,“提高”和“农业”的Collocation值0.043,小于阈值thresh_col1=0.38;因此“提高”和“农业”不是多词单元。“农业”与“机械化”的Collocation值0.337,大于阈值thresh_col2=0.1;“机械化”与“水平”的Collocation值0.264,这两个关联度的BD(0.264/0.337)=0.783,大于阈值thresh_sim1=0.3;“水平”与“。”的Collocation值0.076,BD(0.076/0.264)=0.288;小于thresh_sim1=0.3;因此“农业”、“机械化”和“水平”是一个长低频多词单元。依此类推,“适用”和“农机具”是个短高频多词单元。实验以三个词为长短多词单元的界限,根据多词单元分类及阈值设定可以得到用“//”号分割的汉语句子CS的多词单元划分结果如下。
CS多词单元划分:推广 //先进 //适用 农机具 //, //提高 //农业 机械化 水平//。 //
第三步,应用Giza++得到词对齐结果。图1表示CS与TS词对齐信息:1-5 2-4 3-1 4-3 6-12 7-9 8-9 9-11 10-14。

4 实验
文献[4]中提出的SIBPTM模型和本文提出的CMWEPM模型抽取汉藏多词单元等价对的流程均先抽取汉语有效语块,二者的不同之处在于确定汉语语块边界及获取藏语译文过程。本文将比较两个模型抽取效果,证明本文的CMWEPM模型的有效性。
在实验中,SIBPTM和CMWEPM两个模型从训练语料抽取多词单元等价对之后,采用人工抽样检查的方法判断互译对正确与否,实验准确率(P)定义为:
(6)
召回率(R)定义为:
(7)
通常将P和R两个指标综合为二者的调和平均值F-Score来反映一个系统的整体性能。F-Score可以有不同的定义公式,通常采用:F=2PR/(P+R) ;本文用此定义。
4.1 语料信息
表2给出实验所采用的双语语料库,其内容主要是汉藏法律法规和公文报告等特定领域语料。语料1是训练语料,包括7万余对已经对齐的双语句子,长句占多数。为了提高词对齐准确度,将双语词典追加在语料1上,获取22万余句对的语料2,用于词对齐。目前只选择378句对的语料3用于人工测试。
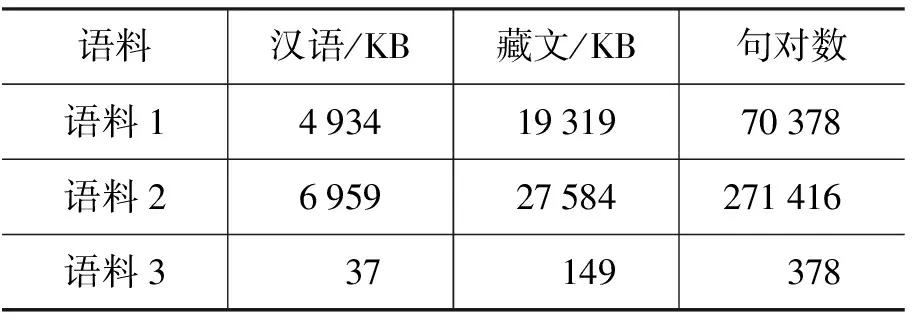
表2 语料信息
4.2 汉语多词单元规模
SIBPTM模型抽取汉藏多词单元等价对过程中用N-gram统计算法计算出汉语语料中所有2-gram到6-gram多词单元作为候选汉语连续串。再根据文献[7]中算法,通过子串归并删除同一频度的子串。
本文尝试CMWEPM模型应用关联度和结合度计算汉语多词单元。两种模型抽取的多词单元统计结果见表3。
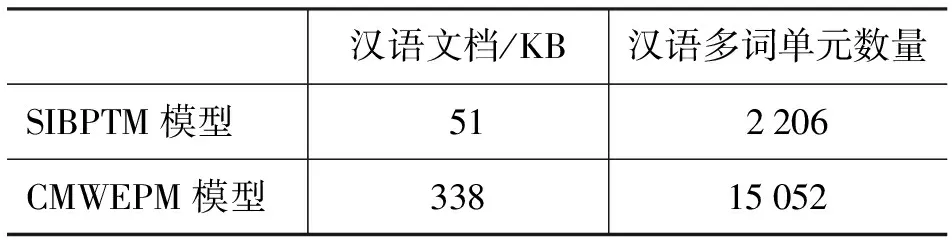
表3 汉语多词单元信息
分析语料结果表明,其中数据稀疏问题十分突出。SIBPTM模型用n-gram统计算法抽取汉语多词单元时候,为了避免太多的干扰信息,过滤掉频次少于8的所有多词单元,进一步过滤掉左右边界处包含的停用词和标点符号后保留包含两个或以上词的多词单元,因此SIBPTM模型抽取的汉语多词单元数量很少,这也是下一步实验中造成此模型召回率低的主要原因。
4.3 多词单元抽取
SIBPTM模型中TIA算法在不依赖于额外资源的前提下,对句对齐双语语料库中包含待翻译汉语多词单元Q的句对求交集,通过后处理得到Q的译文。
本文尝试CMWEPM模型应用关联度和结合度先获取源语的多词单元,再通过Giza++优化词对齐结果采用Koehn方法获取严格多词单元互译对或应用Phi平方系数方法计算词汇结合度约束条件的约束多词单元等价对。表4给出SIBPTM模型抽取多词单元互译对结果、CMWEPM模型获取的严格多词单元和约束多词单元等价对抽取结果。

表4 多词单元抽取结果
表4结果表明,CMWEPM模型的召回率比SIBPTM模型有明显提高。SIBPTM模型算法用双语词典作为辅助资源进行机械匹配来筛选汉藏多词单元,由于自然语言翻译的灵活性和双语词典的有限性,词典译项对真实文本的覆盖率很低,导致召回率过低。而CMWEPM模型严格多词单元抽取方法算法简单,容易实现,因为使用了成熟的开源词对齐工具进行汉藏词对齐,它抽取的多词单元准确率较高。CMWEPM模型不再依赖汉藏词典,避免了因词典覆盖率低带来的问题,能够提高召回率。
但同时,严格多词单元由于限定条件苛刻会丢失一些信息,影响召回率;与严格条件的多词单元结果相比,约束条件的召回率有所提高,这对于处理汉藏语料库有着十分重要的意义。
5 结束语
为了提高汉藏多词单元等价对召回率,本文提出了CMWEPM模型。该模型应用关联度和结合度抽取源语言的多词单元,并定义严格条件和约束条件,抽取出符合条件的多词单元等价对。实验结果表明,新模型在未经分析语言特征的前提下,取得了令人满意的正确率。与SIBPTM模型相比,新模型明显提高了召回率。这对于处理汉藏语料库有着十分重要的意义。
由于藏文形态变化丰富,并且汉语、藏语两种语言差异很大,下一步的工作将考虑加入形态学信息来优化词对齐的准确率,抽取出更为合理的汉藏多词单元等价对。为已经获取的等价对计算翻译概率,用于翻译解码也是论文下一步工作之一。
汉藏多词单元对抽取研究,理论上需要极大语料支持,实验所用资源规模有限,汉藏对齐语料正在建设中,因此进一步工作中还需在更大资源上验证本文方法的有效性。
[1] Nagao M. A framework of a mechanical translation between Japanese and English by analogy principle[C]// Proceedings of the international NATO symposium on Artificial and human intelligence, New York,USA, PublisherElsevier North-Holland, 1984:173-180.
[2] Jörg Tiedemann. Automatical Lexicon Extraction from Aligned Bilingual Corpora [D]. Magdeburg University, Department of Computer Science, 1997.
[3] 常宝宝.基于汉英双语语料库的翻译等价单位自动获取研究[J].术语标准化与信息技术,2002,(2):24-29.
[4] 诺明花,张立强,刘汇丹,等. 汉藏短语抽取 [J]. 中文信息学报,2011,25(2):105-110.
[5] Ying Zhang, Ralf Brown, Robert Frederking, et al. Pre-processing of Bilingual Corpora for Mandarin-English EBMT[C]//Proceedings of the MT Summit 8.Santinago de Compostela,Spain, 2001.
[6] Koehn P,Och F J,Marcu D.Statistical phrase based translation[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology. Morristown NJ: Association for Computational Linguistics, 2003: 48-54.
[7] Xueqiang Lv, Le Zhang, Junfeng Hu. Statistical Substring Reduction in Linear Time[C]//Proceedings of IJCNLP-2004, Springer, 2004: 320-327.
猜你喜欢
湖南工业职业技术学院学报(2022年3期)2022-12-06
新高考·高三数学(2022年3期)2022-04-28
通信技术(2021年12期)2022-01-25
学习周报·教与学(2019年4期)2019-10-21
原生态民族文化学刊(2017年2期)2018-06-01
中文信息(2017年12期)2018-01-27
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
外语教学理论与实践(2014年2期)2014-06-21
郑州大学学报(理学版)(2014年2期)2014-03-01
