
文本中人物性别识别研究
2010-07-18 03:11唐琴林鸿飞
中文信息学报 2010年2期
唐琴,林鸿飞
(大连理工大学计算机科学与工程系,辽宁大连116024)
1 引言
文本中的人物性别识别主要应用于指代消解[1-2]、机器翻译[3]等多种任务当中。目前而言大部分研究工作是针对人名自动识别,并主要是根据男女人名用字差异进行的识别。然而我们知道指代消解、机器翻译所作用的环境通常是一个段落或者一篇文章。所以我们对一个人物进行性别识别时除了利用其人名本身的用字特征外,还可以从整个段落或者整篇文章出发考虑篇章中描述不同性别时的两性特征差异。
目前性别差异主要是从语言学角度出发进行的研究。男性和女性在语言的使用上存在很多的差异,通过语言描述可以得出其生理属性、文化心理、社会价值取向等各种信息[4]。文献[5-6]都指出在描写男性和女性的时候,它们的上下文存在不同的性别语义场。我们也发现汉语语言中在对不同性别的人的特征和言行进行描述时所使用的词汇存在着很大的差别,目前有少量基于词汇使用的性别差异研究,但根据词汇、句式等特点进行性别识别的研究却相对较少。文献[7]选取有名小说家20部代表作,统计其中的男女话语,得到两性感叹词以及程度副词有较大差别。文献[8]主要是对动作动词进行性别倾向性研究,而名词,形容词等却没有进一步研究。
在阅读文章时,通过对人物的描述,我们往往可以比较容易地辨别出描述对象是男是女,但是对于机器而言并非易事。目前性别差异的研究主要是从语言学角度出发,研究两性性别语言差异的各种表现,如词汇差异、句式差异、修辞差异、叙事方式差异等多种形式,但是如何利用这些差异使得机器能够像人一样准确地进行性别识别的研究还是很少。本文旨在通过利用描述男女不同性别人物时的词汇差异以及人物姓名在用字上的特征差异使得机器也能准确进行性别识别为自然语言处理中的一些任务所用。
在人名性别识别方面,文献[9]对7万中国人名进行实验得出结论:男女人名用字有显著性别差异。文献[10]在文献[11]中4万人名的语料基础上加入6万人名进行人名性别识别实验,分别采用贝叶斯方法和根据Hownet和网络挖掘中获得的性别指示词进行人名性别识别,并发现人名尾字对性别识别具有更好的应用能力。
本文的研究重点是从真实的文本中获取大量性别倾向性明显的特征词,然后再利用篇章中两性性别特征差异信息和称谓信息包括人名用字特点对人物进行性别识别。本文组织如下:第二节从性别倾向性描述词和性别倾向性称谓词两个方面介绍汉语词汇的性别倾向性;第三节首先介绍如何获取性别倾向性词汇和人物姓名,在此基础上分别进行基于姓名的性别识别和基于性别倾向性词汇的性别识别;第四节是结论和展望。
2 汉语词汇的性别倾向性
语言中的性别差异是普遍存在的,称谓语作为语言词汇系统的一个重要组成部分,它的划分与性别有直接的关系。称谓语是人们用来表示彼此之间的各种社会关系、身份和职业的名称。通常把称谓语分为亲属称谓和社会称谓,其中社会称谓分为三种,即职业称谓、通用称谓、姓名称谓等[12],除了通用称谓,如“同志、老师、大夫、服务员”等没有专指男性或女性,其他称谓都带有明显的性别倾向。
亲属称谓如“哥哥、爸爸、伯父、舅舅、大爷、外公”等专指男性;“姐姐、妈妈、姨妈、姑姑、阿姨、大娘、奶奶”等专指女性。社会称谓语是人际社会关系的标志,一般不体现被称呼者的具体地位,只有性别的差异,如“先生、打工仔、军长”指男性,“女士、小姐、空姐”指称女性。另外姓名称谓中的名也存在着明显的性别差异,男性名字主要表现男子汉的伟岸、忠孝仁义和儒雅风度,而女性用名多给人娇美、清秀、温柔、贤惠等感觉,更具有女性化特征。
对于这些带有明显的性别倾向的称谓词,在这里我们定义为称谓性别倾向性称谓词。然而随着社会发展,男女姓名用字的界限越来越模糊,所以仅仅从姓名用字来识别人物性别是不够的,还需要借助描述两性特质的词汇差异。
研究者一致认为汉语词汇不具有语法性,但是我们在汉语语言运用中常发现描述不同性别的人的特质和行为时,所使用的词汇却有很大差别,比如“英俊”、“西装革履”、“帅气”、“血气方刚”等词多用来修饰男性,而“苗条”、“天生丽质”、“柳叶眉”、“怀孕”等词往往用来修饰女性。因此在阅读文章时,通过人物描述时所使用的性别倾向性词汇,我们可以比较容易地辨别出描述对象是男是女。
文献[8]将这种较多修饰某一性别的特点称为词汇的性别倾向。因此如果一个词在大多数情况下用来修饰男性,称之为男性性别倾向性词语,如果一个词在大多数情况下用来修饰女性,称之为女性性别倾向性词语。
通常我们在对一个人物进行描述时,主要是通过人物的肖像、语言、动作、心理描写以及细节描写来表现人物的性格特征[13]。人物的肖像,除了人物的外部形象如面貌、体态、衣着等,还包括人物的内部精神的反映如神韵、情态等等。我们发现描述人物的面貌、体态、衣着、神韵、言行的大量词汇具有性别倾向。还有部分描述男女身体器官的词汇也具有明显的性别倾向性。我们把这些描述男女不同性别时具有明显差异的词汇定义为性别倾向性描述词。在此我们把这两类词汇,性别倾向性描述词和性别倾向性称谓词统称为性别倾向性特征词。
本文中我们主要从具有明显性别倾向性的称谓词汇即性别倾向性称谓词和描述人物的性格特征时的具有性别倾向性的词汇即性别倾向性描述词这两方面进行人物性别识别,其中称谓语主要分成两类,一是亲属称谓和社会称谓中的职业称谓,另外是姓名称谓。
3 人物性别识别
从目前的研究工作可以看出,描述男女不同性别时在遣词造句上有较大的差别,另外男女称谓也存在着显著差异。故本文从这两方面入手,根据描述男女人物不同方面时存在的两性差异首先自动获取大量具有明显性别差异的特征词即性别倾向性特征词,然后根据这些特征词以及结合人物的称谓信息进行性别识别。
3.1 性别倾向性词汇的获取
我们从网上下载了3 015篇小说,其中长篇小说2242篇,短篇小说773篇,其中短篇小说是单文档,长篇小说是多文档,共83 859个文件。首先获取小说中的人物名,人工确定小说中人物角色的性别,再根据一定的策略分别统计男性人物和女性人物所在句子的词汇,然后综合出现的频次以及比率,最终得到性别倾向性词语。
我们使用哈尔滨工业大学的分词和词性标注工具对语料进行分词和词性标注。但是由于小说中人物姓名更复杂和特殊,词性标注时大量的人名没有被标注出来。小说中人物名字一般都是多次出现,所以本文采用Tseng算法[14]的最大重复串(Maximally Repeated Strings)来提取文本中人名实体,步骤如下:
(1)首先提取出每篇文档的最大重复串出现次数超过两次以上;
(2)如果第一个字是单姓,则字数是2或者3的标记为候选人名实体;
(3)如果前两个字是复姓,则字数是3或者4的标记为候选人名实体;
(4)对满足条件的最大重复串进行分词和词性标注;(5)如果词性标注中含有nh词性,则为人名;(6)如果词性标注中不含有nh词性,但满足分词后得到的第一个词是姓氏则为人名。
如人名“高至林”,词性标注后得到“高至林/nh”、“江美人”词性标注后得到“江/nh美人/n”满足条件(5),姓+称谓词如萧先生得到“萧/n先生/n”满足条件(6),而最大重复串“简直就”,标注成“简直/d就/p”则不满足条件。另外,对于所获得的人名还要进行后续处理,例如对获取的人名“周顺的”、“韩荷她”这样的人名中尾字为“的”、“她”等常见的停用词则删掉尾字。
除去“萧先生、邵母”等称谓类词语,最后得到8681个姓名,根据人工判定发现其中7 960(91.7%)个姓名是正确的,基本获取了语料中人名实体,为后续实验所用。这7960个姓名中,4 632个是女性姓名,其余3 328个是男性姓名。
在已知人名实体性别的情况下,我们对含有姓名、姓+称谓词或者含有他她他们她们这三类词语的句子分别进行男女性别倾向性词语统计。其中姓+称谓词中由于称谓词有明显的倾向性,所以较容易判别男女性别,如“孙姑娘、阮姐姐、柳小姐、夏大哥、李大爷”等。这里用到常见的15对亲属称谓词,再加上4个社会称谓词“先生、小姐、姑娘、女士”。
另外,由于中文句子的复杂性,我们只统计相对简单的句子中的词语,即句子中只有一个姓名、称谓词或者倾向性代词。如果出现多个以上,则以逗号为界划分句子,对满足句子中只有一个姓名、称谓词或者倾向性代词的词语进行统计,其他则舍弃以此减少噪声。这里,我们只对普通名词、动词、形容词、副词、习用语进行统计。我们统计各个性别相关词语的词频,如词语“妙龄”在女性性别倾向性词汇中出现的次数为357,男性性别倾向性词汇中出现4次。
本文使用性别比率作为一个度量,性别比率定义为词语在女性性别倾向性词汇出现次数比上其在男性性别倾向性词汇次数。根据定义,可得“妙龄”的性别比率为89.25。“玩世不恭”在女性性别倾向性词汇中出现的次数为1,男性性别倾向性词汇中出现139次,则性别比率为1/139=0.007 194,这样不便于根据性别比率阈值抽取倾向性词语。故当某词语在男性性别倾向性词汇中出现次数大于在女性性别倾向性词汇中出现的次数时,性别比率为:-(男性性别倾向性词汇出现次数/其在女性性别倾向性词汇次数),加上负号目的是区别于女性性别倾向性词汇,显得更直观。
在选择确定性别倾向性描述词时,发现女性倾向性词语的特征更明显。我们抽取女性性别倾向性词汇时统计性别比率≥2.0的词语,男性性别倾向性词汇时统计性别比率≤-1.5的词语,且这两类性别倾向性词汇分别在其所属类别中所出现的次数必须大于或等于10次。最后得到男女性别倾向性词汇分别为687和667个。另外根据How Net中每个词条中DEF栏中性别属性“male|男”和“fe-male|女”得到男女倾向性词语分别为217和490个。因此,所得性别倾向性词汇总数为2 061,其中男女倾向性词语分别为904和1 157个。
通过对获得的性别倾向性描述词进行分析,我们发现这些词汇主要集中在面貌、体态、衣着、神韵、言行等方面。另外,除了本节前面所提到的15对常用的亲属称谓词和4个社会称谓词,这些词汇还包括一些具有性别倾向性的称谓词,合起来为性别倾向性称谓词。对于性别倾向性描述词,我们归纳出姿态(体态与神韵)、言行(语言与动作)、着装(衣着和附属物品)、生理特征四类词语,还有性别倾向性称谓词进行分析和研究。性别倾向性称谓词主要是亲属称谓和职业称谓。
(1)生理特征类
男 :剑眉 ,胡子 ,肌肉,膀子,胸膛 ,喉结 …
女 :辫子,娥眉 ,瓜子脸 ,发髻,脸蛋,子宫 …
(2)姿态类(体态与神韵)
男:壮硕,衣冠楚楚,俊逸,血气方刚,娘娘腔,酷…
女:娇小,闭月羞花,天生丽质,贤惠,楚楚动人,泼辣…
(3)着装类(衣着与附属物品)
男 :西装,烟头 ,棍棒,机枪,斧头 …
女:胭脂,口红,脂粉,高跟鞋,手链…
(4)言行类(语言与动作)
男 :花天酒地 ,独裁,称霸 ,酗酒 ,厮杀,冲锋,拂袖而去…
女 :分娩 ,改嫁 ,拭泪 ,破涕为笑 ,尖叫,化妆,唧唧喳喳…
(5)称谓类
男 :大丈夫,痞子,军长 ,的哥,老弟,流氓…女:白衣天使,三陪,农妇,宫娥,贵妇,师母…
3.2 性别识别实验
3.2.1 基于姓名的性别识别
我们对语料中的600篇小说进行测试,其中人名共2 482,男女性别分别为1 009和1473。所有语料共7 960个人名,训练集69%,测试集占31%。文献[10]的实验数据得出采用中国人名尾字的方法可以得到较好的效果。这里我们使用贝叶斯统计方法对尾字进行统计实验,公式如下,其中w是尾字。

由于数据存在稀疏问题,测试时如果姓名尾字不在训练集中则使用文献[15]中男女姓名常用字进行判别,表1是人名性别识别实验结果。

表1 基于姓名的性别识别结果
古代女性的姓名相对简单,但随着社会发展女性地位的提高,部分女性喜用男名。另外也有部分女性姓名是为了显示新颖超脱,使得女性人名特征相对于男性人名更丰富和多元化。故从表1可知,女性人名的识别正确率相对于男性人名要低。2482个人名中男女性人名识别正确总数是2 023,总的准确率为81.5%。
3.2.2 基于性别倾向性词汇的性别识别
为了考察称谓词汇和描述性特征词汇分别对于人物性别识别的影响,利用性别倾向性称谓词语,性别倾向性描述词,以及这两类词语结合起来即性别倾向性特征词分别进行三组实验,但不考虑男女姓名用字差异。
3.1节中获取的性别倾向性特征词中,性别倾向性称谓词语368个,其中男性称谓145个,女性称谓223个;性别倾向性描述词共1 693个,其中男性描述词759个,女性描述词934个。
我们使用3.2.1节中的600篇小说进行实验,共11 881个文本文件,不重复人名2 482个。一篇小说有多章,多个文件,为使实验更接近真实的语料环境,这里以每个文本为单位作为考察对象,对文本中人名实体进行性别识别。每篇小说平均20个文件,故有重复统计,共46 240个人名,每个文件平均3.89个人名,平均每个文件12360个字节。对于每个人名实体,首先获得含有此人名的句子,且句子必须满足有且仅有这一个人名。如果出现多个以上人名,则以逗号为界划分句子。最后得到与人名实体相关的句子集S。
三组实验分别统计句子集S中出现的性别倾向性称谓词,性别倾向性描述词,性别倾向性称谓词和性别倾向性描述词之和,男性别倾向性词数多则此对应的人名实体为男性,反之则为女性。表2是基于性别倾向性词汇的人物性别识别的结果,其中未识别数表示句子集中没有出现相应的性别倾向性词汇;识别准确率是识别正确数比上识别总数的值;总准确率是识别正确数比上总数的值;(性别倾向性)特征词是指基于(性别倾向性)称谓词与(性别倾向性)描述词的合集作为性别识别的特征词。
由表2知,其中基于性别倾向性描述词的实验所得识别准确率最高,而把性别倾向性描述词和性别倾向性称谓词结合起来进行实验所获得的总准确率最高。
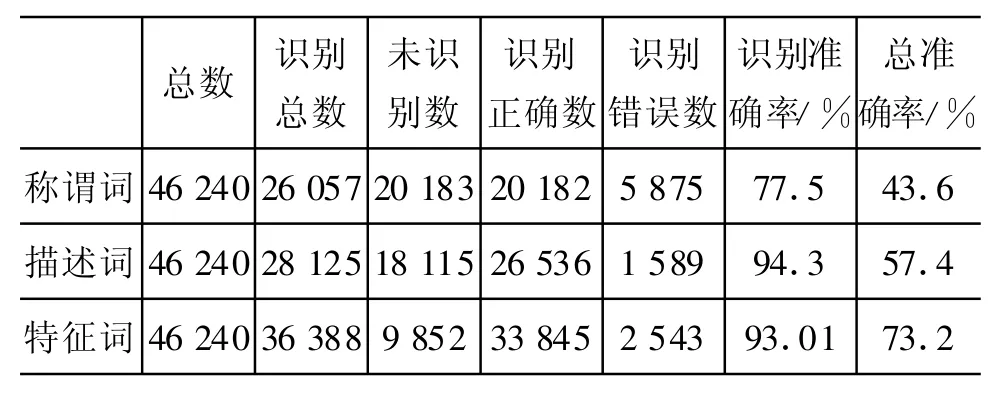
表2 基于性别倾向性词汇的性别识别结果
随着性别倾向性词汇的增加,总的准确率在增加,但识别准确率反而是基于性别倾向性描述词识别的结果较高。我们知道称谓词具有明显的性别倾向性,但是由表2可知,仅仅根据性别倾向性称谓词识别人物性别的准确率反而效果最差。其原因主要是因为,本实验是基于较简单的统计方法,而没有对句子做深入的句法分析。正例如,“李举韶向来也是个天之骄子,而且是家中最受疼爱的公子”,词语“公子”具有很好的性别指示作用。反例如,“白煦顺着妹妹指的方向看去”,在本例中“白煦”是男性,但是统计到妹妹这个具有女性性别倾向的词语,而没有分析出句子结构,可能导致识别错误。
由以上实验可知利用性别倾向性描述词识别的效果最好。我们发现性别倾向性描述词具有很好的性别指示作用,如句子“正是那位名叫云妙裳的娥眉女将,年龄大约十八岁左右,黛丝粉面,柳眉樱唇”中“娥眉”、“柳眉”、“樱唇”都是女性性别倾向性描述词;又如“李举鹏身材颀长,看起来温文尔雅”中“颀长”、“温文尔雅”是男性性别倾向性描述词。理论上讲,性别倾向性描述词加入性别倾向性称谓词具有了更丰富的特征,因而更容易进行性别识别,如“另一个叫张月棋,梳着两条又长又黑的大辫子,是个眉眼清秀的乡下姑娘”句子中除去“辫子”和“清秀”女性性别倾向性描述词,女性性别倾向性称谓词“姑娘”起到正确的性别指示作用。
尽管性别倾向性描述词加入性别倾向性称谓词后识别总数增加了,但是其准确率反而有所下降,例如“单织罗柳眉倒竖,恨恨地为长兄抱屈”,“柳眉”是女性别倾向性描述词,但加入“长兄”这个男性倾向性称谓词反而起到误导作用。
实验当中有部分错误来自于某些性别倾向性特征词的用法多样,如女性别倾向性描述词“惊艳”一词。在句子“美希美得惊艳”中,“惊艳”形容“美希”,起到正确的性别指示作用。在“旁边的彭无惧不由得生出惊艳的感觉”中“惊艳”的用法却不同于前一句,故性别识别时可能带来误判。
分词错误也是性别识别出错的原因之一。对3.1节中获取的男性性别倾向性描述词“花言巧语”,但在句子中可能被分开,如“文秋龄/nh不愧/ns是/v花/nz言/n巧/n语/n的/n天才/w s”,因而不能起到正确地指示作用。另外,3.1节中获取的部分性别倾向性特征词的倾向性不够鲜明,如“意气风发”大部分时候形容男性,并归为男性性别倾向性描述词之列,但并不排除形容女性的可能。
3.2.3 基于性别倾向性词汇和姓名的性别识别
由3.2.2节中实验可知,性别倾向性词语对性别识别有着很好的指示作用。我们结合性别倾向性特征词语与姓名用字信息对性别进行识别实验,简单融合规则是,首先根据性别倾向性特征词语识别人物性别,如不能识别,则根据姓名进行识别,最终得到人物性别,实验结果如表3。

表3 基于性别倾向性词汇和姓名的性别识别结果
由3.2.2实验可知,尽管称谓词具有明显的性别指示作用,但是在没有较好效果的句法分析的前提下,仅根据性别倾向性称谓词识别人物性别并不能带来很好的效果。因而本实验中使用称谓词和姓名结合的方法其准确率最低。由于性别倾向性描述词结合性别倾向性称谓词后性别倾向性特征词数增加,因而性别识别总数增加,故性别倾向性描述词、称谓词和姓名结合起来的实验准确率最高。由3.2.1节中的表1可知,仅根据人名的性别识别,准确率为81.5%,加入性别倾向性词语后,准确率明显上升,由表3可见,性别倾向性词语对于性别识别有着显著的指示作用。
4 结束语
我们发现对文本中人物性别识别时除了利用其人名本身的用字特征外,还可以从整个段落或者整篇文章出发考虑篇章中描述不同性别时的两性特征差异。本文根据描述男女人物不同方面时存在的两性差异首先自动获取大量具有明显性别差异的性别倾向性描述词和性别倾向性称谓词。通过性别识别实验发现,性别倾向性描述词相对于性别倾向性称谓词具有更好的性别指示作用。另外,性别倾向性描述词结合性别倾向性称谓词和姓名的用字特征能较好的识别人物性别。下一步工作是扩大语料,获得更为丰富的性别倾向性特征词语。另外,可以进一步分析出句子结构,各成分的关系,相信性别倾向性特征词特别是性别倾向性称谓词能起到更好的指示作用。
[1] John Hale,Eugene Charniak,Getting Useful Gender Statistics from English Text,Tech Report cs-98-06[EB/OL],Brow n University,Providence,RI,1998.
[2] 王厚峰.指代消解的方法和实现技术[J].中文信息学报 ,2000,14(6):9-17.
[3] 梁茂成,李刚.英汉机器翻译中人称代词的处理[J].中文信息学报1999,13(4):1-6.
[4] 陆春艳.语言里的性别差异[J].安徽文学(下半月),2008(04).
[5] 钱进.语言性别差异研究综述[J].甘肃社会科学,2004(6):47-50.
[6] 董银秀.语言中的性别因素[J].兰州工业高等专科学校学报,2004,11(1).
[7] 樊斌.基于汉语语料库的性别词汇研究[D].武汉理工大学,硕士学位论文.
[8] 段新焕.汉语动作动词的性别编码及对认知的影响[D].华南师范大学,硕士学位论文.
[9] 钱进.姓名用字的性别差异统计分析[J].常州工学院学报,2004,17(5):60-62.
[10] 郎君,秦兵,刘挺,李生.中国人名性别自动识别[C]//第三届学生计算语言学研讨会.
[11] 王厚峰,梅铮.鲁棒性的汉语人称代词消解[J].软件学报,2005,16(5):700-707.
[12] 张莉萍.称谓语性别差异研究[D].中央民族大学,硕士学位论文.
[13] 李新光.浅谈小说教学中的人物形象分析[J].科教文汇,2007,(2):.
[14] Tseng Y H.Automatic Thesaurus Generation for Chinese Documents.Journal of the American Society for Information Science and Technology[J].2002,53(13):1130-1138.
[15] http://www.t351.com/name/changyongzi.htm[EB/OL].
[16] 唐琴,宋锐,林鸿飞.基于 CHUNK-CRF的情感问答系统[J].智能系统学报,2008,3(6):504-510.
[17] 徐琳宏,林鸿飞,杨志豪.基于语义理解的文本倾向性识别机制[J].中文信息学报,2007,21(1):96-100.
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
艺术品鉴(2020年11期)2020-12-28
小天使·一年级语数英综合(2020年4期)2020-12-16
艺术品鉴(2020年7期)2020-09-11
下一代英才(酷炫少年)(2018年4期)2018-04-28
语言与翻译(2015年4期)2015-07-18
传奇故事(破茧成蝶)(2015年7期)2015-02-28
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
