
高性能中文垃圾邮件过滤器
2010-07-18 03:11齐浩亮程晓龙杨沐昀何晓宁李生雷国华
中文信息学报 2010年2期
齐浩亮,程晓龙,杨沐昀,何晓宁,李生,雷国华
(1.黑龙江工程学院计算机科学与技术系,黑龙江哈尔滨150050;2.哈尔滨工业大学计算机科学与技术学院,黑龙江哈尔滨150001;3.哈尔滨理工大学计算机科学与技术学院,黑龙江哈尔滨150080)
1 前言
随着电子邮件的广泛应用,伴随而来的垃圾邮件问题日益严重。它不仅消耗网络资源、占用网络带宽、浪费用户的宝贵时间和上网费用,而且严重威胁网络安全,已成为网络公害,带来了严重的经济损失。中国互联网协会反垃圾邮件中心发布的2007年第四季度反垃圾邮件调查报告显示,垃圾邮件在规模上不断增长,2007年第四季度中国网民平均每周收到的垃圾邮件比例为55.65%。迫切需要有效的技术解决垃圾邮件泛滥的问题。
邮件过滤任务本质上可以看作是一个在线二值分类问题[1-2],即将邮件区分为Spam(垃圾邮件)或Ham(正常邮件)。近几年,基于机器学习的文本分类法在垃圾邮件过滤中发挥了巨大的作用,典型的方法包括贝叶斯方法、支持向量机(SVM,Support Vector M achine)方法、最大熵方法、PPM(Prediction by Partial Match)压缩算法等。由于这些方法过滤正确率高、成本低,因此机器学习方法称为当前的主流方法。应用机器学习方法对垃圾邮件进行过滤时涉及到3个问题:模型选择、特征抽取(邮件表示)以及训练方法。
从模型上看,机器学习技术可以粗略分为生成模型(如贝叶斯模型)和判别模型(如SVM、最大熵模型)。在相关领域——文本分类中,判别模型的分类效果比生成模型的分类效果要好,特别在没有足够多的训练数据的时候,这种现象更明显[1]。在生成模型方面,著名的Bogo系统就是基于贝叶斯模型的,在 TREC评测中作为基准(Baseline)系统。用于数据压缩的CTW(Context Tree Weight)和PPM(Prediction by PartialMatch)等压缩算法被引入到了垃圾邮件过滤[2]。CTW 和PPM是数据压缩中使用的动态压缩算法,其原理是根据已经出现的数据流预测后面要出现的数据流,预测的越准,所需的编码也就越少,并据此进行分类。2004年,Hulten和Goodman在PU-1垃圾邮件集上做实验,证明了在邮件过滤上,判别模型的分类效果比生成模型的分类效果要好[3]。不严格的在线支持向量机(Relaxed On line SVM)克服了支持向量机计算量大的问题被用于解决垃圾邮件过滤的问题[4],并在TREC 2007评测中取得了很好效果。Goodm an和Y ih提出使用在线逻辑回归模型,避免了SVM、最大熵模型的大量计算,并取了与上一年度(2005年)最好结果可比的结果[5]。
在特征抽取(即邮件表示)上,邮件的文本内容是当前过滤器处理的重点。大多数过滤器以词作为过滤单元。由于垃圾邮件对文本的内容进行了变形,使得上述方法存在缺陷。非精确的字符串匹配被用于解决这个问题[6],但该方法只对英文垃圾邮件过滤有效,无法直接用于中文垃圾邮件过滤。在信息检索领域的字符级n元文法被引入垃圾邮件过滤,并在TREC评测中取得优于词袋(Bag o f w ord)假设的结果[4]。字符语言模型也被应用于垃圾邮件过滤,取得了比较好的效果[7]。鉴于大量垃圾邮件将文本内容转换为图像,基于图像分析(Image Analysis)的过滤技术近年来得到重视[8]。
在训练方法上,最简单也是最常用的训练方法就是对每一封邮件都进行训练。这种方法在实际应用中已经获得了很好的效果,但是有两个问题。第一个问题是内容相近的邮件可能被多次训练,增加资源的耗费。第二个问题是会出现过度训练的问题,当某些特征在特征库中已经有足够多的计数时,再过多的进行训练会导致准确率的下降。改用TOE(Train On Error)方法后,仅当邮件被误判时才进行训练,这种方法只能用于判别学习模型。这样可防止过度训练、减小空间占用并提高速度。尽管过度训练会极大的影响过滤器的准确率,但TOE训练法在另一个方向走过了头,仅对误判的邮件进行训练导致过滤器训练数据不足,其对准确率仍有影响。TONE(Train On or Near Error)在 TOE基础上加以改进,预设一个分数界限,当邮件得分与判断阀值之差的绝对值在界限之内时,即使正确判断也进行训练[4]。
本文采用逻辑回归模型、字节级n元文法和TONE训练方法进行中文垃圾邮件过滤。本文描述的系统参加了中国计算机学会主办的SEWM(Search Engine and Web Mining)2008垃圾邮件过滤评测,获立即反馈、主动学习、延迟反馈全部在线评测项目的第一,性能优于第二名100倍左右;在SEWM 2007上 1-ROCA达到了0.000 0%;在TREC06c上也显著优于当年评测的最好结果。
本文的随后部分安排如下。第二节介绍了垃圾邮件的在线过滤模式,第三节介绍了垃圾邮件过滤器的设计,包括过滤模型、特征提取和训练方法,第四节是实验结果,最后给出了本文的结论。
2 垃圾邮件的在线过滤模式
过滤器(分类器)的学习方式可以分为在线学习(Online Learning)和批量学习/离线学习(Batch Learning/Offline Learning)。在离线学习方式下,通过训练样本调整分类器的参数。在实际应用时,不再调整分类器的参数。在在线学习方式下,分类器根据用户的反馈不断调整系统参数,使系统能够适应不断变化的应用环境。在线学习适用于需要快速更新的环境。受制于在线更新学习器,其参数更新算法的复杂度要低,以适应实际应用的需求。为了避免垃圾邮件被过滤器过滤,垃圾邮件发送者不断改进垃圾邮件发送技术。这就要求垃圾邮件过滤器具有良好的适应能力,因而在线学习方式适用于垃圾邮件过滤[9-10]。SEWM 08中文垃圾邮件过滤评测也表明,在线学习方式的性能优于批量学习方式(http ://www 2.scut.edu.cn/antispam/ppt.htm l)。在线学习方式能够满足过滤不断变化的垃圾邮件的要求,这也是TREC(Text REtrieval Conference)公开评测采用在线学习方式的原因。
本文采用在线学习方式,这也是国内外垃圾邮件过滤评测采用的方式。所用的邮件在线过滤模式如图1所示,以过滤器和训练器为中心分为过滤和训练(即学习)两部分。过滤器根据在线更新的特征库,过滤按实际顺序输入的邮件流,判断每个邮件的属性。训练器根据用户的反馈对邮件的过滤结果进行学习,并进一步调整特征权重库中相应特征及其权重,提高过滤器的适应能力与性能。

图1 垃圾邮件过滤在线模式
3 基于逻辑回归模型的垃圾邮件过滤器
模型是影响垃圾邮件过滤效果的核心因素,恰当选择过滤模型是系统成功的关键。逻辑回归(Logistic Regression,LR)模型,和SVM 一样,是一种判别学习模型,具有良好的性能;逻辑回归模型的时间复杂度和空间复杂度都低于SVM,更重要的是,逻辑回归模型可以很容易地以在线学习方式调整模型的参数,使模型能够适应不断演进的垃圾邮件,因此,逻辑回归模型成为当前垃圾邮件过滤中的主流模型之一[11]。特征选择是与过滤模型关系紧密,是影响分类性能的关键因素。本文提出了字节级n元文法的邮件特征提取方法,将邮件视为二进制流,简化了特征提取,保证了过滤器的性能。在训练时,采用TONE方法,该方法可以与逻辑回归模型等判别学习模型配合使用,降低训练量,并提升系统性能。
3.1 逻辑回归模型
逻辑回归(Logistic Regression,LR)模型,和SVM一样,是一种判别学习模型。判别学习模型与以贝叶斯为代表的生成模型有本质差异。传统生成模型认为数据都是某种分布生成的,并试图根据这种分布建模。采用最大似然估计(Maxim um Likelihood Estimation,简称M LE)来求解模型参数,并用平滑算法来解决数据稀疏问题。这种方法仅当以下两个条件都满足时才是最优的:第一,数据的概率分布形式是已知的;第二,存在足够大的训练数据时才能采用最大似然估计来求解模型参数。但在实际应用中,这两个条件很多时候无法满足。判别学习模型是与生成模型相对应的一类建模方法。其假设条件比M LE弱得多,只要求训练数据和测试数据来自同一个分布即可。而且,判别学习算法的目标往往与实际应用的评价标准密切相关(如使模型在训练数据上的错误率最小化)。因此判别学习模型的性能往往要优于生成模型。从计算复杂度上看,逻辑回归模型的计算复杂要明显低于SVM,其分类速度要也比SVM快得多。
在基于内容的邮件过滤系统中,影响一封邮件是垃圾邮件还是非垃圾邮件的因素是该邮件中的特征。应用逻辑回归模型,可以根据邮件的特征判断该邮件是垃圾邮件的概率:
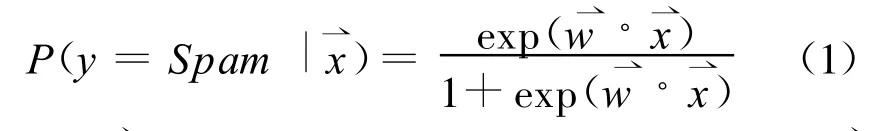
其中:x⇀是该封邮件的所有特征组成的向量,是该封邮件的所有特征相对应的特征权重向量。
定义一个分界值,通常设为0.5。比较P(y)和分界值,若P(y)大于等于分界值,就判断为垃圾邮件;否则就判断为正常邮件。
3.2 基于字节级n元文法的特征提取
邮件过滤的依据是邮件的特征,特征项的定义,是影响分类性能的关键因素。和文本分类问题相比,邮件过滤有其特殊之处。反垃圾邮件技术在进步,发送垃圾邮件的技术也在不断地提高。由于巨大的利益驱动,狡猾的垃圾邮件发送者对其电子邮件信息进行多方面的伪装,通过各种手段将垃圾邮件伪装为正常邮件。同时,大量垃圾邮件以图像的形式出现,导致传统方法失效;单纯的依赖邮件的文本内容对含有病毒的垃圾邮件无能为力。
针对垃圾邮件特征提取面临的问题,提出了基于字节级n元文法的特征提取方法。字节级n元文法在处理邮件文本内容时,提取了邮件的文本内容,在处理邮件的附件、所包含的图片等组成成分时,提取了它们的二进制特征,因此能够在一个简单的框架下处理以往很难处理问题。采用字节级n元文法提取邮件特征,避免了繁杂的邮件解析、汉字编码转换等工作,并使系统具有处理图像、病毒邮件的能力。
字节级n元文法,将邮件按字节流进行大小为n的滑动窗口操作,形成长度为n的字节片断序列,每个字节片断称为gram。n元文法 按字节流进行采用长度为n的窗口切分,如:abcd,按照n=2时进行滑动窗口切分为:ab、bc、cd这样 3个2-gram。采用n元文法信息作为邮件特征具有以下特点:无需任何词典支持,无需进行分词处理;无需语言学先验知识;无需对邮件进行预处理,将邮件当作无差别的字节流对待;不用考虑文字编码的问题;同时具有处理复杂文件的能力,如 HTM L格式邮件、图像文件、压缩文件。与以词字、词组等为特征元素相比,这样定义特征元素能有效防止了垃圾邮件信息的可能被绕过的情况。如product进行文字变形,变换为p!roduct,pro_duct,prod-uct等等,基于词字、词组的过滤器就可能识别不出该特征,而基于字节的n元文法仍可以有效识别出该特征。例如,当n=4时,product进行特征抽取如下:prod、rodu、oduc、duct;当p roduct文字变形后变为p rod-uct时进行特征抽取如下:prod 、rod-、od-u 、d-uct、-uct;两者共有的特征是prod。当出现特征prod时,则该完整的单词为product的概率比只捕捉到特征prod时的概率要大得多。同时,变形后的字符串往往较多地出现在垃圾邮件中,表明了邮件的性质。
中文使用至少2个字节表示一个字(如GB 2312使用两个字节表示1个汉字,GB 18030使用两个字节或四个字节表示1个汉字),不使用空格作为词的分隔符,因此,如果对汉字进行文字变换程度太大的话,是很难让人读懂的,如“办证”,常见的变形文字是“办.证”、“办证”等,由于无法进行正确的分词,这种文字变形使得典型的以词为过滤单元的方法失效。由于字节级n元文法提取连续的n个字节作为特征,字符变形后n元文法依然能够提取有效特征。由于“办.证”、“办证”等大量出现在垃圾邮件中,正常邮件中较少出现。在n元文法下,变形后的文字反而表明了它是垃圾邮件,表明了该邮件的性质。
以词作为过滤单元,词作为最小的能自由运用的语言单位,将有助于过滤性能的提高,需要进行编码识别和分词,但分词的准确度难以保证,尤其是未登录词的识别性能难以得到保证,同时难以处理文字变形;若以字作为过滤单元,不需要进行分词,实现起来比较容易,但字的语义表达能力较弱,上下文信息太少。
在实验中使用了字节级4-gram,并且每一封邮件仅取前3 000个4-gram。邮件的特征值为布尔值,即邮件包含某个4-gram,其值为1,否则为 0。
3.3 TONE训练方法
TONE(Train On or Near Error)方法也被称之为Thick Threshold方法,该方法是在TOE基础上加以改进,预设一个分数界限,当邮件得分与判断阀值之差的绝对值在界限之内时,即使正确判断也进行训练。
现在说明该方法的应用。对于本文采用的逻辑回归模型,当邮件的得分大于等于0.5时,就判断成垃圾邮件;反之,当邮件的得分小于0.5时,就判断成正常邮件。采用TONE训练方法,在下述两种情况下进行训练:(1)过滤器分类错误;(2)如果设定阈值为0.1,则得分介于0.4到0.6之间的邮件都需要进行训练。
TONE训练方法只对分类面附近的样本进行训练,通过算法1将分类错误和在分类面附近的样本向“安全区域”调整。直观上,这个过程与支持向量机模型有异曲同工之妙。支持向量机模型在寻找最大化最近距离的分类面(即最优分类面);在TONE方法中,恰当地设置阀值,可以起到相同的作用。据我们所知,尚未有讨论TONE方法和最优分类面关系的文献。
本文采用梯度下降的方法更新特征库中特征的权重。使用梯度下降方法时,选取合适的特征学习速率以保证适当的学习速率。
具体实现如算法1所示。
算法1:分类及权重更新算法


4 实验
4.1 实验环境
4.1.1 测试数据
中文垃圾邮件过滤的评测数据主要来自国际文本信息检索会议(TREC,Text RE trieval Conference)和全国搜索引擎和网上信息挖掘学术研讨会(SEWM,Search Engine and Web M ining)。TREC评测由美国国防部高级研究规划局(DARPA,Defense Advanced Research Projects Agency和美国国家标准技术研究院(NIST,National Institute of Standards and Technology)主办,每年都吸引大批知名大学和企业研究机构参与,是信息检索领域最重要的评测。TREC会议于2005年开始举办垃圾邮件过滤测评,并在2006年进行了中文垃圾邮件过滤评测。SEWM由中国计算机学会主办。国内于2007年在SEWM上首次增加了垃圾邮件过滤评测项目,2008年有6所大学参加了评测。SEWM评测的目标是通过提供一个以中文为主并反映最新垃圾邮件特征的大规模邮件数据集,并以此检验各种过滤技术在实际垃圾邮件过滤中的有效性。该评测由华南理工大学广东省计算机网络重点实验室主持。
过滤器的性能在目前已有的全部公开中文垃圾邮件公有测试集(TREC06c、SEWM 07和 SEWM 08)上验证,表1是测试数据的情况。TREC06c是TREC 06年中文垃圾邮件评测的公开数据,SEWM 07和SEWM 08分别是SEWM 07年和SEWM 08年评测的公开数据,由华南理工大学提供。
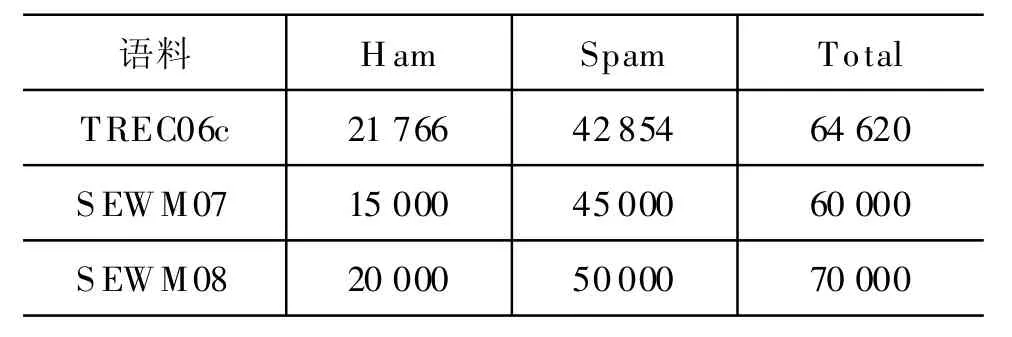
表1 垃圾邮件过滤测试集
4.1.2 评估指标
实验使用(1-ROCA)%作为过滤器的评估指标,lam%也被使用,用于参考。文献[13]给出了垃圾邮件过滤采用(1-ROCA)%和lam%而不是正确率/错误率作为评价指标的原因。
lam%(logistic average misclassification percentage):逻辑平均误判率,定义为lam%=logit-1(logit(ham%)/2+logit(spam%)/2),其中logit(x)=log(x/(1-x)),logit-1(x)=ex/(1+ex),ham%为正常邮件错误判断为垃圾邮件的比率,spam%为垃圾邮件错误判断为正常邮件的比率。
ROC曲线是接受者操作特性曲线(receiver operating characteristic curve)的简称。以ham%为横坐标,以spam%为纵坐标,取不同的 T值时,可以得到ROC曲线(实际表达recall-fallout)。1-ROCA(area above the ROC curve)表明了过滤器的累积失效情况。该值介于0和1之间,该值越小,表示过滤器效能越好。
本文采用 TREC提供的评估工具(下文称为TREC工具)。SEWM 07、08垃圾邮件过滤评测由中国计算机学会主办,华南理工大学承办并为评测提供了评估工具。在SEWM 08评测中,该工具与TREC工具在立即反馈和主动学习测试中,1-ROCA时的最后一位(百万分之一)略有不同,可能是由于舍入误差引起的。
4.1.3 测试任务
实验在所有的中文垃圾邮件过滤测试集上进行,测试 包括 TREC06c、SEWM 07 、SEWM 08 的公开语料。这些测试语料涉及到的测试任务有立即反馈(Immediate Feedback)、延迟反馈(Delayed Feedback)、主动学习(Active Learning)。在立即反馈测试中,过滤器按接收到的邮件次序将邮件分成正常邮件或垃圾邮件,并计算每一封邮件分值。过滤器在对邮件进行分类之后可以立即得到该邮件是否分类正确(即该邮件的答案。立即反馈假定用户在接收到邮件后立即作出判断。然而,真实用户不可能立即向过滤器返回正确的类别。用户经常一次读多封邮件,这导致过滤器不可能马上获得邮件的正确分类。延迟反馈模拟了这种情况。在延迟反馈中,过滤器需要等待一定数据邮件之后才能获得某一封邮件的分类。主动学习任务测试过滤器如何有效的利用反馈信息,降低系统的训练次数和对标注数据的依赖。在主动学习测试中,给定一定的配额(quota),过滤器在配额消耗完后测试系统不再提供反馈。
在实验中,所有的测试任务都使用了相同的过滤器。
4.2 实验结果
在实验中,首先比较了n元文法、TONE值对过滤器性能的影响,然后给出了实验的主要结果。表2至表3中的“active1000”表示在主动学习中最多使用1 000个学习样本。
表2比较了使用3-gram、4-gram和5-gram时,过滤器在不同的测试集合、测试任务的性能。表中所有实验使用了相同的参数,学习速率 rate(算法1中)为0.004,TONE为0.32。通过实验结果可以看出,以4-gram提取特征,过滤器的性能较优。
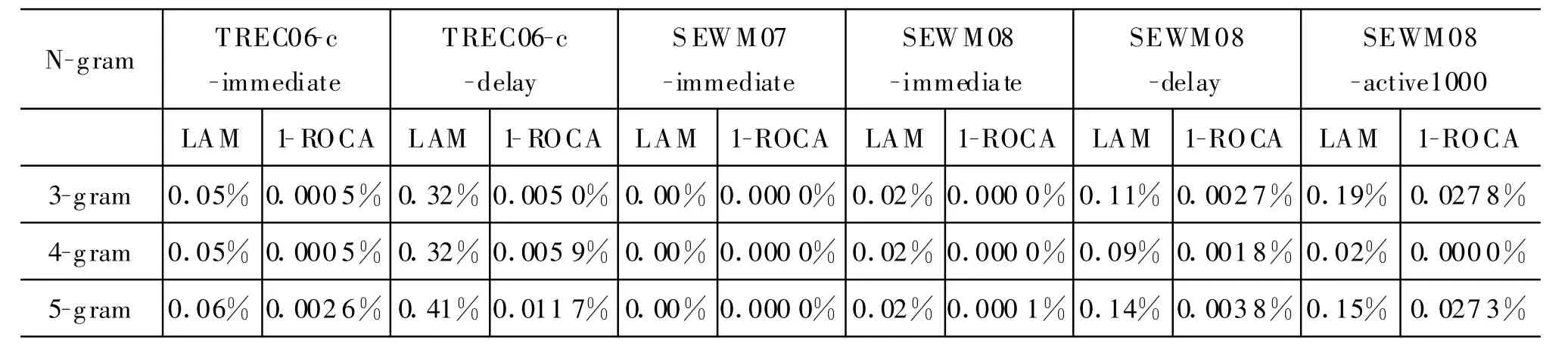
表2 n元文法结果比较
表3比较了TONE对过滤器的影响。实验中采用四元文法、学习速率rate设为 0.004。通过实验结果可以看出,TONE=0.32时,过滤器的性能较优。
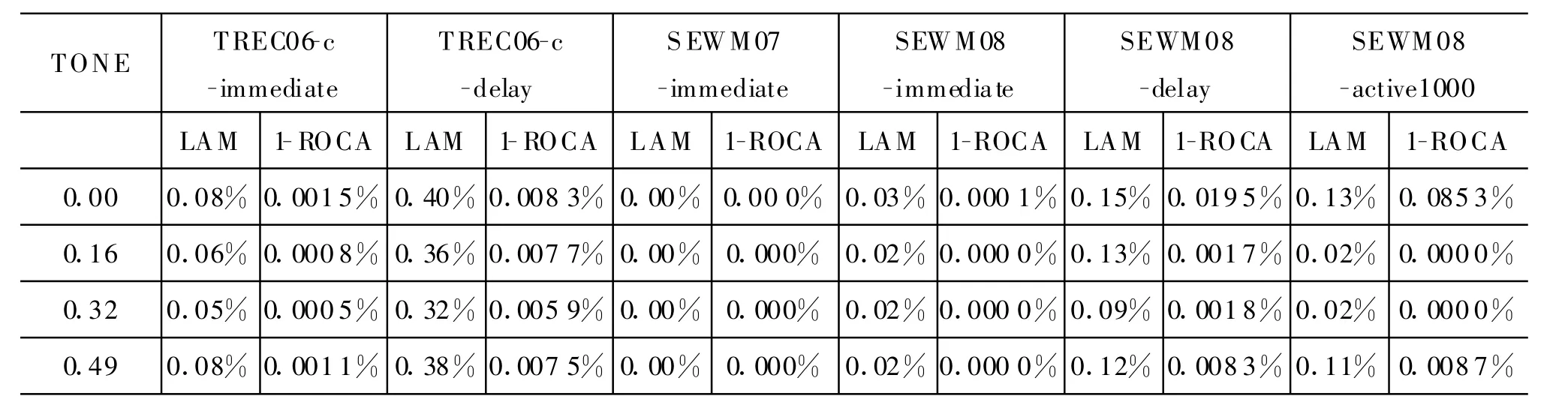
表3 TONE对过滤器的影响
表4是实验的主要结果,分别给出了过滤器在立即反馈、延迟反馈和主动学习上与其他系统的性能比较。在立即反馈、延迟反馈和主动学习的测试上,系统参数设置为:四元文法,学习速率rate为0.004,TONE为0.32。由于SEWM 07评测没有参赛队进行了在线学习任务,只进行了批处理(离线)任务,因此没有在线任务的最佳系统。SEWM 07没有进行延迟反馈测试,TREC06C和SEWM 07没有进行主动反馈测试,没有相关实验数据。表中“最佳系统/第二名系统”表示评测中最佳系统或第二名系统,“/”在后表示最佳系统,“/”在前表示第二名系统。如“0.002 3%/”表示最佳系统的性能,“/0.0094%”表示第二名系统的性能。本文的方法参加了SEWM 08评测,包揽了SEWM 08所有在线任务的第一,在表中SEWM 08下的“最佳系统/第二名系统”标识了第二名系统的性能。
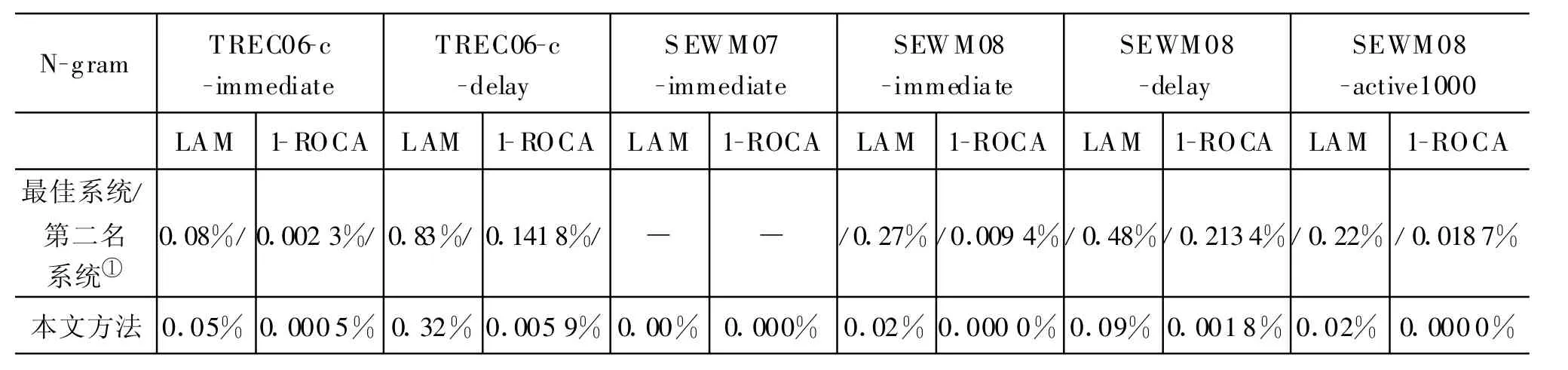
表4 与其他系统结果比较
在SEWM 08的评测中,本文描述的系统取得了较好的效果。除了本文所描述的系统采用n元文法外,其他参评单位均提取字或词作为特征,所使用的模型包括PPM(Prediction by PartialM atching)、基于SVM的过滤器、基于朴素贝叶斯分过滤器、基于语言模型的过滤器。这表明,对于垃圾邮件过滤,字节级n元文法能够更有效地提取过滤器所需的特征。
从实验结果可以看出,本文提出的方法性能优异,要么远远优于当年评测的最佳系统,要么在评测中获得第一,并远远领先第二名。

图2 过滤器的学习曲线
图2给出了过滤器在不同的测试集合上立即反馈的学习曲线。过滤器在SEWM 07立即反馈上的表现极其出色,垃圾邮件误判率=0.00%,正常邮件误判率=0.00%,逻辑误判率=0.00%,1-ROCA=0.000 0%,因此出现了其对应的学习曲线与X轴重回的现象。从图2可以看出,过滤器的学习性能极好,在经历了一定数量的学习后(对应于一段时间的实际应用),过滤器几乎不再出现错误。
5 结论
垃圾邮件与垃圾邮件过滤是电子邮件应用中矛和盾。垃圾邮件的发送者不断改进垃圾邮件的发送技术,以便使垃圾邮件不被过滤。在这种情况下,需要垃圾邮件过滤器能够适应不断演进的垃圾邮件,因此采用在线学习,使得过滤器能够以增量学习的方式调整过滤器的参数,保证过滤器的性能。本文针对垃圾邮件过滤过滤问题,采用在线学习方式,使过滤器具备处理不断变化的垃圾邮件能力,这是本文描述的过滤器能够取得成功的基础。
高性能中文垃圾邮件过滤器的设计是一个整体工作,涉及到模型的学习方式、模型的选择、特征抽取等多个方面,不能单纯地强调某一方面而忽略其他方面,要寻求整体最优解决方案。本文采用在线逻辑回归模型这一典型的判别学习模型,该模型具有处理速度快、适应于在线学习的特点,奠定了高性能过滤器的基础;提出了字节级n元文法获取邮件特征,简化了特征提取,提高了特征提取的速度,该方法与语言无关,并使得过滤器具备处理图像、病毒等复杂对象的能力,提高了过滤器的性能;采用TONE方法进行训练,减轻了系统对训练数据的需求,提高了系统的效率,同时还提高了系统的鲁棒性。实验结果表明,本文的方法的性能极佳,本文描述的过滤器是当前性能最好的中文垃圾邮件过滤器之一。
[1] V.N.Vapnik.Statistical Learning Theory[M].New York,USA:JohnW iley&Sons,Inc.1998:1-18.
[2] A.Bratko,B.Filipi?,G.V.Cormack et al.Spam Filtering Using Statistical Data Comp ression Models[J].The Journal o f Machine Learning Research archive,2006,7:2673-2698.
[3] G.H ulten and J.Goodman.Tutorial on Junk E-mail Filtering[C]//The Twenty-First International Conference on M achine Learning(ICML 2004).2004:(Invited Talk,http://research.m icrosoft.com/en-us/um/peop le/joshuago/icm ltutoria lannounce.htm).
[4] D.Sculley,G.M.Wachman.Relaxed Online SVM s for Spam Filtering[C]//The 30th Annual International ACM SIGIR Con ference(SIGIR'07).New York,NY,USA :ACM,2007 :415-422.
[5] J.Goodman and W.Yih.On line Discrim inative Spam Filter Training[C]//Third Conference on Email and Anti-Spam(CEAS 2006).Mountain V iew,California,USA.2006:113-115.(http ://www.ceas.cc/2006/22.pd f).
[6] D.Scu lley.Advances in Online Learning-based Spam Filtering[D].Medford,M A,USA:Tufts University.2008.
[7] 苏绥,林鸿飞,叶正.基于字符语言模型的垃圾邮件过滤[J].中文信息学报,2009,23(2):41-47.
[8] P.Hayati,V.Potdar.Evaluation of spam detection and prevention framew orks for email and image spam:a state of art[C]//International Conference on Information Integration and web-based Applications and Services(iiWAS 2008)workshops:Proceedings o f the 10th Internationa l Conference on In formation Integration and Web-based App lications&Services(A IIDE 2008).New York,NY,USA:ACM.2008:520-527.
[9] G.V.Cormack,A.Bratko.Batch and On line Spam Filter Comparison.[C]//Third Conference on Email and Anti-Spam(CEAS 2006).Mountain View,California,USA.2006.
[10] J.M.M.Cruz,G.V.Cormack.Using old Spam and H am Samp les to Train Email Filters[C]//6th Conference on Email and Anti-Spam.in Mountain V iew,California,USA,2009.
[11] G.V.Cormack.University o f Waterloo Participation in the TREC 2007 Spam T rack[C]//The Six teenth Text REtrieval Con ference(TREC 2007)Proceedings.Gaithersburg,Mary land,USA.2007.
[12] 刘伍颖,王挺.基于多过滤器集成学习的在线垃圾邮件过滤[J].中文信息学报,2008,22(1):67-73.
[13] G.Cormack,T.Lynam.TREC 2005 Spam Track Overview[C]//The Fourteenth Tex t REtrieval Conference(TREC 2005)Proceedings.Gaithersburg,M D,USA.2005.
猜你喜欢
英语文摘(2021年10期)2021-11-22
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
潍坊学院学报(2020年2期)2021-01-18
计算机与网络(2020年4期)2020-04-20
中国石油大学胜利学院学报(2018年4期)2019-01-17
中国自行车(2018年11期)2018-12-03
西夏学(2018年2期)2018-05-15
中国自行车(2017年1期)2017-04-16
兵团工运(2016年9期)2016-11-09
