
中文论坛内容监测的方法研究
2012-10-15 01:51:32郝秀兰胡运发
中文信息学报 2012年3期
郝秀兰,胡运发,申 情
(1.湖州师范学院 信息与工程学院,浙江 湖州313000;2.复旦大学 计算机科学与技术学院,上海200433)
网络论坛中(又称BBS)的帖子同所有的用户生成内容(User-generated Content,UGC)一样,具有以下特点:可以为不同背景、身份的用户所创建;质量参差不齐,描述语言丰富多彩——书面语、口语、网络用语等。如何对这些杂乱无章的内容进行监控是安全部门所关心的重点之一,话题识别与跟踪(Topic Detection and Tracking,TDT)是监控的有效手段之一。
话题检测与跟踪是一项针对新闻报道进行信息识别、挖掘和组织的研究[1]。话题由一个种子事件以及后续直接相关的事件或活动组成;子话题是针对其中某一事件的相关描述;事件则定义为发生于特定时间和特定地点的事情。例如,“2001年9月11日针对美国世贸和五角大楼的恐怖袭击”是话题“911”的种子事件,它与“灾后处理”、“嫌疑犯调查”和“国际社会援助”等后续相关事件构成完整的“911”话题,其中对每个真实事件的相关描述构成了该话题内的不同子话题。但是,从种子事件到“灾后处理”,话题已发生了“漂移”。
在TDT评测中,话题是由Nt个描述该话题的报道定义的。跟踪系统根据给定的Nt个报道进行训练,并对后继的新闻报道流判断出他们是否与给定的话题相关。
针对BBS的特点先提出了一个基线模型、一个解决“话题漂移”现象的改进模型、权重调节模型。从应对BBS帖子的不规范性及提高中文TDT系统的处理速度出发,提出了一种新的中文特征抽取方法。实验结果显示,该方法是有效的。
1 研究现状
2004年TDT评测结束之后,国外文献有关TDT的介绍较少。这里介绍的国外文献绝大部分是2004年之前在TDT方面的研究,无论从问题定义、还是方法上,对TDT的研究都有重大影响和意义。国内的相关研究更侧重基于TDT本身的特色进行探索,在方法上注重统计策略和自然语言处理技术相结合,在研究趋势上逐步面向融入数据挖掘、信息抽取和篇章理解等相关技术。
1.1 话题跟踪
传统话题跟踪主要基于统计,根据特征的概率分布,采用统计策略判别报道与话题模型的相关性。James Allan[2]采用Rocchio算法实施跟踪。Franz等[3]则尝试采用聚类方法将话题识别系统转化成跟踪系统。
基于统计策略的适应性话题跟踪核心思想是系统可以根据伪相关反馈对话题模型进行自学习。在伪反馈过程中,所加入的话题只是种子事件的某一侧面,会引起“话题漂移”。
为解决这一问题,LIMSI[4]在原有自学习过程中嵌入二次阈值截取功能,来削弱话题漂移。王会珍[5]采用增量式方法对话题跟踪模型进行修正,在修正时考虑话题跟踪任务基于时间的特点。郑伟[6]基于改进的相关性模型,对跟踪中伪相关反馈包含的新颖信息进行检测和建模,跟踪话题漂移。张辉等[7]针对新闻报道的特点,用三个维度:标题特征、内容特征、实体特征来刻画一个文档,构成三维文档向量3DVM,并构建自适应的、基于kNN的追踪器。
1.2 话题识别
统计模型的最大缺陷在于无法有效区分同一话题下的不同事件。Kumaran[8]、Yang[9]等学者使用自然语言处理(NLP)技术辅助统计策略解决新事件识别问题。Kumaran[8]将报道描述成三种向量空间:全集特征向量、仅包含NE的特征向量和排除NE的特征向量。Kumaran对比了三种向量空间模型对新事件识别的影响,发现NE在某些话题中可促进事件之间的区分,在另一些话题中效果却不明显。针对这一现象,Zhang Kuo[10]基于χ2分布统计TDT2中各NE类别与各话题类别的关联性,并将这一关联性的量化指标融入特征权重的再分配。
陈友等[11]提出一种基于噪音过滤的话题发现模型,从内容和用户参与度两个角度来检测论坛话题。
Zhang[12]提出了基于话题的 T-tf×idf权重方式来度量模型中特征的重要性,用动态话题模型来解决两个问题:话题漂移及话题中的噪声。
陈友等[13]提出了一种通用的高质量主题发现框架,利用基于遗传算法、禁忌搜索与机器学习的特征选择算法提取内容特征,利用结构特征去发现高质量主题。
综上所述,在TDT领域,为了提高识别与跟踪性能,人们采用了统计与NLP相结合的方法,同时采用了多种方法并用的策略。在处理具体问题时,还考虑问题本身的特点。
2 话题跟踪模型选择
2.1 BBS帖子的特点
在BBS中,每一篇帖子都具有如下信息:发帖人标识、标题、内容、所属版块(也称为社区)、发帖人IP地址、发帖时间等。例如,复旦日月光华BBS的新闻版块主要包括以下几个子社区:时事、房地产、海峡两岸、证券投资/财经、军事等。
内容相同的帖子,可能会发表在不同的社区。如,“黎巴嫩身上的三座大山:战火把它变成战争代名词”,有的人喜欢把它放在时事区,而有的人则会把它放在军事区,还有人会把它同时放在这两个社区里。也有可能被人从一个社区转载到另一个社区。
同一标题下的帖子,通常第一个发帖人(楼主)的帖子较长,而回帖通常较短。
中文BBS的写法更为随意,有的人从头到尾一个标点符号都不使用,只是使用换行;用语也更为丰富,汉语中夹杂有英文、英文缩写、拼音、拼音缩写,还有许多网络用语,例如,“顶”、“ding”等都是常用词汇。
2.2 基本模型
2.2.1 BBS中帖子的表示
面向BBS的话题识别与跟踪仍然采用向量空间模型VSM来描述每一个帖子。对帖子首先进行分词处理,滤掉停用词。特征权重采用增量式TFIDF。用到的标记符号及其含义如表1所示。
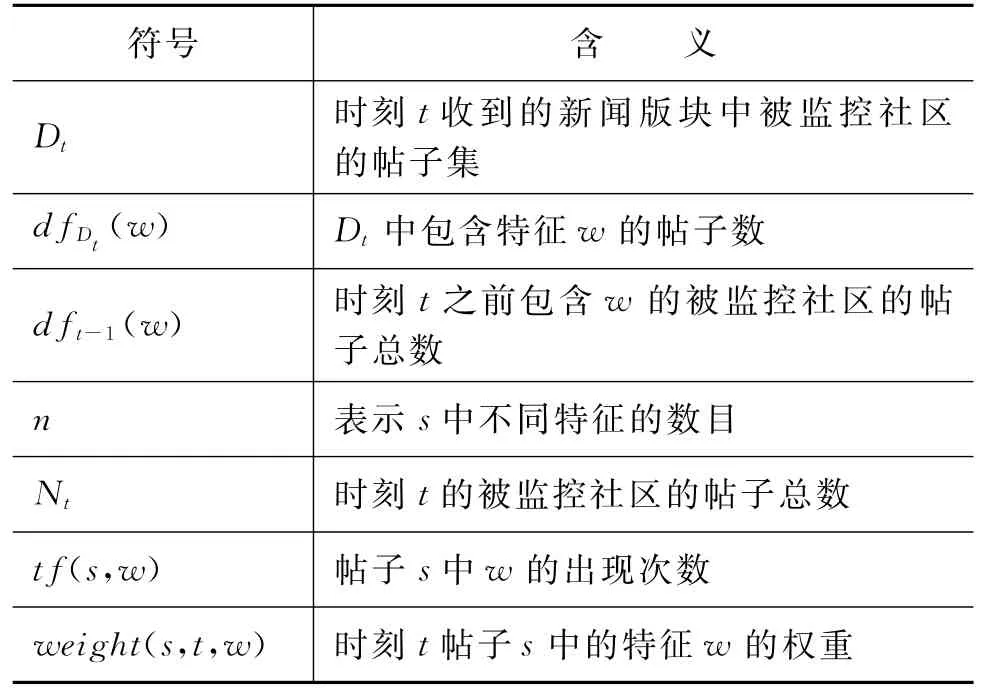
表1 标记符号及其含义
在t时刻包含w的帖子数为:

时刻t收到的帖子s表示为

特征的权重表示为

对于较长的帖子,从帖子中选择权重排在前1 000的特征来表示该帖子的内容。1 000个词语足以使得大部分帖子的所有特征都包含进来,特别长的帖子用更为集中的特征来表示。
2.2.2 帖子的相似度计算
仍然采用余弦法来计算两个帖子之间的相似度:
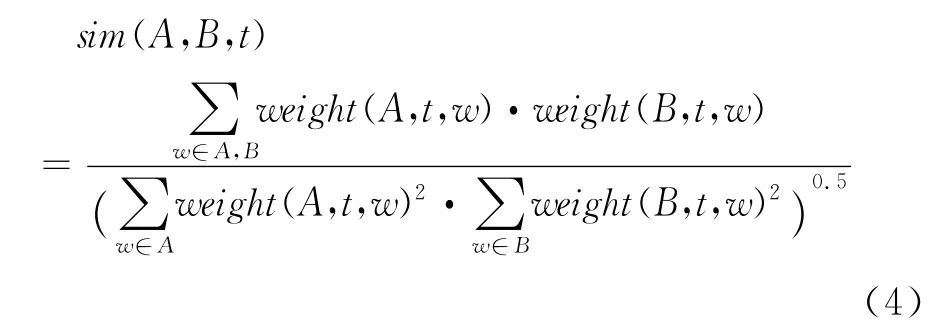
2.2.3 识别与跟踪过程
整个识别与跟踪过程采用TOD+类心(Centroid)法。TOD算法即阈值顺序依赖聚类算法,顾名思义,与阈值及数据的输入顺序密切相关,是一种单遍(Single-pass)聚类算法。在没有话题可跟踪时,只执行话题识别任务:
○ 首先按时间顺序对帖子进行排序;
○第一个话题:将出现最早的、由楼主发出的帖子及其跟帖组成的所有帖子,看作是一个类,形成伪类心,然后计算每个帖子与类心的相似度:
如果相似度小于一定阈值t1,则把这个帖子剔除出去;
否则,保留该帖;
最后再用保留的帖子计算真实类心;
○ 以后的每个话题都按第一个话题的方法,先产生伪类心,再产生真实类心,与前面的话题的真实类心进行相比:
如果与所有的话题相比,相似度都小于一定的阈值t2,则产生一个新的话题;
否则,归入与它相似度最高的话题。
整个过程,可看作是两个算法的嵌套,外层用的是TOD算法,内层用的是类心法。
对话题识别任务稍作修改,即可用于跟踪任务:
对于每一待处理的话题,首先与需要跟踪的话题进行相比,
如果相似度大于一定阈值t2,那么就认为是on-topic;
否则,用与话题识别相同的方法进行处理。
算法采用的是双阈值方法,一个是计算同一标题下的跟帖是否与楼主讨论的话题一致的阈值t1——标题内相似度阈值;另外,是后续话题与前面已产生话题进行比较的阈值t2,即判断该话题是否是一个新话题——新话题阈值。
我们假设大多数的回帖都与楼主的帖子相关,所以标题内相似度阈值t1的设置较小。而进行跟踪时所用到的阈值t2相对t1来说要大得多,可以通过它来控制所能跟踪到的帖子的数量。
2.3 改进的识别与跟踪过程
为了应对“话题漂移”现象,对上面的基准模型进行了修改,每个模型用两个向量表示:
(1)种子向量

其中,s1表示关于某话题的首次帖子,即相应话题的楼主的帖子。由于标题是对帖子内容的概括,其中的词含有表示帖子话题的词。对于s1中出现的标题title中的词,我们对其权重进行加重处理,即

(2)后续话题向量
假设话题Ti有N 个帖子,也就是有N-1个是跟踪到的帖子,那么可用Trcaked向量来表示跟踪到的后续话题向量:
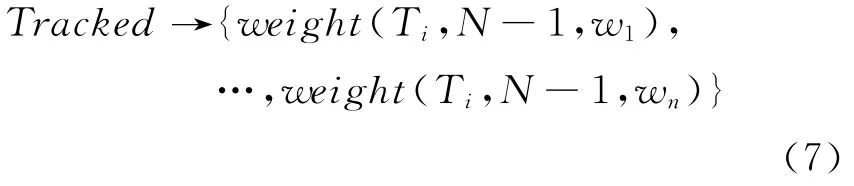
其中,weight(Ti,N-1,wx)表示话题Ti后续帖子有N-1个时,后续话题向量中特征wx的权重。在时刻t,若又有一个帖子sk跟踪到,那么Ti中将有N个跟踪到的帖子,此时,后续话题向量权重的更新公式为
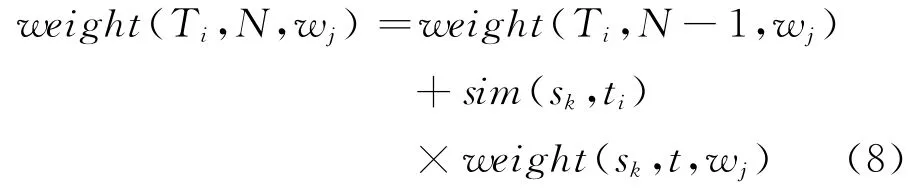
其中,sim(sk,Ti)表示话题Ti与帖子sk的相似度。也就是说,后续话题中出现的词的权重已经按其与话题的相似度进行了加权,在一定程度上可以抑制与它相近而与原话题相差较远的帖子的加入。
帖子s与话题Ti的相关度计算公式为:
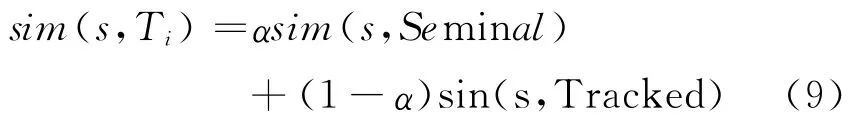
2.4 权重改进模型
在这里我们借鉴Zhang Kuo[10]的思想,引入基于词类及文本类别的权重调节。
词类包括命名实体(人名、地名、组织名、日期、货币)、名词、动词、形容词、副词。不同的词类在不同的话题间的作用是不同的,对特征权重按下式进行更新:
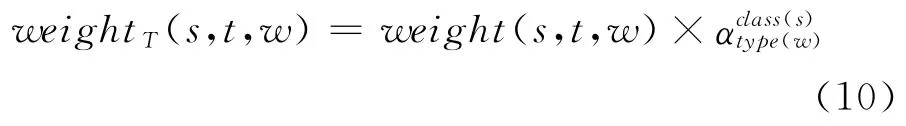
其中,type(w)为 w 的词类,class(s)为s所属文本类别,αck是类c、词类为k的词的权重调节参数。对于BBS的舆情监督而言,较重要的信息有以下几类:丑闻、犯罪、灾害、军事、财经等。参照Zhang Kuo[10],αck的取值如表2所示。

表2 词类在不同文本类别中的加权值
在本模型中,由于用到了文本类别,所以在实施话题识别与跟踪前,需要对时事区中的帖子进行分类。因楼主的帖子所包含的信息量较大,先对楼主的帖子进行分类,跟帖的类别设置与楼主的帖子一致。我们使用kNN文本分类方法对楼主的帖子进行处理。动词的加权值与名词一样,副词的加权值与形容词一样。
3 特征选择
常用的文档特征有词、短语和N-gram项,词语是最直观的表征文档语义特征的方法。对于中文来说,需要借助于词典和使用分词技术。
为了在分类过程摆脱复杂的分词程序,周[14-15]用N-gram项作为文档的特征。但是,N-grams项的语义显然没有真正的词那么明显;同时,N-gram项的数目远远大于词典中词的数目,使算法的时间和空间消耗大大增加。
词性也常常与其他种类的特征一起使用。例如,2.4节中与文本类别结合,对特征的权重进行调节。
在构建BBS话题识别与跟踪系统中,考虑到帖子的不规范性及TDT系统的处理效率,我们尝试使用了一种新的特征抽取方法——基于二元的准词汇抽取方法。使用了以下几个词表:普通的准二字词表(由二字词、多字词处理而成)、地名词表。
3.1 普通词表
由机器可读词典《现代汉语词典》中的词汇整理而成。一方面,由于单字词的歧义很大,对区分话题的贡献不大;另一方面,随着抽取的2-grams的数目的增加,分类性能在不断增加[15],所以在普通词表中,我们只收录了二字及二字以上的词汇。对于二字以上词汇,进行如下处理:
设wordm=τi1…τin,n>2,那么可以把它拆分成n-1个二元项,即
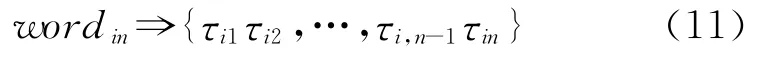
例如,“精益求精”经过处理后,变成三个字串“精益”、“益求”、“求精”;而“计算机”经过处理,变成两个字串“计算”、“算机”。最后,我们得到一个包含47 909个长度为两个汉字的准词汇表general_bigram。
定义1 如果tf(s,w)>1,那么词w 在报道s中的出现次数是频繁的。
定义2 如果dft(w)>2,那么词w在时刻t是频繁的。
定理1 如果wordin在文档s中是频繁的,公式(11)的分解保证了τi1τi2,…,τi,n-1τin的频繁性质。
证明:由Apriori性质证明,证明过程略。
定理2 在文档s中,如果τi1…τi,n-1,τi2…τin是频繁的,那么可以用它来生成1个长度为n的候选频繁串。
定理3 在文档s中,如果wordin是频繁的,那么按式(11)分解之后的二元串不会破坏wordin的n元频繁性,即wordin是可恢复的,且恢复后仍是频繁的。
定理4 在文档s中,对所有的长度大于2的频繁普通词按式(11)分解之后得到的二元串不会损失原有的词信息。
由于篇幅所限,我们省略了以上定理的证明。
3.2 地名词表
对于中国地名,我们收集了县、区以上的地名共2 834个,并对其进行了缩写处理。例如,“吉林省延边朝鲜族自治州”缩写为“延边”等,这样的特征更符合BBS发帖人的习惯。处理后得到的地名分布见表3。

表3 中国县级以上地名长度及其分布
由表3可以得知,中国90%以上的县级以上地名都可用两个汉字来标识。对于三字及以上地名,我们也将其拆分为二元串,经过处理后,得到了3 039个二元字串。
对于外国地名,我们收集了240个国家和地区及其首都的名称,长度及分布见表4。按式(11)分别拆分为二元串,得到了978个二元字串。
将中国地名二元字串及外国地名二元字串合并,最后得到一个包含3 981个二元字串的地名词表place_bigram。

表4 世界各国、首都地名长度及其分布
3.3 未登录词表
对于帖子标题,我们采用2-grams方法进行处理,以识别到gengeral_bigram、place_bigram 中未收录的地名、人名、组织机构名等未登录词,将其放入unknown_bigram中。
例1俄罗斯无法确认车臣匪首巴萨耶夫尸体
在例1里共有16个二元串,其中:俄罗、罗斯、无法、确认、匪首、尸体六个二元串可以由gengeral_bigram、place_bigram表确定为有意义的二元串。对于其他的二元串,可采用以下规则来修剪无意义的二元串。
R1对于字符串τi-2τi-1τiτi+1τi+2τi+3,如果τi-2τi-1、τi+2τi+3是有意 义的二 元串,而τi-1τi、τiτi+1、τi+1τi+2不能确定是否有意义,那么将τi-1τi、τi+1τi+2当作无意义的子串丢弃。
在例1里,斯无、法确、认车、首巴、臣匪、夫尸可用此规则修剪掉。最后可以得到以下四个未登录的二元串:车臣、巴萨、萨耶、耶夫。
R2如果未登录的二元串τiτi+1出现在楼主的帖子s1中,那么保留;否则,修剪。
由于帖子标题的长度有限,用此方法进行处理既不耗时,又可以识别潜在的有意义的词。
3.4 单字名词表
包括地名的简称表abbr_place、化学元素表chem_element等。
有了以上词表,我们就可以构造如图1所示的基于二元的准词汇抽取过程。与纯2-grams相比,本方法在抽取二元特征的过程中避开了大量的无意义的二元串,从而提高了算法的时间效率和空间效率。由于避免了复杂分词技术的使用,所以本特征抽取算法的时间效率要好于分词算法。所抽取到的特征接近分词程序(不会损失二字及二字以上的词信息)。

图1 基于二元的准词汇抽取过程
4 实验设置
4.1 数据集
由于没有规范的语料,项目组从复旦大学日月光华BBS站上下载了一部分帖子,共有9 397篇帖子,进行了实验。
4.2 评测
从漏检和误检两个角度进行评测,公式如下:

其中,PMiss和PFA分别表示系统的漏检率和误检率,漏检即为系统未识别出新话题,误检则是系统将旧话题的后续相关报道误判为新话题;CMiss和CFA分别代表漏检和误检的代价系数;Ptarget和Pnon-target是先验目标概率。检测错误代价CDet的规范化形式 Norm(CDet)如式(13)。
NIST面向TDT研究提供了可视化的评测工具,即检测错误权衡图(Detection Error Tradeoff,DET)。由于系统漏检与误检的概率越低,其性能越好,因此DET曲线越靠近坐标系的左下角代表系统性能更优。DET曲线上的最小规范化指标代表检测系统的最佳性能,简写为Min Norm(Cost)。

计算时,设CMiss=1,CFA=0.1;Ptarget=0.1①通常Ptarget设为0.02。在面向BBS的话题识别与跟踪中,主要识别当前热门讨论的话题,因而目标出现的概率较高,我们采用了常用的10~90原则,即经常出现的话题占10%,另外一些不常见的话题占90%。。
4.3 阈值设置
人工对9 397篇帖子中的两个话题:“黎巴嫩正式对以宣战”、“朝鲜拒绝安理会导弹问题决议”进行了标注。经过对这两个话题的识别与跟踪进行分析,发现t2设为0.2时效果较好。t2值太大,发现不了新的相关话题,即漏报率PMiss太大;t2太小,则引入过多的噪声,即误报率PFA太大。
相似度计算中的α与郑[6]一样,设置为0.5。
4.4 实验结果
4.4.1 模型比较
为了对本文所提的方法进行测试,我们设计并测试了三个系统。基线模型:实现了2.2节所介绍的基本模型;改进模型:实现了2.3节所介绍的改进的话题识别与跟踪过程;
权重调节:在改进模型的基础上,加入了zhang[10]所述的权重调节过程。
如图2所示,改进模型优于基线模型,而权重调节的改进模型又优于单纯的改进模型。
各模型的最小规范化代价为:
基线模型 Min(CDet)Norm=0.307 5
改进模型 Min(CDet)Norm=0.280 2
权重调节的改进模型

权重调节加改进模型较原来的基线系统上升了0.053 9。
4.4.2 特征比较
用纯2-grams提取到的特征中无意义的字串比较多,以GB 2312-80国家标准为例,两级字库中共包括6 763个汉字,它们的二元组合数为6 763×6 763=45 738 169,有四千五百多万。所以,用纯2-grams提取特征,其特征数会不断上升。本文提到的基于二元的准词汇抽取中,普通名词和地名合起来,只有51 890个词汇,所以普通词和地名合起来的上限就是51 890。基于二元的准词汇抽取中的无意义的词汇主要在标题的2-grams划分过程中引入,通常标题的信息都是有用词汇,所以在此引入的无意义词汇是非常有限的。图3显示了用纯2-grams方法、基于二元的准词汇抽取方法抽到的特征数。可以看到,随着帖子数的上升,纯2-grams的特征数上涨很快。

图2 面向BBS的DET图
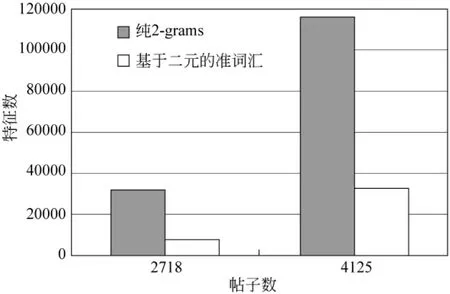
图3 不同特征抽取方法所抽到的特征数比较
4.4.3 时间比较
受抽取到的特征数的影响,由图4可以看到,随着帖子数的上升,纯2-grams的处理时间明显变慢,基于二元准词汇的处理时间变化不大。

图4 不同特征抽取方法的处理时间比较
用分词法取特征的实验数据是经过分词软件预处理的,无法与其他两个实验进行比较。由于BBS文档不规范,加工了近一周时间,才完成9 397篇语料的分词及词性标注。
5 讨论
在对现有的话题识别与跟踪方法进行研究的基础上,我们提出了三个面向BBS的话题识别与跟踪模型,实验结果显示,所提的模型可以较好地完成识别与跟踪任务。
在实现面向BBS的话题识别与跟踪系统过程中,我们的感受是语料太不规范。例如,有的人发表言论时,不使用标点符号,这就使得依赖于标点符号进行文本块分割的分词程序显得无能为力。所以,语料的规范是面向应用时首先需要解决的问题。
另外,BBS中有“挂羊头,卖狗肉”现象,看标题在说一件事情,但实际上内容与标题是不一致的,也是一种变相的“话题漂移”。怎么样识别同一标题下,内容不属同一话题的帖子,也是一个值得研究的问题。
[1]Yang Y,Carbonell J,Brown R,et al.Learning Approaches for Detecting and Tracking News Events[J].In IEEE Intelligent Systems Special Issue on Applications of Intelligent Information Retrieval,14(4),1999:32-43.
[2]J.Allan,R.Papka,V.Lavrenko.On-line New Event Detection and Tracking [C]//Proceedings of SIGIR'98.University of Massachussetts:Amherst,1998,37-45.
[3]M.Franz,J. S. McCarley. Unsupervised and supervised clustering for topic tracking [C]//Proceedings of the 24th annual international ACM SIGIR,New Orleans,Louisiana,USA:ACM,2001:310-317.
[4]Y.Lo,J.L.Gauvain.The LIMSI Topic Tracking System for TDT 2002 [C]//Topic Detection and Tracking Workshop,Gaithersburg,USA,2002.
[5]王会珍,朱靖波,季铎,等.基于反馈学习自适应的中文话题跟踪[J].中文信息学报,2006,20(3):92-98.
[6]郑伟,张宇,邹博伟,等.基于相关性模型的中文话题跟踪研究[C]//全国第九届计算语言学学术会议,2007:558-563.
[7]张辉,周敬民,王亮,等.基于三维文档向量的自适应话题追踪器模型[J].中文信息学报,2010,24(5):70-76.
[8]G.Kumaran,J.Allan.Text classification and named entities for new event detection [C]//Proceedings of the SIGIR Conference on Research and Development in Information Retrieval.Sheffield,South Yorkshire:ACM,2004:297-304.
[9]Y.Yang,J.Carbonell,etc.Topic-conditioned novelty detection [C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2002:688-693.
[10]Zhang Kuo,Li Juan Zi, Wu Gang.New Event Detection Based on Indexing-tree and Named Entity[C]//Proceedings of the SIGIR 2007, ACM:Amsterdam,2007:215-222.
[11]陈友,程学旗,杨森,等.面向网络论坛的突发话题发现[J].中文信息学报,2010,24(3):29-36.
[12]X.Zhang,T.Wang.Topic Tracking with Dynamic Topic Model and Topic-based Weighting Method[J].Journal of Sofware,2010,5(5):482-489.
[13]陈友,程学旗,杨森,等.面向网络论坛的高质量主题发现[J].软件学报,2011,22(8):1785-1804.
[14]周水庚,关佶红,俞红奇,等.基于N-gram信息的中文文档分类研究[J].中文信息学报,2001,15(1):34-39.
[15]周水庚,关佶红,胡运发,等.一个无需词典支持和切词处理的中文文档分类系统[J].计算机研究与发展,2001,38(7):839-844.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
小雪花·成长指南(2016年11期)2016-12-07 06:14:37
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
河南科技(2014年15期)2014-02-27 14:12:51
电脑迷(2012年4期)2012-04-29 06:12:13
女性天地(2012年11期)2012-04-29 00:44:03
