
语体学在语言学中的地位及其研究方法*
2012-01-23 07:26金立鑫白水振
当代修辞学 2012年6期
金立鑫 白水振
(上海外国语大学语言研究院,上海 200083/韩国启明大学中国学系,韩国大邱)
提 要 本文讨论语体在语言系统以及语体学在语言学中的地位及研究方法问题。文章假设,语言机制中存在词汇、句法、语篇和语音的语体模块,它们监控语篇的生成,制约着说写者根据特定语体要求选择相应的词汇、句法结构、语篇衔接形式以及韵律形式。特定语体所采用的语言要素以及这些语言要素在不同语体中的不同配置规则是语体学研究的核心课题。文章例举了部分成果说明统计方法在语体研究中的有效性和可行性。
一、缘 起
语体研究中长期存在一些基本理论问题悬而未决。主要是:
第一,根据我们的理解,语体学从语言系统运作机制上来看,理所当然地应该属于语言学的核心学科,但在学术界一个有目共睹的事实是,语体学日益边缘化。这可以从国内外语体学研究在核心刊物与其他分支领域研究所发表的成果比例中看出。这是一个显而易见的矛盾。那么,语体学到底属于语言学的核心分支学科还是语言学的边缘学科?
第二,语体作为一种语言现象,它到底是一种“语言的规则”还是一种“语言的艺术”?如果是一种规则,那么语体现象是可以通过经典自然科学的手段和方法来研究的,但如果作为一种艺术,或许目前的科学手段还无法满足这一研究的需要,只能处于“非科学”的境地。
第三,语体作为语篇的一种类型,这种类型的鉴别是依据鉴赏者的内心体验还是反映为一套规则和参数?换句话说,一个特定的语体是只可意会不可言传的,还是可以表述为一套规则或参数的?如果是前者我们只能依据个人的语感来断定某一文本的语体类型,如果是后者,我们就能通过一套规则或参数来判断某一文本的语体类型,并且能通过这一系列参数来生成我们所希望得到的某一特定的语体文本。
本文讨论以上问题。
二、语体学学科地位的重新定位
任何一门成熟的学科都会有下位分支学科,各个分支学科的分工协同合作共同完成该学科的终极研究任务。同样,语言学中的任何一个分支学科,它的功能或定位只能根据语言学整个学科的属性来确定。我们知道,现代科学意义上的语言学,其终极目标之一是探求人类语言的内部机制,即探索或发现人类语言是如何生成的,是如何被理解的。生成一个句子,从要表达的语义到表达出来的语言形式(或者相反从形式到语义),语言机制的运作过程是怎样的?或者说,这个过程是遵循哪些规则一步步(运算)得到的?
一种以往熟知的理论模型可以表示为:
语义表达→词汇选择→句法组织→语用修辞→语音合成
这个模型中完全没有语体学的工作,这确实有点荒唐。我们很难想象一个完整的语篇竟然不属于任何语体类型!
事实是,任何人在执笔开始书写任何文本时,无论是在选词还是造句等所有涉及生成任何句子的时候,他都已经进入了一个受到语体规则制约的系统,在他选定文本语体类型之后,语体规则便开始在线监控书写者的每一个用词、每一个句子的构造,语体规则无时无刻不在控制着书写者。通常情况下书写者要突破语体规则的任何控制均属不易。有鉴于此,我们将以上模型修正为:

图1:语体修辞监控与新语言模型
这是一个示意图,它要说明的是当我们在生成任何一个语篇、做每一步心理操作时都受到语体以及修辞规则模块的监控,监控模块也相应地具有词汇、句法、语篇和语音模块,每个模块都对应于生成过程的具体操作。国内学界在词汇的语体分类方面已经有不少研究基础,句法方面国外语言学界也已经有初步的研究成果,例如Biber(1999)编著的《郎曼英语口语与书面语语法》()。
需要说明的是,上面的示意图用的是一种“串联”的表达式,而实际上,人类语言机制更多地表现为一种并联处理模式。也即,在词汇选择时也可能同时受到句法、语篇、语音等模块的监控协调,在句法组织时也同样受到语篇甚至语音模块的监控和协调。因此,这个示意图也是不得已而为之的一种表达。
鉴于以上理论假设,我们认为,语体学和修辞学属于语言学的核心分支,它在语言机制中贯穿了几乎全部生成流程,可谓举足轻重。它的研究直接关系到我们是否能建成各种足够强大的、具有语体色彩的语篇的模型。如果说足够强大的句法规则可以让我们生成合乎语法的句子,同时排除不合语法的句子,那么足够强大的语体规则可以让我们生成合乎各种语境要求的具有明显语体色彩的语篇。其核心目标可以简单归结为:足够强大的语体学理论保证我们能生成正确的语体语篇。
三、语体学的研究目标
如果说语法学是寻求一个句法结构之所以成立的必要条件和充分条件,那么语体学所要研究的是任何一个语言片段与交际语境之间的互动要求,该要求是由一组语言要素构成的。我们知道,任何文本都是在特定语境下表现出的特定文本类型,该文本类型与特定语境相适应。这里所说的文本类型便是语体。例如有语境S1便有所对应的语体R①1,有语境S2同样有其对应的语体R2,以此类推。语境与语体之间的对应关系是任何功能发达的语言和任何成熟的作者所具备的。
1.语体学要研究的是语体R的构成要素
在语言生活中,语体R1和语体R2(以及语体Rn)是由不同的语言要素构成的,语体学要研究的是,在词汇学和句法学等所研究的这些规则之外,构成不同语体R的语言要素(类似的观点可参考丁金国2007、2008)。打个比方,不同的语体类似于不同的菜肴,要做成某一特定的菜肴(特定语体)需要特定的材料(特定的语言要素)。如宫保鸡丁所需要的材料至少包括:鸡胸肉、花生米、蒜、姜、葱、干红辣椒、花椒、油、醋、糖、酱油、料酒、肉汤、淀粉、盐。没有这些材料要做成宫保鸡丁是不太可能的。缺少这些材料做成的宫保鸡丁至少是不正宗的。因此,一道地道的宫保鸡丁一定具有这些材料(或其中的绝大部分材料)。同样,一篇特定语体的文章也一定具有某些必有的语言要素。二者之间形成蕴含关系,这种蕴含关系可以表达为:
语体R蕴含语言要素E②。
前件是后件的充分条件,后件是前件的必要条件。根据这一逻辑规则,那么具有语言要素E并非一定构成语体R。通俗来说,这一蕴含关系表达的是构成某一特定语体的语言要素的“菜谱”中的材料。但是同一菜谱中的材料(必要条件)并不一定构成特定的菜肴,因为某一特定语体的构成还受“菜谱”中各要素比配的制约。同样的材料但不同的数量比配可能做成不同的菜肴。因此我们还需要探求构成语体的其他必要条件。
2.语体学还要研究某一特定语体内语言要素之间的比配规则
我们依旧拿宫保鸡丁这道菜打比方。上节中所列出的仅仅是做宫保鸡丁这道菜的材料,但这些材料需要多少,各种材料之间的比配或比例并未给出,然而这恰恰是极为重要的条件。同样的材料如果比配比例不同完全可能做成另一道菜而不是宫保鸡丁。检索菜谱我们得到宫保鸡丁材料的比配大致为:鸡胸肉250克、花生米50克、蒜2瓣、姜3片、葱1段、干红辣椒3只、花椒10粒、醋1大匙、糖1大匙、酱油1大匙、料酒1大匙、肉汤2大匙、淀粉1匙、盐少量。同理,某一特定语体与语言要素之间也存在特定的比配关系。如果同样的语言要素之间的搭配比例不同,其所形成的语体很可能完全不同。因此,语体与语言要素之间的比配规则可表达为:
语体R蕴含E的比配P③。
根据逻辑规则,E的比配P并非一定构成语体R,换言之,即使有相同的E要素,也有E要素的P比配,但也并非一定能得到我们所期待的语体R。因为语体R的形成还受到强制格式的制约,强制格式的制约相当于菜肴烹制中的烹饪方式——炸还是蒸?是炒还是闷?是煎还是爆?是炝还是氽?是焗还是烩?是煲还是炖?是烘还是烤?是溜还是糟?是醉还是熏?即使同样的材料,同样的比配,但方式不同,最后所形成的菜肴也不会相同。因此我们还要探求构成语体的其他必要条件。
3.确定某一特定语体的强制性格式
任何语体都有一定程度上的强制格式,典型的如公文、说明书、新闻报道、学术论文、诗歌等。中国古典文学作品中的格律诗词是极端的格式表达。最近卫生部长陈竺所写的“水调歌头”就因违背该词牌的强制格式而授人笑柄。尽管其作品在字数和行数上满足了“水调歌头”的要求,但其平仄完全不合“水调歌头”,因此算不得是真“水调歌头”。
特定语体与语言强制格式之间的规则可表达为:
语体R蕴含强制格式F④。
如果将以上E、P和F合起来,它们与R之间是否有充要条件关系?或许不然。某一典型语体还受到该语体所要求的特定的韵律的制约。
4.寻求某一特定语体的韵律规则
一般所见的口语体与书面语体的差别很大程度上与韵律有关。较常见的是播音员通常在播音前要对播音稿进行修改甚至改写,以适合播音的需要(广播体)。
语篇在节奏上是严谨还是活泼,是明亮轻快还是灰暗低沉,这种差别除了词汇因素外,很大程度上与韵律的组配有关,尤其是节奏组配。例如三音节的XX-X还是X-XX,四音节的XX-XX还是X-XX-X;声调的组配上,是高音区多还是低音区多?降调多还是升调多?句式上,是长结构多还是短结构多?等等。这些韵律特征在具体语体中都以一定的比例来表现。
特定语体与特定韵律特征之间的规则可表达为:
语体R蕴含韵律S⑤。
5.小结
到此为止,我们暂且假设以上E、P、F、S四个必要条件是构成某种语体的所有必要条件。总结如下:
语体R蕴含语言要素E;
语体R蕴含E的比配P;
语体R蕴含强制格式F;
语体R蕴含韵律S。
根据逻辑规则,某一对象所有必要条件的总和应该等于该对象的充分条件,因此,以上规则可以总结为:
当且仅当语体R,则E&EP&F&S形式编码为:
R≡(E&EP&F&S)
语体学要研究的便是以上任何一种R与E、P、F、S之间的对应关系。
四、一个或许可行的研究思路
1.寻找特定语体与语言要素之间的对应关系
这一研究的主要任务是揭示不同语体所蕴含的各种必须出现或最可能出现的以及最不可能出现的语言成分。这些成分主要是:各种句式或特定的句法结构,各种功能词(介词、连词、语气词、叹词、助词),各实词的语体小类(同义词或近义词)。
有学者可能会有疑问,这或许是一个“鸡和蛋”的问题⑥。到底是用语体来测量语言要素呢,还是用语言要素来测量语体?这好像真是个问题。有解吗?或许有。只是难度较大,需要采用语料库和统计方法。
我们可以先依赖母语者的语言直觉,选取一些较为典型的迥然不同的语体文本,然后对这些不同的语体文本进行穷尽性语言要素统计,根据统计结果去发现不同语体本文在哪些项目上具有相似性,哪些项目具有对立性。相似性项目可以作为所有语体文本的“共项”,不具有区别性特征,予以剔除。留下那些具有对立意义的项目。在这些具有对立意义的项目的基础上提出不同语体的语言要素成分假设。然后对这些假设进行更大规模的统计证明,或对其进行修正和调试。最后得到某一语体语言要素(大致)的“清单”。
根据以往的研究,语言学家们已经发现,某些语言要素只存在于某些语体文本中,而不存在于另一些语体文本中。这些研究中已经引起学界关注的至少有:方梅(2007),冯胜利(2006),陶红印(2007),陶红印、刘娅琼(2010),张伯江(2007),张先亮、郑娟曼(2006),曾毅平、李小凤(2006)。这些研究都就某些语体与某些语法现象之间的关系做出了极为有意义的探索,值得进一步扩展和发掘。
下面我们以一份网络上的《官场万能讲话稿》(见后附)为例,观察其中一些突出的语言要素。
该“讲话稿”全文不计空格总字数1105个,除去无效字符(X),总有效字数888个,用词256个,根据使用频次由高到低排列如下(括号内的数字表示词语在该文中的使用频次):的(39),工作(31),要(21),是(14),同志(11),各级(7),对于、和、经济、市场、我们(6),必要、加强、我、有(5),局面、开展、了、领导、努力、认真、上、十分、希望、性、也、重要(4),把、非常、很、结合、开创、领会、落实、目前、你们、深刻、新、影响、有机、在、这、这种、组织、作风(3),成绩、充分、出、传达、从、大、大会、大家、但是、地、对、个别、各、关系、关于、官僚、好、讲、讲话、开、看、空话、起来、热衷、认识、认为、上下、社会、它、探索、提高、推动、推进、协调、一、一下、意义、于、与、则、真抓实干、抓(2),必然、必须、变革、并、波及、补充、不、不得、不够、不好、步调、部门、部门、部署、才、财力、参考、参与、层、铲除、扯皮、承担、创造、存在、打、大量、当然、导致、到、得、点、多、二、方面、干、感、感、刚才、岗位、搞、个、各位、各自、更、更加、供、官腔、光、广度、后、互相、还、环节、环境、回去、会、会议、获得、及、几、坚决、肩负、将、降低、脚踏实地、今天、精神、就是、具体、具有、开拓进取、困难、理解、力度、历史、例外、列入、领域、楼、路子、落、没有、每、能、齐抓共管、轻、去、人力、日常、日程、如何、如何、三、上传下达、少、深度、生活、实处、实践、实事、实效、适应、受、顺利、说、思考、思想、四、提、添砖加瓦、条件、同心同德、投入、团结、推诿、威信、为、文件、五、五点、武器、物力、物质、现象、消除、效率、形成、形式主义、宣传、要求、一场、一点、一个、一切、一样、一致、已经、以及、以上、议事、意见、因此、殷切、尤其、有力、有目共睹、有些、舆论、遇事、远远、在座、责任、扎扎实实、召开、这里、这样、振奋精神、证明、执行、只有、指导、中、重、重视、自豪、总之、最、左右(1)
出现率较高的语言成分中,句型主要有祈使句、“是(……的)”字句、“把”字句、“对”字句;词类方面,我们采用ICTCLAS2012自动分词和标注分析,得到的结果是:名词93个、代词46个、介词21个、动词187个、助词48个、副词35个、连词17个、形容词41个、时间词5个、数量词14个、方位词9个。
词例的频率,每100字出现10次以上的词例从高到低依次为:“的”39次、“工作”31次、“要”21次、“是”14次、“同志”11次。这些可看作“工作报告”高频词。平均句长为12.68字,平均每11.38个音节停顿一次。
下面是这份讲话稿中一些主要的或者具有特征性的语言成分及其比配:
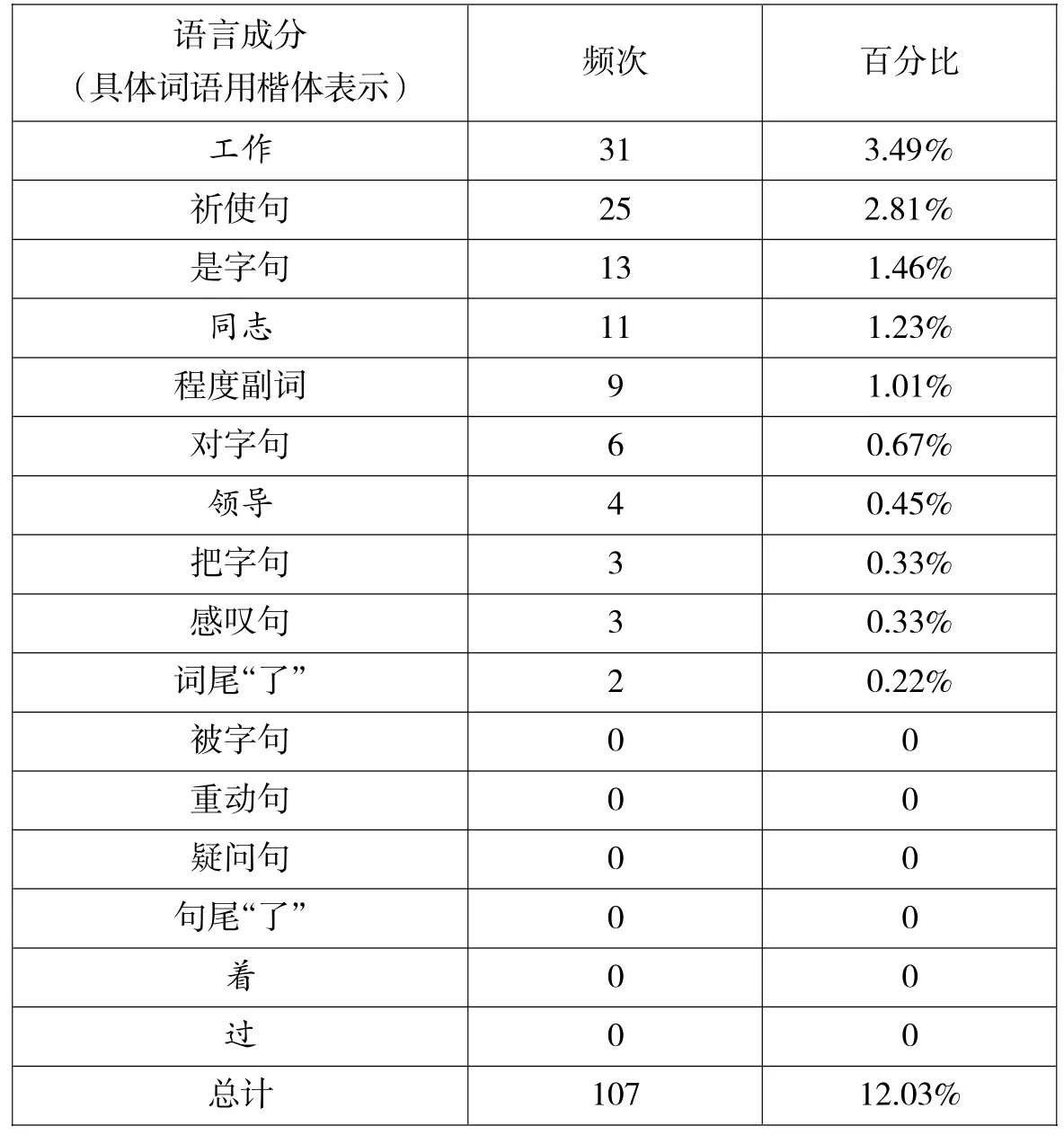
表1:《官场万能讲话稿》中不同语言成分的统计
以上统计还很简单。如果要看出这类语体的语言要素区别性特征,至少还需要做两件工作:
一是选取相同语体的类似语篇进行相应的统计,观察二者是否能互相印证,如果有出入,需要对统计项目进行调试,如增加某些统计项目,重新计算。
二是选取不同语体的语篇(语体差别足够明显),对其进行类似的语篇统计,观察它们之间的差别,证明是否是这些差别造成了该语体的差别。有关这个问题我们在下一小节继续讨论。
我们相信,构成不同语体的语言单位一定有着较为明显的差别,这些差别不仅体现在具体的用词上(词例在语篇中的比例非常重要,下一节具体讨论),还体现在对句法结构或句式的选择上。如“万能讲话稿”中祈使句、“是”字句、“把”字句和“对”字句就相当显著,而被动句和重动句等就几乎不出现。寻求不同语体在语言单位和结构的选择方面所具有的明显的倾向性,是语体研究构成条件的重要课题之一。
2.寻找语言要素在不同语体文本中的比配
我们在寻求特定语体对哪些语言要素有所选择的同时,还需要调查的是,这些所选择的语言要素在不同语体文本中的比配,即某些语言要素与不同语体语篇与总字数的比率。如果没有语言要素的比率,语体之间的差别很难区分出来。
目前,学界对某些语言成分在各种语体中的分布或比配现象的研究还仅仅是一些零星的工作,国内外学者都对该现象有所关注,写作教学界似乎关注得更多。下面是Hyland(2005:102)所统计的教科书与学术论文在使用元语标记方面的差别:

表2:教科书与学术论文在使用元语标记方面的差别
Biber&Conrad(2009:75)统计了英语口语样本(总字数5580个)和学术论文样本(总字数8750个)中名词、代词和形容词的数量,名词分别为1060、2538个,代词分别为837、184个,形容词分别为123、744个。各类词在两种样本总字数中的比重分别为18.96%、29%,15%、2.1%,2.2%、8.5%。英语口语体中代词的使用比例几乎为学术论文的七倍多,相反,口语体中的形容词却只有学术论文中的四分之一强。
而英文小说和报纸每百万句中简单过去体、现在完成体和过去完成体三个时体标记的使用,大约分别达到了 62.5、35 次,4、7 次,6、2.5 次(Biber&Conrad2009:77)。小说中的简单过去时比报纸多出将近一倍,使用率也较高。而现在完成体的使用上小说比报纸少得多,使用率也较低。过去完成体在小说和报纸中的使用都很低,但小说却是报纸使用量的一倍多。
英文报纸和小说每百万字中在使用名词和人称代词数量上的差别,名词大约分别为22、33万,人称代词大约分别为9、3万(Biber&Conrad2009:77)。小说中的名词比报纸少得多,约为报纸的2/3,但人称代词相反,虽然使用率不及名词,但小说中人称代词约为报纸的三倍。
在英语的谈话和学术文章中人称代词和词汇动词(非短语动词)的数量,人称代词在口语中每百万字超过16000次,而在学术文章中只有不足4000次,但词汇动词在谈话中每百万字为12000次强,而在学术文章中却超过8000次。换句话说,学术文章中使用的词汇动词是口语中的两倍多。
再来看动词、名词、形容词、第一人称代词、第二人称代词和第三人称代词分别在谈话、电子邮件、短消息、课堂教师语言和教材中的使用频次(Biber&Conrad2009:219):
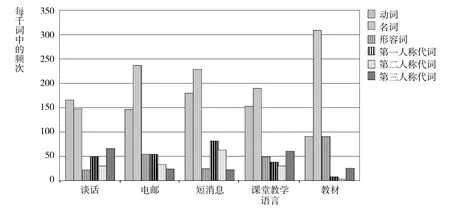
图2:动词、名词、形容词和人称代词在不同语体中的使用频次
在所有的样本中,名词的使用率最高,这很容易理解。但是在形容词的使用上,差别很大。短消息和谈话中形容词最低,而教材中最高,其次是课堂教师语言。动词、第一人称代词和第二人称代词在短消息中最多,在教材中的使用率最低。第三人称代词则在谈话和课堂教师语言中最多。
金立鑫、白水振(2003)统计了人民日报1998年1月1日至1998年1月31日1,860,540字的语料中“着”、“了”、“过”的频率,结果显示:词尾“了”10,001 个(0.537%),句尾“了”1,248个(0.0677%),“着”1,660个(0.0892%),“过”451个(0.024%)。《围城》总共 226023字数中,词尾“了”1296个(0.573%),句尾“了”1411个(0.6242%),“着”649个(0.287%),“过”484个(0.214%)。
运用统计方法对同一语体或不同语体中文本进行统计,从统计结果的趋向性可以发现某些语体所配备的语言要素以及这些语言要素在特定语体中的比例。这种要素与比例关系应该是语体的必要条件之一,弄清楚这些语言要素及其比配是发现语体构成研究的核心工作之一。
3.强制性格式以及韵律等区别性特征的抽象
强制格式是任何事物表现出的最典型特征,如同鸟类的羽毛和翅膀,鱼的鳃和鳍,除非特别的“穿越”或错配(如小说《马桥词典》),正常情况下某类事物都有其较为显著的外部特征。文章同样如此。文章最为显著的外部特征便是其“格式”,典型的如借条、收据、通知,如果这些词出现在一个语篇的顶部并独占一行,那么该语篇的语体通常都能得到绝对倾向性的确定。但也有些语体并没有这类独特的区别性特征用语,单从标题上很难判断其语体类属,还有些文章甚至没有标题,例如书信,留言条等等。但这些文本同样也有一些权重度极高的专属标记和格式,例如书信和留言条中的称谓语独占一行,最后的落款和日期。还有些文本中有“特此批复”“此呈……”以及独占一行并加句号的“同意”等等,这些都是权重度极高的专属标记。这些成分的权重度如何确定,它与其他语言要素之间的关系如何,还需要进一步讨论。
具备某些高权重度成分的文本并非一定是典型的或好的某一语体文本。某一语体文本要求在词汇、语法等许多要素上保持一致,如果这一点做不到,该文本不是一个典型的或好的特定语体的文本。但可以说,强制性格式在所有语体要素中是最为显露也最容易归纳或抽象的。
或许以上所讨论的语言成分在语体中的选择和比配问题是语体研究中最为关键也是比较复杂的问题(当然,某一典型的语体除了合理配备以上所讨论的这些语言要素之外,可能还有其他一些要素也制约了某些语体的形成)。
极端典型的是中文中的格律诗。一种典型的格律诗必须满足两项基本要求:一是强制性格式,主要是每首诗(或词)的句数,每个句子的长短字数;二是每个句子的韵律,主要是每个字的平仄要求、节奏要求和句尾字的押运要求。如果违背了特定词牌韵律的要求,这样的文本便不是特定的诗(如七律、七绝)或词(如念奴娇、水调歌头、蝶恋花、江城子等)。
韵律通常与比语体更下位的语篇类型——“风格”有关。例如,一篇同样的语体文本如散文,因为韵律的不同,可能表现为不同的风格。比如韵律调型主要在低音部展开的与主要在高音部展开的会表现出不同的情绪,前者低沉甚至阴暗,后者高亢或明快。除了调型的选择,还有节奏上的选择。一个文本以长句为主还是以短句为主,长短句结合的频率或长短句之间的间隔规则,都可能影响一篇文本的风格。这个问题或许放在风格学中讨论更适合一些。
五、余 言
从上面的讨论可以看出,语体本身是一套规则系统,它存在于较为发达或较为成熟的自然语言系统中。语体学家的主要工作在于发现这些规则(不同语体的不同规则)。这属于基础研究。语体规则的应用领域至少涉及三大领域:
一是社会应用领域,为社会各行业在撰写该行业文本时提供指导意见;
二是教育领域,为本族人和外族人提供各语体的写作规则,为翻译实践提供指导;
三是计算机自然语言处理领域(霍四通2000),为计算机自动识别语体类型和生成特定语体文本提供规则。
以上讨论可以发现,语体研究是语言学研究的核心领域,到目前为止它具有其他所有分支学科所没有的更令人激动和神往的更为广袤的发展空间,有太多的分支领域还没有人涉足,有太多的工作还没有展开,需要更多的学者去开发去挖掘去考察去统计从而去发现其内在规则。
从普通语言学角度来看,不同语言的语体及其构成要素以及要素的比配并不完全相同,语言之间的语体比较也很值得研究。语体共性甚至语体类型或许也是一个研究方向。
放弃传统的内省的研究方法,走向科学的定量研究,走向实验室方法——语体学研究就有可能走向一个前所未有的、充满科学之美的广阔天地。
注 释
①Register的缩写。
②Element的缩写。
③Proportion的缩写。
④Format的缩写。
⑤Scansion的缩写。
⑥屈承熹先生2012年7月26日在复旦大学召开的“交叉视野中的语体研究”学术讨论会上的发言。
附 录:官场万能讲话稿
同志们:
今天,我们在这里召开的XXX会议,我认为是十分必要的,这对于XXX工作的开展,具有十分重要的指导意义。对于刚才某某同志,以及某某同志的讲话,我认为,讲得非常好,非常深刻。希望在座的同志,认真领会,深刻理解。回去后,要传达某某同志及某某同志的讲话精神,并认真落实。真抓实干,推动XXX工作的顺利开展,努力开创XXX工作新局面。
对于XXX工作,我提几点补充意见:
一、对于XXX工作,我们要从思想上提高认识,充分领会XXX工作的重要性和必要性。目前,XXX工作已经开创了很好的局面,获得了很大的成绩,这是有目共睹的。但是,还是要从深度和广度上更加推进XXX工作。我看,最重要的一点是:提高认识!各级领导要充分领会XXX工作的重要性和必要性,各级组织要加强关于XXX工作的宣传力度,形成上下“齐抓共管”的局面,只有这样,XXX工作才能更上层楼。
二、对于XXX工作,要加强落实,要把工作落到实处。目前,有个别同志、个别部门,存在一个很不好的现象,就是:热衷于搞形式主义,热衷于开大会,传达文件。当然,开大会是必要的,上传下达也是必须的。但是,光是讲空话。打官腔,是远远不够的。对XXX工作,要真抓实干,加强落实。各级领导要把XXX工作,列入日常议事日程,要具体部署。认真执行。各级领导要为XXX工作,创造必要的物质条件和舆论环境,扎扎实实推动XXX工作的开展。要抓出实效,抓出成绩。
三、要加强协调工作历史证明:团结,是我们消除一切困难的有力武器。关于XXX工作也一样,各级领导要加强协调工作,要把上下,左右,各方面,各环节有机结合起来,步调一致地推进XXX工作的开展。目前,有些部门,遇事推诿、互相扯皮,这种官僚作风,十分要不得!这种作风,轻则导致工作效率降低,重则影响我们的威信。我们要坚决铲除这种官僚作风。
四、要在实践中探索XXX工作与市场经济有机结合的新路子。XXX工作与市场经济有没有关系,我看是大有关系。市场经济是一场深刻的社会变革,它的影响将波及社会生活的每一个领域,XXX工作也不例外,它必然会受市场经济的影响。因此,如何适应市场经济的要求,如何和市场经济有机结合起来,希望大家认真地思考一下,去探索一下,这是十分有意义的。
五、参与XXX工作的同志,要有自豪感和责任感。同志们,对于XXX工作,我们是非常重视的尤其各级组织也投入了大量的人力,物力、财力,同志们,你们承担的XXX工作,是肩负了各级组织对你们的殷切希望的,希望你们要脚踏实地同心同德。努力工作,在各自的岗位上努力工作,添砖加瓦!
以上五点,供各位同志参考。总之,大家要振奋精神,多干实事,少说空话,开拓进取,努力开创XXX工作的新局面。(http://www.sowerclub.com/ViewTopic.php?id=78050)
猜你喜欢
天津外国语大学学报(2021年1期)2021-03-29
疯狂英语·初中天地(2021年11期)2021-02-16
疯狂英语·初中天地(2021年12期)2021-02-12
高中生·天天向上(2018年1期)2018-04-14
中国修辞(2016年0期)2016-03-20
长江学术(2016年4期)2016-03-11
中国修辞(2015年0期)2015-02-01
当代修辞学(2014年1期)2014-01-21
当代修辞学(2014年1期)2014-01-21
西南学林(2013年2期)2013-11-12
