
基于特征脸的面部情绪识别研究
2025-02-03 00:00:00路金叶郑方圆王隽滔马宇红
西北师范大学学报(自然科学版) 2025年1期





摘要:人脸面部情绪通常分为开心、伤心、害怕、厌恶、生气、惊讶和正常7种类别.由于面部光照不均匀、情绪变化细微等原因导致现有的人脸情绪识别算法准确率较低,为此本文建立了一种基于特征脸的人脸情绪识别算法.首先应用Viola-Jones算法精准检测和定位面部区域,然后使用Gauss滤波对面部图像降噪后再应用Gamma矫正进行光照均匀化处理,得到精准而清晰的面部图像;其次,应用Haar-like特征对左、右眼睛中心点进行精准定位后,结合人体测量学方法对眉毛、眼睛和嘴巴等情绪器官进行定位与分割,构造特征脸,降低非情绪面部区域的信息冗余;最后,引入经典的Le-Net5卷积神经网络提取特征脸的深层次数字特征进行情绪识别.实验结果表明,该方法可以有效提高人脸面部情绪识别的准确性,在JAFFA公开数据集上的准确率可达90.12%,优于几何特征的53.75%和全脸特征的87.46%,而且性能更为稳定.
关键词:情绪识别;面部特征;特征脸;Le-Net5卷积神经网络
中图分类号:TP 391.42;R742.5""" 文献标志码:A""" 文章编号:1001-988Ⅹ(2025)01-0117-08
DOI:10.16783/j.cnki.nwnuz.2025.01.017
收稿日期:20241019;修改稿收到日期:20241216
基金项目:国家自然科学基金资助项目(51368055)
作者简介:路金叶(1999—),女,甘肃白银人,硕士研究生.主要研究方向为模式识别.
Email:2130899770@qq.com
*通信联系人,男,副编审,博士.主要研究方向为时空预测与模式识别.
Email:mayh@nwnu.edu.cn
Research on facial emotion recognition based on eigenfaces
LU Jin-ye1,ZHENG Fang-yuan1,WANG Jun-tao1,MA Yu-hong1,2
(1.College of Mathematics and Statistics,Northwest Normal University,Lanzhou 730070,Gansu,China;
2.Editorial Department of the University Journal,Northwest Normal University,Lanzhou 730070,Gansu,China)
Abstract:Facial emotions are usually categorized into seven categories:happiness,sadness,fear,disgust,anger,surprise,and normal.Due to uneven facial illumination,subtle emotion changes and other reasons,the accuracy of existing facial emotion recognition algorithms based on eigenfaces is low.Therefore,a new facial emotion recognition algorithm is established in this paper.Firstly,Viola-Jones algorithm was used to accurately detect and locate the facial region,and then Gauss filter was used to reduce the noise of the facial image,and Gamma correction was used to homogenize the illumination to obtain accurate and clear facial images.Secondly,the Haar-like features were used to accurately locate the center points of the left and right eyes,and the anthropometry method was introduced to locate and segment the facial emotion organs such as eyebrows,eyes and mouth,and
then an eigenface is constructed in order to eliminate the information redundancy of non-emotional facial parts.Finally,LeNet-5 convolutional neural network was introduced to extract the deep digital features of eigenfaces for emotion recognition.Experimental results show that the proposed method can effectively improve the accuracy of facial emotion recognition.The accuracy on JAFFA public data set reaches up to 90.12%,which is better than that of geometric feature(53.75%)and full face feature(87.46%),and the performance is more stable.
Key words:emotion recognition;facial feature;eigenface;Le-Net5 convolutional neural network
情绪是人对客观事物的一种心理反应,在不同的情绪状态下,人的心律、血压、呼吸会发生相应的变化.情绪状态直接影响人的表情、语态和行为,人的情绪表现在面部表情、语音表情和姿态表情中,而面部表情是最直接的情绪表达形式.研究发现,面部表情的平均识别准确率比语音表情高约15%,所以大部分的情绪识别研究都是基于面部表情变化开展的.如果机器人能够自动识别人的情绪状态,就能够在人机交互中更好地为人类服务,所以人脸情绪识别技术在社会安全、医疗保健、教育娱乐、智能驾驶等领域有着广泛的应用.
人的情绪一般分为快乐、愤怒、悲哀、恐惧4种基本形式,即喜怒哀惧.20世纪70年代,Ekman[1]提出了6种基本情感分类,分别是开心、伤心、害怕、嫌弃、生气和惊讶.除此之外,在情绪识别研究时通常还会加入面无表情这一类别,以便更好地分析情绪变化导致的面部器官的形态变化,以达到更好的识别效果.
常言道:眉飞色舞、目瞪口呆、咬牙切齿,可见面部的眉毛、眼睛、嘴巴是情绪的主要表达器官,所以在情绪识别研究中,精确捕捉与情绪相关的面部器官细微且独特的几何和纹理变化至关重要.特征脸不仅可以保留几乎全部面部情绪特征,而且可以降低面部非情绪特征的信息干扰,显著提高情绪识别的准确率和有效性,所以,本文建立一种基于特征脸的面部情绪识别方法.首先,应用Viola-Jones算法检测人脸区域,然后使用Gauss滤波对面部图像降噪后再应用Gamma矫正进行光照均匀化处理,得到精准而清晰的面部图像;其次,应用Haar-like特征对左、右眼睛中心点进行精准定位,并结合人体测量学理论对眉毛、眼睛和嘴巴进行定位与分割,构造特征脸;最后,引入Le-Net5卷积神经网络提取特征脸的深层次数字特征进行情绪识别.基于JAFFE数据集的测试结果表明,几何特征的平均识别准确率仅为53.75%,全脸特征为87.46%,而特征脸模型可达90.12%,而且多次实验的方差最小,说明本文方法具有更高的准确性和更强的适应性.
1" 相关研究
情绪识别研究主要分为人脸预处理、面部特征提取和情绪分类模型3个方面.
1.1" 人脸预处理
人脸预处理包括面部检测和图像增强两个方面.面部检测方面,2001年,Viola等[2]基于Haar算子和Adaboost算法设计了一个高效的人脸目标检测器;此后,基于深度学习的人脸检测研究快速发展,RCNN[3,4]、SSD[5-7]、YOLO[8-11]等目标检测算法纷纷涌现.图像增强主要是面部图像的降噪和光照均匀化处理,2003年,Shan等[12]建立了Gamma校正算法,这是一种非线性变换算法,它通过对原始图片进行指数变换,校正图片中的亮度偏差,使图片的亮度更加平滑;2022年,张彩玲等[13]改进了Gamma校正算法,该方法利用光照分量和图像块内中心像素的比值作为当前像素的系数,实现自适应Gamma校正.
1.2" 特征提取
静态图像特征提取技术包括传统几何方法与深度学习方法.传统几何方法通过提取人脸的几何特征,例如人脸特定情绪器官的形状、大小、位置,以及比例关系进行识别,这种方法简单易行,但易受光照、角度等因素的影响;捕捉图像灰度在空间的分布特征描述人脸的结构信息能够有效刻画人脸的纹理特征,但计算量大,且对人脸姿态和表情变化的适应性较差.深度学习方法可以自动提取人脸的高级特征,包括纹理信息、结构信息、表情变化等,所以基于深度学习的特征提取方法具有很强的鲁棒性和适应性,能够处理复杂的人脸图像,已经成为当前人脸面部特征提取的主要方法.2000年,Cootes[14]建立了主动形状模型(ASM),并训练了一种基于统计模型的特征提取方法;2011年,Bag等[15]建立了一种基于主成分分析和最小距离的特征提取技术;2019年,Hassan等[16]建立了一种深度信念网络,可以忽略图像的面部结构,从而精确提取图像的面部特征;2020年,Gupta等[17]提出了一种基于深度卷积神经网络的面部特征自动提取方法.
1.3" 情绪识别模型
当前,人脸情绪识别研究正在从基于面部构形[18-20]的几何判定方法向基于面部纹理[21]的深度学习方法发展.Kwak等[22]结合卷积神经网络和多层感知器(MLP)进行人脸检测与情绪识别,在特定数据上的准确率可达97.9%.Hung等[23]先使用 MTCNN检测视频中包含的对象面孔,再通过残差网络ResNet50提取视频序列的面部变化作为识别特征,然后使用LSTM -WAVE网络与SVM等多个机器学习模型对特征进行训练,最后融合多模型训练结果得到最终决策,其方法在数据集Mase-CaR上的基线准确率为50%.Shivam等[24]融合光流和Mel光谱图特征,经多特征、多模态融合进行群体情绪识别研究,取得了60%的准确率.Cao等[25]基于自监督学习和特征融合技巧进行情绪识别,在WESAD数据集上进行情绪四分类实验取得了92.66%的准确率.Aghabeigi等[26]结合深度卷积神经网络和遗传算法(GA),建立了GA-Dense-FaceliveNet面部情绪识别框架,在CK+、JAFFE和KDEF数据集上的准确度分别为99.96%,98.92%和99.17%.总之,深度学习方法在人脸情绪识别中准确率较高,而卷积神经网络因其卓越的图像处理能力已广泛应用于人脸面部情绪识别研究.
2" 人脸预处理
2.1" 面部检测
提取人脸面部情绪特征首先必须精准定位面部区域.在人脸检测中,Viola-Jones算法[2]是一种经典的目标检测算法,该算法使用的特征来自图像特定矩形区域的像素,并且它对水平或垂直线条具有高度敏感性.Viola-Jones算法的实现一般分为四步:利用Haar-like特征描述人脸特征;建立积分图像,利用该图像快速获取几种不同的矩形特征;利用Adaboost算法进行训练;建立级联分类器进行检测.
2.1.1" Haar-like特征" Haar-like特征源自小波分析中的Haar小波.人脸通常存在一些基本共性,比如眼睛区域比脸颊区域暗很多,鼻子属于脸部的高光区域,鼻子比周围的脸颊要亮很多,一张正脸图像,眼睛、眉毛、鼻子、嘴巴的相对位置遵循一定的规律等.Haar-like特征考虑某一特定位置相邻的矩形区域,把每个矩形区域的像素相加然后再相减,这个特征可以用来区分人脸与非人脸.当然,一个特征的区分度是很有限的,为了增加区分度,可以对多个矩形特征计算得到区分度更大的特征值.
2.1.2" 积分图像与Haar-like特征计算
计算Haar-like特征需要对矩形区域的所有像素求和,一个图像可形成的矩形区域有大有小,为了减少计算负担,该算法用到了一种非常巧妙的数据结构,称为积分图像,其原理是:图像中任何一点的积分图像值等于位于该点左上角的所有像素之和,表达式为
F(x0,y0 )=∑x≤x0∑y≤y0I(x,y),
其中,I(x,y)表示图像中(x,y)处的像素值,并且积分图像还满足下列性质:
F(x,y)=I(x,y)+F(x-1,y)+
F(x,y-1)-F(x-1,y-1).
如图1,矩形区域ABCD的像素值定义为
FABCD=FC-FD-FB+FA.
2.1.3" 级联检测器
通俗地说,Haar-like特征相当于弱分类器,Adaboost算法通过将弱分类器线性组合增强为一个强分类器,其形式是至少有两个叶子的决策树,通过选取恰当的特征阈值对人脸进行筛选.
2.2" 人脸图像增强
人脸图像通常存在摄像机质量、光照不均和环境干扰引起的噪声,
同时人脸的姿态、佩戴物、装饰物等,均对人脸监测和特征提取具有很大的负面影响,通过图像降噪与人脸归一化处理,可以有效降低噪声,提高图像清晰度[27].
2.2.1" 高斯滤波
高斯滤波[28]是一种线性平滑滤波技术,主要用于消除图像中的高斯噪声.高斯滤波的具体操作是:用一个模板(或称卷积、 掩模)扫描图像中的每个像素点,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的灰度值,通俗地说,高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值由其邻域内所有点的像素值经过加权平均得到.高斯滤波将中心点的权值加大,远离中心点的权值减小,在此基础上计算每个像素的加权和.高斯滤波使图像更平滑,并且对边缘有很好的保真作用.
2.2.2" Gamma矫正
人脸光照处理的初衷是在不损失图像内容的前提下,保持图像在各种环境下的光照一致性.常用的Gabor变换虽然能保持较好的光照一致性,但会造成部分低频信息丢失,离散余弦变换不能很好地适应环境光的变化,而Gamma矫正不仅可以调整图像的光照和对比度,而且在视觉上更加舒适自然.
Gamma矫正的核心思想是使用幂函数对图像进行非线性调整[12,13],调整图像的光照强度与对比度.Gamma矫正的公式为
Iout=Iinγ,
其中,Iout为矫正后的图像;Iin为输入图像;γ为矫正指数.γ的值根据图像需求进行调节,γgt;1时,图像的暗部细节被扩展而亮部细节被压缩,整体图像变暗;γlt;1时,图像的亮部细节被扩展而暗部细节被压缩,整体图像变亮.令γ=0.45,人脸图像预处理的流程与效果见图2.
3" 面部特征提取
静态图像面部情绪特征分为外观特征和几何特征.外观特征包括Gabor特征、LBP特征、HOG特征等,这些特征包含人脸的细节信息,但是计算复杂且成本较高;几何特征包括人脸关键点位置、关键点连线的长度、两条连线长度的比例及夹角等,提取几何特征通常使用模板匹配法,训练需要较高的技术要求,且特征很难精确提取.
人体测量学是人类学的一个分支,主要研究人体测量和观察方法.2008年,Abu等[29]创建了人脸测量模型,并检验了来自世界不同地区的150多人的300张面部图像.该模型基于眼睛中心位置定位面部元素,所以要想使用人体测量模型,首先要准确定位眼睛中心,一般所说的眼中心为瞳孔中心,但是这里所的眼中心为眼睛整体部位的中心.
3.1" 特征面
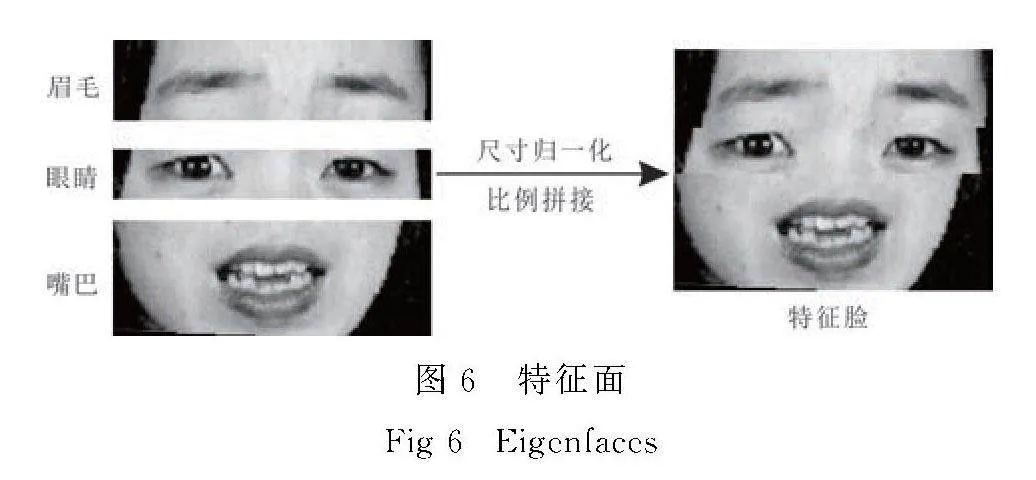
特征面是眉毛、眼睛、嘴巴等情绪表达器官按照一定布局和比例关系拼接而成面部图像,它能够以较少的图像块保留几乎全部的情绪特征,并且降低光照和姿态等噪声的干扰,所以特征脸不仅可以降低计算的复杂度,而且能够提高人脸识别的准确性.特征面的构造流程如图3所示.
3.1.1" 定位眼睛中心
使用人体测量学理论首先要精确定位左、右眼睛的中心.2010年,Timm等[30]提出了一种基于梯度幅值与梯度阈值的眼中心定位法,利用Haar-like特征在眼睛没有完全打开时也能够检测到眼睛并且抵抗多变的光照条件.首先利用级联检测器大致提取眼睛部位,然后使用高斯滤波器对左、右眼图像分别进行滤波处理,降低图像噪声,减少细节和纹理的影响,同时增强眼睛中心与周围区域的对比度,使眼睛中心的特征更为突出.滤波后计算图像的加权值与图像水平方向与垂直方向的梯度值,根据梯度计算梯度阈值,梯度阈值是图像处理中用于区分图像或数据特征的一个重要参数.由于梯度可以反映图像灰度的变化率,对于眼睛中心这种具有明显边缘特征的区域,越靠近中心,就会有更多梯度方向的连线交于那个点,所以眼睛中心就是梯度方向上直线相交最多的点.通过相同流程,就可以在脸部区域左侧和右侧分别确定左、右眼睛中心.
3.1.2" 定位情绪器官中心
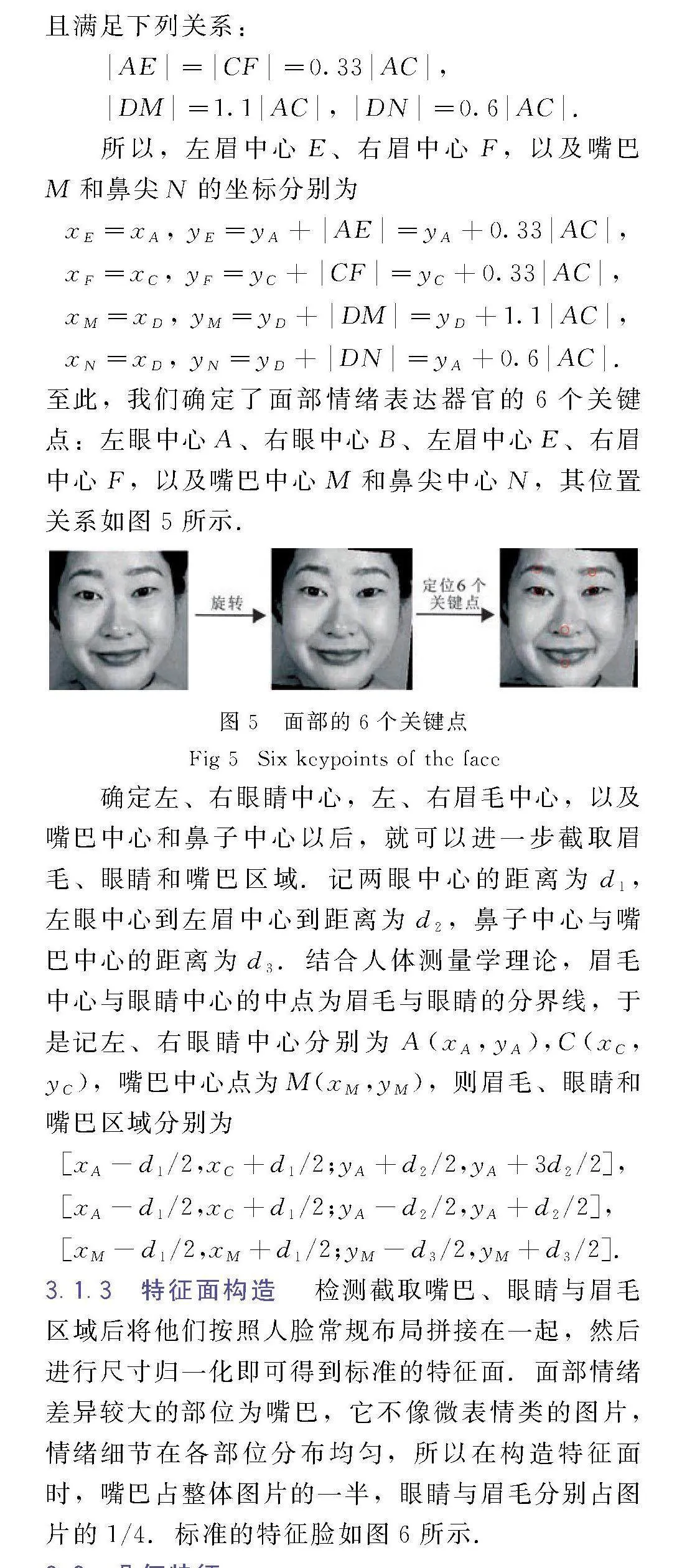
左、右眼睛中心定位之后,需要对图片进行旋转消除面部倾斜问题.端正人脸的左、右眼睛中心总是水平的,所以可以根据两眼中心的坐标确定面部需要上下旋转的角度.
记左、右眼睛中心分别为A(xA,xA),B(xB,yB,因为标准的脸部两眼保持在同一水平线上,所以A点保持不动,而B点则需要顺时针旋转,旋转角α满足
tanα=yB-yAxB-xA,
于是右眼中心B经过旋转后的位置为C,则C点的坐标满足
xC=xA+(xB-xA)2+(yB-yA)2,yC=yA.
于是两眼中心的距离
AC=xC-xA=(xB-xA)2+(yB-yA)2,
两眼水平连线的中点D的坐标为
xD=xA+AC/2,yD=yA.
根据人体测量学理论[31,32],左眉中心E(右眉中心F)与左眼中心A(右眼中心C)保持在同一垂直线上,嘴巴M和鼻尖N与两眼的中点D保持在同一垂直线上,见图4.
且满足下列关系:
AE=CF=0.33AC,
DM=1.1AC, DN=0.6AC.
所以,左眉中心E、右眉中心F,以及嘴巴M和鼻尖N的坐标分别为
xE=xA, yE=yA+AE=yA+0.33AC,
xF=xC, yF=yC+CF=yC+0.33AC,
xM=xD, yM=yD+DM=yD+1.1AC,
xN=xD, yN=yD+DN=yA+0.6AC.
至此,我们确定了面部情绪表达器官的6个关键点:左眼中心A、右眼中心B、左眉中心E、右眉中心F,以及嘴巴中心M和鼻尖中心N,其位置关系如图5所示.
确定左、右眼睛中心,左、右眉毛中心,以及嘴巴中心和鼻子中心以后,就可以进一步截取眉毛、眼睛和嘴巴区域.记两眼中心的距离为d1,左眼中心到左眉中心到距离为d2,鼻子中心与嘴巴中心的距离为d3.结合人体测量学理论,眉毛中心与眼睛中心的中点为眉毛与眼睛的分界线,于是记左、右眼睛中心分别为A(xA,yA),C(xC,yC),嘴巴中心点为M(xM,yM),则眉毛、眼睛和嘴巴区域分别为
[xA-d1/2,xC+d1/2;yA+d2/2,yA+3d2/2],
[xA-d1/2,xC+d1/2;yA-d2/2,yA+d2/2],
[xM-d1/2,xM+d1/2;yM-d3/2,yM+d3/2].
3.1.3" 特征面构造
检测截取嘴巴、眼睛与眉毛区域后将他们按照人脸常规布局拼接在一起,然后进行尺寸归一化即可得到标准的特征面.面部情绪差异较大的部位为嘴巴,它不像微表情类的图片,情绪细节在各部位分布均匀,所以在构造特征面时,嘴巴占整体图片的一半,眼睛与眉毛分别占图片的1/4.标准的特征脸如图6所示.
3.2" 几何特征
眼睛的大小,瞳孔的扩张或收缩,眉毛的上扬、下降或皱起,嘴巴的张开及嘴角的上扬或下拉,情绪特征部位的比例和结构,脸型的线条风格(圆形、椭圆形或长形、菱形等),以及比例关系
(如“三庭五眼”等标准)等几何特征,都在情绪识别中扮演着重要角色.几何特征根据面部情绪部位的诸多关键点,刻画情绪器官的位置、大小、形状及比例关系,以表征人的情绪变化.基于几何特征的人脸情绪识别方法具有存储量小和对光照不敏感的特点,但该方法对图像的质量要求很高,对于特征点的定位要求非常准确,侧向人脸或装饰物遮挡会严重影响情绪识别的准确率.复合多重投影法[33]就是反复利用人脸在水平和垂直方向投影量的变化,分析定位诸多关键点来确定眼睛、眉毛、嘴巴的准确位置,通过测量这些关键点之间的相对距离和比例关系,得到描述人脸情绪信息的特征向量.文献[33]通过积分投影法确定了22个面部关键边缘点,以左、右眉毛宽高比,左、右眼睛宽高比,嘴巴宽高比,以及它们与固定长、固定宽的比例作为几何特征,刻画眉毛、眼睛、嘴巴等器官的情绪变化.
3.3" 全局特征
人脸面部由于情绪波动产生的纹理褶皱,以及明暗度变化等特征的综合分析有助于准确解读个体的情绪状态.基于人脸图像全局特征的情绪识别方法仅需充分利用人脸图像本身的灰度信息,通过卷积神经网络(CNN)提取全脸的深度特征,不需要精准提取人脸情绪部位的具体信息,就可以获得较好的识别效果.
4" 情绪识别模型
近年来,基于机器学习的模式识别研究取得了很大发展[34,35],而卷积神经网络(CNN)在提取面部表情特征方面则具有显著优势,这得益于其独特的网络结构和功能.CNN是一种深度学习模型,特别适用于处理图像数据,其核心结构包括卷积层、池化层和全连接层.LeNet-5[36]是一种经典的CNN,已广泛用于数字图像的特征提取、筛选和分类,并展现出了卓越的性能.LeNet-5通过卷积层和池化层的交替使用,能够在保持图像空间结构信息的同时减少参数数量,提高模型的泛化能力.LeNet-5共有7层,由卷积层和最大池化层交替构成,卷积核对原始图像卷积的结果加上相应的阈值,经过激活函数处理后输出,形成特征映射.每个特征映射共享权重和阈值,以减少训练开销.池化层进行亚抽样,减少数据量的同时保存有用信息,更高层则是全连接和高斯连接.
5" 实验与分析
5.1" 数据集
实验在JAFFE数据集[37]上进行.JAFFE数据集是一个用于表情识别的研究数据集,该数据集包含了10位日本女性表达者展示的7种面部表情(6种基本面部表情加上中性表情),6种基本面部表情分别是愤怒、厌恶、恐惧、快乐、哀伤、惊讶,总共有212张情绪图片,每张图片都有60位日本观众对6个面部表情的平均语义评分,分辨率为256×256,每个人的面部特征在不同情绪状态下会发生变化,每张图片标有对应的情绪标签.JAFFE数据集提供了标准和可量化的面部表情,它在计算机视觉领域的情感计算、表情识别和人机交互等方面有着重要的应用价值,已广泛用于测试或评估表情识别算法的可靠性和稳定性.
5.2" 实验设置
计算机情绪识别建立在图像处理和逻辑运算基础上,情绪的特征提取和机器学习通过Matlab 编程实现,处理器基本配置为Intel i7处理器或 AMDx86-64双核处理器,内存16GB,显卡支持 OpenGL3.3并具有1GBGPU内存,所以当前主流的台式电脑或笔记本电脑均满足系统运行要求.
实验首先对图片进行重排,随机抽取80%的图片作为训练集,20%的图片作为测试集.初始学习速率为0.001,最小学习批次30,最大迭代次数250;编程使用Matlab 2018b,CPU配置为Intel(R)Core(TM)i7-4702MQCPU@2.20GHz.
5.3" 性能分析
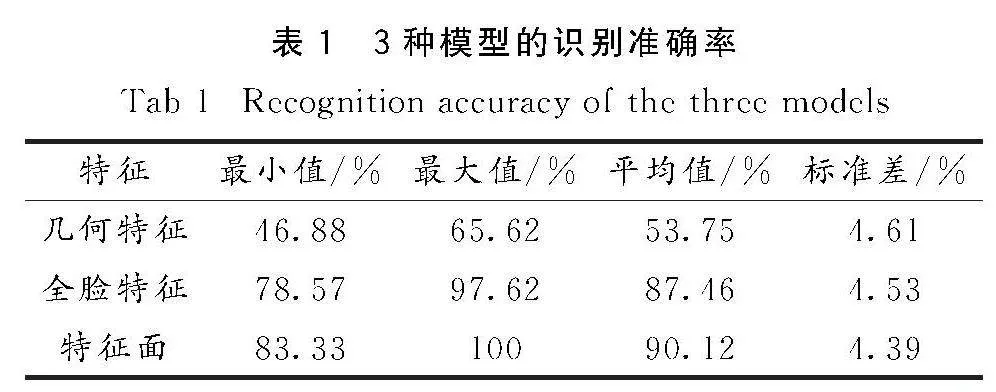
本文使用情绪识别的准确率衡量模型的性能,使用混淆矩阵[38]呈现不同类别情绪识别的差异,在混淆矩阵中,横坐标为预测标签,纵坐标为真实标签.从实验得到的混淆矩阵可以看出,全脸模型在生气、恐惧与悲伤这3种表情的识别中都出现了错误,且都错误识别为厌恶,准确率分别为83.3%、83.3%和66.7%;而特征面模型仅将厌恶错误识别为悲伤,识别准确率为66.7%,其余表情的识别准确率都为100%,所以特征面模型的识别性能更好.表1给出了30次独立实验得到3种特征模型的识别准确率.可以看出,特征面模型平均识别准确率为90.12%,全局特征模型为87.46%,而几何特征模型仅为53.75%,特征面模型性能最为优异.特别地,特征面模型30次独立实验准确率的方差也最小,所以性能更稳定.
需要说明的是,几何特征需要定位关键点坐标,这在实际操作中需要克服人脸的特异性,并不适应于所有图像,而且不同感官需要不同的处理方式,这大大增加了模型的实现难度,极易产生定位不精准等问题,从而影响模型的识别性能;全局特征模型既不需要计算图像的横向和纵向直方图,也不需要面部器官的关键点和几何特征,但对图像质量要求高,很容易受面部装饰物或身体姿态的影响.特征面模型仅需要借助6个关键点和人体测量学技术就可以构造特征面,它不仅保留了全部面部情绪信息,继承了感官位置之间的关联性,而且抑制了与情绪关联性不强的面部冗余信息的干扰.
6" 结论
总的来说,本文特征面模型不仅操作简单,比几何特征模型和全局特征模型情绪识别性能更好,而且特征面的构造有效消除了非情绪信息的干扰,计算效率更高,在JAFFE公开数据集上的平均识别准确率可达90.12%.
参考文献:
[1]" EKMAN P.Basic emotions[J].Handbook Cognition Emotion,1999,98(45-60):16.
[2]" VIOLA P,JONES M.Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Los Alamitos,California:IEEE Computer Society,2001:1.
[3]" GIRSHICK R.Fast r-cnn[C]//Proceeding of the 2015 IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2015:1440.
[4]" REN S,HE K,GIRSHICK R,et al.Faster RCNN:Towards real-time object detection with region proposal networks[J].IEEE Transac Pattern Analy Mach Intel,2017,39(6):1137.
[5]" WEI L,DRAGOMIR A,DUMITRU E,et al.SSD:Single shot multibox detector[C]//European Conference on Computer Vision.Cham:Springer,2016:21.
[6]" FU C Y,LIU W,RANGA A,et al.DSSD:Deconvolutional single shot detector[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Washington:IEEE,2017:958.
[7]" LI Z,ZHOU F.FSSD:Feature fusion single shot multibox detector[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:752.
[8]" REDMON J,DIVVALA S K,GIRSHICK R,et al.You only look once:Unified real-time object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2016:779.
[9]" REDMON J,FARHADI A.YoLo9000:Better,faster,stronger[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:6517.
[10]" REDMON J,FARHADI A.Yolov3:An incremental improvement[J].arXiv preprint arXiv:1804.02767,2018.
[11]" BOCHKOVSKIY A,WANG C Y,LIAO H Y.Yolov4:Optimal speed and accuracy of object detection[J].arXiv preprint arXiv,2004.10934,2020.
[12]" SHAN S,GAO W,CAO B,et al.Illumination normalization for robust face recognition against varying lighting conditions[C]//Analysis and Modeling of Faces and Gestures.Piscateway,New Jersey:IEEE,2003:257.
[13]"" 张彩玲.人脸识别中降低光照角度影响的预处理方法研究[D].重庆:重庆邮电大学,2022.
[14]" COOTES T.An introduction to active shape models[A]//BALDOCK R,GRAHAM J.Image Processing and Analysis,Oxford:Oxford University,2000:223.
[15]" BAG S,SANYAL G.An efficient face recognition approach using PCA and minimum distance classifier[C]//2011 International Conference on Image Information Processing,Piscataway.New Jersey:IEEE,2011.
[16]"" HASSAN M M,ALAM M G R,UDDIN M Z,et al.Human emotion recognition using deep belief network architecture[J].Inform Fusion,2019,51:10.
[17]" GUPTA A,ARUNACHALAM S,BALAKRISHNAN R.Deep self-attention network for facial emotion recognition[J].Pro Compu Sci,2020,171:1527.
[18]" ASTHANA A,SARAGIH J,WAGNER M,et al.Evaluating AAM fitting methods for facial expression recognition[A]//2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops,2009:1.
[19]" SUNG J,KIM D.Real-time facial expression recognition using STAAM and layered GDA classifiers[J].Image Vision Comput,2009,27(9):1313.
[20]" TSAI H H,CHANG Y C.Facial expression recognition using a combination of multiple facial features and support vector machine[J].Soft Comput,2018,22(13):4389.
[21]" ISLAM R,AHUJA K,KARMAKAR S,et al.SenTion:A framework for sensing facial expressions[J].arXivpreprint,arXiv:1608.04489,2016.
[22]" KWAK T,KIM M.Mobile APP classification method using machine learning based user emotion recognition[A]//ICICM18:Proceedings of the 8th International Conference on Information Communication and Management,2018.DOI:10.1145/3268891.3268909.
[23]" HUNG H M,KIM H S,YANG H J,et al.Multiple models using temporal feature learning for emotion recognition[A]//The 9th International Conference on Smart Media and Applications,2020.DOI:10.1145/3426020.3426122.
[24]" SHIVAM S,SAANDEEP A,SIDHAPUR L,et al.Recognizing emotion in the wild using multimodal data[A]//ICMI20:Proceedings of the 2020 International Conference on Multimodal Interaction,2020.
[25]" CAO X,SUN M.An emotion recognition method based on feature fusion and self-supervised learning[A]//2nd Asia Conference on Algorithms,Computing and Machine Learning(CACML),2023.
[26]" AGHABEIGI F,NAZARI S,ERAGHI N O.An optimized facial emotion recognition architecture based on a deep convolutional neural network and genetic algorithm[J].Signal,Image Video P,2024,18(2):1119.
[27]" 张蕾,马慧芳.自适应边缘相似度非局部均值图像去噪方法[J].西北师范大学学报(自然科学版),2021,57(6):50.
[28]" 张灏,王素珍,郑宇,等.一种组合GAUSS-filter、SOBEL、NMS、OTSU 4种算法的图像边缘检测的FPGA实现[J].液晶与显示,2020,35(3):250.
[29]" SOHAIL A S M,BHATTACHARYA P.Detection of facial feature points using anthropometric face model[J].Signal P Image Enhance Multimed P,2008,31:189.
[30]" TIMM F,BARTH E.Accurate eye centre localization by means of gradients[A]//International Conference on Computer Vision Theory and Applications(VISAPP 2010),2011,11:125.
[31]" SOHAIL A S M,BHATTACHARYA B.Detection of facial feature points using anthropometric face model[J].Signal P Image Enhance Multimed P,2008,31:189.
[32]" JULIA J,RAFA K,KRZYSZTOF M.Anthropometric" facial emotion recognition[J].Lect Notes Compu Sci,2009,5611(1):188.
[33]" SOBOTAKA K,PITAS I.A novel method for automatic face segmentation,face feature extraction and tracking[J].Signal P:Image Commun,1998,12(3):263.
[34]" 马宇红,王小小,薛生倩,等.基于绕口令的帕金森病计算机辅助诊断系统的构建[J].武汉科技大学学报,2024,47(4):312.
[35]" 张蕾,张正军,郭康惠,等.甘肃道地中药黄芪饮片质量等级分类算法研究[J].西北师范大学学报(自然科学版),2023,59(5):58.
[36]" LECVN Y,BOTTOV L,BENGIO Y,et al.Gradient-baled learning applied to document recognition[J].P IEEE,1998,86(11):2778.
[37]"" LEE H S,KANG B Y.Continuous emotion estimation of facial expressions on JAFFE and CK+ datasets for human-robot interaction[J].Inte Serv Robot,2020,13(1):1.
[38]" MOHAMMADREZA H,THOMAS E D,REZA S.MLCM:Multi-label confusion matrix[J].IEEE Access,2022,10:19083.
(责任编辑" 马宇鸿)
