
基于词典信息的先秦汉语全文词义标注方法研究
2012-06-29 03:54张颖杰陈家骏陈小荷
中文信息学报 2012年3期
张颖杰,李 斌,,陈家骏,陈小荷
(1. 南京大学 计算机软件新技术国家重点实验室,江苏 南京 210093;2. 南京师范大学 语言信息科技研究中心,江苏 南京 210097)
1 引言
词义消歧(Word Sense Disambiguation, WSD)是在特定的上下文中为指定的词自动选择合适词义的过程,也称为自动词义标注。在主流的词义消歧方法中,有指导方法的效果最好[1],但需要较大的人工标注数据集,并且其结果对训练数据集有很强的依赖性,泛化能力较差。相对而言,基于知识的方法,将词语在词典中的义项数作为类别数,将词典对词语的解释和例句作为义项出现的语境信息,虽然受限于词典规模,其效果通常不如有指导的方法,但是在一定程度上减少了对人工标记数据的依赖性,义项标注的覆盖率较高,在缺乏人工标注数据集的情况下,可以提供初始的自动标注结果。
目前,古汉语的词义自动标注工作还处于起步阶段,在资源和技术上都呈稀缺状态。对于经典传世之作,虽有历代学者的大量注疏,但这些注疏并不是在同一个释义词典或语义体系的基础上进行的。目前较为实用的、能够服务于古汉语文献词义标注的词典是《汉语大词典2.0》(后文简称为《大词典》)[2]。该词典收词目30余万条,给出了词语的古今义项和最早用例,是一本质量高、释义丰富的大型语文词典。文献[3]介绍了采用《大词典》为主要的释义词典,人工逐词标注古籍义项以构建中古汉语研究型语料库的工作,工作量特别巨大。因此,研究古汉语义项的自动标注方法,已经成为了中国古典文学和文献研究的重要而迫切的需求。
对于缺乏训练数据的古汉语的词义标注来说,有指导的方法难以直接使用。在本文中,我们利用词典信息作为知识来源,采用了基于半指导方法的全文词义标注方法,对《左传》进行了标注实验,人工抽样的统计结果显示,该方法的平均准确率远高于系统基线,能够在古汉语全文词义标注的起步阶段提供初始结果,为人工标注词语义项提供良好的数据底本。
本文后续部分结构如下,第二节介绍了古汉语词义标注的相关研究;第三节介绍了本文使用的全文词义标注方法;第四节说明了实验的设计和结果分析;第五节给出了我们的结论及后续的研究工作。
2 相关研究
目前在古汉语的义项标注方面研究较少。文献[4]首先分析了古汉语词义义项的分布情况与特点,考察了词义消歧的难点。然后在现有的词义消歧理论和方法的基础上,基于条件随机场,选择上下文的词及其词性的复合特征,并加入其他语言学特征,设计6个不同的模板,对“將”、“如”等7个古汉语高频词进行了词义消歧实验,平均F值达到了83.04%。不过,该方法使用的词典是《春秋左传词典》,不适用于其他先秦语料的词义标注,缺乏一般性。因为文献[4]采用的是有指导方法,需要预标注大量训练样本,代价太高,泛化能力有限。
对于任意语言的词义标注,最简单的基于词典的方法是通过计算目标词的定义及其所在的上下文之间重叠的词数来确定词义[5]。
scoreLeskVar(S)=|context(w)∩gloss(S)|
S表示某个特定的词义,w为待标注的词,context(w)表示w所在的上下文,gloss(S)为词义的定义。这种方法主要局限在于词典中的定义通常比较简洁,未必能包含足够的能标识当前词义的词汇[6]。
随着包含分类和语义关系的本体词典的广泛使用(如WordNet),基于词典的WSD研究中也出现了依赖于这些词典中结构化信息的结构化方法,主要有基于相似度计算的方法[7]和基于图的方法[8-9]两类。基于相似度计算的方法比较目标词的各个词义与文本中其他词之间的语义相似度,从中选择使得下式结果最高的词义。
基于图的方法通常把全文表示成一个以词义为结点、语义关系为边的图结构,通过随机游走等方法确定节点的得分,从而得到最终的词义。近年来针对英语或现代汉语的全文标注主要就用了这一类的方法。
然而,对于古汉语这一特殊的应用领域,很难使用结构化方法。首先,古汉语的结构化词典资源缺乏。在汉语中运用广泛的《同义词词林》和HowNet中的概念描写和分类主要针对现代汉语,由于古今异义等原因,无法直接用来计算古汉语词语间的相似度。其次,结构化方法通常严格的遵守一个前提,即“一段一义”[9],用来构成图的段落中相同的词最后将会被标注上同一个词义。但是古汉语词类活用现象比较频繁,同样的词在同一段落中表现出多种不同的词义是常见的现象,一般来讲很难满足这样的前提。
考虑到以上问题,本文利用现有的古汉语词典资源,采用了一种半指导方法,对大量的古汉语语料实现了全文词义标注,对其性能进行抽样验证和分析。
3 半指导的WSD方法
本文的半指导方法沿用了文献[9]提出的一种通过极少量人工标注语料来进行大量词义标注的方法,并根据古汉语特点和《大词典》释义方式进行了调整和优化。
3.1 Yarowsky的方法
在Yarowsky的研究要求每个词只有两个义项[10]。该方法首先对每一个需要标注词义的二义词建立上下文列表U。其次,对该词的每个可能词义,手动标记一个包含典型搭配信息的可信小训练集seed,根据“一个搭配一种含义”的先决条件给出表示搭配信息的决策表。该可信小训练集对于每个含义只包含了一种搭配情况。再次,在seed上训练决策表分类模型,并将其用于待标注集的分类,将所有概率超过既定阈值的结果增加到seed中,同时根据“一段一义”的约束条件扩充seed,剩余用例仍作为待标注集用于下一次的迭代。重复此过程至结果收敛,即所有未标注用例的分类结果概率均在阈值以下。最后,为剩余用例标注结果。
具体流程可表示如图1。
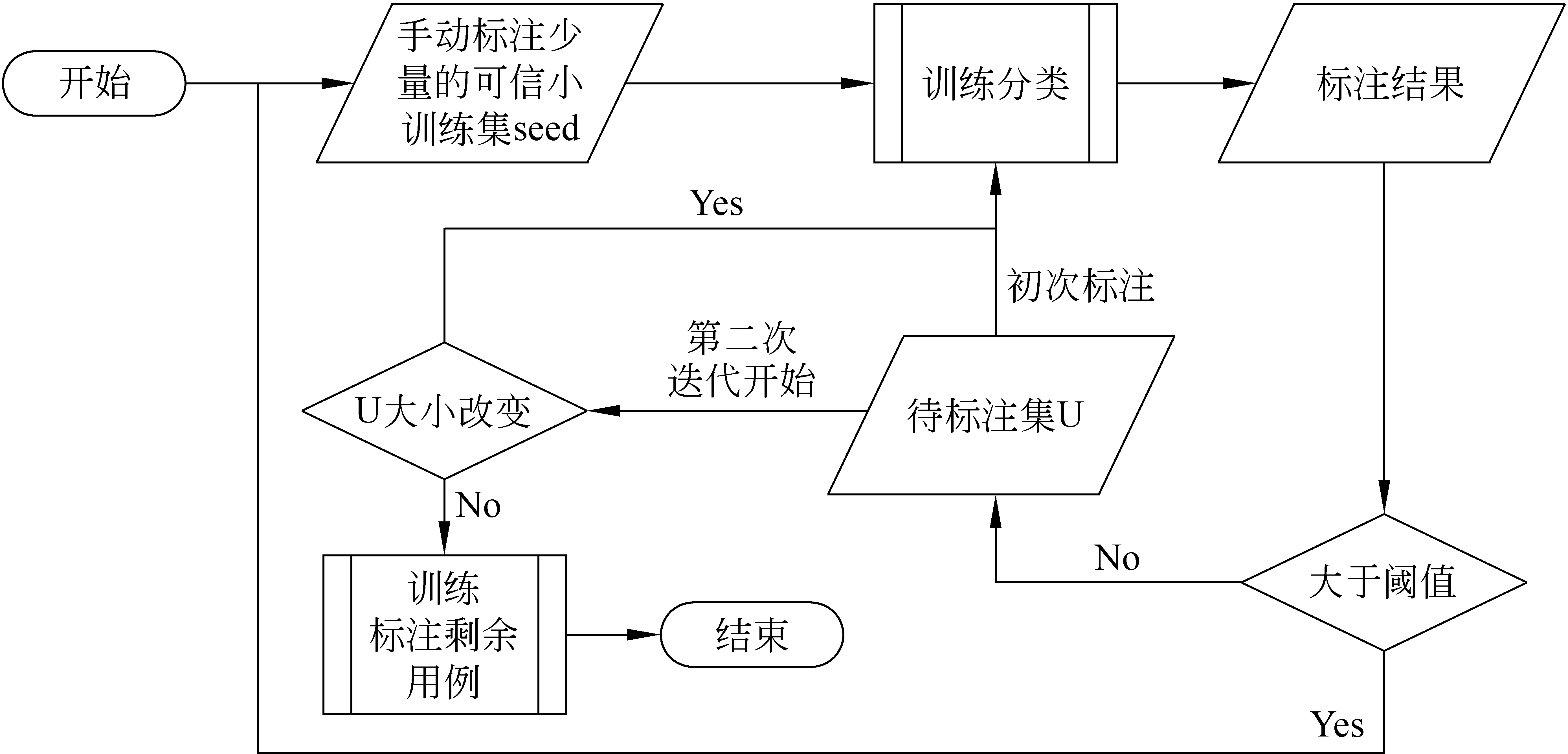
图1 Yarowsky方法的流程图
3.2 改进的半指导词义标注方法
在本文中针对古汉语全文词义标注需要考虑的下述多个方面,对Yarowsky的方法作出一定的改进,使之适用于古汉语这一特殊应用对象和《大词典》的释义方式。
(1) 词义粒度。本文中待标注词的词义不只两项,而是根据词典中的义项来确定。词典中凡是具有来自先秦文献的例句的义项,均被用来作为词义集合的一个元素。
(2) 特征选择。这里不止采用一种搭配信息,而是选取了词形、词性的一元特征和两者搭配的二元特征,如表1所示。有研究表明,二元特征窗口增大反而降低词性标注结果的准确性[4],因此对于二元特征,仅使用前后大小为1的窗口。

表1:特征选择
由于“一段一义”的约束条件并不完全适用于古汉语,尤其对一些义项较多、应用情况灵活的高频词。因此,本文降低其强制性,仅将待标注词所在的段落编号作为一个特征进行考虑。
(3) 可信小训练集的选取。本文中不使用手动标注的方式,而是根据词典信息自动得到。由于古汉语词典中的释义通常用现代汉语表示,两者的上下文在形式和内容上差别较大,不能直接使用。而词典中除了释义外通常还包含一些例句,这些例句一般都具有典型性,且能保证其与词义对应的准确性,故而我们通过这些例句得到标注之初所需的seed。
(4) 迭代过程。在Yarowsky的方法中每次迭代的过程都将所有高于阈值的分类结果加入seed中。而本文在每一轮分类结束后仅加入概率最大且大于阈值的结果用于下一轮分类。对于迭代过程的终止条件则分别考察设阈值和不设阈值(即阈值为0)两种情况对结果的影响。
(5) 方法选择。由于本文中所用的特征不再是单一的搭配信息,故而也不再使用简单的决策表,而改用了SVM的方法,其核函数使用了默认的线性核[11]。
4 实验4.1 数据来源
本文将人工完成了分词和词性标注的18万字《左传》作为实验语料[12],对其中的4 671个实词共11万个词例进行了词义标注。这些实词中有635个多音词,占待标注词的13.6%。
知识来源采用了《大词典》,该词典对词的释义中涵盖了从古至今所出现过的几乎所有词义,并给出了词典编纂者认定的词义最早的文献出处及例句。
以“忘”为例,其在词典中第一个读音的释义如图2所示。
忘1 [wànɡ ㄨㄤˋ]
[《廣韻》巫放切,去漾,微。]
1.忘记;不记得。《诗·小雅·隰桑》:“中心藏之,何日忘之。”《司马法·仁本》:“天下雖安,忘戰必危。” 宋 曾巩 《尚书都官员外郎陈君墓志铭》:“ 泉州 歲凶,君築室止窮民,飢者給食,病者給醫,人忘其窮。” 周恩来 《致柯棣华大夫家属的慰问信》:“我们受惠于他的极多,使我们永不能忘。”2.指健忘症。《列子·周穆王》:“ 宋 陽里華子 中年病忘。”3.遗弃;不顾念。《诗·秦风·晨风》:“如何,如何!忘我實多。” 马瑞辰 通释:“忘我實多,猶云棄我實甚。”《庄子·山木》:“覩一蟬,方得美蔭而忘其身;螳蜋執翳而搏之,見得而忘其形。”《後汉书·宋弘传》:“貧賤之知不可忘。”4.玩忽,怠忽。《史记·孔子世家》:“昔 武王 克 商 ,道通九夷百蠻,使各以其方賄來貢,無使忘職業。” 唐 韩愈 《潮州祭神文》之四:“惟神之恩,夙夜不敢忘怠。”5.无。《史记·孟尝君列传》:“日暮之後,過市朝者掉臂而不顧。非好朝而惡暮,所期物忘其中。” 司马贞 索隐:“忘者,無也。其中,市朝之中。言日暮物盡,故掉臂不顧也。”《史记·平津侯主父列传》:“ 高皇帝 蓋悔之甚,乃使 劉敬 往結和親之約,然後天下忘干戈之事。”6.通“ 妄 ”。《老子》:“不知常,忘作,凶。” 朱谦之 校释:“忘、妄古通。”《韩非子·解老》:“前識者,無緣而忘意度也。” 王先慎 集解:“忘與妄通。”
注:下划线的内容表示出处,根据出处就可以得到例句出现的年代
图2 “忘”的第一个读音在《大词典》中的释义表示
4.2 实验预处理
(1) 根据年代筛选义项。由于《大词典》收录的义项非常丰富,每个词语的义项往往多达数十条,这对于词义自动消歧是非常困难的,因此需要对义项和例句进行年代的筛选。考虑到先秦时代时期较长、词义也无法完全由《大词典》的《左传》出处涵盖。我们根据60多种先秦文献的名称(如《左传》、《论语》等)对义项进行时代筛选,保证了用于标注的义项均有可能出现在先秦文献中,剔除了大部分不可能出现的词义。筛选后的义项被称为该词的先秦义项。如图2所示:“忘1”的第四个释义“玩忽”和第五个释义“无”最初都是在汉代的《史记》中出现的,故这两个义项不包含在我们要分类的义项列表中。而第一个释义“忘记”的例句除了来自于先秦文献《诗经》和《司马法》以外,还有的选自宋代和现代的文章,本文中所用的上下文信息仅从前两者中提取。
(2) 词典例句的词性标注。为了得到最初的种子训练集,实验利用南京师范大学开发的先秦古汉语的词性标注工具[3]对这些例句进行分词和词性标注,该工具在左传上的分词和词性标注F值均超过90%。然后通过词典中给出的拼音和释义信息,得到用于训练的上下文特征。由于这些上下文特征来自于词典中的例句,因而此种子训练集的标注结果是可信的,其特征也具有典型性,保证了它对词义标注的指示作用。
4.3 词义标注
汉语中包含了很多的多音词,同一个词的不同读音含义差别较大,甚至有时可以看作两个不同的词来处理。因此本文在标注过程中针对多音词分别使用“直接标注词义”和“先标音再标义”两种标注方法,来考察区分读音对古汉语词义自动标注效果的影响。
(1) 直接标注词义(Tag Sense Straightly, TSS)
根据词典得到待标注词的词义列表{senseik},i=1,2,…,n,k=1,2,…,ni,N=∑ni,n为拼音的数目,ni为拼音i下的义项数目,N为待标注词的总义项数。执行图3的过程,最终为中的所有条目标上词义。
(2) 先标音再标义(Tag Pinyin before Sense, TPBS)
首先自动标注读音。根据词典得到待标注词的读音列表{Pi},i=1,2,…,n,n为读音的数目。执行图3的过程,为S中的所有条目标上拼音Pi。
然后根据读音的标注结果将原待标注集S分块成为S1,S2,…,Sn,n表示该目标词拼音的数目,同一个分块Si中的目标词都具有相同的读音。同样原可信训练集seed也根据读音分类成为seed1,seed2,…,seedn。
最后自动标注词义。针对每个Si,根据seedi再次执行图3的过程,得到最终的词义标注结果senseik,i=1,2,…,n,k=1,2,…,ni,n为读音的数目,ni为读音Pi中义项的数目。

图3 本文中半指导学习的流程图
4.4 实验基线的设定(baseline)
本文中设定了两条基线用于对比实验结果。由于《大词典》中是将常用的读音排在前面,而第一个释义通常是该词的本意或常用义,因此本文将目标词根据年代筛选释义后的第一个读音的第一个词义和第二个词义分别作为标注结果的baseline1和baseline2。
4.5 实验结果及分析
自动标注完成后,由于标注数据量大,且对于这些数据原先并不存在已知的正确结果,故而我们根据标注数据在原文中的词频及其在词典中的词义数量分布从4 671个待标注词中抽取了22个样本,人工检查其结果进行评测。表2给出了测试样本在《大词典》中的词典义项数、读音数、先秦义项数、《左传》中的词频,并按照先秦义项数降序排列。这些词在《左传》中的词频从1到1 124不等,义项数最少为2,最多有13种,其中包含了5个多音词。表3则给出了这些词语的评测结果。

表2 评测抽样词语信息
根据表3,我们发现不关注读音直接标注词义在平均值上取得了最好的效果,其宏平均和微平均[13]准确率分别达到了67.15%和49.09%。分析实验结果我们讨论以下几个方面。
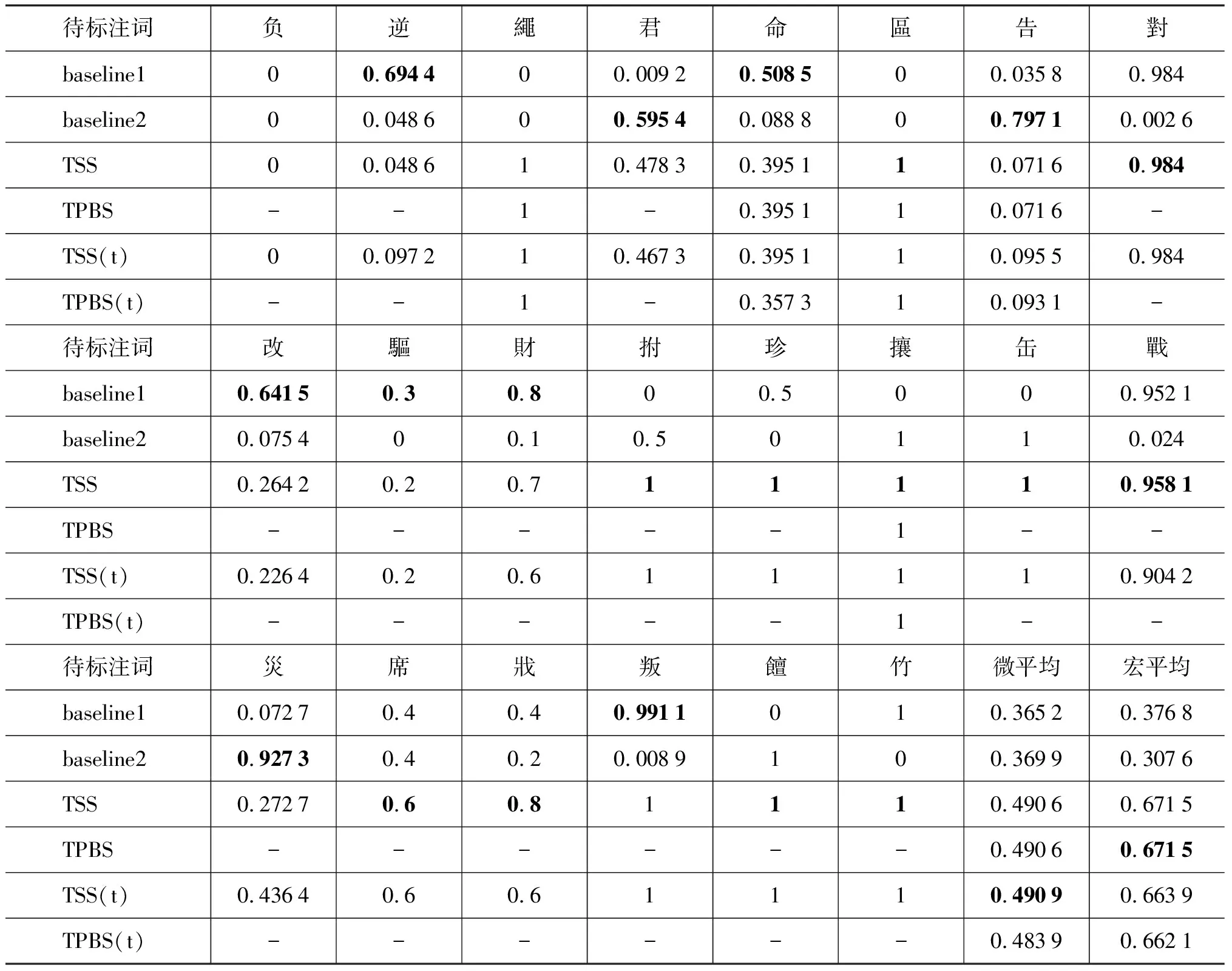
表3 抽样标注结果准确率[0,1],t表示设定了阈值
(1) 低频词的词义标注。对于《左传》中的低频词,如果在大词典包含了出自《左传》的例句,即使义项数较多,也可以得到较好的结果。而当其在词典中的义项数目多且相应的例句出处并非《左传》或者语言与《左传》差别较大时,该词的释义很难被准确标出。
例如,“缶”、“拊”、“區”、“繩”、“饘”和“珍”等词虽然在《左传》中只出现了一到两次,但由于词典中用于说明其释义的例句正是由《左传》而来,故而我们根据例句得到的上下文对于这些词的自动词义标注具有很强的指示性,使得结果的准确率比较高。同样作为低频词的“负”在本次的抽样结果中标注效果很差。“负”在《左传》中的词频仅有一次,使得它在自动标注时从客观情况上无法进行迭代的过程,只能通过例句给出的上下文来判断。而在词典中“负”的先秦义项有13项之多,且其中没有出现出自《左传》的例句,尤其是标示其正确释义的例句出自与《左传》语言差别很大的《诗经》,由此得到的种子上下文难以为该词的词义标注做出正确的指引。
(2) 词典中义项区分度对结果的影响。对于词典中不同的义项间用法、语义或词性区分度高的待标注词,不论其在《左传》中词频高低,均能取得较好的标注效果。例如,“對”、“戰”和“竹”,它们的词频有高有低,词典中的义项数有多有少,但这些义项间均存在明显的区别,因此,这3个词的词义标注结果也取得了较好的效果。同样作为高频词的“叛”,由于它的两个释义在词性上有很明显的区分,因此标注的准确率达到了100%。
而当词典中存在释义间的“不平等”关系或义项粒度过细时,则会导致词义的错误标注。这时阈值的加入可以防止迭代过程中错误分类的蔓延,提高结果的准确率。例如,“戕”在词典中的第三个释义为“他国之臣杀本国君主”,要判断这一点需要有一些外在的先验知识,仅从局部上下文是很难分出该词义与释义一“残害,杀害”的区别,甚至可以认为释义三是释义一的一种特例,这也是导致了“戕”唯一的一个错标。又如“災”有两个义项分别为“特指火灾”和“泛指灾害”,在自动标注时难以将“泛指”从“特指”中区分开来,但在设定阈值的情况下准确率有了显著的提高。
(3) 词典中例句的分布对结果的影响。《大词典》中对于一个词的每个义项给出的例句数量比较随意,并没有给予常用义更高的“权重”。这在词义粒度细、区分度不高的情况下,为词义的自动标注带来了很大的困难,导致了结果的低准确率。例如,“逆”和“告”,义项数目均在十个以上,而表示其常用义的例句都只有一句,反而是有些不常用的释义被用了更多的例句来说明,最终的标注准确率都降到了baseline1以下。
(4) 读音对多音词词义标注的影响。对于义项数目分布不平均的多音词,先区分拼音后区分词义的过程对提高词义标注的准确率的意义不大,甚至可能起到反作用。例如,“告”,由于seed中表示第一种拼音的例句远比第二种拼音多,使得分类结果更偏向于标注为第一种读音,以至于没有能正确的把拼音二区分开来,从而对最终的标义的准确性起了反作用。
综上所述,在利用《大词典》进行古汉语的词义自动标注时,对于词频低且在词典中包含了所标文献的例句时,即使释义的条目较多,也可能得到较好的结果。对于释义间有明确的词性差别的待标注词也能给出比较正确的结果。对于是多音词的待标注词而言,只有当其不同的读音间释义数目分布平均时,先标读音后标词义的两步过程才更有意义。对于终止迭代过程的条件中所使用的阈值问题,当待标注词含义丰富,且词频较高时,加入阈值可以在一定程度上减少误标。另外,我们也从实验中发现了《大词典》本身的释义粒度有时过细或者两个释义存在“泛指”和“特指”的关系,这为我们的自动标注词义过程带来了很大的困难。
5 结论与未来工作
本文针对先秦古汉语这一特殊的文本对象,将WSD的过程分为先区分读音后区分具体词义这两个步骤。实验过程使用了《大词典》为知识来源,《左传》作为测试语料,采用了基于支持向量机(SVM)的半指导方法。微平均和宏平均正确率分别达到49.09%和67.15%。对于义项区分度较大、用例相近的词语,自动标注的效果可以达到95%以上。对于义项区分度低、《大词典》用例差异大的词语,效果还不太理想。在我们同时开发的人机交互式义项标注平台的辅助下,可以作为人工标注的良好初始结果,服务于古汉语词义标注语料库的建设。
在今后的工作中我们考虑从以下几方面对本文的工作进行改进:(1)加入更多语言信息,如句法结构、语义角色、依存分析等,并加入特征选择的过程,进一步提高词义标注的效果; (2)利用较为丰富的历代注疏文献和验证指导学习方法的自动标注结果,同时提高全词标注的效果; (3)将词义列表根据待标注词在不同释义上的词性不同分类,来减小自动标注的难度。
[1] Pradhan, S., Loper, E., Dligach, D., et al. Semeval-2007 task-17: English lexical sample srl and all words[C]// Proceedings of SemEval-2007, ACL, 2007, 87-92.
[2] 汉语大词典2.0[CD]. 商务印书馆(香港). 2005.
[3] 董志翘.为中古汉语研究夯实基础[J].燕山大学学报(哲学社会科学版),2011,12(1):1-6.
[4] 于丽丽,丁德鑫,曲维光,等. 基于条件随机场的古汉语词义消歧研究[J].微电子学与计算机,2009,10: 45-48.
[5] Lesk. M. Automatic sense disambiguation using machine readable dictionaries: how to tell a pinecone from an ice cream cone[C]// Proceedings of the 5th annual international conference on Systems documentation, 1986:24-26.
[6] Patwardhan, S., Banerjee, S., Pedersen, T. Using measures of Semantic Relatedness for Word Sense Disambiguation[C]// Proceedings of CICLing, 2003:241-257.
[7] Pedersen, T., Banerjee, S., Patwardhan, S. Maximizing semantic relatedness to perform word sense disambiguation[R]. Minneaplis: University of Minnesota Supercomputing Institute, Res. rep: UMSI 2005/25, 2005.
[8] Sinha, R., Mihalcea, R. Unsupervised graph-based word sense disambiguation using measures of word semantic similarity[C]// Proceedings of the IEEE International Conference on Semantic Computing, 2007:363-369.
[9] Agirre E., Soroa A. Personalizing PageRank for word sense disambiguation[C]// Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, 2009:33-41.
[10] Yarowsky D. Unsupervised Word-Sense Disambiguation Rival Supervised Methods[C]// Proceeding of the 33rd Annual Meeting of the Association for Computational Linguistics, 1995:189-196.
[11] Jin P. Li F., Zhu D., et al. Exploiting External Knowledge Sources to Improve Kernel-based Word Sense Disambiguation[C]// Proceedings of IEEE International Conference on Natural Language Processing and Knowledge Engineering, 2008:222-227.
[12] 石民,李斌,陈小荷. 基于CRF的先秦汉语分词标注一体化研究[J],中文信息学报,2010,2: 39-45.
[13] Manning C, Raghavan P, Schütze H. An introduction to Information Retrieval[M]. Cambridge, England: Cambridge University Press, 2007: 210-211.
猜你喜欢
潍坊学院学报(2021年4期)2021-11-20
红河学院学报(2021年4期)2021-11-19
汉字汉语研究(2020年2期)2020-08-13
汉字汉语研究(2020年1期)2020-04-21
汉字汉语研究(2019年1期)2019-05-21
华声文萃(2018年8期)2018-09-18
文萃报·周五版(2018年29期)2018-08-04
汉字汉语研究(2018年1期)2018-05-26
知识窗(2015年1期)2015-05-14
Beijing Review(2012年37期)2012-10-16
