
基于隐最大熵原理的汉语词义消歧方法
2012-06-29 03:54:18张仰森黄改娟苏文杰
中文信息学报 2012年3期
张仰森,黄改娟,苏文杰
(北京信息科技大学 智能信息处理研究所,北京 100192)
1 引言
汉语词汇中的多义词始终是自然语言理解中难以处理的问题,多年以来,关于汉语词汇的语义消歧研究一直是中文信息处理领域的研究热点。词义消歧从研究方法上讲主要有基于规则的方法、基于词典知识的方法、有指导的统计消歧法、无指导的统计消歧法[1]。其中有指导的统计词义消歧法是目前WSD领域的主流,它将词义消歧问题作为分类问题来考虑,将机器学习领域里广泛流行的算法用于词义消歧,包括决策树(Decision Tree)方法(Black,1988)[2]、决策表(Decision List)方法(Yarowsky)[3]、Naïve Bayes方法[4]、向量空间模型(VSM)[5]、最大熵方法(Maximum Entropy)[6-7]、神经网络模型[8]、基于实例的方法[9]等。其中,最大熵方法由于可以将多种上下文特征集于统一的模型框架之中,词义消歧效果比较好,受到学界的广泛应用。最大熵模型与n-gram模型相比,能够获取和使用自然语言多个方面的信息特征,将多种特征信息集成于一个模型之中,与朴素贝叶斯模型、决策树等统计语言建模方法相比,有无需独立性假设及自动特征权重确定的优点。但其主要缺点是只能处理显性统计特征信息,对那些自然语言中经常遇到的语义和句法信息无法进行处理。
为了将自然语言中人们不能直接观察到的隐性特征,如语义信息或语法结构引入最大熵方法中,本文提出基于隐最大熵原理的词义消歧方法,将语义搭配特征等隐性特征与显性统计特征等一同引入一体化的指数性概率框架模型之中,以提高汉语词汇的语义消歧正确率。
2 隐最大熵原理
在最大熵方法中,由于使用的是显性统计特征,因此,在进行模型参数估计时,可以使用最大似然估计法来计算训练语料中的概率分布,对模型参数进行估计。然而,对于真实的自然语言来说,除了词语、词性标注等显性统计特征以外,还有句法和语义特征,如何将句法语义特征融入最大熵模型以提高模型的效率,shaojun wang等于2002年提出了隐最大熵原理[10],提出了将句法语义信息融入模型的方法。
设X∈Φ是概率为p(X)的完全数据,Φ为一自然语言,Y∈Ψ是可观察的非完全数据,Ψ表示词、句、文档等,并且Y=Y(X)是一个从Φ到Ψ的多对一映射,丢失的数据在文档级为语义内容,在语句级为句法结构,如图1所示。

图1 语言信息结构表示
图1中表示自然语言可观察的不完全数据是词、句、文档,丢失数据语句级是语法结构,文档级是语义内容,图中黑节点表示丢失的信息。
设P(Y)表示Y的概率,P(X|Y)为给定Y条件下的X的条件概率。则:

这里,Φ(Y)={X:X∈Φ,Y(X)=Y},并且p(X)=p(Y)p(X|Y)具有隐变量的最大熵原理的问题是从一组允许的概率分布中选择一个模型p,使其具有最大的熵:

(1)
服从

(2)
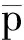
对隐变量没有约束,最大熵的解将把相等的概率分配到各隐变量上去,如果没有丢失数据,则问题将被简化为Jaynes模型,因此,式(2)比ME具有更一般的描述。
3 特征表示与特征提取
随机过程的输出与上下文信息x有关,但在建立语言模型时,如果考虑所有与y同现的上下文信息,则建立的语言模型会很繁琐,而且从语言学的知识上来讲,也不可能所有的上下文信息都与输出有关。所以在构造模型时,只要从上下文信息中选出与输出相关的信息即可,称这些对输出有用的信息为特征。
特征表示由两部分构成,一部分是目标类的上下文语境x,另一部分是目标类y。为了让模型能够理解特征,可以使用特征函数来表示(x,y)的特性。定义一个{0,1}域上的二值函数来表示特征:
(3)
特征的选择与提取可通过特征模板的方法来实现,在设计模板时可将影响多义词词义的上下文距离信息以及特定位置上的词性信息考虑进来。一般考虑的因素有:(1)特征类型,包括词形(Word)、词性(Pos)、词形+词性; (2)窗口大小,包括语句中当前词前后的n个词;词形特征表示使用Word+Index的形式, 词性特征表示法与词形类似。这里Word用字母W表示,Index为特征词相对于当前词的位置。本文中所设计的特征模板如表1所示。依据特征模板进行特征提取过程如算法1所示。

表1 特征模板设计
算法1特征提取算法
Step1: 从第一句开始扫描语料库;
Step2: 循环特征模板中的特征列表,利用当前模板开始匹配特征并进行提取,命名为feature;
Step3: 查看特征文件中feature是否存在,如果已经存在,特征数目加1,转到Step2;如果不存在,将feature写入特征文件,转到Step2;
Step4: 是否扫描到语料库结尾,如果是,结束;否则,转到Step1继续扫描。
利用特征模板所得到的候选特征集合比较大,需要采用特征筛选方法从中筛选出对输出影响较大的特征。本文采用特征频次和互信息相互结合的特征选择方法进行特征筛选。
(1) 特征频次筛选法。特征频次筛选法就是计算特征集中每个特征出现的次数,并根据实验需求设定一个阈值,把出现次数较少的特征舍弃[11]。
(2) 互信息选择法。互信息是用来衡量两个变量之间的相关度的量[12]。词义消歧中可以使用互信息来表示特征词与多义词之间的相对语义距离。计算公式如下:
(4)
P(w1)、P(w2)和P(w1,w2)分别是词语在语料库中出现的概率和共现概率。根据计算结果,选择满足一定互信息要求的特征。
4 基于义原搭配信息的文本隐性特征提取
利用上述设计的特征模板提取的上下文特征属于显性统计特征,是比较容易获取的,如果上下文的窗口宽度选择的比较大的话,其特征数量将是相当大的,参数空间也会非常大,使建模的工作量增大。所抽取的特征反映的是上下文中词语与当前词之间的词语搭配特征,而更深一层次的语义特征被忽略了。借助《知网》,词语搭配之间更抽象一层关系能够被抽取出来,这就是义原搭配信息[13]。为了避免算法过于复杂,本文只考虑从动宾结构中抽取义原搭配特征。将动宾结构中的两个词语之间的二元搭配组合转变为多个义原之间相互制约的多元组合。这样就丰富了文本特征所涵盖的语义信息。
表2中给出了义原搭配的例子。多义动词为“吃”,可能的宾语为“老本”、“利息”、“面包”、“饭”、“汽油”等。在传统最大熵模型中,这些搭配信息都会被考虑到。但如果借助《知网》,就能够抽取出义原搭配的信息,获取到语义搭配特征。表2中词义ID是表示当前多义动词“吃”的义项编号。表中第三列和第四列分别是从《知网》中抽取出来的动词和宾语的义原信息。这种义原信息可以反映出上下文的语义搭配特征,大大减少最大熵模型的特征数量,缩小参数空间,优势是显而易见的。

表2 义原搭配示例
义原搭配信息能够表征语义特征,但如何获取和存储语义搭配特征就成为关键。下面以动宾结构短语为例,给出获取和构建义原搭配信息数据库的方法,如算法2所示。在本算法中暂不考虑动宾结构中动词和名词均为多义词的情况。
算法2义原搭配信息数据库的构建算法
Step1: 从训练语料中抽取动宾结构搭配词语,作为义原搭配信息抽取的对象。
Step2: 在《知网》知识库中查找动词条目。以“展开”为例,查找“W_C=展开”,若存在,判断词性是否为动词,即G_C的值是否以“V”开始,若是,则跳到下一步;若不是,则返回step2继续查找;若文件结束,则返回。
Step3: 在“DEF”中读取动词概念中的第一义原,记作Verb_DEF。如果动词在《知网》知识库中具有多个概念,则抽取训练语料中与动词所标注词义相一致的概念所在的义原。
Step4: 在《知网》知识库中查找名词条目。以“地图”为例,查找“W_C=地图”,若存在,判断其词性是否为名词,即G_C的值是否以“N”开始,若是,则执行下一步;若不是,则继续执行查找;若文件结束,则返回。
Step5: 在“DEF”中读取名词概念中的第一义原、领域义原和主体义原,分别记作Nouns_Sememe_First,Nouns_Sememe_Domain,Nouns_Sememe_Host。如果领域义原或主体义原不存在,则赋值空串。
Step6: 更新数据库操作。将step2和step5中所抽取的信息插入到数据库中。
Step7: 如果还存在未处理的动宾结构搭配词语跳转step2,否则,结束。
生成的义原搭配信息将被存储于MySQL数据库中。数据库建立完成之后,义原搭配信息在数据库中存储形式如图2所示。其中第三列(Verb_Word)为多义动词原型;第五列(Feature_Verb_Sememe)为多义动词的义原信息;第六列(Feature_Nouns_Sememe)为多义动词的义原搭配信息;最后一列(Sence_ID)为动词的义项标示。将最后两列按照一定的格式,输出到文本文件中,就可以作为隐性特征供词义消歧模型来使用。
图2 数据库中的义原搭配信息
5 基于隐最大熵原理的词义消歧实现
最大熵模型的缺点是它只考虑了目标词所在上下文中的显性特征[14]。隐最大熵模型是在最大熵模型基础上考虑了隐性特征,将显性特征和隐性特征相结合应用于消歧模型。本文通过《知网》从词语搭配中所获取义原搭配是一种语义搭配特征,它将最大熵模型的特征空间变成了语义类的特征空间,从而使参数空间大大缩小,提高了最大熵参数估计算法的效率和词义消歧的准确率。
本文设计并实现了一个词义消歧实验系统。它把系统分成了三个大的部分:训练模块、测试模块、评价模块。本实验采用OpenNLP MaxEnt[15]提供的以Java程序编写的最大熵模型参数计算开源代码,参数计算算法为GIS。词义消歧系统的总体设计框架如图3所示。
机器学习模块主要包括文本预处理、特征提取、模型参数计算等操作。文本预处理主要的功能是去除停用词和非法字符等。特征提取包括显性特征提取和隐性特征提取。显性特征依据算法1按照所设计的特征提取模板来实现,隐性特征的提取则依据《知网》,依据算法2实现。模型参数的训练使用隐最大熵原理来实现,输出的模型参数信息将保存在文本文件中供下一步中的预测模块来使用。

图3 基于隐最大熵的词义消歧系统的总体设计框架图
词义消歧模块用来对待消歧的文本进行词义消歧。本模块中文本预处理过程与机器学习模块相同。特征提取模块提取多义动词所在上下文的特征词语,用频次和互信息相结合的方法来进行特征筛选,同时提取该多义动词的宾语,并获取机器学习模块所获得的义原搭配信息,最后根据模型参数与所选特征,计算出该多义动词的可能词义。
结果评测模块是通过将机器标注的语料与人工标注的语料进行比较,对词义标注模型与算法的性能进行评价。
6 实验结果与分析
6.1 系统实现工具与实验语料的选择
Java语言和Eclipse是目前的强势语言和开发环境之一,从系统的可移植性以及人才培养的角度考虑,本课题选择的开发语言为Java,开发环境为Eclipse。数据库使用MySQL3.5版本。数据库设计工具使用MySQL Workbench5.0。
我们选取了由北京大学计算语言所开发的粗粒度词义标注语料库。该语料库是在北京大学与富士通公司共同制作的2000年《人民日报》基本标注语料库的基础上,以《现代汉语语法信息词典》和《现代汉语语义词典》为依据,经过机器粗标再经过人工校对而完成的词义标注语料库,在国内外具有较大影响。本实验选用2000年11和12月的词义标注语料库开展研究,其中50天的语料作为模型参数训练语料,剩下十天语料作为测试与评测语料。
另外,所选择的《人民日报》粗粒度词义标注语料是以《现代汉语语法信息词典》和《现代汉语语义词典》的体系为依据构建而成,而我们在进行隐性信息提取时所采用的语义类是以《知网》中的义原为依据。尽管两个知识资源的标注体系不同,但本文在应用它们时并不会引起矛盾。我们的词义标注体系采用与北京大学计算语言所《人民日报》词义标注语料相同的体系,对于《知网》的应用主要采用其“义原”的思想将多义词上下文语境中的特征词映射为语义类,这样就将字词级特征空间转换为语义类特征空间,使得参数训练的规模大大缩小。所以,《知网》主要应用在特征的提取方面,使得一些的隐性的语义类特征能够被提取出来,以提高标注模型的通用性和正确率。
为了使实验简单,我们从确定的语料中选取十个多义动词进行实验。选取目标多义词的原则如下:
(1) 目标词应当具有多于一个词义;
(2) 应当选取出现次数较多的动词,一般来说,出现的次数越多越好;
(3) 多义词的某一词义在所有词义中所占的比重不应当太大。例如,某个动词有三个词义,而其中一个词义所占比重达到90%,其他两个词义总共占10%,剩余两个词义的区分将变得十分困难。选定的多义动词及其在语料中出现的次数如表3所示。

表3 多义词表

续表
所选动词的词义数目为2、3、4,在统计词义的过程中,我们发现,所用的北大《人民日报》基本标注语料库的义项数与《知网》中所列义项数并不完全一致。我们以《人民日报》语料所标的义项为准。
6.2 实验结果与分析
系统采用准确率、召回率和F值对实验结果进行评测。对测试语料去除义项标注后,进行义项标注的测试。实验结果按未使用义原搭配信息和使用义原搭配信息来进行分类。实验系统运行结果如表4所示。
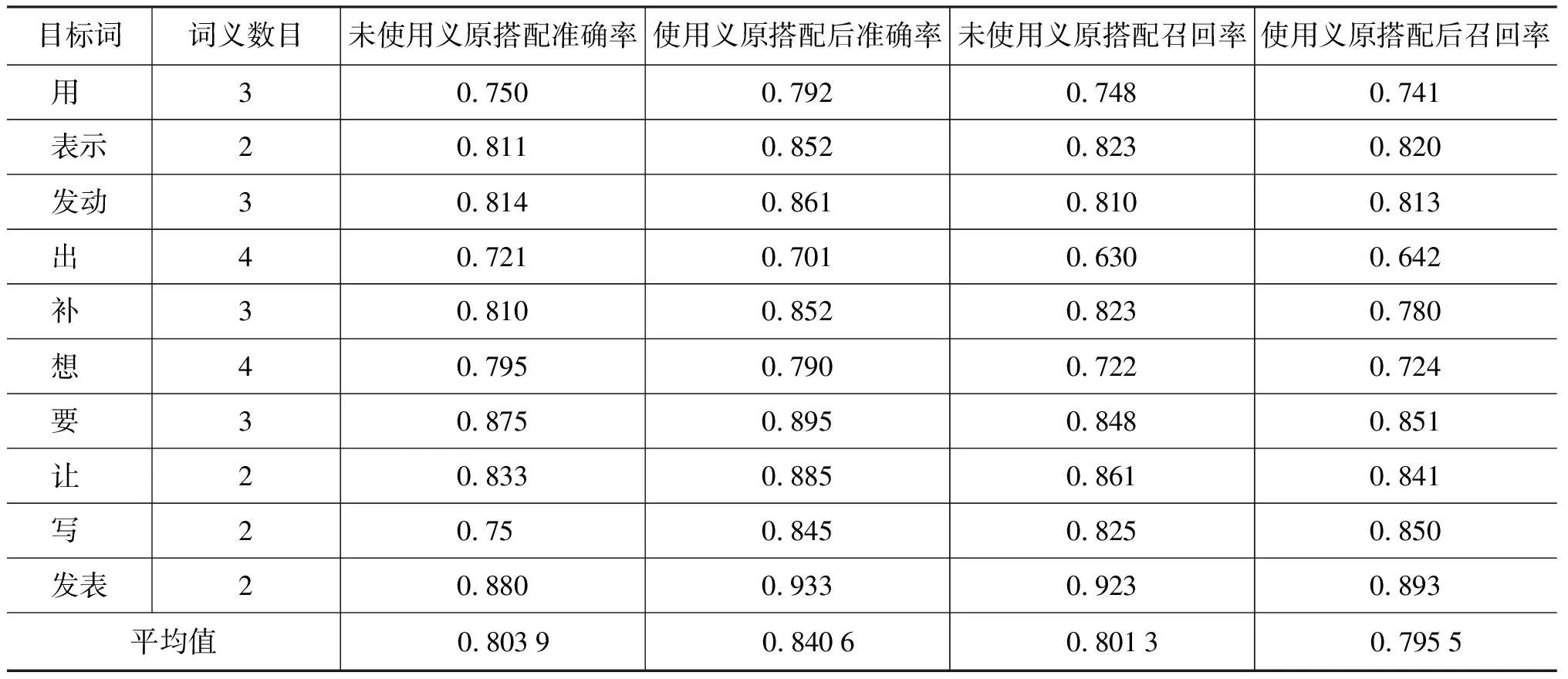
表4 多义动词消歧结果
上面的表格显示出不同多义词在使用义原搭配信息和不使用义原搭配信息情况下的准确率对比。从表4中可以看出。
(1) 使用义原搭配隐性特征后,系统词义消歧的平均准确率为84.06%,比未使用义原搭配信息前提高了大约4个百分点。
(2) 系统对义项数目较少的多义词,消歧结果较好,例如,“发表”、“表示”,“发动”等,而当多义词义项数目较多时,消歧的结果稍差。分析原因主要有两点:a)对于某些词,如“发表”,在《人民日报》的语料中有其固定的搭配。《人民日报》不是小说,一些拟人、虚构等手法在《人民日报》中并不会出现。《人民日报》语料中更多的是关于政治、事实的报道,一些固定搭配可能对词义消歧产生较大影响。例如:
例句①:表示/v!1 亲切/a 的/ud 问候/vn !/wt
例句②:按照/p “/wyz 三/m 个/qe 代表/v!2 ”/wyy 的/ud 要求/n
对于例句①和例句②中“表示”、“代表”的消歧,固定搭配将会起到关键性作用; b)当多义词义项数目较多,而在训练集或测试集中出现的次数较少时,由于语料的不充分造成的准确率不高。
(3) 有少量词在使用义原搭配信息后并未呈现出较好的结果,例如,“出”、“想”,分析其原因,可能的因素有两个方面:一是多义词在语料中出现的次数较少造成的;二是可能多义词词义较多,系统抽取义原搭配信息的结果会导致其中某两个词义或多个词义出现义原搭配相同或相似的情况,对词义消歧产生混淆作用,从而导致消歧的准确率下降。
[1] 张仰森.面向语言资源建设的汉语词义消歧与标注方法研究[D]. 北京大学博士后研究工作报告. 2006.12.
[2] Black, Ezra. An Experiment in Computational Discrimination of English Word Sense[J]. IBM Journal of Research and Development, 1988, 32(2): 185-194.
[3] Yarowsky, D. Decision Lists for Lexical Ambiguity Resolution: Appliaction to Accent Restoration in Spanish and French[C]// Proceedings of the 32th Annual Meeting of ACL. 1994.
[4] Escudero G, Marquez L , et al. Naive Bayes and examplar-based approaches to word sense disambiguation revisited[C]// Proceedings of the 14th Europear Conference on Artificial Intelligence (ECAI) , 2000.
[5] Schutze, H. Automatic word sense discrimination. Computational Linguistics[J]. 1998,24(1):97-124.
[6] Adam L.Berger, Stephen A. Della Pietra, Vincent J.Della Pietra. A Maximum Entropy Approach to Natural Language Processing[J]. Computational Linguistics, 1996, 22(1): 1-36.
[7] Gerald Chao, Michael G.Dyer, Maximum Entropy Models for Word Sense Disambiguation[C]// Proceeding of COLING 2002 1: 155-161.
[8] Kawamoto, A.H. Distributed representations of ambiguous words and their resolution in a connectionist network[C]// Proceeding of Small, S., ed.Lexical Ambiguity Resolution: Perspectives from Psycholinguistics, Neuropsychology, and Artificial Intelligence. San Mateo, CA:Morgan Kaufman, 1998: 195-228.
[9] Ng, H.T. Exemplar-Based word sense disambiguation: some recent improvements[C]// Proceeding of Johnson, M., Allegrini, P., eds. Proceedings of the 2nd Conference on Empirical Methods in Natural Language Processing. Providence, Rhode Island, 1997: 208-213.
[10] Shaojun Wang, Dale Schuurmans, Yunxin Zhao. The Latent Maximum Entropy Principle[C]// Proceeding of IEEE International Symposium on Information Theory, 2002:182-185.
[11] 代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,18(1):26-32.
[12] 王国胤,于洪,杨大春.基于条件信息熵的决策表约简[J].计算机学报,2002,25(7):759-766.
[13] 郭充, 张仰森. 基于《知网》义原搭配的中文文本语义级自动查错研究[J], 计算机工程与设计, 2010.9,31(17):3924-3928.
[14] 张仰森.基于最大熵模型的汉语词义消歧与标注方法[J].计算机工程,2009,(9):15-18.
[15] http://maxent.sourceforge.net[OL].
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
作文大王·低年级(2021年9期)2021-09-10 20:54:28
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
西夏研究(2020年1期)2020-04-01 11:54:26
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
电脑与电信(2018年12期)2018-03-23 02:37:20
湖北经济学院学报·人文社科版(2015年10期)2015-12-29 05:53:16
陕西学前师范学院学报(2015年4期)2015-12-25 06:33:18
语言与翻译(2014年3期)2014-07-12 10:31:59
中文信息学报(2012年4期)2012-06-29 06:29:14
