
OHR:一种基于本体的个性化混合服务推荐模型
2010-07-18 03:11:46潘拓宇朱珍民滕吉叶剑曾庆峰
中文信息学报 2010年2期
潘拓宇,朱珍民,滕吉,叶剑,曾庆峰
(1中国科学院计算技术研究所,北京100190;2湘潭大学信息工程学院,湖南湘潭411105)
1 引言
网络的快速发展带来了信息量的指数级增长,如何从这些海量的信息中抽取出用户感兴趣的内容变得意义重大,这就是当前众多大型网站,数字图书馆等广泛研究的个性化服务推荐技术。个性化服务推荐技术主要分为基于内容过滤,基于协同过滤,以及混合过滤三种类型。目前应用较为成功的是基于协同过滤的个性化信息推荐技术[1-2]。
本文对服务本身进行描述,并对其内容进行过滤抽象出服务主题和特定主体。以此对整个服务项目集合进行服务子类的划分,通过建立用户兴趣概率模型,来计算出要推荐的服务子类集合,然后再对每个推荐服务子类中特定的项目和用户进行项目协同过滤,从而得到某个用户的推荐项目集合结果。
本文第二节介绍个性化推荐系统的相关工作和已有进展。第三节描述该本体模型下的推荐过程,包括用户子类的兴趣概率计算和在服务子类中具体项目推荐计算。第四节为模型实现和实验结果分析。最后一节对全文总结和将来工作进行展望。
2 研究现状
基于协同过滤技术由于推荐精度较高且与服务资源的无关性,使得它成为近些年来个性化服务技术的主流,比较典型的方法包括:文献[3]提出使用基于项目的协同过滤代替基于用户的协同过滤,它首先计算项目之间的相关性,然后通过用户对相关项目的评分预测用户对未评分项目的评分。实验证明了前者在计算性能和推荐的品质上明显高于后者,在后续的工作中作者又进一步扩展该方法[4]。文献[5]提出一种结合项目访问概率和协同过滤的方法,解决了普通协同过滤中的新用户加入无法有效推荐问题。文献[6]提出一种利用联合式检索框架(associative retrieval framework)和相关传播激活算法(related sp reading activation)从他们过去一些行为和反馈中提取传递联合体(transitive associations),有效解决了用户评分矩阵稀疏性问题。单纯的基于某种协同过滤的技术在实践过程中容易遇到两个很难解决的问题,一个是稀疏性,也就是指在系统使用初期,由于系统资源还未获得足够多的评价,该方法很难利用这些评价来发现相似的用户。另一个是可扩展性,也就是指随着系统用户和资源的增多,该方法的性能会越来越低。对于这些问题,虽然最近人们通过聚类,矩阵划分,粗糙集,模糊集,贝叶斯网络,修正相似度公式[7-11]等方法改进但始终未从根本上解决上述问题。
另一方面在特定领域资源模型表达较好的情况下,人们更加倾向使用简单快速的内容过滤技术。但它往往使用向量模型精确表达用户兴趣,使得用户和资源项目的相似度计算精度大大降低,虽然可以通过概率模型和模糊集加强相似计算的精度,但与协同过滤模型相比在没有很好的预处理下,内容过滤推荐精度要远远低于协同过滤技术。Bayesian网络技术利用训练集创建相应的模型,模型用决策树表示,节点和边表示用户或者项目信息。训练得到的模型非常小,所以对模型的应用非常快。这种方法适合于用户的兴趣爱好变化比较慢的场合。内容过滤方法最大的缺点就是每个用户或者项目都只能被分到一个类中。当类的粒度较大时,在同一个类下项目或用户不能具体区分,而当类较小的时候,可能会出现有多个子类符合同个项目或用户的分配。
混合过滤是为了消除各种技术的缺点,利用它们各自优点来达到一个较好的推荐效果。文献[12]提出了基于内容的协作过滤方法,也就是利用用户浏览过的资源内容来预期用户对其他资源的评价,这样可以增加资源评价的密度,并利用这些评价再进行协作过滤,从而提高协作过滤的性能。文献[13]通过不同用户对同一项目,同一用户对不同项目以及其他用户对相似项目三方面的预测融合,结合项目协同过滤和用户分类衰退,并利用这些评价再进行协作过滤,从而提高协作过滤的性能。文献[14]提出了一种混合项目和用户两方面的评分预测算法,改善协同过滤方法的数据稀疏性。文献[15]提出了先进行协作过滤,然后对中间结果再做内容过滤的评分预测,有效改善内容过滤中不能发现新的其他用户未访问过的可能感兴趣的内容。
基于内容过滤的技术优点是简单、有效,缺点是矢量模型计算精度较低,难以区分资源内容的品质和风格,而且不能为用户发现新的感兴趣的资源,只能发现与用户已有兴趣相似的资源。基于协作过滤的技术其优点是能为用户发现新的感兴趣的资源,并且能够为一些非结构化对象进行推荐比如电影,歌曲等,但是有两个很难解决的缺点,一个是稀疏性,即在系统使用初期,由于系统资源还未获得足够多的评价,系统很难利用这些评价来发现相似用户。另一个是系统的可扩展性,即随着系统资源和用户数量增加,系统的性能会越来越低。
为了克服普通内容过滤方法中矢量模型计算精度较低,改善协同过滤中用户评分数据的极端稀疏性,本文提出了一个基于内容过滤和项目协同过滤的混合个性化服务推荐子模型。该模型对服务本身进行描述,并对整个服务项目集合进行以概率模型为基础的服务子类层次结构划分。通过先前的用户训练和使用时的数据统计,来计算出要推荐的服务子类集合,然后再对每个推荐服务子类中特定的项目和用户进行项目协同过滤,从而得到某个用户的推荐项目集合结果。仿真实验结果表明,该子模型具有较高服务推荐的准确率和召回率。
3 服务推荐模型框架
本服务推荐模型框架分为三个部分,按服务提供流程分为:服务内容预处理部分,内容过滤部分和协同过滤部分。我们通过服务子类本体,对整个项目集合进行服务子类的划分,为后续统计每个用户兴趣分布提供模板。当用户注册登入后,根据一个时间窗内(如两个星期)的历史访问信息的统计,计算出新的兴趣分布,然后以此为基础对新的可能感兴趣子类进行特定范围内的基于项目的协同过滤计算得到具体推荐服务项目返回给用户,从而完成推荐过程,如图1。

图1 服务推荐模型框架
3.1 服务子类选择描述
通过服务内容预处理,我们得到以服务子类属性为节点的服务层次结构图,如图2。其中Si,F j,Ck,Al分别对应着服务类型,服务领域,服务主题,特定主体。路径SiFjCkAl则对应着一特定服务子类。
假定每段路径表示为某服务子类属性层次结构下起点到终点的兴趣概率,那么每个服务子类的兴趣概率为:
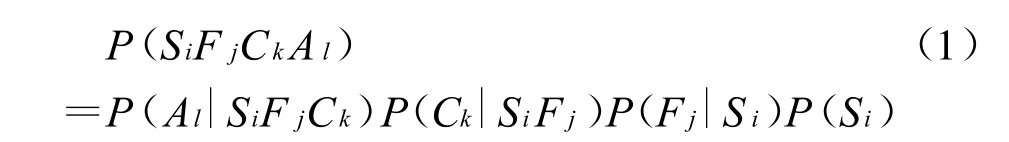
设不同服务子类属性粒度的集合为X,Y

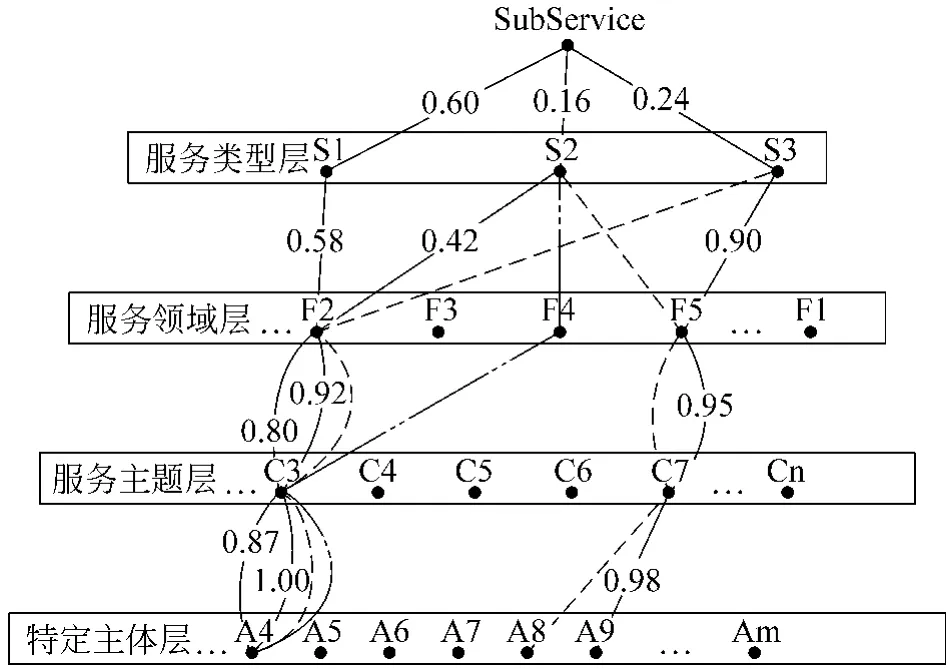
图2 服务子类属性本体层次结构
在具体应用中,我们使用专家经验值或用户使用项目的频率Freq(一般是后者)来代替(1)式中每段部分路径兴趣概率P:
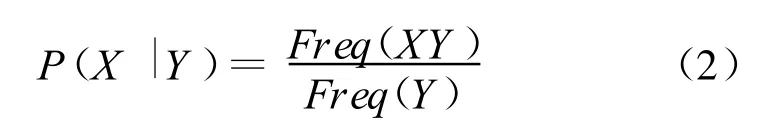
在没有专家经验值和用户使用项目的频率(或者是使用次数λ达不到某一启动阀值α,即用户是偶尔使用该服务子类中的项目,不考虑为用户的真正兴趣)的情况下,我们用剩余兴趣量(即该服务子类属性粒度层下,总频率减去其他已有使用项目的频率)乘上一个估计因子 μ(在本模型中用该服务粒度下已有兴趣量的最大值,即猜想在剩余兴趣量中,没有比已有兴趣比值更大的剩余兴趣分量,显然比传统的1/n更接近真实兴趣,因为针对同一个领域或主题,用户的兴趣量很少是均匀的),即:

例1:假设图2中实线路径为系统对某个(或某类)用户的项目服务使用频率进行学习和统计后,得到的k(这里设定k=3)个先前最感兴趣(即使用频率最高)的服务子类S1 F2 C3 A4,S2 F2 C3 A4,S3F5C6A7。根据公式(1),(2)我们可得:p1=0.242 2,p2=0.061 8,p3=0.201 1。那么除了这k个可直接推荐的服务子类外,与此类似我们还应该计算出其他相关子类。如图2中虚线路径为三种典型代表。利用公式(1),(2),(3)可得路径S2 F 4 C3 A4,S2F5C7A8,S3F2C3A4的p4=0.035 9,p5=0.036 3,p6=0.019 9。最后根据兴趣概率 P值大小对所有结果选取前m个推荐服务子类。
3.2 具体项目推荐描述
在选择m个服务子类后,根据每个子类的兴趣概率在m子类中的比重依次确定各子类的具体推荐项目数量。

图3 某子类中的项目—用户评分矩阵及其项目之间相似关系

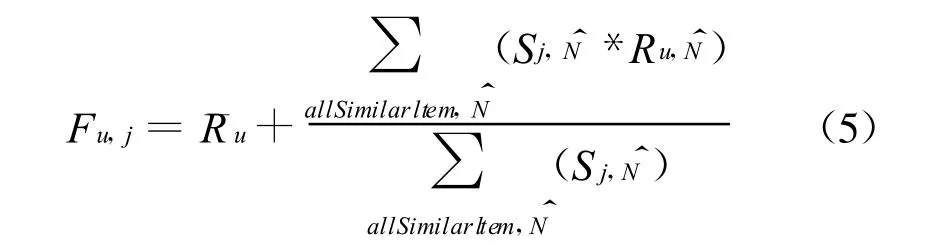
求出未访问过的其他项目的估计评分,Fu,j是第u个用户对第j个项目的预测评分。最后根据下式

即在有预测评分情况下,选择评分最高的前t个项目;在没有预测评分但有其他用户评分的情况下,选择最热点(访问次数最多)的前t个项目;否则随机选取时间最新t个项目,推荐给用户。
4 方法验证与实验分析
实验分为两个部分,实验一与实验二为第一部分,实验三为第二部分。在第一部分中实现并验证以本文提出的理论模型为基础的个性化混合Web服务推荐平台。在第二部分中是用衡量推荐方法质量中比较常用的M ovieLens数据集验证OHR方法的推荐质量,并与传统协同过滤方法进行对比分析。
在第一部分中,没有采用用户手动评分(因大多数用户不会或不愿主动参与评分),而是采取了用户访问过某项目,则认为他对该项目的评分是1否则为0.2的策略,评分高低的设定(有一定梯度)不影响推荐方法本身。在第二部分中,我们利用标准数据集,用训练集来推荐用户未访问过的项目,用测试集来验证此方法的可靠性以及发现新兴趣的能力。
采用信息检索领域广泛使用的准确率(p recision)和召回率(recall)来评价实验结果。本实验准确率和召回率的定义如下:

据实验统计,实验数据集共有4种服务类型覆盖13个服务领域,63个主题和537个特定本体,共4 098个具体项目。它们分别来自各大门户网站的新闻信息,中国农业信息网的政策与科技信息,商务平台中用户自己发布的交易信息等。
【实验1】 随机选取6组用户,每次随机抽取40个用户分别使用传统基于项目协同过滤(IBCF),传统基于用户协同过滤(UBCF)和本文提出的基于本体的混合推荐方法(简称OHR)推荐10个页面并计算出其相应推荐的平均准确率(实验结果见图4)。
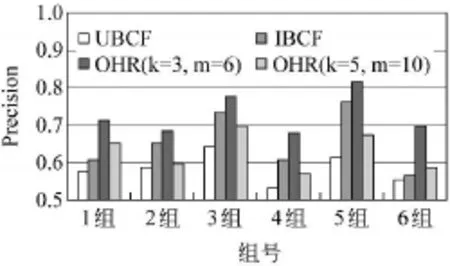
图4 OHR方法与传统协同过滤方法的准确率比较
如图4所示,OHR方法在推荐服务子类范围较小(k=3,m=6)的情况下,平均推荐精度比传统基于项目过滤方法要提高了5%~8%。在推荐服务子类范围扩大,推荐项目数量较少的情况下,推荐精度会略有下降(实验结果见图5)。

图5 OHR方法与传统协同过滤方法的召回率比较
【实验2】 随机选取上述全体用户的某次会话。据统计,大多数用户访问服务子类的数量在8~25个之间,用户的平均访问项目为63个,在此基础上我们分别计算出4种方法在推荐项目数为10,20,30,40,50的召回率。
如图5所示,本文提出的方法在推荐服务子类范围较大(k=5,m=10)的情况下,随着推荐项目的增多其召回率的大小和上升速度明显高于传统协同过滤方法。
通过实验我们得知随着k和m值增加,推荐服务子类范围随之增大,推荐服务的召回率(recall)越高,但推荐服务的准确率(precision)会有所越低。反之,虽然推荐服务的准确率会很高,但是由于过滤掉了很多非主要兴趣的服务子类,使得推荐服务的召回率(recall)会有所降低。
【实验3】 我们使用目前在衡量推荐方法质量中比较常用的 M ovieLens数据集(http://movielens.umn.edu)对本文提出的方法与传统协同过滤方法再次进行比较验证。这个数据集由美国M innesota大学的GroupLens研究小组创建并维护,它包括943个用户对1 682部电影的100 000个评分(评分值 1~5,5表示“perfect”,而“1”表示“bad”)记录,每个用户至少评价了20部电影,并已经以80%训练集,20%测试集的划分比例生成了7组实验集,其中ua,ub组中的测试集中每个用户评分数量被标准化为10个。
在TopN的推荐结果评价中,既要考虑命中数量问题(命中数量越多越好)又要考虑推荐精度问题(推荐精度的评估标准一般采用平均绝对偏差MAE(m ean absolute error),通过计算预测用户的评分与用户的实际评分之间的偏差来度量预测的准确性,MAE越小意味着推荐的精度越高),为了权衡两者,本文建议提出一种新的评价TopN推荐结果的综合标准:每命中项目 M AE影响值M PH(MAE per hit)。即每推荐一个命中项目所带来的平均绝对偏差代价。同MAE相似,MPH值越小,意味着每推荐一个命中项目所带来的平均绝对偏差代价越小,TopN的推荐质量越高。
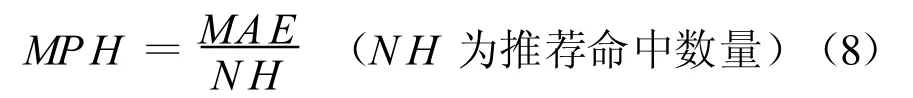
对M ovieLens该数据集中的7个数据组,分别计算出 OHR4(k=m=4),OHR6(k=m=6),OHR8(k=m=8),IBCF Top10,Top15,Top20的NH,MAE,MPH值(如表1所示)。
从上表数据分析,可得到在推荐Top10的所有实验中,虽然OHR4,OH R6,OH R8比同条件下IBCF方法的平均MAE值分别要高3%,6%,8%,但平均推荐项目命中数量(NH)却分别提高了13%,23%,22%(如图6所示,Uavg为各组实验MPH的平均值)尤其是在标准Top10实验(即测试集中每个用户评分数量被标准化为 10个)ua,ub组中OHR方法的优势更加明显。在Top15,Top20的实验中,OH R对IBCF方法的综合推荐质量优势逐渐减小。这是因为随着推荐项目数量的增多,次要兴趣的项目也逐渐增多的缘故,导致了综合推荐质量相对优势有所下降。在实际应用中,由于应用系统本身信息表现空间有限,用户的最感兴趣信息集中,推荐数量一般不超过十个,综合考虑OH R方法推荐质量明显好于传统方法。

表1 OHR方法与基于项目协同过滤方法在推荐TOP-10,15,20的NH,MAE,MPH
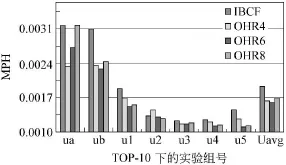
图6 OHR方法与基于项目协同过滤方法在TOP-10的MPH比较
5 小结
个性化服务推荐目前被广泛地应用于电子商务,Web检索,数字图书馆等各个领域,而现有的推荐方法存在着许多不足。本文提出的基于本体的个性化混合服务推荐模型(OHR),能够简洁高效地表达服务的核心内容,方便自然的描述用户兴趣的分布变化,以及较准确和广泛的向用户提供服务。实验结果表明本模型在服务推荐上具有较高的准确率和发现用户新兴趣的能力,但如何通过收集更多的上下文信息更加精确地描述用户兴趣仍是一个困难的问题,而怎样实现不同服务主元的跨类型领域的服务推荐则是我们进一步要研究的重点。
[1] 许海玲,吴潇,李晓东,阎保平.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[2] Gediminas Adomavicius,A lexander Tuzhilin,Tow ard the NextGeneration of Recommender Systems:A Survey of the State-of-the-A rt and Possib le Extensions[C]//IEEE T ransactions on Know ledge and Data Engineering,2005,17(6):734-749.
[3] B.Sarwar,G.Karypis,J.Konstan,and J.Ried l,I-tem-Based Collaborative Filtering Recommendation A lgorithms[C]//Proc.10th Int'lWWW Conf.,2001.
[4] M ukund Ddeshpande,George Karypis,Item-Based Top-N Recommendation A lgorithms[J].ACM Transactions on Information Systems,2004,22(1):143-177.
[5] K.Yu,A.Schwaighofer,V.Tresp,X.Xu,and H.-P.K riegel,Probabilistic Memory-Based Collaborative Filtering[J].IEEE Trans.Know ledgeand Data Eng.,2004,16(1):56-69.
[6] Z.H uang,H.Chen,and D.Zeng,App lying Associative Retrieval Techniques to A lleviate the Sparsity Prob lem in Collaborative Filtering[J].ACM T rans.Information System s,2004,22(1):116-142.
[7] 王明文,陶红亮,熊小勇.双向聚类迭代的协同过滤推荐算法[J].中文信息学报,2008,22(4):61-65.
[8] 宗胜,姜丽红.推荐系统中遗漏值解决方法的研究[J].计算机应用与软件,2008,(6)
[9] 戴亚娥,龚松杰.个性化服务中基于模糊聚类的协同过滤推荐[J].计算机工程与科学,2009,(4)
[10] 罗喜军,王韬丞,杜小勇,刘红岩,何军.基于类别的推荐-种解决协同推荐中冷启动问题的方法.计算机研究与发展,2007,z3.
[11] 欧洁.基于贝叶斯网络模型的用户兴趣联合推送[J].计算机科学2003,30(12):73-77.
[12] Balabanovic,M.,Shoham,Y.Fab:content-based,co llaborative recommendation[J].Communications of the ACM,1997,40(3):66-72.
[13] Jun Wang,A rjen P.de V ries,Marcel J.T.Reinders,Unifying User-based and Item-based Co llaborative Filtering App roaches by Sim ilarity Fusion[C]//Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval Pages:501-508.
[14] Rong Hu,Yansheng Lu,A Hybrid User and Item-Based Co llaborative Filtering w ith Smoothing on Sparse Data[C]//16th International Conference on A rtificial Reality and Telexistence——Workshops(ICAT'06),2006:184-189.
[15] James Sa lter,N ick Antonopou los,CinemaSc reen Recommender Agent:Combining Collaborative and Content-Based Filtering[C]//IEEE Intelligent Systems,2006,21(1):35-41.
猜你喜欢
数学年刊A辑(中文版)(2021年4期)2021-02-12 01:21:02
科学大众(2020年23期)2021-01-18 03:09:08
汽车观察(2019年2期)2019-03-15 06:00:50
数学物理学报(2018年1期)2018-03-26 08:16:37
商用汽车(2016年11期)2016-12-19 01:20:16
中国卫生(2016年5期)2016-11-12 13:25:26
商用汽车(2016年6期)2016-06-29 09:18:54
商用汽车(2016年4期)2016-05-09 01:23:12
创业家(2015年5期)2015-02-27 07:53:25
生物进化(2014年2期)2014-04-16 04:36:26
