
基于深度强化学习算法的投资组合策略与自动化交易研究
2024-09-14 00:00:00杨旭刘家鹏越瀚张芹
现代电子技术 2024年6期
关键词:深度强化学习




摘 "要: 投资组合策略问题是金融领域经久不衰的一个课题,将人工智能技术用于金融市场是信息技术时代一个重要的研究方向。目前的研究较多集中在股票的价格预测上,对于投资组合及自动化交易这类决策性问题的研究较少。文中基于深度强化学习算法,利用深度学习的BiLSTM来预测股价的涨跌,以强化学习的智能体进行观测,更好地判断当期情况,从而确定自己的交易动作;同时,利用传统的投资组合策略来建立交易的预权重,使智能体可以在自动化交易的过程中进行对比,从而不断优化自己的策略选择,生成当期时间点内最优的投资组合策略。文章选取美股的10支股票进行实验,在真实的市场模拟下表明,基于深度强化学习算法的模型累计收益率达到了86.5%,与其他基准策略相比,收益最高,风险最小,具有一定的实用价值。
关键词: 投资组合策略; 自动化交易; 深度强化学习; BiLSTM; 深度确定性策略梯度(DDPG); 权重对比
中图分类号: TN911⁃34 " " " " " " " " " " " " " "文献标识码: A " " " " " " " " " " " 文章编号: 1004⁃373X(2024)06⁃0154⁃07
Research on investment portfolio strategy and automated trading based on deep reinforcement learning algorithm
YANG Xu1, LIU Jiapeng2, YUE Han1, ZHANG Qin1
(1. College of Economics and Management, China Jiliang University, Hangzhou 310018, China;
2. College of Business, Zhejiang Wanli University, Ningbo 315100, China)
Abstract: The problem of investment portfolio strategy is an enduring topic in the financial field, and the application of artificial intelligence techniques in financial markets is an important research direction in the information technology era. Current research is more focused on price prediction of stocks, and less on decision⁃making problems such as investment portfolio and automated trading. Based on the deep reinforcement learning algorithm, the BiLSTM of deep learning is used to predict the rise and fall of stock prices, and the reinforcement learning agents is used to observe and better assess the current situation, so as to determine one's own trading actions. Intelligent agents can comparison during automated trading processes by using traditional investment portfolio strategy to establish pre weights for transactions, so as to continuously optimize their strategy choices and generate the optimal investment portfolio strategy at the current time point. 10 stocks from the US stock market are selected for experiments. Under real market simulations, the results show that the cumulative return of the model based on deep reinforcement learning algorithm can reach 86.5%. In comparison with other benchmark strategies, it has the highest return and the lowest risk, and has a certain practical value.
Keywords: investment portfolio strategy; automated trading; deep reinforcement learning;BiLSTM;DDPG; weighting comparison
0 "引 "言
投资组合策略的目标是指对所购买的金融产品的权重进行调节以尽可能控制并缩小风险,扩大收益。传统的投资组合模型往往伴随着较多的假设和约束,但当今金融市场瞬息万变,数据海量,传统的投资组合模型已经不能适应现实的需要,亟待有新的方法来解决不同情境下的投资组合管理问题。
近年来,随着科技的进步与硬件设施的发展,人工智能在各行各业上的优势逐步显现。在金融科技领域,深度学习算法常常被国内外学者用于股价预测[1⁃3]方面。强化学习属于近些年的一个新兴方向,在金融领域的应用较少;但是依据强化学习的基本原理和运作模式,其非常适合于金融领域的一些决策性活动。因此在已有的研究里,强化学习常常被用于量化交易和资产组合方面[4]。
近年来,学者们已经在金融市场中进行了广泛的深度学习和强化学习,主要总结其在量化交易上的成果。Liang等人通过比较PPO、DDPG和PG算法在投资组合市场中的应用,发现基于策略梯度(PG)的算法要优于其他算法[5]。Xiong等人训练了一个深度强化学习代理,获得自适应交易策略,并将其与道琼斯工业平均水平和传统的最小变化投资组合分配策略进行了比较,发现该系统在夏普比率和累积回报方面都优于其他两个基准[6]。Buehler等人提出了一种DRL框架,通过强化学习方法,直接利用历史价格来解决投资组合问题[7]。Gao等人将DQN算法用于股票市场的投资组合管理,为了使DQN适应金融市场,将行动空间离散为不同资产中投资组合的权重[8]。
在实验上,选取了5支美国股票来测试该模型。结果表明,基于DQN策略的表现优于其他10种传统策略,DQN算法的利润比其他策略的利润高30%。此外,夏普比率表明,使用DQN制定的政策风险最低。Weng等人提出了一种三维注意门网络,它对上升时期的资产赋予更高的权重[9]。在不同的市场条件下,这个系统获得了更大的回报,大大提高了夏普比率,并且风险指数远低于传统算法。
Lei等人提出了一个基于时间驱动的特征感知联合深度强化学习模型(TFJ⁃DRL),结合门控循环单元(GRU)和策略梯度算法,实施股票交易[10]。Lee等人提出了一个HW_LSTM_RL结构,它首先使用了小波转换以消除股票数据中的噪声,然后基于深度强化学习分析股票数据,做出交易决策[11]。许杰等人提出了一种将CNN和LSTM相结合的自动交易算法,通过CNN模型对股票数据进行分析,从中提取动态特征;然后使用LSTM模型对股票数据的动态时间序列进行循环学习,通过强化学习制定相应的交易策略[12]。实证表明,该方法比标准模型具有更好的鲁棒性。
现有的研究大多只将深度强化学习算法直接用于股票的投资组合决策中,而本文引入传统的投资组合理论,使强化学习算法可以不断优化自己的权重选择;不同于仅仅单一用深度强化学习算法,用神经网络预测股价的下一步走势,使强化学习智能体在做出交易决策时可以更好地把握下一时刻的股价信息。
1 "整体模型建立
1.1 "BiLSTM预测股票价格
1.1.1 "LSTM网络结构
LSTM中引入了3个门以及与隐藏状态形状相同的记忆细胞,通过门来控制信息的流动。
[t]时期的输入包括前期输出[ht-1]、当期市场信息[xt]以及前期细胞记忆[Ct-1]。遗忘门[ft]对前期细胞信息进行选择。其计算公式如下:
[ft=σWf∗ht-1,xt+bf] (1)
式中:[σ]表示非线性函数;[Wf]表示遗忘门的权重系数;[ht-1]是LSTM单元的隐藏状态;[bf]是偏置项;“*”符号代表向量点乘。
通过对[xt]、[ht-1]的函数映射机制,可以得到当期市场信息的临时细胞记忆[Ct∼]。具体计算公式如下:
[it=σWi∗ht-1,xt+bi] (2)
[Ct∼=tanhWC∗ht-1,xt+bC] (3)
式中:[it]表示记忆现在某些信息;[tanh]是双曲正切函数;[Wi]、[WC]表示对应门的权重系数;[bi]、[bC]表示偏置项。
通过遗忘门和输入门得到新的输入信息的记忆[Ct],公式为:
[Ct=ft·Ct-1+it·Ct∼] (4)
式中[Ct]表示将过去与现在信息合并。
[tanh]函数将单元格状态规范到-1~1之间,并乘以sigmoid门输入,作为最终的结果。
[ot=σWo∗ht-1,xt+bo] (5)
[ht=ot·tanhCt] (6)
式中:[ot]表示输出门输出;[Wo]是输出门输入权重参数;[bo]是偏置项,每个单元的相同门的输入参数共享。
1.1.2 "BiLSTM预测股票涨跌
BiLSTM(Bi⁃directional Long Short⁃Term Memory)是LSTM网络的一种改进模型,也称为双向LSTM网络,它利用了后续时间信息对于当前时间进行判断,可以获得更加准确的预测效果。实验设计的BiLSTM网络整体的输入序列为样本个数(samples)、时间步长(time steps)和特征(features)。实验过程是:首先将选择好的数据进行归一化处理;接下来采用滑动窗口的方式来构建预测模型的数据集;再使用Keras框架进行模型的构建与训练,采用Adam算法更新,将数据分批输入模型;然后测试不同时间步长下预测模型的性能,对比时间步长为3、7、10、20,找出最优的时间步长;最后测试模型最优时间步长下最小的RMSE和MAPE。
1.2 "投资组合权重分配
本文以马科维茨的投资组合理论为基础建立资产配置的权重模型,它包含了均值⁃方差模型和投资组合有效边界模型。投资者可以预先确定一个期望收益,进一步确定投资者在每个项目上的权重,使其总投资风险最小,故不同的期望收益对应着不同的最小方差组合。在有效边界模型中,将收益率作为纵轴,收益率标准差作为横轴,绘制出所有包含最小方差的点,构成投资组合理论中的有效边界。该理论的核心思想是将不同的投资资产组合在一起,以实现最小化投资组合风险和最大化预期收益率。投资组合的风险和收益率是由其中每种资产的风险和收益率以及它们之间的相关性所决定的,通过组合不同风险和收益率的资产,可以降低整个投资组合的风险,同时最大化预期收益率。
本文以马科维茨的投资组合理论为基础,去除交易成本限制,用数据训练生成一组最优的投资组合权重。首先输入股票数量,随机生成一组权重;接着计算该权重下的收益率标准差和收益率,重复该过程,得出最优边界;最后,在最优边界上可以找到最小风险和最大收益的投资组合权重。将此过程建模为MPT模型。
1.3 "强化学习算法
1.3.1 "股票市场定义
将投资组合过程近似看作是一个马尔科夫决策过程(MDP)。MDP定义为元组[S,A,P,r],其中[S]是状态空间,[A]是动作空间,[PSt+1St,at]表示在[at∈Α]、[st∈S]到下一个状态[St+1]的概率,[rSt,at,St+1]表示在状态[St]采取行动的直接回报,同时达到新状态[St+1]。强化学习的具体操作是选择最佳的投资组合权重向量,并根据前后的向量之差进行交易,计算收益(或正或负),从而达到最大化累计收入,并且尽可能降低风险以及交易成本的目的。
本文预设初始资金为1 000 000美元,基于强化学习对于股票市场的描述如下:
1) 状态空间(state)。[ct]:[t]时刻的可用余额;[Otyst]:[t]时刻每支股票的持有市值;[Closet]:[t]时刻后10天每天的收盘价。
2) 动作空间(action)。在投资组合交易问题中,智能体的工作是计算出每种股票的买入和卖出量。允许投资者在行动空间内做多和做空资产,但是在做空时,卖出要从价格最低的进行卖出,以获得最大的收益。对于单个股票,动作空间被定义为[-k,…,-1,0,1,…,k],其中[k]和[-k]代表可以买卖的股票数量,[k≤hmax]。[hmax]是一个预定义的参数,用于设置每次购买行为的最大股份数量;操作空间归一化为[-1,1],这也意味着操作空间是连续的。在每个状态的操作选择之后,首先进行判断,对每支股票是执行卖出操作,还是执行买入或持有操作。
3) 股票支数[M]。本文定义的股票支数为[M=10]。
4) 投资组合向量。第i项表示投资总预算与第i项资产的比率,即:
[wt=w1,t,w2,t,…,wM,tT∈RM] (7)
式中[wt]的每一个元素[wi,t∈0,1],且[i=1Mwi,t-1=1]。
5) 调整后的收盘价。本文将股票i在时间[t]的调整后的收盘价记为[pi,t]。
6) 资产价格。本文定义资产在[t]时期的价格为:
[Vt=i=1Mhi,t-1·pi,t+ct-1] (8)
7) 持股情况。本文定义在时间[t]股票i的持股为:
[hi,t=Vt·wi,tpi,t] (9)
8) 奖励函数(Reward Function)。将奖励函数定义为:
[Rt=Vt-Vt-1] (10)
9) 为增加预期投资汇报,设置投资组合交易深度强化学习框架中的动作向量为:
[at=wt] (11)
式中[wt]的每一个元素[wt,j∈0,1],且[j=0mwt,j=1]。
1.3.2 "DDPG算法
深度确定性策略梯度(DDPG)算法采用的是经典的Actor⁃Critic架构,Actor网络为策略[μ],Critic网络为价值函数[Q]。Actor网络输入环境的状态,输出在该状态下价值[Q]最大的动作[a],以此构成确定性策略[μ]。该网络直接对价值函数[Q]做梯度下降,其目的是找到最大的动作[a]。这里的[Q]来源于上一轮Critic网络的输出。根据策略梯度定理推导出确定性策略梯度定理:
[∇θμ=ESt∼pβ∇aQs,aθQS=St,a=μ(st)·∇θμμ(sθμ)s=st] (12)
Critic网络输入环境的状态,Actor网络输出动作[a]、输出拟合[Q]。该网络的Label为通过Bellman最优方程计算出的价值,描述最优动作的Bellman等式为:
[Q∗(s,a)=Er(s,a)+γmaxQ∗(s',a')] (13)
DDPG的Q⁃learning算法使用目标网络实现目标的表达式为:
[ρ=r+γ(1-d)maxQϕ(s',a')] (14)
综上,整体的模型结构如图1所示。
2 "实验过程
2.1 "数据准备
本实验的数据来源是雅虎财经网站,选择具有代表性的10支上市公司的股票,分别为谷歌(GOOGL)、苹果(APPL)、亚马逊(AMZN)、高通(QCOM)、特斯拉(TSLA)、微软(MSFT)、好市多(COST)、迪许网路(DISH)、卡康斯特(CMCSA)和易趣(EBAY)。选取美股市场的股票原因在于市场比较稳定,更利于训练和分析模型。
本实验的数据范围是2013年1月29日—2022年12月30日之间10年的数据,除周六、周日以及节假日外所有交易日共2 500条数据。其中,将训练集与测试集按7∶3的比例划分。在数据字段中以收盘价作为主要的标准数据,以苹果(APPL)的部分股票基本数据为例,如表1所示。
同时,选取4类技术指标作为辅助,以便更好地提取股票的特征,技术指标的选取如表2所示。
2.2 "实验环境
本实验的代码整体上使用Python进行编写,LSTM网络预测模型在基于TensorFlow的Keras框架下进行建立,并利用Python提供的sklearn、numpy等第三方工具库进行辅助,实现了数据的预处理以及预测结果的可视化工作。本次实验所使用的环境信息如表3所示。
2.3 "评估指标
2.3.1 "BiLSTM评价指标
本文选取RMSE(均方根误差)和MAPE(平均绝对百分比误差)来作为预测模型结果的评价指标。
其中,RMSE为MSE的平方根。MSE定义为预测数据与原始数据对应点误差的平方和的均值,公式如下:
[MSE=1ni=1nyi-yi2] (15)
[RMSE=MSE] (16)
且RMSE越小,表明结果越好。
MAPE的公式如下:
[MAPE=1ni=1nyi-yiyi×100%] (17)
且MAPE越小,表明结果越好。
2.3.2 "投资组合策略评价指标
本文使用累计收益率、夏普比率、最大回撤、Alpha和Beta等5个指标对投资组合策略结果进行评估。
股票的累计收益率(CR)是衡量投资组合管理在时间期间上投资结果的常用指标,即投资组合的累计收益除以本金。夏普比率反映了单位风险资产净值增长率超过无风险收益率的程度,是用股票的净值增长率的平均值减无风险利率再除以股票的净值增长率的标准差,是最主流的评价投资组合策略绩效的指标。其计算公式如下所示:
[Sharpe=ERp-Rfσp] (18)
最大回撤是指在任一时间点向后推,产品净值到达最低点时,收益率回撤幅度的最大值。这一指标描述了投资者买入某资产可能出现的最为糟糕的情况,其计算公式如下所示:
[max down=minXi-XjXj×100%] (19)
Alpha值是用来衡量模型相较于基准模型获得的超额收益。Alpha值越大,表示相较于基准获得的额外回报越多,其计算公式如下所示:
[Alpha=Rp-Rf+βpRm-Rf] (20)
式中:[Rp]表示组合收益率;[Rf]表示无风险收益率;[Rm]代表市场收益率(本文选取道琼斯指数作为基准市场)。
Beta值是用来评估模型到基准市场的相对于评估模型系统风险的指标。如果Beta值大于1,则模型的波动性大于基准;如果Beta值小于1,则模型小于基准;如果Beta值等于1,则波动率模型的性能与基准测试的性能相同。其计算公式如下所示:
[Beta=CovRp,Rmσ2m] (21)
式中[σ2m]表示基准市场即道琼斯市场的方差。
2.3.3 "基准策略
本文选取4个基准策略和所提投资组合模型进行对比,即道琼斯工业平均指数(DJI)、买入持有计划(BAH)、集成有三个Actor⁃Critic算法的强化学习模型(ES)[13]以及基于主成分分析和小波去噪的方法(PCAamp;DWT)[14]。
3 "实验结果
3.1 "BiLSTM预测效果
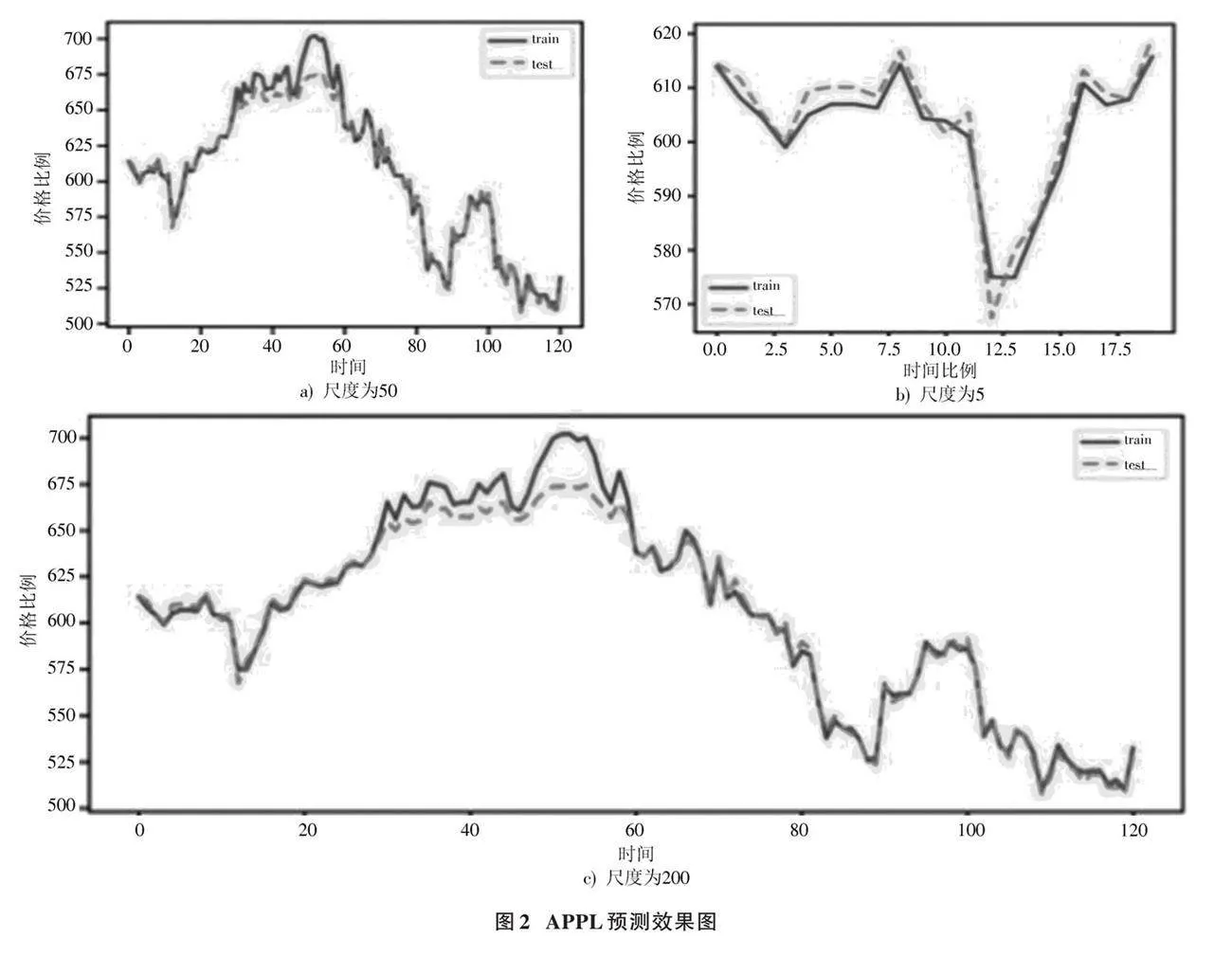
根据BiLSTM网络的预测结果进行如下评估。首先对模型预测效果进行分析,由于每支股票有其数据特性,因此在训练时,常选取不同的网络进行预测。本文选取APPL作为展示结果,模型的预测值与真实值的对比结果如图2所示。
图b)、a)、c)分别为尺度为5、50、200的真实值与预测值的对比。由图中可见在局部的振荡上预测值准确,在整体上的趋势预测也能准确实现,且得到的评价指标分别为:RMSE是8.145;MAPE是0.836%。可知预测结果较好。
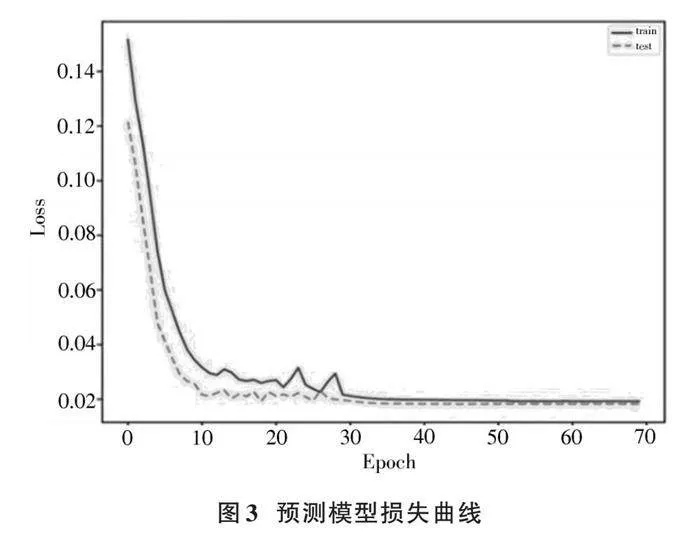
对APPL预测模型的损失评估如图3所示。训练轮次达到70次左右时,模型收敛,得到的误差结果在0.042 5左右,此时模型误差最小。再增加训练轮次时,模型训练效果会产生过拟合,使模型效果变差。
3.2 "DDPG决策效果
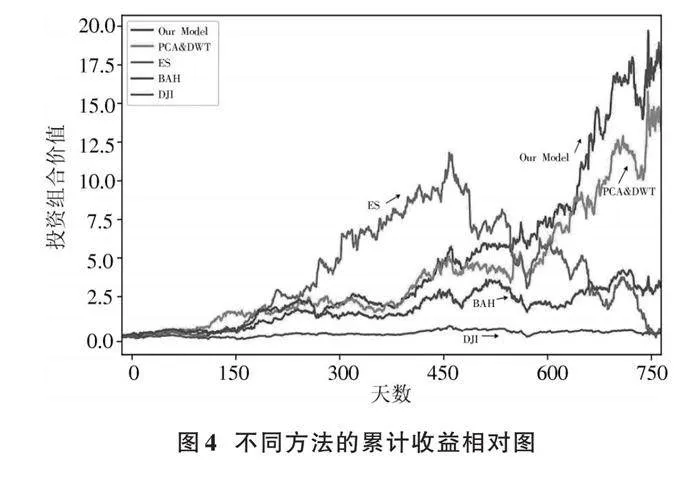
基于相同的市场数据来对比投资组合方法的优劣,各个算法的评价结果如表4和图4所示。
由表4可知:本文提出的模型在累计收益率上高于其他4个模型;本文的交易策略有着最高的夏普比率,这表明与其他策略相比,本文模型可以在同等风险水平下获得更高的回报。由于本文模型相较于其他模型有最低的最大回撤值,这表明可能发生的最大亏损幅度是最小的;相较于其他模型,本文的模型基于基准市场有着最高的Alpha值,这说明同等情况下,本文的模型可能会获得更多的额外收益;Beta值最低,说明本文的模型相较于基准市场存在的系统风险最低。综上所述,本文模型在同等市场条件下,可以获得较高的收益,且风险水平较小,具有一定的实用意义。
4 "结 "论
本文基于深度强化学习技术,提出一种适合于个人投资者的智能投资组合优化方法及交易模型。通过使用股票的价格数据以及技术指标数据作为BiLSTM的输入,引入注意力机制,预测市场下一步的价格走势,强化学习智能体在此基础上进行股票的买卖操作;与此同时,将经典的马科维茨投资组合理论进行建模,在本文的权重选择过程中,不断与其进行对比,使本文的权重选择不断趋于更优解。本研究有助于个人投资者在不确定的市场环境中做出理性投资决策,提升投资风险管理意识,同时获得更高的投资回报。本文基于真实的市场数据进行实证分析,且丰富了现代投资组合理论与金融实证研究,为人工智能技术在经济学和管理学中的深入研究提供了参考。
深度强化学习作为人工智能的前沿技术,已经在投资组合和自动化交易方面展现了优势之处,是未来金融市场发展的重要方向。未来的工作也许可以从以下几个方面考虑:
1) 股价波动受到多种因素的共同影响,以往的工作将多种信息并行拼接,而忽略了各种信息之间的内在联系。因此,如何利用各个信息之间的关系重构向量是未来研究的一个重要方向。
2) 金融市场是一个复杂的系统,凭借单一的不变的模型不可能一直获利,因此需要构建一种多资产投资组合的动态交易模型,根据不同的市场环境和不同的限制要求来满足投资者的需求。
3) 情绪因素也是影响金融市场变动的一个重要因素,如何将情感量化加入股票的买卖之中,也是一个值得研究的课题。
注:本文通讯作者为刘家鹏。
参考文献
[1] SHAHI T B, SHRESTHA A, NEUPANE A, et al. Stock price forecasting with deep learning: a comparative study [J]. Mathematics, 2020, 8(9): 1441.
[2] JI Y, LIEW W C, YANG L. A novel improved particle swarm optimization with long⁃short term memory hybrid model for stock indices forecast [J]. IEEE access, 2021(9): 23660⁃23671.
[3] 翁晓健,林旭东,赵帅斌.基于经验模态分解与投资者情绪的长短期记忆网络股票价格涨跌预测模型[J].计算机应用,2022,42(z2):296⁃301.
[4] 梁天新,杨小平,王良,等.基于强化学习的金融交易系统研究与发展[J].软件学报,2019,30(3):20.
[5] LIANG Z, HAO C, ZHU J, et al. Adversarial deep reinfor⁃cement learning in portfolio management [EB/OL]. [2023⁃08⁃07]. https://arxiv.org/pdf/1808.09940.
[6] XIONG Z, LIU X Y, SHAN Z, et al. Practical deep reinfor⁃cement learning approach for stock trading [EB/OL]. [2023⁃02⁃15]. http://arxiv.org/pdf/1811.07522.
[7] BUEHLER H, GONON L, TEICHMANN J, et al. Deep hedging [J]. Quantitative finance, 2019, 19(8): 1271⁃1291.
[8] GAO Z, GAO Y, HU Y, et al. Application of deep q⁃network in portfolio management [C]// 2020 5th IEEE International Conference on Big Data Analytics. [S.l.]: IEEE, 2020: 268⁃275.
[9] WENG L, SUN X, XIA M, et al. Portfolio trading system of digital currencies: a deep reinforcement learning with multidimensional attention gating mechanism [J]. Neurocomputing, 2020, 402: 171⁃182.
[10] LEI K, ZHANG B, LI Y, et al. Time⁃driven feature⁃aware jointly deep reinforcement learning for financial signal representation and algorithmic trading [J]. Expert systems with applications, 2019, 140: 112872.
[11] LEE J, KOH H, CHOE H J. Learning to trade in financial time series using high⁃frequency through wavelet transformation and deep reinforcement learning [J]. Applied intelligence, 2021(2): 1⁃22.
[12] 许杰,祝玉坤,邢春晓.基于深度强化学习的金融交易算法研究[J].计算机工程与应用,2022,29(3):1⁃11.
[13] YANG H, LIU X Y, ZHONG S, et al. Deep reinforcement learning for automated stock trading: an ensemble strategy [EB/OL]. [2022⁃12⁃07]. https://blog.csdn.net/weixin_37958272/article/details/121506666.
[14] LI L. An automated portfolio trading system with feature preprocessing and recurrent reinforcement learning [EB/OL]. [2023⁃04⁃11]. http://arxiv.org/abs/2110.05299v1.
猜你喜欢
电脑知识与技术(2021年4期)2021-03-22 17:05:34
湖北农业科学(2020年13期)2020-09-14 12:20:20
工业技术创新(2020年3期)2020-06-21 15:10:52
物联网技术(2020年3期)2020-04-09 04:33:59
理论与创新(2020年24期)2020-03-24 22:28:38
航空科学技术(2020年10期)2020-02-04 07:28:05
计算机应用(2019年5期)2019-08-01 01:48:57
物联网技术(2019年6期)2019-07-29 01:12:33
商情(2019年14期)2019-06-15 10:20:13
电脑知识与技术(2019年4期)2019-05-24 14:11:40
