
融合交叉注意力机制的轻量化街景语义分割算法
2025-02-03 00:00:00邵玉裴东
西北师范大学学报(自然科学版) 2025年1期











摘要:在城市街道场景中进行语义分割对实现自动驾驶和智能交通系统等应用至关重要.然而,由于主流的语义分割模型通常参数较多且计算复杂,使得它们难以在移动端或嵌入式设备上高效部署以及对系统实现实时响应.为了解决这一问题,文中提出了一种融合交叉注意力机制的轻量化街景语义分割算法.首先,使用轻量级的MobileNetV3网络替代原模型中的特征提取主干网络,从而提升参数利用率并减少模型的总体参数量;其次,对空洞空间金字塔池化模块(ASPP)进行了改进,设计了一种轻量化的密集连接ASPP模块LD-ASPP,通过密集连接将多个卷积层串联,并使用深度可分离空洞卷积取代ASPP模块中的标准空洞卷积,从而降低计算量并提升训练效率.同时,加入了条带池化模块,以捕获更加丰富的上下文信息,从而增强模型在复杂场景中的表现能力;最后,融入了交叉注意力机制,有效捕捉像素与周围像素之间的关系以及通道间的依赖性,实现更加精准的语义分割.实验结果表明,该算法在Cityscapes城市街景数据集上的平均交并比(mIoU)达到了74.02%,模型参数量仅为2.18Mb;与使用MobileNetV2作为主干网络的DeepLabV3+模型相比,mIoU提升了3.11%,训练速度提升了17.92%,且模型参数量仅为原模型的42.6%.
关键词:图像语义分割;DeepLabV3+;轻量化;注意力机制;条带池化
中图分类号:TP 391.41;TP 183""" 文献标志码:A""" 文章编号:1001-988Ⅹ(2025)01-0061-11
DOI:10.16783/j.cnki.nwnuz.2025.01.011
收稿日期:20240520;修改稿收到日期:20241010
基金项目:国家自然科学基金资助项目(61961037)
作者简介:邵玉文(2001—),女,河南周口人,硕士研究生.主要研究方向为图像处理、机器人技术与应用.
Email:3227338932@qq.com
*通信联系人,男,副教授,硕士研究生导师.主要研究方向为电路与系统、机器人技术与应用.
Email:peidong@nwnu.edu.cn
A lightweight street scene segmentation algorithm
incorporating criss-cross attention
SHAO Yu-wen1,PEI Dong1,2
(1.College of Physics and Electronic Engineering,Northwest Normal University,Lanzhou 730070,Gansu,China;
2.Gansu Engineering Research Centre for Intelligent Information Technology and Application,Lanzhou 730070,Gansu,China)
Abstract:Semantic segmentation in urban street scenes is crucial for enabling applications such as autonomous driving and intelligent transportation systems.However,mainstream semantic segmentation models often have large parameter sizes and high computational complexity,making them difficult to efficiently deploy on mobile and embedded devices.To address these issues,this paper proposes a lightweight DeepLabV3+ optimization algorithm for urban scene segmentation,incorporating criss-cross attention.Firstly,the lightweight MobileNetV3 network is used to replace the original backbone for feature extraction,enhancing parameter efficiency and reducing the models overall parameter size.Secondly,the ASPP(Atrous Spatial Pyramid Pooling) module is improved by designing a lightweight densely connected ASPP(LD-ASPP) module,where densely connected convolutional layers are sequentially connected.Depthwise separable atrous convolutions replace the standard atrous convolutions in the ASPP module,thereby reducing computational overhead and improving training efficiency.A stripe pooling module is also introduced to capture richer contextual information,enhancing the models ability to represent complex image scenes.Lastly,Criss-Cross Attention is integrated to effectively capture relationships between pixels and their surrounding regions,as well as channel dependencies,enabling more accurate semantic segmentation.Experimental results demonstrate that the proposed algorithm achieves a mean Intersection over Union(mIoU) of 74.02% on the Cityscapes urban street dataset,with a parameter size of only 2.18MB .Compared to the DeepLabV3+ model using MobileNetV2 as the backbone,the mIoU is improved by 3.11 percentage points,training speed increased by 17.92 % and the models parameter size being only 42.6% of the original.
Key words:image semantic segmentation;DeepLabV3+;lightweight;attention mechanism;strip pooling
城市街景是构成智能城市的重要部分,其研究对于无人驾驶、智能导航等应用至关重要[1].图像语义分割和目标检测技术可以用于街景信息的提取[2],其中图像语义分割因其卓越的图像理解能力被广泛应用.作为计算机视觉的重要分支[3],语义分割通过为图像中的每一个像素分配预定义的语义标签,帮助理解场景内容.例如,识别并区分行人、车辆与建筑物,并为不同类别的像素赋予预设颜色[4].由于语义分割结合了高层语义信息与低层空间位置信息,因此在自动驾驶、智能安防、医学图像分析、遥感等领域得到了广泛应用[5].
在早期的研究中,传统图像分割方法主要包括基于阈值、边缘和图论的分割方法[6].这些方法通常通过浅层特征如灰度、纹理与几何信息来划分图像,将图像分割成具有一致性特征的区域,且不同区域之间表现出明显差异.然而,这些传统方法在处理复杂场景时适应性差,计算量大,且容易受到遮挡与噪声的影响,难以满足高复杂度的图像处理需求.近年来,随着深度学习技术的发展[7],卷积神经网络(CNN)被广泛应用于语义分割中[8],推动了分割方法快速发展并逐渐取代传统方法[9].Long等[10]提出了全卷积网络(FCN),这是基于深度学习进行像素级预测的开创性工作,FCN通过将CNN的全连接层转换为卷积层,实现了端到端的像素级预测.Ronneberger等[11]提出了U-Net网络,U-Net在医学影像分割领域取得了显著成果,使用了编码器-解码器结构[12],并引入了分层特征融合,通过在编码和解码网络之间进行多层次特征融合,补偿了采样过程中的信息损失.Zhao等[13]提出的PSPNet通过金字塔池化模块从多个尺度提取上下文信息,为场景预测提供了有效框架.
DeepLab系列模型结合了深度卷积神经网络(DCNN)与全连接条件随机场(CRF),用于处理语义分割任务.Chen等[14]提出的DeepLabV1采用VGG16作为骨干网络,用卷积层替代全连接层,并引入空洞卷积扩大感受野,增强上下文信息的捕获能力.DeepLabV2[15]在此基础上进行改进,采用ResNet代替VGG16,并引入空洞空间池化金字塔(ASPP)模块,以不同空洞率的卷积提取多尺度特征信息.在DeepLabV3[16]中,ASPP模块进一步增强,加入了批量归一化和全局平均池化以提升全局上下文的获取能力.DeepLabV3+[17]进一步结合解码器模块,与ASPP结合形成了编码-解码结构,通过上采样逐步恢复空间信息,优化物体边界细节.
上述语义分割算法中大多都是参数量较大而且计算时间长,但是在自动驾驶、智能机器人移动等任务中,不仅需要较高的分割精度还需要更为轻量化并且有较高的实时性[18].因此,为了模型能够灵活的部署到移动端和嵌入式设备中,文中提出了一种融合交叉注意力机制的轻量化街景语义分割算法.将DeepLabV3+模型中的原始特征提取网络替换为更为轻量的MobileNetV3[19],在ASPP模块中设计了轻量级的密集连接LD-ASPP模块,通过密集方式连接卷积层,并将标准空洞卷积替换为深度可分离空洞卷积.同时,引入条带池化模块取代全局平均池化,最后在ASPP模块后加入了注意力机制(Criss-cross attention, CCA)[20],可以增强模型对复杂场景和细粒度特征的理解,从而提高分割精度.经过上述优化操作,在平衡算法分割精度的同时降低了参数量提高了计算速度.
1" 改进的轻量化DeepLabV3+模型
1.1" 改进后的DeepLabV3+网络
DeepLabv3+模型采用了经典的编码-解码结构,如图1所示.在编码器阶段,DCNN模块负责对输入图像进行特征提取,生成具有丰富语义信息的特征图.DeepLabv3+提供了3种可选的特征提取网络,包括MobileNetv2、ResNet-50[21]和Xception[22].ASPP模块旨在捕捉多尺度上下文信息,同时通过全局池化分支获取全局语义.该模块包括1×1卷积、3个膨胀率分别为6,12,18的空洞卷积,以及一个全局池化层,共有5个操作生成5个不同的输出.随后,这些输出经过特征融合处理,并通过1×1卷积进行通道压缩,最终输出编码器提取的特征信息.在解码器部分,首先对编码器的输出进行4倍采样,接着对特征提取网络输出的浅层特征进行1×1卷积以调整通道数,然后将两者拼接,并通过3×3卷积进一步融合特征,细化后进行4倍采样,精细化目标物体边缘,最终输出分割结果[23].
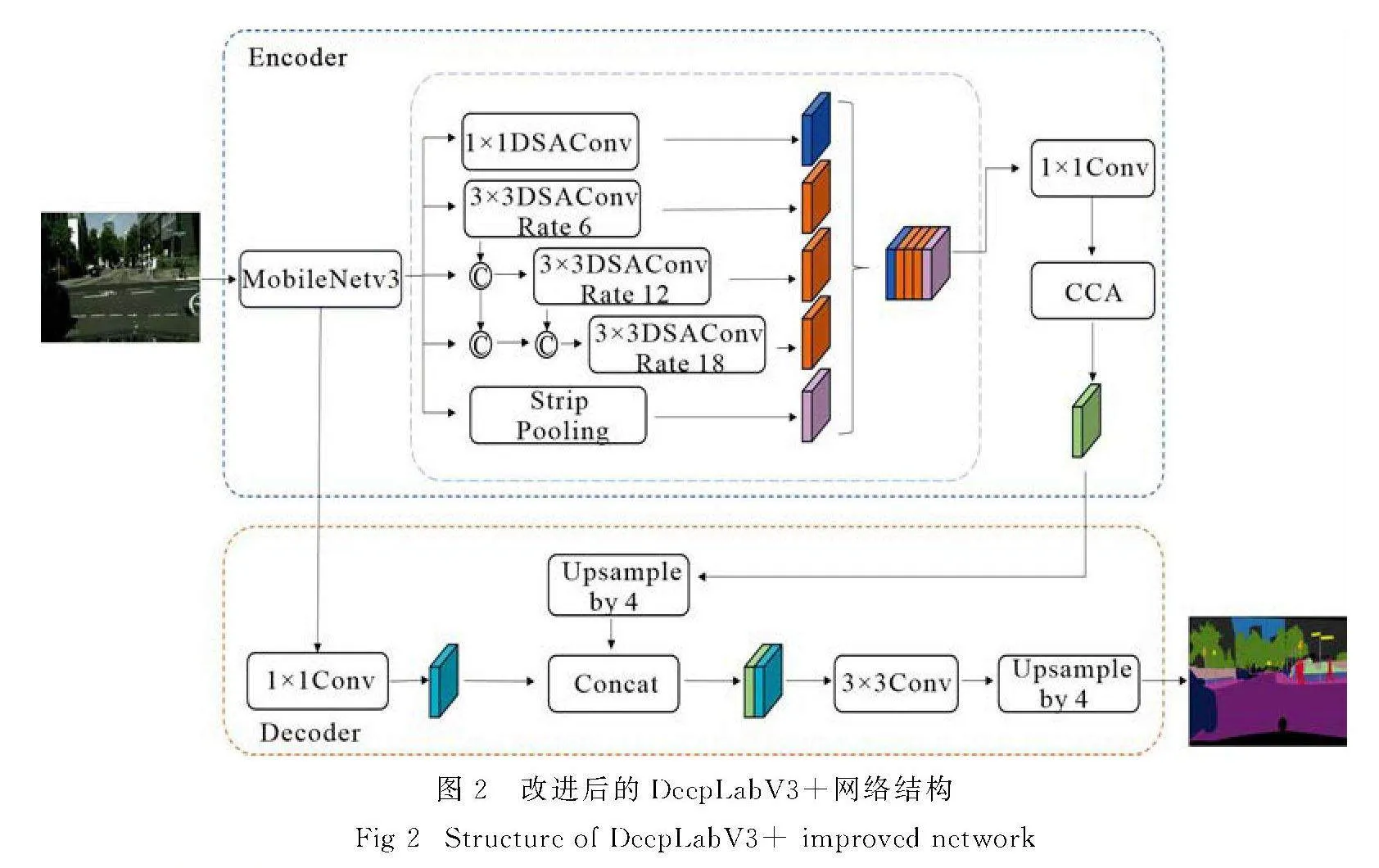
文中在DeepLabV3+模型的基础上提出了创新的优化方法,如图2所示,在骨干网络和ASPP模块等部分进行了改进,旨在解决语义分割模型参数量大、计算耗时长的问题,同时在保证精度的前提下减少模型参数并提升运行速度和可部署性.首先,文中引入了轻量级的MobileNetV3作为特征提取的骨干网络,替代了原有的主干网络,从而提高了参数利用效率并降低了模型的总体参数量,提升了网络的效率和速度,使其更适合在资源受限的移动设备和嵌入式系统上运行,实现高效的语义分割.其次,设计了轻量化的密集连接ASPP模块(LD-ASPP),通过密集连接串联多个卷积层,并用深度可分离空洞卷积替换传统空洞卷积,这样不仅减少了计算开销,还通过丰富的上下文信息增强了模型对复杂场景的理解能力.同时,条带池化模块的引入能够捕捉不同尺度和位置的上下文信息,进一步增强了模型在复杂图像场景下的表现能力.最后,该算法在ASPP模块之后融合了交叉注意力机制,以提升模型在捕捉图像全局信息方面的能力.该机制在行列维度分别计算注意力,逐步聚合全局上下文信息,使得每个像素不仅关注邻域,还与整行和整列的像素信息进行交互,从而可以提升特征表达能力,简化计算复杂度、增强全局感知、提升边界处理和分割精度.
1.2" MobileNetV3卷积神经网络
MobileNet[24]是一种轻量级卷积神经网络,特别适合资源受限的设备,如移动设备等场景.该网络在维持较低参数量和计算复杂度的同时,仍具备较快的运行速度和良好的性能.MobileNetV3是MobileNet系列的第3代版本,如图3所示.
MobileNetV3延续了MobileNetV1的深度可分离卷积与MobileNetV2[25]的线性瓶颈逆残差结构,同时增加了基于Squeeze-and-excitation(SE)结构的轻量级注意力机制,并采用了h-swish(x)激活函数[26].逆残差结构与传统的先降维、再深度卷积、最后逐点卷积升维的残差结构相反,它首先升维并使用Relu6替代Relu激活函数,随后进行深度卷积处理,最终通过逐点卷积降维并应用Linear激活函数.此逆残差设计有助于减少参数和M-Adds的计算量.SE模块[27]是一种特征校准机制,能够增强有效特征权重,抑制无效或次要特征,以较小的计算代价提升现有深度模型的性能.
1.3" ASPP模块的改进
1.3.1" LD-ASPP模块
文中设计的LD-ASPP模块是一种轻量化的密集连接ASPP结构,其结构如图4所示.在LD-ASPP中,每个卷积层的输出不仅传递给下一层,还与更后续的卷积层输入相结合,使后续层能够获取前面所有层的特征.这种设计使模型在捕捉多尺度信息方面更具优势,尤其在复杂场景下表现更为出色.此外,模块中的空洞卷积被替换为深度可分离空洞卷积,以减少计算量和参数,同时保持对多尺度信息的有效捕捉.全局平均池化也被条带池化取代,进一步增强模型对全局特征的感知能力,同时不会显著增加计算复杂度.经过改进的LD-ASPP模块在维持较高分割精度的同时,提供了较快的推理速度.
如图5所示,深度可分离空洞卷积(Depthwise separable atrous convolution,DSAConv)将空洞卷积引入深度可分离卷积[28]的逐通道卷积中,以降低参数和计算量的同时扩大感受野.空洞卷积通过
调整卷积核内部采样点的间隔,使得采样点之间的距离增加,在相同卷积核尺寸下能够捕捉到更多远离中心的上下文信息.
深度可分离空洞卷积的第一步是逐通道的空洞卷积,每个输入通道只通过对应的空洞卷积核卷积处理,既减少计算开销,又保持对每个通道的独立特征提取.第2步是逐点卷积,使用1×1卷积核对深度卷积的输出进行卷积操作,将不同通道的特征进行线性组合,以获取更高级别的特征表示.深度可分离空洞卷积结合了空洞卷积和深度可分离卷积的优势,既能扩大感受野,又降低了模型参数量和计算复杂度,从而提高了模型的分割效率.
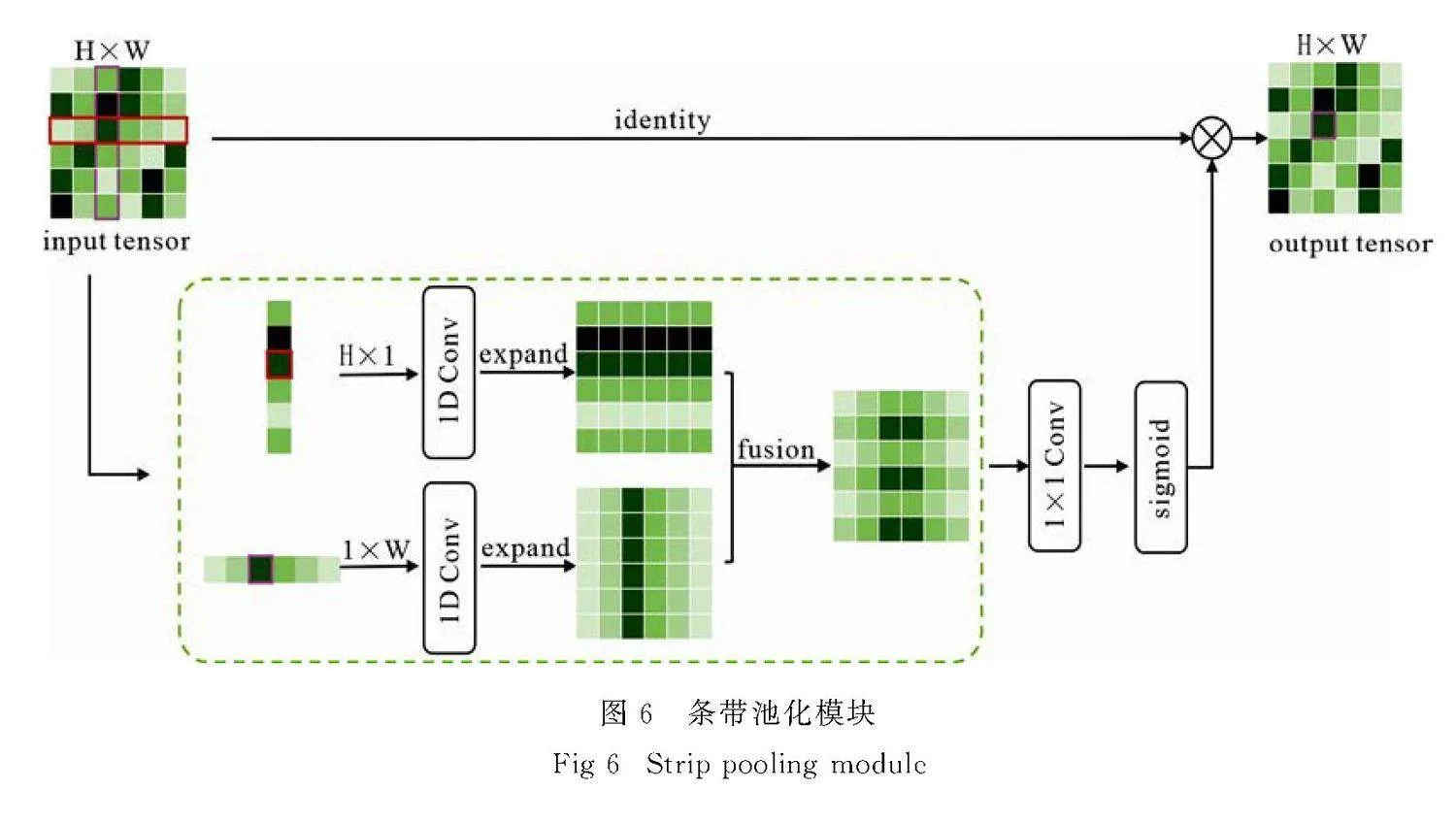
1.3.2" 条带池化模块
Hou等[29]提出的条带池化模块旨在增强网络对边缘和细节信息的感知,以此捕获孤立区域的远程关系与局部上下文信息.传统池化操作通常通过方形池化核对图像或特征图进行下采样,而条带池化采用的是一种长而窄的池化核,通常为1×N或N×1的形状.在文中模型的ASPP模块中,全局平均池化被替换为条带池化,其结构如图6所示.
条带池化核的长条形设计能够有效建立水平或垂直方向的长程依赖关系,从而有助于获取全局信息.由于条带池化核在另一维度上较窄,能够捕捉到物体的细节,进而收集图像中不同维度的远程上下文信息,在兼顾全局与局部信息的同时,使得提取的特征更加具有代表性,从而更好地支持后续的图像分割任务.
条形池化是标准平均池化的变体,标准平均池化可以表示为
yi0,j0=1h×w∑0≤ilt;h∑0≤jlt;wxi0×h+1,j0×w+j.(1)
水平条带池化和垂直条带池化的计算公式分别为
yhi=1W∑0≤jlt;wxi,j,(2)
yhj=1H∑0≤ilt;Hxi,j,(3)
其中,yhi和yhj分别表示水平方向的条形池化输出和垂直方向的条形池化输出.
1.4" 交叉注意力机制
CCA旨在增强模型对全局上下文的理解,并改善特征图的细节表达.其结构如图7所示,CCA模块接收来自卷积网络中间层输出的特征图,这些特征图包含了丰富的局部信息.特征图H经过十字交叉注意力模块处理后得到新的特征图H′,特征图H′中像素所包含的上下文信息仅限于水平和垂直维度,对于需要更高分割精度的任务,这样的上下文信息可能不足.因此,再次将特征图输入十字交叉注意力模块,得到特征图H″.此时,特征图H″的每个像素都结合了与所有位置像素的信息.
图8给出了CCA模块的细节,大小为RC×W×H的特征图H输入后分别通过1×1的卷积核生成查询(Query)、键(Key)和值(Value)特征图.在QC′×W×H的空间维度上每一个特征点u的位置上,都可以得到一个向量Qu,
同时,也在KC′×W×H中在对应着特征点u的所处位置从相同水平和竖直方向上收集特征,得到集合Ωu,其中Ωi,u是Ωu的第i个元素.将K上图像中心展开的纵横元素与Q上的每一个C维的特征向量进行乘积求和操作,得到关系参数,其计算如(4)式所示.然后将得到的结果进行softmax操作,生成注意力特征图A.
di,u=QuΩRi,u.(4)
在V的空间维度上每一个特征点u的位置上,都可以得到一个向量Vu,并且还能从u所处位置从相同水平和竖直方向上收集特征,得到集合Φu∈R(H+W-1)×C.将注意力特征图A作用于特征图V上,过程如(5)式所示.特征图H′获得更大的上下文感受野,并且可以通过注意力特征图,从而有选择性地聚集上下文特征.
H′u=∑H+W-1i=0Ai,uΦi,u+Hu.(5)
2" 结果与分析
为了确保实验的有效性,文中所有实验均基于CityScapes公共数据集进行验证.CityScapes数据集广泛应用于街景场景图像的语义分割任务中,该数据集由奔驰公司于2015年发布,旨在推动对城市街景语义理解的研究.CityScapes数据集包含了来自50个不同城市的街景立体视频序列,提供了20 000张弱注释图片和5 000张高质量强注释图片.文中在街景分割实验中使用了5 000张精细标注的图像[30],其中2 975张作为训练集,500张作为验证集,1 525张作为测试集.图像涵盖了不同时间段和天气条件下的街道动态场景,并为30个类别提供了标注,以供研究者选择使用.数据集中的图像分辨率为2 048×1 024像素,这些图像中的街景背景信息复杂且待分割目标尺寸较小.
由于服务器性能和模型的要求,将输入图像的分辨率从1 024×2 048调整为513×513,并通过随机裁剪和翻转来增强数据.利用CityScapes数据集,研究者能够开发和评估语义理解与分割的算法.CityScapes数据集的示例如图9所示,依次展示了原始图像、标签图像和粗标注图像.
2.1" 实验环境及设置
实验环境分为软件环境以及硬件环境.其中软件环境所采用的操作系统为Windows 10,基于PyTorch 1.10.1网络框架,CUDA11.3版本,Cudnn8.2.1版本,编程语言为Python3.10.硬件环境配置CPU为Intel(R)Core(TM)i7-11700K @ 3.60GHz,GPU为NVIDIA GeForce RTX 3070Ti 8GB.
根据设备性能调整实验设置,最大程度利用计算机的资源与性能,文中实验过程中优化器采用带动量的随机梯度下降法(SGD),权值衰减率(Weight decay)为0.0001,训练时的批次大小(Batch size)为8.网络初始学习率设为 0.1,并且采用poly衰减策略,计算公式为
lr=initial_lr×1-itrstotal_itrspower,(6)
其中,动量参数(power)为0.9;initial_lr为初始学习率;itrs为当前迭代次数;total_itrs为迭代训练的总次数,其值设置为40 000.输入图像分辨率为513×513,指定损失函数的类型为交叉熵损失函数,其表达式为
Loss=-∑ni=1yilog(pi ),(7)
其中,n为类别数,yi=1表示真实标签为第i类,其余元素为0.pi表示模型预测为第i类的概率.
2.2" 评价指标
为了评估实验的有效性,文中采用模型参数量(parameters)、平均交并比(mean intersection over union,mIoU)、平均像素精度(mean pixel accuracy,mPA)以及模型训练时长(model train time)等关键指标对模型进行评估.其中,模型参数量表示模型的空间复杂度,mIoU反映了分割网络整体的准确性,平均像素精度用于评估图像分割任务中模型预测结果与真实标签之间的像素级匹配程度,模型训练时长则衡量了网络的计算速度.
模型参数量指的是语义分割模型中所有参数总和,能够体现模型的空间复杂度.在图像语义分割任务中,模型通过卷积操作提取目标特征,这些特征以权重参数的形式存储在模型中.卷积核的尺寸和数量直接决定了模型的参数量.对于单层卷积操作,参数数量可以通过下式计算:
Nparameters=a2×Cin×Cout,(8)
其中,a为卷积核尺寸; Cin为输入通道数;Cout输出特征图的通道数.
mIoU作为图像语义分割的核心评价指标,衡量了模型性能和分割结果的质量.mIoU用于评估实际值集合与预测值集合的交集与并集之间的比例,能够直接反映分割的精确度.通过对每个类别的IoU进行计算,并对所有类别的IoU取平均,最终得到mIoU值.mIoU越高,表明分割结果与真实值的吻合程度越高,其分割效果越好.公式如下:
IoU=TPTP+FN+FP=
pii∑nj=0pij+∑nj=0pji-pii,(9)
mIoU=1n+1∑ni=0IoU.(10)
其中,TP表示将标签和预测都判断为正例的像素数量;FN表示标签为反例,但预测为正例的像素数量;FP表示标签为正例,但预测为反例的像素数量;n表示所有像素的类别数;pii表示将第i类别的像素预测为第i类别的像素的总数;pij表示将第i类别的像素预测为第j类别的像素的总数;pji表示将第j类别的像素预测为第i类别的像素的总数.
mPA是对每个类别的像素准确率进行平均,它衡量模型在每个类别上的像素分类准确程度,并计算所有类别的平均值.平均像素精度提供了一种直观的方式来评估图像分割模型在像素级别上的准确性.较高的平均像素精度表明模型能够准确地将像素分配到正确的类别或区域.平均像素精度的计算公式为
mPA=1n∑ni=1TPiTPi+FNi,(11)
其中,n为类别的总数;TPi第i类别的真阳性像素数;FNi为第i类别的假阴性像素数.
2.3" 实验结果与分析
2.3.1" 不同主干网络对比实验
在执行语义分割任务时,特征提取网络至关重要.不同的骨干网络在提取图像特征方面表现各异,因此选择合适的骨干网络至关重要.文中采用了DeepLabV3+模型,测试了常见的骨干网络如ResNet-50、Xception和MobileNetV2,并引入了MobileNetV3,在Cityscapes数据集上进行训练与测试.通过mIoU和Parameters指标对模型性能进行了评估,实验结果如表1所示.
通过表1可以看出,在实验4中将骨干网络替换为MobileNetV3后,mIoU达到了71.18%,而参数量仅有2.18Mb.尽管与实验1中的ResNet-50和实验2中的Xception相比,mIoU略低,但参数量大幅减少.与实验3中的MobileNetV2相比,分割精度相差不大,模型参数量则缩减至其42.6%.综合来看,MobileNetV3在分割精度不逊色的情况下,还具备更快的分割速度.对于城市街景这种实时变化较大的应用场景,其优势尤为明显.此外,参数量小且模型复杂度低的特点使其更适合部署在移动设备和嵌入式系统中.
2.3.2" 注意力机制对比实验
注意力机制通过动态调整模型的权重分配,使卷积神经网络能够更有效地识别和利用与当前任务相关的关键特征.通过对重要权值的计算,模型能够更专注于对结果有显著影响的信息,从而减少不相关特征的干扰,同时提高计算效率.文中以MobileNetV3为骨干网络,并在改进后的ASPP模块中引入了4种轻量级注意力机制进行对比实验,利用mIoU、训练时间和mPA指标进行评估,实验结果如表2所示.
MobileNetV3-Small作为一种轻量化网络结构,具备较低的参数量和计算复杂度,引入不同注意力机制后对参数量影响不大.表2显示,CCA在分割精度、训练速度和像素精度上均优于Self-Attention SA.尽管在训练速度上,Efficient Channel Attention ECA和Convolutional block attention module CBAM表现略优,但在分割准确度和像素精度上,CCA表现更优.综合分析后,文中选择性能较好的CCA,帮助模型实现更高效、更准确的语义分割.
2.3.3" 优化算法消融实验
为了验证MobileNetV3、LD-ASPP模块、条带池化模块以及CCA注意力机制的有效性,文中在相同实验环境下设计了7组消融实验进行对比分析.第1组将DeepLabv3+模型的骨干网络Xception替换为轻量化的MobileNetv2;第2组则将骨干网络替换为MobileNetv3;第3组使用LD-ASPP模块代替原ASPP模块;第4组在第3组基础上进一步引入条带池化模块;第5组基于第2组集成CCA注意力机制;第6组在第5组基础上加入条带池化模块;第7组则在第4组基础上集成CCA注意力机制.实验结果见表3.
通过比较第1与第2组,可以发现将骨干网络由MobileNetV2替换为MobileNetV3后,模型的分割精度和计算效率均有所提升.第2组与第3组的对比结果显示,使用LD-ASPP模块替换原ASPP模块后,mIoU略有提升,且计算效率显著提高.进一步比较第3组与第4组,以及第5组与第6组,引入条带池化模块在不显著影响分割速度的情况下,提升了分割精度和像素精度.通过对比第2组与第5组,以及第4组与第7组,可以看出引入CCA注意力机制能够更好地捕捉像素间和通道间的关系,横向和纵向提升分割任务的准确性,进一步增强了模型的分割性能.
2.3.4" 不同分割模型对比实验
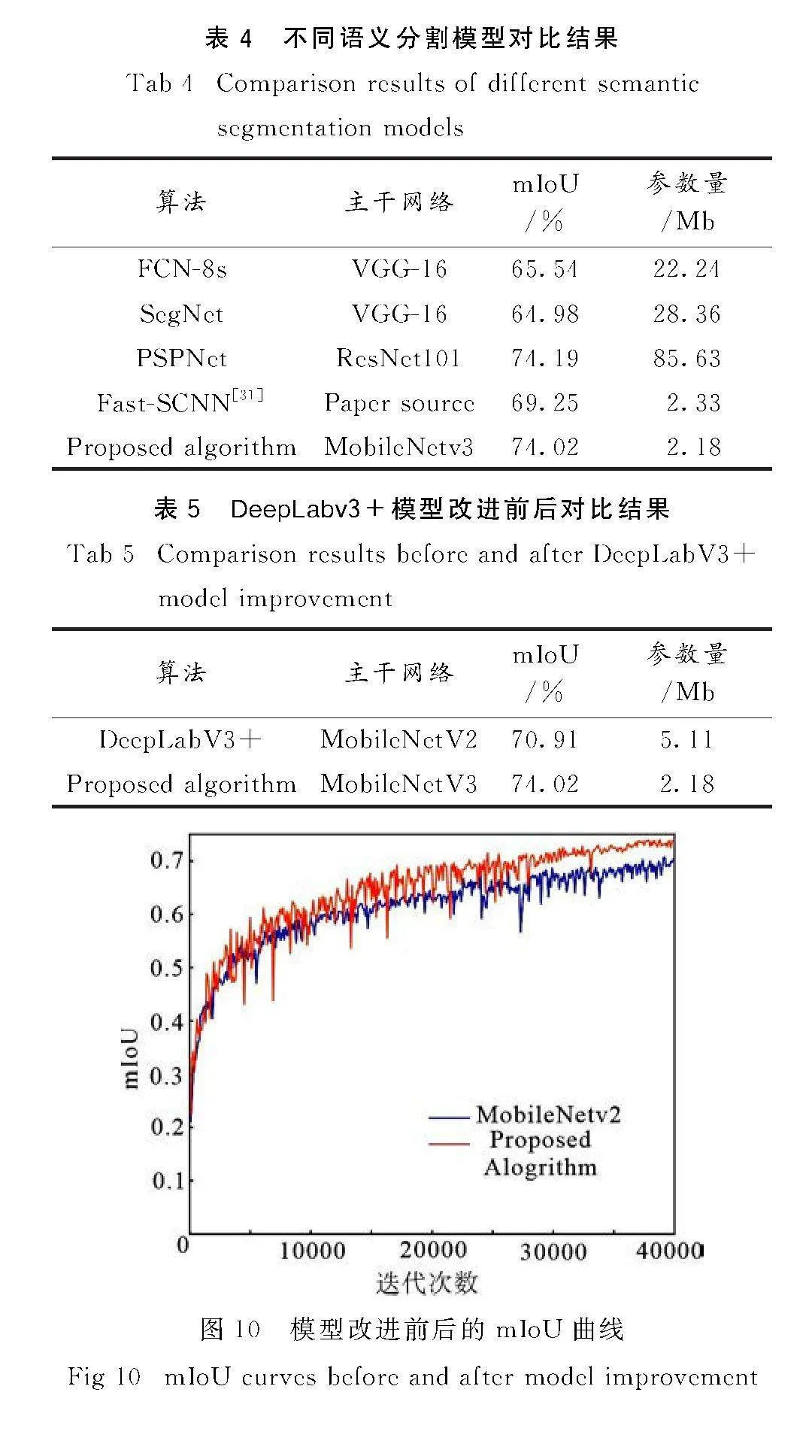
为验证文中所提算法的优越性,在CityScapes数据集上将文中所提模型与FCN-8s、SegNet、PSPNet和Fast-SCNN等常用语义分割模型进行比较,其结果如表4所示.从表中可以看出,文中所提算法相比于FCN-8s和SegNet无论是在分割精度还是参数量运行速度方面都是更优秀的;相比于PSPNet虽然在分割精度上略逊一些,但是其参数量仅有PSPNet的2.5%,很大程度上节约了计算资源,提高了的计算效率;相比于Fast-SCNN与其模型大小相似,但是分割精度高出了4.77%.综合而言,文中改进的模型有较好的优越性.
为了展现文中所改进的算法在分割精度和参数量方面的提高,将DeepLabV3+改进前后的实验结果进行对比.对比结果如表5和图10所示,改进后的算法不仅在分割精度方面相比原来的
DeepLabV3+提升了3.06%,模型参数也减少了57.34%,平均像素精度也有所提升,损失值整体有较大幅降低,有效降低了特征信息损失提高分割精度,更能满足移动端和嵌入式设备等实际场景的需求.
3" 结论
文中提出了一种结合交叉注意力机制的轻量化街景语义分割算法.首先,将原有的DeepLabV3+模型中的特征提取网络替换为更轻量的MobileNetV3,从而显著降低了模型的参数量.其次,在ASPP模块中设计了轻量化密集连接的LD-ASPP模块,该模块通过密集连接卷积层,并将标准空洞卷积替换为深度可分离空洞卷积,同时引入条带池化模块代替全局平均池化,以提升分割精度并降低计算复杂度,从而提高训练效率.最后,在ASPP模块后加入CCA注意力机制模块,增强模型对全局上下文的感知,使得模型在进行像素级别预测时能够更全面地考虑整体图像的信息.实验表明,文中算法在Cityscapes城市街景数据集上的mIoU达到74.02%,模型参数量仅为2.18Mb,训练时间减少了17.92%.通过对比实验与消融实验,优化后的模型在保证分割精度的同时,降低了计算复杂度和参数量,实现了轻量化部署,适合移动端与嵌入式设备.未来工作将侧重于提升模型的实时性,旨在实现视频实时分割,并进一步提高分割精度,使模型同时具备轻量化、高精度和强时效性.
参考文献:
[1]" 魏玮,安小米.物联网和智慧城市数据处理与管理概念体系构建——以 ITU-T 数据处理与管理焦点组标准化项目为例[J].中国科技术语,2021,23(2):70.
[2]" 王晨,杜晨曦,刘瑞军,等.基于RGB-D图像的语义分割方法综述[J].计算机辅助设计与图形学学报,2024,11:21.
[3]" WANG L,WU J,LIU X,et al.Semantic segmentation of large-scale point clouds based on dilated nearest neighbors graph[J].Complex Intellig Syst,2022,8(5):3833.
[4]" ZHAO W,CHEN Y,XIANG S,et al.Image semantic segmentation algorithm based on improved deepLabV3+[J].J System Simul,2023,35(11):2333.
[5]" GAO Z J,HE Y,LI Y.A novel lightweight Swin-unet network for semantic segmentation of COVID-19 lesion in CT images[J].IEEE Access,2022,11:950.
[6]" 高常鑫,徐正泽,吴东岳,等.深度学习实时语义分割综述[J].中国图象图形学报,2024,29(5):1119.
[7]" 陈运成,郑晨,李晶莹,等.离散ADMM 方法下像素与对象基元协同优化的遥感影像无监督语义分割[J].计算机应用研究,2023,40(7):2217.
[8]" 张鑫,姚庆安,赵健,等.全卷积神经网络图像语义分割方法综述[J].计算机工程与应用,2022,58(8):45.
[9]" ZHAO Y,LIU S,HU Z.Dynamically balancing class losses in imbalanced deep learning[J].Electron Lett,2022,58(5):203.
[10]" LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2015:3431.
[11]" RONNEBERGER O,FISCHER P,BROX T.U-net:Convolutional networks for biomedical image segmentation[C]//Medical Image Computing and Computer-assisted Intervention-MICCAI 2015:18th International Conference,Munich,Germany.October 5-9,2015,proceedings,part Ⅲ 18.Berlin:Springer,2015:234.
[12]" 谢娟英,张凯云.SOSNet:一种非对称编码器-解码器结构的非小细胞肺癌CT图像分割模型[J].电子学报,2024,52(03):824.
[13]" ZHAO H,SHI J,QI X,et al.Pyramid scene parsing network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2017:2881.
[14]" CHEN L C,et al.Semantic image segmentation with deep convolutional nets and fully connected CRFs[J].arXiv preprint arXiv,2014,1412:7062.
[15]" CHEN L C,PAPANDREOU G,KOKKINOS I,et al.Deeplab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected crfs[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,40(4):834.
[16]" CHEN L C.Rethinking atrous convolution for semantic image segmentation[J].arXiv preprint arXiv,2017,1706:05587.
[17]" CHEN L C,ZHU Y,PAPANDREOU G,et al.Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European Conference on Computer Vision(ECCV).Piscataway:IEEE,2018:801.
[18]" 姚燕,胡立坤,郭军.基于改进DeepLabv3+网络的轻量级语义分割算法[J].激光与光电子学进展,2022,59(4):200.
[19]" HOWARD A,SANDLER M,CHU G,et al.Searching for mobilenetV3[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.Piscataway:IEEE,2019:1314.
[20]" HUANG Z,WANG X,HUANG L,et al.Ccnet:Criss-cross attention for semantic segmentation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.Piscataway:IEEE,2019:603.
[21]" HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2016:770.
[22]" CHOLLET F.Xception:Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2017:1251.
[23]" 石浩德,侯劲,陈明举,等.改进的DeepLabV3+人脸口罩分割方法[J].无线电工程,2023,53(4):957.
[24]" GAVAI N R,JAKHADE Y A,TRIBHUVAN S A,et al.MobileNets for flower classification using TensorFlow[C]//2017 International Conference on Big Data,IoT and Data Science(BID).Piscataway:IEEE,2017:154.
[25]" SANDLER M,HOWARD A,ZHU M,et al.Mobilenetv2:Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2018:4510.
[26]" 马冬梅,王鹏宇,郭智浩.一种基于注意力机制的轻量级语义分割[J].计算机工程与科学,2024,46(8):1503.
[27]" HU J,SHEN L,SUN G.Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2018:7132.
[28]" HERLAWATI H,ABDURACHMAN E,HERYADI Y,et al.Improving DeepLabV3+ using normalized satellite indices in land-cover segmentation[J].Int J Fuzzy Logic Intellig Syst,2023,23(4):389.
[29]" HOU Q,ZHANG L,CHENG M M,et al.Strip pooling:Rethinking spatial pooling for scene parsing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:4003.
[30]" 张文博,瞿珏,王崴,等.融合多尺度特征的改进Deeplab V3+图像语义分割算法[J].电光与控制,2022,29(11):12.
[31]" POUDEL R P K,LIWICKI S,CIPOLLA R.Fast-scnn:Fast semantic segmentation network[J].arXiv preprint arXiv,2019,1902:04502.
(责任编辑" 孙对兄)
猜你喜欢
精密成形工程(2022年2期)2022-02-22 05:44:14
哈尔滨轴承(2020年4期)2020-03-17 08:13:52
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
智富时代(2019年2期)2019-04-18 07:44:42
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
中国铸造装备与技术(2017年3期)2017-06-21 11:33:34
