
基于CRF的先秦汉语分词标注一体化研究
2010-07-18 03:11陈小荷
中文信息学报 2010年2期
石 民,李 斌,陈小荷
(南京师范大学文学院,江苏南京,210097)
1 引言
中文信息处理研究在现代汉语领域已经取得了比较丰硕的成果,但古代汉语信息处理还有待探索。目前,先秦文献的信息处理大体还处于字处理阶段,以解决古文字的输入输出、文献逐字索引等问题为主要内容,实用成果仅限于古籍文献的专题索引和查询。
我们正在实施的项目是“先秦汉语词汇统计与知识检索系统”,准备对25种最重要的先秦传世文献进行词语切分、词性标注、个别常用词(包括古今字和通假字)的词义标注,建立先秦文献的词汇知识库以及历史知识库,并研制相应的检索系统。要实现这一目标,古文献的切分标注是古汉语语料库建设的一项基础性工作。先秦汉语以单字词为主,也存在着一定量的多字词,在缺少分词词典和训练语料的条件下,分词标注仍有难度。正如古汉语计算语言学家尉迟治平的呼吁:“我们期望能有可以用于汉语史电子文献自动分词、自动断句、自动标注的软件早日问世,专家只需对结果刊谬补缺,这将大大减轻属性式标注的劳动强度,加快工作进度[1]。”
针对古汉语的自动分词,已经有了一些研究成果。台北中研院的“汉籍电子文献”对以《十三经》为主的先秦文献进行了分词和词性标注,可以通过“瀚典全文检索系统”对文献进行检索、统计、搭配[2]。但文献数量还较少,分词标注方法也以较为传统的最大概率和隐马尔科夫模型为主。邱冰则提出一种启发式的混合分词方法,以反向最大匹配分词为主,同时统计已出现词语的频率和汉字间的互信息,一方面对高频词进行直接的提取,另一方面调整词表增加新的词语[3]。由于采用《汉语大词典》作为通用分词词典,存在一定的局限性。
汉语的分词和词性标注工作,通常是在自动分词的基础上,再进行词性标注。这种“两步走”的方法,存在错误扩散问题,会影响到最后的标注精度。白栓虎给出了汉语词切分和词性标注一体化的隐马尔科夫模型,并进行了小规模试验[4]。Hwee Tou Ng和Jin Kiat Low则深入比较了两步走和一体化的优劣,提出基于字标注的一体化方法是最佳的方案,其分词系统获得Sighan2003四个测试语料中的三项封闭测试第一,同时又肯定了两步方案在训练和测试时间上的优势[5]。Yue Zhang和 Stephen Clark提出使用单一感知器模型的分词和标注一体化方法,由于充分利用了词性信息,分词准确率和召回率均有大幅提高[6]。这些研究表明,在现代汉语语料上,分词标注一体化方法效果较好,只是训练时间开销较大。
本文着力研究面向先秦文本的分词和词性标注,以人工标校的《左传》作为实验对象。首先进行了语料分析,然后分别设计了基于条件随机场模型(CRF)的自动分词、词性标注、分词标注一体化实验,以寻找适合古汉语分词标注的最佳方案。研究成果可以服务于古籍文献的语料库建设,将研究人员从繁重的语料标注工作中解脱出来,仅需校对机器自动处理的结果,也可以有效缓解人工标注一致性较差的问题。
2 先秦汉语分词标注规范及语料考察
2.1 语料来源
《左传》是先秦文献的经典之作,内容是传《春秋》的,即春秋时期各国的历史。篇幅约23万字,是先秦传世文献中单本字数最多的文献,非常适合用来作为机器学习的对象,服务于先秦其他文献的自动标注。
本文使用的语料底本,是由香港中文大学中国古籍研究中心建设的汉达文库的《左传》的“传”文。该文库收录的文献版本,均为旧刻善本,后由研究人员重新标点、校勘。为了保证语料质量,我们参照了古文献界较为公认的杨伯峻的《春秋左传注》[7],以解决异文(添字、缺字、异体字等)问题,不一致处按中华书局版校正。语料采用Unicode编码存储。
2.2 先秦汉语分词标注规范
确定古汉语的分词标准及词类体系,是分词标注的基本前提。我们参照了台北中研院的《资讯处理用分词规范》,采用词汇意义和语法功能兼顾的标准,确定出适合古汉语的分词单位及词类体系①可以查阅南京师范大学CIPP中文信息处理平台网站《先秦汉语分词标注规范》,http://www.cipp.cn/new s_view.asp?id=76。。和中研院的主要差别是,将数词进行了捆绑处理,区分了三种常见的词类活用方式,共设立了21个词类标记(见表1)。

表1 先秦汉语词类标注基本集及词类统计信息
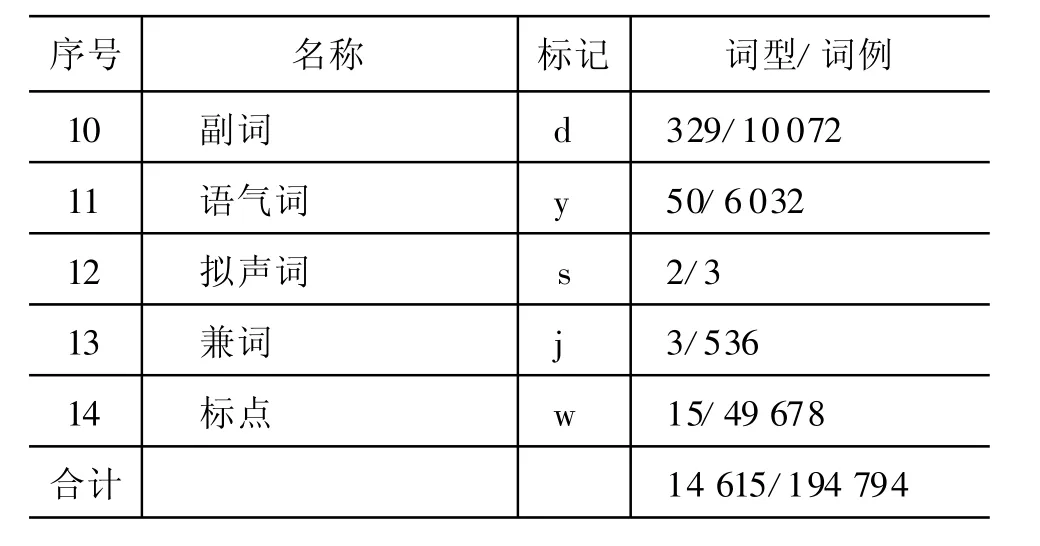
续表
2.3 语料的人工标注和考察
四位语言学专业的研究生,参照杨伯峻的注释和《春秋左传详解词典》[8],对语料进行了人工切分标注和校对。本文所用语料版本为V 2.0①CNCCL2009会议论文所用语料为V 1.0,详见《中国计算语言学研究前沿进展》,P46-P51,清华大学出版社,2009年7月出版。会后对语料进行了一次校对工作,形成现在的版本V 2.0。。《左传》的传文部分,共179 792个汉字,除去标点,共3 308个字型、14 600个词型(区分词性)。其中,多字词有9 973个词型,占全部词型的68.31%,但只占词例数的21.02%(见表2),平均词长为1.81字。由此可见,先秦汉语的基本特点是以单字词为主的,同时,多字词也是不可忽视的。如果整个语料按照单字来切分,正确率大约只有79%。因此,如何处理多字词应成为分词的重点研究对象。

表2 左传词型、词例统计(除去标点,区分词性)
3 实验及分析
3.1 实验语料
《左传》按照鲁国12个国君的谥号,共分12卷。在实验中,本文将前十卷作为训练语料,后两卷作为测试语料,训练测试比约为6∶1(见表3)。
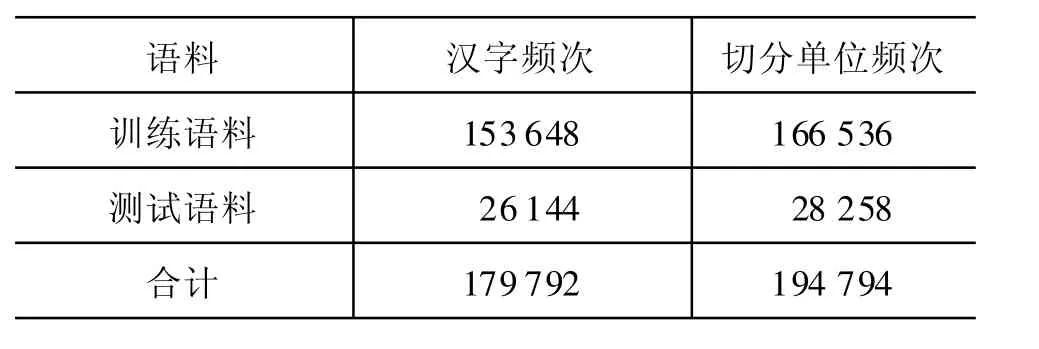
表3 训练测试语料情况
3.2 基于CRF的分词实验
本文采用由字构词原理进行汉语自动分词,将分词问题转化为词位信息的序列标注问题。CRF是一个应用广泛的序列标注模型,该模型允许增加复杂特征,可以有效地处理标记偏置问题。实验采用Taku Kudo开发的“CRF++0.53”工具包进行训练和测试。②下载地址为:h ttp://crfpp.sou rceforge.net/ 。由于《左传》的平均词长为1.81字,且存在三字以上的词,因此使用四词位标注集,即T={B,M,E,S},其中B代表词首第一个字,E代表词尾最末字,M代表一个词中间的任意字,S代表单字词和标点。语料样例见表5的“字符”列和“分词格式”列。
仿照SIGHAN竞赛,我们给分词精度设定了Baseline和Topline。分别为采用训练和测试语料的词表,对测试语料进行正向最大匹配法分词,F值分别为83.39%和96.46%。
实验一 采用字面信息作为特征,比较了上下文窗口为左右1~3个字,以及二字、三字同现情况下的分词结果。
从表4可以看出,任何一个分词结果都超过了Baseline。增加二元、三元同现特征,比单字上下文特征效果要好。在窗口为±1个字、二元字同现(1W+2)的情况下,精度最高,达到了93.75%。

表4 基于字面特征的分词评测结果
实验二 为了获得更佳的分词效果,以分词效果较好的“1W+2”、“2W+2” 、“3W+2”3 个模板为基础,增加了一些语言学特征进行实验。这些特征包括字符分类、声、韵、调、部首。我们将字符分为“汉字(HZ)、普通标点(Punc)、句末标点(Sen-Punc)、西文数字(Num)、汉字数字(CNum)、干支(CCNum)”等类别。由于先秦汉语的声、韵、调皆为拟音推测,也没有比较公认的数据库,因此选取了描写中古汉语的《广韵》作为基本数据库来近似,为了保证字符的覆盖率,部首信息取自《康熙字典》。语料样例见表5(“分词标注一体化格式”列除外)。
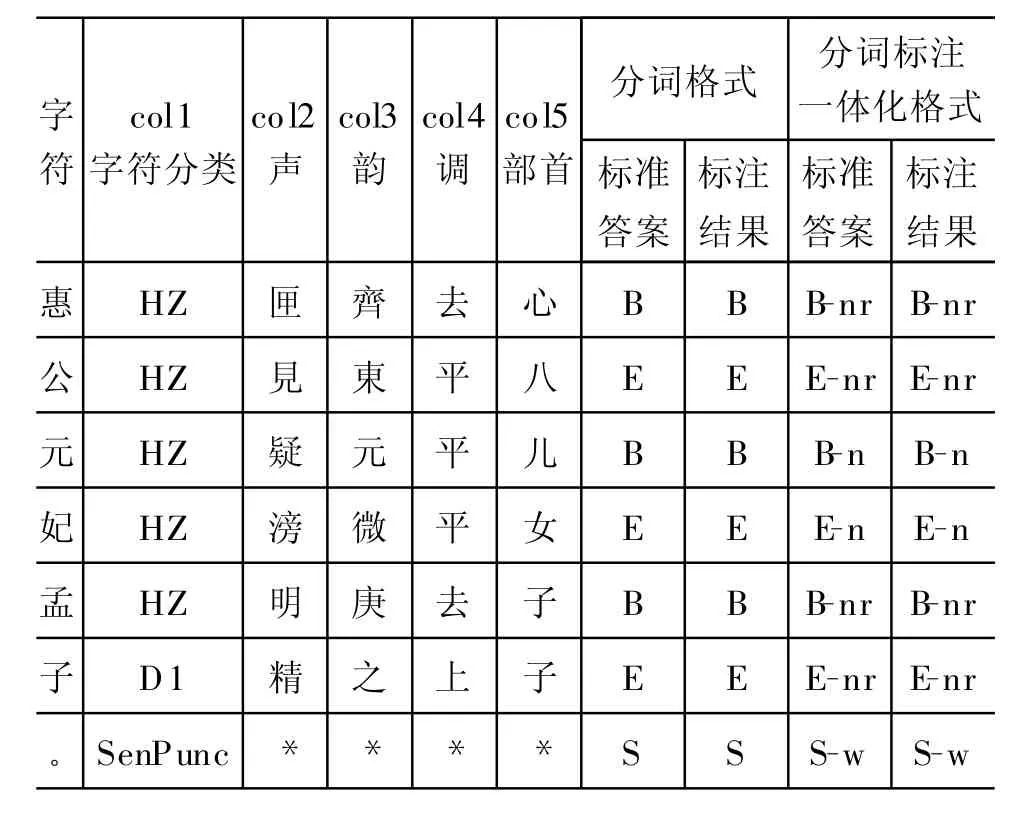
表5 增加语言学特征的分词/一体化训练和测试语料样例
根据是否采用字符分类特征以及不同的特征组合、上下文窗口,分别进行了四组实验(见表6)。第一组与第二、三组的区别为是否增加字符分类,二至四组主要是上下文窗口长度不同。
从实验结果来看:
(1)增加字符分类特征有助于提高分词精度。使用字符分类特征的结果普遍好于不使用的结果。在“2W+2+C1”和“2W+2+C123”下,精度最高,F值达到了93.79%,且以“2W+2+C1”为基础的模板性能最为稳定,实验效果普遍较好。因此,我们进一步增加了字符分类的二元同现特征,F值提高到93.92%(见表7前三列)。
(2)“2W+2+C1”效果好也说明,字符二元同现是有效的特征。而宋彦在现代汉语分词实验中,六词位标记集在字符三元同现条件下效果最好[9]。这可能正是先秦汉语的特点造成的。现代汉语以多字词为主,三元同现可以提供充足的构词信息,而在古汉语中单字词居多,三元同现可能是冗余信息。
(3)在字符分类基础上再增加声韵、声韵调、声韵调及部首,实验效果差别不大,特别是增加部首后,甚至出现了下降。究其原因,声韵调这三个特征本身也需要消除歧义。每个字的声韵调,在不同的词性或义项下往往是不同的,还需要仔细分析。而汉字的部首是不需要消歧的,分词精度的下降,说明部首特征对于分类并无贡献。
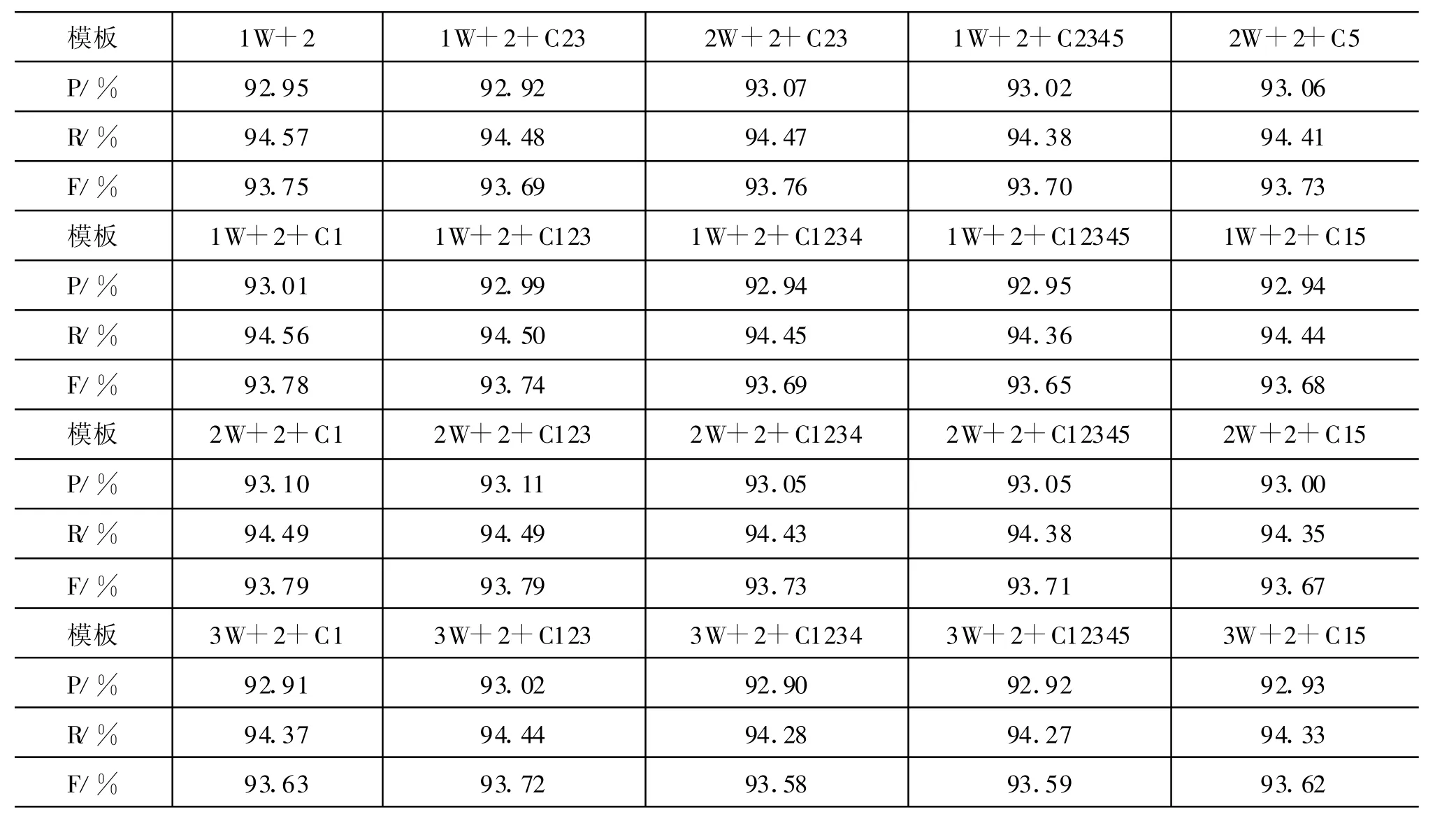
表6 增加语言学特征模板的分词评测结果1
实验三 先秦汉语的声韵系统本身就比较复杂,我们使用的《广韵》是中古音系,有206韵,对于先秦汉语的声韵来说可能不太准确,但调类只有“平、上、去、入”四类,消歧也许相对容易,为此本文在声韵调内部又做了对比实验。在模板选择上,以“2W+2+C1′”为基础模板,然后分别增加声、韵、调特征(见表7)。

表7 增加语言学特征模板的分词评测结果2
通过表7与表6的对比,我们发现字符分类二元同现特征能够提高分词精度,F值最多提高了0.15个百分点。增加声、调特征后也有不同程度提高 ,而加韵后明显降低,“2W+2+C1′24”模板实验效果最佳,F值达到了93.94%。可见声、调对于汉字也是有效的特征,但作用并不显著,还需要进一步探讨。可以得出的初步结论是:基于上下文两个汉字、二字同现、字符分类二元同现的模板“2W+2+C1′”,最适合《左传》的自动分词。
3.3 基于CRF的词性标注实验
词性标注是CRF模型的典型应用,可以将词性标注问题视为词语的词类属性的序列化标注问题,这里不再详述。特征选择上,仅使用词形信息,分别在上下文词语观察窗口为[-1,1]、[-2,2]、[-3,3]的基础上增加词语二元同现。为了验证“两步走”方案在先秦语料上是否存在弊端,在词性标注时,分别对标准分词文本(Right,即人工校对过的标准答案)和实验得到的最佳分词文本(BestSeg,由3.2节复杂特征模板“2W+2+C1′24”得到)进行了评测。

表8 CRF词性标注评测结果
与单纯使用字面信息的分词实验一样,表8中“1W+2”特征模板下的词性标注效果最好。在BestSeg和Right分词文本基础上,F值分别达到了86.82%和91.95%。如果把BestSeg文本的分词精度93.94%和Right文本的词性标注精度91.95%相乘,则可得到BestSeg文本词性标注的预测值86.38%,和实际测得的86.82%是相近的。实际测得的精度略高,是由于标点部分的词性标注都是正确的,不会受到分词错误的影响。
3.4 基于CRF的分词标注一体化实验
我们将“由字构词”的方案应用到词性标注问题上,让汉字承载分词和词性的双重信息,即该字所属词的词性标记(n、v等)以及该字在词中的词位信息(B、M 、E、S)。例如:“范献子/nr” ,“范”为词首 B,“子”为词尾E,“献”为词内字M 。则词性标注格式为“范 B-nr,献 M-nr,子 E-nr”。语料样例见表 5(“分词格式”列除外)。
在3.2节的分词实验中,使用语言学特征时,我们得出模板“2W+2+C1′”最适合《左传》的自动分词,分别增加声、调特征也都有不同程度提高,在模板“2W+2+C1′24”上效果最佳,因此在基于字的一体化标注时,我们设计了“2W+2”、“2W+2+C1”、“2W+2+C1′” 、“2W+2+C1′2” 、“2W+2+C1′4” 、“2W+2+C1′24”六个模板进行对比实验。为了和上文的实验结果对比,对一体化标注分别给出了分词和词性标注的评测结果。
从实验结果来看:
(1)分词精度有较大提升。表9与表7相比,一体化实验效果均优于单独分词,F值最多提高了0.66个百分点,说明一体化方法能将汉字的词位信息和所属词的词性信息结合起来,有效提高分词效果。
(2)词性标注精度明显提升。表9与表8中基于BestSeg文本的词性标注最好结果相比,F值提高了2.83个百分点,说明一体化方法能有效减少“两步走”方法分词错误导致的扩散。
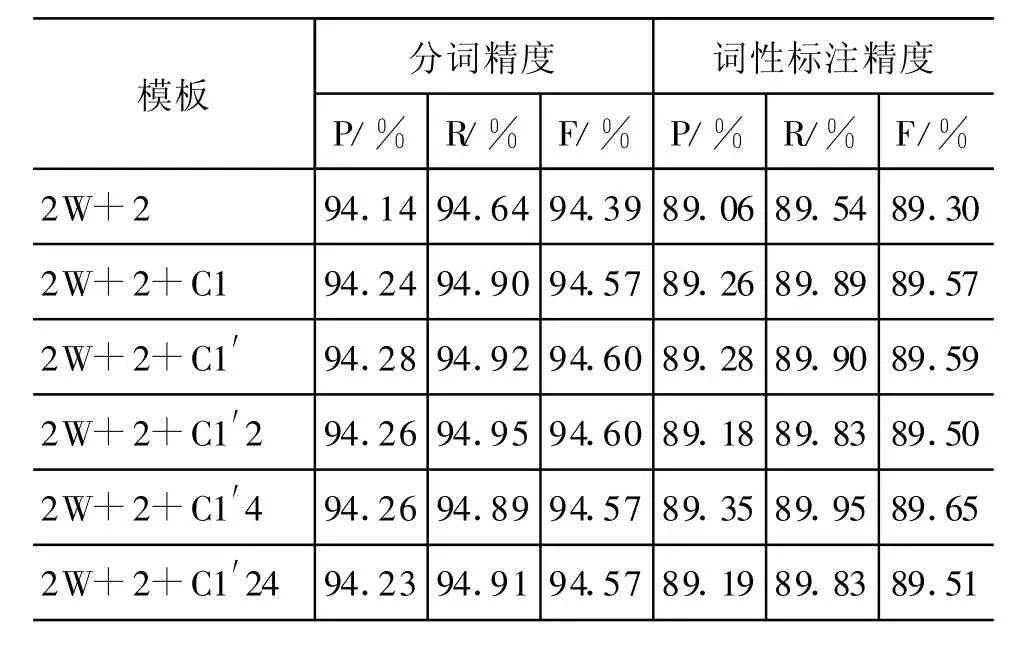
表9 一体化分词标注评测结果
(3)字符分类依然是有效特征,增加声、调特征性能并不稳定。由于测试语料的标准切分单位总数是固定的,从召回率上考虑,分词最佳模板为“2W+2+C1′2” ,词性标注最佳模板为“2W+2+C1′4” ;从综合性能上考虑,“2W+2+C1′”是比较稳定的方式,研究者可以根据侧重点的不同进行取舍。当然,更好的特征模板仍然是我们进一步寻找的目标。
从平均时间消耗(Tave)上来看,一体化方法在时间开销上,确实比较大。本文实验采用的硬件配置为Intel四核处理器,4G内存。3.2节分词实验Tave为326秒;3.3节词性标注实验Tave为6 732秒,约1.87小时;3.4节一体化方法Tave为98 945秒,约27.48小时。虽然分词标注一体化方法性能优于两步方法,但由于分类的类别数量大,时间消耗也大了很多。
总的来说,一体化方法不仅提高了分词精度,词性标注效果也有了明显提升。由于先秦语料库的建设,往往是人工标校出一部分语料作为训练数据,使用一体化方法来标注,可以满足实际需要。而在训练时间的开销方面,问题并不是很大,因为20多种先秦文本的规模总共只有200多万字,训练语料的数量更是有限的。
3.5 分词和标注错误分析
本节对一体化最佳标注结果的分词和词性标注错误类型做了分类统计(见表10)。在分词错误中,未登录词和分词标准问题导致的错误占到77.97%。测试语料中未出现于训练语料的未登录词(OOV)共1817个,OOV率为8.75%,切分个数为1 693个,正确个数为1214个,准确率为71.70%,召回率为66.81%,F值为69.17%。在错误的603个未登录词中,多字词占97.18%。同时,多字词的错误率占全部错误总数的70.87%。可见,多字词是古汉语信息处理的难点。分词标准问题是指,机器自动切分的结果,分与合在意义上是两可的,只是与人工标注不同。切分歧义中,交集型歧义很少,组合型歧义居多。我们采用全切分算法统计了测试语料中的交集型歧义字段,总计只有84个段型和128个段例,其中错误的仅为9例。组合型歧义错误,则多是将二字词误切为两个单字,这主要是这些字在训练语料中多为单字词。人工标注错误而机器标注正确的词也有部分存在,这也可以看到自动标注具有一定的自动纠错能力。

表10 分词标注错误统计
在词性标注错误中,n、ns、nr三个词类之间混淆错标的占全部标注错误的37.04%,这源于《左传》中的姓氏多取自爵位、职官、封邑等,造成识别困难。由n、v混淆错标以及错标为n或 v的共占43.89%,其中“v → n” 占 13.43%,“n → v”占9.48%。这是由于古汉语词的兼类和活用现象比较频繁,造成词类消歧困难。
4 结论及未来工作
本文在古代汉语自然语言处理领域进行了新的探索。在《左传》传文上的一系列实验表明,基于CRF的分词标注一体化方法可以用于古代汉语语料库建设。与两步方法相比,分词、词性标注性能均有明显提高,开放测试的F值分别达到了94.60%和89.65%。该方法可以应用于先秦其他语料的自动标注工作,有效降低人工标注的工作量,加快语料库的建设。从《左传》得到的训练模型,可以用于先秦语料中内容相近的语料的自动标注,如《公羊传》、《谷梁传》和《吕氏春秋》等,给我们的项目进展带来了巨大的效益。
我们下一步的工作主要是:(1)考虑先秦语料中诗词、语录体、典章制度等与《左传》差异较大的文本的自动标注。采取“人工标注训练语料→机器学习自动标注→人工校对”的方式,完成先秦25种传世文献的切分标注和后期校对,建立起先秦文献切分标注语料库。(2)继续探索改善CRF标注性能的特征模板和方法,如采用多分类器集成技术和迁移学习技术。(3)进一步细化词类体系。本文分词标注遵循的是《先秦汉语分词标注规范基本集》,仅仅给出了21个词类标记,对各词类的内部子类没有细分,今后要尝试对词类进一步扩展,制定出《扩展集》,将先秦汉语的语料库加工技术研究深入下去,在此基础上进行词汇统计和知识检索的工作。
致谢 感谢硕士生于丽丽、汪青青、肖磊同学在语料标注校对方面所做的大量工作。
[1] 尉迟治平.计算机技术和汉语史研究[J].古汉语研究,2000,3:56-60.
[2] 魏培泉,黄居仁,等.建构一个以共时与历时语言研究为导向的历史语料库[J].中文计算语言学期刊,1997,2(1):131-145.
[3] 邱冰.基于中文信息处理的古代汉语分词研究[J].微计算机信息,2008,1:100-102.
[4] 白拴虎.汉语词切分及词性标注一体化方法[C]//计算语言学进展与应用.北京:清华大学出版社,1995:56-61.
[5] Hwee Tou Ng and Jin K iat Low.Chinese Part-of-Speech Tagging:One-at-a-Time or A ll-at-Once?Word-Based or Character-Based?[C]//Proceedings of ACL-04:277-284.
[6] Yue Zhang and Stephen Clark.Joint Word Segmentation and POS Tagging using a Sing le Percep tron[C]//Proceedings of ACL-08:888-896.
[7] 杨伯峻.春秋左传注(修订版)[M].北京:中华书局,1990.
[8] 陈克炯.春秋左传详解词典[M].河南:中州古籍出版社,2004.
[9] 宋彦,等.一种基于字词联合解码的中文分词方法[J].软件学报,2009,9:2366-2375.
猜你喜欢
汉字汉语研究(2021年2期)2021-08-30
汉字汉语研究(2021年1期)2021-06-11
校园英语·月末(2021年13期)2021-03-15
汉字汉语研究(2020年3期)2020-12-14
新世纪智能(英语备考)(2019年10期)2019-12-16
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
新世纪智能(语文备考)(2019年3期)2019-01-12
中国修辞(2016年0期)2016-03-20
中学语文(2015年18期)2015-03-01
