
基于最大频繁项集的搜索引擎查询结果聚类算法
2010-07-18 03:11陈清才王晓龙孟宪军
中文信息学报 2010年2期
苏 冲,陈清才,王晓龙,孟宪军
(哈尔滨工业大学深圳研究生院智能计算研究中心,广东深圳518055)
1 引言
随着网络信息的爆炸式增长,搜索引擎日益成为信息时代不可或缺的工具。现在大部分通用的搜索引擎将与用户查询相关的网页按照其与用户查询的相关度进行排序,返回给用户一个列表形式的网页查询结果,用户需要对每个网页逐一判断是否满足自己的要求。研究[1]表明大多数用户使用非常短的不确定的搜索字符串,并且85%的用户只查看第一页的结果,78%的用户从来不更改他们的查询词,另外由于用户的知识背景不同,对结果的期望也不同。因此为了满足日益增长的网络用户对查询质量的要求,必须提高搜索引擎查询结果对用户的可用性。
聚类技术可以有效地解决这种由于查询的模糊性而导致结果集合中主题分散的问题。文献[2]提出了“聚类假设”,即紧密联系的文档倾向于与同一查询相关。显然,通过聚类技术把查询相关的网页按照不同的主题分组呈现给用户,可以使用户更快的定位自己需要的信息。然而,传统的文本聚类算法大多基于向量空间模型和简单的无序词的集合(Bag-of-Words)进行聚类,不能更好的利用网页作为文本所拥有的自然语言的特点,也很难生成高质量的类别标签,因此准确性不高,且无法生成好的聚类描述信息帮助用户迅速把握各个聚类内的主题内容。
为解决这一问题,研究者提出了后缀树聚类算法(Suffix Tree Clustering)[3]和Lingo[4]等结合自然语言特点的聚类算法,这些算法提高了聚类的精度,更重要的是生成了描述性较好的标签。不过基于算法复杂性考虑,这两类算法都只是针对网页摘要进行处理,聚类效果难以获得更大的提高。解决这种算法复杂性与聚类性能之间的矛盾的关键在于寻找一种更加准确的网页文本表示方法。频繁项集是源自数据挖掘领域的概念,简单地讲就是在超过一定数目的网页中出现的词及词的集合。频繁项集的挖掘能很好的降低网页维数,并且在全文级别上挖掘出对聚类有贡献的词及词的集合。最大频繁项集是那些所有超集都不是频繁项集的频繁项集。采用最大频繁项集能大大降低频繁项集的规模,因此可以作为网页集合的更紧凑表示。同时,基于最大频繁项集的聚类也有可能进一步降低处理时间。正是基于这一概念,本文提出了一种基于网页最大频繁项集的查询结果在线聚类算法。通过改进最大频繁项集的挖掘算法,使其可以用于搜索引擎查询结果的在线聚类。新的算法利用网页集合对频繁项集的共享关系进行聚类,同时对每个类别生成清晰明确的标签加以描述。实验结果表明:基于最大频繁项集的聚类降低了基于全文的聚类时间,同时聚类精度提高了15%左右。
本文后续章节组织如下:第2节介绍了搜索引擎在线聚类的相关研究。第3节介绍了最大频繁项集挖掘算法。第4节对基于最大频繁项集的聚类算法进行了详细描述。第5节介绍了类别标签词的生成算法。最后给出了实验及结果,并对研究工作做出总结和展望。
2 相关研究
传统的文本聚类算法基于向量空间模型,将文档当作词的集合,根据TFIDF计算每个词的权重,以此计算文档间的相似性。很多聚类算法都已经被应用到文本聚类中,比如 K-Means[5],BisetKMeans[5-6],遗传算法[7],自组织映射算法(SOM)[8]等。但由于没有利用文档自身的自然语言的特点,传统的聚类算法准确度不高,且难以生成高质量的标签信息。
1997年Zamir和Etzioni[3]提出了后缀树聚类算法(Su ffix Tree Clustering,STC),突破了传统文本聚类算法应用到文本聚类问题中的局限与不足。随后研究者们提出了很多基于后缀树算法的改进,比如,文献[9]提出了ESTC(Ex tended STC)算法通过类别选择来改进后缀树聚类效果,文献[10]提出GAHC(Group-average Agglomerative Hierarchical Clustering)算法,通过改进相似度度量来提高基于后缀树的聚类效果。各种改进算法完善后缀树聚类算法,提高了聚类精度,但是基于后缀树的聚类算法在聚类应用(特别是中文聚类应用中)中有一些问题,主要包括:1)后缀树模型是针对英语提出来的,对中文不能有效地提取关键短语,容易生成没有意义的短语,比如“限公司”,“士学位”等;2)后缀树聚类算法目前的应用主要是基于网页摘要进行聚类,由于不能对网页进行降维,后缀树算法基于网页正文的聚类时间复杂度较高,难以满足在线聚类的要求,所以聚类精度的提高有瓶颈。
Lingo算法[4]着重于类别标签的提取,期望通过描有意义的标签来表达查询返回结果中包含的核心概念,然后通过奇异值分解将网页指派到不同标签对应的集合中。Lingo算法优势在于标签的提取,同时也取得较高的聚类精度。但由于中文语言的特点,Lingo算法标签提取的效果不够理想。
将频繁项集的思想用到网页(文本)聚类中的动机在于同一主题的网页在描述主题时会用到一些共同的词语,比如对于“金刚”这一查询词,描述变形金刚动画片中的网页,“动画,变形,科幻,擎天柱”等词会经常被用到;描述金刚石方面的网页,“金刚石,磨料,砂轮,材料”等词经常出现;而描述吉利公司金刚汽车的网页,“汽车,价格,市场,吉利”等频繁出现。反过来讲,包含相同频繁项集的网页倾向于属于同一类别。在基于频繁项集的文档聚类方面,FTC算法(Frequent T rem-based Clustering)[11]挖掘文档集合的所有频繁项集,由这些频繁项集生成候选簇,通过一种贪心策略,每次选择与其他候选簇重叠程度最小的簇来覆盖文档集合,直到所有文档被覆盖。文献[12]则利用挖掘出来的最大频繁项设定聚类的初始质心,然后进行 K-Means聚类,提高了KM eans算法的聚类效果。FIHC(Frequent Item setbased Hierarchical Clustering)算法[13]先是生成每个频繁项集对应的簇,然后根据文档与簇之间的紧密程度将文档指派到最紧密的簇中,最后对簇进行选择合并生成层次化的簇结构,同时依据频繁项生成簇的标签。
虽然与文档聚类有很大的相似性,但搜索引擎查询结果聚类并不等同于文档聚类,事实上,查询结果聚类是一种实时,动态的聚类,并且要求产生具有导航作用的标签。之前频繁项集方面的聚类算法的时间复杂度较高不能满足用户在线需求,另外其产生的标签仅仅是频繁项或者频繁项的组合,可读性不高,所以并不适用于查询结果的在线聚类。
另外,查询结果聚类不同于文档聚类还在于其处理的数据集是与用户查询词相关的网页集合,查询词本身对数据集具有很大指导作用。文献[14]提出利用查询词来指导聚类过程,从基类的生成到合并,拆分,到最后的簇的选择,取得了很好的聚类效果。本文借鉴了这种思想,在我们的聚类算法中利用了查询词本身对聚类的指导作用。
目前大部分搜索引擎查询结果聚类算法的研究是基于网页摘要的,Zamir[15]研究表明基于全文的聚类要比基于摘要的聚类更准确,但处理时间较长。经过对频繁项集挖掘算法的研究,我们发现在频繁项集的挖掘中,只挖掘最大频繁项集可以显著降低挖掘时间;另一方面,长度越长的频繁项集表达的意义越具体,对聚类的价值越大。因此通过挖掘全文最大频繁项集进行聚类是一种有效利用全文内容聚类的途径。
3 最大频繁项集的挖掘
3.1 频繁项集的基本概念
为了采用最大频繁项集来作为基于全文的网页在线聚类算法的基本特征,本节首先简要给出频繁项集的基本概念,有关频繁项集的更详细介绍请参见文献[16]。
定义1 设 I={I1,I2,…,In}是n个不同项的集合。如果对一个集合X,有X⊆I且k=|X|,则X称为k项集,或者简单的称为项集,X的长度为包含项的数目,即k。
定义2 记D={T1,T2,…,Tm}是m个不同事务的集合,其中Ti⊆I。对于给定事务集合D,定义X的支持度为D中出现X的事务的数目,记为Sup(X)。用户可以自己定义一最小支持度计数m in_supp,可以是绝对计数,也可以是相对计数。
定义3 给定事务集D和最小支持度计数m in_supp,对于项集X ⊆I,若Sup(X)>min_supp,则称X为D中的频繁项集,包含此频繁项集的事务集合称为频繁项集覆盖的事务集合。
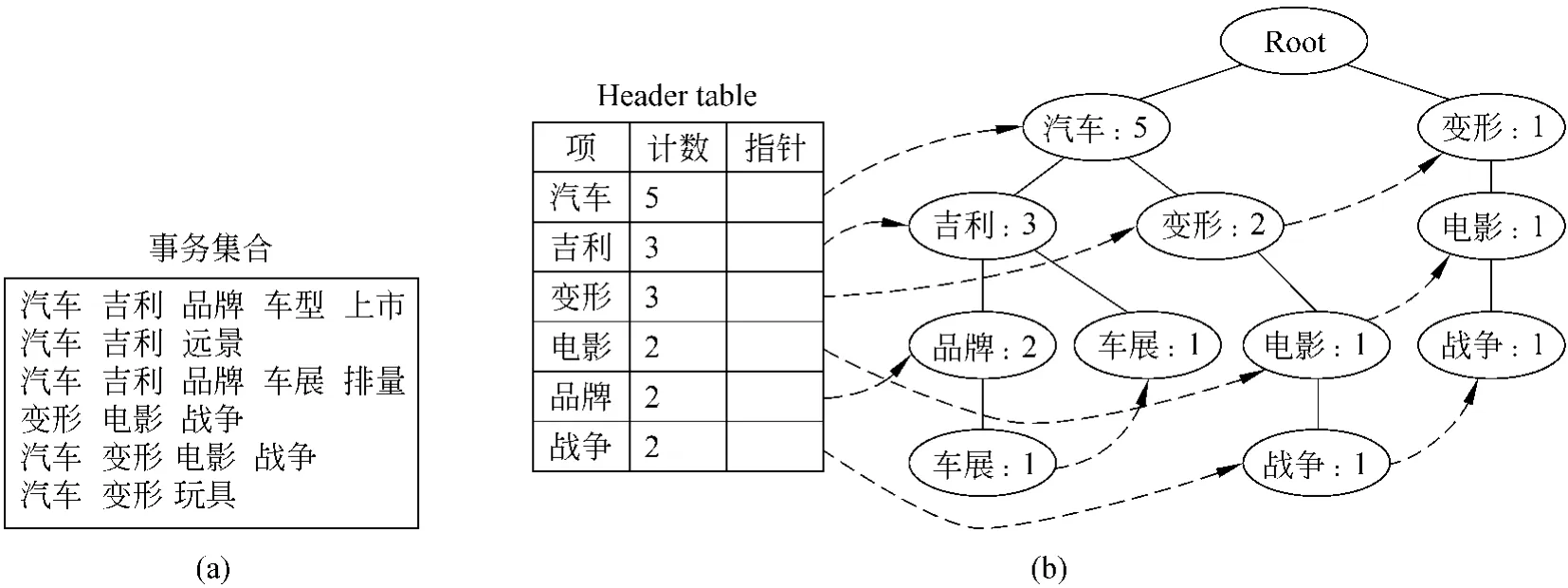
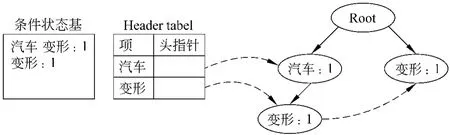
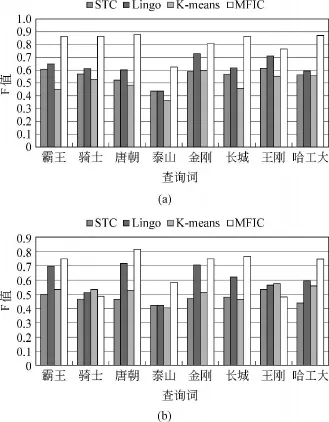
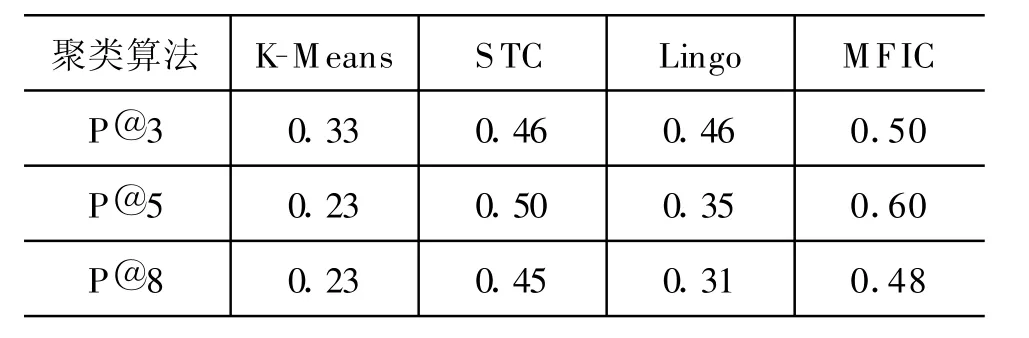
定义4 给定事务集D和最小支持度计数m in_supp,对于项集X ⊆I,若Sup(X)>min_supp,且对∀(Y⊆I∧X⊆Y),均有 Sup(Y) 在本文中,事务集即查询返回结果的网页集合,其中的每一篇网页即一个事务。项集就是网页中包含词语的集合,网页中的词即事务中的项。 最大频繁项集是本文聚类算法的基础,下面将介绍挖掘最大频繁项集采用的方法。 频繁项集的挖掘常用的算法是FP-Grow th算法[17]。算法首先构造一种称为FP-Tree(Frequent Pattern Tree)的线索树形结构存储集合中的事务。FP-Tree的构造首先要统计所有项的支持度,将支持度超过最小支持度计数的项按其支持度的降序排列在FP-T ree的Header table中;然后算法每次读进一个事务,将其映射到FP-T ree中的路径中。图1中给出了一个FP-Tree的例子(最小支持度为2),其中(a)为事务集合,(b)为构造成的FP-Tree。图中实线表示事务映射到树中的路径,虚线从Header Table开始指向项在树中出现的位置,节点中的计数表示从root节点开始到当前节点结束的路径对应项集的支持度,比如节点“品牌:2”表示{汽车,吉利,品牌}这一项集的支持度为2。 构造完 FP-Tree之后,FP-Grow th算法从Header table中最后一个项开始对每一个项,计算它的条件状态基(Conditionalpattern base),再由条件状态基构造新的FP-Tree,递归地挖掘频繁项集,直到树中只包含一条路径,判断当前项集的支持度是否大于最小支持度。图2就是图1树中项“电影”的条件状态基以及生成的新的FP-Tree,下一步再计算“变形,电影”的条件状态基等等。详细挖掘过程请参考文献[17]。 图1 一个FP-Tree的例子(m in_supp=2) 图2 项“变形”的条件状态基及对应的FP-Tree 最大频繁项集的挖掘,要对挖掘出来的频繁项集进行最大频繁项集的判断。比如现在已挖掘出最大频繁项集{电影,变形,战争},而频繁项集{电影,变形}是{电影,变形,战争}的子集,则不是最大频繁项集。这种子集判断的计算复杂度较高。为解决该问题,我们借鉴了Gosta等人提出的FPMax算法的基本思想[18]。FPMax算法的核心在于提出了一种M FI-Tree(Maximal Frequent Item-Tree)的数据结构,用来记录以挖掘出的最大频繁项集,降低了子集判断的时间。 上述最大频繁项集的挖掘算法应用到查询结果聚类中的不足在于,对于某一给定的最小支持度计数(绝对计数10或者相对计数5%),不同的查询词的挖掘时间有较大差异。降低支持度计数会造成部分查询词的频繁项集规模较小,提高支持度计数则造成部分查询词挖掘时间过长不能满足用户在线查询的需要。本文通过取支持度最高的前N个词,然后将第N个词的支持度设为最小支持度计数,使得不同查询词挖掘时间的差异显著降低,更好地适用于查询结果聚类。另一方面,不同于经典聚类应用中的标准数据,网页集合中包含的词是语言学的基本单位,不同词性的词在表征文本的时候其贡献不同[19]。本算法中为了提高聚类速度,我们只选择名词,动词,形容词等实词,而将连词,代词,助词等去掉。我们进行实验发现,进行词性选择后网页平均长度降到之前的50%左右,聚类精度保持在95%左右。 在挖掘出频繁项集之后,聚类途径有两种选择:第一,用频繁项集替代词构造网页的特征向量,使用传统的基于向量空间模型的聚类算法;第二,通过频繁项集覆盖网页集合的关系进行聚类。前者的时间复杂度已被证明不能满足在线聚类的需要,同时受限于传统聚类算法的缺陷,聚类效果不理想。本文采用第二种途径。 算法[13]也采用了第二种聚类途径,但它基于所有频繁项集生成簇,然后依据统计信息对生成的簇进行评价,选择出来最后的簇集合。一方面,由于频繁项集的规模较大,相比于最大频繁项集需要更多的挖掘时间。另一方面,相比于频繁项集,最大频繁项集是紧凑的表示,且长度较大,对聚类更有意义。例如,查询词“金刚”的一个最大频繁项集{变形,电影,战争,汽车,擎天柱},表述了《变形金刚》电影这个方面的主题,其覆盖的网页集合相关性较大。显然,这个最大频繁项集的所有非空子集都是频繁项集(共31个),比如{战争,汽车},其覆盖的网页集合的主题过于宽泛,可能包含多个类别的网页。 本文的聚类算法正是基于上面的想法,利用网页共享最大频繁项集的关系进行聚类。 为后文描述方便,我们定义如下:记D={T1,T2,…,Tm}为所有事务的集合,在本文中即查询网页的集合。记I={I1,I2,…,In}为所有项的集合,即网页集合中包含词的集合。记Sm={M 1,M 2,…,Mn}为挖掘得到的所有最大频繁项集的集合,一个最大频繁项集Mi覆盖的网页集合(即包含这个频繁项集的网页集合)记做Pi,Pi⊆D。聚类的过程就是把网页集合分成若干个簇,记C={C1,C2,…,Cl}为簇的集合,一个簇Ci包含的网页集合记做CPi,CPi⊆D,包含的最大频繁项集的集合记做CMi,CMi⊆Sm,包含的频繁项的集合CIi,CIi⊆I(注:簇包含频繁项的集合不是频繁项集,是簇中所有最大频繁项集包含频繁项的并集,本身不是频繁项集)。记Dc={T1,T2,…,Tk}为D中已被簇覆盖的网页集合。 下面介绍聚类算法的核心步骤:Step 1 簇的生成 频繁项集的长度越长,其包含的词越多,越能表达一个具体的话题,因此我们优先选择长的频繁项集生成簇。 将Sm中的频繁项集按其长度排序,依次选择最长的频繁项集M i生成簇Ci,Ci包含的网页集合CPi即Mi覆盖的网页集合Pi,记录已被簇覆盖的网页集合D c=Dc∪Pi。为了提高簇生成的速度,减少后续合并过程中的传递效应,要对Sm中的频繁项集做一步过滤。如果一个频繁项集Mk覆盖的网页集合P k⊆Dc,说明Pk中所有网页已被簇覆盖过,不生成Mk对应的簇Ck。 Step 2 簇的合并 初始生成的簇数量过多,且有很多重叠,需要进行合并生成最后的簇。簇的合并即把相似度较高的簇合并为一个,通常簇的相似度通过包含网页集合的相似度来判断。基于频繁项集的聚类算法中簇包含的频繁项是簇的重要特征,我们可以结合包含频繁项的相似度进行簇的相似度计算,提高精确度。本文提出公式(1)进行簇相似度的计算: 簇Ci与Cj的相似度记做Sim(Ci,Cj),包含网页的相似度记为SimPij,包含频繁项的相似度记为Sim Iij。 Sim(Ci,Cj)越大,簇Ci与Cj相似度越高,越倾向于合并。 这种依据集合的关系运算计算簇能够对多数簇正确合并,但仍有不足:第一,参数敏感,阙值的设定对不同的数据集有很大偏差;第二,传递效应,比如A与B相似,B与C相似,会把A,B,C三者合并,然而A和C可能不相似 。针对这一问题,算法深入结合簇中包含频繁项的特征就行判断。利用簇中频繁项在另一簇中出现的频率指导簇合并的判断。 共现率是指簇Ci中的频繁项在簇包含的网页中的平均出现次数。通过对方簇中网页对自己簇中的频繁项的“认可度”指导簇的合并。本文引入公式(2),定义簇Ci在簇Cj中的共现率cf ij(簇 Cj在簇Ci中的共现率同理): 其中t f(I,P)为项I在网页P中出现的次数。 共现率高说明簇之间包含网页内容上相近。 结合共现率的概念,本文设计簇合并的判断算法,在算法实现中,对于簇的相似度设定两个阙值,强约束阙值Ts比如(比如1.1),弱约束阙值Tw(比如0.8),对共现率设定一个阙值Tc f(比如3)。算法如下: ·如果Sim(Ci,Cj)大于Ts,合并簇; ·如果Sim(Ci,Cj)小于Tw,不合并簇; ·如果Sim(Ci,Cj)在 Ts与Tw 之间,计算簇之间的共现率c fij,如果cfij大于Tc f,合并簇,否则不合并。 合并过程将满足上面条件的簇进行合并,生成最终簇的集合。对于可以合并的簇,将簇Cj对应的CPj,CMj,CIj合并到簇Ci对应的CPi,CMi,CIi中,然后将从簇Cj集合中删除。 Step 3 簇的净化 聚类可以分为硬聚类和软聚类,硬聚类要求一个网页只能属于一个类别,软聚类允许一个网页属于多个类别,相对于硬聚类能更好地反映现实情况。但由于簇合并过程的传递效应,簇中会包含一些不相关的网页。如何识别簇中的网页是无关网页还是多类别网页是关键问题。本文中无关网页的识别是通过网页相对簇的支持度判断的。为此本文定义网页P相对簇Ci的支持度如下: 根据实验我们可以获得一个经验值,当Supp(P,Ci)小于这一值时,认为是簇无关网页,将其从簇中删除。 基于频繁项集的聚类,会有部分网页因为未包含任何频繁项集,而没有被簇覆盖,需要将这部分网页分类到已有的簇中。 查询返回网页聚类的应用中簇的标签词是对簇内容的标示,指导用户浏览结果和进一步查询,有着非常重要的意义。 基于频繁项集的聚类算法生成的簇中,频繁项是标签词的候选。例如对于查询词“金刚”,生成的一个簇包含的频繁项集{价格汽车 上市 吉利自主图片轿车售价对比车型最低报价}。一方面具有较高的描述能力和可读性的项(即词)适合做簇的标签词语,比如上面例子中“汽车”;另一方面,短语相对单个词有更好的描述能力,为用户查询提供更好的提示,比如“吉利汽车”,“变形金刚”。 本文的标签生成算法就从这两个方面挖掘标签词或短语, 第一,选择对簇内容最有代表性的项。考虑的因素有: a.项的词性。名词比动词,形容词更适合做标签,同时动词性名词,形容词性名词也有较好的描述能力。根据项的词性,选择名词,动词性名词及形容词性名词做标签候选; b.项在簇包含频繁项集中的支持度。即有多少个频繁项集包含这个项。项被越多的频繁项集包含就越能表达簇的内容; c.项在簇中包含网页集合的统计数据,即项在网页集合的出现的频率(TF)及项的逆文档频率(IDF)。这是借鉴传统文本表征模型统计词权重时采用的方法。 综上所述,本文引入公式(5)定义簇Ci中项Ij的标签得分: 其中 posScore(W j)为项 W j词性的得分,t fid f(Wj,Pk)为项Wj在网页Pk中TFIDF值。 第二,通过词语间的顺序关系,挖掘短语性标签。网页不仅是词的组合,词语间顺序出现的关系也是表达网页内容的重要特征,比如说“金刚”这个词进行聚类后,其中一个簇是变形金刚动画片相关的网页,“变形”是其中一个很重要的标签词,直接用“变形”做标签比较生硬。通过挖掘标签词与查询词紧邻出现的关系,可以生成可读性更好的标签,比如“变形金刚”。短语标签的挖掘是通过统计的方法获得的,具体做法:如果两个词的顺序组合在簇中半数以上的网页摘要中出现,则可做为短语标签。 综上所述,本文算法标签词生成算法步骤如下: 1)选择词性为名词,动词性名词,形容词性名词的项做标签候选; 2)根据公式(7)计算项对于簇的标签得分; 3)从标签候选中选择得分最高的项开始,检查是否可与查询词组成短语标签。如果可以,则以此短语标签做簇的标签;否则把项从标签候选中删除,重复步骤3),如果标签候选为空,转到步骤4); 4)如果所有项都不能与查询词组成短语,选择得分最高的两个项做类别标签。 这里采用的簇标签生成算法不仅有效地利用了全文挖掘的深层次内容,还借鉴了后缀树算法生成标签的思想,生成质量更高的标签,对基于频繁项集的文本聚类标签生成算法是一个重要改进。 实验所用机器配置为Intel(R)Pentium D CPU 3.00GH z,2G内存,操作系统为 Linux Fedora Core 4。 实验所用数据是选择8个有查询歧义的查询词对应的数据集。对每个查询词取得相应的百度以及Google返回结果的前100条,取并集,然后对网页进行分词和词性标注,建立索引后保留网页的分词结果以备后面算法需要。上述工作离线完成,为在线查询聚类准备数据。 我们对网页集合进行人工的类别标注,每个查询词网页集合标注了若干类别。 由于K-M eans算法需要设定k值,我们分别设定4次K值(5,6,7,8)进行实验,对每个查询取4次实验结果中F值最高的做为最终结果。STC算法,Lingo算法,MFIC算法自动生成不定数目的类别,同时会有一些只包含2,3篇网页的簇,而实际应用中通常会只显示包含网页较多的簇,结合实际应用我们把包含网页数目小于5的类归为其他类。实验中我们通过调整参数使得这三种算法的类别数目分布在5~10范围内。 本文实验比较了基于全文的M FIC算法和K-Means算法,同时比较了基于摘要的后缀树聚类算法(STC)的聚类时间(图3)。由于STC对网页全文聚类时间太长(实验数据显示在10秒以上)不能用做在线聚类,在此不做详细展示。另外由于Lingo算法使用的是开源的Java实验,其他算法是C++实现,这里没做比较。 从图中看出M FIC聚类时间优于K-Means聚类的时间。由于M FIC聚类是基于网页全文,聚类时间长于基于摘要的STC在预料之中。实验结果表明MFIC聚类时间基本控制在2秒左右,可以满足在线聚类需要。为了进一步提高系统反应,在具体应用中可以通过设置聚类结果缓存,减少用户等待时间。 图3 聚类算法时间对比 检索结果聚类系统的评价不同于一般的文本聚类评价,除了对文档在类别中的分布进行评价外,还需要对类别标签进行评价。其中对文档在类别中的分布进行评价,常用的两个指标为:纯度[20]与F值[6]。 对于聚类后形成的任意类别r,聚类的纯度定义为: 整个聚类结果的纯度定义为: 其中n是预定义类别的个数,k是聚类类别的个数,nr为聚类类别r中的文档个数,是属于预定义类别i且被分配到聚类类别r的文档个数。 F值的定义则参照信息检索的评测方法,将每个聚类结果看作是搜索的结果,从而对于最终的某一个聚类类别r和原来的预定类别i有: 其中ni是预定义类别i的文档个数,其他定义同前。则聚类r和类别i之间的FMeasure值计算如下: 聚类结果总的F值为: 对类别标签进行评价常用的方法是P@N[20],P@N定义为前N个结果中的精度,即: 其中R是聚类算法返回的前N个标签词集合,C是人工标注的标签词集合。 在纯度的比较方面,M FIC算法纯度明显优于其他算法(见图4(a))。这跟MFIC算法的特点有关:第一,MFIC算法通过最大频繁项集确定簇,最大频繁项集包含较多的频繁项(比如,金刚这个查询词对应的一个最大频繁项集{电影导演上映 全球票房}),对网页集合具有较高的区分度,共同包含一较长频繁项集的网页基本都属于一个类别;第二,通过共现率概念的引入,提高了簇合并过程的精度。这一特点,使得M FIC算法能给用户带来更好的搜索体验。比如金刚这一查询词生成了四个类别“变形金刚”,“吉利金刚”,“电影 剧情”,“金刚石”等,其中少数“电影 剧情”方面的网页错分到了“变形金刚”类中,其他类别包含的网页几乎全是类别相关的。 STC通过将共享同一字串的网页归为一个类别,也能生成纯度较高的类别,不过可能会产生较多的类别,类别的合并可依据的内容较少,聚类精度会受影响[9]。Lingo算法首先寻找重复出现的,描述性强的标签,依据这些标签生成簇,然后通过奇异值分解将网页划分到簇中[4]。Lingo算法的纯度值优于STC算法,但由于效果较依赖于第一步中寻找出的标签,如果标签本身区分度差,该标签生成的簇的纯度就会受影响。K-M eans算法因为对初始参数和噪音较为敏感,有时会造成聚类结果失衡,即生成的簇的大小差异很大,所以其聚类的纯度明显差于其他算法[22]。 图4 聚类算法纯度和F值对比 在F-M easure的比较上MFIC算法明显优于其他算法(见图4(b))。K-M eans算法受初始参数影响较大,且对噪音敏感。查询结果的聚类难以准确的设置初始参数,同时噪音信息较多,影响了K-Means的聚类效果,使得K-Means算法不适合用来做查询结果的聚类,实验数据也说明了这一点。 STC算法和 Lingo算法因为只根据搜索引擎查询结果中的摘要进行聚类,可靠性差,且受限于摘要的质量,精确度不如MFIC算法。另外相对于Lingo算法,STC算法F值较差,原因在于仅仅根据摘要中的共享字符串来聚集查询结果,会造成很多网页未被任何挖掘出来的共享字符串覆盖,使得这些网页不能被正确的聚类;而Lingo算法,通过奇异值分解方法,即使网页不包含相同词,也可能被聚集到一起。 MFIC算法相对与STC算法与Lingo算法的优势还在于算法的可改进性,因为其依据的是网页全文内容,在频繁项集的选择和类别的合并,净化等过程可以采用尝试很多算法来优化整体效果。 聚类标签的评测我们采用的P@N方法。表1是对查询词标注的类别: 表1 人工标注的类别标签词 我们分别对所选聚类算法的每次查询计算P@3,P@5,P@8值,取8个查询词的平均值做为评价标签质量的依据,最终结果见下表。 表2 聚类算法类别标签P@10值比较 由于M FIC算法基于全文且考虑了多种因素,挖掘出的标签更能表征网页集合的内容与主题,比如“历史” 、“电脑” 、“小说”等,这是STC 算法和Lingo算法较难挖掘的。 STC和Lingo算法擅长挖掘频繁出现的字串,即短语标签,比如“霸王条款”、“变形金刚”、“詹姆斯”,而本文的算法也借鉴这种思想进行了改进,挖掘标签词和查询词之间的顺序关系,可以生成短语性标签,改进了基于频繁项集聚类的标签生成。改进后的标签挖掘算法可以挖掘出“变形金刚”、“霸王条款”形式的标签,然而由于M FIC算法依赖分词结果,对于词典中不存在的词(比如“詹姆斯”)无法生成标签。 本文提出了一种基于全文最大频繁项集的搜索引擎返回结果聚类算法。首先我们研究了频繁项集的挖掘算法,结合FPMax算法对最大频繁项集的挖掘进行了改进,提高了最大频繁项集的挖掘速度。然后提出了一种基于最大频繁项集聚类的算法M FIC。M FIC主要包括三步,(1)由挖掘出的最大频繁项集生成簇;(2)结合频繁项集的相似度和簇包含文档集合的相似度进行簇的合并判断;(3)最后对生成的簇提出了一种结合频繁项集与词语顺序的标签生成算法。 实验结果表明MFIC算法聚类效果优于其他算法,聚类时间优于同样基于全文的K-M eans算法,且能满足在线聚类的需要。 通过本文研究发现,基于频繁项集的聚类算法在全文聚类方面有较大优势,不仅能对网页很好的降维,同时产生的频繁项集可以做为标签的候选。另一方面基于频繁项集的聚类算法还有许多可以改进的地方:第一,中间簇的合并过程,线性的合并不能很好的代表网页之间的类别联系,可以尝试通过图的模型进行簇的合并;第二,标签词的生成,如何判断识别较高概念层次的词,生成更智能的标签也是一项有研究价值的课题。 [1] Lan H uang.A Survey on Web Information Retrieval Technologies[EB/OL].ECSL Technical Report,State University of New York,2000. [2] C.J van Rijsbergen.In formation Retrieval[M].London:Butterw orths,1979. [3] Oren Zamir,O ren Etzioni.Web document clustering:A Feasibility Demonstration[C]//Research and Development in In formation Retrieval,1998:46-54. [4] Stanislaw Osinski,Jerzy Stefanowski,and Dawid Weiss.Lingo:Search Results Clustering A lgorithm Based on Singular Value Decomposition[C]//Proceedings o f the International IIS:Intelligent In formation Processing and Web M ining Conference,Advances in SoftCom puting,2004:359-368. [5] Liping Jing,Michael K.Ng,and Joshua Zhexue H uang.An Entropy Weighting k-M eans A lgorithm for Subspace Clustering of H igh-Dimensional Sparse Data[J].IEEE Transactions on Know ledge and Data Engineering,2007,19(8):1026-1040. [6] M ichael Steinbach,George Karypis,Vipin Kumar.A Comparison of Document Clustering Techniques[EB/OL].Technical Report,University of M innesota,2000. [7] Wei Song;Soon Cheol Park.Genetic algorithm-based tex t clustering technique:Automatic evolution of clustes with high efficientcy[C]//Seventh International Conference on Web-Age Information Management Workshops.H ong Kong 2006:17-17. [8] Richard Freeman,Hu jun Yin.Self-Organising M aps for Hierarchical Tree V iew DocumentClustering Using Contextual In formation[C]//Proceedings o f the IEEE International Joint Con ference on Neural Networks.2002:123-128. [9] Daniel Crabtree,Xiaoying Gao,Peter Andreae.Imp roving Web Clustering by Cluster Selection[C]//The 2005 IEEE/WIC/ACM International Conference on Web Intelligence.2005:172-178. [10] Hung Chim,Xiaotie Deng.A New Suffix T ree Sim ilarity Measure for Document Clustering[C]//World W ide Web Conference Comm ittee.2007:121-129. [11] Florian Beil,Martin Ester,Xiaow ei Xu,Frequent Term-Based Text Clustering[C]//Proceedings of ACM SIGKDD International Con ference on Know ledge Discovery and Data M ining.2002:436-442. [12] Ling Zhuang,Honghua Dai.A Maximal Frequent Itemset Approach For Web Document Clustering[C]//Proceedings of the Fourth International Conference on Computer and Information Technology.2004:970-977. [13] Benjam in C.M.Fung,Ke Wang,Martin Ester.H ierarchical Document Clustering Using Frequent Itemsets[C]//Proceedings of SIAM Internationa l Conference on Data M ining.2003:59-69. [14] Daniel Crabtree,Peter And reae,X iaoying Gao.Query Directed W eb Page Clustering[C]//Proceedings of the IEEE/W IC/ACM International Con ference on W eb Intelligence.2006:202-210. [15] O ren Zamir.Clustering Web Documents:A Phrase-Based Method for Grouping Search Engine Resu lts[D].PhD Thesis,University of Washington,1999. [16] Jiawei H an,H ong Cheng,Dong Xin,Xifeng Yan.Frequent pattern m ining:Current status and future directions.Data M ining and Know ledge Discovery[J].10th Anniversary Issue,2007,15(1):55-86. [17] Jiawei H an,Jian Pei,Yiwen Yin,Runying Mao.M ining Frequent PatternsW ithout Candidate Generation[C]//Proceeding o f Special Interest G roup on Management of Data.2000:1-12. [18] Gosta Grahne,Jianfei Zhu.High Performance M ining of M aximal Frequent Itemsets[C]//Proceedings of the 6th SIAM International Workshop on H igh Performance Data M ining.2003:311-337. [19] K rishna Kummamuru,Rohit Lotlikar,Shourya Roy.A H ierarchical Monothetic Document Clustering A lgorithm for Summarization and Brow sing Search Resu lts[C]//Proceedings of the 13th Internationa l Conference on W or ld Wide Web.2004:658-665. [20] Ying Zhao,George Karypis.Criterion Functions for Document Clustering:Experiments and Analysis[EB/OL].TechnicalReport,Department of ComputerScience,University of M innesota,2001,01-40. [21] Huajun Zeng,Qicai He,Zheng Chen,et al.Learn to cluster web search resu lts[C]//Proceedings of Sheffield SIGIR.2004:210-217. [22] Zhe Zhang,Junxi Zhang,H uifeng Xue.Imp roved K-means Clustering A lgorithm[J].Journal of Southeast University.2007,23(3):435-438. [23] 刘远超,王晓龙,等.文档聚类综述[J].中文信息学报,2006,20(3):55-62. [24] 赵世奇,刘挺,李生.一种基于主题的文本聚类方法[J].中文信息学报,2007,21(2):58-62. [25] 邱志宏,宫雷光.利用上下文提高文本聚类的效果[J].中文信息学报,2007,21(6):109-113. [26] 李红梅,丁振国,周水生,等.搜索引擎中的聚类浏览技术[J].中文信息学报,2008,22(3):56-63 [27] 骆雄武,万小军,杨建武,等.基于后缀树的W eb检索结果聚类标签生成方法[J].中文信息学报,2009,23(2):83-88.3.2 最大频繁项集挖掘算法
3.3 面向查询结果聚类应用的改进
4 基于最大频繁项集的查询结果聚类算法




5 簇标签的生成


6 实验结果与分析
6.1 实验环境与实验数据
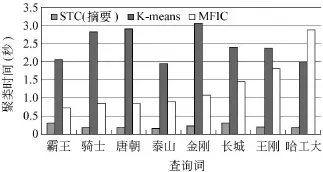
6.2 聚类算法时间
6.3 聚类评测标准
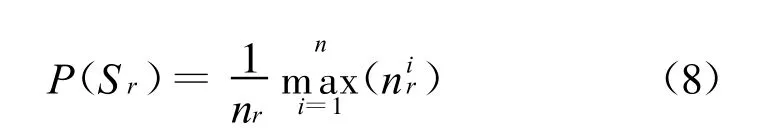
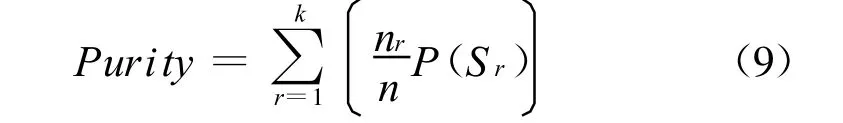

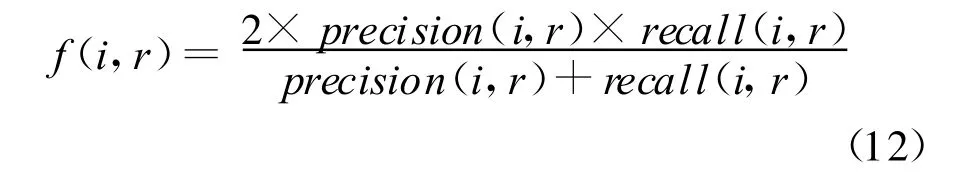
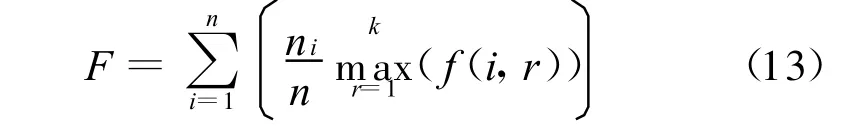
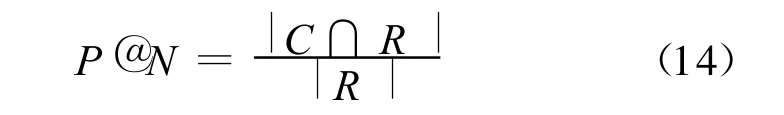
6.4 聚类评测结果
6.5 聚类标签效果

7 结论
猜你喜欢
成都信息工程大学学报(2021年6期)2021-02-12
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
民族古籍研究(2018年1期)2018-05-21
计算机技术与发展(2017年8期)2017-09-01
电子制作(2017年2期)2017-05-17
西夏学(2016年2期)2016-10-26
浙江大学学报(工学版)(2015年1期)2015-03-01
