
基于大数据的人才分类精准培养平台研究
2024-07-12 04:40:02谢盛嘉
现代职业教育·高职高专 2024年17期
[摘 要] 依托“互联网+教育”大平台,发挥信息技术在教学改革中的重要作用,解决高职学生分类精准培养问题,提高人才培养质量,探讨利用大数据应用创新教与学的智能诊断、教学资源推送和多维学习辅导,构建使用Hadoop的平台系统架构设计方案,构建深度学习模型,完成学生行为过程画像,运用聚类算法实现个体现状与职业发展岗位匹配预测,实现技术与教育深度融合,有效促进学生的个性化发展。
[关 键 词] 大数据;人才分类精准培养;系统设计;算法设计
[中图分类号] G717 [文献标志码] A [文章编号] 2096-0603(2024)17-0053-04
职业教育在国民教育体系和人力资源开发中扮演着重要角色,在党的二十大报告中特别提到要着力推动高质量发展的职业教育。社会发展需要各类高技能职业人才,为了实现人人成才、人人皆可成才的培养目标,针对高职学生开展分类精准培养,提高人才培养质量,成为高职院校教学改革亟待解决的问题。因此,职业教育应依托“互联网+教育”的大平台,发挥信息技术在教学改革中的重要作用,基于大数据应用创新教与学的智能诊断、教学资源推送和多维学习辅导,实现技术与教育深度融合,有效促进学生的个性化发展。
一、职业教育要满足学生个性化发展
依据人职匹配的理论,当学习者的个性特征、职业能力等与其从事的职业性质相一致,可以最大限度发挥个人的潜力,提高满意度和成就感,对未来的就业起到推动作用;与之相反,若学习者个性特征与职业不符,则影响和限制学习者的职业发展。而当前高职院校存在多种招生方式,包括普通高考、学考、学徒制、中高职贯通培养三二分段等多种形式,生源类型呈现多样性,不同生源水平基础参差不齐,学生所处的学习环境不同[1],学生教育经历、学习兴趣、学习方法等方面存在较大差异,传统的人才培养标准和教育模式已不能很好地适应新时代对学生个性化发展的需求。为适应当前高职院校生源类型相对复杂的教育现状,高校需要基于教育学理论中的“以人为本”的学习理论,从职业院校教学活动的现状入手,分析人才分类培养和分层教学存在的问题,提出造成高校无法有效展开人才分类培养和分层教育的原因机制,寻找解决问题的可靠性方法[2-3],建立学生个性化培养指导体系、构建学生个性化分类培养模型,提出符合学生个性化分类培养方法[4-6],以满足学生多样化发展为目标,以职业岗位需求为导向,以提升培养质量为宗旨,以专业类别差异化为手段,对培养过程数据分析,根据不同生源学生特点和学生发展需求进行分类培养,设计多元成长路径,推行多元考核与分层分类评价,探索能够最大限度地实现因材施教,实施横向差别化分类培养,做到精准培养[7-8]。
基于大数据技术应用的职业人才分类精准培养是教书育人与职业规划相结合,大数据技术代表一种新的价值观和方法论,它并不仅仅是简单地将多个数据组合在一起,而是通过运用智能处理方法和模式对数据进行分析和处理,旨在实现数据价值的最大化,这与传统意义上的“大量数据”概念有很大的不同。在职业教育中构建人才分类精准培养平台,围绕“教、学、管、练、评”5大教学场景,融入互联网+的理念,实现人才培养对接产业需求,专业课程内容对接职业标准。将大数据、AI大模型等现代信息技术应用到系统中,通过对学生在校学习行为分析,对照职业岗位能力素质标准,为学生提供基于大数据分析的信息,帮助学生更为客观地评价自己,制订动态的、精准的职业规划方案,实现技术技能人才精准培养。
二、人才分类精准培养平台构建
人才分类精准培养平台系统,参照国家对学生职业核心素养能力要求,根据高职学生的培养内容和学习特点,运用大数据收集与统计分析技术,对学生的认知、创新、协作、实践、管理、人格、心理综合等多个方面开展评价,学生各项能力表现被分解为若干二级指标,系统对二级指标完成加权折合计算,最后得到学生综合表现指标值。通过对学生各方面的能力的综合评价分析,可以有针对性地为学生提供个性化的培养规划指导。
(一)人才分类精准培养平台系统架构
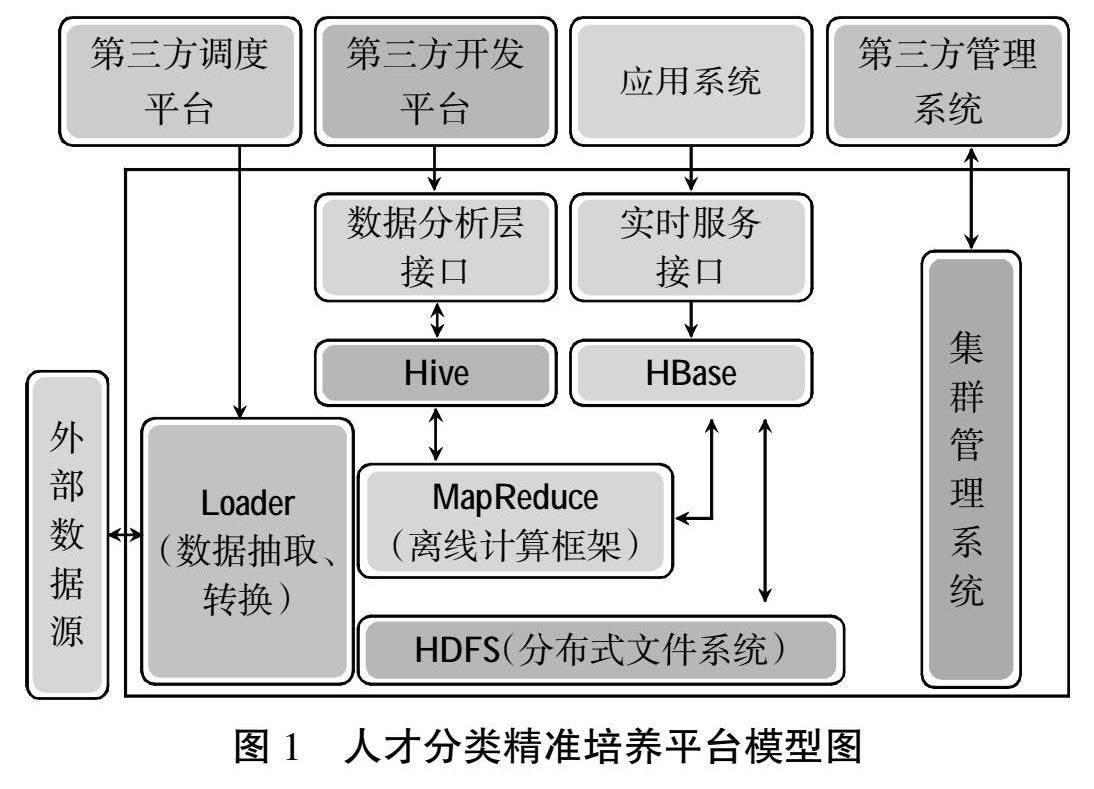
人才分类精准培养平台设计架构选择Hadoop的HDFS分布式文件系统作为大数据处理的基础,为底层存储提供支持。通过使用Hive技术,平台能够发挥基于HDFS存储并管理大量的数据集的优势,完成对海量、多源数据进行采集和处理,借助MapReduce分布式计算框架进行更深入的分析,以构建学习者画像并获取每个学习者的当前状态信息,使用Spring Boot等实现数据的图表可视化展示,以便与基准数据进行对比,从而发现学习者的知识薄弱点,为学生优化学习提供有效的技术支持。图1所示为基于Hadoop平台的系统设计框架。
(二)数据来源
学校在实施数字化校园建设时,以信息化、自动化、智能化驱动重点领域改革,将数字化业务流程融入教学管理、科研创新等领域工作,构建基于云服务的数据平台,打破数据孤岛效应,实现数据标准化无缝交换,有效解决了跨部门、跨业务领域数据同步和工作协调的问题。一方面,通过部署新一代智能协同管理平台,搭建在线教学、图书馆管理、校园一卡通、教务管理、学籍管理、学生工作管理等业务功能子系统,依托人脸识别、物联网技术提升教学管理基础设施,实现学校全面数字化管理,促进智慧校园应用全面融合,智能管理。另一方面,基于大数据形成高度融合互通的全院校本数据应用中心,通过数据采集、清洗整合和深度挖掘、辅助决策,为师生以及相关用户提供全面精细化数据综合查询,充分发挥数据共享效益,为构建学校信息化应用体系实施提供大数据支撑。另外,基于云应用的信息化系统,可以在教学管理过程中,以系统日志或实时服务方式,记录行为发生时间、行为类型及相关系统信息,为人才分类精准培养平台提供了持续、有效的数据来源。
近年来,高职院校积极探索推进线上线下教育教学新模式,推动教育教学改革,在线学习平台已经作为主要教学载体,平台不仅聚合了教师、学生、管理者等使用者的基础信息数据,而且在课前、课中、课后不同教学环节同步产生多维大数据,大量的数据真实反映了师生日常教与学行为和活动过程状况,为分析和改进教育教学过程提供了丰富的数据基础。
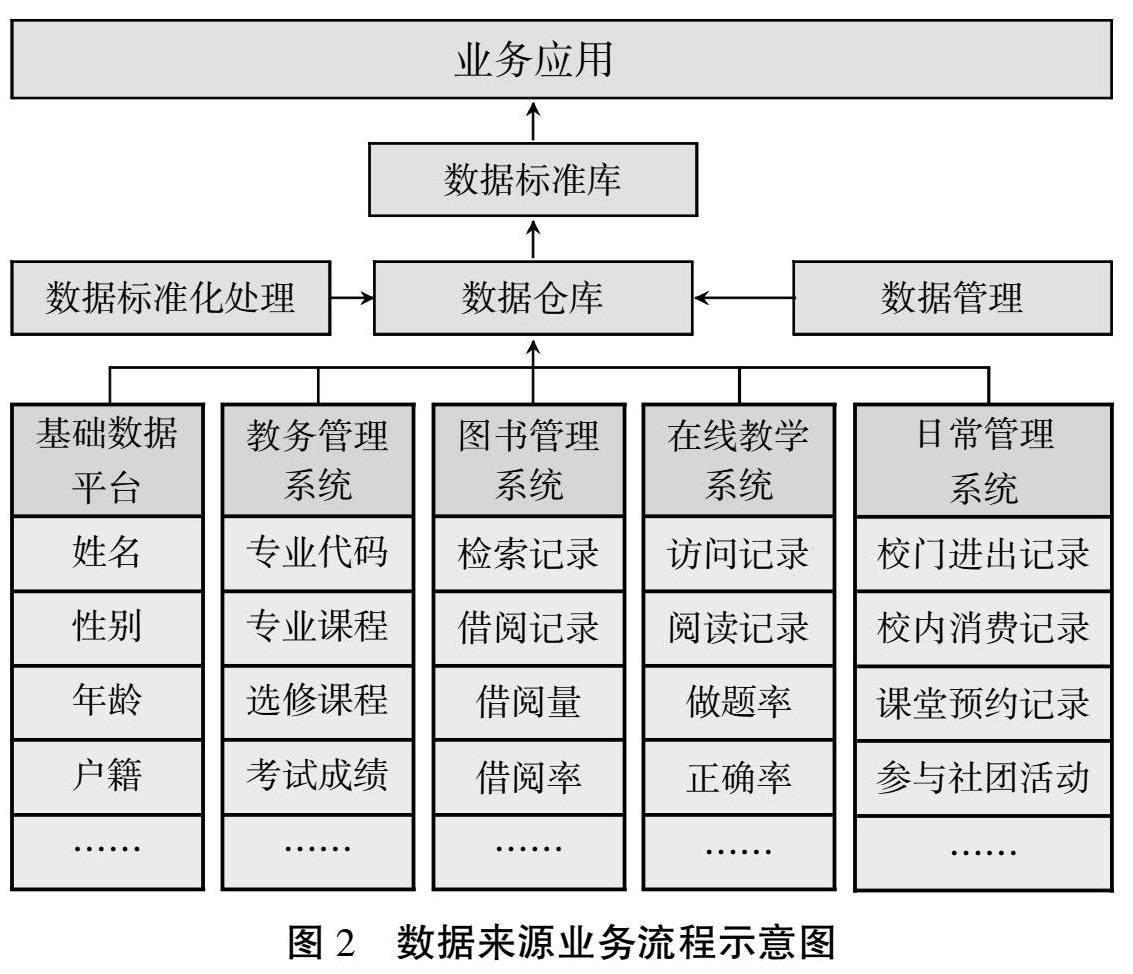
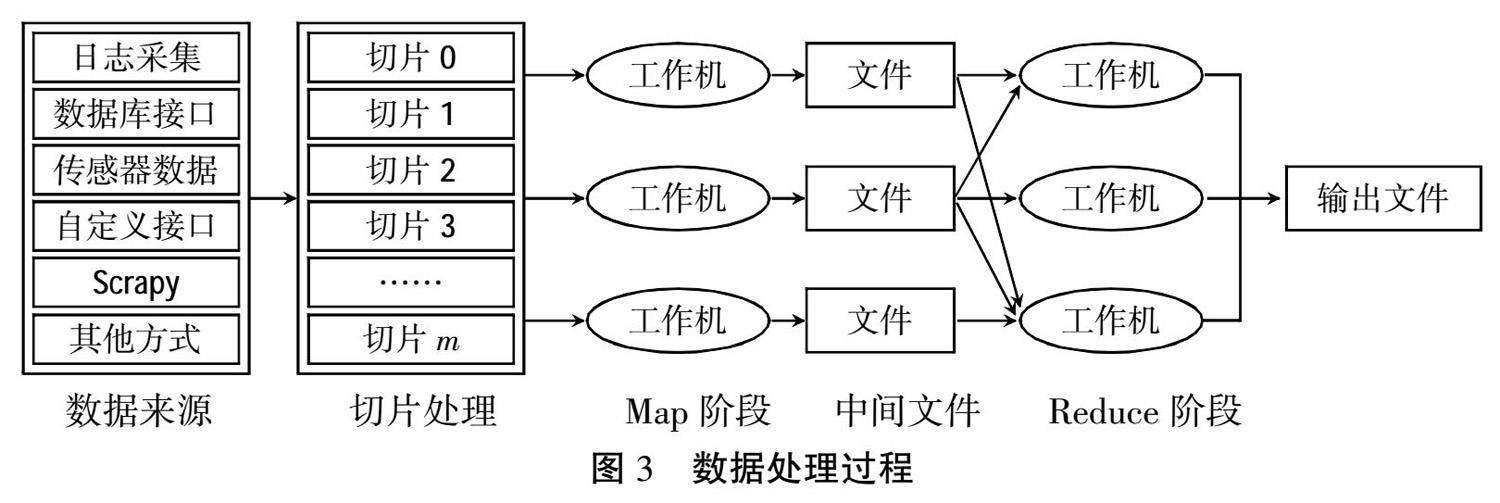
图2的示意图显示了数据来源业务流程,数据来源主要是从基础数据平台、教务管理系统、图书管理系统、在线教学系统、日常管理系统等获得相关数据,完成学习者数据的采集工作后,会将采集的数据存储在HDFS上,再使用MapReduce分布式并行计算来对海量数据进行处理,通过对原始数据进行清洗处理,保证数据的有效性和可信度,完成从数据到信息到知识的有效过渡[9],过程如图3所示。
在数据结构及接口标准方面,人才分类精准培养平台系统为了能与教育管理部门的信息平台进行数据对接,如全国职业教育智慧大脑院校中台,参考教育部职业教育与成人教育司、教育部教育管理信息中心2023年6月发布的《全国职业教育智慧大脑院校中台高职数据标准及接口规范(试行)》、教育部《职业院校数字校园规范》(教职成函〔2020〕3号)等技术标准,例如,数据项结构由编号、数据项名、中文简称、类型、长度、约束、值空间、解释、引用编号等9项内容进行组合[10]。
编号:数据项的唯一标识,标注出数据大类、子类、类别等信息。
数据项名:由中文简称的汉语拼音首字母(大写)组成,或标识语义的英文字母组成,与中文简称一一对应,具有良好的可读性与可解释性。
中文简称:所用的数据元的名称,具有语义,面向用户。
类型:数据项使用的数据类型,常见有字符型(VARCHAR)、日期型(YYYYMMDD)等。
长度:数据项能容纳的最大字符数(一种属性)。
约束:数据项约束状态的描述,即必备数据项或可选数据项。
值空间:数据项取值的范围与规范属性。
解释/举例:数据项属性的说明或举例。
引用编号:指明此数据项引用其他已定义数据项的编号。
(三)行为画像
行为画像是人才分类精准培养的核心关键点,需要利用数据统计、数据分析、数据挖掘等数据处理分析方法,对学生基本信息、学习状态、行为表现等数据进行有效处理,依据学生的行为过程数据,对学生个体特征、学习态势、生活习惯各方面的状态进行标签化,构建学生行为画像,实现对学生当前情况的全面把握、对学生未来情况的预测估计、为学习者设计学习内容、优化学习过程、更有效地达成教学目标。
学生行为画像的基础是个人数据的收集和分析处理,学生信息数据通常包括所属学院、所学专业、所在班级、学生姓名、性别、学号等内容,在属性方面有较高的相似性和辨识度,只需要进行归类处理,但反映日常行为的数据可能存在缺失值、重复值、异常值,或者数量级标签差异等,对于这些数据,需要进行预处理,如果直接使用会导致建模预测结果错误。
缺失值是指数据集中可能存在某个或某些属性的值不完全的情况,对于缺失值的处理方法一般是删除或者填充。可以采用Pandas提供了dropna( )方法进行缺失值删除,fillna( )方法填充缺失值,或者调用interpolate( )插值方法求得的值进行填充。数据集中难免会出现重复值,有些是需要的,有些是不需要的。不需要的重复值会影响数据分析的准确率,所以要进行处理,pandas提供了drop_duplicates( )方法删除重复值。对于异常值的处理必须重视,如果忽视这些异常值,在后续的数据分析中可能会导致结论的错误。检测异常值的常用方法有最大最小值法,标准差法和箱线图法。常用的异常值处理方法是删除和替换。如果要对检测出的异常值进行替换,要根据实际的情况确定替换的值,常常可以用最大值、最小值或者均值等。而对于可能存在数量级标签差异,此类数据需要进行归一化处理,即将学生的各项标签信息统一映射到[0,1]的区间内,各个标签都真实地反映其贡献度,使转化后的数据更好地呈现相应的归类效果,通常采用线性函数转换、反正切函数转换等方法对学生个人信息数据进行归一化处理。
学生行为数据画像核心部分是学生认知掌握程度诊断,学生学习行为的场景主要集中在静态考试,动态能力和学生在线学习,可以通过构建认知诊断模型来进行分析,基于深度学习建模方式的优势在于其较强的特征表征能力和复杂交互函数建模能力,其可提高认知水平建模准确性,目前常见的离散型认知诊断模型有DINA模型(Deterministic Inputs,Noisy and Gate),其具有建构简单、参数解释性好、判断准确性高的特点,通过DINA模型可以将学生表述为一个掌握知识点的多维向量,根据学生对知识点题目的作答进行结果判断,模型定义学生i在问题j上的作答情况如式(1)所示:
其中,η ij表示学生i在问题j上的潜在作答情况;表示学生i对知识点k的掌握情况,以及问题j对知识点k的考查情况;η ij = 1表示学生i已经掌握问题j所包含的所有知识点;η ij = 0表示学生i对问题j中的知识点至少有一个没有掌握。
DINA模型结合试题知识点关联矩阵Q矩阵,学生作答情况X矩阵对学生情况进行建模,在已知学生掌握知识点的条件下,答对试题j的概率为:
P j (α i) = P (Xij = 1│α i) (2)
其中,α i表示学生i的知识点掌握情况,sj表示学生掌握了试题j所关联的知识点情况下错误概率,g j表示学生在并不完全掌握试题j所关联的知识点情况下猜对概率。
(四)匹配预测
在完成学生行为画像构建后,需要构建个体现状与职业发展岗位匹配预测模型。
在学生行为画像的基础上,系统根据学生的数据信息使用聚类算法进行全方位的分析对比,计算学生认知掌握程度与岗位职业素养的指标值之间的匹配运算,产生不同维度的差异值,最终给出与岗位匹配度情况。
1.系统根据职业岗位对学习者各方面的能力要求进行细分,形成参照指标体系。
2.通过学生基础数据加权系数后,对信息数据进行筛选,形成与参照指标体系相同的个人指标体系。
3.使用聚类K-Means算法,进行个人指标体系与岗位参照指标体系差异化对比,从而得到多维度分值,表示其与岗位的匹配度情况。
具体实现过程如下:
学生个人指标体系作为样本集,设每个样本x = x (1),x (2),…,x (k)),以岗位数目作为聚类簇数(假设为k),初始簇的聚类中心由系统随机选择k个数据点,设C = C 1,C 2,…,C k,计算出每个样本离哪个簇的中心arg k min距离值,根据距离最短原则将样本分配到对应的簇中,根据这个划分不断反复迭代来更新聚类,再用这K个聚类的簇作为新的中心检查收敛性,,直到聚类中心值不能带来新的分类结果变化,或完成最大迭代次数。最后根据聚类中心与岗位参照指标体系的差异来预测个体与岗位的匹配度。同时,也有助于从各个簇中挖掘其他有价值的隐含信息。
三、人才分类精准培养平台的应用
系统可以帮助学生清楚把握自己的综合状态,做出精准的职业发展规划,并由系统提供对应的职业能力培养实施计划。学生在系统的辅助下,在不同的时间点对自己的当前情况进行较为准确的态度数据分析,并以预设的职业岗位技能、能力、素质等标准体系指标为参照,测算出当前的职业匹配值,学生可以根据预测值找到自己在学习过程中的偏差,及时发现自己的问题,做出合理的、适时的调整。系统会整合后台的丰富教学资源,更有针对性地给学生进行推送,支撑学生的职业发展能力培养需求。
参考文献:
[1]薛宏.河南省普通高等学校分层分类发展研究[D].郑州:郑州大学,2016.
[2]刘海蓉.高职院校人才分类培养和分层教学探索[J].河北交通教育,2019(1):11-14,34.
[3]袁咏平.高职院校人才分类培养和分层教学研究[J].北京经济管理职业学院学报,2018,33(3):55-58, 71.
[4]韩雪平,基于学生个性化发展的高职学生分类培养研究:以河南职业技术学院为例[J].才智,2020(11):130-131.
[5]梁赞,吕春丽.高职扩招生源实施“分类培养”教育模式的应对之策[J].科技视界,2020(9):11-13.
[6]阮志刚,廖崎兵.基于高职院校生源结构现状的分类分层培养路径探索[J].现代职业教育,2019(9):92-94.
[7]张军,苑占江,郑述招.高职IT专业群“分类培养、精准育人”的创新与实践[J].职业技术,2022,21(7):1-8.
[8]何景师.生源多样化背景下职业院校分层分类精准育人的培养模式[J].机械职业教育,2021(3):41-44.
[9]陈瑞辉,李冬青,吴婷婷.基于大数据的学情分析系统设计[J].信息技术与信息化,2021(9):57-60.
◎编辑 张 慧
①基金项目:广东女子职业技术学院2021年度校级科研项目(粤女院[2021]44号)(ZDXM202106)。
作者简介:谢盛嘉(1975—),男,汉族,广东博罗人,副教授,硕士研究生,研究方向:计算机应用、数据智能处理。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
当代陕西(2020年21期)2020-12-14 08:14:36
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
NBA特刊(2018年11期)2018-08-13 09:29:22
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
民生周刊(2017年19期)2017-10-25 16:48:02
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
