
中文维基百科的结构化信息抽取及词语相关度计算方法
2012-06-29 03:54:20涂新辉张红春周琨峰何婷婷
中文信息学报 2012年3期
涂新辉,张红春,周琨峰,何婷婷
(1. 华中师范大学 计算机科学系, 湖北 武汉 430079;2. 国家语言资源监测与研究中心 网络媒体语言分中心, 湖北 武汉 430079)
1 引言
随着互联网的快速普及以及廉价大容量存储设备的不断出现,人类社会已经产生了海量的数字化信息。这些数量惊人的数字化信息可谓是人类知识的一个重要的宝库。如何从海量的语言材料中自动地获取语义知识,以及如何有效地利用这些语义知识来提高计算机的自然语言理解水平,已成为一个重要的研究课题。
维基百科作为一个以开放和用户协作编辑为特点的Web 2.0知识系统,具有知识面覆盖度广,结构化程度高,信息更新速度快等优点。维基百科中蕴涵有丰富的语义知识,是目前众多学者进行语义知识获取研究所青睐的语言资源。近几年来,国外的许多学者专家以英文维基百科作为语料库、语义知识库,从不同的角度抽取语义知识进行研究,取得了很多突破性的成果。Struble 和 Ponzetto最先利用维基百科进行了语义相关度的研究[1]。他们把在WordNet知识库上效果比较好的一些经典算法移植到维基百科的分类图中,并使用三个测试数据集M&C、R&G和WS-353分别做了实验。结果表明,在大数据集上,维基百科的计算结果要远好于WordNet。Zesch 等人利用德语版的维基百科和GermaNet进行了类似的实验研究,得出了一致的结果[3]。Gabrilovich 和 Markovitch提出了显示语义分析算法 (Explicit Semantic Analysis),简称ESA[4]。他们的主要思想是采取一种基于质心的策略,把文本的语义隐射到一个由维基百科概念所形成的带有权重的高维空间向量中,再利用简单的向量乘法计算两者之间的语义相关度。Milne则只分析使用了文档中出现的内链接,他认为链接中蕴含了更丰富的语义信息[5]。
目前,在国内,基于中文维基百科的研究还缺少开源的工具和很方便计算的数据。在词语间语义相关度计算方面,李赟博士提出的综合多条关联路径的算法[6],综合考虑了分类图和文档图中两节点间路径的条数、每条路径的长度、图中节点间的不同关联程度等多个特征。
本文首先从中文维基百科官方所提供的原始数据文件中抽取和整理了维基百科链接、类别和锚文本等多种类型的结构化信息;然后,对维基百科的信息建立了类结构模型,并提供了一套开放的应用程序接口,方便了用户对维基百科中信息的获取和使用;在此基础上,利用包括链接和链接类别等特征进行词语语义相关度的计算的方法进行了对比实验。
2 维基百科的结构化信息抽取
在维基百科中,信息是按照一套预先定义的结构来组织和创建的。主要的结构元素包括:主题页面、重定向页面、消歧页面、类别等。
主题页面: 主题页面是维基百科中最重要的元素。每一个主题页面都代表一个单独的概念,其标题是一个严格定义、具有格式统一的词语或词组。在维基百科中的标题是其唯一的标示符,歧义页面通常使用附加的信息加以区分。例如,“苹果”这个标题代表一种常见的水果这个概念的页面,而“苹果 (电影)”这个标题则是一个电影页面的标题。页面中通常使用不同语种的自然语言来描述这个概念的相关信息。页面中的信息都是和这个概念密切相关的,可以被看作为这个概念的语义上下文。
重定向页面: 在自然语言中,存在很多同义现象,即多个词语表达相同的概念。在维基百科中,如果多个概念是等同的,那么这些概念中除了一个概念的页面中包含概念的描述以外,其他的概念使用重定向的链接映射到这个页面中。这种包含重定向链接的页面被称为重定向页面,这种方式避免了概念的重复定义,同义的概念被组织一个共同的信息页面,在一定程度上也简化了信息的维护。这种重定向页面的机制还被用于处理大写方式、拼写变体、缩写以及专业术语等问题。例如,在中文维基百科中,有一个页面为“电子计算机”,指向它的重定向页面包括:“电脑”,“计算机”。
消歧页面: 和同义现象相反,自然语义中还普遍存在歧义的现象,即一个词语可以表达多个不同的概念。在维基百科中,消歧页面就是专门处理歧义现象的一种机制。例如,在“苹果 (消歧义)”这个消歧页面中,存在多个不同链接到以下多个概念的页面:“苹果“,“苹果公司”,“苹果 (电影)”等。
类别: 类别是维基百科中对概念页面信息进行组织的一种有效的手段。通常,每一个主题页面至少归属于一个类别。例如,“电子计算机”这个主题页面归属于“计算机”等多个类别。类别本身不是专题页面,它们的存在只是为了便于组织和管理页面。类别的目标是建立信息的层次关系,实际上维基百科的类别并不是严格的树型结构,而是一种接近图形的复杂结构。
内链接:在主题页面的正文中,通常存在一些到其他的主题页面的链接,这些链接以及链接中包含的锚文本信息都是获取维基百科主题间语义信息的重要资源。
维基百科中的链接和类别等结构信息中蕴含了丰富的维基百科概念间的语义关系的信息。但是,维基百科的官方仅提供一些基本数据文件,很多有用的包括链接和类别在内的结构化信息并不能直接地获取和利用。
本文从中文维基百科官方网站下载了2010年08月29日的数据文件,并针对维基百科页面中的正文、链接以及链接中包含的锚文本信息进行了抽取和整理。其中,对页面中正文内容的处理主要包括中文繁体转简体、文本中噪音的过滤(例如,模板、表格、外链接等)、文本的索引等几个方面。对链接的处理则包括对维基百科类别页面中链接的处理和对主题页面中链接处理两个方面,前者主要为了构建维基百科类别图型结构信息、计算类别在图型结构中的深度以及提取主题页面与类别的从属关系;后者主要是统计主题页面间链接、重定向链接和消歧义链接。最后,结合主题页面中文本内容和链接信息,对链接中的锚文本的使用情况进行了统计。在实现的过程中,本文把抽取的结构化数据都按表存储在数据库中,并对各个重要字段建立了索引。经过一系列的处理之后,本文得到了七张数据表,包含了对中文维基百科中锚文本、内链接和分类的统计情况。
为了让用户能够方便地获取和使用这些结构化的信息和数据,我们建立了基于Java的应用程序接口,如图1所示。在本文中构建的维基百科结构化信息系统中,从整体上对维基百科的信息建立了类结构模型,其中主要的Java类有:维基百科页面基类,主题页面类,类别页面类,消歧义页面类,重定向页面类,锚文本类和维基百科类。表1中列出了类及其对应实体的相关信息。每一个类中都实现了获取其相应的数据信息的方法,例如,对应维基百科页面基类,本文实现了获取正文标题和内容信息的接口;对于主题页面类,本文实现了获取其入链接、出链接、所属类别的接口;对于维基百科类别页面类,实现了获取其子类、父类、所有属于该类别的主题页面的接口;对于重定向页面类,实现了获取其重定向的目的页面等信息的接口;对于消歧义页面类,实现了获取其正文中所列举出的所有主题页面等信息的接口;对于锚文本类,实现了获取该锚文本所链接到的所有的不同主题页面等信息的接口。用户可以通过这些定义的类和成员方法定义的接口就可以获取和使用这些结构化的信息。并且,在处理数据的过程中,我们还实现了一系列程序接口和方法,包括文字的繁简体转换接口、文本处理及数据库访问接口、文本信息过滤接口、语义相关度计算接口等。
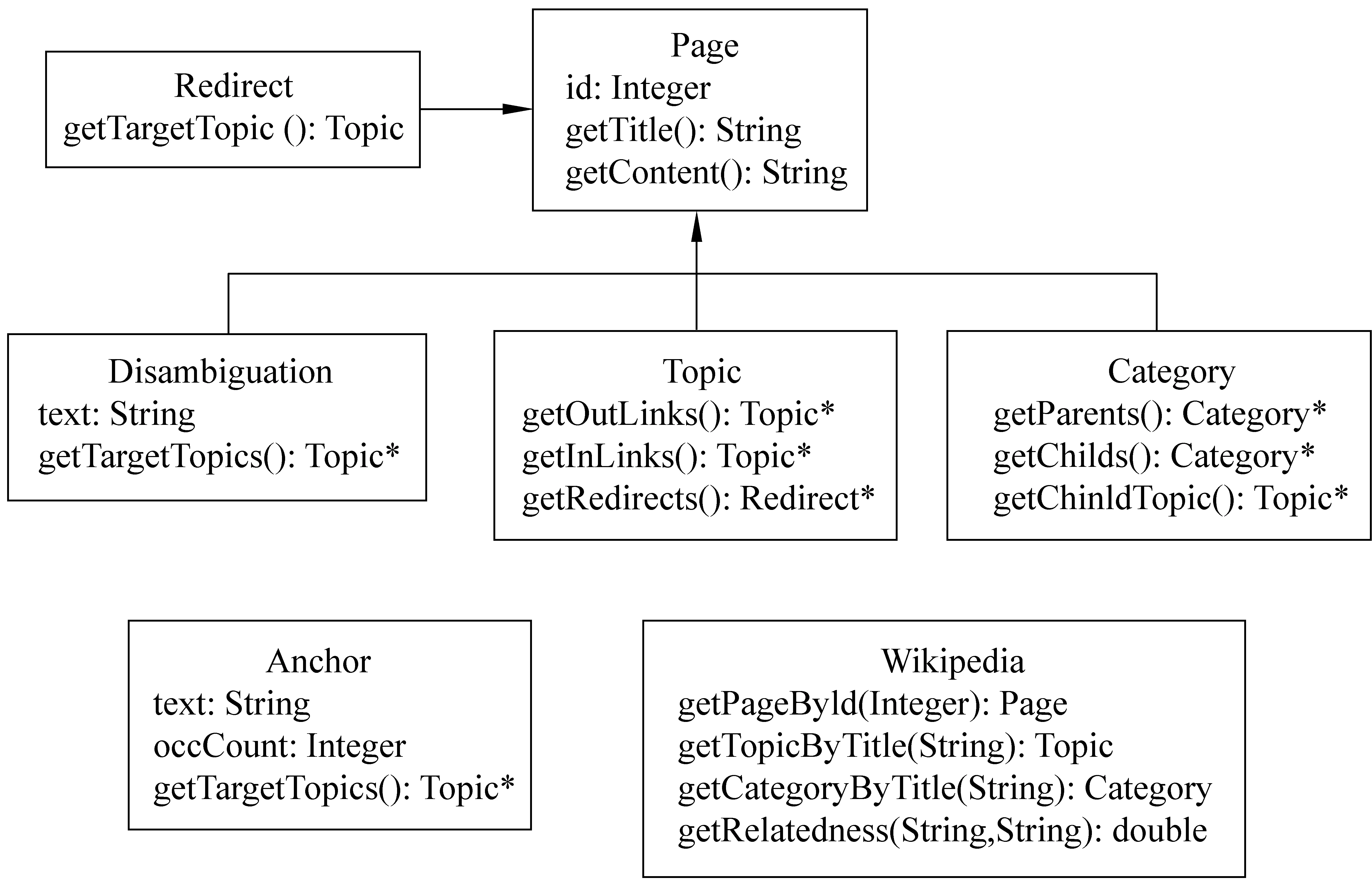
图1 中文维基百科系统类结构

表1 中文维基百科系统中类的统计信息
3 基于中文维基百科的词语间语义相关度计算
本文中计算词语语义相关度的方法分为两个步骤:(1)分别把词语wA和wB映射到维基百科主题页面PA和PB; (2)计算维基百科主题PA和PB的语义相关度值SIM(PA, PB),这个值即可作为wA和wB的语义相关度。
3.1 维基百科主题间的语义相关度计算
在英文维基百科中,主题页面中包含了丰富的内链接,这些链接通常指向和当前主题页面相关的其他维基百科主题。David Milne提出了一种利用两个主题页面的入链接特征来计算这两个维基百科主题的语义相关度的方法。这种方法的基本思想为:如果有很多主题页面中都同时存在链接指向主题页面PA和PB,则PA和PB两个维基百科主题的相关度将会较高。这种方法在英文维基百科上取得了不错的效果。然而,中文维基百科在规模上远远不如英文维基百科,主题页面之间的链接也比较少,存在一定的稀疏性。因此,在中文维基百科上仅利用链接可能难以充分地评估主题的相关度。
主题页面所属的类别信息也是相关度的一种重要的暗示,相对于链接的稀疏性,类别信息更加集中地体现了维基百科主题页面之间的语义关联信息。针对中文维基百科,本文提出了一种利用主题页面中链接所对应的主题页面的类别特征来计算主题相关度的方法,并对包括入链接、出链接、入链接和出链接所对应的主题页面类别的四个方面的特征进行了对比实验分析。本文中计算方法的主要步骤如下:
设有两个维基百科主题页面Pa和Pb,链接到Pa和Pb的不同主题页面所构成的向量分别为Va_in和Vb_in。计算这两个向量的余弦值即可得到Pa和Pb的相关度。在构建向量的过程中,每个链接的权重通过以下的方法计算:
(1)
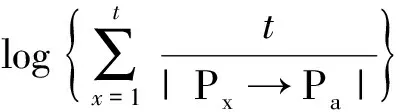
对于维基百科主题页面Pa和Pb,它们的所有入连接所对应的主题页面集合为{Pi|i=1…n},则入链接构成的向量如下:
(2)
(3)
构建了基于入链接的向量后,可以通过计算这两个向量的余弦值得到两个主题的相关度。基于出链接的计算方法和入连接方法是类似的,在利用链接的主题页面的的类别进行计算时,我们把链接的向量转换为类别的向量,具体的方法如下:
对于维基百科主题页面Pa和Pb,它们的所有入连接所对应的主题页面集合为{Pi|i=1…n},这些链接所从属的类别集合为{Cj|j=1…m},则对于主题页面Pa和类别Cj,权重为:
(4)
这里的w(Pi→Pa)为主题页面Pm到Pa的链接m→a的权重,当专题页面Pi属入类别cj时,b(Pi,Cj)为1,否则为0。
可以构建主题页面Pa和Pb所对应入连接的类别的向量如下:
(5)
(6)
构建了基于入链接类别信息的向量后,可以通过计算这两个向量的余弦值得到两个维基百科主题的相关度。基于出链接类别的计算方法和入连接类别方法是类似的。
3.2 词语到维基百科主题的映射
在自然语言中普遍存在一词多义的现象。在计算两个词语间相关度时,首先需要把这两个词语分别映射到的两个维基百科主题,否则无法进行计算。在计算两个词语的相关度时,如果其中某个词语为歧义词可以对应到多个不同的维基百科主题时,通过各种两个主题对的相关度以及主题的常用度信息,可以获取可能性最大的维基百科主题。歧义词语到维基百科主题的映射过程也包含两个步骤:(1)找出词语所对应的维基百科主题; (2)从所有的主题中找到可能性最大的主题。
在获取词语所对应的所有主题信息时可以使用消歧义页面。消歧义页面是一个词语对应多个维基百科主题的列表页面,列出了词语对应的各个维基百科主题,在不考虑条目标题补充说明的前提下,每个维基百科主题都有相同标题。查找一个词语的在维基百科中的所有主题,最简单的方法,就是利用图1中的消歧义类接口,判断该词语与哪些义项标题相等,把所有符合条件的条目作为该词语的主题集合。然而中文维基百科为多义词提供的消歧义页面数目又非常少,许多词语都没有与之对应的消歧义页面,利用消歧义页面也只能完成少部分的工作。
经分析发现,维基百科条目之间含有大量的链接,而这些链接中的锚文本有一些是所指向主题页面的标题,要么是所指向维基百科主题的别名。因此,通过收集链接的锚文本构建的图1中的锚文本类接口,可以被利用来获取词语对应的维基百科主题。例如,利用消歧义信息,可以找到词语“苹果”对应的维基百科主题 “苹果(水果)”、“苹果(电影)”、“苹果(韩国电影)”这几个维基百科主题。而利用Anchor表中的信息还可以找到苹果对应的“苹果公司”、“苹果日报”等维基百科主题。
从所有的维基百科主题中确定词语在当前的相关度计算过程中应该选取的主题的时,本文考虑了两个方面的因素:(1)维基百科主题的普遍性; (2)和另外一个词语对应主题的相关性。普遍性是指一个词语对应的某个维基百科主题被人们所熟知的程度,这个值可以通过锚文本的使用情况来近似获得,例如,利用词语A作为锚文本,指向的维基百科主题条目有(c1, c2, …, cn),每种链接在整个维基百科中出现的次数分别为(k1, k2, …, kn),则词语A映射到维基百科主题ci的概率为:
(7)
相关性是指所有的词语A所对应的维基百科主题与词语B的所对应的维基百科主题,两两配对计算相关度,哪一对主题的得分越高,则认为这对主题更可能是词语A和词语B的当前含义。最后,通过普遍性和相关性值的线性加权,选取总得分最高的那个义项对的相关性值作为词语A和词语B的相关度。例如,苹果有苹果(公司)和苹果(水果)两个义项,那么苹果和乔布斯的相关度最终就应该是苹果(公司)义项和乔布斯之间的相关度,如图2所示;苹果和梨子的相关度对应的就应该是苹果(水果)义项和梨子之间的相关度,以达到消歧义的目的。
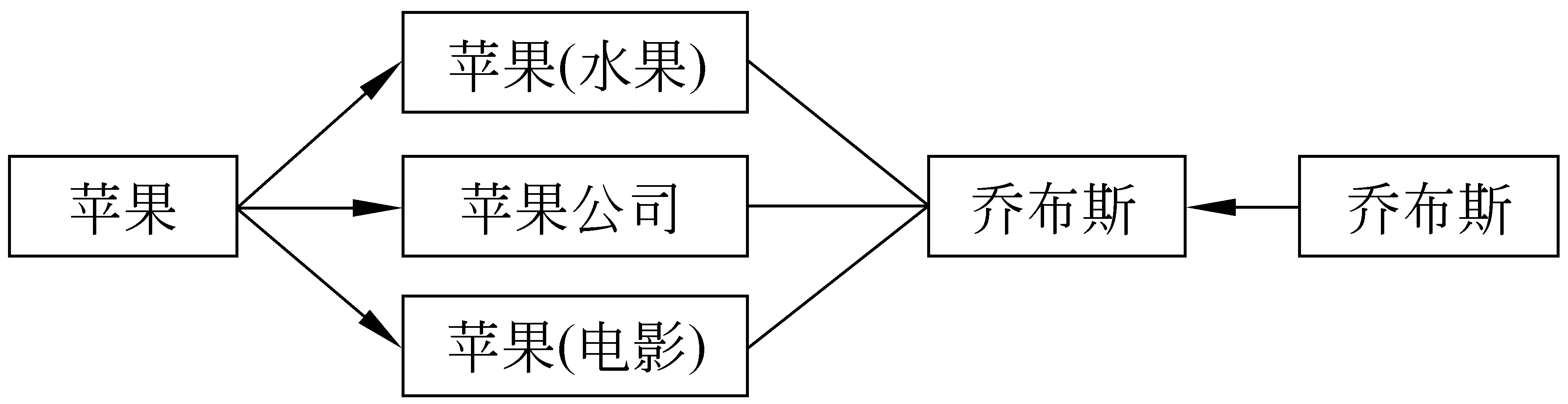
图2 词语到维基百科主题的映射
4 实验结果和分析
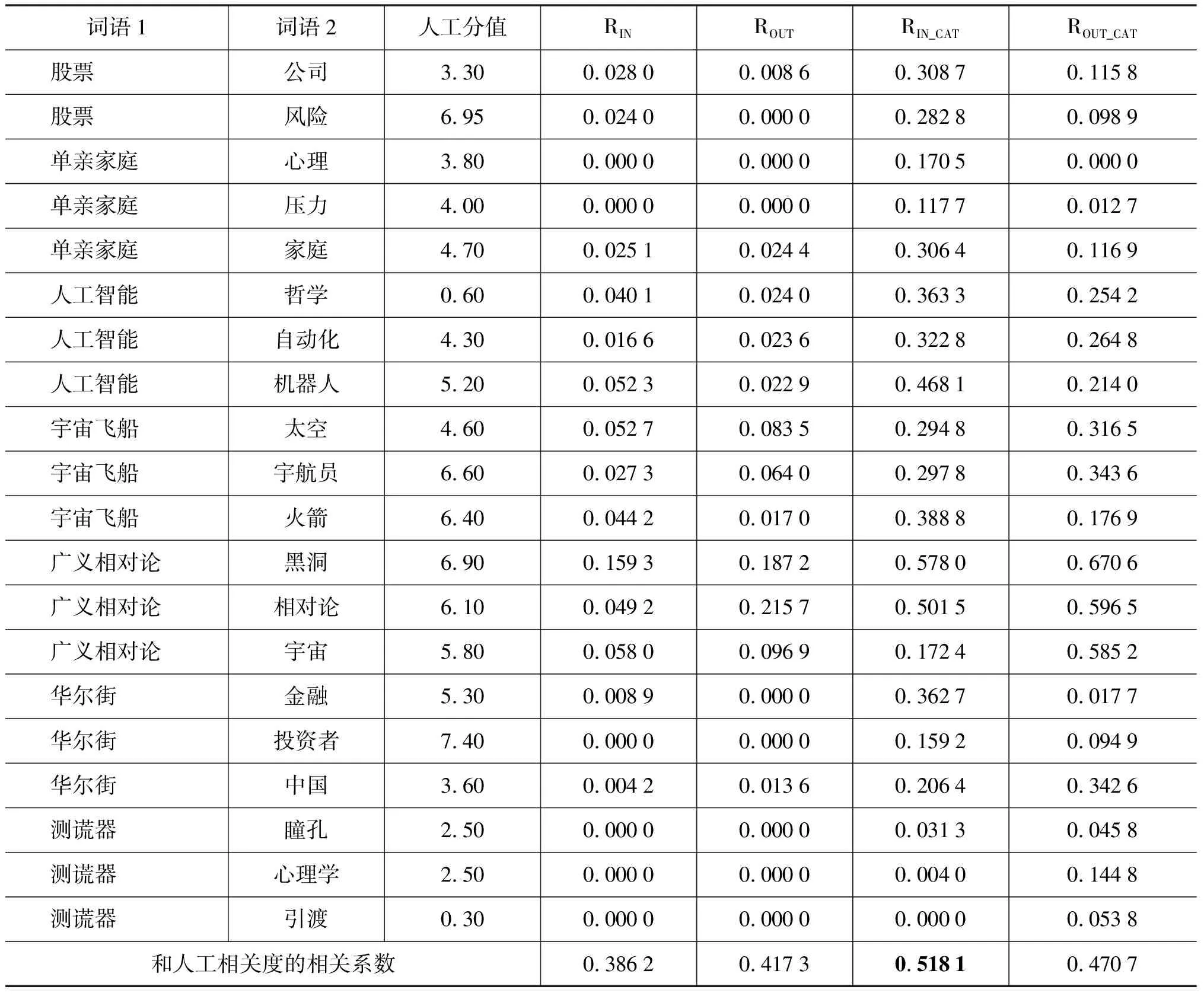
为了讨论与本文提出的相关度计算的各种特征的作用,本文随机选取了多个领域的30对词语组成了测试数据集。在具体的评测过程中,分别利用四种特征进行了对比实验:(1)基于入链接的相关度,简称为RIN; (2)基于出链接的相关度,简称为ROUT;(3)基于入链接主题所属类别的相关度,简称为RIN_CAT; (3)基于出链接主题所属类别的相关度,简称为ROUT_CAT。
为了评价各种方法的效果,同时,让10位测试人员各自独立对每对词语进行相关度打分,分值在0~10直接,0表示完全不相关,10表示等价。然后,对每对词语的10个打分计算平均值,来得到数据集中每对词语的人工相关度值。
再分别计算了每种方法得到的相关度与人工相关度的相关系数,具体实验结果见表2。所有的计算结果都是四舍五入后,保留了4位小数。
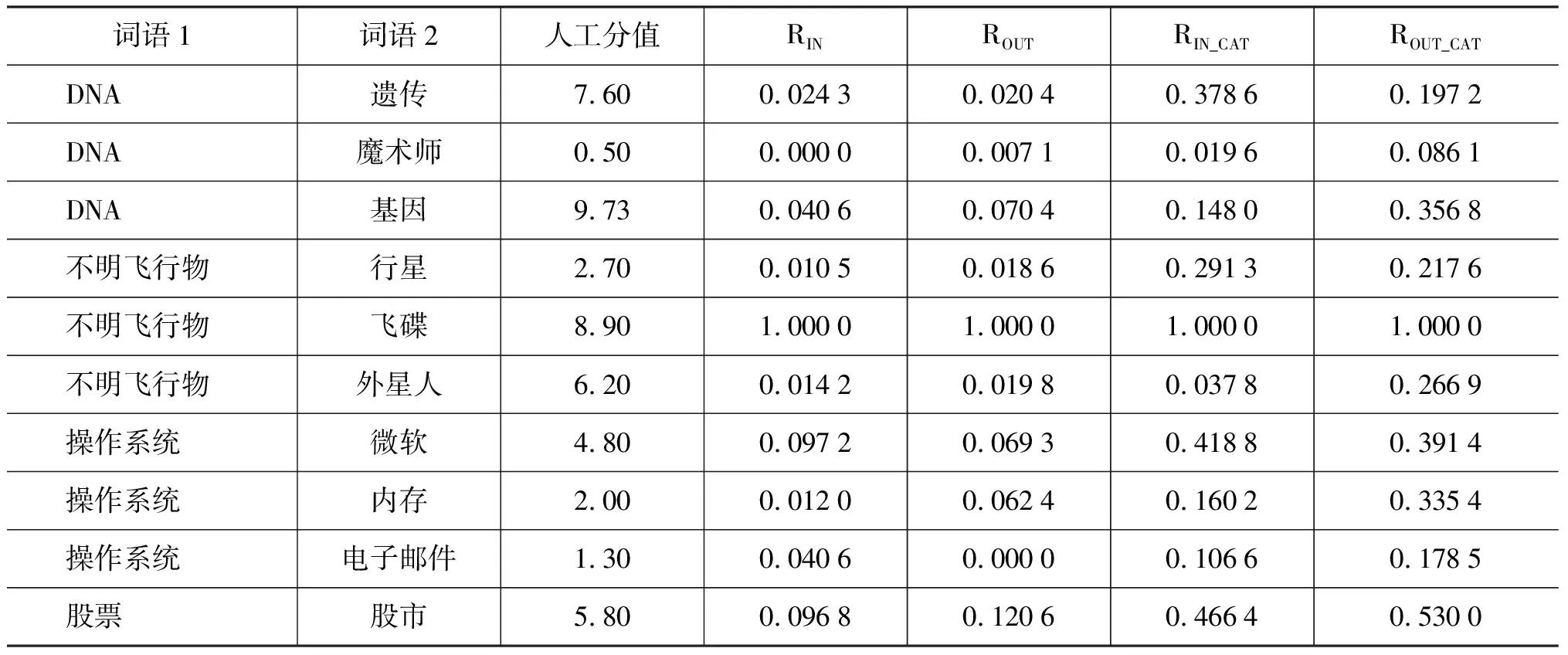
表2 语义相关度计算结果
续表
分析实验结果可以得出以下结论:1)基于入链接或出链接的方法在中文维基百科上效果较差,反映了中文维基百科数据稀疏性问题对相关度计算的负面影响; 2)本文提出的利用链接主题所属类别的方法得到的相关度更接近人工的相关度值,其中基于出链接主题所属类别的相关度的方法效果最好。
5 结论和展望
本文首先抽取整理了中文维基百科结构化信息;对维基百科的知识结构建立了类模型,并实现了一套开放的应用程序接口;在此基础上,进行了词语语义相关度计算的实验,讨论了利用中文维基百科页面的链接信息进行语义相关度计算的效果。 然而,从表2可以看出,不论是维基百科的词条数目,还是其中的链接、分类信息,规模都不是很大,依然存在数据稀疏性的问题;因此,在后续的工作中,可以结合维基百科中的文本内容提供更好的词语语义相关度计算模型。
[1] Michael Strube, Simon Paolo Ponzetto. WikiRelate! Computing semantic relatedness using Wikipedia[C]// Proceedings of the 21rd national conference on Artificial intelligence, 2006: 1419-1424.
[2] Simone Paolo Ponzetto, Michael Strube. Knowledge Derived From Wikipedia For Computing Semantic Relatedness[J]. Journal of Artificial Intelligence Research, 2007, 30: 181-212.
[3] Torsten Zesch, Christof Muller, Iryna Gurevych. Using Wiktionary for Computing Semantic Relatedness[C]//Proceedings of the 23rd national conference on Artificial intelligence, 2008: 861-867.
[4] Evgeniy Gabrilovich, Shaul Markovitch. Computing Semantic Relatedness using Wikipedia-based Explicit Semantic Analysis[C]//Proceedings of the 20th International Joint Conference on Artificial Intelligence, 2006: 1606-1611.
[5] David Milne. Computing Semantic Relatedness using Wikipedia Link Structure[C]//Proceedings of the New Zealand Computer Science Research Student conference, 2008.
[6] 李赟. 基于中文维基百科的语义知识挖掘相关研究[D]. 北京邮电大学博士学位论文, 2009.
[7] http://zh.wikipedia.org/[DB/OL].
[8] 刘群, 李素建. 基于《知网》的词汇语义相似度计算[C]// 第三届汉语词汇语义学研讨会, 2002.
[9] Pu Wang, Carlotta Domenicon. Building Semantic Kernels for Text Classification using Wikipedia[C]// Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, 2008.
猜你喜欢
英语世界(2023年10期)2023-11-17 09:18:46
英语文摘(2021年8期)2021-11-02 07:17:46
中国外汇(2019年12期)2019-10-10 07:26:58
疯狂英语·新悦读(2017年2期)2017-04-08 01:31:27
新校长(2016年8期)2016-01-10 06:43:59
海南师范大学学报(社会科学版)(2015年7期)2015-12-28 08:17:40
读者·原创版(2015年11期)2015-03-01 06:15:34
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
意林(2014年2期)2014-02-11 11:09:17
