
评论挖掘中产品属性归类问题研究
2012-06-29 05:53:54马云龙林鸿飞
中文信息学报 2012年3期
杨 源,马云龙,林鸿飞
(大连理工大学 信息检索研究室,辽宁 大连, 116024)
1 引言
随着网上购物的发展,网上产品评论的数量也急剧增多,产品评论的情感分析一直是一个热点研究问题。在分析产品情感时,除了分析产品的整体情感外,也从更细的粒度上来分析,如产品的各个属性。由于写评论的人习惯各异,对产品的同一种属性会用不同的描述,例如,手机的“外观”和“外形”指的是同一种属性。把这些属性进行归类,才能更好的进行情感分析。
手工进行属性归类虽然会很准确,但是这是一项耗费时间的工作,需要寻求一种自动的方法来解决这个问题。属性的归类也可以通过现有的同义词资源,把同义的属性归为一类,但是这只能解决其中的一部分,还有很多同类的属性不是同义词,例如,手机的“外形”和“设计”。需要其他的方法更全面的解决这个问题。
Carenini等人[1]利用WordNet得到了几个相似性矩阵,把一些属性描述映射到一个特定领域的属性分类上。Carenini等人是根据存在的资源来计算词的相似性,这种方法的缺点是没有考虑词之间的分布相似性,而这是很有用的信息。分布相似性主要考虑了属性周围的一些词,衡量相似性的方法有Cosine、Jaccard、Dice等[2]。
Guo等人[3]提出了mLSA算法,进行属性归类,mLSA将LDA运行了两次,是一种无监督算法。属性归类问题也与限制性聚类相关,限制性聚类中使用了两种限制,一种是某些节点肯定在一类中,另一种是某些节点不可能在一类中。Andrzejewski等人[4]把这两种限制引入到LDA中,提出了DF-LDA算法。
Zhai等人[5]针对属性归类,提出了一种半监督的SC-EM算法,并把以上提到的几种算法作为对比试验,通过实验证明了SC-EM算法对属性归类的结果要优于以上几种算法。SC-EM算法是对EM算法的改进,首先从语料中获取每个属性周围的一些词,作为属性对应的文档,然后把其中的一部分属性进行标注,选用朴素贝叶斯模型作为分类器。SC-EM算法利用了两条自然语言知识,一条是含有相同字的两个属性有可能是同类属性,另一条是同义词的两个属性有可能是同类属性。SC-EM算法利用这两条知识,得到了更好的初始化效果。
SC-EM算法既用到了存在的资源,又用到了分布相似性,但是有一个缺点,产品评论中含有丰富的情感信息,对于同类属性,评论中往往会有一些相同的情感词来修饰,例如,手机的“外观”和“外形”常常和“小巧”搭配,而“声音”是不与“小巧”搭配的,显然这些情感词对属性的归类是很有意义的。本文充分考虑了产品评论中的情感因素,从语料中抽取出属性和情感词的搭配对,利用这些搭配对形成二部图,然后用权重标准化SimRank算法[6]来计算各个属性之间的相似度,并把所得的结果与SC-EM算法中的贝叶斯分类器进行融合,得到了更好的分类结果。
本文的结构安排如下:第二节介绍相关术语,第三节介绍产品属性和情感词的搭配,第四节介绍权重标准化SimRank与SC-EM算法的结合,第五节介绍实验结果和相关分析。
2 相关术语
属性:实验语料选取手机评论,用属性表示手机的一些具体特征,例如,屏幕、按键等,手机型号或品牌也属于属性的范围。
属性描述:同一类的属性可能会有不同的词或短语来描述,例如,手机的“外观”和“外形”,这样的词或短语称为属性描述。
同类属性:同类属性是指意思相同的属性,例如,手机的“外观”和“外形”。
3 属性与情感词的搭配
3.1 产品属性的获取
要进行产品属性归类,首先要获取产品的属性, Hu等人[7]和Liu等人[8]对属性的抽取已经做了很多工作。本文所要解决的主要问题是产品属性的归类而不是抽取,所以预先准备了一个手机属性表,用于属性归类。
3.2 情感词的获取
情感词的识别主要依据大连理工大学信息检索实验室的情感词汇本体[9]。情感词汇本体已经能够识别绝大部分的情感词,但是可能会出现例外的情况,例如,产品评论中有些情感词没有在情感词汇本体中登录,有些产品属性周围找不到情感词。为了更好的解决情感词缺失的问题,把形容词作为情感词的补充,很多形容词都有情感,而且根据日常用语的习惯,形容词也和产品属性之间存在搭配关系。
3.3 属性与情感词的搭配
产品评论是评论者对产品的评价,有很多都是主观性文本,包含了丰富的情感。根据语言习惯,对不同的产品属性进行评价时,会用不同的情感词,例如,评价手机的“外观”时,经常用“小巧”,而评价手机的“价格”时,经常用“低廉”。就像修饰名词时要用相应的形容词一样,评价产品属性时也会用相应的情感词,属性和情感词之间自然地产生了一种搭配关系,如表1所示。

表1 属性与情感词搭配举例
实验中把离产品属性最近的情感词与产品属性进行搭配,形成候选搭配对,然后通过式(1)计算情感词与产品属性的互信息。
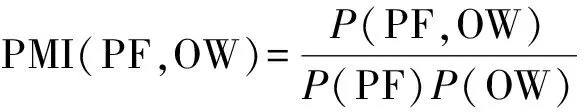
(1)
公式(1)中PMI(PF,OW)是属性与情感词的互信息,P(PF,OW)是属性与情感词共现的概率,P(PF)是属性出现的概率,P(OW)是情感词出现的概率。
实验没有采用依存分析技术来确定情感词和产品属性的搭配关系主要考虑了两点:一方面受目前依存分析技术准确率的影响,可能会带来一定的误差,另一方面由于产品评论来自网络,其句法结构不是很规范,并不太适合对其进行依存分析。
在有限的语料中,情感词和产品属性的共现可能是不均匀的,致使互信息偏低或偏高,为了更好的适应这种不均匀性,先假设含有相同字的两个属性是同类属性,同义词的两个属性是同类属性,计算互信息时,不是计算情感词与单个属性的互信息,而是计算情感词与这类属性的互信息。当然,所有属性中,只有一部分是同义词或含有相同的词,其余的仍计算情感词与单个属性的互信息。实验中主要通过《同义词词林》[10]判断两个词是否是同义词,只是进行简单的判断,并没有利用《同义词词林》的层次信息,对多义的词不进行处理,只利用属性词和情感词的共现信息,避免为初始化引入更多噪音。
计算出所得搭配对的互信息之后,去掉一些互信息过低的搭配对,这些可能是抽取过程中引入的噪音。剩余的搭配对形成了一个二部图的形式,如图1所示。
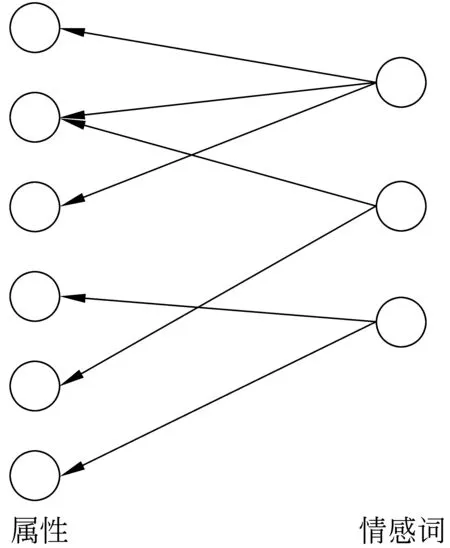
图1 属性情感词形成的二部图
图1是由属性与情感词的搭配对形成的二部图,左边是属性,右边是情感词,有向的箭头表示情感词对属性的修饰关系。由图1可以看出同类属性经常与相同的情感词共现,另外同类属性并不都与同一个情感词共现,但是修饰同类属性的若干个情感词会与某个属性共现,使这些属性和情感词连接在一起,形成整个二部图中的一个子图,这个子图中的属性应该是同类属性。
4 权重标准化SimRank与SC-EM算法的结合
4.1 SimRank
属性与情感词形成了二部图,可以用Glen等人[11]提出的SimRank算法来计算属性之间的相似度,SimRank算法的基本思想是:与相似节点相连的节点相似。这样应用到本文中,被同一个情感词修饰的属性是相似的,修饰同一个属性的情感词是相似的。SimRank计算公式如下:
(2)
在图GT={VT,ET}中,I(vt)表示节点vt的入边源节点集合,Ii(vt)表示节点中第i个入边源节点,|I(vt)|是节点vt的入度,Sim(va,vb)表示节点va和vb的相似度,常数C是取值从0到1的实数,表示相似度在沿有向边传递过程中的衰减系数。
4.2 权重标准化SimRank
属性与情感词形成的二部图中,不同属性与情感词的相关程度不一样,它们的互信息也不一样,经常共现的属性与情感词应该有较高的互信息,所以连接属性和情感词的边是有权重的,实验中把属性和情感词的互信息作为边的权重,因为它能反映出属性和情感词的相关程度。
直接用SimRank计算二部图中属性的相似度会有一个缺点,SimRank在计算节点间相似度的时候仅利用了有向图的结构信息,而没有考虑有向边的权重。也就是说直接用SimRank进行计算的话,会把相关程度较低的搭配对和相关程度较高的搭配对统一对待,而抽取搭配对的时候难免会引入一些噪音,如果把这些噪音搭配按照正常的搭配进行计算的话,会影响实验结果。为了更好的降低这些噪音的影响,实验采用了马云龙等人[6]提出的权重标准化SimRank算法(Weight Normalized SimRank,WNS)。
WNS算法首先对图中每个节点的入边权重进行标准化,使之对于任意节点vt均满足:
(3)
WNS的计算公式如下:
(4)
(5)
其中,ω(va→vb)表示由va节点到vb节点的有向边上的权重,其他符号与基础SimRank公式中同义。
用WNS算法计算二部图中属性的相似性时,既利用了有向图的结构信息,又利用了有向边的权重。假设抽取的搭配对中,有两个属性与同一个情感词搭配,其中有一个是错误的搭配,如果用SimRank算法计算,这两个属性会有很高的相似度,而用WNS算法计算的话,错误搭配的有向边的权重比较小,从而会降低这两个属性的相似度。
4.3 权重标准化SimRank与贝叶斯的结合
如引言所述,Zhai等人[5]使用半监督的SC-EM算法,进行产品属性的归类,本文使用权重标准化SimRank对SC-EM算法进行了改进。SC-EM算法首先从语料中获取属性周围左右各3个词作为该属性对应的文档,然后对其中的一部分属性标注类别,进行半监督学习,选取贝叶斯分类器,用以下三个公式计算每个属性属于某个类别的概率。
(6)
(7)
(8)
其中,D是训练文档集,di是D中的一篇文档,wdi,k是文档di中的第k个词,训练集中的总词表是V={w1,w2,…,w|V|},C={c1,c2,…,c|C|}是属性的类别集合,Nti是词wt在文档di中出现的次数。
通过WNS算法可以算出测试集中每个属性与训练集中每个属性的相似度,对应测试集中的每个属性,训练集每个类别的属性中都会有一个属性,使得测试集中的属性与该属性在对应类别中的相似度最大。本文把测试集中属性与该属性的相似度作为测试集中属性与这个类别的相似度,这样可以得到测试集中的属性与各个类别的相似度。本文定义了式(9),从属性与情感词搭配的角度,计算属性属于某个类别的概率。
(9)
其中,fi是对应文档di的属性,WNS(fi,cj)是属性fi与类cj的相似度。
式(8)是从属性与周围的词共现的角度,式(9)是从属性与情感词搭配的角度,计算属性的类别,把式(8)和式(9)相乘,所得的结果作为属性类别判断的依据更为充分,得到
(10)
通过式(10)得到测试集中每个属性的类别,然后把训练集和测试集作为训练集进行迭代,完成半监督学习。
5 实验
实验语料是来自IT168网站[12]的31 624句手机评论,其中包含159个属性描述,共分为21类。选取SC-EM算法作为对比试验,采用SC-EM中的三个评价标准,实验采用的是半监督学习,可以使用分类准确率作为一个评价标准,分类准确率采用宏平均的方式计算,另外两个采用聚类的评价标准,标准熵和纯粹度,数据集DS上的类别集合是C={c1,…,cj,…,ck},DS被分为k个子集DS1,…,DSi,…,DSk,熵的计算公式如下。
(11)
(12)
其中,Pi(gj)是cj类数据在DSi中所占的比例。纯粹度的计算公式如下。
(13)
(14)
实验采用六次交叉验证的方式,本文主要考虑的是半监督的学习模式,想用较少的标注来得到较好的结果,这些比较少的训练集就像种子节点,而且主要思路是通过SimRank该进半监督学习的模式,所以设计实验时没有与分类方法进行对比,只把选取SC-EM算法作为baseline,把SC-EM算法与WNS相结合的结果作为最终结果,交叉验证的平均结果如表2所示。

表2 产品属性归并结果
如表2所示,把WNS算法融入到SC-EM算法中后,提高了准确率,得到更小的熵值和更大的纯粹度,在产品评论中,属性和情感词经常搭配使用,针对不同的属性,评论者会用不同的情感词来表达情感,而同类属性描述的是产品的同一个部分,可以用相同的情感词来修饰,利用属性和情感词的搭配,以及属性和情感词的互信息形成的二部图,用WNS算法利用二部图的信息算出各个属性的相似度,并与SC-EM算法中的贝叶斯分类器进行结合,所得的结果要好于只用贝叶斯分类的结果,两者结合的方式既考虑了同类属性周围有相同的词共现,又考虑了评论句中属性与情感词的搭配,所以得到了更好的属性归类结果。
例如,手机的“设计”和“外观”这两个属性词,周围共现的词可能不太一致,但是都会被“时尚”这个情感词所修饰,所以加入WNS算法后,会增加两者之间的相似度。
随着训练集比例的增大,实验结果增长的幅度越来越小,这一方面是因为有些属性通过较小的训练集就能得到比较准确的分类,另一方面是因为SC-EM算法通过同义词和含有相同字的属性优化了初始化过程,新增加的训练集有可能已经出现在优化的过程中,所以这个优化过程,比较有用,可以用较小的训练集得到更好的结果。当然,更多的训练集会带来更好的结果,但是半监督学习的初衷就是想减少训练集的规模,所以表2中没有显示过多比例训练集的结果。
实验过程中也会有一些因素,影响实验结果,分词过程会产生一定的偏差,从而会影响产品属性周围词的抽取,也会影响属性与情感词搭配对的抽取。有些属性在《同义词词林》中未登录,这也会用影响半监督学习中初始化的优化过程。
6 结论
本文主要把产品评论中同类属性的不同描述进行归类。同类属性虽然有不同的描述,但是在句中却和相同的情感词搭配使用。本文首先抽取评论句中属性和形容词的搭配关系,形成一个二部图,然后用权重标准化SimRank计算不同属性之间的相似度,并把所得的结果与半监督学习中的贝叶斯分类器进行融合,得到了更好的分类结果。
本文进行产品属性归类时,仍存在一定的不足。在利用属性与情感词搭配构成的二部图计算属性之间的相似度时,难免会引入一些噪音搭配,本文主要通过互信息来降低噪音搭配中属性与其他属性的相似度,能更精确的发现搭配,会得到更好的分类结果。下一步的工作可以研究属性与情感词之间的搭配关系,在比较全面发现搭配的同时,保障搭配的精度。
[1] Carenini G., R. Ng, E. Zwart. Extracting knowledge from evaluative text[C]//Proceedings of International Conference on Knowledge Capture, Banff, Canada, 2005: 8-15.
[2] Lee L. Measures of distributional similarity[C]//Proceedings of ACL. Maryland, USA, 1999: 25-32.
[3] Guo H., H. Zhu, Z. Guo, et al. Product feature categorization with multilevel latent semantic association[C]//Proceedings of CIKM. Hong Kong, 2009: 1087-1096.
[4] Andrzejewski D., X. Zhu, M. Craven. Incorporating domain knowledge into topic modeling via Dirichlet forest priors[C]//Proceedings of ICML. Montreal, Quebec, Canada ,2009: 25-33.
[5] Zhongwu Zhai, Bing Liu, Hua Xu, et al. Grouping Product Features Using Semi-Supervised Learning with Soft-Constraints[C]//Proceedings of the 23rd International Conference on Computational Linguistics (COLING-2010), Beijing, China, August 23-27, 2010: 1272-1280.
[6] Y. L. Ma, H. F. Lin, S. Jin. A revised simrank approach for query expansion[C]//Proceedings of the 6rd Asia Information Retrieval Societies Conference(AIRS 2010). Springer, December, 2010: 564-575.
[7] Minqing Hu, Bing Liu. Mining and summarizing customer reviews[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD-2004), Seattle, Washington, USA, Aug 22-25, 2004: 168-177.
[8] Lei Zhang, Bing Liu. Extracting and Ranking Product Features in Opinion Documents[C]//Proceedings of the 23rd International Conference on Computational Linguistics (COLING-2010), Beijing, China, August 23-27, 2010: 1462-1470.
[9] 徐琳宏, 林鸿飞,潘宇,等. 情感词汇本体的构造[J]. 情报学报,2008, 27(2):180-185.
[10] HIT-IRLab-同义词词林(扩展版),哈尔滨工业大学信息检索研究室: http://ir.hit.edu.cn/[EB/OL].
[11] G. Jeh, J. Widom. SimRank: A measure of structural-context similarity [C]//Proceedings of SIGKDD. Edmonton, Alberta, Canada, 2002: 538-543.
[12] IT168网站http://pinglun.it168.com [OB/OL].
猜你喜欢
幼儿画刊(2023年7期)2023-07-17 03:38:24
中学生数理化·中考版(2021年10期)2021-11-22 07:26:40
童话世界(2019年32期)2019-11-26 01:03:00
疯狂英语·新读写(2018年2期)2018-11-29 17:59:24
中学生数理化·七年级数学人教版(2017年12期)2017-04-18 11:22:16
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
儿童故事画报(2015年7期)2016-01-27 00:01:18
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2015年9期)2015-04-09 11:59:22
弹箭与制导学报(2015年1期)2015-03-11 15:32:31
