
基于随机森林算法的短期降水预测及对农业生产的影响
2024-09-25 00:00:00张思远王才士范楠
智慧农业导刊 2024年19期

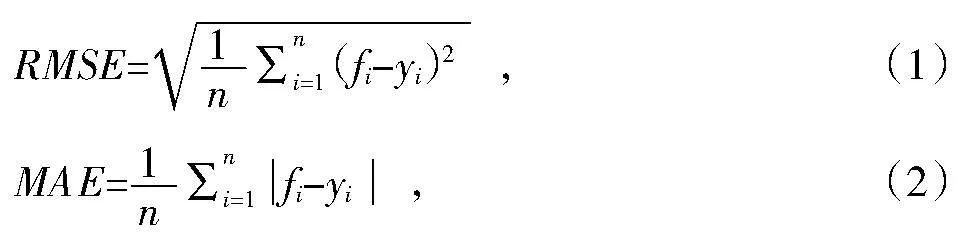
摘 要:准确有效地预测降水量有利于农业生产发展的规划、水资源管理以及自然灾害的预防等方面,对于干旱半干旱地区作用更为显著。该文利用庆阳市2023年1月至2024年1月的降水数据,基于包装法中的递归特征消除,迭代移除不重要的特征,后使用随机森林模型对该数据进行分析和预测。结果表明,通过对2种方法的整合使用,能够使模型具有良好的预测性能,且对庆阳市降水时刻与降水量作出较好的预测。该文研究内容对其他地市的降水量预测具有参考价值,也对当地的水资源合理利用以及促进当地社会经济可持续发展具有十分重要的意义。
关键词:包装法;递归特征消除;特征选择;随机森林;降水预测
中图分类号:P457.6 文献标志码:A 文章编号:2096-9902(2024)19-0010-04
Abstract: Accurately and effectively predicting precipitation is conducive to the planning of agricultural production development, water resources management and prevention of natural disasters, and is more significant in arid and semi-arid areas. This paper uses the precipitation data of Qingyang City from January 2023 to January 2024, iteratively removes unimportant features based on recursive feature elimination in the packaging method, and then uses the random forest model to analyze and predict the data. The results show that by integrating the two methods, the model can have good prediction performance, and can make a good prediction for precipitation time and precipitation amount in Qingyang City. The research content in this paper also has reference value for precipitation prediction in other cities, and is also of great significance to the rational use of local water resources and the promotion of sustainable local social and economic development.
Keywords: packaging method; recursive feature elimination; feature selection; random forest; precipitation prediction
近年来,随着区域经济发展和流域开发在国民经济的地位日趋提高,对降水量预报提出了更高的要求。同时,提高降水量的精细化预报水平是现如今很多行业共有的需求。庆阳市作为我国西北地区的重要粮仓,农业发达,对降水预测的需求更高。随着大数据时代的到来,相比于传统方法,机器学习算法可以更有效地提高降水量预测的精度。准确地预测庆阳市降水量对于该地区农业生产[1]、社会经济发展[2]、水资源合理利用[3]及防灾减灾[4]等方面都有积极影响,并对促进当地社会经济的可持续发展、提高人民生活质量具有十分重要的意义。
1 材料与方法
1.1 研究区域概况
庆阳市位于中国西部地区的甘肃省东部,总面积27 119 km2,下辖1个区和7个县,古称庆州,常被称为“陇东”,是中国“第一块旧石器”的发现地,也是中医鼻祖岐伯的出生地、中医药文化的发祥地。庆阳还是甘肃的革命老区,长庆油田的发源地,因此被誉为“红色圣地、岐黄故里、农耕之源、能源新都”。庆阳是中华民族早期农耕文明的发祥地之一,素有“陇东粮仓”的美称。庆阳市属大陆性气候,冬季常受西北风影响,夏季多为东南风,冬季干冷而晴朗,夏季炎热而多雨。降雨量南多北少,气温南部高于北部,年平均气温在9.5~10.7 ℃,无霜期约为140~180 d。年日照时数2 213.4~2 540.4 h,太阳总辐射量125~145 kcal/m2,地面平均蒸发量为520 mm,总体上呈现出干旱、温和、阳光充足的特点。
1.2 数据来源及变量选取
本文所使用的数据均来自美国国家大气研究中心、计算与信息系统实验室研究数据档案ds094.0-NCEP气候预报系统版本2(CFSv2)6小时产品(https://rda.ucar.edu/datasets/ds094-0/)。该数据档案收录的数据时间尺度为2011年1月至当前日期,空间尺度为全球,空间分辨率为0.5°×0.5°的网格数据,时间频率为6 h。本文所使用的数据时间尺度为2023年1月至2024年1月,数据参数包括总降水量、温度、相对湿度、蒸腾作用、冠层水分蒸发、裸土直接蒸发、臭氧总量、地热通量、露点温度、风的u分量、晴空向下长波通量和向下短波辐射通量等24个指标,每项指标包含1 461个数据。
1.3 研究方法
1.3.1 包装法
高维数据的特征选择算法主要分为筛选法(Filter)、包装法(Wrapper)、嵌入法(Embedded)以及集成法(Ensemble)4类。包装法是一种基于机器学习模型性能评估的特征选择方法,与其他3种不同,包装法直接使用特定机器学习模型进行特征选择,以评估特征的贡献,并选择最佳的特征子集。包装法的基本思想是:对于给定的特征子集,使用一个特定的机器学习算法进行训练,并通过交叉验证或者留出法等方式评估模型的性能。根据模型的性能表现,对特征子集进行评分,然后选择性能最佳的特征子集作为最终的特征集合。这个过程可以通过递归地添加或删除特征来进行,直到达到某个预设的停止条件。主要的包装法有以下4种:递归特征消除(Recursive Feature Elimination)、前向选择(Forward Selection)、后向选择(Backward Elimination)以及递归特征加入(Recursive Feature are Added)。本文主要使用基于随机森林的递归特征消除法来筛选特征,相较于其他算法,此算法具有较好的特征选择准确率,迭代次数少,且筛选出的特征子集有较好的一致性,对大数据集筛选也具有良好的效果[5]。
1.3.2 随机森林算法
随机森林是一种重要且有用的集成学习方法,具有灵活简单、适应能力强、应用范围广等特点,在众多领域都有良好的性质,是一种常见的机器学习方法[6]。决策树作为随机森林的基本单元,有着较好的泛化能力,既可以完成分类任务也适用于回归问题。所以基于随机森林算法对于分类和回归问题的优良性能,本文在特征选取及对降水量作回归预测方面都选取了随机森林这种算法。一棵决策树的建立通常包含特征选择、决策树生成和剪枝3个部分。在决策树生成过程中,考虑全部特征可能会带来过拟合问题,决策树的剪枝就是通过去掉部分细分的结点来提高决策树泛化能力的过程。
1.3.3 回归模型评价指标
在本文的研究中,分别选择均方根误差(Root Mean Square Error,RMSE)和绝对平均误差(Mean Absolute Error,MAE)作为回归模型精度的评价指标。RMSE和 MAE都是常用的评价模型的指标。RMSE不仅考虑了预测模型的方差,也包含模型的偏差。而MAE通常用于衡量预测值与观测值之间的紧密程度。这2个指标的计算公式为
式中:fi表示模型得到的降水量预测值,yi为降水量真实值,n表示测试集样本数量。
2 结果与分析
2.1 特征重要性的选择分析
为了确定数据集中哪些自变量特征对因变量总降水量的预测最为关键,使用了基于随机森林的递归特征消除(RFE)法。它利用机器学习模型来评估特征的重要性,并逐步剔除不重要的特征,直到达到指定的数量为止。
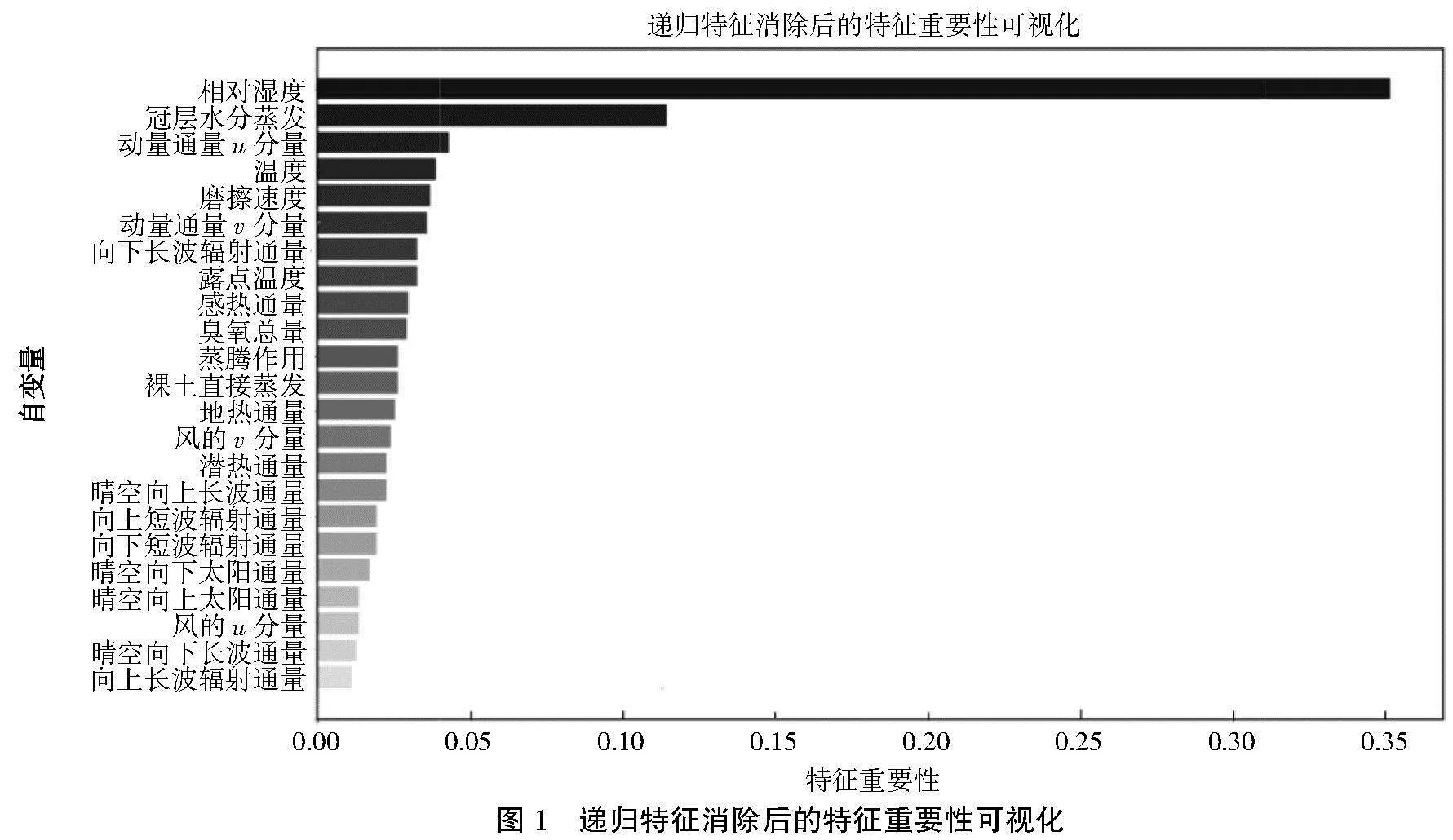
在研究中,首先训练了一个随机森林模型,然后使用RFE对特征进行递归消除,选取了重要性前12的特征作为最终的特征集合,这些特征被认为对因变量总降水量的预测最具有影响力。为更明显地显示对于23个自变量的选择,将所有自变量的特征重要性得分(特征重要性得分是随机森林模型根据特征对目标变量的预测贡献度进行计算的,得分越高表示该特征对目标变量的影响越大)以可视图的形式展示如图1所示。
根据可视化图中变量特征的重要性程度,最终选择的12个变量:相对湿度、冠层水分蒸发、动量通量u分量、温度、磨擦速度、动量通量v分量、向下长波辐射通量、露点温度、感热通量、臭氧总量、蒸腾作用和裸土直接蒸发。
2.2 相关性分析与偏相关性分析
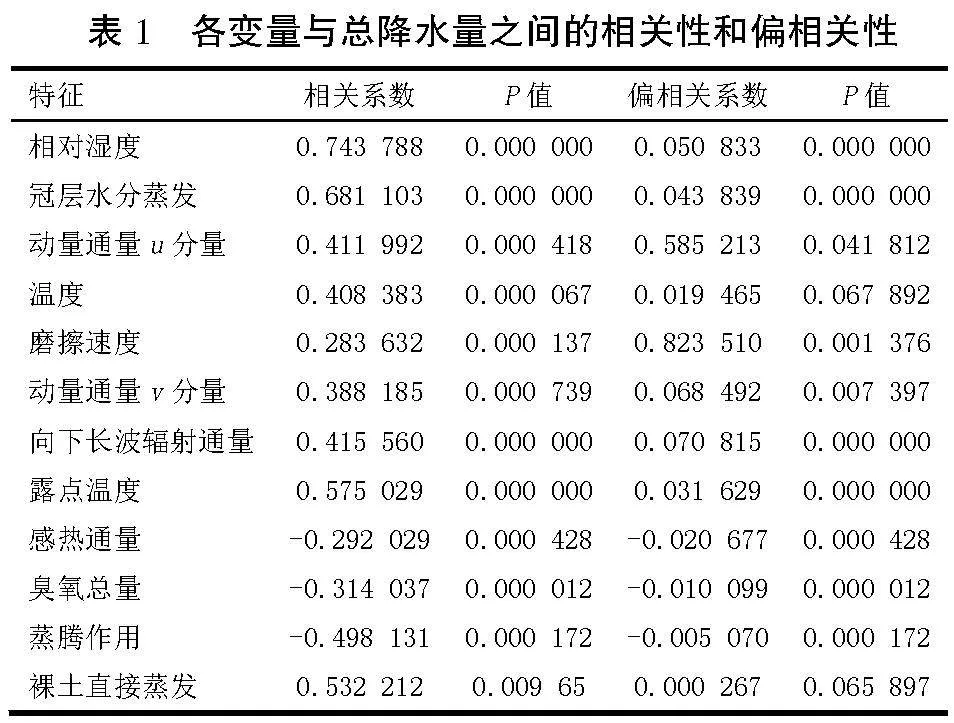
相关性分析和偏相关性分析是2种常见的统计方法。相关性分析是指对2个或多个具有相关性的变量元素进行分析,以确定它们之间的线性关系,即当一个变量的值发生变化时,另一个变量的值是如何相应地发生变化的。与此相反,偏相关性分析则旨在确定2个变量之间的关系,同时控制一个或多个其他变量的影响。它可以帮助研究者了解在控制其他因素的情况下,2个变量之间的独立关系。相关系数与偏相关系数的取值范围都在-1到1之间,通常它们的绝对值越接近于1,表示2个变量之间的关系越强。而P值用于判断相关系数和偏相关系数的统计学意义,一般而言,如果P值小于0.05,则认为它们在统计学上有意义。
由表1可以看出,在5%显著性水平下,筛选后保留的12个变量与总降水量的相关性均显著,且偏相关性大多数也显著,说明通过基于随机森林的递归特征消除法选择后的特征可以用于降水预测。
2.3 模型回归预测结果分析
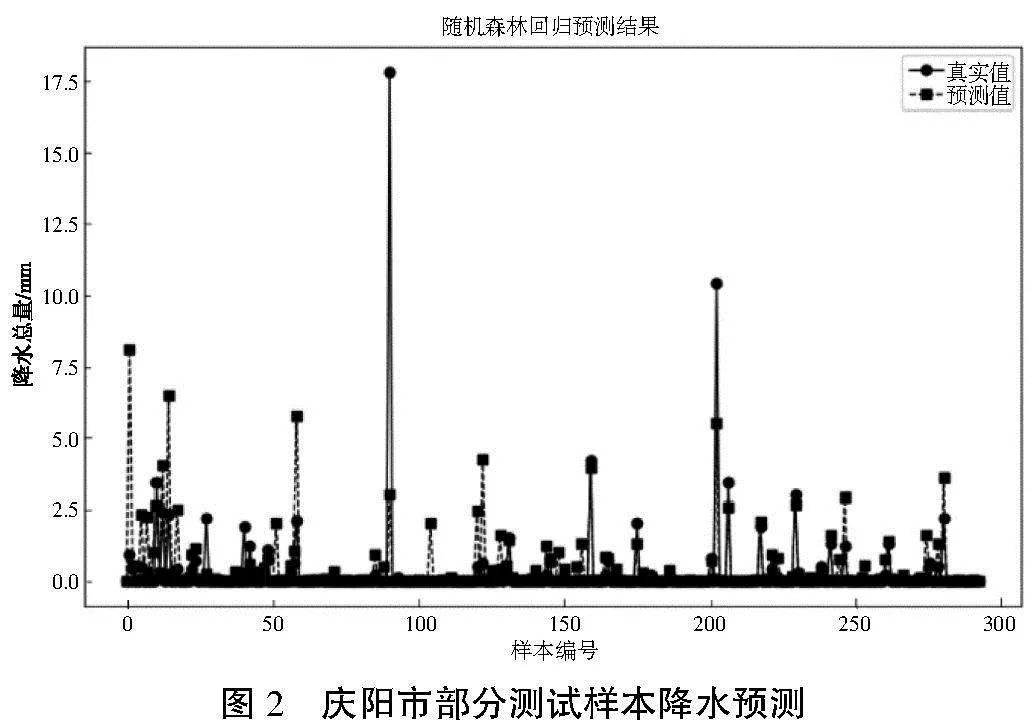
由表2可得,随机森林预测模型的RMSE=1.069 993,MAE=0.267 631,考虑到目标变量的取值范围比较大,且模型能够在这种情况下预测得到比较准确的结果,可以说RMSE和MAE的值是可以接受的,并且反映了模型的预测误差比较小,模型能够很好地预测目标变量的值,这也被视为一个良好的模型性能表现。
图2展示了部分测试样本的随机森林预测模型的拟合效果。从图中可以看出,该模型对于大多数降水时刻能够准确预测,并且在定量数据方面表现良好。然而,当总降水量显著增加时,模型的拟合程度仍有改进的空间。
3 精确降水预测对农业生产的影响
3.1 及时调整种植计划
通过提前知道未来一段时间内的降水量,农民可以及时地调整种植计划,选择适宜的作物品种和种植时间。例如,如果预测到某一地区即将迎来干旱期,农民可以选择耐旱性较强的作物进行种植;反之,如果预测到将有大量降雨,农民则可以考虑种植一些对水分需求较大的作物。这不仅可以保证作物的正常生长,还能提高产量和质量。
3.2 合理安排灌溉及排水
准确的降水预测还有助于农民合理安排灌溉和排水工作。在干旱期间,农民可以通过灌溉为作物提供必要的水分,避免因缺水而导致减产甚至绝收;在多雨季节,农民则可以提前做好排水工作,防止农田积水过多而引起作物根部腐烂或其他病害。
3.3 减少或避免自然灾害损失
准确的降水预测还可以帮助农民更好地应对自然灾害。通过了解可能出现极端天气事件的概率和时间,农民可以及时采取相应的防范和应对措施,减少灾害造成的损失。同时,这也为政府和社会组织制定救灾策略和规划提供了科学依据。
4 结束语
降水的精确化预测对地方生产生活有着至关重要的作用。本文通过递归特征消除法和随机森林算法对庆阳市一年的降水数据进行模型建立,得出以下结论:利用随机森林的特征降维能力,引入包装法中的递归特征消除法来提高特征选择的稳定性。通过综合2种方法,提升了后续随机森林算法中的特征子集的一致性,减少了特征选择程序的迭代次数,并在处理大数据集时取得了良好的效果。在实际数据分析中,选取庆阳市降水数据,以最终选择的12个气象要素建立了随机森林预测模型,通过最终结果的分析表明,该模型在回归预测方面表现出色。
未来的工作还可以从以下几个角度展开,以提升预测的准确度。
1)考虑更多的机器学习方法。在本文中仅仅考虑了最为常用的随机森林算法,除此之外,还有许多机器学习方法如支持向量机、k-近邻算法等[7],它们与递归特征消除算法的结合也可能取得更好的特征选择效果。
2)考虑张量在预测中的作用。张量作为一种高阶数据形式,其多维性与降水数据的类型不谋而合,合理地使用张量来处理降水数据中的多维要素可能会使预测结果更加准确有效[8-10]。
3)考虑多种回归预测模型。本文中的预测对于实际降水量过高的情况表现得不尽如人意,可以考虑其他回归预测模型,如BP神经网络预测[11]等。
参考文献:
[1] 陈昌毓.甘肃干旱半干旱地区降水特征及其对农业生产的影响[J].干旱区资源与环境,1995,9(1):25-33.
[2] 李佳伟,左其亭,马军霞.新疆水资源-经济社会-生态环境时空演变特征分析[J].北京师范大学学报(自然科学版),2020,56(4):591-599.
[3] 任博.基于旱涝指标的辽宁省水资源应急管理影响效应研究[D].大连:辽宁师范大学,2023.
[4] 詹德权.新技术在气象防灾减灾中的应用进展及成效[J].海峡科学,2023(11):23-26.
[5] 冯晓荣,瞿国庆.基于深度学习与随机森林的高维数据特征选择[J].计算机工程与设计,2019,40(9):2494-2501.
[6] 李航.统计学习方法[M].2版.北京:清华大学出版社,2019.
[7] 李智裕.基于机器学习的气候降水预测模型[D].成都:成都理工大学,2021.
[8] 杨兵.基于张量数据的机器学习方法研究与应用[D].北京:中国农业大学,2014.
[9] 莫乃榕.张量分析[M].武汉:华中科技大学出版社,2023.
[10] 黄克智,薛明德,陆明万.张量分析[M].3版.北京:清华大学出版社,2019.
[11] 智协飞,张珂珺,田烨,等.基于神经网络和地理信息的华东及华南地区降水概率预报[J].大气科学学报,2021,44(3):381-393.
