
基于“固结词串”实例的中文分词研究
2012-06-29 05:53:48修驰,宋柔,2
中文信息学报 2012年3期
修 驰,宋 柔,2
(1. 北京工业大学 计算机学院,北京 100022;2. 北京语言大学 语言信息处理研究所,北京 100083)
1 引言
解决中文分词问题的方法主要分为两类:基于词(或词典)的方法,例如,基于规则的最大匹配方法[1]、基于统计的词的N元语法的方法[2]。基于字的方法,例如,基于最大熵模型(ME)[3]、基于条件随机场模型(CRF)[4]的中文分词方法。
分词歧义和未登录词(OOV)一直是影响中文分词效果的两大因素。Bakeoff 2005的语料库统计数据说明未登录词造成的分词精度失落比歧义切分造成的精度失落至少大5倍以上[5]。基于CRF模型的字标注分词方法在训练语料与测试语料同质的情况下可以较好的解决OOV问题,在近几年的bakeoff中都取得了很好的成绩。但是歧义切分错误仍然是汉语分词中不可忽视的问题,CRF模型对歧义切分问题的解决并不够好,而且这一方法开销大、不灵活。有人采用规则加实例库的办法消除分词歧义[6]。但这种方法需要人工构建规则与实例库,只能解决有限语言现象,难以适用于各种不同的语料。因此,希望找到一种专用于中文分词的机器学习方法,既可以吸收基于字的分词方法的优点,充分挖掘训练语料中的分词信息,又不需要太长的训练时间得到较好的分词结果。
本文从CRF在分词歧义上存在的问题入手,提出了基于“固结词串”词表分词的方法,即一种基于实例的中文分词方法。利用固结词串可以简化机器学习过程,充分利用训练语料中的知识。本文组织方式如下:第二节分析CRF中文分词方法存在的问题;第三节提出基于固结词串解决中文分词歧义的方法;第四节阐述实验设计并分析结果;第五节进行总结。
2 CRF
近几年流行的基于字序列标注的机器学习方法在分词方面取得了较好的结果。在各种机器学习方法中,基于CRF模型的方法效果最优。条件随机场CRF(Conditional Random Filed)[4]是一个无向图模型,在给定观察值的情况下计算状态值的条件概率。在基于该模型的分词方法中,通常是用字形和字类作为观察值的特征。测试结果表明,这种方法可以较好的解决OOV问题。也可以在一定程度上解决已登录词的分词歧义(如表1所示)。但是我们分析分词结果发现,CRF在解决OOV和分词歧义的同时产生了很多外加的错误。本文第四节给出的实验数据表明,CRF同正向最大匹配方法相比,在后者的分词歧义错误中解决了1 426例,占96%左右,但是产生了1 836例分词歧义错误。表2、3、4举例给出了CRF分词中存在的问题。

表1 CRF解决歧义切分

表2 训练语料中出现的词CRF切分错误
表2显示在训练语料中出现的、有且只有一种分词方式的字符串,利用CRF分词方法切分错误的词。字符串“一支支”在训练语料中出现过1次,“一 / 支 / ”出现75次。“支”共出现1 248次,词首占69%、词尾占10%,单字占15%。“动”共出现4 163次,词尾占71%。“一支”分开的概率更大,“支动”连接在一起概率更高。因此CRF产生错误的切分结果。

表3 不应该成词的字符串被CRF合成一个词

表4 同种类型的字符串CRF分词结果不同
表3显示训练语料中没有出现,但也不应该识别为词的字符串。如果被测字符没有在训练语料中出现,前一个和后一个字符对它的影响十分重要。“6”这个字符在测试语料中是半角的,训练语料中没有半角字符,因此半角“6”没有在训练语料中出现过,但由于“分”经常做词首,“路”经常做词尾,取全局最优值后,“分6路”被划分为一个词。
表4显示测试语料中类型相同的两句话,由于上下文字形不一样,CRF的分词方式不同。“同比”在训练语料中出现15次,其中13次为“同比 / 增长”,因此字符串“同比增收”可以正确切分。但“比 / 上”在训练语料中出现过131次,从全局出发,切分成“比 / 上” 比切分成“同比”可以得到更好的概率值。因此“同比上升”不能切分正确。
3 固结词串3.1 固结词串定义
CRF训练的目的是为了让模型尽可能的挖掘训练语料中的分词信息,拟合训练语料。OOV可以按训练语料的分词知识进行构词。但对于在训练语料中已经存在的词所构成的词串,如果没有切分歧义,则不需要拆开再重新构词,可以不使用CRF分词。
对于测试训练语料中存在的词,字符串匹配是最简单的拟合语料的过程。假设测试语料中的字符串Stest,可以与训练语料中的字符串Strain完全匹配,且Strain在训练语料中只有一种分词标记方式,使用Strain的分词标记方式对Stest分词,也是一个拟合训练语料的过程。
如果Strain是由几个词组成的,Strain串中间的字符携带了上下文信息,这样的字符在上下文环境的约束下,分词标记一定是确定的。利用这样的分词信息,可以消解分词歧义而且不需要再计算概率和全局最优化,可以避免CRF中“一支/支动/听”“请/教老者”这样的错误发生。
因此我们提出利用“固结词串”对训练语料中出现过的字符串分词。“固结词串”可以由多个词组成,在训练语料中有且仅有一种切分方式。定义如下:
设每个字的分词信息使用标注符号表示:B代表词首,M代表词中,E代表词尾,S代表单字词(也可以加入B2、B3等标记表示词首第2个字、第3个字等,不影响下面的定义)。

定义中限制所有的Tj必须完全相等,目的是为了使字符串内部无多种切分情况;字符串的首尾必须被切开是为了让字符串的边界不存在交搭歧义。例如,字符串“中共北京市委”在训练语料中出现过多次,每次出现时的切分方式都是“ / 中共 / 北京 / 市委 / ”,则“中共北京市委”是一个固结词串。
但是如果仅限制字符串的首尾必须被切开,当训练语料中同时存在“基本 / 生存”和“基本 / 生存权”时,字符串“基本生存”因为“存”有两种标记方式,则不能成为固结词串。当语料不断增加,类似于“基本生存”的现象将会不断增加。另一方面,这种限制相当于对训练语料的过度拟合,测试语料中字符串上下文的变化,会产生部分新的切分形式。在这种情况下,利用现有的固结词串分词会带来新的切分歧义。例如,“中央歌剧”在训练语料中出现多次,切分方法都是“中央 / 歌剧”,测试语料遇到“中央歌剧院”, “剧”则被切成词尾,实际应该是“中央 / 歌剧院”,由此产生了新的歧义切分。因此定义中对“固结词串”添加了上下文的限制。
引用上文的例子字符串“基本生存”在训练语料中出现多次,例如,“缺乏 / 基本 / 生存 / 和 / 生产”和“人民 / 的 / 基本 / 生存权 / 造成”。在“基本生存”的下文不是“权”,例如,当α(上文)是“缺乏”β(下文)是“和”的情况下,“基本生存”都被切分成“/ 基本 / 生存 /”,则“基本生存”在特定的上下文中也是固结词串。
3.2 固结词定义
实验中,如果测试字符串在固结词串词表中找不到匹配项,则在普通词表中查找是否有匹配项。使用普通词表会出现如下问题。例如,字符串“新世纪”在训练语料中以词的形式出现过,那么“新世纪”是普通词表中的一个词。但是这个字符串在训练语料中存在两种分词方式“新 / 世纪”和“新世纪”。大部分情况下的切分为“新 / 世纪”,只有在特定的上下文环境下才会被切分为“新世纪”(“新世纪 / 出版社”)。由于切分方式不唯一,这个字符串不是固结词串。当测试语料出现字符串“新世纪”时,则会按照普通词词表“新世纪”的方式切分,造成大部分错误。实验中这样的问题十分明显,因此将实验中使用的“普通词”更改为“固结词”。
固结词是指,普通词表中的词,如果在训练语料中总是整体出现从不被切开,或者虽然有被切开的情况但以整体一个词的形式出现的次数最多,就将这个词作为固结词。因此,“新世纪”不在固结词词表中。虽然固结词和固结词串词表中都不存在“新世纪”这个词,但是当测试语料拥有足够的上下文,则可以找到包含“新世纪”的固结词串,将“新世纪”正确切分出来。
3.3 分词策略
分词策略是将基于固结词串实例的方法与基于普通词表的方法相结合。原则是以固结词串为主,普通词为辅。具体方法如下。
词表包含:携带上下文信息的固结词串表、不携带上下文信息的固结词串表、普通词表。从左至右前向最大匹配(FMM)对测试语料进行分词。设测试语句为Sen。
Step1 取Sen已经切分出的最后一个词(如果还未开始切分,则为φ)为上文α,在携带上下文信息的固结词串表中查找最长匹配字符串αCβ。如果找到,并且此串α与C之间是被切开的关系,则将匹配的字符串按照固结词串C的切分标记标注。转Step1。如果没有匹配到,转Step2。
Step2Sen中等待被切分的字符串,在没有上文信息的固结词串表中进行最大字符串匹配Cβ。如果匹配成功,将匹配的字符串按照固结词串C的切分标记标注。转Step1。如果没有匹配,转Step3。
Step3Sen中等待被切分的字符串,在普通词表中进行最大字符串匹配。如果匹配成功,将这个词切分出来转Step4。如果没有匹配到,将首字符字切分出来,此字符为单字。转Step1。
Step4对于利用普通词表切分出的字符串,回退一个字。如果以回退的这个字为首字,与后面的字符串可以组成固结词串,并且,原字符串去掉这个字仍然是个普通词,则更改利用普通词表切分的结果,使用回退一个字得到的切分结果,转Step1。否则放弃回退直接转Step1。
例如,字符串“为了看清楚”,在切分时首先在携带上下文信息的固结词串表中查找,找到的固结词串其分词方式为“φ/ 为了 / 看 / 清 /”。“φ”和“清”分别相当于定义中的“α”和“β”, “为了看”是“α”和“β”中间的固结词串C,可以确定其分词方式为“为了 / 看 / ”。然后再顺序查找以“看”为上文的携带上下文环境的固结词串,如果查找到“看 / 清楚”,则“清楚”被的切分出来。如果在固结词串中找不到“看清楚”,则在普通词表中查找“清楚”。如果普通词表中查找到“清楚”,利用Step4回退一字,查看是否存在以“楚”字开头的固结词串,如果没有则“清楚”被切分出来。
Step4中使用普通词表有时会产生歧义切分问题,为了减少此类问题,普通词表可换成固结词词表。目前,在选用这种最简单的分词策略的情况下,已经有效的降低了分词歧义。如果改进策略,相信将得到更好的分词效果。
4 实验4.1 实验语料基本情况
本实验采用第二季国际分词竞赛(bakeoff-2005)中PKU的语料对分词方法进行测试(如表5所示)。语料中数字、英文、全半角符号进行了统一的预处理。

表5 bakeoff-2005 pku语料词形词数
Pku训练语料中数字、英文、符号,使用全角符号(比如1.1%在训练语料中为1.1%)。
PKU测试语料中全半角符号混合使用,大部分数字使用半角符号。未登录词6 006个(token),占测试语料总词数(token)的5.7%。在不包含单字词的情况下共有5 592个未登录词(token),其中数字、英文、日期为2 370个,占未登录词的42.3%。
4.2 Baseline和Topline
实验的主要目的是测试固结词串分词方法对歧义的影响。实验结果采用准确率P、召回率R和调和平均值:F=2RP/(R+P)来进行评估(如表6、表7所示)。

表6 baseline

表7 topline
利用训练语料生成普通词词表,使用FMM的方法对测试语料进行分词,得到分词歧义的baseline。为了进一步确定歧义切分对分词结果影响,实验设置了topline。topline表示测试语料中所有分词歧义问题都被解决,只存在OOV错误的分词结果上限。实验中,将测试语料标准答案中的OOV用训练语料中提取的普通词表进行FMM分词,其他不改变,得到topline。如果所有的分词歧义都被正确解决,那么F值已经可以达到0.95。由此可见,歧义切分问题的解决对分词结果有着重要的影响。由于测试语料、训练语料中存在分词不一致现象,表7显示的是的topline理想值。
4.3 实验设计与结果
CRF的实验使用6-tag[7]标注集:B B2 B3 M E S。本实验对5字窗口和3字窗口特征的结果进行对比,采用3字窗口(如表8所示)可以得到更好的分词结果。工具为CRF++0.54*http://crfpp.sourceforge.net.。

表8 CRF实验使用的特征集

续表
固结词串分4个实验进行测试。固结词串不包含标点符号,长度限制在50个字符以内。表9显示分词实验结果。实验1按照分词策略的Step1到Step3进行,分词的词典由固结词串和普通词组成。虽然结果明显好于baseline,但是普通词会产生一些新的分词歧义。为了进一步解决这个问题,实验2加入Step4,将普通词切分的字符串回退一个字。例如,“正面 / 对 / 世界”中的“正面”是由普通词切分得到的,回退“面”。以“面”为首字,可以在固结词串表中找到“面对 / 世界”,而且去掉“面”字,“正”是一个单字词,则修改分词结果。

表9 固结词串词结果对比
实验3、4采用固结词替代普通词。实验表明,将普通词表换成固结词词表,结果有所提高。表10显示分词实验中使用固结词串的最好成绩与CRF成绩的对比,在没有识别OOV的情况下,固结词串Recall的成绩已经好于CRF的成绩。表11显示固结词串和CRF在相同机器上的训练、分词时间。

表10 固结词串与CRF结果对比
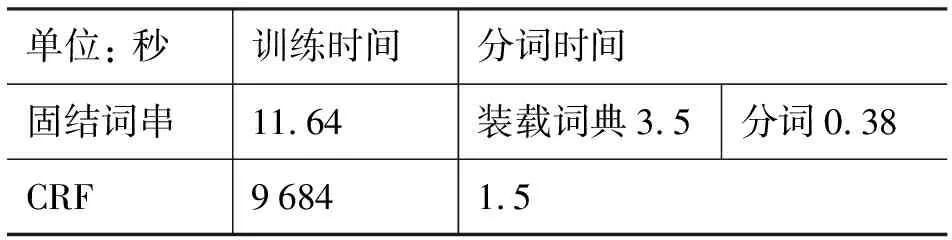
表11 固结词串和CRF训练时间对比
表12显示的是固结词串和CRF分词结果各类错误的数据统计,斜杠两边分别是type和token的数量。其中分词不一致是指训练测试语料中都存在的词,但是分词方式不同,并且不是组合歧义。由于固结词串携带上下文信息,对于这种分词不一致情况的适应能力好于baseline。

表12 固结词串和CRF各类错误数量对比

表13 固结词串和CRF解决分词歧义对比
从表12、13可以发现,对于训练语料和测试语料都是像《人民日报》这样的同质语料的情况,CRF主要解决的是OOV识别的问题,CRF分词所产生的新切分歧义要大于其解决的分词歧义。利用固结词串这种简单的机器学习方法,不仅可以解决分词歧义,带来的新分词歧义相对较少,而且不需要大量训练时间,既可以提高速度也可以提高分词效果。
5 结语
本文分析了CRF在解决分词歧义时存在的问题,指出CRF在切分训练语料中出现过的字符串时会产生更多新的分词歧义。提出了基于固结词串的分词方法,将基于固结词串实例和基于普通词表的分词方法相结合,利用简单的机器学习拟合训练语料,解决测试语料中分词歧义的问题。实验表明,这种方法可以在一定程度上解决分词歧义问题,并且不会产生太多的副作用。
固结词串虽然可以解决部分歧义,但仍需要改进分词策略才能取得更好的效果。无标注语料库中固结词串边界的识别和固结词串内部切分方法,OOV的处理,这些任务将是我们下一步的工作。
[1] 骆正清,陈增武,胡上序. 一种改进的MM分词方法的算法设计[J].中文信息学报,1996,10(3):30-36.
[2] 吴春颖,王士同.基于二元语法的N-最大概率中文粗分模型[J].计算机应用,2007,27(12):332-339.
[3] N. Xue. Chinese Word Segmentation as Character Tagging[J]. Computational Linguistics and Chinese Language Processing,2003,8(1): 29-48.
[4] J.Lafferty,A. McCallum, F.Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data.[C]// Proceedings of the 18th International Conf. On Machine Learning, 2001: 282-289.
[5] 黄昌宁,赵海. 中文分词十年回顾[J]. 中文信息学报,2007,21(3):8-19.
[6] 罗智勇,宋柔. 现代汉语通用分词系统中歧义切分的实用技术[J].计算机研究与发展,2006,43(6):1122-1128.
[7] Hai Zhao, Chunyu Kit. Unsupervised Segmentaion Helps Supervised Learning of Character Tagging for Word Segmentation and Named Entity Recognition[C]//Proceedings of the Sixth SIGHAN Workshop on Chinese Language Processing(SIGHAN-6), Hyderabad, India,2008:106-111.
猜你喜欢
英语世界(2021年13期)2021-01-12 05:47:51
新世纪智能(教师)(2019年2期)2019-09-11 05:57:22
新闻传播(2018年15期)2018-09-18 03:19:58
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
疯狂英语(双语世界)(2016年3期)2016-02-27 10:12:00
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
图书馆建设(2012年3期)2012-10-23 05:16:30
对联(2011年20期)2011-09-19 06:24:36
网络安全与数据管理(2011年17期)2011-07-25 00:33:50
