
维吾尔语元音的声频特性分析和识别
2010-10-15 01:38王昆仑张贯虹吐尔洪江阿布都克力木
中文信息学报 2010年2期
王昆仑,张贯虹,吐尔洪江◦阿布都克力木
(1.合肥学院计算机科学与技术系网络与智能信息处理重点实验室,安徽合肥230601,2.新疆师范大学数理信息学院,新疆乌鲁木齐830001)
1 引言
现代维吾尔语(以下简称维语)属阿尔泰语系突厥语族,维语语音音节由元音和辅音构成,每个音节必须且只能有一个元音,维语语音的八个元音分别是/i、e、ε、a、o、ø、u、y/ 。由于单元音可构成音节,因此在语音识别技术中常对元音进行精密的声学测量。
随着计算机多媒体技术的发展,各种语言的语音识别研究工作在深入展开。呼和[1]、伊◦达瓦[2]对蒙古语的元音进行了定量和定性分析;李净[3]等以扩展声韵母为汉语连续语音识别的声学建模识别基元,识别性能有了很大提高;曹剑芬[4]等采用声学和生理实验以及感知实验相结合的方法,探讨了汉语“2”与“8”的区别性语音学特征及其在二者识别中的作用。在缺乏声调信息的情况下,第三共振峰(F3)的差异是决定性的区别特征。他们认为在自动语音识别中,加强对语音学特征知识的了解是个迫在眉睫的任务,在系统中充分地综合利用这些区别性特征信息,是提高识别率的有效途径。张家騄[5]等根据汉语普通话语音知觉混淆的群集分析结果,建立了声韵调体系的区别特征系统。易斌[6]对维语的/i/元音进行了声学特征分析,结合声学分析结果对该元音的音值进行了讨论;陶梅[7]等根据维吾尔语的特点,分析设计了维吾尔语语音识别系统的总体结构,讨论了维吾尔语最佳识别基元的选择方法,提出建立基于决策树聚类的上下文相关模型,并采用混合高斯分布(GMD)拟合观测概率分布,优化维吾尔语连续语音中HMM模型系统以提高识别性能。王昆仑[8-9]在维语语音识别和识别基元问题上做了初步的探讨。更多的维语语音学的研究在元音、辅音的性质、发音部位、发音方法等方面做了大量的工作,维语的实验语音学方面有许多基础性问题需要研究。本文运用实验语音学的基本理论和方法,对维吾尔语八个元音进行声频特性统计分析和识别验证。
2 声学资料
本文实验所采用的声学资料来源于新疆师范大学建立的维吾尔语综合语音数据库[10]。发音人的选择以标准音为准,年龄在18~30岁之间,同时兼顾各地区的特点,对发音人没有地域方言限制,可以带方言,常态自然发音。录音环境为与实用环境相近的办公室,噪音<45db。录音工作以PC(386)机为主体,配以Sound Blaster—16位声卡和驻极电容式话筒进行录制,采样频率为22050Hz,采样精度为16bits,多音节语料的录音语速约4个音节/秒。录音使用自编的录音工具软件进行,语音数据采用WAV文件格式存储。同组发音人之间实行实时监听、监控。语音数据库以一个音节或词为单位存储,加上包含该语音数据有关参数的文件头,参数包括发音人信息,语料信息和切分标注信息。
3 维吾尔语元音的共振峰频率分析
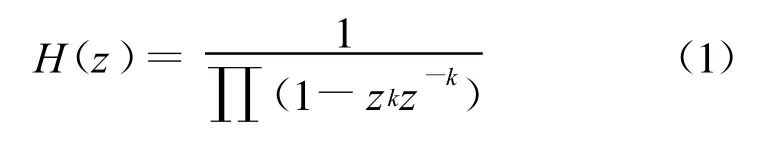
3.2 实验数据
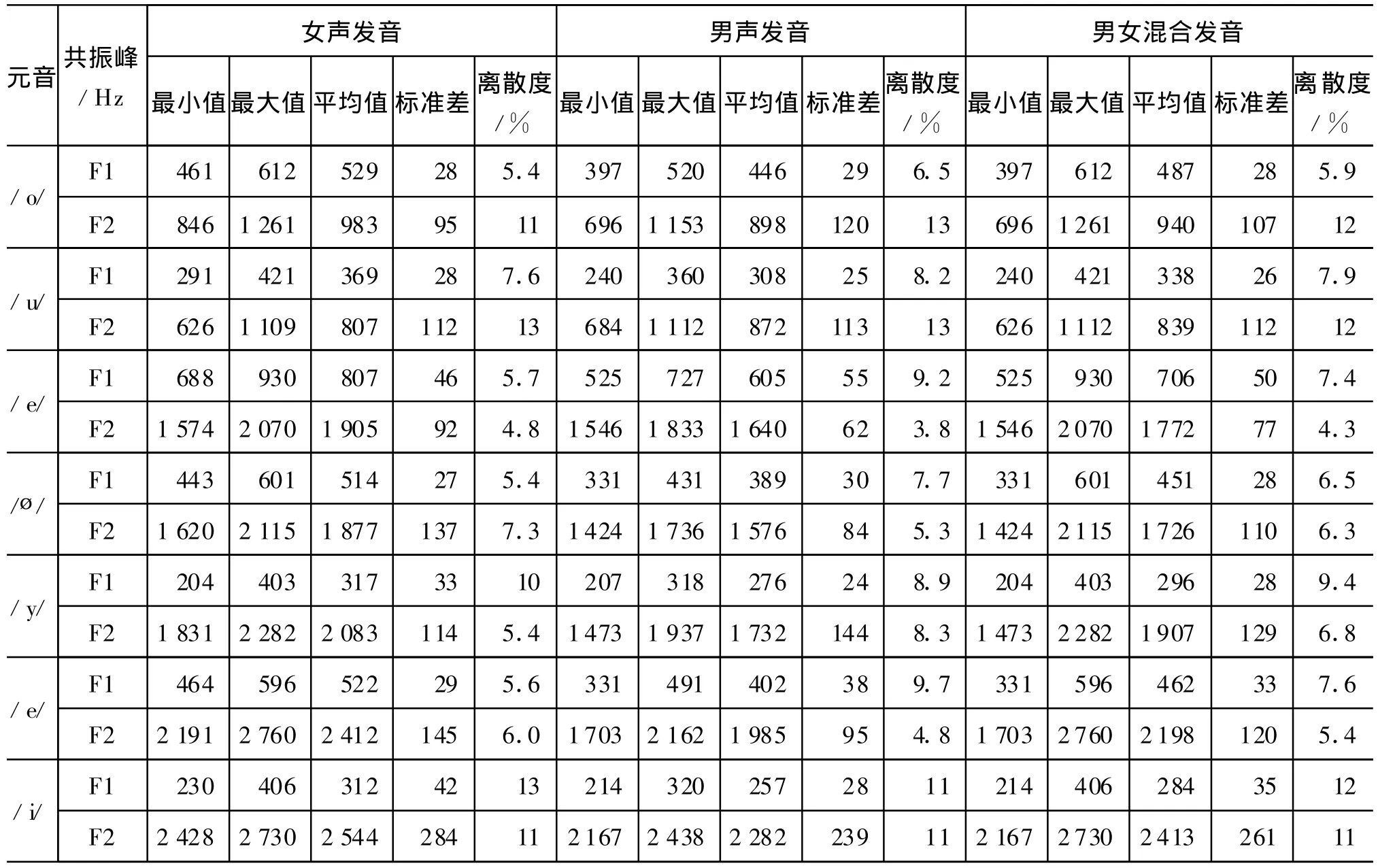
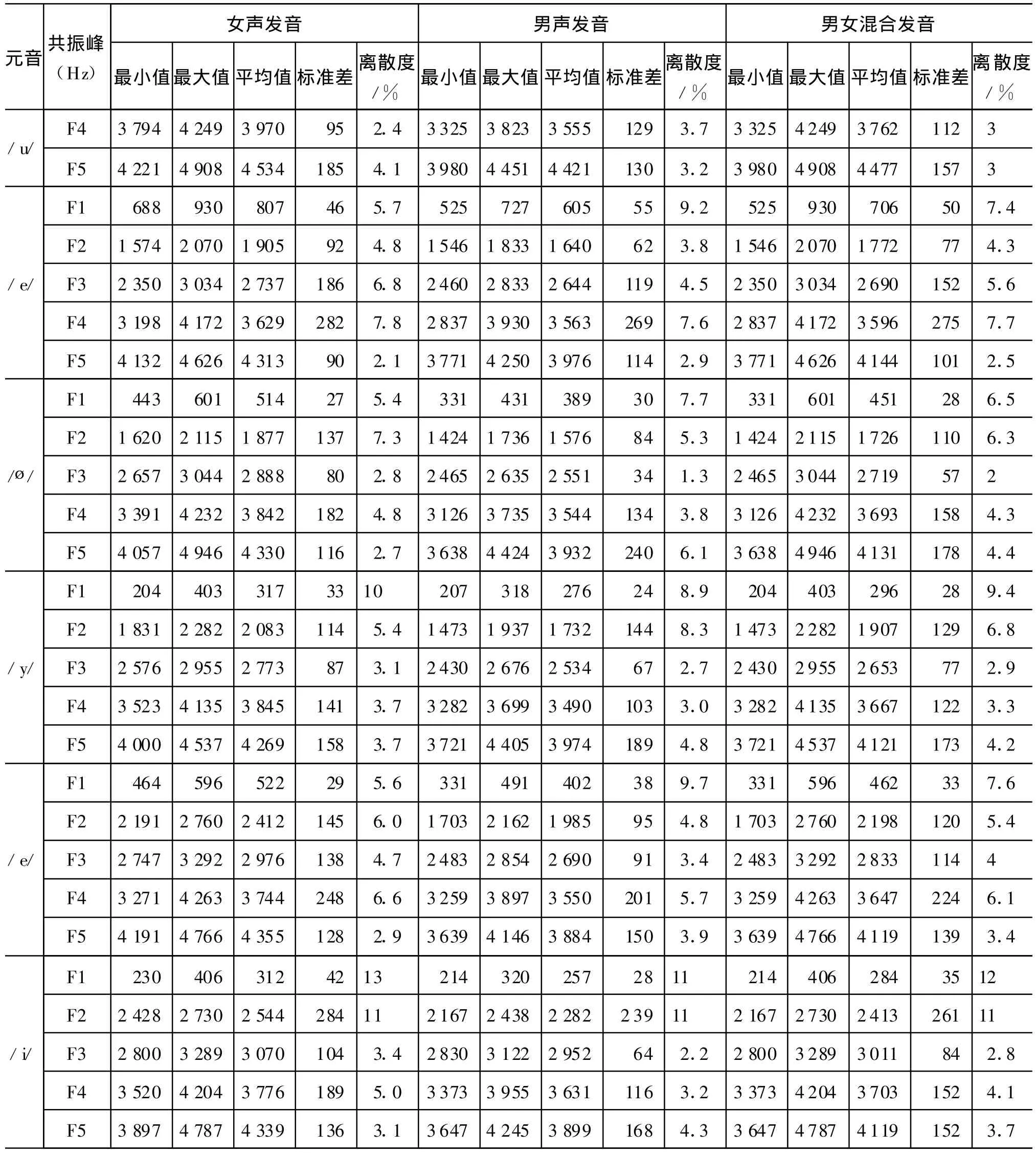
为了使实验具有一定的代表性,实验从维吾尔语综合语音数据库[10]里任意抽取了男、女声各10名共160个元音语音语料,我们分男声、女声和男女混合三组测量了八个元音的五个共振峰频率值(F1、F2、F3、F4和F5)。全部样点在元音共振峰的相对稳定段选取,对所测得的共振峰数据进行了统计,统计结果见附录A。其中离散度是标准差与平均值的比值,用来衡量各个体距平均值的远近。
共振峰频率是语音信号的一个很重要的特征参数,它的配置和时间模式反映出语音音色的重要特征,在语音的分析、识别、合成等研究中被广泛的利用。
3.1 分析方法
在语音信号的共振峰分析的众多方法中,线性预测编码(Linear Prediction Coding,LPC)[11]是一种常用的分析方法,LPC模型中,数字滤波器传递函数H(z)为公式(1)。

表1 维吾尔语元音共振峰频率统计表
续表
根据表1的数据,绘制的JOSS型声学元音图见图1、图2和图3。每个元音音位的外圈以平均值为中心,半径按“平均值±标准差”值大小绘制。这样绘制成的声学元音图与元音舌位图有很好的对应性,元音外圈的大小反映该音位的离散度。
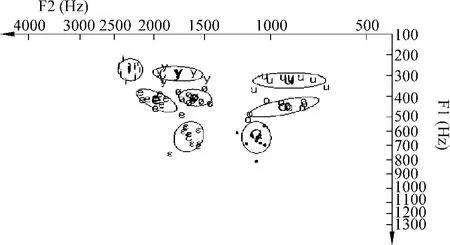
图 1 维吾尔语八个元音 F1-F2分布(男性发音10人)

图 2 维吾尔语八个元音 F1-F2分布(女性发音10人)
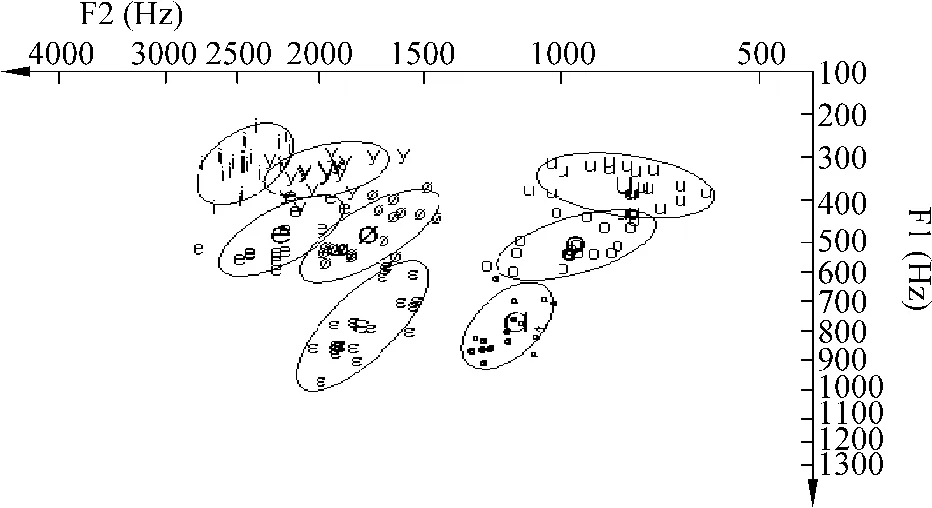
图3 维吾尔语八个元音F1-F2分布(男女混合发音20人)
3.3 实验分析及结果
Delatrre[12]对舌位和共振峰的关系进行的研究认为,用口腔开度(上、下门齿之间的距离)与F1相联系,用舌头整体的后缩前伸与F2相关联。他的结论是:F1频率增加同开口度直接相关,频率值越高开口度越大,频率值越低开口度越小;F2降低同舌头后缩直接相关,频率越低舌位越后,频率越高舌位越前;另外F2与圆唇度有关,唇越圆,F2也越低。
由本文实验所得数据(表1、图1、图 2、图3)分析得出:
1)维语的男声和女声两类发音人的八个元音相对位置是完全一致的,在图1、图2和图3上的排列是合理的。/i/、/y/是等高的前高元音,/e/和/ø/是等高的的前次元音,/ε/是前次低元音;从后元音看,/u/是高元音,/o/是次高元音。/a/元音是所有元音中最低的元音,而且是居于中间位置。
2)/a/音位是最低的一个元音,其F1位于543~918Hz的区域内。
3)/ε/元音音位相对集中,是维语元音中舌位最低的前元音,两类发音人的F2均值分别为1905Hz、1640Hz。/ε/ 音位从总体上看,在高纬度(F1)上与/a/相当,在前后纬(F2)上,/ε/和/a/分得比较清楚,/ε/在前而/a/在后。
4)/e/、/ø/元音在维语中的发音比较集中,离散度较小。这两个元音都属于前元音,但/ø/的F2比/e/的降低了535Hz(女发音人)和409Hz(男发音人)。这种F2的降低、表明了该两类元音发音的相对圆唇度和相对舌位后缩度。
5)/u/、/o/是彼此独立又相互靠近的两个后元音,它们的F2的离散度都大于10%,发音的舌位靠后。
6)/y/、/i/ 元音的F1、F2的离散度较大,因此在声学元音图上所占范围较大。/y/与/i/相比,高度(F1)相当,但/y/的F2比/i/的小,这是因为/y/圆唇的影响。
7)从图1、图2和图3中可以看出维吾尔语各个元音有较独立的共振峰频率分布,因此在通常的会话中各元音的音色听起来比较清楚。
8)从表1中还可知维吾尔语各个元音的共振峰频率F1、F2具有较大的差别,这表明各个元音具有不同的声学特性,在用计算机进行维吾尔语元音的语音识别时,应该有较高的正确识别率。
3.4 维语、汉语元音对比
我们参照吴宗济[13]汉语普通话元音共振峰频率数据(见表2和图4),把汉语普通话10个元音和8个维语元音的共振峰频率数据进行对比,可以看出:
1)汉、维语中都有前、半低、不圆唇元音/ε/、/er/,但维语/ε/比汉语/er/舌位略低,开口度略大,维语/ε/的 F1、F2值分别比汉语/er/ 降低了50Hz和 150Hz。
2)汉语中独有的音位有/i/(资)、/i/(知)、/r/ 、/e/,维语中独有的音位有/e/ 、/ø/ 。
3)除了以上完全不同的音位外,汉维语中其他元音的音位大致上相对应,F1、F2共振峰频率值相差不大。

表2 汉语普通话10个元音共振峰频率数据表
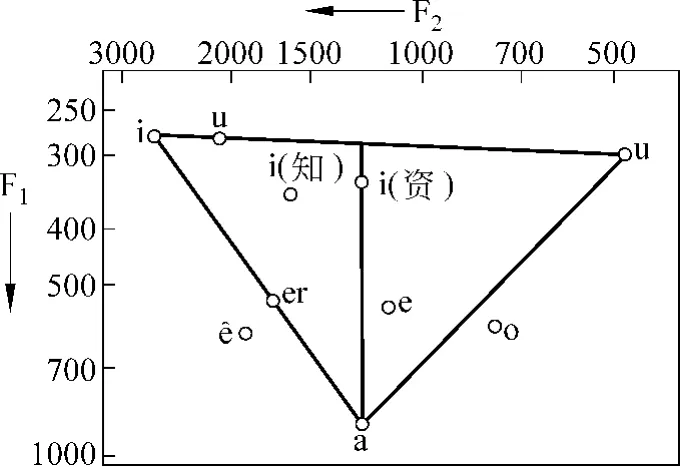
图4 汉语普通话十个元音声学元音图
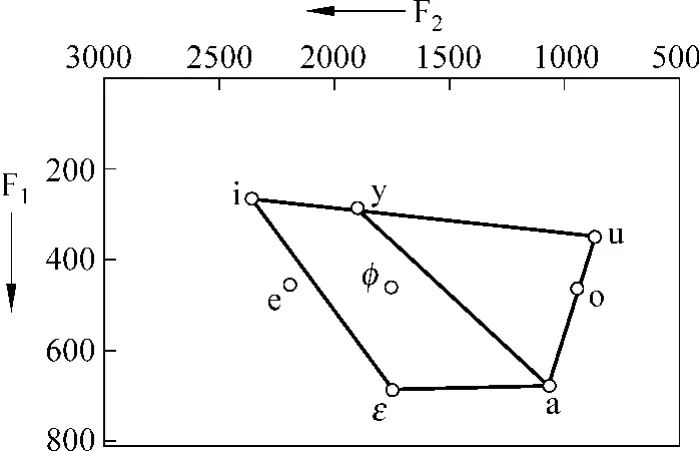
图5 维吾尔语八个元音声学元音图
4 维语元音语音识别及分析
本文使用隐马尔可夫模型工具集[14](Hidden Markov Model ToolKit,HTK)对维语八个元音进行语音识别实验,并分析实验结果验证维语八个元音共振峰频率分布规律的正确性。
4.1 HTK及模型参数
声学模型是识别系统的底层模型,和语言发音特点密切相关,并且是语音识别系统中最关键的一部分[3-4]。通过概率密度函数计算语音参数对HMM模型的输出概率,经搜索最佳状态序列,以最大后验概率得到识别结果。对以上共振峰频率的分析结果,用H TK进行元音识别实验以确认分析结果的正确性。实验数据所用的特征向量是39维的 MFCC(Mel-Frequency Cepstrum Coefficients),其中包括20阶倒谱系数。基于HTK的语音识别流程见图6,其中:
1)数据准备。准备训练及待识别语音文件(.wav),训练语音的特征文件(.mfc、.plp)。
2)创建模型及学习。首先构建Proto文件,定义模型拓扑结构,构建单音素模型。使用HComp V工具统计训练数据全局均值、方差,HInit估计出初始模型参数。然后通过多次使用HERest工具重估模型参数,进行模型学习。
3)识别及评估。使用HVite工具进行识别,H Results工具进行评估。
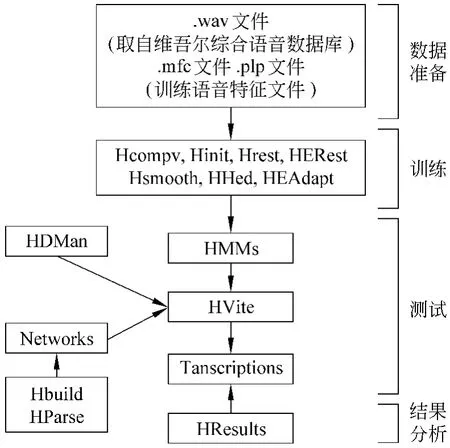
图6 基于HTK的语音识别流程
4.2 实验及结果分析
由于男声语音和女声语音在声学特征上有比较明显的区分,为了得到更明显的实验结果,实验分四组进行。实验数据同3.2节所述,分别用10名男发音人语音和10名女发音人语音训练得到识别模型M 1和M2,从中任取3男3女语料作为集内识别语音M-in-Set和F-in-Set,另外从文献[10]中任取3男3女元音语料作为集外识别语音M-out-Set和F-out-Set。在识别模型M1和M 2中分别测试男、女声和集内、外的交叉语音识别结果如表3。

表3 维语八个元音的识别结果(识别率%)
实验结果分析:
1)从表3中可知,维语八个元音具有很高的识别率,几乎为百分之百的识别,其原因和前面3.3节所述是相同的。维吾尔语各个元音的共振峰频率F1、F2具有较大的差别,这表明各个元音具有不同的声学特性,在用计算机进行维吾尔语元音的语音识别时,具有很高的识别正确率,验证了3.3节的分析结论。
2)表3中元音/ø/,/y/在M 1模型下女声识别集外识别率和元音/e/,/i/在M 2模型下男声识别集外识别率略有下降。对实验语料分析后,元音/ø/,/y/在M1模型下女声识别集外识别率略有下降的主要原因是个别男声实验语料的发音清晰度不够,有4人的发音存在一定的混浊发音现象,另外,实验语料存在男、女声发音音强差别较大的问题;元音/e/,/i/在M 2模型下男声识别集外识别率略有下降的主要原因除了上面的原因之外,我们还发现男声集外识别集中的一男声发音/e/的F2共振峰值发生了跳跃,如图5所示,影响了语音识别的结果。所以,影响识别率的主要原因来自于第2节介绍的语料数据库,如发音者发音状态、方言和语料采集环境等因素。
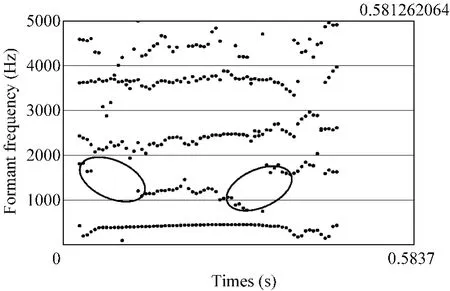
图7 男声元音/e/的共振峰图
5 结论
通过对维吾尔语八个元音进行的物理声学分析,在维吾尔语综合语音数据库的实验数据条件下,给出了维吾尔语八个元音的共振峰分布参数和实验分析,同时通过元音识别实验验证了本次实验结果的正确性。可以看出维吾尔语的八个元音具有比较强的可区分声频特性,在进行语音识别时能够获取很高的识别率,因此对于维吾尔语元音语音信息传送接受的估计正确性会比较高。
对于维吾尔语辅音声频特性及其分析以及在连续语音条件下,基于维吾尔语语言的构词规律以及发音规律的特殊性和特殊现象,将更为复杂,此方面的实验结果我们将另文阐述。

附录A 维吾尔语元音共振峰频率统计表
续表
[1]呼和.蒙古语元音的声学分析[J].民族语文,1999,(4):58-60.
[2]伊◦达瓦,大川茂村,白井克彦.蒙古语七个元音声频特性计算机分析[J].声学学报,1999,24(1):94-97.
[3]李净,郑方,张继勇,吴文虎.汉语连续语音识别中上下文相关的声韵母建模[J].清华大学学报(自然科学版),2004,44(1):61-64.
[4]曹剑芬,李爱军,胡方,张利刚.语音学知识在语音识别中的应用[J].清华大学学报(自然科学版),2008,S1:748-753.
[5]张家騄.汉语普通话区别特征系统[J].声学学报,2005,30(6):506-514.
[6]易斌.现代维吾尔语元音/i/的实验分析[J].语言与翻译(汉文),2008,(1):20-24.
[7]陶梅,吾守尔◦斯拉木,那斯尔江◦吐尔逊.基于HTK的维吾尔语连续语音声学建模[J].中文信息学报,2008,22(5):56-59.
[8]王昆仑.维吾尔语音节语音识别基元的研究[J].计算机科学,2003,30(7):182-184.
[9]王昆仑.基于CDCPM的维吾尔语非特定人语音识别[J].计算机研究与发展,2001,38(10):1242-1246.
[10]王昆仑,樊志锦,吐尔洪江,方晓华,徐绍琼,吾买尔.维吾尔语综合语音数据库系统[C]//第五届全国人机语音通讯学术会议论文集,1998.
[11]杨行骏.语音信号与数字处理[M].电子工业出版社,1995.
[12]Delattre,P.The physiological interpretation of sound spectrogram[M].PLM A,Vol LXVI(5),1951.
[13]吴宗济.普通话单音节语图册[M].中国社会科学出版社,1986.
[14]http://htk.eng.cam.ac.uk/.
猜你喜欢
延边大学学报(社会科学版)(2022年4期)2022-07-15
考试与评价·七年级版(2021年1期)2021-08-14
文化创新比较研究(2020年8期)2021-01-22
考试与评价·七年级版(2020年1期)2020-10-23
中国民族博览(2019年10期)2019-11-29
自动化学报(2017年4期)2017-06-15
人间(2016年32期)2017-02-26
语言与翻译(2015年1期)2015-07-18
语言与翻译(2015年4期)2015-07-18
小学生时代·大嘴英语(2014年6期)2014-11-04
