
普通话发音错误自动检测技术
2010-10-15 01:38:08戴礼荣
中文信息学报 2010年2期
张 峰,黄 超,戴礼荣
(1.中国科学技术大学电子工程与信息科学系科大讯飞语音实验室,安徽合肥230027;2.微软亚洲研究院,北京100080)
1 引言
近年来,计算机辅助语言学习(Computer Assistant Language Learning,CALL)获得了越来越广泛的关注。在计算机辅助语言学习系统中,给学习者提供一个整体说话水平评估是非常有帮助的。目前,这个方向已经有了很多的研究[1-2]。除了话者的整体说话水平得分以外,提供一个更加详细的具体的发音错误反馈,对于学习者的语言学习有更大的帮助。因此,本文专注于提高普通话的字发音错误自动检测系统的性能研究。
现在的发音错误检测方法的研究主要有两大类。一类是基于语音学知识以及区分性特征的方法,例如Truong[3]利用时长、共振峰和基频作为区分性的特征,Ito等[4]采用基于决策树的多门限来检测发音错误;另一类是基于统计语音识别框架的发音检错方法。在这两类方法中,基于统计语音识别框架的检测方法处于主流位置,本文采用此框架。基于此框架的很多研究集中于置信度标准的设置,其中Franco[5]采用基于隐马尔科夫模型(Hidden Markov Model,HMM)的后验概率得分和基于高斯模型的似然比得分来检测错误发音;Witt[2]采用了一种后验概率的变形方法——GOP(Goodness of Pronunciation)。
在基于统计语音识别框架的检测方法中,除了研究更好的置信度度量外,通过改进声学模型的方法也是提高系统性能的有效途径之一。最初用于自动语音识别(Automatic Speech Recognition,ASR)系统的话者自适应技术能很好的改进ASR系统的声学模型。此技术对于发音检测也同样适用。但是考虑到自动语音识别和发音错误自动检测系统的不同目的,本文采用了说话人自适应训练(Speaker Adaptive Training,SAT)和选择性最大似然线性回归(Selective Maximum Likelihood Linear Regression,SMLLR)的说话人自适应技术,以适用于发音错误自动检测问题。
虽然采用了以上的策略,发音错误自动检测任务仍然是个巨大的挑战。目前的发音错误自动检测任务和与之类似的任务——说话人发音自动评分任务,两者的性能差距非常大,而后者的性能已经能接近专家的水平[1]。一个主要的原因就是,对于发音错误自动检测任务,一般仅通过一个字的发音数据来做判断;而对于说话人发音自动评分任务,可以通过该说话人的很多个字的发音数据来生成一个得分。这提示我们如果在说话人的层次上检测发音错误,将有效提高检测的性能。为此,本文引入了说话人归一化的方法。
本文具体组织如下:第二节介绍系统采用的普通话字发音质量打分方法;第三节介绍通过说话人自适应的方法来提高系统的声学统计模型的检错性能;在第四节中,介绍了通过说话人归一化的方法来改进系统后端;第五节给出了各种方法的实验结果;最后是总结和展望。
2 普通话的发音质量打分
2.1 音素的发音质量打分
本文基于统计语音识别框架,采用HMM统计模型来表示每个音素的标准发音。为了获得某个测试音素的发音质量,很多研究表明对数后验概率(Log-Posterior Probability,LPP)是个很好的参数。由于说话人特性的不同和信道的变化会导致输入信号的频谱不匹配,而该参数受频谱变化的影响较小,能更加集中的反映发音质量。
在实际的应用中,由于声学得分的动态范围非常大,会导致 LPP值仅仅分布在几个很窄的范围内。因此,需要把声学得分做比例化处理,从而使得分具有可操作性。通过引入一个合适的比例化因子α,使得后验概率在0和1之间的分布更加均匀,经过比例化的LPP值在本文中称为比例化对数后验概率(Scaled Log-Posterior Probability,SLPP)。在一个基于HMM的语音识别器中,给定某个音素的观察矢量O和它对应的标注qi,该音素的SLPP值可计算如下:
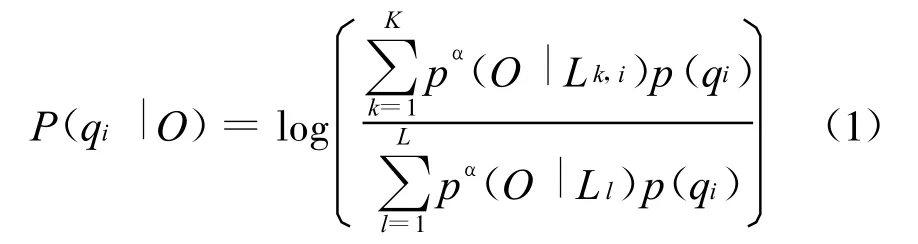
其中 L是维特比(Viterbi)解码产生的网格(Lattice)中的路径总数,K是其中含有音素qi的路径总数,p(O|Ll)是网格中第l条路径的似然比,p(O|)是网格中包含有qi的第k条路径的似然比,p(qi)是音素qi的先验概率。
2.2 字的发音质量打分
为了检测普通话的字发音错误,首先要获得每个音素的SLPP值。然后,每个字的得分就可以用其音素的SLPP值来做加权平均。由于普通话每个字一般都由声母和韵母组成,则字的发音质量得分可用下式表示:
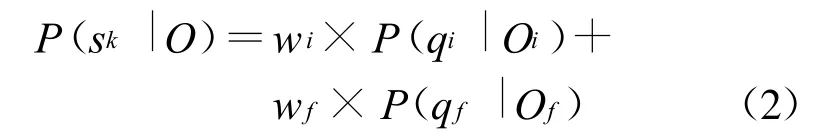
其中wi和w f是声母 qi和韵母q f,的权重。
3 声学模型的改进方法
为了改进发音错误自动检测系统的性能,除了改进打分方法外,提高声学模型的性能也很重要。本部分提出了两个策略来获得更好的声学模型。在模型训练的时候,引入基于受限最大似然线性回归(Constrained Maximum Likelihood Linear Regression,CMLLR)的SAT方法来进行说话人归一化,减少由于训练数据说话人特性不同而带来的对模型参数的不可靠估计;在测试时,引入最大似然线性回归(Maximum Likelihood Linear Regression,MLLR)的技术来进行说话人自适应,减少训练数据和测试数据的不匹配。由于自动语音识别和发音错误自动检测的目标不一致,本文提出了选择性最大似然线性回归(SMLLR)技术。
【例4】(2018·福建中考·34)泡菜的制作工艺是我国悠久的食文化遗产之一。在制作泡菜过程中,应控制亚硝酸盐在一定浓度范围内,以免对人体产生危害。兴趣小组研究不同浓度食醋对泡白菜中亚硝酸盐含量的影响,具体做法是:称取等量白菜4份,每份均加入等量7%盐水、鲜姜和辣椒,再加入食醋,调节料液的食醋浓度分别为0、0.3%、0.6%、0.9%。重复做3次。从泡菜制作第1天开始,每天测定其亚硝酸盐含量,测定10天,结果如图2所示。
3.1 采用SAT进行说话人归一化
为了估计HMM模型的参数,训练数据通常需要包含大量的说话人。由于说话人特性的不同,导致说话人之间声学特性的变化,从而影响模型参数,尤其是方差。这不仅是自动语音识别系统产生错误的主要原因之一,也大大影响了发音错误自动检测系统的性能。在说话人无关模型的训练中,基于SAT的说话人归一化方法已经证明可以有效的减少由于不同说话人的特性引发的交叠。SAT的方法通过最大似然准则进行线性变换,目的在于分离两个过程,一个是说话人相关变化,另一个是语音信号的音素相关变化。主要有两种实现SAT的方法,一个是不受限的要最大似然线性回归[6],其均值和方差不相关;另一个是受限的CMLLR[7],其均值 μ和方差∑的变换矩阵 A′是一致的。CMLLR的通常形式如下:

其中b′是偏移值。考虑到运算量和性能[8],在我们的系统中采用了基于CMLLR的SAT方法。
3.2 采用SMLLR进行说话人自适应
在训练的时候,使用SAT的方法可以获得说话人方差更小的模型。而在测试的时候,由于测试数据的说话人相关和语音学相关的变化,使得必须使用说话人自适应技术来消除这种不匹配。在自动语音识别系统中,MLLR已经证明是一种非常有效的方法来补偿训练模型和测试数据的差异。对于发音错误自动检测系统,MLLR也是有效的。但是对这两种系统使用MLLR技术有很大的不同。语音识别的目的是为了提高识别率,因此,语音识别中的说话人自适应就需要尽可能的降低训练和测试数据的不匹配程度,无论它是由于说话人的特性还是由于说话人的错误发音引起的。而发音错误自动检测的目的是判断发音正确与否,因此,说话人自适应的目的就是为了减少由于说话人特性带来的不匹配,而不是由于说话人发音错误带来的不匹配。这里我们采用两个方法来实现这个目的。一个方法是在MLLR的时候利用一个全局变换矩阵,全局变换矩阵带有更多的说话人特性和更少的音素相关的变化,除此以外,这个全局变换矩阵应该尽可能少的用说话人错误发音数据来产生。因此,本文提出用自动挑选的发音水平高的数据来做MLLR自适应。在获得一个说话人的所有字的SLPP得分后,高分的字则被近似认为是好的,发音错误少的。在这些被挑选的字数据上做MLLR自适应,我们称为选择性的MLLR(SMLLR),它可以有效的降低自适应中错误发音带来的影响。
图1表示了利用SAT和SMLLR来改进声学模型的方法。初始(步骤0),我们有一个性别相关(Gender Dependant,GD)的模型作为基线模型。在步骤1中,采用SAT的方法建立一个更加紧凑的GD+SAT的模型。步骤2,按照公式(2)对一个说话人的每个字计算其SLPP得分。步骤3,得分高的字被选中作为自适应训练数据。步骤4中利用这些数据来做MLLR自适应。在步骤5中,通过GD+SAT+SMLLR的模型和合适的门限选出错误发音。
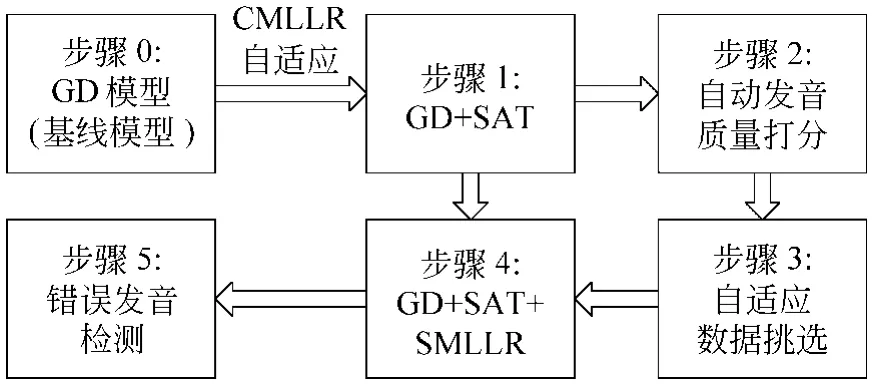
图1 改进声学模型的流程图
4 说话人得分归一化的方法改进系统后端
4.1 引入该方法的动机
近年来,对发音错误自动检测的任务,已经有很多研究,提出了很多方法。但是,发音错误自动检测系统离实际应用还有很大的差距,该任务目前仍然是个巨大的挑战。同时我们发现,说话人整体发音自动评分任务与该任务非常类似,其目标是通过一个说话人的几十个甚至上百个字的发音,来给该说话人的发音水平评分。研究表明,此任务的性能已经能接近专家的水平,可以达到实用[9]。两者性能差距的一个主要原因就是,对于发音错误自动检测任务,我们仅通过一个字的数据来做判断;而对于说话人整体发音自动评分任务,我们可以通过该说话人的很多的数据来生成一个得分。信息量的差距很大。这提示了我们可以在说话人的层次上检测发音错误。为此,本文引入了说话人归一化的方法,将说话人整体发音得分作为一个新的判断因素。
引入说话人整体发音得分除了可以提高信息量外,对于不同发音水平的说话人错误发音,专家的评价标准也不一样。对于整体水平高的说话人,专家要求更严格,而对于整体水平低的说话人,专家要求较放松。我们将40个测试说话人按照其发音水平从1到4依次分为4个等级(1为最好,4为最差),计算对每个等级的说话人,专家认为的正确发音和错误发音的SLPP得分均值和方差,结果如表1所示。

表1 不同等级说话人正确和错误发音得分
从该表中可以发现发音最好的说话人的错误发音得分甚至要好于发音最差的说话人的正确发音得分。可以看出,对于不同发音水平的说话人,专家的评判标准也是不一致的。因此,引入说话人整体发音得分作为一个新的参数是必要的。
4.2 说话人得分归一化方法
在本文的系统中,使用一个合适的门限来判断正确和错误的发音。由4.1可知,不同水平的说话人的判决门限应该不一样,因此,文中用说话人的整体得分来归一化其每一个字的得分,如公式(5)所示:
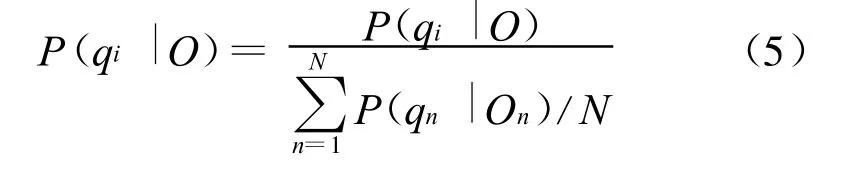
式中的分子为一个字的原始得分,分母为说话人的得分,其中N为该说话人所说的字的个数。这里用的归一化方法虽然还是一种很简单的方法,但是后文的实验结果表明该方法的有效性。以后可以考虑采用更加复杂的方法。
5 实验配置与实验结果
5.1 实验数据
普通话水平测试(Putonghua Shuiping Ceshi,PSC)是中国官方测试说话人普通话发音水平的考试。我们设计的实验数据库,与 PSC的标准相一致。
数据库中有 140个本国说话人(70个男性,70个女性),其中100个(50个男性,50个女性)发音标准的说话人用来训练标准发音模型,其余的40个说话人的发音水平从很好到很差,作为测试数据。每个说话人说两题,每题包含4个部分:100个单字,由100个单字组成的49个词,一段阅读以及一段主题演讲。100个标准发音说话人的前两个部分用来训练单音素(mono-phone)模型。剩下的40个说话人的第一部分作为测试数据进行发音错误检测实验。
为了获得错误发音的参考,我们邀请了三位获得国家认证的PSC评分专家来为每个说话人的每个字的发音标准与否做标注。任何一个字只要有一个专家认为发音有缺陷或者发音错误,我们就认为该字发音错误。实验中,我们共有来自40个说话人的8000个字,其中错误发音有1746个。数据的专家一致性方面,两个专家检错一致的发音占总错误发音的36%,三个专家检错一致的发音占总错误发音的13%。
5.2 声学统计模型
我们知道,普通话是一种带调语言,调对于普通话的发音很重要,例如方言发音者很容易发错调。研究表明,F0相关的特征能够有效地提高调的识别率,但是F0不连续一直是个很大的问题。
最早由 Tokuda[10]提出的多空间分布(Multispace Distribution,MSD)方法,能够有效地处理F0不连续的问题,提高带调语言的识别率和检测调型错误[11]。因此,在我们的实验中采用了包含有184个单音素的MSD-HMM模型。声学模型的特征由39维频谱特征和5维F0特征组成。
5.3 实验结果
对于任何检测任务,都有两种错误类型。在发音错误自动检测任务中,任何发音有缺陷或者有错误的都是我们的检测目标。因此,我们定义了两种度量标准,正确率(Precision)和召回率(Recall)。通过设置不同的门限,一个目标字就可以判断为正确或错误的发音。Precision为检测出来的真正的错误发音占检测出来的错误发音总数的比值;Recall为检测出来的错误发音占所有真正错误发音数目的比值。后文中采用正确率—召回率曲线表示实验结果。
关于实验中声母和韵母的权重问题,我们测试了平均加权、按时长加权和线性搜索最优权重的方法。其中,线性搜索最优权重的效果最好。通过测试集和开发集的验证,得出声母和韵母的权重为1∶3较为合适。
5.3.1 SAT的性能
作为一种有效的说话人归一化方法,基于CMLLR的SAT技术能够获得一个带有更少说话人变更的标准模型,它在发音错误自动检测任务中的性能如图2所示。可以看到,在中部和低部Recall区域,SAT可以提高系统的性能。
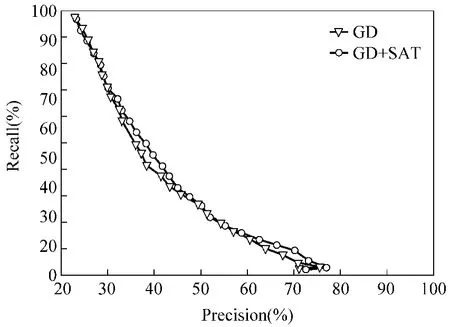
图2 SAT方法的性能
5.3.2 SMLLR的性能
在训练时采用SAT能够改进声学模型,在测试时,MLLR的说话人自适应技术能够消除训练模型和测试数据的不匹配。实验中的M LLR采用了一个全局变换矩阵以反映说话人特性而忽略掉其发音变异。为了减少自适应数据中错误发音的影响,采用了SM LLR技术。其具体实现细节如图1所示。
我们用5.3.1节中的SLPP得分较高的字作为自适应训练数据。实验中,大约用每个说话人40%的字用来做自适应,这个值实际上可按照说话人的水平来动态调整。SMLLR的性能如图3所示,在低Recall区域,SMLLR能够有效的增加Precision的值。从图中可发现,单纯使用MLLR的性能没有变好,因为它也会消除错误发音带来的不匹配。
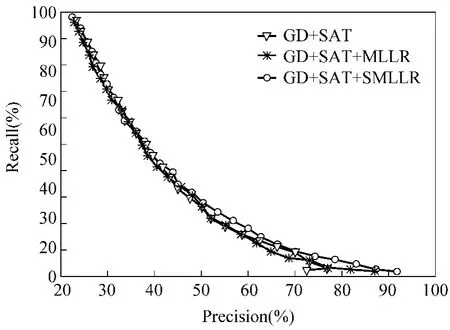
图3 SMLLR方法的性能
5.3.3 后端说话人得分归一化的性能
由于单个字的信息量过少和不同水平发音人评价等级不一致这两个原因,我们引入了说话人整体打分的特征,并做了一个简单的说话人得分归一化处理,其效果如图4所示。可以看出,该方法极大地改进了系统的性能。
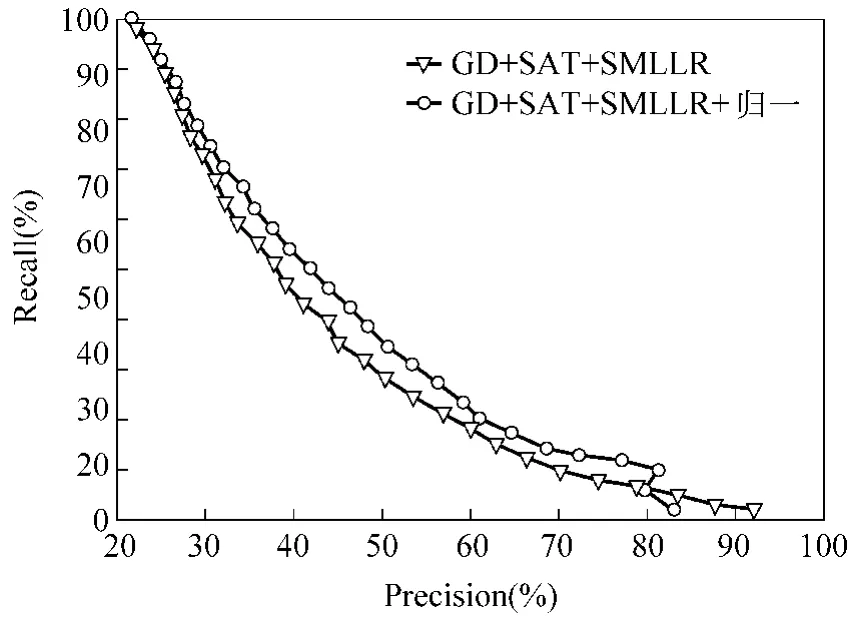
图4 后端说话人得分归一化方法的性能
5.4 实验总结
以上所有实验的结果总结在表2中。由于我们认为把正确发音误判为错误发音对用户的影响会远远大于错误发音没有检测出来的影响,所以,我们对正确率的值会更关注。因此,表中显示了在相同召回率的情况下正确率的变化。可以看到,我们提出的方法一步步地提高了发音错误自动检测系统的性能。
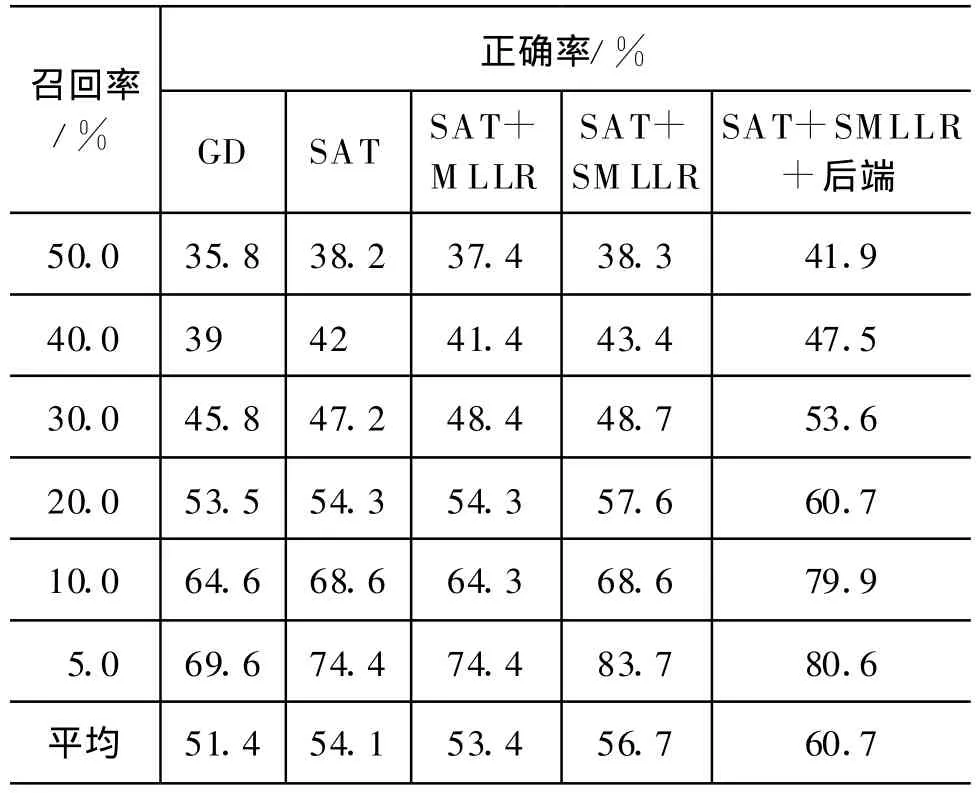
表2 各种方法的性能总结
6 结论与展望
本文从两个方面提出了改进普通话的发音错误自动检测系统性能的方法:一方面用SAT和SMLLR方法来提高系统声学模型的性能;另一方面引入说话人整体发音质量来做说话人归一化,以提高后端性能。实验结果验证了这些方法的可靠性,召回率为30%时,正确率从45.8%提升到了53.6%,召回率为10%时,正确率从64.6%提升到了79.9%。虽然系统性能有了很大的提高,但是离实际使用还有差距,其原因除了算法方面外,专家标注的一致性不高和错误发音的样本数不多也有影响。下一步考虑将更多的说话人信息融入到单个字的发音检错里面去。
[1]Zheng,J.,Huang,C.,Chu,M.,Soong,F.K.,Ye,W.,Generalized Segment Posterior Probability for Automatic Mandarin Pronunciation Evaluation[C]//Proc.ICASSP,Hawaii,USA,2007:201-204.
[2]Witt,S.,M,Use of Speech recognition in Computer assisted Language Learning[D].PhD Thesis,University of Cambridge,1999.
[3]Truong,K.,Automatic Pronunciation Error Detection in Dutch as a Second Language:an Acoustic-Phonetic Approach[D].Master's thesis,Utrecht University,Netherlands,2004.
[4]Ito,A.,Lim,Y.,Suzuki,M.,Makino,S.,Pronunciation Error Detection Method based on Error Rule Clustering using a Decision Tree[C]//Proc.EuroSpeech,2005:173-176.
[5]Franco,H.,Neumeyer,L.,Kim,Y.,Ronen,O.,Bratt,H.,Automatic Detection of phone-level mispronunciation for language learning[C]//Proc.Eurospeech,1999,2,851-854.
[6]Anastasakos,T.,McDonough,J.,Schwartz,R.&Makhoul,J.A compact model for speaker-adaptive training[C]//Proc.ICSLP, Philadelphia,1996:1137-1140.
[7]Giuliani,D.,Gerosa,M.,Brugnara,F.,Improved automatic speech recognition through speaker normalization[J].computer speech and language,2006,20,107-123.
[8]Gales,M.J.F,Maximum likelihood linear transformations for HMM-based speech recognition[J],Computer Speech and Language,1998,12,75-98.
[9]魏思,刘庆升,胡郁,王仁华,普通话水平测试电子化系统[J],中文信息学报,89-96,2006。
[10]Tokuda,K.,Masuko,T.,Miyazaki,N.,and Kobayashi,T.,Multi-space Probability Distribution HMM[J],IEICE Trans.Inf.&Syst.,E85-D(3):pp.455-464,2002.
[11]Zhang,L.,Huang,C.,Chu,M.,Soong,F.K.Automatic detection of tonemispronunciation in Mandarin Chinese[C]//Proc.ISCSLP,LNAI 4272,Springer,2006:590-601.
猜你喜欢
中学生英语·阅读与写作(2023年9期)2023-10-19 14:24:34
北京教育·普教版(2020年9期)2020-10-09 11:15:09
家庭影院技术(2020年6期)2020-07-27 01:37:54
校园英语·中旬(2019年11期)2019-11-26 10:01:06
家庭影院技术(2019年1期)2019-01-21 02:25:04
家庭影院技术(2018年11期)2019-01-21 02:20:50
电子制作(2018年19期)2018-11-14 02:36:50
家庭影院技术(2018年10期)2018-11-02 05:35:26
疯狂英语·新策略(2018年7期)2018-08-29 08:54:26
电子制作(2018年9期)2018-08-04 03:30:58
