
事件信息结构分析
2012-06-29 03:54杨尔弘曾青青李婷婷
中文信息学报 2012年3期
杨尔弘, 曾青青, 李婷婷
(1. 北京语言大学 国家语言资源监测与研究中心 平面媒体语言分中心,北京 100083;2. 首都体育学院 国际教育学院,北京 100191)
1 引言
随着互联网的广泛应用,准确地从海量、无序、杂乱、无结构的网页文本中提取用户感兴趣的事件信息是信息抽取领域的重要研究课题[1]。在美国,DARPA,NIST组织的MUC、ACE[2-4]等评测任务中,对事件信息抽取给出了明确的定义。当前的事件抽取研究,大多以这样的定义为基础:以若干特定的事件类型为目标,研究事件模板的获取以及事件的论元识别[5-10]。事件模板主要依靠经验给出种子模板或聚类的方式获取[5-7,10-12];论元角色多以计算事件模板论元的语义约束与词语的相关属性之间的对应关系进行填充[6,12]。
目前,从整个语篇的角度探索事件信息的分布与事件抽取技术的研究还较少。文献[7]尝试了从语篇中过滤非事件句子,文献[13]探索了语篇中事件与事件的关系,研究事件之间的推理。
本文针对突发事件新闻报道,从可操作的角度,将“事件”定义简单化——与突发事件相关的动作、状态改变都定义为一个事件,事件以事件词为标示,事件词可以是动词、名词化(Nominalizations)、形容词等。在此基础上,研究事件信息在报道文本中的分布,从而确定文本中事件信息的组织方式,寻找到篇章结构和事件信息结构之间存在的联系,为事件信息的形式化描述和准确定位服务。
2 突发事件文本的篇章结构和事件信息结构
2.1 事件信息在篇章结构中的分布调查
戴伊克(Van Dijk)在《作为话语的新闻》[16]一书中概括了新闻文本的假设性话语结构图式,如图1所示。
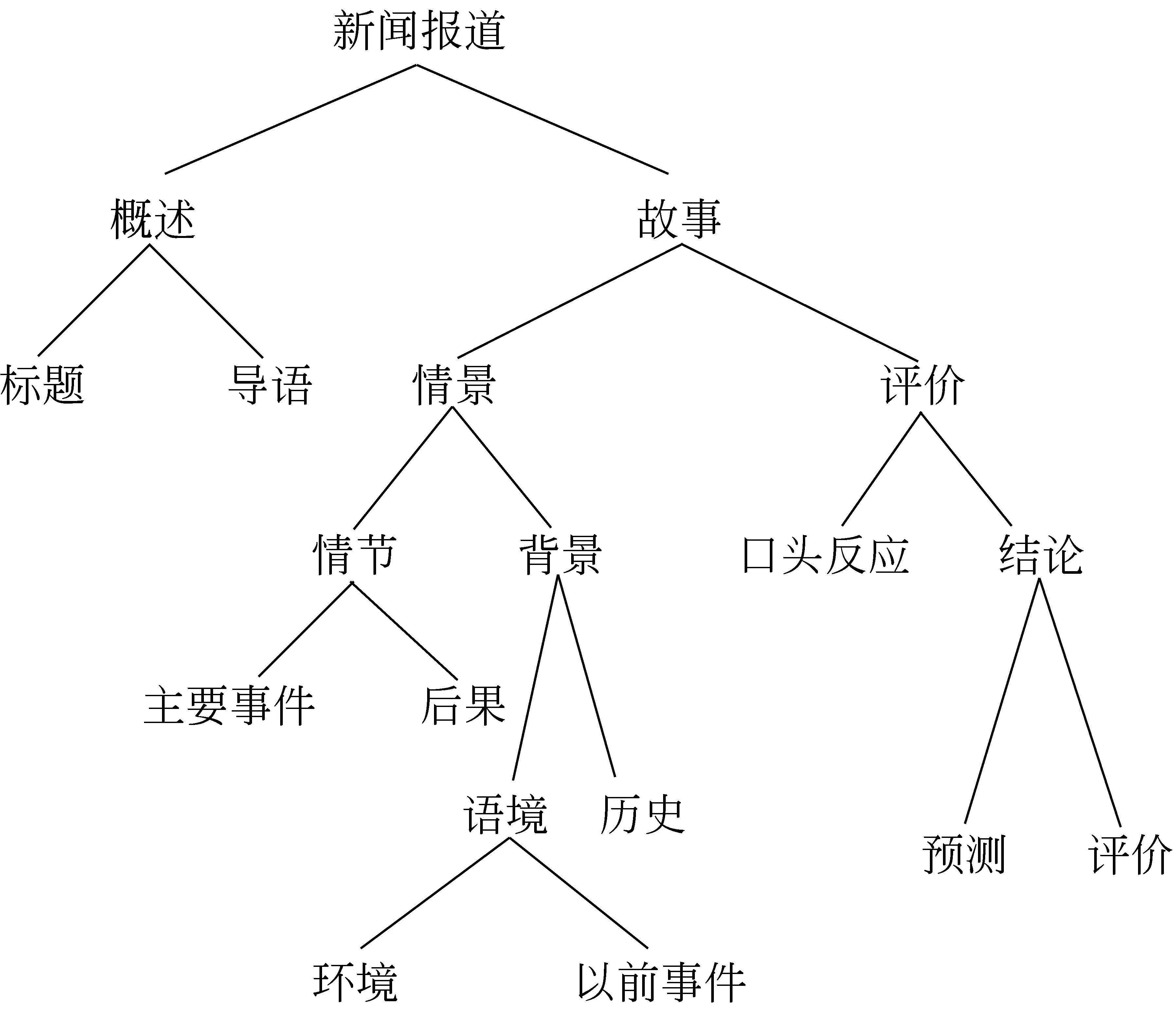
图1 假设性新闻图式结构
以戴伊克阐释的假设性新闻图式结构为基础,了解文本描述的事件信息,需要阅读“主要事件”和“后果”组成的“情节”部分,可以忽略图式中的“背景”及“评价”信息。换言之,可以假定“情节”部分是突发事件的主体,也是事件信息抽取的主要部分。本文选取了关于火灾、地震、食物中毒等方面的新闻报道文本各200篇以及关于恐怖袭击的新闻报道80篇,以此作为语料,调查报道的篇章结构以及报道的主体内容——事件信息在文本中的分布,以期发现新闻的图式结构和事件信息结构之间的关系规律。
事件词是文本中体现事件信息的重要元素,以事件词作为事件信息的核心表达,调查事件信息在篇章中的分布,具有表达简洁、目标明确、可操作性强的特点。人工标注文本中出现的事件词,得到每类文本的事件词集合*地震类文本事件词个数为132,火灾类文本事件词个数为164,食物中毒类文本事件词个数为202,恐怖袭击类类文本事件词个数为115。,事件信息的分布可以通过集合中事件词的分布情况获得。
标注过程中发现:“情节”部分基本上囊括了事件的信息,是事件信息抽取的重要部分;但此外,“情节”还包括了一些描述事件特别细节的句子和一些事件词缺省的句子。由此,在戴伊克新闻图式结构的基础上,进一步对突发事件新闻报道文本定义“主线信息链”、“副线信息链”,将报道文本的篇章结构与事件信息对应。
(1) 主线信息链。主线信息链是指报道“情节”部分中除去细节信息所在句子和事件词缺省的事件信息所在句子之后,由事件词关联起来的信息链。此信息链是以事件词为显性标记,将报道中的突发事件、核心事件及与该核心事件相关的各类事件关联在一起,是文本的中心内容部分,是篇章结构中的主体部分,是读者进行篇章阅读和理解的最重要的部分。
(2) 副线信息链。副线信息链是由“评价”部分、“背景”部分以及“情节”部分中的细节信息和事件词缺省的事件信息所在的句子构成。从信息抽取的角度来说,副线信息链的信息不作为信息抽取的关注对象。副线信息链的作用在于使读者加深对新闻报道的认识和理解,深化新闻的主题。
突发事件新闻报道中的主副线信息链与新闻图式结构成分的对应关系如图2所示。
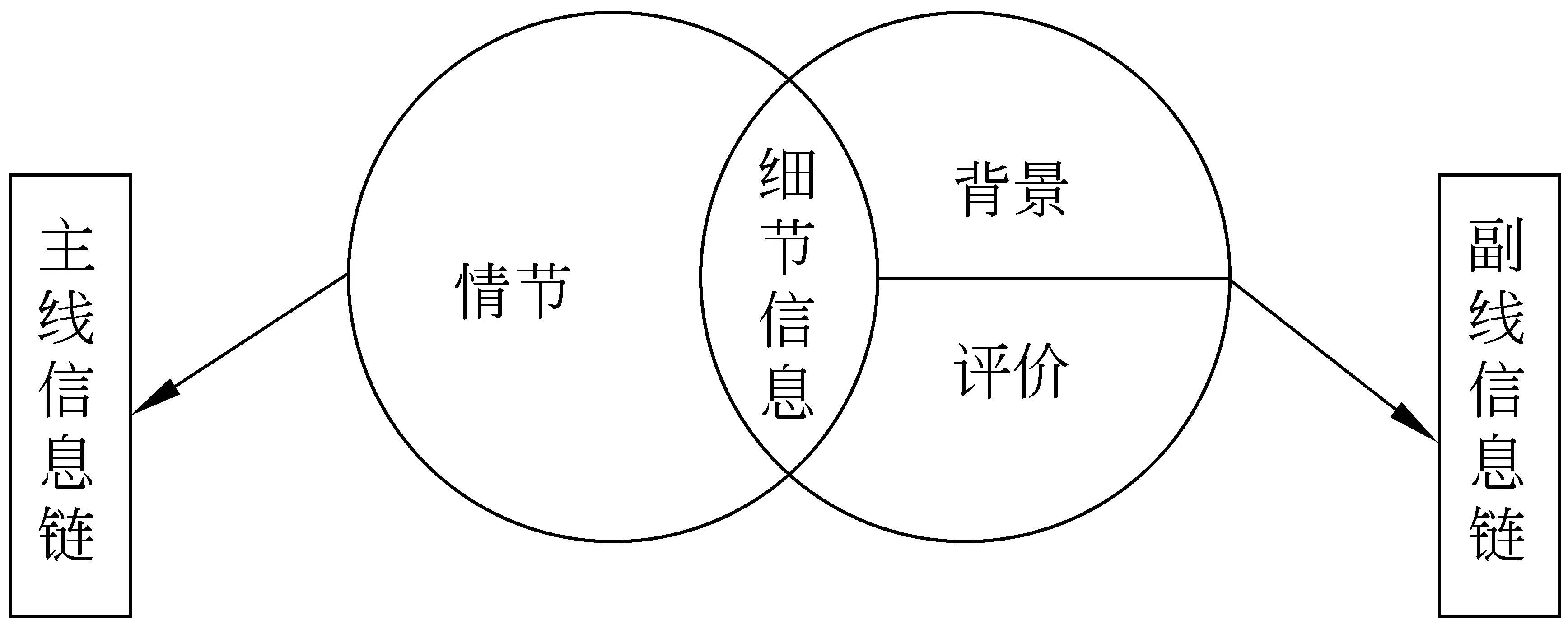
图2 主副线信息链和新闻图式结构成分的对应关系
由此,在戴伊克的话语宏观结构理论下,突发事件新闻报道的篇章结构进一步由主线信息链和副线信息链两个下位的结构组成。通过考察发现,突发事件文本中构成主线信息链的句子和副线信息链的句子没有明确的界限,它们总是交织在一起。如图3所示。
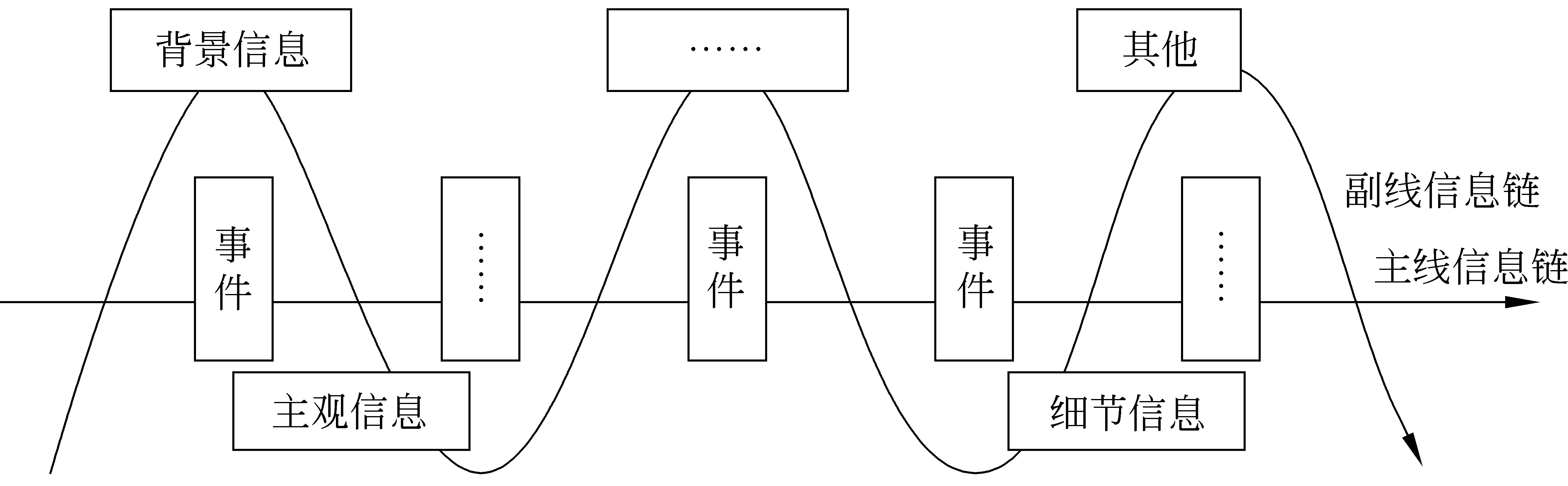
图3 突发事件文本信息链
2.2 事件信息结构
前文定义的主线信息链即为突发事件文本的信息结构,主线信息链上关联了事件词和事件论元,这些是事件信息抽取的对象。通过对四类突发事件,共计680篇新闻报道文本的主线信息链进行意义分析,同时对以事件词为标志的事件和事件之间的关系进行分析,可以发现主线信息链代表的事件信息结构通常是由四个部分组成的事件描述,即核心事件、前核心事件、次生事件以及后次生事件。在此信息结构中,核心事件是主体,其余三部分事件信息都是围绕核心事件而产生、存在的。组成事件信息的四个部分对应的事件词有明显的差别。由此,可以事件词为驱动,识别、区分事件的信息结构。以火灾类突发事件为例,以事件词集合为事件的基本表示,对应的事件信息链示例如下:
(1) 核心事件信息链。核心事件是事件信息结构中的重要构成成分,它是突发事件文本报道的焦点事件。标志核心事件发生的事件词即为核心事件词。包含核心事件词的事件小句是核心事件信息链上的基本元素。例如,火灾文本的核心事件词集合如下:
Core Event Words of Fire=【火灾、火灾事故、火势、火海、大火、火、余火、火苗、明火、残火、火情、火场、火魔、火光、火警、起火点、着火点、火源、过火面积、着火、着起火来、起火、失火、燃烧、冒烟、滚滚冒出、烟雾、黑烟、焦烟、烟柱、浓烟、浓烟滚滚、浓烟弥漫、浓烟笼罩、浓烟刺鼻、火光冲天、火光四射、火猛烟大】
(2) 前核心事件信息链。前核心事件指先于核心事件而发生的事件,通常前核心事件是造成核心事件发生的原因。前核心事件词在文中标示前核心事件的发生。包含前核心事件词的事件小句构成前核心事件信息链。例如,火灾类文本的前核心事件词集合如下:
Former-Core Event Words of Fire =【爆炸、点燃、短路、使用不当、操作不当、纵火、闪电、雷击、释放烟花、燃放烟花炮竹、取暖、泄露、拆除、熏制、焊接、超负荷、故障、争执】
(3)次生事件信息链。次生事件是由核心事件直接造成的不可抗拒的事件,是事故造成的直接影响。次生事件词在文本中标示所发生的次生事件。包含次生事件词的事件小句构成次生事件信息链。例如,火灾文本的次生事件词集合如下:
Secondary Event Words of Fire =【伤亡、死亡、死、丧生、失踪、遇难、伤亡、伤、受伤、重伤、轻伤、烧伤、烧烫伤、烫伤、伤势、轻微伤、灼伤、熏晕、熏黑、熏晕、熏得萎靡、熏伤、熏死、昏迷不醒、吓坏、损失、被困、昏迷、蔓延、损害、身体不适、砸晕、骨折、撤离、撤退、逃出、逃生、逃散、逃离、踩踏、呼救、自救、跳窗、碎裂、损毁、破损、烧毁、烧焦、烧穿、被烧、被炸爆、炸裂、烧尽、爆炸、坍塌、砸、影响】
(4) 后次生事件信息链。后次生事件是指由核心事件造成的间接影响,主要是描述人在面对突发性的灾难时采取的各种应对措施。后次生事件词表示文本中描述的后次生事件。包含后次生事件词的事件小句组成后次生事件信息链。例如,火灾文本的后次生事件词集合如下:
Regeneration Events Words of Fire=【启动(应急预案)、报警、警戒、封闭、关闭、调集、安置、增援、出动、赶到、赶赴、奔赴、处理、指挥、部署、清理、撤离、搬出、转移、扑灭、救火、灭火、扑救、救援、控制、疏散、善后、喷水、接水、泼水、抢险、抢救、急救、救出、搜救、救治、治疗、观察、就医、检查、核查、检测、检查、调查、隔离、呼吁、逮捕、运抵、宣判、判、通知】
3 事件词扩充和副线信息链过滤
3.1 事件词扩充
在第二节中,我们通过人工标注,获得了每一类突发事件对应的事件词集合,进一步将事件词区分,可以使事件词集合中的不同元素,表达事件的信息结构,也就是可以利用事件词区分前核心、核心、次生和后次生事件信息链,不同的事件信息链对应不同的事件词。
如果每一类突发事件的事件词是一个相对稳定的词语集合,这对事件信息结构的发现与识别将有很大帮助。为验证从标注文本中标注得到的事件词集合对新的文本事件信息表示的有效性,本文做了一个简单的实验,将标注得到的事件词作为种子事件词,对新的测试语料文本进行事件词覆盖测试。以地震文本为例,重新选择50篇新的文本。覆盖结果表明从200篇地震文本中获得的种子事件词不能完全覆盖新文本中事件信息,即新文本中出现了新的事件词。这说明所获得的事件词对同类事件新闻报道文本信息表达的有效性不够。
如何扩大事件词集合?解决这个问题的方法可以是:增加标注量,直到事件词达到一个比较稳定的状态,即随着新文本的加入,不再出现新的事件词。此方法的问题是:究竟多大的标注量就够了?如何选择需进行标注的文本?这两个问题解决起来都比较困难。扩大事件词集合的另一种方法是利用已有的词典、知识资源。在此我们利用常识知识库《知网》(HowNet)[15]对已有的种子事件词进行扩充,从《知网》中获得种子词的相关词,再利用词性等限制筛选相关词,得到扩充词集合。以地震文本为例,核心事件词经扩充后由原来的17个扩展为21个*地震核心事件词扩充个数较少。在人工标注地震类文本的时候,表示地震事件的事件词大多数已经标出了。;次生事件词由原来的64个扩展为1 146个;后次生事件词由原来的51个扩展为548个*地震类突发事件没有明显的前核心事件。。
在对四类突发事件文本的事件词进行扩充时,扩充原则一样,但是四类文本的前核心、次生、后次生事件词之间有很多交集词语,因此对组成事件信息结构的不同部分,事件词的扩充可以采用不同的策略获得:突发事件的核心事件词需要根据突发事件类型各自进行扩充,即分别对地震、火灾、食物中毒、恐怖袭击文本的核心种子事件词进行扩充;对于突发事件的前核心、次生和后次生事件词,可以不考虑突发事件类型,按各个部分扩充。
3.2 副线信息链过滤
人工标注过程中,已经发现副线信息链中很多句子包含事件词,诸如背景信息、评价信息等。因此从事件信息提取的角度来看,以事件词作为驱动来识别、提取事件信息,文本中的副线信息链将会产生较大噪音。为此,根据篇章结构,对新闻报道文本中的副线信息进行过滤,可以消除文本中影响事件抽取的干扰信息,并提高事件词对事件信息表达的区分度。
为过滤副线信息链,必须在文本中找到区分主线信息链和副线信息链的特征。一般来说,细节信息属于客观信息的一部分,但是因为其过于琐碎,往往句子中不会包含有标注和扩充得到的事件词,所以对于细节信息可以暂不考虑。例如,以下两个例句都属于火灾事件的细节信息,均未包含事件词。
(1) 罗周忠因外出不在家,逃过一劫,罗还有一个女儿在外地读书。
(2) 这家店的店主说:“我们的所有财物都被烧毁了,彻底被毁了。我们失去了曾拥有的一切,现在可算是彻底完了。要知道,我们把所有的钱都投资到这个店上了。”
另外,有一些背景信息也不包含事件词,不会对事件抽取造成干扰,例如:
(1) 呼图壁县位于新疆中北部,距离新疆首府乌鲁木齐约六十公里。
(2) 巴达赫尚省是阿富汗最偏远的地区,交通不便、通信落后、人口密度很低。
因此副线信息链中过滤的重点是包含事件词的评价信息和背景信息。对这部分内容的过滤方法,本文主要采取词语的显性标记作为特征。例如,在标注过程中发现,地震文本的背景信息有比较明显的词语特征。通过对200篇地震文本考察,发现很多背景信息表达方式如下:
(1) 日本地震频发,每年发生有感地震1 000多次,是世界上地震最频繁的国家之一。
(2) 墨西哥处于环太平洋地震带东部,属地震多发国家。
(3) 地处太平洋板块和加勒比板块交界处的尼加拉瓜境内地壳运动频繁,历史上曾多次发生地震。
(4) 去年8月,秘鲁发生里氏8级地震,至少造成500人死亡,4万座房屋被毁。
在这些包含知识、历史、环境以及以前事件在内的背景信息中,诸如“(频繁)|(频发)|(多发国家)|(多发区)|(多发带)|(多发地带)|(强地震带)|(最易发生)|(经常发生)|(活跃)|(曾发生)|(曾多次发生)|(曾遭遇)|(发生过)|(上次发生)|(上一次发生)|(去年)……”这样的词语是副线信息的显性标记。将从文本中提出的明显标示背景信息的词语作为显性标记,可以识别副线信息。在选取的200篇地震文本中,人工标记有59个句子是背景信息,用程序根据显性标记在文本中自动识别背景信息,得到45个句子。由此,提取表达副线信息的显性词语,可以作为过滤副线信息的特征。
副线信息链中的不同内容对应的词语特征是不一样的。以下示例了评价信息部分对应的特征词语。
(1) 分析人士认为,不管调查结果如何,巴基斯坦的国际形象因这次袭击事件而再次遭受严重影响,使外界对巴基斯坦的安全形势感到进一步担忧。
(2) 警方初步判断是泰南武装分子制造了这起恶性恐怖袭击事件。
(3) 估计在未来24小时内,景泰原震区发生更大级别地震的可能性不大。
(4) 伊朗驻联合国官员的一系列可疑行为已引发了纽约警局官员有关伊朗特工可能主使发动恐怖袭击的担心。
3.3 实验
为验证事件词扩充和副线信息链过滤的效果,设计如下实验:
以已经标注的200篇地震文本为基础,提取事件词,标记副线信息链。随机选择50篇新的地震类事件报道文本进行测试。分别测试事件词扩充前后和副线信息过滤前后,事件词对文本中事件信息结构的识别与区分结果。测试的指标定义如下:
表1给出了未进行事件词扩充和副线信息过滤时的情况。封闭测试的测试对象只包含200篇人工标注过的突发事件报道文本,开放测试的测试对象是新选择的50篇突发事件报道文本。
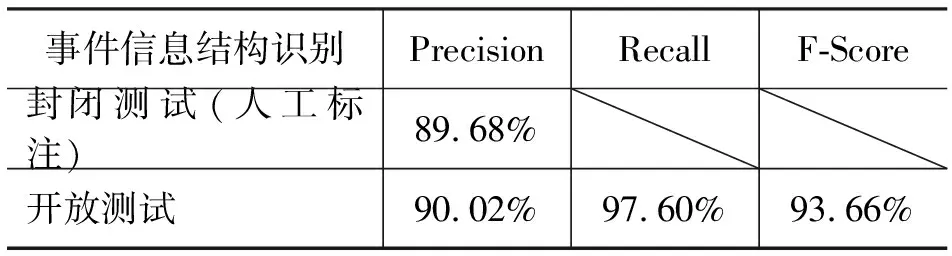
表1 地震类文本事件词扩充前封闭及开放测试实验(未过滤副线信息)
封闭测试的准确率较低是由于副线信息链中的噪声数据引起的。随着文本量的增加,副线信息链的数量增加,噪声会增大,这也是开放测试的准确率比封闭测试的要高的原因。
表2给出了扩充事件词并过滤副线信息链之后,对事件信息结构的识别结果。实验的步骤是:(1)利用显性标记规则过滤副线信息链; (2)利用扩充后的所有事件词对文本中的事件信息结构进行识别。
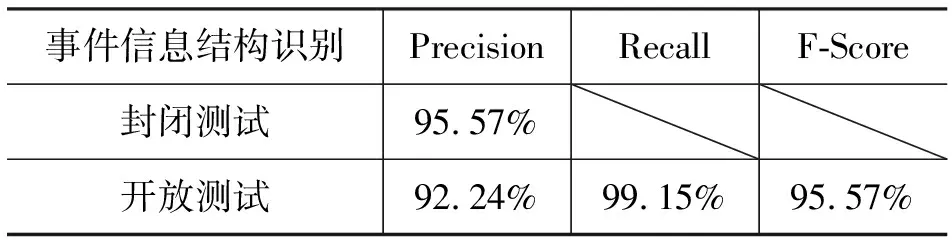
表2 地震类文本事件词扩充后封闭及开放测试实验(且过滤副线信息)
表2的实验数据表明,通过过滤副线信息链和事件词扩充两个步骤,一方面减少了错误识别结果,提高了识别的准确率;另一方面,因为扩充后的事件词集扩大,使得更多的事件词能够被机器识别出来,召回率也得到了提高。
4 结语
本文结合戴伊克新闻文本的话语图式,通过考察事件词在篇章中的分布情况,提出了突发事件新闻报道语篇可以进一步描述为主线信息链和副线信息链结构。主线信息链中包括了突发事件新闻报道的主体内容——事件信息,该信息在主线信息链中以事件信息的层级结构形式体现出来,即事件信息由前核心事件链、核心事件链、次生事件链和后次生事件链构成,事件信息结构可以简单地以事件词的分布来区分,这为事件信息提取提供了帮助。副线信息链则是由“评价”部分、“背景”部分以及“情节”部分中的细节信息和事件词缺省的事件信息所在的句子等构成,不作为事件信息抽取时考虑的内容。在此调查的基础上,实验了利用《知网》(HowNet)扩充事件词、利用显式词语规则过滤副线信息链,从而尽可能准确地识别、区分事件信息结构。目前,本文的研究只考察了地震、火灾、食物中毒、恐怖袭击这四类突发事件新闻报道文本,实验结果表明方法是有效的。
核心事件词需要根据突发事件的类别分别获取,且相对稳定。事件信息结构中其他事件信息链对应的事件词有些具有共性,可以根据性质获取,并被不同的突发事件共享。本文的研究只是从文本结构的角度,初步探索了以事件词为区分特征的事件信息结构识别。当新闻报道的事件类型不断增加时,还需要分类分析文本的特点,以获得其相应的事件信息结构。
[1] Ralph Grishman. Information Extraction: Techniques and Challenges [M]. Information Extraction, ed. Maria Teresa Pazienza, Spring Notes in Artificial Intelligences, Spring-Vealag.1997.
[2] ACE. ACE Chinese Annotation Guidelines for Entities (Version 5.5) [EB/OL].http://www.ldc.upenn.edu/Projects/ACE/docs/Chinese-Entities-Guidelines_v5.5.pdf. 2005a.
[3] ACE Chinese Annotation Guidelines for Relations (Version 5.5.1) [EB/OL]. http://www.ldc.upenn.edu/Projects/ACE/docs/Chinese-Relations-Guidelines_v5.5.1.pdf.2005b.
[4] ACE Chinese Annotation Guidelines for Events [EB/OL].http://www.ldc.upenn.edu/Projects/ACE/docs/Chinese-Events-Guidelines_v5.5.1.pdf. 2005c.
[5] 姜吉发.一种事件信息抽取模式获取方法[J].计算机工程,2005, 31(15): 96-98.
[6] 赵妍妍,秦兵,车万翔,等.中文事件抽取技术研究[J].中文信息学报,2008,22(1): 3-8.
[7] 许红磊,陈锦秀,等.自动识别事件类别的中文事件抽取技术研究[J].心智与计算,2010,4(1): 34-44.
[8] 吴平博,陈群秀,马亮.基于事件框架的事件相关文档的智能检索研究[J].中文信息学报,2003, 17(6): 25-30.
[9] 梁晗,陈群秀,吴平博.基于事件框架的信息抽取系统[J].中文信息学报,2006, 20(2): 40-46.
[10] 杨尔弘.突发事件信息提取研究[D].北京语言大学,2005.
[11] 冯礼,李芳,盛焕烨.基于词对特征的事件新侧面探测[J].计算机工程,2009,35(3): 45-47.
[12] 冯礼.基于事件框架的突发事件信息抽取[D].上海交通大学,2008.
[13] 仲兆满,刘宗田,周文,等.事件关系表示模型[J].中文信息学报,2009,23(6): 56-60.
[14] Van Dijk(著),曾庆香(译).作为话语的新闻[M].华夏出版社,2003.
[15] 董振东,董强.《知网》(HowNet)[EB/OL].http://www.keenage.com.
猜你喜欢
军事文摘(2022年14期)2022-08-26
军事文摘(2022年14期)2022-08-26
军事文摘(2022年12期)2022-07-13
云南教育·小学教师(2022年4期)2022-05-17
艺术评论(2020年3期)2020-02-06
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
教书育人·教师新概念(2017年6期)2017-06-15
领导科学论坛(2016年10期)2016-06-05
文史春秋(2016年8期)2016-02-28
