
基于遗传算法的染色体编码的分析
2010-11-03 06:06吴焱岷
重庆电子工程职业学院学报 2010年1期
吴焱岷
(重庆大学 计算机学院,重庆400044;重庆电子工程职业学院,重庆401331)
基于遗传算法的染色体编码的分析
吴焱岷
(重庆大学 计算机学院,重庆400044;重庆电子工程职业学院,重庆401331)
遗传算法为解决复杂问题,特别是NP类问题提供了一种全新的思路,其编码方式也将在一定程度上决定算法效率的高低和程序设计的复杂程度,需要针对想要解决问题类型的不同而采取不同的编码方式。
遗传算法;编码;值类型;事务类型
遗传算法的概念最早是由Bagley J.D在1967年提出的,而开始遗传算法的理论和方法的系统性研究在1975年开始,这一开创性工作是由Michigan大学的J.H.Holland所实行。遗传算法简称GA(Genetic Algorithm),在本质上是一种不依赖具体问题的直接搜索方法,其基本思想是基于Darwin进化论和Mendel的遗传学说。
Darwin进化论最重要的是适者生存原理。它认为每一物种在发展中越来越适应环境,物种每个个体的基本特征由后代所继承,但后代又会产生一些异于父代的新变化。
Mendel遗传学说最重要的是基因遗传原理。它认为遗传以密码方式存在细胞中,并以基因形式包含在染色体内。每个基因有特殊的位置并控制某种特殊性质,所以,每个基因产生的个体对环境具有某种适应性。基因突变和基因杂交可产生更适应于环境的后代。经过存优去劣的自然淘汰,适应性高的基因结构得以保存下来。
遗传算法最大的特点莫过于可以绕过复杂的数学推导而采用最直接的方式在有限空间中搜索结果。例如求函数 f(x)=x*sin(10πx)+2 在(-1,2)区间上的极大值,按照常规思路,需要对函数求导,找出函数的变化趋势和拐点,才能确定最大值的位置。对于相对简单的函数,采用这些数学的方法还没有太高的难度,但是对于复杂的函数,则需要较为深厚的数学功底,同时也增加了程序设计的复杂程度。
对于GA,采用一套全新的思路,首先任意给定一组随机值x,由此开始进行演化,这些值就是代表一系列原始生命,这些生命是否可以延续,取决于他们的适应程度。将这些随机值带入函数中进行运算,对得到的一系列函数值进行排序,求最大值,可以认为值较大的函数值对应的x接近我们所需要的结论,这些结果可以保留;反之,对于另外一些函数值较小的x,则表明应该被淘汰。
第二步就是按照Mendel的基因理论,对这些将被淘汰的x进行演化,演化分两步进行:
(1)交叉。两个x值交换数据,类似生物界的交配,染色体进行重新重组,交换基因以期得到新的品种,新品种可能更加适应环境而得到生存的机会,也可能向相反的方向发展,从而失去生存的机会。因此通过某种方式得到新的x的值可以导致函数值增大,也可能导致减小,他们都将参加新一轮的竞争。
(2)变异。单一的x值进行自身的调整,这类似于生物界的染色体发生基因突变,突变后的基因也可能导致物种更加适应或更加不适应环境,因此通过突变方式后要重新评估函数值以决定新的x值的去留,同样新的x值也必将参加新一轮的竞争。
通过一系列操作,我们始终保留函数值较大的一系列x,如同生物竞争中只有最强的个体才能生存下来一样,最终我们可以得到最佳答案。
按照上面的思路,我们任意产生100个随机数,经过100代的进化,得到如下结论:
在第27代最早出现最佳运算结论:

共使用4.828125秒,起始时间:21:54:08.31,结束时间:21:54:12.859
经过反复测试,结果可以稳定x=1.85附近,这和理论值也是非常近似的。那么GA是如何保证这种收敛性的呢?原因就在于它的编码方式可以很好地与基因理论相融合。
显然,由于x的编码方式千差万别,因此J.H.Holland本人也提及采用二进制才是最佳方式,这样做的好处有两点:
1.数据在计算机内部就是采用二进制方式,这样的编码方式与计算机内部的数据表示相吻合,便于计算机的处理。
2.如同染色体的基因,每一位二进制数据单元就是可以进行操作的最小单元,便于对交叉与变异这两种基本的遗传现象的模拟。
正是将生命遗传、进化的规律运用到程序设计中,所以程序运行符合自然规律,可以得到理想的结果。
遗传算法在当时提出主要解决科学计算方面的问题,即值类型的问题,采用二进制的形式可以很好的解决编码问题,一般我们这样来进行操作:
不失一般性,我们可以假设在(a,b)区间上搜索某一个结论,假设对于x要求精度为小数点后n位。
首要问题是需要确定染色体的二进制位数,a到b的长度为(b-a),每个待编码的数据保留到小数点后n位,表明1个单位数据中包含10n个待编码的数,那么整个探索空间中就有(b-a)*10n个需要编码的数据,由于采用二进制编码,所以要表示这么多数据,需要至少m位,则有:

所以 m 可以由 ln2((b-a)*10n)的结果向上取整表示,这样m位的二进制数至少可以表示出(b-a)*10n个数据了。
这种编码方式对于科学计算类的问题是非常有效的,因为我们的解空间是连续的,而采用二进制编码方式,我们也可以近似的认为其表示的数值空间也是 “连续”的。这样我们按照基因组成染色体的方式,可以对二进制数据进行重组,以考查哪些基因有利于问题的解决。但是需要注意的问题是,随着GA在更加广泛的领域加以应用,有一个新的情况出现了,即对于事务性的问题,二进制编码同样高效么?
以GA在排课系统的应用为例,如果用二进制表示的话,必须按照定长进行切割p位表示上课教室、q位表示上课时间,每一个课程需要(p+q)位来表示未来课表中的上课时间与上课教室信息,但是由于初始状态是随机的,上课时间和上课教室必然存在很多的冲突或搭配不理想的地方,需要对这些问题进行逐一的统计及处理,那么需要将原来二进制表示的信息还原成原本表示的上课时间、上课教室信息,同时课程表的二维表格被修改成一维空间,这给操作也带来了很多不必要的麻烦,所以有必要对原有的编码形式重新认真考虑。
针对上述问题,没有必要一定采用一维的二进制编码习惯,到底如何表示染色体和基因要视具体情况而定,在排课问题中,我们大可将染色体直接设计成二维模型,表示上课时间、上课教室的二维布局,将课程(含班级、教师信息)填充其中,只要保证一个单元格中仅仅放入一项课程就已经避免了上课时间、上课教室上潜在的冲突的可能性。做了这样的调整后,在进行交叉、变异操作时,也可以以班级或老师为单位进行,而不必像二进制编码一般随机的抽取,这样可以保留较好的基因,加快收敛的速度以取得更加令人满意的结果。
改造后的染色体如下图所示
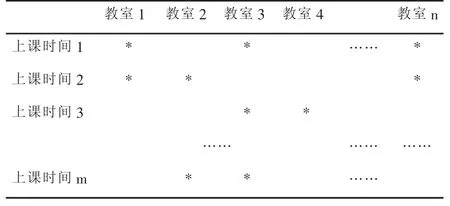
基因的编码可以采用灵活的方式,不一定非要采取二进制形式,因为每一单元格中包含课程、班级、教师等信息,可以用类或结构体将其封装起来,至于课程、班级、教师等信息的编码则可以灵活处理,为了和数据库进行数据的无缝交流,建议采用十进制编码形式,以便与数据库内部的代码保持一致,从而可以省却许多不必要的编码和解码开销。
综上所述,在GA中我们对于染色体的编码不一定要采取二进制的形式,具体要视待解决问题的性质而定:
1.对于值类型的求解问题,可以采用二进制的编码形式,以便保持数据在计算机内部以及染色体表示上的一致。
2.对以事务型的求解问题,可以灵活采用一维或多维的染色体表示形式,对基因的编码,则可以采用更加灵活形式:十进制、字符串、结构体或类等。
任何算法需要随时代的发展而不断的修正,在遗传算法提出之初,我们解决的多是数值运算类型的问题,用二进制的表达形式便于保持基因内在数据与外在表现形式的统一,但是当我们把这种方法移植到事务型问题的求解上时,二进制编码由于本身的缺陷而不足以表达丰富的含义,反而成为绊脚石,我们可以对其编码方式进行调整,以适应问题求解的需要。
在遗传算法提出之机,计算机硬件水平相对较低,需要充分考虑硬件上时间、空间的开销,而如今硬件水平高速发展,牺牲一定的空间、时间而带来程序设计难度的降低也不失是一种可行的方案。
TP39
A
1674-5787(2010)01-0086-02
2009-12-18
吴焱岷(1974—),男,湖北武汉人,重庆大学计算机学院计算机科学技术专业2004级在职研究生,重庆电子工程职业学院计算机应用系党总支副书记,主要从事软件设计、网站建设方面的研究。
责任编辑 王荣辉
猜你喜欢
中等数学(2021年8期)2021-11-22
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
价值工程(2017年22期)2017-07-15
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
电脑知识与技术(2016年36期)2017-04-17
统计与决策(2017年2期)2017-03-20
系统工程与电子技术(2016年4期)2016-08-24
现代计算机(2016年34期)2016-02-28
火控雷达技术(2016年2期)2016-02-06
