
基于生成式投影插值的双域CBCT稀疏角度重建方法
2024-11-11 00:00:00廖静怡彭声旺王永波边兆英
南方医科大学学报 2024年10期


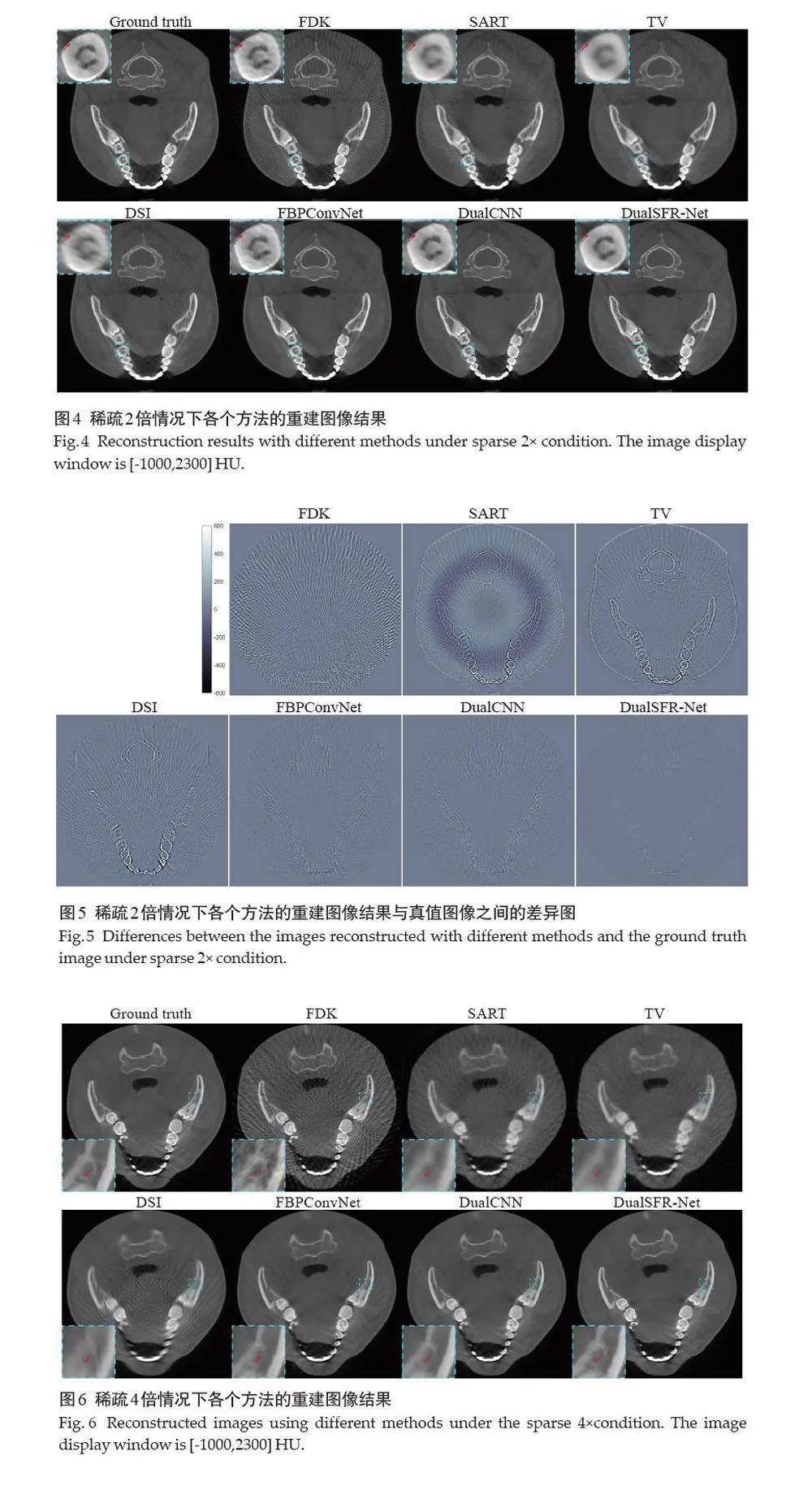


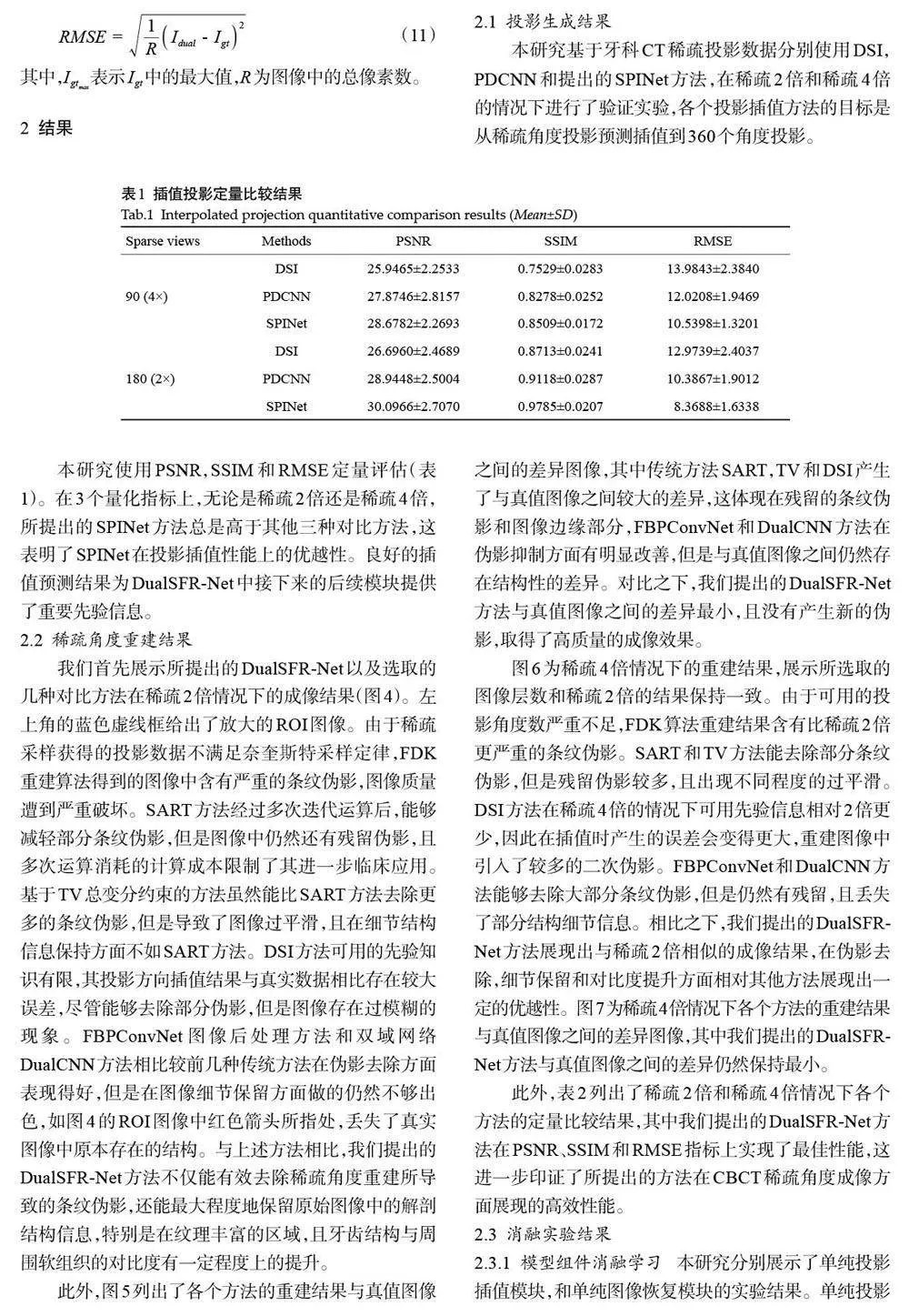
摘要:目的 为了解决稀疏角度CBCT 重建的图像伪影问题,本文提出了一种基于生成式投影插值的双域CBCT 重建框架(DualSFR-Net)。方法 提出的DualSFR-Net方法主要包含3个模块:生成式投影插值模块、域转换模块和图像恢复模块。生成式投影插值模块包括一个基于生成对抗网络的稀疏投影插值网络(SPINet)和一个全角度投影恢复网络(FPRNet)。其中,SPINet针对稀疏角度投影数据进行投影插值合成全角度投影数据,FPRNet则是对合成全角度投影数据进一步修复。域转换模块引入重建和前投影算子实现双域网络的前向和梯度回传过程。图像恢复模块包含一个图像恢复网络FIRNet,对域转换后的图像进行微调以去除残留的伪影和噪声。结果 在牙科CT数据集上进行的验证实验结果显示,本研究提出的DualSFR-Net在稀疏采样协议下能够重建出高质量的CBCT图像;定量上,所提出DualSFR-Net方法在稀疏2 倍和4 倍协议下在PSNR指标上相对于现有同类最优方法分别提高了0.6615和0.7658,在SSIM指标上分别提高了0.0053和0.0134。结论 本研究提出的基于生成式投影插值的双域CBCT稀疏角度重建方法DualSFR-Net能够有效地去除条纹伪影,改善图像质量,成功实现了对CBCT稀疏角度双域成像网络的高效联合训练。
关键词:CBCT;稀疏角度成像;双域网络
锥束计算机断层扫描系统(CBCT)在牙科[1]、放疗[2]、介入成像[3]等临床领域获得广泛应用。然而,CBCT扫描对人体带来的X射线辐射损伤风险是不容忽视的重点问题,本着最低合理可行(ALARP)[4]的原则,现代CBCT需要朝着更低辐射剂量的方向发展,以进一步降低患者的辐射损伤风险。现有主流的低剂量CBCT扫描方式有两种:低管电流、稀疏角度扫描。低管电流扫描是通过降低X光子照射量来减少辐射剂量。但是,此类方法受到硬件的限制,当X光子照射量想进一步降低时,可能会发生“光子饥饿”效应,即X光子量已经降低到无法穿透物体或者穿过的X光子量极低,导致探测器不能探测到有效、充足的X光信号,且易受到量子噪声与系统电子噪声影响,无法对测量信号进行精确的物理建模。稀疏角度扫描不仅可以减少患者接受射线照射的次数,而且可以加快数据采集的速度,因此在CBCT成像中被广泛利用。
在CBCT图像重建中,主流的重建算法是FDK重建算法[5],而FDK算法对测量数据的完备性有较高的要求,稀疏角度扫描难以支撑其重建出高质量的图像,主要原因是所获得的投影数据不满足奈奎斯特采样定律,此时利用欠采样的投影数据进行图像重建则变成了CT成像领域中不适定的逆问题,重建得到的图像存在条纹伪影,边缘不清晰,细节纹理信息丢失以及强噪声等问题,严重影响临床医生对病情的诊断。利用稀疏角度采样的投影数据,设计一种有效的CBCT稀疏角度重建方法具有非常重要的临床价值。
针对稀疏角度CT成像问题,研究人员提出的解决方案大致可以分为:⑴投影插值方法:利用深度网络合成缺少的投影数据,再利用FBP方法进行图像重建[6, 7],然而投影插值方法很难估计出接近真实分布的完整投影,容易在图像中引入二次伪影,且图像分辨率难以保证;⑵图像后处理方法:学习从稀疏角度CBCT图像到全角度CBCT图像的映射[8-12],然而图像域后处理方法没有利用投影域中丰富的先验信息,难以恢复解析重建过程中丢失的图像结构信息,且难以对真实伪影分布进行准确建模;⑶迭代展开方法利用深度学习技术将传统的迭代重建模型展开成可学习的网络,通过端对端训练,获得优秀的重建性能[13-15],然而迭代展开方法不可避免地需要多次引入前反投影操作,尽管结合CNN的迭代重建模型取代了正则项与平衡参数的更新过程,降低了人工选择参数与正则化项的实验成本,但是其迭代过程中依然存在非常高的复杂度与计算成本,尤其是三维的CBCT成像系统;⑷投影-图像双域学习方法结合了投影域和图像域的优点,同时避免了迭代重建方法的高昂计算成本[16-21]。通过深度学习方法设计双域网络,在双域之间同步进行优化与处理,能充分发挥图像先验知识的作用,实现了数据保真性的双重约束,这种方法在恢复细微结构和减少伪影方面相较于单域处理能够展现出更出色的性能。既往研究者们在CBCT双域成像问题上做过一些探索并且取得了令人鼓舞的性能,然而这些工作中的域转换方式是不可微的[22, 23],投影域和图像域的数据分离处理,通过级联方式构成了“伪”双域网络,因而在深度学习框架中无法通过标准的反向传播算法直接优化双域子网络的参数。在主流的CT域转换策略中,学习型域转换需要利用全连接层来端到端地学习投影数据到图像数据的参数映射,尽管能够在平行束和扇形束等CT模态成像问题上实现精准域转换[20, 21],但是对于CBCT而言,其投影域和图像域都是3D规格,重建过程中的参数映射需要庞大的计算资源支持,因此并不适合CBCT双域网络。而传统型域转换通过引入前反投影算子来完成双域网络的前向和梯度回传过程,从而规避掉学习型域转换所需的庞大的参数计算图存储[24-26]。构建一种可微分的域转换模块,更适合于设计CBCT双域网络,其参数学习集中在更新投影域和图像域子网络中。
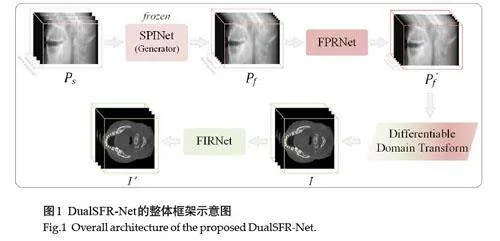
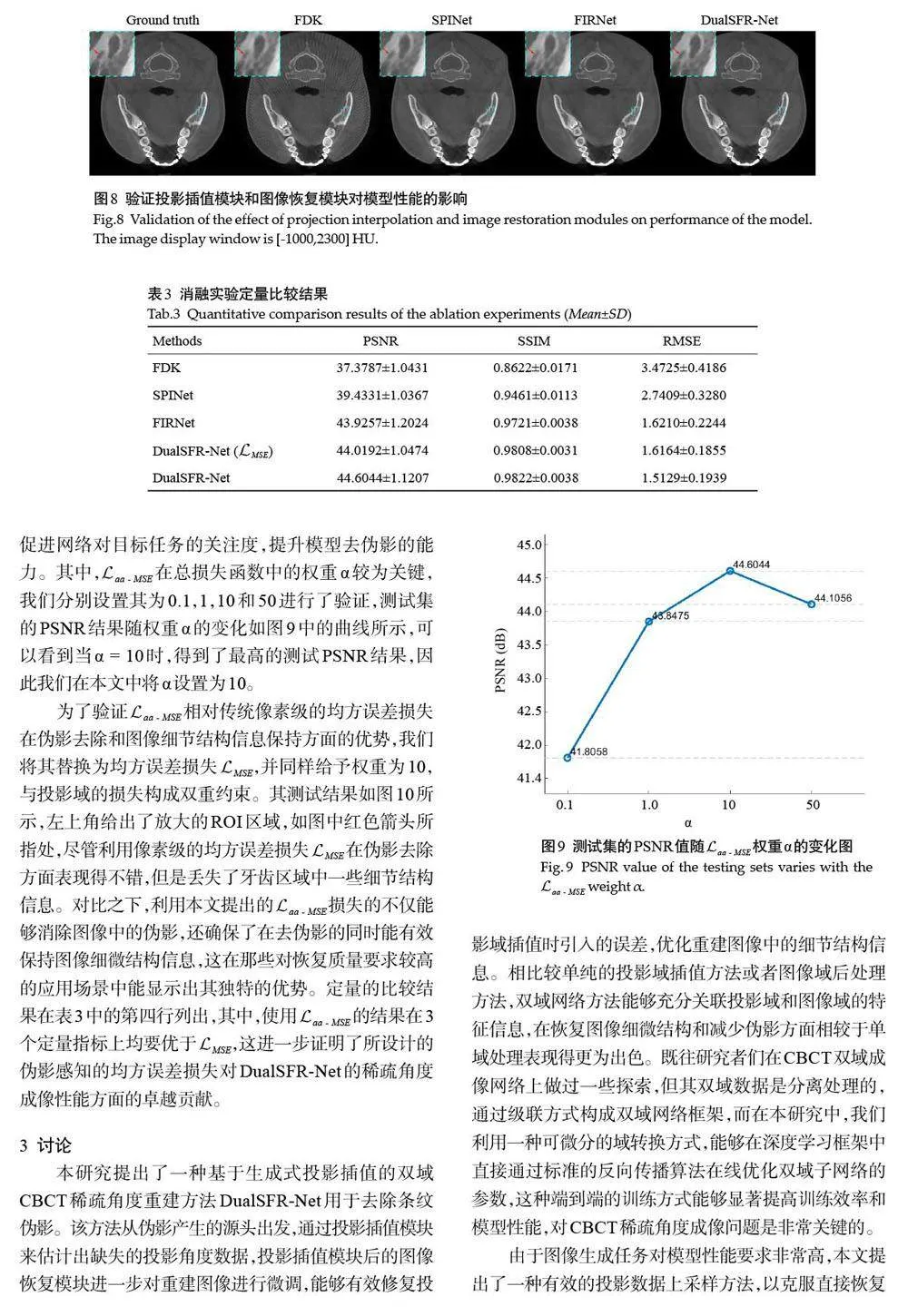
鉴于此,我们提出了一种基于生成式投影插值的双域CBCT稀疏角度重建方法DualSFR-Net。DualSFRNet包括3个模块,分别是投影插值模块,域转换模块和图像恢复模块。具体地,投影插值模块包括一个基于生成对抗网络的稀疏投影插值网络SPINet和一个全角度投影恢复网络FPRNet,稀疏投影插值网络SPINet针对稀疏角度投影数据进行投影插值,获得全角度下的完备投影数据,全角度投影恢复网络FPRNet针对完备角度投影数据进行整体恢复,以消除插值后相邻角度投影数据间的冗余差异,提高插值数据的真实性;在域转换模块中,利用传统型可微分域转换模块来实现双域联动;图像恢复模块包含一个图像恢复网络FIRNet,对域转换后的图像进行微调以去除残留的伪影和噪声。此外,考虑到稀疏成像形成的条纹伪影在空间分布中的不均匀性,我们设计了一种伪影感知的损失函数,使网络能够重点关注条纹伪影较重的区域,从而更加高效地进行稀疏角度成像。
1 材料和方法
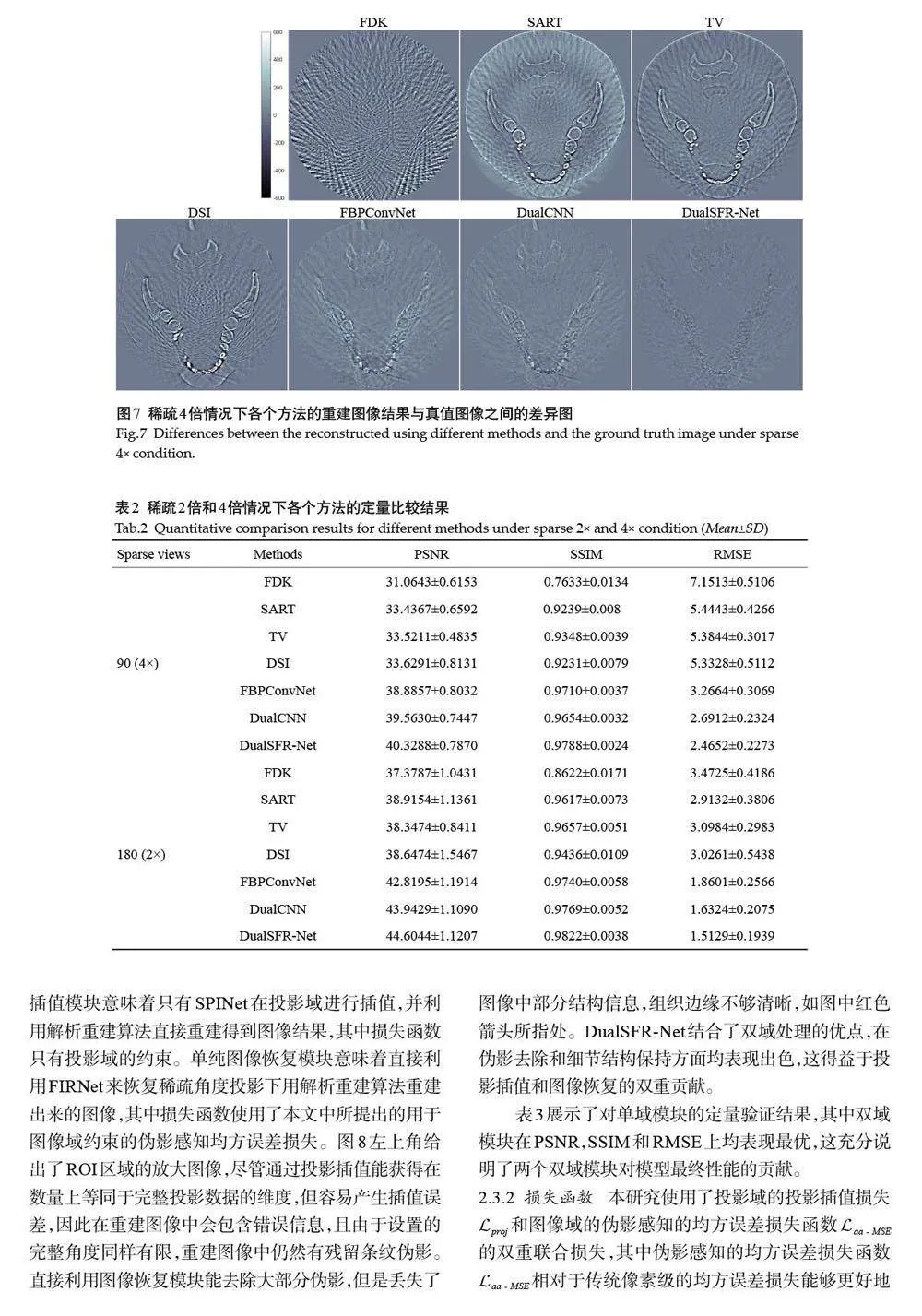
1.1 总体框架
本研究所提出的双域CBCT 稀疏角度重建框架DualSFR-Net的结构由投影插值模块、域转换模块和图像恢复模块组成(图1),其中投影插值模块基于稀疏采样的投影数据来插值出完整角度下的投影数据;域转换模块用可微分域转换方法实现双域联动,保证了全扫描区域图像的回传梯度的精度;图像恢复模块对域转换后的重建图像进一步微调以去除残留的伪影和噪声。我们将详细展开描述各个模块。
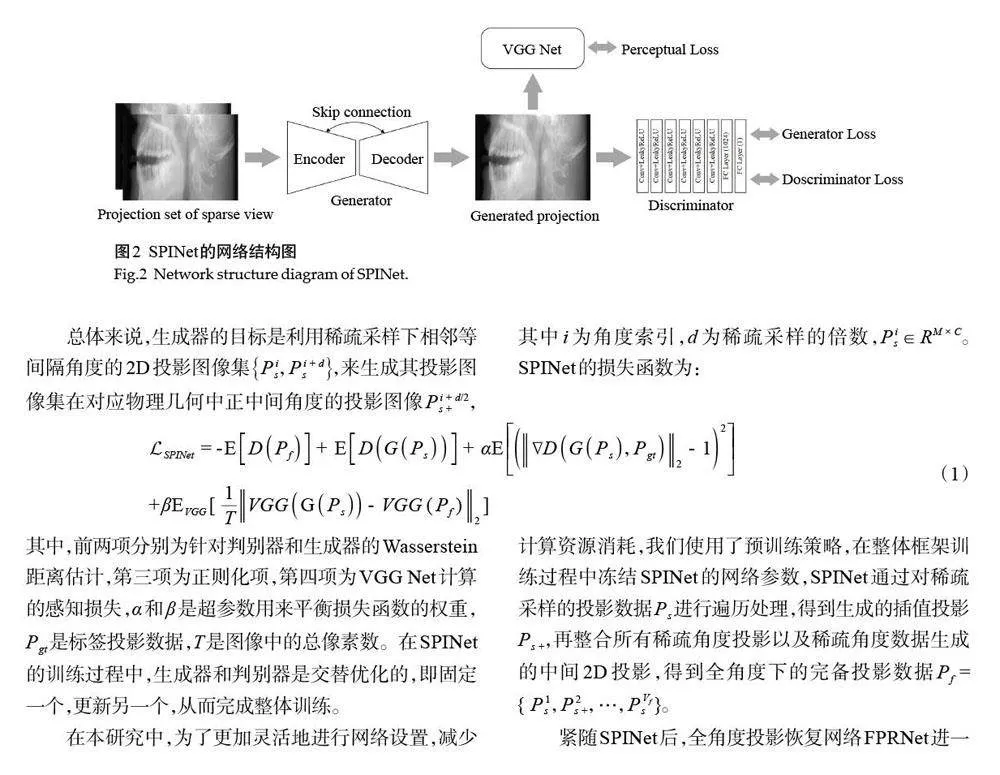
1.1.1 投影插值模块 投影域插值模块包含2个子网络,分别是稀疏投影插值网络(SPINet)和全角度投影恢复网络(FPRNet)。基于给定的稀疏采样投影数据Ps ∈ RM × C × Vs,其中M是初始投影数据的排数,C是探测器通道数,Vs是稀疏采样的投影角度数,SPINet旨在对Ps进行精确的插值处理,以生成数量上等同于全角度采集的完备投影数据Pf ∈ RM × C × Vf,其中Vf 代表完备投影角度数。
SPINet框架(图2)由生成器G,判别器D,和感知损失计算器VGG Net组成。其中G由编码器(Encoder)和解码器(Decoder)构成,编码器负责提取图像中的特征并编码成更高层次的表征,而解码器则负责将这些编码的特征重新构建成恢复后的图像。编码器采用了4 个卷积层,每一层的卷积核大小为3×3,步长为2,其中第一层卷积层的卷积核数量设置为64,随后的每层卷积核数量翻倍,直至达到512,以增加网络的表示能力,每个卷积层后跟随一个批量归一化层和ReLU激活函数,以增强网络的非线性能力和稳定性。解码器的结构与编码器相呼应,采用了逐渐上采样(转置卷积)的方式来重建图像,每一层的卷积核大小为3×3,步长为1,输出层采用了1×1卷积核,来调整输出通道数,匹配目标输出维度。为了更好地保留细节信息以及促进梯度的流动,类似于UNet[27],我们在编码器-解码器之间采用了跳跃连接的策略,该策略已在多个成像任务中表现出有效的性能提升[28, 29]。D包含6 个卷积层,前2 个卷积层有64 个卷积核,随后的2个卷积层有128个,最后的2个卷积层有256 个,与生成器类似,所有的卷积层中的卷积核大小为3×3。在卷积层后,紧随的是两个全连接层,其中第一个全连接层输出大小为1024,第二个全连接层输出大小为1,以匹配目标输出维度。与Yang 等[30]提出的WGAN-VGG类似,本研究中的感知损失计算器VGGNet是基于预训练的VGG-19 网络[31]来实现,其分别提取生成器生成的投影图像以及标签投影图像的特征,来计算特征之间的差异,该差异将通过标准反向传播算法来更新生成器的参数,从而使生成器达到更好的性能。
