
增强问句和文本交互的答案抽取方法
2024-09-14 00:00:00邓涵
现代电子技术 2024年6期





摘 "要: 答案抽取对提高问答的质量和性能有着重要的作用,但现有的答案抽取方法存在问句和文本信息交互的问题。结合上下文的答案抽取模型虽然可以从文本中抽取出给定问题的答案,但这种抽取方法并未考虑文本和问句的信息交互。而只有问句和文本数据时,要从文本中获取更加精准的问句答案,可以利用问句和文本之间的语义信息,预测问句与文本实体之间的关联。基于此,使用问句对齐层和多头注意力机制构建一个交互文本和问句之间的信息模型。实验结果表明,相较于BIDAF⁃INDEPENDENT模型,改进后模型的EM值和F1值分别提高了1.281%和1.296%。
关键词: 答案抽取; 问答系统; 信息交互; 语义信息; 深度学习; 多头注意力机制
中图分类号: TN919.6+5⁃34; TP391 " " " " " " " " " 文献标识码: A " " " " " " " " 文章编号: 1004⁃373X(2024)06⁃0179⁃08
Method of answer extraction for enhancing question and text interaction
DENG Han
(Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China)
Abstract: The question answering quality and performance are significantly enhanced by means of the answer extraction. The existing answer extraction methods suffer from the problem of interaction between questions and text information. The answer extraction model that combines context can extract the answer to a given question from the text, but this extraction method does not consider the information interaction between the text and the question. When there is only question and text data, to obtain more accurate question answers from the text, the semantic information between the question and the text can be used to predict the association between the question and the text entity. When there is only question and text data, the semantic information between the question and the text can be used to predict the association between the question and the text entity, so as to to obtain more accurate question answers from the text. On this basis, a question alignment layer and multi head attention mechanism are used to construct an information model between interactive text and questions. The experimental results show that, in comparison with the BIDAF INDEPENDENT model, the improved model has an increase of 1.281% in EM value and 1.296% in F1 value, respectively.
Keywords: answer extraction; Qamp;A system; information exchange; semantic information; deep learning; multi head attention mechanism
0 "引 "言
MRC(机器阅读理解)作为自动化学习的重要组成部分,其主要任务就是帮助计算机深入了解并准确地应对特定的文本内容,从而达到预期的学习效果。这个任务通常包括两个关键方面:文本理解和问题回答。MRC的核心目标是通过分析给定的上下文提取出有效的信息,以便更好地解决问题。
为此,目前已经有多个国际公开的数据集[1]可供使用,如SQuAD、MS⁃MARCO[2]、NewsQA[3]、TriviaQA[4]等。2016年,斯坦福大学的研究人员Rajpurkar发布了一个名为SQuAD的问答数据集[5],它不仅提供了一些具有挑战性的问题,而且还提供了一系列可以从给定文本中获得正确答案的令牌序列。
阅读理解任务不仅要求计算机能够提取关键信息、理解句子和段落的含义,还需要理解问题的意思并准确回答问题。因此,阅读理解任务可以有不同的形式,例如抽取式问答和生成式问答。抽取式问答要求计算机从给定文本中选择合适的答案,而生成式问答则要求计算机基于理解的内容生成自己的答案。
在大多数基准数据集中,问题可以被看作多项选择问题,其正确答案将从一组提供的候选答案中选择,这属于抽取式问答。根据现有大量实验推测,具有更多给定候选答案的问题更具有挑战性。SQuAD数据集自提出以来就引起了学术界的极大关注,使得阅读理解任务成为问答技术研究的热门,它也成为了抽取式问答技术核心的基准数据集,并推动了一大批抽取式阅读理解模型的研究。随后,若干大规模问答数据集被相继提出,如MS⁃MARCO、NewsQA以及TriviaQA等,以扩充阅读理解的任务形式,也不断催生新的问答模型的产生。此外,与其他一些以完形填空形式去自动创建问题和答案的数据集不同,SQuAD中的问题和答案是由人类通过云检索创建的,这使得数据集更加真实。鉴于SQuAD数据集的这些优势,在本文中专注于这个新的数据集来研究文本机器理解中的答案抽取任务。
神经阅读理解技术是一种利用深度神经网络来处理复杂的语言现象的技术,它可以有效地提升阅读理解的准确性和效率[6],而且这种技术的优势远远超过了传统的人工设计的模型,它可以帮助人们更好地理解和处理复杂的语言现象。
开放域问答系统中,答案抽取是一项非常重要的任务,它旨在从给定的文本中提取出准确的答案,并且能够根据文本内容创建出更加复杂的答案。一般来说,系统会先以一段文本形式呈现,比如新闻、故事等,然后期待机器回答与文本相关的一个或多个问题。
通过对以上背景和方法的研究与分析,本文将增强问句和文本信息用于深度学习网络,提出一种节省内存、训练更快的增强问句和文本交互的答案抽取方法(Answer Extraction Method for Enhancing Question and Text Interaction, AEMEQA)。AEMEQA是一种基于多种神经网络的深度学习技术,它可以帮助机器学习者更好地理解和处理复杂的信息,其中包括双向长短期记忆网络(BiLSTM)、多头注意力网络和GloVe预训练模型,它们可以帮助机器更加准确、高效地完成任务。AEMEQA将多种独立的学习环节,如编码、特征提取、文本⁃问题交互以及答案抽取等整合到一个统一的深度学习框架中,从而构建出一种全新且可以被广泛应用的阅读理解网络。
1 "相关概念
1.1 机器阅读理解
机器阅读理解的核心任务包括:完成多项选择题,提取关键信息并进行自主回答,其中完形填空测试通过从段落中删除一些单词或实体来生成问题。完形填空测试是一项极具挑战性的任务,因为它要求机器人填写空白部分,并且需要理解上下文和词汇用法。这种测试不仅会增加阅读难度,还会让机器人面临更大的挑战。完形填空测试的最显著特征是答案来自于上下文段落中的单词或实体,此任务可以视为单词或实体的预测。多项选择是一种更加灵活的考试方式,它不仅要求考生根据上下文段落中的单词或实体来选择正确的答案,而且还要求考生能够根据自己的理解和判断,从多个可能的答案中挑选出最合适的[7]。
虽然完形填写和多项式挑战考验了人类在处理自然语言方面的表现,但它们仍存在一定的局限。例如,在一些特定的场景中,如果一个单词无法准确地表达意思,而且在许多情境下也无法找到合适的替代方案,就必须使用一个完整的句子。而通过进行跨域抽样,能够有效地解决这些问题,这个过程需要根据特定的背景知识来抽样一段文字,并将其用于回答特定的问题。
跨度提取任务的出现大大改善了机器学习解决问题的能力,它不仅可以提供更加灵活的答案,而且可以从多个上下文中获取有效的数据,从而使机器能够更加准确地回答问题。在这4个任务中,自由回答是最具挑战性的,它的表达方式不受任何限制,而且更加符合实际的应用需求。图1所示为跨度提取任务的SQuAD数据集示例。
总而言之,完形填写题目可以轻松地创建一组数据,以便对其进行评估。然而,由于题目的表达方式只局限于一些特定的字母和字母组合,因此,它们难以准确地反映出人类的阅读和写作技巧,也难以满足日常的使用需求。多项选择是检验学生能力的一种有效方法,无论在解决什么样的问题时,都能够通过多种方式获得有价值的信息。这种方法的优势在于能够快速地收集和分析大量的信息,从而更好地判断学生的能力。但该方法的候选答案导致合成数据集和实际应用之间存在差距。自由回答任务在理解、灵活性和应用范围方面很有优势,这是最接近实际应用的,但是其回答形式灵活,很难构建数据集,因而如何有效评估这些任务的性能仍然是一项挑战。相比之下,跨度提取任务是一个适度的选择,其数据集易于构建和评估,并且接近实际应用[6]。
1.2 注意力机制
引入注意力机制(Attention Mechanism)可以充分利用计算资源,从而克服信息超载的困境[8],提升神经网络的性能。此外,随着模型的参数增加,其可以提供的表示效果和可用的信息量也有所增加,从而减少了信息的负担。采用注意力分配技术将大量的外部资源集中到当前任务的核心部分,减少对外部资源的依赖,可以有效地抑制外部资源的干扰,从而有助于缓解资源的紧张状态,进而极大地提高任务的完成速度与精确度。这种方法的应用就像人类的眼睛一样,能够观察整个画面,找到想要的焦点,然后集中精力去捕捉它,并且不会放弃任何一个不相干的部分,在有限的时间内,迅速地提炼出最具价值的内容。
注意力机制并不是一种特定的神经网络结构,而是一种通用的机制,可以应用于不同的神经网络结构中。比如,可以在卷积神经网络中使用注意力机制来关注输入图像中的重要区域,也可以在循环神经网络中使用注意力机制来关注输入序列中的重要部分。一般来说,注意力机制可分为自我调节(Self⁃Attention)、多头调节(Multi⁃head Attention)等多种形式,它们的基本原理可归纳为三个步骤:
1) 计算每个输入位置的注意力权重。这个权重可以根据输入数据的不同部分进行加权,即对不同部分赋予不同的权重。权重的计算通常是基于输入数据和模型参数的函数,可以使用不同的方式进行计算,比如点积注意力、加性注意力、自注意力等。
2) 将每个输入位置的权重与其他输入位置的权重相乘,从而得到一个加权的输入表示,它能够更准确地反映出输入数据中的关键信息,从而提高模型的准确性和可靠性。
3) 根据加权的输入表示和其他模型参数计算输出结果,这个输出结果可以作为下一层的输入,也可以作为最终的输出。
2 "相关工作
2.1 "神经阅读理解
近年来,机器读写理解能力的研究取得了巨大的进展,这得益于两个重要的推动力:一是大量的读写理解能力数据的收集;二是基于端口的机器学习技能的深入理解模式的开发。这些技术的开发可以使机器学习的效果得到显著改善,同时,机器学习技术的改善更有利于应对机器学习所面临的挑战和难度。
当前,许多神经网络信息技术如循环神经网络(Recurrent Neural Network, RNN)[9]、卷积神经网络(Convolutional Neural Network, CNN)[10]和注意力机制技术,已经被广泛应用于神经阅读和理解领域,并取得了显著的进展。在编码领域,GPT和BERT使用Transformer架构,而其余的模拟则使用LSTM、GRU(Gated Recurrent Unit networks)、 CNN等信息技术[11]。编码层主要是采用双向长短期记忆网络方法和双向门控循环单元,并且采取较多的技术手段来改善模型的可识别性;而在交互层,学术界正致力于探索一种更为灵活的方法,既可以利用传统的注意力机制,也可以利用新的自适应技术,以改善模型的表现。
BiDAF模型是一种重要的神经阅读理解模型[12],它通过总结前人的研究成果,提出了双向注意力机制这一概念。这一概念首次将双向注意力机制纳入BiDAF模型,以表征上下文中哪些单词与问题中的单词有最大的相关性。BiDAF模型具有灵活的输出层编码能力,能够有效地处理各种复杂的数据集。
文献[13]将Maxout网络[14]及Highway网络[15]的特性有机地融入到BiDAF的研究中,并以HMN(Highway Maxout Network)为核心,构建出具有高度灵活性的DCN模型。Chen和其他研究者提出的DrQA模型旨在支持开放式的阅读理解[16],它首先使用Document Retriever 搜寻与问题有关的文本,接着使用Document Reader查询文本,并以Wikipedia为基础,最终将结果输入SQuAD1.1的数据库,以实现有效的学习。DrQA在这方面取得了巨大的进步,它首次将命名实体识别和其他特征融合在一起,取得了巨大的成就。
D. Weissenborn等学者指出,当前的神经网络阅读理解技术存在着较大的复杂性,其中包括两个主要部分:一个用来构建文本序列的模型,另一个则用来处理段落与相关的问题[17]。因此,他们提出了轻量级的模型FastQA。FastQA利用RNN编码技术将复杂的段落与简单的问题结合起来,并利用定向搜索(beam⁃search)技术提取出有效的答案。
R⁃Net模型被认为是神经阅读理解领域的里程碑[18],它首次将自我调节的概念引入到模型的第2个交互层,以便更好地识别和处理包含相关知识的句子,并且能够更好地预测句子的长度和复杂度。R⁃Net的出色表现,自我调节能力变得更加重要,因此,它已被广泛应用于各种神经网络学习和认知领域,并且被认定是未来发展中的必备技术。
2.2 "多头注意力机制
多头注意力(Multi⁃Head Attention)是注意力机制的一种扩展形式,可以在处理序列数据时更有效地提取信息,结构如图2所示。
在标准的注意力机制中,计算一个加权的上下文向量来表示输入序列的信息。而在多头注意力中,使用多组注意力权重,每组权重可以学习到不同的语义信息,并且每组权重都会产生一个上下文向量。最后,这些上下文向量会被拼接起来,再通过一个线性变换得到最终的输出[8],公式为:
[headi=AttentionQWQi,KWKi,VWVi] "(1)
根据图2可以看出,在进行线性变换时,需要进行h次,即多头。在Query、Key、Value等关系中,头与头的参数独立,而且在进行线性变换时,头与头的参数W会有差异。通过h次的放大和减小,可以构建出一个具有多个输入的集合,并通过线性变换来获取它们的最终形式。这种方法可以让本文模型从各种不同的输入中获取有用的信息,具体公式如下:
[MultiHeadQ,K,V=Concathead1,head2,…,headhWO] (2)
3 "深度学习实验模型
3.1 深度学习框架
利用深度学习技术建立一种新的机器学习和认知框架。根据图3机器阅读理解系统的基础构架,一个典型的机器学习系统由4个部分组成:嵌入、特征提取、上下文⁃交互以及预测。它能够根据上下文和问题的信息,自动生成有效的答案。
由于机器无法直接学习和认知自然语言,故MRC系统最初由嵌入模块将输入单词更改为固定长度的向量是必不可少的。该模块以上下文和问题为输入,通过各种方法输出上下文嵌入和问题嵌入。通常使用的经典单词表示方法one⁃hot或word2vec有时将其与其他语言功能结合使用,如词性标注、命名实体识别和问题类别等,以表示单词中的语义和句法信息。此外,由大型语料库预训练的上下文化词表示法在编码上下文信息方面也显示出优异的性能。
通过将相关的数据嵌入到神经网络模块,可以获得有关上下文的详细信息。这可以通过循环神经网络(RNN)或者卷积神经网络(CNN)来实现,它们可以有效地收集并分析这些数据,以便对这些数据有所洞察。
MRC系统通过利用单向或双向注意力机制,可以有效地检测出上下文⁃问题交互模块中的相关性,从而更准确地预测出最终的答案。这种方法可以帮助机器更好地理解问题,并且更快地找到最有效的解决方案。为了更好地探索上下文与问题之间的联系,可能会进行多次跳转,以模拟人类的思维过程,从而更深入地理解它们。
MRC系统的最后一个功能是答案预测,其能够将所有已经收集的数据按照特定的方法和结果有效地划分成多个子任务[6],并且能够快速准确地提供给用户。例如,在完形填写题目中,这个模块能够快速提供准确的结果,使用户能够更加轻松地获得所需的知识。这个模块专门针对特殊情况,它可以从特殊的上下文中抽取信息,并使用Wang等人提出的边界模型[19]来估算问题的起点和终点;它还可以使用一些特殊的算法来解决这些问题,且这些算法可以根据特殊情况进行调整。
大多数基于端到端神经网络的机器学习模型都采用4层架构[20],如图4所示。
图4中,嵌入层包括字符、词、上下文以及特征级别,它们分别代表C维的词汇和d维的问题;另一些模型则利用注意力机制,将问题的词汇信息融入上下文段落[21],以便更好地理解上下文内容。接着,模型会将预先嵌入的上下文和问句输入到编码层,并利用循环或卷积神经网络来提取其中的内在特征,最终通过注意力机制生成能够反映上下文段落的表达或者能够反映出上下文段落的问题表达[12]。本文使用一种新的模型来处理问题和上下文的关系。这种模型使用自注意力机制来捕捉这些关系中的信息,并将它们融合到一起;再使用循环或卷积神经网络来解码这些关系,并生成一个最终的表示。根据最终任务的类型,输出层将会有不同的表示方式。
3.2 "实验模型结构
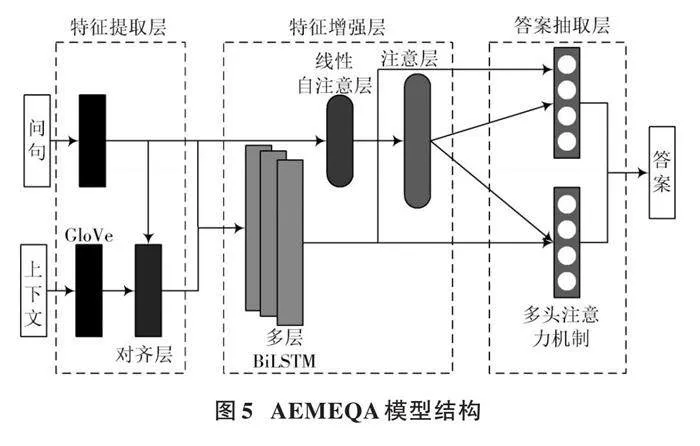
鉴于深度学习强大的泛化能力和特征提取能力,AEMEQA模型主要由特征提取层、特征增强层、答案抽取层三部分组成,其结构如图5所示。
首先,需要为给定的上下文和问题创建一个虚拟词典,通过访问训练集和测试集来获取已知的答案,并将它们作为标签;然后,在数据集中创建一个词汇表,并将这些文本和问题逐一输入到模型中,模型对预处理后的上下文和问句进行特征提取,将答案抽取任务视为输入的文本和问句的一个匹配任务,抽取出文本的语义信息和问句的语义信息,比较两者的相关性,将融合问句信息后的文本信息和问句作为输入特征,调节网络参数;最后,模型进行答案抽取。在上述训练完成后,将数据输入深度学习网络,深度学习网络进行计算处理后输出预测答案的开始和结束位置,并与预训练得到的答案位置标签进行比较,判断答案抽取结果是否正确。
3.2.1 "预处理
对数据集的文本和问句中离群值进行检索并删除,对文本中的单词建立词汇表,将用于训练集和验证集的文本和问句数字化;再检索删除字符级错误以及由于空格等原因出现的错误数据;最后从文本中得到答案的开始和结束位置,作为训练问答系统模型的基本标签。输入训练的数据包含已经处理成令牌级别的文本和令牌级别的问句,以及从文本段落本身所得到答案的起始位置和结束位置。问句数据示例如图6所示。
3.2.2 "特征提取
预处理之后的问句和文本通过使用预训练的GloVe模型词向量初始化的嵌入层传递,其中GloVe模型是840 B网络爬虫版本的300维向量版本,有220万个单词的词汇量。针对存在于数据集中但是不存在于GloVe预训练模型词汇中的单词,即词汇表外单词,由零向量进行初始化。这些词向量用于将单词投影转换为浮点向量,该浮点向量将与词相关的各种特征编码为其维度。这种转换是十分必要的,因为计算机不能直接将单词作为字符串处理,但可以无缝地处理大量的浮点矩阵。通过这样的转换,语义相似的单词向量之间的点积接近于1,反之,越不相似的单词向量之间的点积接近于0。
本文针对上下文文本和问句有不同的编码程序,文本的编码更加详细彻底。上下文文本问句对齐层包括以下额外的特征:
1) 精确匹配(Exact Match, EM),指的是如果可以完全匹配到一个原始、引理或者小写形式的相关单词,对其进行二进制特征处理和编码,得到一个准备匹配的结果。
2) 令牌特征,包括文本段令牌级的词性标注、实体识别和词频表示,以及问句对齐嵌入。在上下文文本问句对齐层中,主要是实现了与问句的对齐嵌入。将计算向量化并直接处理张量,是问句嵌入的加权表示,此操作使模型能够了解文本上下文的哪一部分对于问题更重要或更相关。当问句和文本上下文中的相似单词相乘时,可确保在标记级别进行预测的乘积有更高的值,这是通过反向传播和训练密集层的权重来实现的。在实现时,首先计算文本上下文和问句向量的投影;然后使用torch.bmm来计算分子中的乘积,对乘积进行掩码;最后通过softmax函数将结果与问句嵌入进行相乘。该层输出一个附加的文本上下文嵌入,然后与GloVe嵌入连接起来。
经过上下文问句对齐层的处理,文本向量具备了两个独特的特性:GloVe模型嵌入和问句对齐嵌入。这些特性被传递到三层双向长短期记忆网络层,在这里,每层都会收集隐藏单元的数据,并将其串联起来,以实现更加高效的信息处理。通过前向传播,循环遍历LSTM,存储每层的隐藏状态,最后返回串联输出。
线性自注意层用于对问句进行编码,比前面的层更加简洁。令牌级的问句首先经过GloVe嵌入层,然后经过多层双向长短期记忆网络层,最后到达这一层。该层用于计算问句中每个单词的重要性,通过在输入上采用softmax函数来实现。但是为了向模型添加更多的学习能力,问句向量还需要输入并乘上可训练的权重向量,然后再通过一个softmax函数。本质上,该层正在对输入执行“注意”这一行为。
平均权重层则是将线性自注意层所计算的权重乘以问句通过多层双向长短期记忆网络层的输出,这使得模型可以为每个问题中的重要单词分配更高的值。
3.2.3 "抽取答案
处理过的文本向量和问句向量分别输入到两个多头注意力网络,从文本上下文中返回答案的开始和结束位置。多头注意力机制将每个头所输出的结果拼接起来,然后再通过一个线性层映射成一个输出,针对每个注意力,每个头筛选到的信息不同,信息越丰富,越有利于最终模型取得更好的效果。
4 "实验设置
4.1 实验数据集
4.1.1 "数据集
2016年,P. Rajpurkar等发表的SQuAD数据集[1]收录了10万个经精心编辑的优秀回复,并且涵盖了500篇维基百科的相关内容,这些回复都是基于特定的文字背景,从而使得它们更容易进行准确的分析。SQuAD数据集是一个广泛应用于阅读理解任务的数据集,旨在让计算机根据给定的文章上下文段落来回答问题。
在SQuAD任务中,每个样本由一篇文章上下文段落和与该上下文段落相关的一系列问题组成。计算机的目标是从上下文段落中正确理解并提取出与每个问题相关的答案。SQuAD数据集中的答案通常是上下文段落中的连续片段,因此属于提取式问答。SQuAD任务的挑战在于计算机需要准确理解文章的内容、句子的结构和问题的意图,然后从上下文段落中找到正确的答案。这要求计算机具备语义理解、推理和推断的能力,并且能够在大量文本中进行准确的定位和抽取。图7中显示了一段文本样本及其3个相关问题。
SQuAD任务的研究和评估推动了阅读理解领域的发展,许多模型和算法被设计和优化,以在SQuAD数据集上获得更高的准确率和更好的效果。这些模型的进步对于实际应用中的问答系统和信息提取任务都具有重要的意义。
斯坦福数据集的数据格式是由标题、上下文段落构成,标题主要是表达上下文段落的一个主题,文本段落包含问答对以及上下文段落。同一个主题可能会由几个文本构成,但是问答对总会在相应的文本前面。主题一般是无用的,利用的信息主要是问答对中的问句和文本,其中问答对里面的is_impossible属性有些时候是1和true,表明了是否有相应的答案,如果为true,则表明该问题回答不了。
4.1.2 "数据预处理
通过采用有效的降噪技术,可以有效地清除数据集中的文本、问题以及其他不必要的信息,包括删减标点符号、删减多余的空白,以及把大写字母变成小写;此外,还可以把原有的数值标识替换成文本标识,详见图8。
4.2 "基 "线
在答案抽取中,有多种方法可以用来根据上下文推理答案并从上下文中抽取出答案。以下是一些常见的方法:
1) BIDAF是一种用于阅读理解的先进技术,它将字符和词汇嵌入到模型中,并采用多粒度结构,在交互层中实现双向注意力机制,从而能够准确地预测出模型对上下文单词级别的理解能力[12]。
2) 通过将Match⁃LSTM with Ans⁃Ptr与Match⁃LSTM with Ans⁃Ptr(Boundary)相结合[19],可以更好地利用神经网络技术来预测答案的起止位置[22],这是阅读理解领域最早的应用之一。PointerNet也提供了类似的模型,可以更准确地预测答案的起止位置。其中,PointerNet中的Boundary Model模型是O. Vinyals等人提出的一个序列到序列的模型[23],其用来实现从输入序列中查找相应的令牌来作为答案输出。通过Attention,可以从输入序列中精确定位一个特定的词,并以此作为输出,来实现对该词的准确定义。
3) BIDAF⁃INDEPENDENT:通过独立目标训练后的BIDAF模型[24]。
4) BIDAF⁃COMPOUND:通过复合目标训练后的BIDAF模型[24]。
本文实验选取的基线均选用答案抽取领域内较为前沿的技术。与以往的方式相比,新一代的技术不但拥有出色的性能,还拥有极大的灵活性,已成为各种领域的理想选择。
4.3 参数设置
本文基于Featurize的数据库,采用RTX 3060和Python 3.7的技术,构建了一个5层的模拟系统。该系统包含37 367 549个参数,每个参数的嵌入字数达到了300个,每个字的隐含维度达到了128个,每个字的dropout值达到了dropout=0.3,每个字的epoch数达到了10个,多头个数达到了12个。
5 "实验结果与分析
在解决问题时,通常会使用P. Rajpurkar等人提供的EM(Exact Match)值和F1值[1]来评估解决方法。EM值描述了在解决问题时,假设解决方法能够得到正确的结果,并且可能会发现所用的解决方法并非总能达到理想的效果。F1值描述了在解决问题时,假设解决方法能够得到正确的结果,并且可能会发现解决方法并不总能达到理想的效果,公式如下:
[F1=2×P×RP+R ] " " " " " " " "(3)
式中:P代表精确率;R代表召回率[20]。
为了直观地反映AEMEQA模型的答案抽取性能,对模型进行实验,并与BIDAF⁃INDEPENDENT模型和BIDAF⁃COMPOUND模型结果进行对比,如表1所示。
由表1可见,AEMEQA模型的答案抽取性能相较于Match⁃LSTM with Ans⁃Ptr(Boundary)模型、BIDAF⁃INDEPENDENT模型和BIDAF⁃COMPOUND模型都有一定的提升,虽然精度提升较低,EM值分别只提升了5.113%、1.281%和1.05%,F1值分别提升了7.69%、1.296%和1.335%,但AEMEQA模型在提升性能的同时,能够节省内存,训练更快,进一步提升了深度学习在答案抽取任务的效果。
6 "结 "语
本文提出了一种增强问句和文本交互的答案抽取方法,通过融合问句和文本的语义信息,使用更少的参数量来实现交互。实验证明,这种方法在阅读理解任务中获得了较好的答案抽取结果;在模型训练时,答案抽取效果有所提升。未来的工作将着手于问句的分类处理,将问句分类信息输入模型进行更加充分的利用,对上下文进行实体识别,提高交互信息利用效率。此外,由于模型参数数量限制,实验未使用大规模模型去进行答案抽取任务,但目前已经有许多自然语言领域的大规模模型,如BERT、ALBERT等,未来将研究这些大规模模型是否与现有答案抽取任务框架适配,进一步提高模型的答案抽取能力。
参考文献
[1] RAJPURKAR P, JIA R, LIANG P. Know what you don't know: Unanswerable questions for SquAD [EB/OL]. [2022⁃01⁃14]. https://arxiv.org/abs/1806.03822.
[2] NGUYEN T, ROSENBERG M, SONG X, et al. Msmarco: A human⁃generated machine reading comprehension dataset [EB/OL]. [2022⁃07⁃01]. https://arxiv.org/abs/1611.09268.
[3] TRISCHLER A, WANG T, YUAN X, et al. Newsqa: A machine comprehension dataset [EB/OL]. [2022⁃01⁃20]. https://ui.adsabs.harvard.edu/abs/2016arXiv161109830T/abstract.
[4] JOSHI M, CHOI E, WELD D S, et al. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension [EB/OL]. [2022⁃10⁃03]. https://ui.adsabs.harvard.edu/abs/2017arXiv170503551J/abstract.
[5] 唐竑轩,武恺莉,朱朦朦,等.基于双向注意力机制的多文档神经阅读理解[J].计算机工程,2020,46(12):43⁃51.
[6] LIU S, ZHANG X, ZHANG S, et al. Neural machine reading comprehension: methods and trends [J]. Applied sciences, 2019, 9(18): 3698.
[7] CHEN D. Neural reading comprehension and beyond [M]. California: Stanford University, 2018.
[8] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. California: ACM, 6000⁃6010.
[9] GOODFELLOW I, BENGIO Y, COURVILLE A, et al. Deep learning [M]. Cambridge: MIT Press, 2016.
[10] CHENG J, WANG P S, GANG L I, et al. Recent advances in efficient computation of deep convolutional neural networks [J]. Frontiers of information technology amp; electronic engineering, 2018, 19(1): 64⁃77.
[11] SUNDERMEYER M, SCHLÜTER R, NEY H. LSTM neural networks for language modeling [C]// Interspeech. [S.l.]: IEEE, 2012: 601⁃604.
[12] SEO M, KEMBHAVI A, FARHADI A, et al. Bidirectional attention flow for machine comprehension [EB/OL]. [2022⁃04⁃07]. http://arxiv.org/pdf/1611.01603.
[13] XIONG C, ZHONG V, SOCHER R. Dynamic coattention networks for question answering [EB/OL]. [2022⁃07⁃11]. https://www.semanticscholar.org/.
[14] GOODFELLOW I, WARDE⁃FARLEY D, MIRZA M, et al. Maxout networks [C]// International Conference on Machine Learning. Atlanta: ACM, 2013: 1319⁃1327.
[15] SRIVASTAVA R K, GREFF K, SCHMIDHUBER J. Training very deep networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal: ACM, 2015: 2377⁃2385.
[16] CHEN D, FISCH A, WESTON J, et al. Reading wikipedia to answer open⁃domain questions [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: ACL, 2017: 1870⁃1879.
[17] WEISSENBORN D, WIESE G, SEIFFE L. Making neural QA as simple as possible but not simpler [EB/OL]. [2022⁃03⁃02]. http://arxiv.org/abs/1703.04816v3.
[18] WANG W, YANG N, WEI F, et al. Gated self⁃matching networks for reading comprehension and question answering [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: ACL, 2017: 189⁃198.
[19] WANG S, JIANG J. Learning natural language inference with LSTM [EB/OL]. [2022⁃01⁃12]. https://ui.adsabs.harvard.edu/abs/2015arXiv151208849W/abstract.
[20] 顾迎捷,桂小林,李德福,等.基于神经网络的机器阅读理解综述[J].软件学报,2020,31(7):2095⁃2126.
[21] HUANG H Y, CHOI E, YIH W. Flowqa: grasping flow in history for conversational machine comprehension [EB/OL]. [2022⁃03⁃11]. http://arxiv.org/pdf/1810.06683.
[22] WANG S, JIANG J. Machine comprehension using match⁃lstm and answer pointer [EB/OL]. [2022⁃02⁃11]. https://ui.adsabs.harvard.edu/abs/2016arXiv160807905W/abstract.
[23] VINYALS O, FORTUNATO M, JAITLY N. Pointer networks [J]. Advances in neural information processing systems, 2015(1): 28.
[24] FAJCIK M, JON J, SMRZ P. Rethinking the objectives of extractive question answering [EB/OL]. [2023⁃02⁃07]. https://arxiv.org/abs/2008.12804.
猜你喜欢
科技与创新(2016年21期)2017-02-14 10:27:51
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
人民论坛(2016年22期)2016-12-13 10:20:24
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
中国市场(2016年27期)2016-07-16 04:40:01
现代交际(2016年12期)2016-07-09 02:45:50
