
经济变量动态关系的时间序列方法研究
2011-10-30 03:31文书生
重庆理工大学学报(社会科学) 2011年6期
文书生
(重庆理工大学经济与贸易学院,重庆 400050)
经济变量动态关系的时间序列方法研究
文书生
(重庆理工大学经济与贸易学院,重庆 400050)
阐述了GETS、VAR、VECM三种时间序列自回归方法的建模程序和对经济变量的预测效果,并对三种方法各自的优势和缺陷进行了评述。根据实证经验,三种方法各有所长,当不同方法预测和分析的结果与实际相差太大时,应同时运用多种方法,进而得出综合的结果。
时间序列;GETS;VAR;VECM
自从时间序列方法成为研究宏观经济问题的主要手段以来,预测和估计经济变量的计量方法日益增多,以自回归形式出现的就有:GETS,Engle-Granger(1987)的两步程序法,Philips—hansen(1990)全面修改的 OLS估计法,Pesaran和Shin(1995)的边界检验法,VAR,VECM等。目前,西方国家主要采用GETS,VAR,VECM三种方法来研究和估计宏观经济变量的长期和短期关系。国内学者运用这三种方法研究我国的经济和金融问题的现象也日渐增多。这三种研究方法在统计技术和模型描述上都有很多相似的地方,但它们在模型产生的方法论上存在很大的争论,因此在实证中会给研究者带来选择的困惑。本文根据国内外的一些相关资料和研究经验对这三种方法从方法论角度加以探讨。
一、经济变量动态关系的GETS方法
GETS方法以传统计量经济学为基础,在时间序列对经济学产生重大影响之前就发展起来了。GETS与传统的Cowles Commission方法并不冲突,基本上还是一种动态结构方程的估计方法。使用线性结构方程(LSE)方法的计量经济学家关心经济理论的静态均衡与用来检验和估计理论的假设数据之间存在方法上的冲突。这冲突的原因是用来估计理论关系的数据来源于非均衡状态的现实世界,而现有的静态经济理论对动态调整几乎没有任何解释作用。这种冲突在过去通常用随意的滞后结构,如误差纠正和Almon滞后来解决。后来,Saragan教授认为正确的方法应该是使用数据来确定动态调整结构以便它能符合数据生成过程(DGP)。这是一个有效地协调理论与数据之间存在冲突的方法。用一个简单的例子来说明GETS,假设研究理论的内容是消费(C)和收入(Y)之间存在下列关系,

由于是均衡关系,与数据生成过程DGP相吻合的动态调整方程开始用一般的、详细的模式进行搜索。这个初始的一般模式被称为广义非限制模型(GUM)。一个优化的广义非限制模型可以表示为:

这也是自回归分布滞后模型(ARDL)。在ARDL方法中,滞后结构由滞后搜索程序来确定,这个程序也可以用来确定GUM的滞后长度。方程(2)中消费C只有一个滞后期。理论上的消费与收入关系的均衡可通过设置所有变量的滞后增量为零来进行实现。这就是零点均衡条件。例如方程(2)的第2期,其均衡是
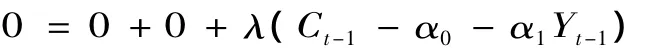
因此C*=α0+α1Y*,方程(2)中的滞后变量的表达式就成了误差纠正模型(ECM),它意味着当系统在近期偏离了均衡点时,在当前期以λ的速度向均衡点回补。λ应为负值,它的绝对值不限于一个单位。这表明有时会过渡调整。从这一角度看ECM仍是一个线性结构方程的概念。W.B.Phillips教授第一个提出了这个概念并用它确定政策工具中所需要的调整值,以便能使目标变量更接近它的期望值。后来,ECM又运用在其他许多方面,包括GETS和Granger的协整概念中。
随后,通过剔出不重要的变量,对估计系数设置限制条件形成方程(2)的简缩形式。由此来看,GETS就是一个从一般模型到特殊模型不断探求过程。它需要研究者在每一个约化阶段作出判断,直到获得最简便的形式。GETS可以使用Hendry Krozig(2001)最新的自动选择模型的软件PcGets来计算。变量剔除检验在一些标准的软件如Microfit中都有简便的程序。
然而,GETS方法不能对变量的序进行前测。一般说来大多数宏观经济变量都是I(1)序列(一阶单整序列),一阶差分后变成I(0)。在(2)式中既有I(0)又有I(1)变量,这就是一个不平衡的方程,这样会得出一些虚假的结果,但Hendry认为如果潜在的经济理论是正确的,那么滞后部分的变量就必定是协整的,因此I(1)水平的变量的线性组合是I(0)。如果潜在的经济理论不正确,其滞后期部分估计的系数就与期望的相反,例如(2)式中的α1就可能大于一个单位,或者不显著,甚至为负,产生难以置信的值。还有一种批评是,在GETS方法中,使用可随意改变的程序,没有其他方法使用的程序严谨。
GETS的另一种表达形式是由Pesaran和Shin(1995)提出来的。这就是有名的ARDL方法(自回归分布滞后模型)。它不需要对变量的单整序进行检验,可以运用修正的F检验对变量间的协整关系进行检验。这个方法也有其局限性,就是由于是大量的不确定性统计检验,其关键值的确定需要样本量在500和20 000之间,有时出现没有协整的虚无假设就可能存在既不接受也不拒绝的情况。Shin自己也觉得小样本调整的关键值会很大,难以拒绝虚无假设,不同阶的变量是协整的,也难以让人接受。
二、经济变量动态关系的VAR模型
VAR模型是处理大规模经济变量的经济计量模型,广泛运用于经济预测方面。VAR把所有的变量都当成内生变量。它的一般模型为:
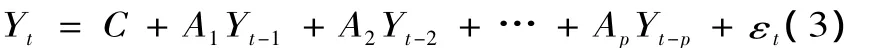
Y为要研究的经济变量的向量,Yt=(y1t,y2t,…,ynt)' ,C=(c1,c2,…,cn)',A1,A2,…,An为 n × n 系数矩阵 εt=(ε1t,ε2t,…,εnt)',且 εt~ N(0,Σ)。
我们用Simth(2000)的例子来说明向量自回归的理论推导。忽略货币和收入模型中的名义利率,假设目标是建立实际货币和实际收入之间关系的模型。出于简便需要不考虑利率,根据商品和货币市场理论,货币和收入方程可表示:

式(4)和式(5)中的T为时间趋势项。过去常用OLS估计式(4)并把它解释为以y作为外生变量的货币需求方程。同样把mt作为外生变量方程,式(5)就被当作了收入的货币方程。与此相反,VAR把他们都当成了内生变量。为了减少识别问题,假定式(4)和式(5)都具有均衡关系,引入偏向调整机制,推导出下列短期调整的形式:

将式(6)和式(7)的mt和yt相互代换,得到相应简化方程:
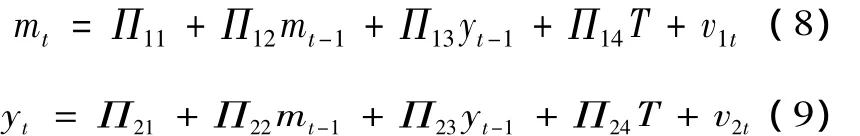
式(8)和式(9)矩阵形式是
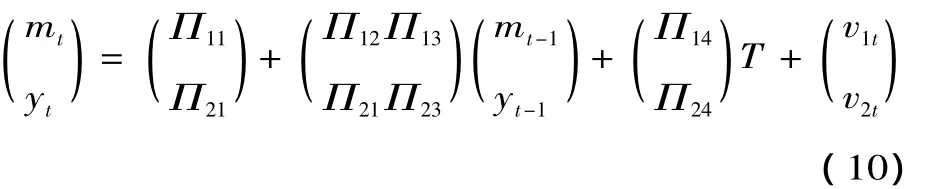
注意,在简化方程中消去了当前期变量yt和mt。原则上式(6)和(7)中的8个结构系数可用式(8)和(9)中的8个简约方程系数识别,然而这种识别借助偏调整机制是可行的。
像GETS一样,VAR方法也因其估计的调整机制的有效性受到质疑,因为它可能与DGP理论不一致,VAR也提出用一般的动态形式表示ARDL来获取简化的单方程。
由于简化的方程m和y都是内生的,式(7)和(8)可以看成是简单VAR模型的ARDL模式。通过VAR最优阶的检验,可以确定VAR模型的阶,但不可能识别VAR模型单方程的结构系数。
一般来说VAR模型的系数个数是L×N2,L是滞后阶数,N是变量数。由于这个原因,用有限的30~40年的年度数据,发展中国家很难运用VAR模型来预测宏观经济变量。
如果样本容量合适,VAR模型的优势就是比其他的在Cowles Commission方法基础上建立的大规模结构模型产生的预测效果要好。但也有人持反对意见,如Bischoff(2000)就认为纠正的大规模结构模型比VAR对美国1981—1996年的经济活动预测效果好些。
三、经济变量的协整关系和VECM模型
Johansen(1988)创建的方法是在实际工作中使用最广泛的一种方法。运用这种方法建立的模型叫做向量误差纠正模型或协整VAR模型(CVAR),VECM可以看成是特殊的VAR模型,它的结构系数是可识别的。
VECM方法的合理性在于强调结构系数的识别和检验以及与潜在理论的关系。简单的VAR模型不需要识别结构系数,也不作严格的单位根检验。
像VAR一样,VECM把所有变量都当成内生变量,但与此不同的是VECM把变量定义在对特定理论有关的那些问题上。例如,如果我们对估计货币需求感兴趣,这个理论的含义是货币的实际需求(m)依赖于实际的收入(y)和名义利率(r),这三个变量形成一个系统。根据VECM,m是因变量,y和r是自变量的假设则需要检验。因此开始用一般的ARDL来表述三个变量各自的小系统。为了简便,略去了变量r的方程,m和y两个变量的系统的模型类似于式(8)和(9)
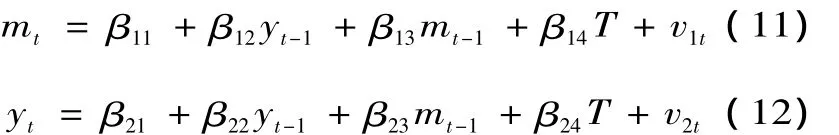
首先必须执行单位根检验证明m和y是I(1)序列。如果是,上述系统就可以变成下列形式,

注意Δmt和Δyt都是I(0),如果这些变量水平都一致,都是I(0),根据潜在理论的定义,它们就是协整的。它们相同水平的线性组合是协整向量。在考虑估计程序之前,意识到VECM所强调的重点是有用的。这就会认为现有的货币需求理论做了一个武断的假设即y引起m。在现实世界中,m和y都一直在变。因此因和果的关系在两个方面都有可能,这必须经过检验。这些因果关系的检验可用下列较简单的方法来做。系统中协整向量的数量,最多为系统中的变量数减1。因此在m和y两个变量的系统中,要么有一个协整变量要么一个也没有。假设有一个协整向量,因果关系的检验如下。
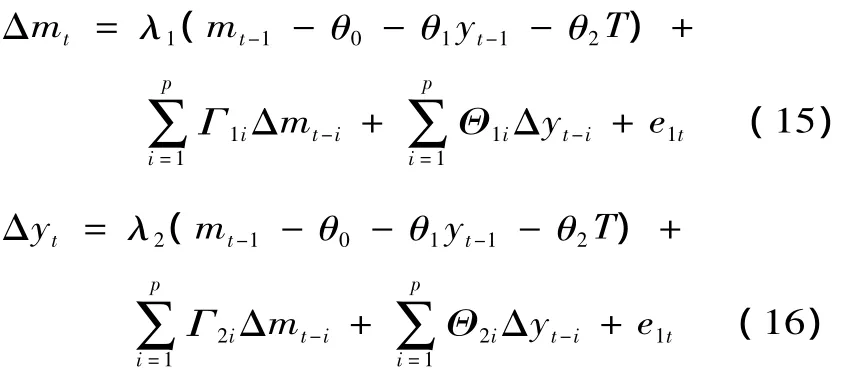
此处λi度量了这种水平的变量对于过去偏离均衡值的调整速度,其水平期与 GETS中的ECM部分是一样的。如果λ1在式(17)中是显著的,而λ2在式(18)中是不显著的,那么就可以推导出,对于y,m就不足以解释方程中的参数,因此y就当成了外生变量(因为m不影响它的值)。这就是弱外生性检验。如果 λ1和 λ2都显著,式(17)和(18)通过对其参数设置交叉方程限制,VECM就近似于VAR,因而也就不知道估计的参数是货币需求的参数还是金融收入方程的参数。(一般来说,把协整向量解释为货币需求而没经过因果检验,很难说这种解释是有效的)。如果λ1和λ2都不显著有可能没有任何协整向量,这意味着现有的理论不成立。
对VECM模型估计程序不加详述,因为大多数计量经济学软件都包含了这些程序。VECM估计的方法步骤总结如下:
(1)用单位根检验相关变量的平稳性并确定它们是I(1),一阶差分为I(0)。
(2)搜索VAR的最优滞后程度,确定VAR模型的阶数。
(3)使用VAR最优阶检验协整向量。如果协整向量数等于变量数,那么变量在其水平上是平稳的,I(0),方程用标准的传统方法就可以估计了。如果没有协整向量经济理论就可能不正确,或许是其他相关变量从模型中漏掉了。假如我们找到了一个协整向量,就可以把协整向量解释为货币需求,但也可以解释为是收入方程和利率方程的货币供给。因此有必要做外生性检验。
(4)需要在ECM基础之上建立货币需求的短期动态方程。为此,要把从式(15)中获得残差表示为ECM。
(5)通过使用变量的删除检验,删除系数不显著的变量寻找简化形式得到最终的短期动态方程。符号λ应该为负,它的绝对值大约就是向均衡调整的速度。
四、三种自回归方法存在的局限
对于不同的方法,三种方法的创立者,都各持己见,并相互指责。Sim(1980)不赞成使用VECM方法,认为使用单位根检验效率很低。他说,坚持对数据进行单位根的检验,然后建立最终模型来满足传统的统计检验的显著性,是不正确的。
VAR能够很快收敛,能够达到研究者期望的结果,但它在模型的推论上,没做数据的统计特性分析,因此缺乏严谨性。GETS的支持者Hendry(2000)认为,Sim的VAR就是让一个人把所有的垃圾都扔进一个模型里,随便堆放就作出推断。事实上,在八九个水平的协整变量模型中多重共线性都很容易产生。但是得到的结果却是不可解释的。
协整能够解决非平稳经济数据的相关问题,而大多数经济变量都不是I(0),在进行协整检验后,具有协整关系的变量才有长期均衡关系,符合了经济事实。但协整也有局限性,当经济变量的数据很长时,几乎所有变量都变成协整了。Hendry认为不应该把协整模式化。他说,如果让抵押股份远离至无穷,建筑材料的存货量远离至无穷,它们之间的比例基本会停留在一个90%的常量范围。在这种情况下,协整就是毫无意义的。协整结果是当事人想要达到的目标,他们想要达到哪里,它们就会停在哪里;它们不再那里,也会移动到那里。
Sim(2000)对协整概念和CIVAR或VECM也持批评态度。他认为用偶然的、天真的方式产生理论是不值得推崇的。例如看到M、P、Y和r之间表现出了协整关系,然后就把讨论的概率当作货币需求关系。这就是一种错误。他认为协整分析对识别变量没有多大帮助。
当今有运用最多的SVAR(结构向量自回归)弥补了VAR只能做预测的单一功能缺陷,能够解释经济变量的波动,以及各变量之间的传递性,但Hendry认为SVAR模型识别的精确度和模型结构参数存在问题。他认为波动不是有结构的,永远不能解释。波动是由模型遗漏的事物组成的,它从规范的属性演变而来,从数据的测量结构中而来,从使用过的信息和设置的限制条件而来,它永远也不会有结构,不能识别。
以上三种不同的方法都是基于自回归的形式,一些时间序列专家对他们的有效性也持怀疑态度。许多应用经济学家力求拟合向量自回归形式VAR。但对于一些计量经济学家来说,VAR就意味着非常可怕的回归(Very Awful Regression)。但是,如果他们能够使反应长期关系的协整限制条件具体化,并据此加以调整,还是值得推崇的。向量误差纠正机制在这方面就有很大的影响,因为它能够让研究者利用Johansen设计的程序检验协整关系数。
五、研究经济变量长期关系计量方法的选用
由以上的分析可以看出,这三种方法在方法论、建模程序和预测经济变量的效力方面,各有优劣。给哪一种方法一个最优的判断都是不合适的。实用主义的观点认为当相反的两种观点都被证明是明确的时候,将两者结合起来加以研究,才是佳的选择。如果一个研究者都明白了这些不同方法,将不同的方法加以融合,也将是处理归纳数据的一种技术。
我们认为最好是同时使用三种方法来估计和检验有关的经济理论关系。如果它们都产生了相同的结果,那就更能增强我们研究的信心。如果产生了冲突就选择更可靠的一种。尽管VECM看起来复杂一点,但它不难,因为大多数软件都附有相关程序,减少了计算问题。尽管如此,VECM比GETS的要求更高,特别是在计算理论关系时要研究者具有一定理论背景和相关知识。而且,内生结构突变的单位根检验使得VECM变得越来越复杂,特别是在没有季节调整的月度和季度数据中存在显著的季节模式。尽管有季节单位根检验和协整方法,那也只是是计算上的要求。因此在许多的应用中当季节数据不可用时,这些数据就是季节调整。这就需要季节调整程序来修正。
从有限的资料中,我们了解到用 GETS和VECM同时估计的货币需求有相似的结果。但也有些报告指出,在汽油消费和汽油价格的调整方程中用月度数据,GETS给出的结果比用Granger两步法估计得出的VECM结果要好。然而由于实证结果的数据的有限,这种说法的推广应该谨慎,希望有更多的研究者运用三种不同技术,报告更多的结果。有一些资料显示,GETS方法比较受应用经济学家的青睐,在实证研究中应用较广泛,因为它便于使用,而且它的结果也与VECM的结果吻合度较高。但目前运用SVAR的也逐渐多了起来,主要是因为它能够揭示系统中的波动情况,便于研究者找到各种变量之间的相互关系。
[1]李子奈,叶阿忠.高等计量经济学[M].北京:清华大学出版社,2000.
[2]Bahmani-Oskooe M,Rehman H.Stability ofthe money emand function in Asian developing countries[J].Applied Economics,2005:773 -792.
[3]Engel R F,Granger C W J.Cointegrationand error correction representation,estimation and testing[J].Econometrica,1987,251 -276.
[4]Hendry D F,Krolzig H M.Automatic EconometricModel Selection[S.l]:Timberlake Consultants Press,2001.
[5]Smith R P.Unit Roots and all that:the impact of timeseries methods on macroeconomics[M].Backhouse,R.E.and Salanti,A.Macroeconomics and the Real World.Oxford:Oxford University Press,2000.
[6]Pesaran M H,Smith R J.The interactionbetween theory and bservations in economics[J].the Economicand Social Review,1991:1 -23.
Research on Time Sequence Methods for the Dynamic Relationships of Economic Variables
WEN Shu-sheng
(School of Economics and Trade,Chongqing University of Technology,Chongqing 400050,China)
This paper expatiates upon the modeling procedures of three time sequence auto-aggression methods of GETS,VAR,and VECM,and their predicting effects for economic variables,and reviews their advantages and disadvantages.Based on empirical experience,the three methods have their own advantages.Different methods can be used to achieve synthetic results when there are big differences between predicting results and the facts with different methods.
time sequence;GETS;VAR;VECM
F224
A
1674-8425(2011)06-0032-05
2010-10-18
文书生(1964—),男 ,博士,教授,研究方向:劳动经济学、人力资源管理。
(责任编辑 邝坦励)
猜你喜欢
中学生数理化·七年级数学人教版(2022年5期)2022-06-05
新高考·高一数学(2022年3期)2022-04-28
中学生数理化·七年级数学人教版(2021年5期)2021-11-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
新世纪智能(数学备考)(2020年12期)2020-03-29
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
高中生学习·高三版(2016年9期)2016-05-14
