
基于依存关系的旅游景点评论的特征—观点对抽取
2012-06-29 05:53王素格吴苏红
中文信息学报 2012年3期
王素格,吴苏红
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3. 山西大学 数学科学学院,山西 太原 030006 )
1 引言
随着人民生活水平的提高,旅游已成为人们生活的重要组成部分。许多游客利用论坛、博客和旅游点评网等空间发表有关旅游景点的评论。与此同时,对于游客,在出游之前,可以通过网上的评论了解其他游客对一些景点的看法,规划自己的旅游行程。而景点管理商可以通过景点评论了解游客对景点的意见和态度,以便提高服务质量。但是,人工逐篇阅读海量的评论,需要花费大量的时间和精力,阅读者可能会“迷失”其中,无法识别和利用其中有价值的观点信息。如何准确、高效地挖掘出游客感兴趣的观点信息,特征—观点对抽取是可以利用的关键技术之一。
特征—观点对是指特征及其观点词语之间的搭配,表现为二元对(特征,观点词语)。在2011年中文倾向性分析评测大纲中将领域观点词抽取、评价对象抽取以及评价搭配抽取确定为要素级评测任务[1]。Popescu[2]构建了一个无监督的信息抽取系统OPINE,该系统利用名词或名词短语与具有一定区分的符号间的点互信息值获取产品特征,然后利用手工构建的10条规则用于识别与特征相关的观点词。刘鸿宇等[3]对评价对象抽取和倾向性判断进行了研究。他们使用句法分析结果获取候选评价对象, 继而结合基于网络挖掘的PMI算法和名词剪枝算法对候选评价对象进行筛选,并使用无指导方法完成评价对象在情感句中的倾向性判断。文献[2-3]在采用点互信息计算相关性时,需要以大量的统计数据为代价。Li Zhuang等[4]采用WordNet、电影知识和标注训练数据等生成关键词列表,再利用规则获得特征和观点对,该方法依赖于大量的资源。Kobayashi等[5]利用文本挖掘技术,提出了一种半自动用于快速收集评价表达的方法。J.Wiebe[6]将观点词语的词性局限于形容词词性,而忽略了其他词性的观点词语。Somprasertsri等[7]在句法信息和语义信息的基础上,提出一种采用依存关系提取特征—观点对方法,并对文本进行观点综述。由于该文处理的文本为英文,系统中的部分技术无法直接向中文移植,另外,考虑到评价的对象与观点间的结构特征与领域相关。因此,本文针对旅游领域评论,利用依存关系,研究了评论文本中特征—观点对的抽取方法。首先利用依存关系制定用于获取含特征和观点的组块规则,在此基础上,进一步利用句子中词与词之间的依存关系,设计特征、特征—观点对的识别算法,实现旅游领域景点评论文本中具有观点倾向的特征—观点对的抽取。
2 特征与观点词语
(1) 特征:对于许多旅游评论,读者通常关注被评论的对象的观点倾向。但评论中的“评价对象”很难有一个统一的定义。文献[3]给出的定义:“评价对象是指某评论中所讨论的主题,具体表现为评论文本中观点词语所修饰的对象”。我们通过对大量相关的旅游景点评论文本的观察,发现评价的对象一般为名词或名词短语。例如,对某个景点或者景点的某些属性的评论。因此,本文将景点的评价对象看作特征,限定在名词、动名词、代词或名词组块范畴内抽取。例如,“景点”、“服务”、“交通”、“环境”等。
(2) 观点词语:观点词语又称为情感词或极性词,特指带有情感倾向性的词语。观点词语在情感文本中处于举足轻重的地位。Hatzivassiloglou等[8]从大语料库《华尔街日报》(Wall Street Journal)中发掘出大量的形容词性的观点词语。G. Somprasertsri等[7]把形容词和动词作为观点词语进行特征观点抽取,而J.Wiebe[6]将观点词语的词性局限于形容词词性。本文选用形容词、动词、形容词组块、动词组块、成语,作为候选观点词语。例如,“漂亮”、“不错”、“值得去”等。
3 含有特征和观点词语的组块获取3.1 组块的定义
为了获取含有特征和观点词语的组块,本文在李素建等[9]提出的组块定义基础上,结合词语间的依存结构,定义了三种类型的组块:名词组块、动词组块和形容词组块。其中,单独一个名词、动词或形容词均不在组块构成范围内,而并列结构中的词语与连接词一起包含在相应组块中。本文依存分析采用哈尔滨工业大学社会计算与信息检索研究中心[10]提供的“语言技术平台LTP”。
(1) 名词组块:是由中心词为名词的ATT、COO或QUN结构构成。ATT结构的中心名词的修饰词个数可以是一个或者多个。若“的”字结构作修饰成分时,将修饰的中心名词一起构成一个名词组块。对于数量结构,当数量词为数字时,不包含在名词组块中。
(2) 动词组块:是由中心词为动词的ADV、VOB、CMP、VV、MT或COO结构构成。中心动词的对象宾语和后置修饰成分补语也包含在动词组块中。趋向动词、助动词与其前面的中心动词构成动词组块。当“地”字结构作修饰成分时,将中心动词一起被划分为一个动词组块。
(3) 形容词组块:是由中心词为形容词的SBV、ADV、ATT、QUN、MT或COO结构构成。需要说明的是,名词组块或动词组块内部的形容词组块不用标记。“的”字结构与其所修饰的中心形容词构成一个形容词组块。形容词加助词也可以组成形容词组块。
3.2 组块获取规则
为了获得这三类组块,利用词与词之间的依存关系和相关词性,建立由词语构成组块的规则。
其规则形式为:如果词与词间满足依存关系与词性条件,则这些词可构成组块。
其规则的前件由表1 RuleSet1和表2 RuleSet2所示。除特殊说明外,表1均只限于相邻词之间的依存关系。parent.pos表示关系中支配词的词性,child.pos表示关系中从属词的词性。
利用RuleSet1中的条件得到的组块,有部分组块中同时含有特征和观点词语。例如,利用规则N1获取的组块“不错的历史博物馆”、“独特的建筑格局”等,该类组块的共同点都含有名词与其修饰成分,利用这类组块很容易获得特征—观点对。为此,在RuleSet1的基础上,对部分规则的条件做进一步限定,得到RuleSet2,如表2所示。

表1 RuleSet1

表2 RuleSet2
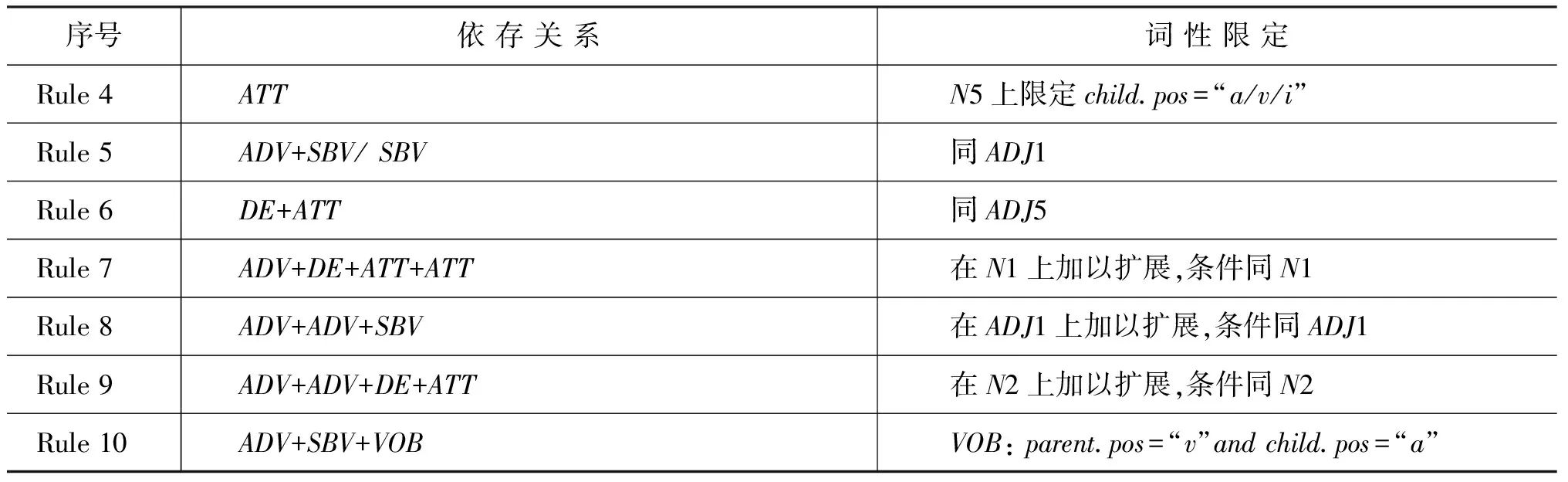
续表
3.3 基于规则的组块获取算法
利用RuleSet1和RuleSet2中的规则获取情感倾向组块的算法如下。
算法1:基于规则的组块获取
输入:经过依存句法分析后格式为XML的评论句集合SSet={s1,…,sn}, 组块集ChSet1=∅,ChSet2=∅;
输出:ChSet1和ChSet2;
Step1 利用RuleSet2中的规则Rulei(i=1,…,10),对SSet中的句子进行组块获取,得到候选组块集CanChSet2;对于这些组块:
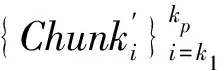
Step2ChSet2=ChSet2∪CanChSet2;
Step3 利用RuleSet1中的规则Rulej(j=1,…,22) 对SSet中的句子进行组块获取,得到组块集ChSet1;
Step4 算法结束。
4 特征—观点对抽取
由于ChSet2中的组块含有特征和观点词语,则利用这些组块可构成句子中的部分候选特征—观点对。RSSet={r1,…,rm}代表除去含有ChSet2中组块的句子。
4.1 候选特征识别
在算法1获得ChSet1的基础上,再利用词与词之间的依存关系,对抽取组块后的句子设计候选特征的识别算法。
算法2:识别句子中的候选特征
输入:RSSet={r1,…,rm},候选特征集CanFSet=∅ ,ChSet1,k=1;
输出:候选特征集CanFSet;
Step1 对于∀rk∈RSSet,如果存在SBV关系或者VOB关系且关系从属词W的词性为名词(“话”字除外)/代词(仅包括指示代词和第三人称代词)/动名词,则,如果从属词W在ChSet1的组块中,则CanFSet=CanFSet∪{ChunkW},否则CanFSet=CanFSet∪{W};//ChunkW为从属词W所在组块;
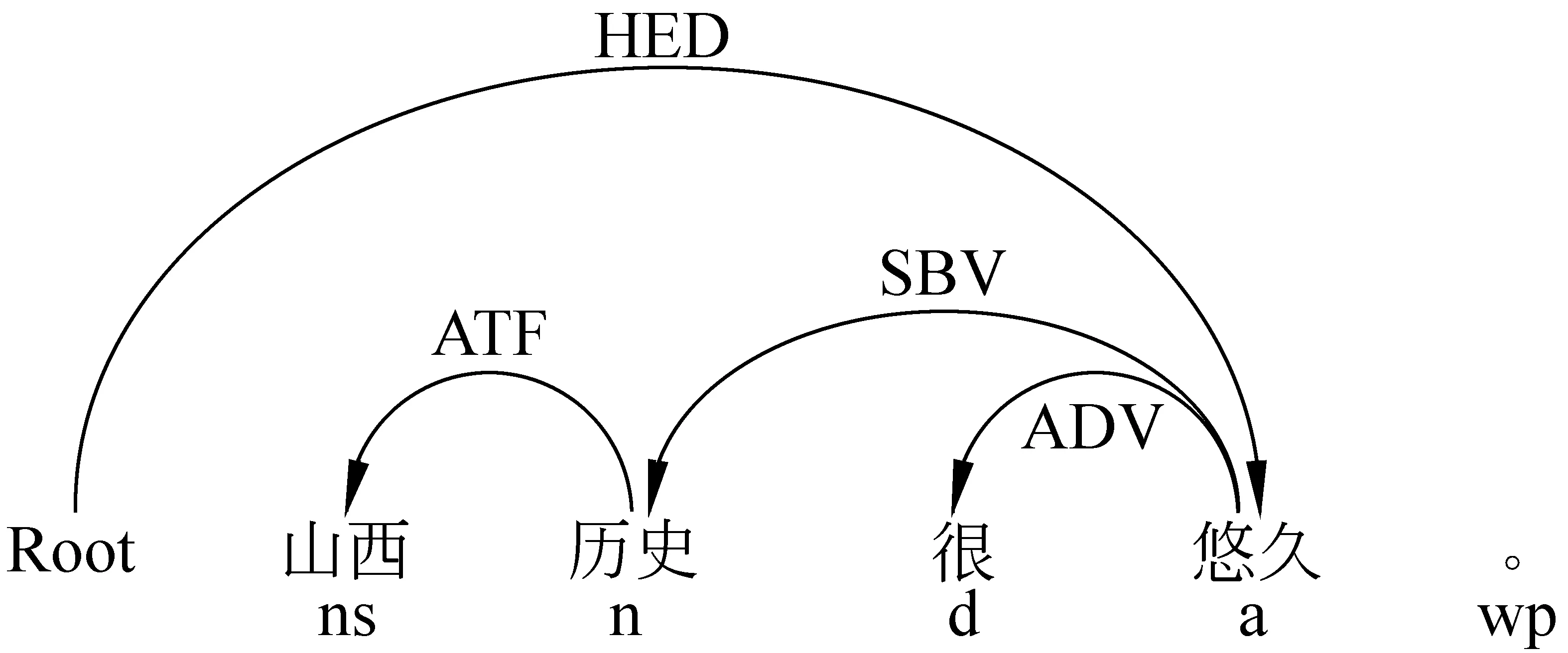
Step2 如果k Step4 算法结束。 候选特征—观点对的抽取分为两种。 (2) 利用算法1和算法2得到候选特征和候选观点词语,当句子中出现一个以上的特征和观点词语时,采用邻近法[11]确定候选观点词语与候选特征之间的相关性。最后从候选特征—观点对集中选出含有情感倾向的特征—观点对,得到特征—观点对集合。特征—观点对的情感倾向由观点词语在情感词表[12]、《知网》情感词语集的情感倾向、文献[13]以及与旅游评论相关的情感词决定。其算法如下: 算法3:特征—观点对的抽取 输出:特征—观点对集合FOSet; Step1 ∀sk∈SSet句子的候选特征Fki,若 Step3若候选观点词语w和候选特征集F存在于同一个span且|F|>1或者若w和F存在于不同的span,则w选择邻近的f∈F构成CFw=(f,w),CanFOSet=CanFOSet∪{CFw}; Step4 如果∀CanFO∈CanFOSet,若CanFO包含有情感倾向,则FOSet=FOSet∪{CanFO}; Step5 算法结束。 上述算法中句子片段为以逗号隔开的子句。 实验数据采用互联网上的论坛、博客、旅游点评网等有关山西省11个地级市的180个景点的相关评论作为语料库,共618篇评论,平均每篇评论大致包含2~3个句子。为了衡量特征—观点对的抽取结果,本文采用三个评价指标:精确率(查全率)、召回率(查准率)和F1值。 对于旅游景点评论,利用算法1得到组块集ChunkSet2,共915个组块;含三类组块集Chunk-Set1,共3 985个组块,其中名词组块1 742个,动词组块1 871个,形容词组块372个。例如,评论句“山西历史很悠久。”,依存句法分析结果如图1所示。该评论句中,利用RuleSet2中的ADV+SBV规则获取组块“历史很悠久”,由于该组块前面词出现ATT关系,则应把词“山西”也识别在组块中,得到新的组块“山西历史很悠久”。 图1 依存句法分析示例 利用算法2~3,分别对正面、反面、全部的旅游评论进行特征—观点对抽取,共抽取出1 758对。例如,对“悬空寺绝对是个一定要去的地方,精致奇特。”这句话进行特征—观点对抽取,依存句法分析结果如图2所示。 由Rule9抽取组块“一定要去的地方”,获得候选特征—观点对(地方,一定要去),利用算法2识别候选特征为“悬空寺”,最后利用算法3获取候选特征—观点对(悬空寺,精致奇特)、(悬空寺,绝对是),在此基础上,得到特征—观点对(地方,一定要去)、(悬空寺,精致奇特)。 图2 依存句法分析示例 采用以上三个评价指标对特征—观点对抽取实 验进行评价,其结果如表3所示。 表3 特征—观点对抽取实验结果 从表3中可以看出,本文的方法在精确率上达到预期的效果。其中,对正面评论进行特征—观点对判别时,精确率、召回率、F1值都优于反面评论。主要原因是反面评论含有的否定词、程度副词较多,致使反面评论的判别结果错误率高于正面评论,从而影响了实验结果。 另外,对识别错误的结果分析发现,(1)有80.07%的错误来自特征的识别错误,当利用规则抽取含特征和观点词语的组块时,句中的特征可能被抽掉,致使识别特征时出现错误;(2)有14.76%的错误来自于观点词语的识别错误,该错误主要是由组块获取错误引起的。 本文利用词对间的依存关系,构建了用于获取含情感倾向组块的规则以及候选特征识别算法,在此基础上,设计了具有情感倾向的特征—观点对的抽取算法。本文对山西旅游景点评论语料进行了特征—观点对的抽取,整体的F1值达到了87.10%,验证了本文方法的有效性。但仍存在一些特征—观点对无法正确识别,尤其对特征的识别,约有80.07%的错误由它的判别错误所引起。因此,在未来的工作中,应进一步开展特征识别方法的研究。 致谢:感谢哈尔滨工业大学社会计算与信息检索研究中心提供的“语言技术平台LTP”以及董振东先生提供的《知网》中的评价词汇和情感词汇。 [1] 许洪波,孙乐,姚天昉. 第三届中文倾向性分析评测总结报告[R]. 第三届中文倾向性分析评测(COAE2011). 2011,1-24. [2] Ana-Maria Popescu, Oren Etzioni. Extracting product fFeatures and opinions from reviews[C]// Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing.2005:32-33. [3] 刘鸿宇, 赵妍妍, 秦兵, 等. 评价对象抽取及其倾向性分析[J]. 中文信息学报,2010, 24(1):84-88. [4] Li Zhuang, Feng Jing, Xiaoyan Zhu. Movie review mining and summarization[C]// Proceedings of the 15th ACM International Conference on Information and Knowledge Management. 2006: 43-50. [5] Nozomi Kobayashi, Kentaro Inui, Yuji Matsumoto. Collecting evaluative expressions for opinion extraction[C]// Proceedings of the 1st International Joint Conference on Natural Language Processing. 2004: 584-589. [6] Janyce Wiebe, Theresa Wilson, Rebecca Bruce, et al. Learning subjective language [J].Computational Linguistics. 2004, 30(03): 277-308. [7] G. Somprasertsri, P. Lalitrojwong. Mining Feature-Opinion in online customer reviews for opinion summarization[J]. Journal of Universal Computer Science. 2010,16(6): 938-955. [8] V. Hatzivassiloglou, KR. McKeown. Predicting the semantic orientation of adjectives[C]// Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics.1997:174-181. [9] 李素建,刘群.汉语组块的定义和获取[C]//全国计算语言学联合学术会议(SWCL2003)论文集.2003:110-115. [10] 语言技术平台LTP. 哈尔滨工业大学社会计算与信息检索研究中心[DB/OL]. http://ir.hit.edu.cn/ [11] Minqing Hu, Bing Liu. Mining and summarizing customer reviews[C]// Proceedings of the Conference on Knowledge Discovery and Data Mining. 2004:168-177. [12] 王素格,杨安娜,李德玉.基于汉语情感词表的句子情感倾向分类研究[J].计算机工程与应用,2009,45(24):153-155. [13] 王素格,杨安娜.基于混合语言信息的词语搭配倾向判别方法[J].中文信息学报,2010,24(03):69-74.
4.2 特征—观点对的抽取


5 实验结果与分析
5.1 组块获取
5.2 特征—观点对抽取


6 结束语
猜你喜欢
石油和化工设备(2022年6期)2022-07-11
小学生学习指导(低年级)(2021年4期)2021-07-21
中学课程辅导·教师通讯(2020年22期)2020-02-04
中文信息学报(2019年12期)2019-12-30
船海工程(2019年1期)2019-03-04
军营文化天地(2018年1期)2018-08-15
营销界(2015年22期)2015-02-28
清风(2014年10期)2014-09-08
高中生学习·高三版(2014年3期)2014-04-29
中国党政干部论坛(2009年9期)2009-09-29
