
基于深度学习的命名实体识别研究综述
2024-09-14 00:00:00张继元钱育蓉冷洪勇侯树祥陈嘉颖
现代电子技术 2024年6期





摘 要: 命名实体识别是自然语言处理领域的一项关键任务,其目的在于从自然语言文本中识别出具有特定含义的实体,如人名、地名、机构名和专有名词等。在命名实体识别任务中,研究人员提出过多种方法,包括基于知识和有监督的机器学习方法。近年来,随着互联网文本数据规模的快速扩大和深度学习技术的快速发展,深度学习模型已成为命名实体识别的研究热点,并在该领域取得显著进展。文中全面回顾现有的命名实体识别深度学习技术,主要分为四类:基于卷积神经网络模型、基于循环神经网络模型、基于Transformer模型和基于图神经网络模型的命名实体识别。此外,对深度学习的命名实体识别架构进行了介绍。最后,探讨命名实体识别所面临的挑战以及未来可能的研究方向,以期推动命名实体识别领域的进一步发展。
关键词: 命名实体识别; 深度学习; 自然语言处理; 卷积神经网络; 循环神经网络; Transformer; 图神经网络
中图分类号: TN919⁃34 " " " " " " " " " " " " " " "文献标识码: A " " " " " " " " " " 文章编号: 1004⁃373X(2024)06⁃0032⁃11
Survey of named entity recognition research based on deep learning
ZHANG Jiyuan1, 2, 3, QIAN Yurong1, 2, 3, LENG Hongyong2, 3, 5, HOU Shuxiang2, 3, 4, CHEN Jiaying1, 2, 3
(1. School of Software, Xinjiang University, Urumqi 830000, China;
2. Key Laboratory of Signal Detection and Processing in Xinjiang Uygur Autonomous Region, Urumqi 830046, China;
3. Key Laboratory of Software Engineering, Xinjiang University, Urumqi 830000, China;
4. School of Information science and Engineering, Xinjiang University, Urumqi 830000, China;
5. School of computer science, Beijing Institute of Technology, Beijing 100081, China)
Abstract: Named entity recognition is a crucial task in the field of Natural Language Processing, which aims to identify entities with specific meanings from natural language texts, such as person names, place names, institution names, and proper nouns. In the task of named entity recognition, researchers have proposed various methods, including those based on domain knowledge and supervised machine learning approaches. In recent years, with the rapid expansion ofinternet text data and the rapid development of deep learning techniques, deep learning models have become aresearch hotspot in named entity recognition and have made significant progress in this field. A comprehensive review of existing deep learning techniques for named entity recognition is provided, categorizing them into four main categories: models based on convolutional neural networks (CNN), recurrent neural networks (RNN), Transformer models, and graph neural networks (GNN) for NER. An overview of deep learning architectures for named entity recognition is presented. The challenges faced by named entity recognition and potential research directions in the future are explored to promote further development in the field of named entity recognition.
Keywords: named entity recognition; deep learning; natural language processing; convolutional neural networks; recurrent neural network; Transformer; graph neural network
0 "引 "言
自然语言处理(Natural Language Processing, NLP)是计算机科学和人工智能领域的重要研究方向,主要研究人与计算机之间用自然语言进行有效交流的理论和方法。信息提取(Information Extraction, IE)是NLP的一个重要子领域,通常涉及命名实体的提取、命名实体之间的关系以及实体所涉及的事件等方面的处理。其中,命名实体识别(Named Entity Recognition, NER)是IE的子任务之一,它将自然语言文本中的专有名称划分为个人、地点、组织名称等。NER任务的准确性对进一步的IE任务,如关系和事件的提取[1],有着重要影响。此外,在各种NLP应用中,如文本理解[2⁃3]、信息检索[4⁃5]、自动文本摘要[6]、问答[7]、机器翻译[8]和知识库构建[9]等方面,NER也发挥着重要作用。
命名实体(Name Entity, NE)最初是在1995年的第六届消息理解会议(MUC)上提出的,主要指文本中具有特定名称的单词或短语。它通常包括三大类(实体类、时间类和数字类)和七个子类(人名、地名、机构名、时间、日期、货币和百分比)[10]。NER旨在识别文本中的专有名词,并将其正确分类。自MUC 6会议以来,NER已成为NLP领域的研究热点。许多科学事件,如CoNLL03[11]、ACE[12]、IREX[13]和TREC实体轨道[14],都对NER进行了深入研究。NER实例图如图1所示。
目前,NER任务主要分为三类方法:基于规则和字典的方法、基于统计学习的方法和基于深度学习的方法。在早期的NER任务中,通常使用基于规则和字典的方法。这些方法依赖于手动开发的基于实体特征分析的规则、词典、正字特征和本体,而无需标注数据。规则模板依赖于知识库和字典的建立,是一个简单而有效的处理文本中众多实体的方法。例如,1991年Rau在IEEE人工智能应用大会上发表一篇关于“提取和识别公司名称”的论文,主要使用启发式算法和手动规则编写[15]。1997年,张小衡和王玲玲使用基于规则的方法来识别中国的大学名称[16],准确率和召回率分别为97.3%和96.9%。另外,D. Farmakiotou等人在2000年提出一种基于规则的希腊金融文本命名实体识别方法[17],而香港理工大学的王宁等人在2002年使用基于规则的方法实现有效的名称识别[18]。然而,基于规则和字典的方法通常依赖于特定的语言、领域和知识库,这限制了它们的适用性,并且维护成本很高。因此,近年来,这些方法逐渐被基于统计学习的方法所取代。
基于统计学习的方法主要包括有监督和无监督的学习方法。近年来,基于特征的有监督学习方法逐渐成为NER任务的主流方法。这种方法将NER任务视为多类分类问题,并使用特定的特征集来提取与实体相关的特征。这些特征用于训练机器学习模型,例如隐马尔可夫模型和支持向量机等。
这些方法通常需要大量标记数据来训练模型,但在一些特定任务和领域中,它们已经取得相当不错的性能。例如,D. M. Bikel等人提出一种基于手工特征工程的监督式命名实体识别系统,对名称、时间表达式、日期和数值表达式进行分类[19]。然而,传统的基于机器学习的实体提取方法存在严重问题,即严重依赖专家的特征工程,模型的泛化能力较差。
基于无监督学习的实体识别方法通常采用聚类或利用实体与术语之间的相似性对语料库中的词汇特征进行统计分析,来实现实体识别。例如,D. Nadeau等人提出一种基于无监督学习的NER系统,采用简单的启发式方法对给定文本中的实体进行分类[20]。然而,由于无监督学习方法的模型训练依赖于数据本身,因此需要使用数量更大、质量更高的数据来提高模型性能。同时,由于缺乏领域专业知识,其实体识别准确率也难以保证。近年来,随着互联网文本数据的快速增长和深度学习技术的进步,出现大量基于深度神经网络的命名实体识别方法。这些方法无需依赖专家特征工程,采用端到端的方式就可以直接从原始输入中学习特征表示,能更好地提高识别准确率和效率。
近年来,基于深度神经网络的方法不仅在自然语言处理领域取得显著进展,而且在计算机视觉(Computer Vision, CV)、图像处理等领域也获得重要成果。在NER任务中,基于深度神经网络的方法具有显著优势。深度神经网络往往具备多层神经网络,经过在训练集上的训练,能更好地从原始输入数据中提取复杂特征,最后利用非线性激活函数来实现预测任务。
例如,R. Collobert等人提出一种基于卷积神经网络的NER方法[21];而Huang等人则提出一种基于双向长短时记忆网络的序列标注方法[22]。这些方法基于深度神经网络强大的特征提取能力,获得更高的识别准确率。总体而言,基于深度学习的NER方法为解决实际应用中的复杂问题提供了一种有效的途径,并且在实践中已经得到广泛应用与认可。
1 "常用命名实体识别数据集和评价指标
1.1 "数据集
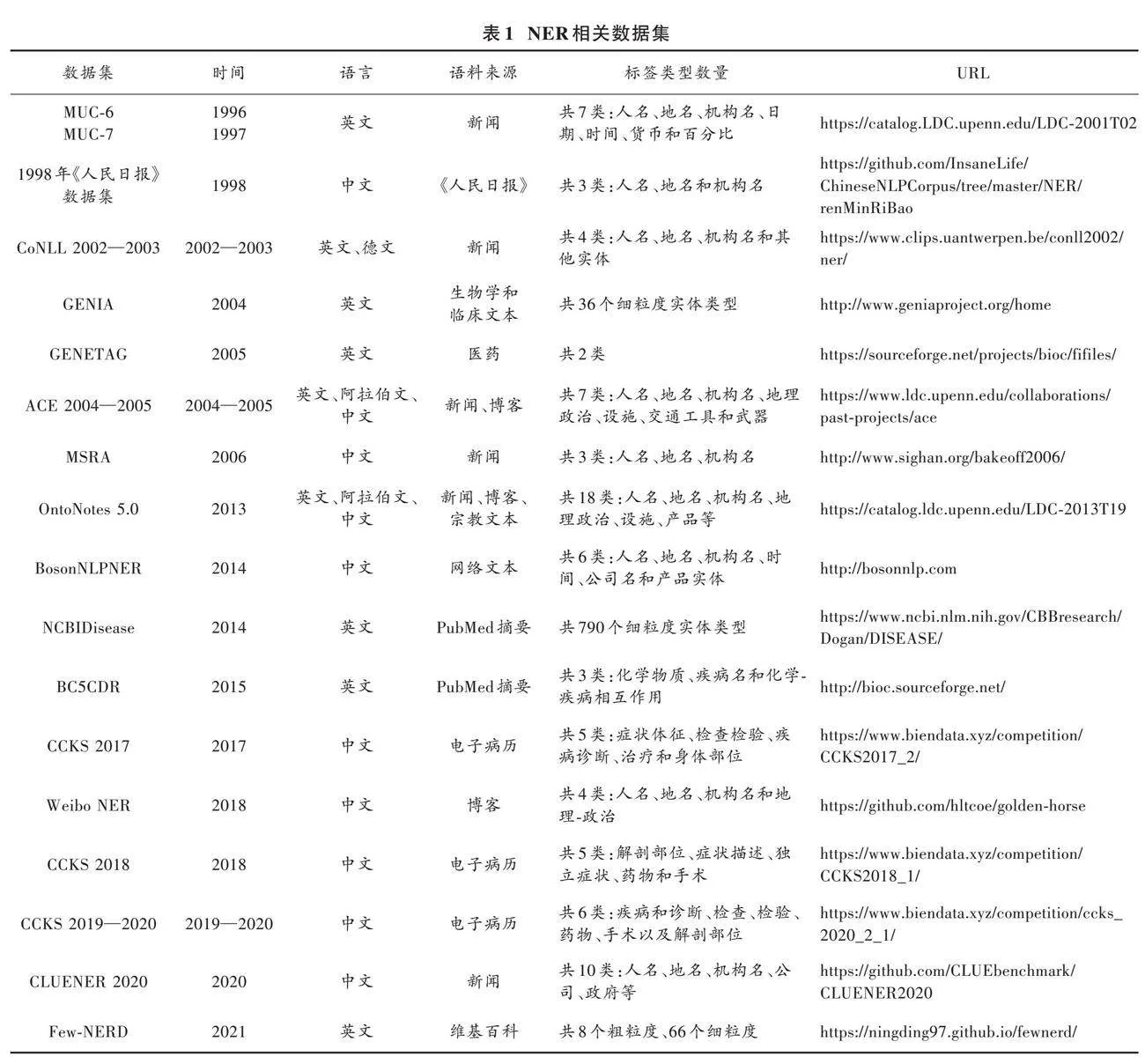
自1996年Grishman和Sundheim首次提出NER任务以来,已经为命名实体识别创建了许多共享任务和数据集。例如,CoNLL 2002(Tjong Kim Sang,2002)和CoNLL 2003(Tjong⁃Kim Sang和De Meulder)是根据西班牙语、荷兰语、英语和德语的新闻通信文章创建的,CoNLL重点关注4个实体——个人PER、地点LOC、组织ORG和其他MISC。本文总结出目前广泛使用的中英文NER数据集,如表1所示。
表1总结一些广泛使用的数据集,并列出它们的数据源以及实体类型(也称为标签类型)的数量。如表1所示,在2005年之前,数据集主要是通过对新闻文章标注少量的实体类型来构造的,适用于粗粒度的NER任务。后来,基于各种文本源开发更多的数据集,包括维基百科的文章、对话和用户生成的文本(如推特、YouTube评论和W⁃NUT中的StackExchange帖子)。标签类型的数量也在明显增加,例如NCBIDisase中就有790个标签。而像OntoNotes的目标是注释大量不同文本类型的语料库,包括网络日志、新闻文章、脱口秀、广播、Usenet新闻组和对话式电话语音,其中包含语法和谓词论证结构等结构信息,以及本体和共指等浅层语义信息。从1.0~5.0版本,OntoNotes目前拥有18类命名实体。此外,本文还列出一些特定领域的数据集,比如在PubMed和MEDLINE文本上开发的数据集。
1.2 "评价指标
NER系统的评估通常与人工注释进行比较,以确定系统是否能正确地标记文本中的实体。这种比较可以通过两种方式来量化,即宽松匹配和精确匹配。
在宽松匹配中,它允许系统标记的实体与人工注释的实体在一定程度上不完全匹配,但仍然可以被视为正确。具体来说,宽松匹配可以分为部分匹配和类型匹配两种方式。部分匹配是指系统标记的实体与人工注释的实体在部分单词上匹配;类型匹配是指系统标记的实体类型与人工注释的实体类型匹配,但实体的具体单词可能不同。在实际的评测中,往往是以精确匹配为主。在精确匹配评估中,系统需要同时正确识别实体的边界和类型,否则将被视为错误。具体而言,系统的输出与标注数据进行比较,以计算误判(False Positive, FP)、漏判(False Negative, FN)和正确判定(True Positive, TP)实例的数量,从而计算精确度、召回率和F1分数等评价指标。
[Precision=TPTP+FP] (1)
[Recall=TPTP+FN] (2)
[F1=2Precision·RecallPrecision+Recall] (3)
式中:精确度(Precision)指的是系统正确标记的实体数量与系统总标记数量之比;召回率(Recall)指的是系统正确标记的实体数量与标注中所有实体数量之比;F1分数是精确度和召回率的加权平均数,它是评估NER系统性能最常用的指标之一。
此外,宏观平均F1分数(Macro⁃F1)和微观平均F1分数(Micro⁃F1)都考虑多种实体类型的性能。其中Macro⁃F1分别计算每个实体类型的F1分数,然后取F1分数的平均值:
[Precisioni=TPiTPi+FPi] (4)
[Recalli=TPiTPi+FNi] (5)
式中:[Precisioni]和[Recalli]表示第i类标签的精确率和召回率。
[Precisionmicro=i=1nTPii=1nTPi+i=1nFPi] (6)
[Recallmicro=i=1nTPii=1nTPi+i=1nFNi] (7)
[F1micro=2Precisionmicro·RecallmicroPrecisionmicro+Recallmicro] (8)
式中n是标签总数。
微平均F⁃score聚合所有实体类型的个体FN、FP和TP,并用它们来获得统计数据。
[Precisionmacro=1ni=1nPrecisioni] (9)
[Recallmacro=1ni=1nRecalli] (10)
[F1macro=2Precisionmacro·RecallmacroPrecisionmacro+Recallmacro] (11)
由于Macro⁃F1对各类别的精确度和召回率求平均值,因此并没有考虑数据数量的问题。这种情况下,Precision和Recall值较高的类别会对F1值的影响较大。
2 "基于深度学习的命名实体识别研究现状
目前,用于NER任务的深度学习模型包括卷积神经网络模型(Convolutional Neural Network, CNN)[23]、循环神经网络模型(Recurrent Neural Network, RNN)[24]、长短期记忆网络模型(Long⁃Short Term Memory, LSTM)[25]、双向LSTM模型(Bi⁃directional LSTM, Bi⁃LSTM)、基于Transformer的预训练模型[26]和图神经网络模型。在这些模型中,基于条件随机场(Conditional Random Field, CRF)[27]的Bi⁃LSTM是NER任务中最常用的模型之一。它使用Bi⁃LSTM提取句子特征,并使用CRF对标签之间的依赖关系进行建模。这些模型具有利用大量数据进行训练、自动提取文本中的重要特征、实现更高识别准确率等显著优势。特别是Bi⁃LSTM在处理长文本序列和捕获句子中的双向信息方面非常有效,使其非常适合实体本地化[28⁃29]。
2.1 "基于卷积神经网络的命名实体识别方法
尽管CNN更多被应用于CV领域,但是其强大的局部特征捕捉能力也让它被广泛应用于文本序列的特征提取。如R. Collobert等人提出一种句子级的模型,通过卷积层提取每个单词周围的局部特征[21]。模型将卷积层提取的局部特征向量组合构成全局特征向量,再利用池化操作对每个特征进行降维操作,获取更具代表性的文本特征。在这个过程中,R. Collobert等人使用多通道CNN方法,即利用多个卷积核提取文本序列的不同特征,将提取出的特征拼接成多个通道的特征图,并将这些特征图输入到后续的分类器中进行NER任务[21]。相较于单通道CNN,多通道CNN能更好地捕捉文本序列中的予以信息,进而提高模型性能,提升NER的准确性和鲁棒性。
Ma和Hovy同时采用CNN来提取词语的特征表示[30]。首先,他们使用CNN在字符级别上捕捉词法特征;然后,将字符级表示和嵌入式词语连接起来,再输入RNN上下文编码器中进行处理。G. Aguilar等人提出一种多任务的NER方法。该方法利用CNN在字符级别上捕捉正字法特征和单词形状[31]。Wu等人使用卷积层来生成由多个全局隐节点表示的全局特征[32]。然后将局部特征和全局特征输入到标准仿射网络中,以识别临床文本中的命名实体。
2.2 "基于循环神经网络的命名实体识别方法
相较于全连接神经网络(Fully Connected Neural Network, FNN)需要固定输入长度的问题,RNN由循环单元构成,能够处理变长的输入数据,更适合类似于文本数据这样的时序输入。RNN在计算时根据前一个时间步的隐藏状态和当前输入向量计算当前时间步的隐藏状态。通过双向模型的叠加,可以利用前后文信息进行预测。RNN对时间维度特征的强大捕捉能力在NLP的各类任务中都是最为适用的模型之一。
2.2.1 "长短时记忆网络
在应对长序列时,传统的RNN往往会出现梯度消失或梯度爆炸的问题,而这些问题会严重影响模型的训练效果。为此,研究人员提出一种特殊类型的RNN,即LSTM。在LSTM中,内存单元替换隐藏层更新。记忆单元由输入门、遗忘门、具有自回路连接的神经元和输出门组成。自回路连接确保存储单元的状态在一个时间步骤到另一个时间步骤之间保持不变。输入门决定输入信号对存储单元状态的影响,输出门决定存储单元状态对其他神经元的影响。最后,遗忘门通过控制记忆单元的自回路连接,允许每个单元保留或遗忘其最后的状态。LSTM通过引入门结构来控制信息的流动,可以对冗余信息进行遗忘,并加强对有效信息的记忆,从而在一定程度上缓解梯度问题,更适用于长序列场景。
得益于长距离依赖能力,LSTM在NER任务中能够有效提取上下文的语义信息,并更好地理解文本内容,从而提高模型的识别准确率。如O. Kuru等人提出一种基于LSTM的字符级NER方法,即CharNER[33]。CharNER将句子视为字符序列,利用LSTM提取字符级别的表示。它为每个字符而不是每个单词输出标记分布,然后从字符级别标记获取单词级别标记。实验结果表明,以字母为主要表示单位的输入方式优于以单词为基本输入单位的方式。CharNER的方法还可以解决一些NLP任务中单词分割和词性标注的挑战。
2.2.2 "双向长短时记忆网络
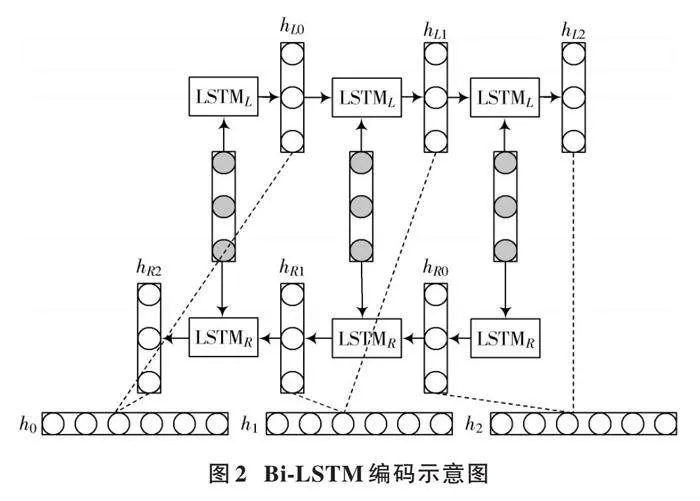
Bi⁃LSTM作为一种能够对序列中的上下文信息进行建模的神经网络模型,可以通过前向和后向两个方向的处理,有效地捕捉到序列中每个位置的上下文信息。目前在NER领域中较为流行的模型包括Bi⁃LSTM和Bi⁃LSTM⁃CRF。相较于O. Kuru等人的工作,Wan等人使用Bi⁃LSTM替换单向的LSTM,能更好地获取字符特征。再通过softmax层,可将数据特征转换为标注结果,进而实现序列标注任务,并应用在NER任务中[34]。Ma和Hovy提出一种结合Bi⁃LSTM、CNN和CRF的神经网络模型[30],利用GloVe[35]预训练的维度为100的词嵌入以自动提取单词及字符级特征,利用CRF对标签序列进行全局建模,避免Bi⁃LSTM在处理长序列时可能存在的信息遗漏问题,从而提高序列标注的性能。Bi⁃LSTM编码示意图如图2所示。
2.2.3 "门控循环单元
门控循环单元(Gated Recurrent Unit, GRU)[36]是一种常用的循环神经网络结构。GRU的基本结构包括重置门、更新门和隐藏状态。重置门控制忘记历史信息的程度,而更新门控制合并新信息的程度。两个门都取决于当前输入和前一个时间步的隐藏状态。更新后的隐藏状态会同时考虑当前输入和以前的隐藏状态。通过逐步重置和更新输入数据的历史信息,GRU可以有效地对顺序数据进行建模,特别是在长序列中,同时避免梯度消失和爆炸的问题。相较于传统的RNN模型,GRU拥有更好的长期记忆能力;与LSTM对比,GRU又拥有更少的参数,易于训练。
Rei等人利用门机制将字符级表示与词嵌入相结合[37]。Yang等人使用深度GRU模型在字符和单词级别编码形态和上下文信息[38]。他们的模型能动态地决定从字符或单词级表示中使用多少信息。总体而言,GRU已成为近年来NER等序列建模任务的主流模型之一。
2.3 "基于Transformer的命名实体识别方法
Transformer是一种利用自注意力机制来建模序列的神经网络结构,它会对自然语言处理任务产生革命性的影响。在NER任务中,也有许多基于转换器的方法被提出。无论是生成式预训练Transformer(Generative Pre⁃trained Transformer, GPT)[39]还是BERT(Bidirectional Encoder Representation from Transformer)[40]都是基于Transformer模型的预训练模型,相较于传统的Word2Vec[41]和GloVe[35],这些预训练模型能根据上下文获得更加准确的表示,对于诸如NER之类的下游任务也有着明显的提升效果,如图3所示。尽管BERT作为早期的预训练模型还存在着一定的局限性,如静态掩码策略,后期的一些工作,如RoBERTa[42]、Albert[43]、XLNet[44]等都对BERT类模型进行改善,但是利用基于Transformer模型的预训练模型进行NER任务也已然成为一种新的范式。
2.4 "基于GNN的命名实体识别方法
与传统的神经网络模型不同,图神经网络(Graph Neural Network, GNN)是一种用于处理图结构数据的网络结构,通过迭代地传递和聚合节点间的信息来学习节点的表示,以推断其状态或标签。GNN的核心思想在于将节点的表示视为其邻居节点表示的函数,并通过多轮迭代更新节点表示,从而融合局部和全局的图结构信息。在命名实体识别任务中,GNN将NER任务转化为在图结构上的节点分类问题,其中每个节点表示一个单词或字符,节点的标签表示其是否属于命名实体。GNN通过建模节点之间的关系和上下文信息学习到更为准确的节点表示。常见的GNN方法包括基于图卷积网络(Graph Convolutional Network, GCN)的NER模型和基于图注意力网络(Graph Attention Network, GAT)的NER模型。基于GCN的模型利用卷积操作来聚合邻居节点的信息,通过多层GCN网络来学习节点的表示。而基于GAT的模型则通过自注意力机制,根据节点之间的重要性动态地聚合邻居节点的特征。
2.4.1 "基于GCN的命名实体识别方法
对于NER任务,GCN能够有效地捕捉节点之间的上下文关系和信息传递能力。传统的NER方法主要基于局部上下文和序列信息,但在处理实体之间的关联性和上下文语境时存在一定的局限性,尽管可以用上下文特征表示,但这些模型往往对全局关系进行了错误的表示。GCN通过结合图结构和节点特征,能够更好地利用实体之间的关联信息。
基于GCN的NER模型利用卷积操作来聚合邻居节点的信息。具体而言,GCN通过迭代地传递和聚合节点特征,使得节点能够融合其直接邻居节点的信息。这种信息传递和聚合的过程能够捕捉实体之间的上下文信息,有助于提取实体的特征表示。通过多层GCN网络的堆叠,模型可以逐步学习到更抽象和语义丰富的节点表示。
T. T. H. Hanh等人提出结合上下文特征和图卷积网络的全局特征来提高NER性能,并通过广泛的实验进行验证[45]。Tang等人使用交叉GCN来同时处理两个方向的字符有向无环图,引入了全局注意力GCN块来学习以全局上下文为条件的节点表示[46]。
2.4.2 "基于GAT的命名实体识别方法
GAT与GCN的核心思想相似,都是通过节点之间的信息传递和聚合来学习节点的表示,基于图卷积操作对节点之间的关联性进行建模。然而,在聚合方式和权重分配方面,它们有明显的差异。GCN采用固定的邻居聚合策略,通过对邻居节点的特征进行均值或加权求和来更新节点的表示。这种聚合方式无法自适应地分配权重,对所有邻居节点采用相同的权重,未能精细建模节点之间的重要性。相比之下,GAT引入了自注意力机制,通过计算节点之间的注意力系数来灵活地分配权重。它通过加权聚合邻居节点的特征表示来更新每个节点的表示,权重由注意力系数决定。GAT能够根据节点之间的相关性自适应地学习节点的重要性,并更好地捕捉实体之间的上下文信息和语境。Chen等人在研究中通过引入额外的图注意力网络层来增强短语内部依赖性的表示[47]。Wang等人提出一种多态图注意力网络,从多个维度上动态调节匹配字符与匹配词之间的细粒度相关性,以增强字符表征[48]。Tian提出一种有助于词汇增强型汉语NER且选词简单有效的多任务学习方法[49]。该方法中的一项任务是对匹配的单词进行评分,并从中选择前K个更有帮助的单词;另一项任务是通过多头注意力网络对所选单词进行整合,并通过字符级序列标记进一步实现中文NER。GAT通过注意力权重的优化能够强化与实体相关的邻居节点的特征表示,从而提升命名实体识别的准确性。
GAT和GCN在模型结构上也存在差异。GAT具有更高的灵活性,能够为每个节点计算独立的注意力权重,从而学习到不同节点之间的关联模式。相反,GCN采用固定的邻居聚合策略,在信息传递过程中使用相同的权重分配。常用基于深度学习的方法总结如表2所示。
3 "命名实体识别的深度学习架构
在深度学习环境下,NER通常被视为一个序列标注问题。在序列标注中,针对输入序列(通常是文本句子),模型需要为每个输入元素(通常是单词或字符)预测一个标签,这个标签可以是命名实体类别,也可以是其他类型的标记,如词性标注、情感分析等。在NER中,模型的目标是预测输入句子中每个单词的命名实体标签,例如人名、地名、组织名等。因此,NER问题也可以被视为多类分类问题的一种,其中每个输入元素需要被分类为多个标签中的一个或多个。
如本文在第2节中所述,在解决NER问题时,常见的深度学习网络,如CNN、RNN、LSTM通常被用于学习输入序列中的上下文信息,并对每个输入元素进行分类。相较于传统的神经网络,近些年来出现的一些基于预训练模型的NER方法如BERT、RoBERTa等,和结合图神经网络的方法,往往具备更好的性能。
深度神经网络用于NER是由CNN⁃CRF模型[21]开创的,其中CNN用于获取输入文本的特征,可以理解为编码器,而CRF层则作为解码器,用于生成对应的标签。通过应用固定大小的上下文窗口,该模型在NER任务中F1值高达89.59%。
J. P. C. Chiu等也提出一种使用CNN从字符嵌入中提取字符特征和每个单词的字符类型特征的方法[50]。这些字符向量与单词嵌入和额外的单词级特征连接在一起,然后将级联的输入提供给多层LSTM,其中每一层依次彼此连接。在每个时间步,线性层和log⁃softmax层都通过解码每个前向层和后向层的输出来分别计算每个标签类别的对数概率(向量)。最后,将这两个向量求和以产生最终输出。除此之外,DBpedia中已知命名实体的列表也被用作外部知识源。
迭代扩张卷积神经网络(Iterated Dilated CNN, ID⁃CNN)是一种基于CNN的模型,与传统的CNN不同之处在于,它可以对输入进行多次迭代。在NER任务中,E. Strubell等人使用ID⁃CNN和CRF混合模型进行序列标记,其中ID⁃CNN被用于提取单词级别的特征,而CRF则用于对整个序列进行结构化的预测[51]。相比于其他前沿模型,ID⁃CNN允许固定长度的卷积在输入中并行运行,具有更好的处理较大上下文和结构化预测的能力,并且可以充分利用GPU的并行机会,实现更快的序列标记过程。相较于CNN,Huang等人提出一系列基于RNN的NER任务模型[22],这些模型包括LSTM、Bi⁃LSTM、LSTM⁃CRF和Bi⁃LSTM⁃CRF。在Bi⁃LSTM⁃CRF中,词嵌入和额外的单词特征(如拼写和上下文特征)被输入到Bi⁃LSTM网络中,以产生单词级别的表示。然后,该单词级别表示被传递到CRF层,以预测输出标签。相较于CNN⁃CRF模型,Bi⁃LSTM⁃CRF模型对词嵌入的依赖性较小,F1值也达到90.10%。
除前文提到的Lample、Ma和Hovy等人在Bi⁃LSTM上的工作外,Yao等人也通过提出一个轻量级架构“CNN⁃CNN⁃LSTM模型”,为NER任务引入深度主动学习算法,该模型由卷积字符、单词编码器以及LSTM标签解码器组成[52]。在这项工作中,他们证明通过深度主动学习可以大幅减少标记数据的数量。该模型通过Word2Vec训练的潜在词嵌入进行初始化,并且在训练期间对这些词嵌入进行微调。基于深度学习的NER模型总结如表3所示。
4 "研究趋势
从谷歌Word2Vec到最近的BERT模型,NER从深度学习的进步中受益匪浅。预训练的词嵌入允许开发不需要复杂特征工程的深度学习模型。这些进步不仅为NER带来新的挑战,同时也为潜在的未来研究方向提供机会。
4.1 "中文NER
相对于英文,中文的标注数据较少,这给深度学习模型的训练带来了一定的困难。缺乏大规模高质量的标注数据限制了深度学习在中文NER任务中的性能表现。此外,中文拥有丰富的词汇和复杂的语法结构,给深度学习模型的训练带来了一定的困难。在中文NER任务中,需要解决命名实体的边界识别、实体类型多样性和歧义性等问题,这进一步提高了任务的难度[53]。另外,中文命名实体通常由多个字符组成,而字符级别的特征表示相对较弱。由于缺乏准确建模上下文信息,可能导致对命名实体的识别和分类产生误判。
同时,中文文本中经常出现多个实体嵌套的情况,即一个实体包含另一个实体。如何准确识别和处理这种嵌套实体关系,以捕捉更准确的实体边界和层次结构,是中文NER中的一个关键问题。
随着语言建模技术的不断改进和现实世界的应用对更复杂的自然语言处理的需求,NER将越来越受到研究人员的关注。然而,NER通常被视为下游应用程序的预处理组件和特定NER任务的要求,如实体类型和嵌套实体的检测,都由这些应用程序的需求决定。此外,由于数据注释的固有挑战,包括质量、一致性和复杂性问题,开发更高效的注释方法对于推进NER研究至关重要。基于这项调查的结果,本文列出以下NER研究的进一步探索方向。
4.2 "细粒度NER和边界检测
对现实世界应用的需求使得细粒度的NER和边界检测成为研究人员关注的领域。尽管现有的许多文献都集中在一般领域的粗粒度NER[31⁃32,54],但本文认为有必要在特定领域对细粒度NER进行更多研究,以支持各种实际的单词应用。细粒度NER面临的挑战是,当命名实体具有多个实体类型时,实体类型的数量和复杂性会显著增加。这需要重新评估常见的NER方法,这些方法通常使用B⁃I⁃e⁃S(实体类型)和O等解码标签同时检测实体边界和类型。其中,一种方法是将实体边界检测定义为一种专门任务,用于检测实体的边界,同时忽略实体类型。边界检测和实体类型分类的解耦是实现边界检测的更通用和稳健的解决方案。该解决方案可以在不同的领域之间共享,并为实体类型分类提供专门的领域特定方法。准确的实体边界也有效地减少了实体链接到知识库中错误的传播。尽管一些研究将实体边界检测作为NER[55⁃56]的一个中间步骤(即子任务),但目前还没有专门关注实体边界检测以提供鲁棒识别器的现有工作。
4.3 "多模态NER
实际应用场景中的数据通常是多样化的,实体识别不仅仅取决于文本本身,还与其他模态的信息,如图像、音频和视频等相关联。引入多模态数据可以更好地捕捉这些信息,并且提高NER的性能。例如:在医疗领域,医学图像和临床报告都可以提供对疾病和治疗的关键信息;在社交媒体分析中,文本和图像可以相互补充,帮助确定实体的边界和类型。多模态NER结合多种类型的数据,以便更全面地描述实体,并提高识别的准确性。
4.4 "时空图
时空图是一种用于序列数据处理的图形结构,其中节点表示时间步长,边表示时间步长之间的依赖关系。在深度学习中,时空图常用于语音处理、自然语言处理、图像处理等领域中的序列数据。在NER任务中,时空图可以用于识别文本中的命名实体,如人名、地名、组织机构等。通过将文本表示为时空图,可以更好地理解文本中实体之间的关系,并提高实体识别的准确性和效率。
5 "结 "语
本文主要介绍基于深度学习的NER技术的研究背景、研究现状以及NER的深度学习架构,并介绍基于卷积神经网络、循环神经网络、Transformer模型和图神经网络模型的命名实体识别方法。最后,本文讨论基于深度学习的命名实体识别技术未来可能会面临的研究趋势。随着深度学习技术的不断发展和应用,基于深度学习的NER技术已经取得令人瞩目的进展和很好的效果。未来可以继续探索更加有效的编码器、解码器和特征提取方法,同时结合领域知识和先验信息,进一步提高NER任务的性能。此外,也可以将基于深度学习的NER技术应用到更多的场景中,为信息处理和人机交互等领域提供更加优质的服务。
注:本文通讯作者为钱育蓉。
参考文献
[1] 刘源,刘胜全,常超义,等.基于依存图卷积的实体关系抽取模型[J].现代电子技术,2022,45(13):111⁃117.
[2] 冯宇航,邵剑飞,张小为,等.基于特征融合的中文新闻文本情感分类方法研究[J].现代电子技术,2023,46(3):62⁃68.
[3] 郑文丽,熊贝贝,林燕奎,等.基于上下文感知自适应卷积网络的实验室文本分类[J].现代电子技术,2023,46(13):85⁃90.
[4] 王艺皓,丁洪伟,王丽清,等.基于BERT的情感分析研究[J].现代电子技术,2021,44(9):110⁃114.
[5] 帅训波,石文昌,冯梅,等.面向用户体验增强的信息检索评估模型研究[J].电子技术应用,2023,49(8):88⁃92.
[6] 张少迪,艾山·吾买尔,郑炅,等.高并发汉英信息抽取系统的设计与实现[J].现代电子技术,2019,42(16):104⁃107.
[7] LIU A T, XIAO W, ZHU H, et al. QaNER: prompting question answering models for few⁃shot named entity recognition [EB/OL]. [2022⁃01⁃11]. https://arxiv.org/pdf/2203.01543.pdf.
[8] MOTA P, CABARRÃO V, FARAH E. Fast⁃paced improvements to named entity handling for neural machine translation [C]// Proceedings of the 23rd Annual Conference of the European Association for Machine Translation. Ghent, Belgium: ACM, 2022: 141⁃149.
[9] VEENA G, KANJIRANGAT V, GUPTA D. AGRONER: An unsupervised agriculture named entity recognition using weighted distributional semantic model [J]. Expert systems with applications, 2023, 229: 120440.
[10] 高翔,王石,朱俊武,等.命名实体识别任务综述[J].计算机科学,2023,50(z1):26⁃33.
[11] SANG E F T K, DE MEULDER F. Introduction to the CoNLL⁃2003 shared task: language⁃independent named entity recognition [J]. Development, 1837, 922: 1341.
[12] DODDINGTON G R, MITCHELL A, PRZYBOCKI M, et al. The automatic content extraction (ACE) program–tasks, data, and evaluation [EB/OL]. [2023⁃02⁃14]. http://www.lrec⁃conf.org/proceedings/lrec2004/pdf/5.pdf.
[13] DEMARTINI G, IOFCIU T, DE VRIES A P. Overview of the INEX 2009 entity ranking track [C]// Focused Retrieval and Evaluation: 8th International Workshop of the Initiative for the Evaluation of XML Retrieval. Schloss Dagstuhl: Springer, 2010: 254⁃264.
[14] BALOG K, SERDYUKOV P, VRIES A P. Overview of the TREC 2010 entity track [EB/OL]. [2022⁃07⁃14]. https://www.xueshufan.com/publication/3013426078.
[15] RAU L F. Extracting company names from text [C]// 1991 Proceedings. The Seventh IEEE Conference on Artificial Intelligence Application. [S.l.]: IEEE, 1991: 29⁃32.
[16] 张小衡,王玲玲.中文机构名称的识别与分析[J].中文信息学报,1997(4):22⁃33.
[17] FARMAKIOTOU D, KARKALETSIS V, KOUTSIAS J, et al. Rule⁃based named entity recognition for Greek financial texts [C]// Proceedings of the Workshop on Computational Lexicography and Multimedia Dictionaries. Greece: University of Patras, 2000: 75⁃78.
[18] 王宁,葛瑞芳,苑春法,等.中文金融新闻中公司名的识别[J].中文信息学报,2002(2):1⁃6.
[19] BIKEL D M, MILLER S, SCHWARTZ R, et al. Nymble: a high⁃performance learning name⁃finder [C]// 5th Applied Natural Language Processing Conference. Washington, USA: ACL, 1997: 194⁃201.
[20] NADEAU D, TURNEY P D, MATWIN S. Unsupervised named⁃entity recognition: Generating gazetteers and resolving ambiguity [C]// Advances in Artificial Intelligence: 19th Conference of the Canadian Society for Computational Studies of Intelligence. Québec, Canada: Springer, 2006: 266⁃277.
[21] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural language processing (almost) from scratch [J]. Journal of machine learning research, 2011, 12: 2493⁃2537.
[22] HUANG Z, XU W, YU K. Bidirectional LSTM⁃CRF models for sequence tagging [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery amp; Data Mining. New York: ACM, 2018: 1049⁃1058.
[23] LE CUN Y, BOSER B, DENKER J, et al. Handwritten digit recognition with a back⁃propagation network [C]// Proceedings of the 2nd International Conference on Neural Information Processing Systems. Cambridge: ACM, 1989: 396⁃404.
[24] MEDSKER L R, JAIN L C. Recurrent neural networks [J]. Design and applications, 2001, 5: 64⁃67.
[25] HOCHREITER S, SCHMIDHUBER J. Long short⁃term memory [J]. Neural computation, 1997, 9(8): 1735⁃1780.
[26] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 6000⁃6010.
[27] WALLACH H M. Conditional random fields: an introduction [J]. Technical reports, 2004, 53(2): 267⁃272.
[28] MIKOLOV T, DEORAS A, POVEY D, et al. Strategies for training large scale neural network language models [C]// 2011 IEEE Workshop on Automatic Speech Recognition amp; Understanding. Waikoloa: IEEE, 2011: 196⁃201.
[29] LEE H Y, TSENG B H, WEN T H, et al. Personalizing recurrent⁃neural⁃network⁃based language model by social network [J]. IEEE/ACM transactions on audio, speech, and language processing, 2016, 25(3): 519⁃530.
[30] MA X, HOVY E. End⁃to⁃end Sequence Labeling via Bi⁃directional LSTM⁃CNNs⁃CRF [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: ACM, 2016: 1064⁃1074.
[31] AGUILAR G, MAHARJAN S, LÓPEZ⁃MONROY A P, et al. A multi⁃task approach for named entity recognition in social media data [J]. W⁃NUT, 2017, 2017: 148.
[32] WU Y, JIANG M, LEI J, et al. Named entity recognition in Chinese clinical text using deep neural network [J]. Studies in health technology and informatics, 2015, 216: 624.
[33] KURU O, CAN O A, YURET D. Charner: Character⁃level named entity recognition [C]// COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference. Osaka, Japan: ACL, 2016: 911⁃921.
[34] WAN Q, LIU J, WEI L, et al. A self⁃attention based neural architecture for Chinese medical named entity recognition [J]. Mathematical biosciences and engineering, 2020, 17(4): 3498⁃3511.
[35] PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014: 1532⁃1543.
[36] CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder⁃decoder for statistical machine translation [EB/OL]. [2023⁃02⁃25]. http://www.arxiv.org/pdf/1406.1078.pdf.
[37] REI M, CRICHTON G K O, PYYSALO S. Attending to characters in neural sequence labeling models [EB/OL]. [2023⁃01⁃12]. http://arxiv.org/pdf/1611.04361.
[38] YANG Z, SALAKHUTDINOV R, COHEN W. Multi⁃task cross⁃lingual sequence tagging from scratch [EB/OL]. [2023⁃11⁃05]. http://arxiv.org/pdf/1603.06270.
[39] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre⁃training [EB/OL]. [2022⁃12⁃07]. https://www.docin.com/p⁃2176538517.html.
[40] KENTON J D M W C, TOUTANOVA L K. BERT: pre⁃training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, MN, USA: Association for Computational Linguistics, 2019: 4171⁃4186.
[41] RONG X. Word2vec parameter learning explained [EB/OL]. [2022⁃11⁃09]. http://www.arxiv.org/pdf/1411.2738.pdf.
[42] LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. [2022⁃11⁃20]. https://www.xueshufan.com/publication/2965373594.
[43] LAN Z, CHEN M, GOODMAN S, et al. Albert: A lite bert for self⁃supervised learning of language representations [C]// International Conference on Learning Representations. Addis Ababa: ICLR, 2020: 102⁃108.
[44] YANG Z, DAI Z, YANG Y, et al. XLNet: Generalized autoregressive pretraining for language understanding [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, BC, Canada: 5753⁃5763.
[45] HANH T T H, DOUCET A, SIDERE N, et al. Named entity recognition architecture combining contextual and global features [C]// Towards Open and Trustworthy Digital Societies: 23rd International Conference on Asia⁃Pacific Digital Libraries. Cham: Springer, 2021: 264⁃276.
[46] TANG Z, WAN B, YANG L. Word⁃character graph convolution network for chinese named entity recognition [J]. IEEE/ACM transactions on audio, speech, and language processing, 2020, 28: 1520⁃1532.
[47] CHEN C, KONG F. Enhancing entity boundary detection for better chinese named entity recognition [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. [S.l.]: Springer, 2021: 20⁃25.
[48] WANG Y, LU L, WU Y, et al. Polymorphic graph attention network for Chinese NER [J]. Expert systems with applications, 2022(11): 117467.
[49] TIAN X, BU X, HE L. Multi⁃task learning with helpful word selection for lexicon⁃enhanced Chinese NER [J]. Applied intelligence: the international journal of artificial intelligence, neural networks, and complex problem⁃solving technologies, 2023(16): 53.
[50] CHIU J P C, NICHOLS E. Named entity recognition with bidirectional LSTM⁃CNNs [J]. Transactions of the association for computational linguistics, 2016, 4: 357⁃370.
[51] STRUBELL E, VERGA P, BELANGER D, et al. Fast and accurate sequence labeling with iterated dilated convolutions [EB/OL]. [2023⁃04⁃01]. https://arxiv.org/abs/1702.02098v1.
[52] YAO L, LIU H, LIU Y, et al. Biomedical named entity recognition based on deep neutral network [J]. International journal of hybrid information technology, 2015, 8(8): 279⁃288.
[53] 赵继贵,钱育蓉,王魁,等.中文命名实体识别研究综述[J].计算机工程与应用,2024,60(1):15⁃27.
[54] ROJAS M, BRAVO⁃MARQUEZ F, DUNSTAN J. Simple yet powerful: an overlooked architecture for nested named entity recognition [C]// Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju, Republic of Korea: International Committee on Computational Linguistics. 2022: 2108⁃2117.
[55] GHADDAR A, LANGLAIS P. Robust lexical features for improved neural network named⁃entity recognition [EB/OL]. [2023⁃01⁃27]. http://arxiv.org/abs/1806.03489.
[56] ZHAI F, POTDAR S, XIANG B, et al. Neural models for sequence chunking [C]// Proceedings of the Thirty⁃First AAAI Conference on Artificial Intelligence. San Francisco, California, USA: AAAI, 2017: 3365⁃3371.
猜你喜欢
计算机应用(2016年12期)2017-01-13 20:26:21
计算机应用(2016年12期)2017-01-13 01:24:36
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
电脑知识与技术(2016年10期)2016-06-16 21:16:32
电脑知识与技术(2016年5期)2016-04-14 11:12:38
科技视界(2016年5期)2016-02-22 11:41:39
